
Этот пост основан на лекции «Deep Learning: Theoretical Motivations» («Глубокое обучение: теоретические обоснования») доктора Йошуа Бенджио (Dr. Yoshua Bengio), которую он читал в летней школе по глубокому обучению в Монреале (2015 год). Мы рекомендуем её прослушать – так вы лучше поймете нижеизложенный материал.
Глубокое обучение – это набор алгоритмов машинного обучения, основанных на изучении множества уровней представления. Множество уровней представления означают множество уровней абстракции. В этом посте рассматривается проблема обобщения, то есть возможности определять сложные объекты на основании успешно изученных уровней представления.
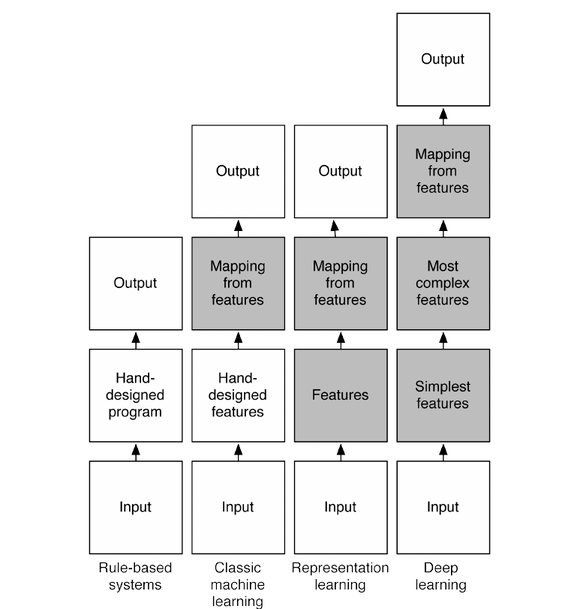
Схема выше показывает, как взаимодействуют части системы в различных подразделах искусственного интеллекта. Серым отмечены блоки, способные обучаться.
Экспертные системы
Экспертная система – это программа искусственного интеллекта, все алгоритмы поведения которой прописаны человеком вручную. Необходимые для этого знания предоставляются экспертами из той или иной области. Для ответа на заданные вопросы такие системы используют факты и объединяющую их логику.
Классическое машинное обучение
В классическом машинном обучении важные экспертные знания вводятся вручную, однако затем система обучается, организуя вывод данных на основании самостоятельно изученных признаков. Этот тип машинного обучения широко используется для решения простых задач распознавания объектов. При проектировании таких систем большая часть времени тратится на выбор верного обучающего набора данных. Когда знания экспертов удается формализовать, то для получения выходных данных используется обычный классификатор.
Обучение представлениям (Representation Learning)
По сравнению с классическим машинным обучением обучение представлениям делает шаг вперед и исключает необходимость формализации знаний экспертов. Все важные закономерности система определяет самостоятельно на основании введенных данных (как, например, в нейронных сетях).
Глубокое обучение
Глубокое обучение – это часть более широкого семейства методов машинного обучения – обучения представлениям, где векторы признаков располагаются сразу на множестве уровней. Эти признаки определяются автоматически и связывают друг с другом, формируя выходные данные. На каждом уровне представлены абстрактные признаки, основанные на признаках предыдущего уровня. Таким образом, чем глубже мы продвигаемся, тем выше уровень абстракции. В нейронных сетях множество слоев представляет собой множество уровней с векторами признаков, которые генерируют выходные данные.
Путь к искусственному интеллекту
Чтобы создать искусственный интеллект, нам нужны три главных ингредиента:
1. Большие объемы данных
Для создания системы искусственного интеллекта требуется огромный объем знаний. Эти знания формализуются людьми или формируются на основании других данных (как в случае машинного обучения), необходимых для принятия верных решений. Сегодня подобные системы способны обрабатывать видео, изображения, звук и так далее.
2. Очень гибкие модели
Одних данных недостаточно. На основании собранных данных нужно принять какое-то важное решение, более того, всю информацию нужно где-то хранить, поэтому модели должны быть достаточно большими и гибкими.
3. Априорные знания
Априорные знания позволяют «снять» проклятие размерности путем сообщения системе достаточного количества знаний о мире.
Классические непараметрические алгоритмы способны обрабатывать огромные объемы данных и имеют гибкие модели, однако требуют проведения процедуры сглаживания. Этот пост, в большинстве своем, посвящен именно этому третьему ингредиенту.
Что нам нужно?
Знания. Мир – очень сложная штука, а искусственный интеллект должен научиться понимать его. Чтобы система научилась понимать мир так, как понимаем его мы, потребуется огромное количество знаний – гораздо большее, чем системы машинного обучения имеют на данный момент.
