
Цель публикации — разобрать на рабочих примерах процесс извлечения геоданных OSM. В результате будет получен программный код (на C#), который можно собрать в Visual или Xamarin Studio, выполнить его на разных ОС (под Mono) и получить результат в форматах CSV и geoJSON. Ограничений на размер обрабатываемых OSM-данных нет (от минимального до полного). Публикация рассчитана на разработчиков ПО, без опыта работы с OSM.
Введение
Как самостоятельно получить ответ на вроде бы простые и понятные вопросы (просто так, для интереса):
— сколько на Земле государств, каково их население?
— где расположены на Земле города с населением, например, более миллиона человек?
— сколько на Земле вулканов?
Или (легко получить на основе примеров):
— где расположены больницы, гостиницы в вашем/чужом городе? А между городами?
— где расположены заправки, зоопарки, музеи, рестораны? Да всё что угодно.
Задачу, в общем виде, можно сформулировать примерно так — найти нужные объекты, определить их точное расположение (широту, долготу), название и другую доступную информацию.
Далее эти объекты можно отобразить, например, на карте (OSM, Google, Yandex). В публикации, для визуализации результатов, используется (автоматическое отображение на GitHub данных в формате geoJSON).
Базовые понятия и терминология
Точка (node)
Базовым элементом структуры данных OSM является точка (node) с географическими координатами — широтой (latitude) и долготой (longitude). Высота точки над уровнем моря, в настоящее время, не указывается.
Точка может быть самостоятельным объектом (светофор, киоск, родник) и, без ограничений, входить в состав других объектов (линий и отношений). Точками могут помечаться и большие объекты — страны, города и даже континенты с набором соответствующих тегов.
<node id="231477" lat="52.2600355" lon="0.0172928" version="2" timestamp="2011-02-27T02:33:27Z" changeset="7406582" uid="39894" user="markpeers"/>
<node id="231478" lat="52.2552032" lon="0.0281442" version="4" timestamp="2011-02-27T02:33:25Z" changeset="7406582" uid="39894" user="markpeers">
<tag k="exit_to" v="Bar Hill B1050; Longstanton"/>
<tag k="fixme" v="What is with all the layer=3s around this junction?"/>
<tag k="highway" v="motorway_junction"/>
<tag k="layer" v="3"/>
<tag k="name" v="Bar Hill"/>
<tag k="ref" v="29"/>
</node>
Атрибуты node:
— id — уникальный идентификатор в базе OSM (используется для way и relation);
— lat — широта, lon — долгота;
— uid и user — идентификатор и имя оператора, внёсшего изменения (используется для way и relation);
— version — версия изменения (используется для way и relation);
— timestamp — время изменения (используется для way и relation);
— changeset — номер изменения (что-то типа транзакции, которую можно применить или отменить) (используется для way и relation).
Теги:
— k=«highway» v=«motorway_junction» — указывает на начало съезда с дороги;
— k=«ref» v=«29» — номер съезда;
— k=«name» v=«Bar Hill» — название;
— k=«exit_to» v=«Bar Hill B1050; Longstanton» — куда;
— k=«layer» v=«3» — уровень;
— k=«fixme» v=«What is with all the layer=3s around this junction?» — автор сделал «узелок на память».
Количество точек в OSM, в настоящее время приближается к значению, которое превышает возможности 32-битного хранения. Поэтому OSM перешёл на 64 бита (для контроля количества точек в OSM даже сделан on-line монитор).
Линия (way)
Линия — это последовательности точек. Менять последовательность нельзя. Несколько линий, логически, могут представлять один объект. Например, длинная дорога состоит из нескольких линий. Линии одной дороги связаны в единое целое соблюдением условия — точка окончания одной линии строго соответствует точке начала другой линии или нескольких линий (в случае ветвления дороги или съезда на другую дорогу). Такая целостность по точкам для линий в OSM хорошо соблюдается.
Полигон — это замкнутая линия, у которой совпадают первая и последняя точки. Полигон не является самостоятельным элементом OSM. Для больших полигонов (границы государств, береговые линии), которые состоят из набора незамкнутых линий, определены правила. Например, при определении береговых линий, земля будет слева по ходу движения, вода — справа. Для административных границ явно указывается — кто слева по ходу движения, кто справа.
<way id="9933583" version="18" timestamp="2013-01-06T20:59:43Z" changeset="14555667" uid="30525" user="The Maarssen Mapper">
<nd ref="2098832234"/>
<nd ref="81448050"/>
<nd ref="1263117830"/>
<nd ref="1263117982"/>
<nd ref="81448052"/>
<nd ref="81448053"/>
<nd ref="81448054"/>
<nd ref="1297466013"/>
<nd ref="81448063"/>
<tag k="admin_level" v="6"/>
<tag k="boundary" v="administrative"/>
<tag k="left:county" v="Cambridgeshire"/>
<tag k="right:county" v="Essex"/>
<tag k="source" v="OS_OpenData_Boundary-Line"/>
</way>
Атрибут ref — указывает на id точки (для получения значения координат lat, lon). Важно учитывать последовательность элементов nd.
Теги:
— k=«boundary» v=«administrative» — административная граница;
— k=«admin_level» v=«6» — уровень 6;
— k=«left:county» v=«Cambridgeshire» — кто слева;
— k=«right:county» v=«Essex» — кто справа;
— k=«source» v=«OS_OpenData_Boundary-Line» — ссылка на первоисточник информации.
Отношение (relation)
Отношение — это логическое объединение точек, линий и других отношений в единый объект.
<