Обучение. Обучение – это очень важный процесс, позволяющий искусственному интеллекту самостоятельно обретать сложные знания. Обучающие алгоритмы включают в себя два элемента: априорные знания и методы оптимизации.
Обобщение. Этот аспект является самым важным в машинном обучении. Обобщение – это попытка угадать, какой результат является наиболее вероятным. С точки зрения геометрии – это попытка угадать, где расположен центр масс.
Способы борьбы с проклятием размерности. Оно является следствием появления переменных высокой размерности, повышающих сложность функции. Даже при наличии всего двух измерений, количество возможных конфигураций огромно. Если же измерений множество, то совладать со всеми доступными конфигурациями практически нереально.
Решение проблемы объясняющих факторов. Искусственный интеллект должен понимать способы и причины получения данных. Это та проблема, которой сейчас занимается наука – проводятся эксперименты и проверяются способы объяснения мира. Глубокое обучение – это шаг навстречу искусственному интеллекту.
Почему не классические непараметрические алгоритмы?
Для термина «непараметрические» существует множество определений. Мы говорим, что обучающий алгоритм является непараметрическим, если сложность функций, которые он способен изучить, растет с ростом объема тренировочных данных. Другими словами, это означает, что вектор параметров не фиксирован.
В зависимости от имеющихся у нас данных, мы можем выбрать семейство функций, которые будут более или менее гибкими. В случае линейного классификатора увеличение количества данных не приводит к изменению модели. Напротив, в нейронных сетях мы имеем возможность выбрать большее количество скрытых элементов.
Термин «непараметрический» не означает «не имеет параметров» – он означает «не имеет фиксированных параметров», то есть мы можем выбрать количество параметров в зависимости от количества данных, которыми располагаем.
Проклятие многомерности
Проклятие многомерности – это следствие обилия конфигураций, возникающего из-за большого количества измерений. Число возможных конфигураций растет по экспоненте с ростом числа измерений. Таким образом, встаёт задача машинного обучения – получить неизвестную нам конфигурацию.
Классический подход в непараметрической статистике уповает на «гладкость». Такой подход хорошо работает при небольшом числе измерений, однако при достаточно серьезном их количестве в конечный результат могут попасть или все примеры, или ни одного, что само по себе бесполезно. Чтобы провести локальное обобщение, нам понадобятся примеры представлений для всех релевантных исходов. Невозможно выполнить локальное усреднение и получить что-нибудь стоящее.
Если мы углубимся в математику, то увидим, что число измерений – это количество различных вариаций изучаемых нами функций. В этом случае понятие равномерности относится к количеству впадин и выпуклостей, представленных на кривой.
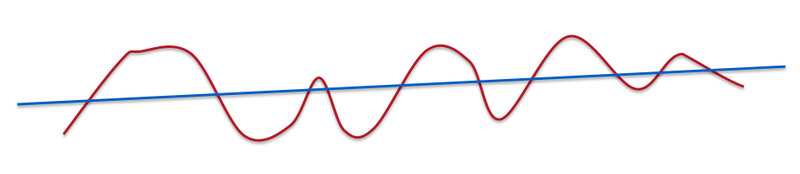
Линия – это очень гладкая «кривая». Кривая с несколькими выпуклостями и впадинами по-прежнему гладкая, но уже в меньшей степени.
Изучаемые нами функции не гладкие. В таких случаях, как компьютерное зрение или обработка натурального языка, целевая функция получается очень сложной.
Многие непараметрические статистические методы полагаются на гауссову функцию влияния, усредняющую значения в определенной небольшой области. Однако ядерным машинам, использующим распределение Гаусса, требуется как минимум k примеров для изучения функции, имеющей 2k пересечений оси x. С ростом числа измерений количество выпуклостей и впадин увеличивается по экспоненте. Можно получить очень негладкую функцию даже в одном измерении.

Если подходить к проблеме с точки зрения геометрии, то мы должны поместить вероятностную меру туда, где структура наиболее правдоподобна. В случае эмпирической функции распределения мера попадает на тренировочные примеры. Рассмотрим иллюстрацию выше, где представлены двумерные данные. Если считать график гладким, то вероятностная мера оказывается равномерно распределенной между примерами.
Округлые фигуры изображают Гауссовы ядра для каждого примера. К такому подходу прибегают многие непараметрические статистические методы. В случае двух измерений все выглядит достаточно просто и реализуемо, однако с увеличением числа измерений размеры кругов (шаров) увеличиваются настолько, что перекрывают собой все пространство или же, наоборот, оставляют пустые места там, где должна находиться максимальная вероятность. Поэтому нам не стоит уповать на гладкость функции и нужно придумать что-нибудь более эффективное – какую-нибудь структуру.
На изображении выше такой структурой является одномерное многообразие, где собрана вероятностная мера. Если мы сможем определить представление вероятности, то решим наши проблемы. Представление может быть меньшей размерности или располагаться вдоль других осей в том же измерении. Мы берем сложную нелинейную функцию и встраиваем её в Евклидово пространство, изменяя представление. Так проще делать предсказания, проводить интерполяцию и осуществлять оценку плотности распределения.
Снимаем проклятие
Гладкость была главным требованием в большинстве непараметрических методов, но довольно очевидно, что с её помощью мы не можем побороть проклятие размерности. Мы хотим, чтобы гибкость семейства функций росла при увеличении количества данных. В нейронных сетях мы изменяем количество скрытых элементов в зависимости от объема данных.
Наши модели машинного обучения должны стать композиционными. Натуральные языки используют композиционность, чтобы представлять более сложные идеи. В глубоком обучении мы используем:
- Распределенные представления;
- Глубокую архитектуру.
Давайте предположим, что данные поступают к нам не все сразу, а партиями. Партии могут поступать или параллельно, или последовательно. Параллельное поступление партий являет собой распределенное представление (обучение представлениям). Последовательное поступление данных похоже на обучение представлениям, но с несколькими уровнями. Композиционность дает нам возможность эффективного описания мира вокруг нас.
Мощь распределенных представлений
Нераспределенные представления
Среди методов, не использующих распределенные представления, можно выделить кластеринг, метод N-грамм, метод ближайших соседей, метод радиальных базисных функций и опорных векторов, а также метод дерева решений. На вход таких алгоритмов подается пространство, а на выходе получаются области. На выходе некоторых алгоритмов получаются строгие разделения, а на выходе других нестрогие, позволяющие гладкую интерполяцию между близлежащими областями. Каждая область обладает своим набором параметров.
Результат, который сообщает область, и её местоположение регулируются данными. С количеством областей связано понятие сложности. С точки зрения теории обучения, обобщение зависит от отношения числа необходимых примеров и сложности. Богатая функция требует большего количества областей и данных. Существует линейная зависимость между числом различимых областей и числом параметров. Также существует линейная зависимость между числом различимых областей и числом тренировочных примеров.
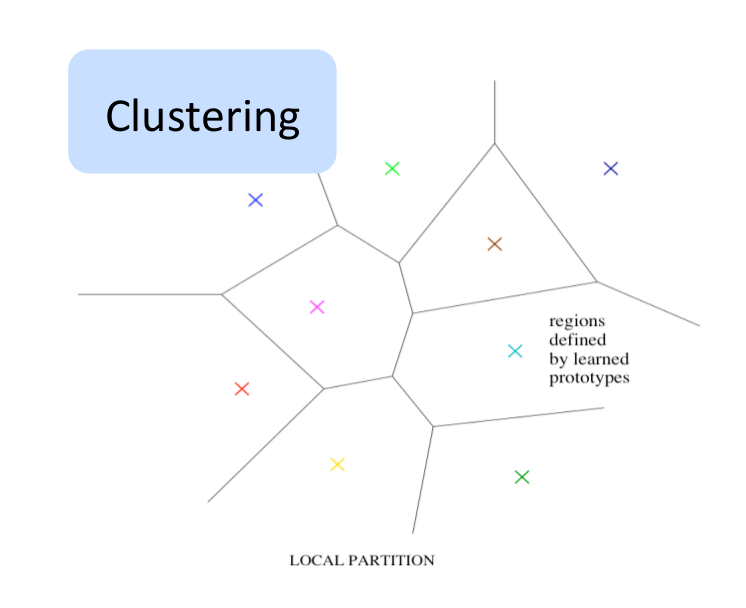
Почему распределенные представления?
Вот другой вариант. Возможно представить экспоненциальное количество областей линейным набором параметров, используя распределенные представления. Магия распределенного представления заключается в том, что с его помощью можно изучить очень сложную функцию (с множеством выпуклостей и впадин), имея в распоряжении небольшое количество примеров.
В нераспределенных представлениях количество параметров находится в линейной зависимости от числа областей. Отсюда следует, что количество областей может расти экспоненциально числу параметров и примеров. В распределенных представлениях отдельные признаки имеют значение, не зависящее от других признаков. Различные корреляции имеют право на существование, но большинство признаков изучаются вне зависимости друг от друга. Нам не обязательно знать все конфигурации, чтобы принять правильное решение. Несовместные признаки создают большой комбинаторный набор различных конфигураций. Все преимущества видны при использовании всего одного слоя – количество примеров может быть очень маленьким.
Однако такое преимущество не наблюдается на практике – оно большое, да – но не экспоненциальное. Если представления хорошие, то они разворачивают многообразие в новой плоской системе координат. Нейронные сети преуспели в изучении представлений, затрагивающих семантические аспекты. Обобщение образовывается на основании таких представлений. Если пример находится в пространстве, где нет никаких данных, то непараметрическая система не сможет сказать о нем ничего. Используя распределенные представления, мы можем делать выводы о том, что никогда не видели. Это суть обобщения.
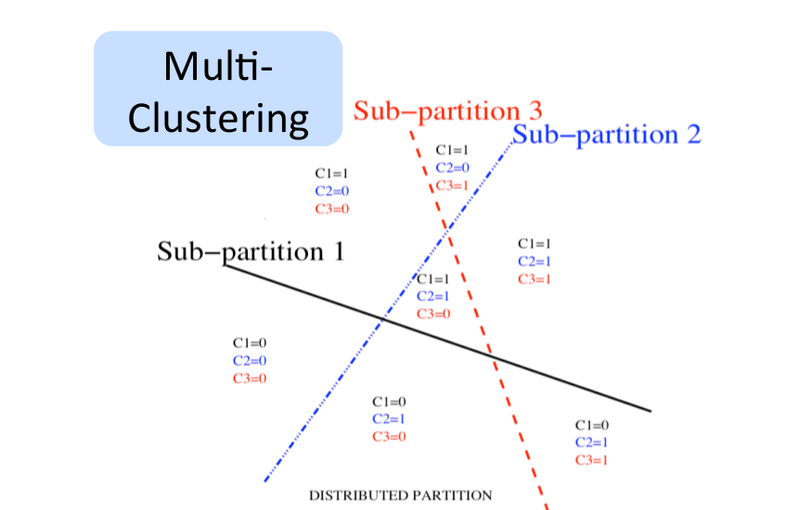
Классический символьный искусственный интеллект и обучение представлениям
Распределенные представления лежат в основе коннекционизма или коннеционистского подхода, зародившегося в 1980 году. Классический подход основан на понятии символов. В символьной обработке таких вещей, как язык, логика, или правила, каждая концепция ассоциирована с определенной сущностью – символом. Символ или существует, или нет.
Нет ничего, что бы определяло связи между ними. Обратимся к примеру с собакой и кошкой. В символьном искусственном интеллекте – это два разных символа, не имеющие никакой взаимосвязи между собой. В распределенном представлении они имеют схожие особенности, к примеру, они являются питомцами, имеют 4 лапы и так далее. Можно расценивать эти концепции как шаблоны признаков или шаблоны активизации нейронов в мозгу.
Распределенное представление в программировании натурального языка
С помощью распределенных представлений удалось добиться очень интересных результатов в обработке натурального языка. Я рекомендую ознакомиться со статьей «Deep Learning, NLP, and Representations» («Глубокое обучение, программирование натурального языка и представления»).
Мощь глубоких представлений
Многие неправильно понимают слово «глубокий». Исследование глубоких нейронных сетей не проводилось раньше, поскольку люди считали, что в них нет нужды. Плоская нейронная сеть с одним слоем скрытых элементов способна представить любую функцию с заданной степенью точности.
Это свойство называется универсальной аппроксимацией. Однако в этом случае мы не знаем, сколько скрытых элементов нам понадобится. Глубокая нейронная сеть позволяет значительно уменьшить количество скрытых элементов – снизить стоимость представления функции. Если мы пытаемся изучить глубокую функцию (имеющую множество уровней композиции), то нейронной сети понадобится большее число слоев.
Глубина не является необходимостью: не имея глубоких сетей, мы по-прежнему можем получить семейство функций с достаточной гибкостью. Более глубокие сети не обладают большей емкостью. Глубже – не означает, что мы можем представить больше функций. Использовать глубокую нейронную сеть стоит тогда, когда изучаемая нами функция обладает определенными характеристиками, ставшими результатом композиции нескольких операций.
«Плоская» и «глубокая» компьютерная программа
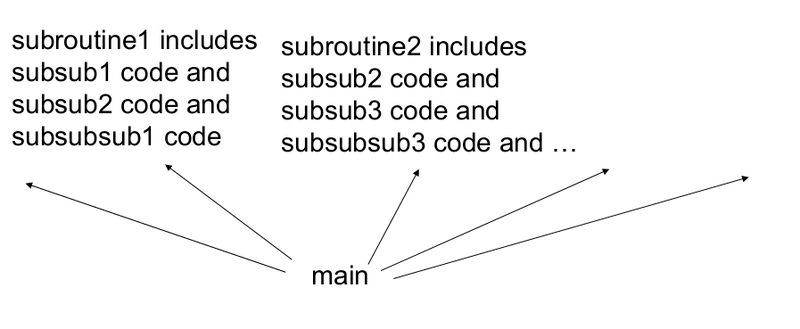
«Плоская» программа
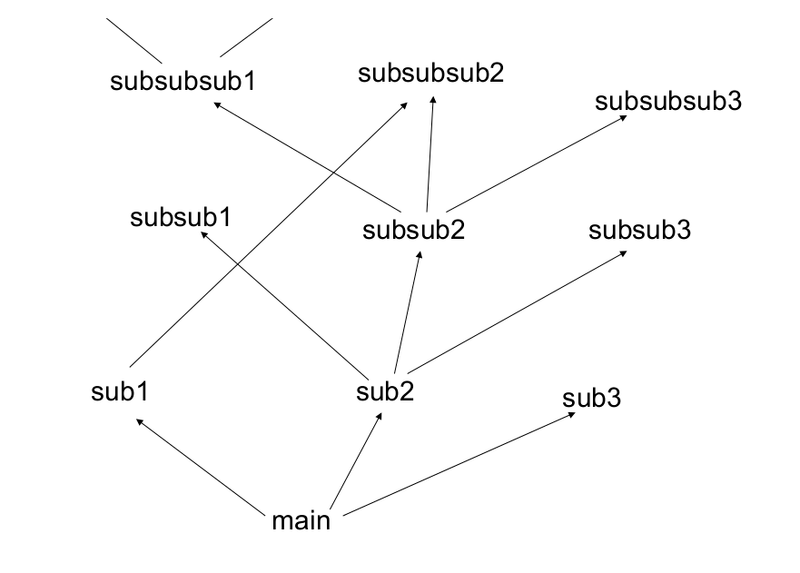
«Глубокая» программа
При написании компьютерных программ мы не располагаем все строки кода друг за другом – обычно мы используем подпрограммы. Так вот, скрытые элементы выступают в качестве подпрограммы для большой программы – финального слоя. Можно считать, что результат вычислений каждой строки программы меняет состояние машины, одновременно передавая свой вывод другой строке. Каждой строке на вход подается состояние машины, а на выходе строки появляется уже другое состояние.
Это похоже на машину Тьюринга. Количество шагов, выполняемых машиной Тьюринга, зависит от глубины вычислений. В принципе, мы можем представить любую функцию за два шага (таблица поиска), однако это не всегда эффективно. Ядерный метод опорных векторов или плоская нейронная сеть могут рассматриваться как таблица поиска. Нам нужны более глубокие программы.
Разделяемые компоненты
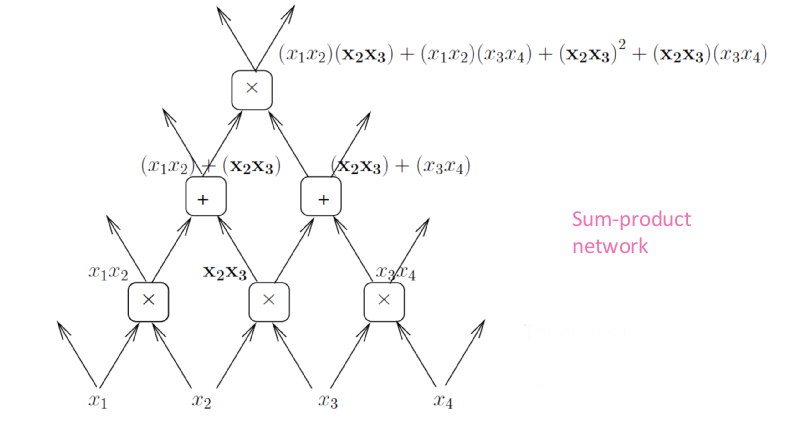
Полиномы часто представляются как суммы произведений. Еще одним способом представления является граф вычислений, где каждая вершина производит сложение или умножение. Подобным образом мы можем представить и глубокие вычисления – так количество вычислений уменьшится, поскольку мы сможем повторно использовать некоторые операции.
Однако глубокие сети с вентильными нейронными модулями гораздо дороже элементов плоских сетей, поскольку они способны разделять пространство на большее количество линейных областей (с условиями).
Иллюзия выпуклости
Одной из причин отвержения нейронных сетей в 90-х годах стала невыпуклость проблемы оптимизации. С конца 80-х и начала 90-х годов мы знаем, что в нейронных сетях имеется экспоненциальное количество локальных минимумов. Это знание, наряду с успехом ядерных машин в 90-х годах, сыграло свою роль и сильно снизило интерес многих исследователей нейронных сетей.
Они считали, что раз оптимизация является невыпуклой, то нет никаких гарантий нахождения оптимального решения. Более того, сеть могла зациклиться на плохих, неоптимальных решениях. Исследователи изменили свое мнение совсем недавно. Появились теоретические и эмпирические доказательства того, что проблема невыпуклости – вовсе не проблема. Это поменяло все наше представление об оптимизации в нейронных сетях.
Седловые точки
Давайте рассмотрим проблему оптимизации на малом и большом количестве измерений. В малых измерениях существует множество локальных минимумов. Однако в высоких измерениях локальные минимумы не являются критическими точками (точками интереса). Когда мы оптимизируем нейронные сети или любую другую функцию нескольких переменных, для большинства траекторий критические точки (точки, где производная равняется нулю или близка к нему) являются седловыми. Седловые точки являются неустойчивыми.
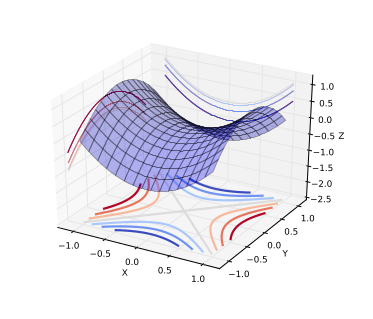
На изображении выше как раз приведена седловая точка. Если точка является локальным или глобальным минимумом, то при движении от неё во всех направлениях будет наблюдаться увеличение значений функции (при движении от локального максимума – уменьшение). При наличии фактора случайности в задании функций или при независимом выборе направления движения, крайне маловероятно, что функция будет возрастать во всех направлениях в других точках, кроме глобального минимума.
Интуитивно понятно, что если мы обнаружили минимум, который близок к глобальному, то функция будет возрастать во всех направлениях – ниже этой точки опуститься нельзя. Статистическая физика и матричная теория предполагают, что для некоторых семейств функций (достаточно большого их количества), наблюдается концентрация вероятности между индексом критических точек и целевой функцией.
Индекс – это коэффициент направления, определяющий, в каком направлении происходит уменьшение значения функции. Если индекс равен нулю – это локальный минимум, а если индекс равен единице – это локальный максимум. Если индекс равен числу между нулем и единицей, то это седловая точка. Таким образом, локальный минимум – это частный случай седловой точки, индекс которой равняется нулю. Чаще всего встречаются именно седловые точки. Эмпирические результаты показывают, что, действительно, между индексом и целевой функцией существует сильная связь.
Это лишь эмпирическая оценка, и нет доказательств того, что результаты подходят для оптимизации нейронных сетей, однако подобное поведение соответствует теории. На практике видно, что стохастический градиентный спуск всегда будет «покидать» поверхности, где нет локального минимума.
Другие методы, работающие с распределенными представлениями
Путь человека
Люди способны делать выводы на основании очень небольшого количества примеров. Дети обычно учатся делать что-то новое на небольшом количестве примеров. Иногда даже на основании одного, что статистически невозможно. Единственное объяснение – ребенок использует какие-то знания, полученные им до этого. Априорные знания могут быть использованы для построения представлений, благодаря которым, уже в новом пространстве, появляется возможность сделать вывод на основании всего одного примера. Человек в большей степени опирается на априорные знания.
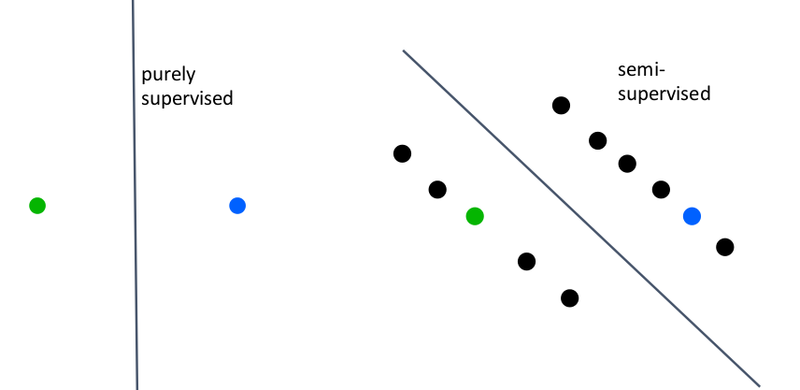
Методы частичного обучения
Частичное обучение – это нечто среднее между обучением с учителем и без учителя. В обучении с учителем мы используем только маркированные примеры. В частичном обучении мы дополнительно используем немаркированные примеры. На изображении ниже показано, как частичное обучение может найти лучшее разделение, используя неразмеченные примеры.
Многозадачное обучение
Приспособление к решению нового типа задач – это очень важный момент в разработке искусственного интеллекта. Априорные знания – это связывающие знания. Глубокие архитектуры учат промежуточные представления, которые могут быть разделены между заданиями. Хорошие представления, увеличивающие коэффициент вариации, применимы для решения множества задач, поскольку каждое задание учитывает поднабор признаков.
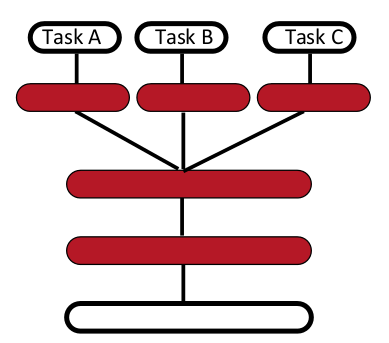
Следующая схема иллюстрирует многозадачное обучение с различными входными данными:

Изучение множества уровней абстракции
Глубокое обучение позволяет изучать большие уровни абстракции, увеличивающие коэффициент вариации, что упрощает процесс обобщения.
Заключение
- Распределенное представление и глубокая композиция позволяют значительно улучшить способности к обобщению;
- Распределенное представление и глубокая композиция выдают нелокальное обобщение;
- Локальные минимумы не являются проблемой из-за седловых точек;
- Необходимо пользоваться другими методами, такими как частичное обучение и многозадачное обучение, способными лучше обобщать глубокие распределенные представления.
Комментарии (9)

dtestyk
17.11.2015 17:12Плоская нейронная сеть с одним слоем скрытых элементов способна представить любую функцию с заданной степенью точности. Это свойство называется универсальной аппроксимацией.
Если это так, то что мешает трасформировать глубокую сеть после окончания обучения в однослойную?
barmaley_exe
19.11.2015 23:57Теоретически — ничто не мешает. С практической же точки зрения
1. Непонятно, как это делать.
2. Размер нейросети может вырасти экспоненциально.
dtestyk
17.11.2015 19:03Локальные минимумы не являются проблемой из-за седловых точек;
а не превращается ли проблема локальных минимумов в проблему поиска выхода из лабиринта со стенками из высоких значений?
kraidiky
20.11.2015 03:35+1Именно в это оно и превращается. И это ещё в лучшем случае. В худшем вы вообще получаете что-то такое:
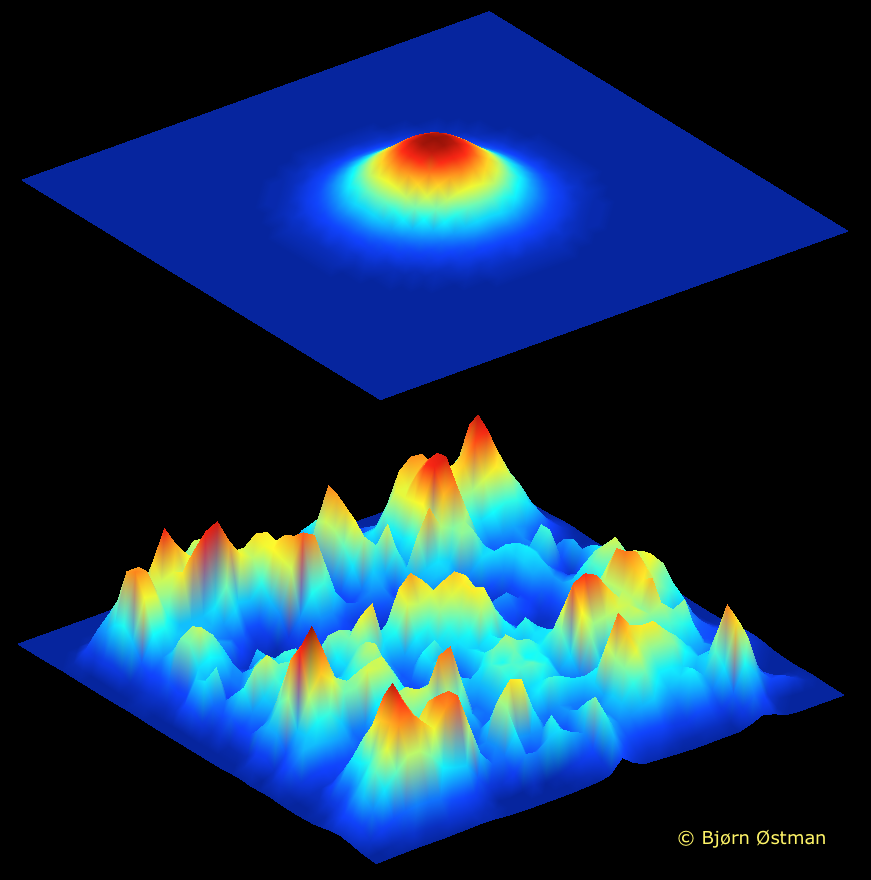
Тему как на таком ландшафте найти хоть что-нибудь автор вообще не затронул, только вскользь упомянув стохастические методы, хотя понятно понятно, что в такой ситуации это самое серьёзное ограничение.
В моей статье: habrahabr.ru/post/221049 Я как раз показываю пример как реальная нейронная сеть на достаточно реальной задаче ползает вдоль и поперёк как раз по такому ландшафту.
ServPonomarev
Писать про глубокие сети и ни разу не упомянуть машину Больцмана? Ведь именно она позволила уйти от проклятия алгоритма обратного распространения (быстрого затухания) и строить современные глубокие сети (с количеством слоёв больше 3-х). Нет упоминаний о свёрточных слоях — а это тоже один из столпов глубоких сетей.
barmaley_exe
А сейчас RBM'ки где-то используются? Тогда их использовали для предобучения, но теперь придумали новые трюки (например, дропаут, правильная инициализация, нормализация), с помощью которых можно обучать полносвязные нейросети, не занимаясь их предобучением.
А вот без свёрточных сетей действительно никуда.
mephistopheies
очень важно что именно теория РБМов позволила доказать теорему о том что добавление нового слоя увеличивает нижнюю вариационную границу правдоподобия глубокой сети, проще говоря, добавление нового слоя — это хорошо; так же как и лет 50 до этого Колмогоров и Арнольд решили 13-ую проблему Гильберта, что легло в основу универсально аппроксимационной теоремы, суть которой в том что любую функцию можно аппроксимировать нейросетью с одним скрытым слоем, или, больше нейронов в слое — это хорошо
на счет практики, ну тут тоже не соглашусь, РБМ положили начало претрейнингу, и например тут benanne.github.io/2015/03/17/plankton.html это эксплуатируется
в то же время все отцы сетей, Хинтон, ЛеКунн и другие признают, что все равно придется прийти к ансупервайзд претрейнингу, каким либо способом, тк размеченных данных в мире не так много
barmaley_exe
А можно ссылку на статью? А то я не очень понимаю смысл утверждения.
Согласно википедии, ещё в 91-м году было известно, что в корне этой теоремы лежит многослойность. Ну и очевидно, что отсюда при добавлении нового слоя выразительная сила сети увеличивается, так что было бы крайне удивительно, если бы нижняя вар. оценка не улучшалась.
Dieleman, конечно, вполне авторитетен, но вот Goodfellow, например, говорит:
kraidiky
Область нейронных сетей сейчас всё же исследуется скорее как естественная экспериментальная наука, нежели как математическая. Поэтому все эти открытия безусловно велики и могучи, но в при столкновении с практической исследовательской деятельностью сулят скорее разочарования.
Например, Колмогоров и Арнольд безусловно велики невероятно, мне такая как у них математика в мозг не поместиться при всём желании, однако о адаптивном ландшафте они ничего не говорят, а если он такой, как изображено на картинке снизу, то та самая точка, которая успешно всё аппроксимирует достижима градиентным спуском только из своих непосредственных окрестностей. А это значит, что нахождение такой точки примерно столь же вероятно, как то, что все атомы вашего тела случайно стунеллируют на метр вправо и там снова соберутся в ваш организм. Вероятность такая есть и это конечно радует…
Кроме того мы ничего не знаем о том на сколько устойчиво такое решение к применению к сети алгоритмов с элементами стохастики. А как мы знаем из практического опыта алгоритмы без стохастики годятся только для абстрактных рассуждений и теории. Получается что даже если нужное состояние мы случайно можем найти не факт, что нас не вынесет из него.
То же с претрейнингом. Для теоретических рассчётов RBM конечно пригодилась и даже, редко-редко, используется. Но мы же знаем, что во-первых, существует много способов учить глубокие сети и без претрейнинга, во-вторых, то что более глубокая сеть это хорошо, если вдруг её удалось обучить, эмпирически люди заметили давно, и если бы никакого доказательства не было копать бы в эту сторону не перестали. Рано или поздно нашли бы более простые и эффективные способы, известные сейчас. Так что спасибо РБМ-у и до свиданья.
Практическая исследовательская работа идёт и пока далеко опережает возможности математиков что-либо доказать в отношении нейронных сетей. Есть прорва хороших действенных алгоритмов глубокого обучения, и для большинства из них даже отдалённо непонятно со строгой математической стороны, почему они хорошие и лучше других.
А модет всё-таки к ансупервайзинг лёрнингу?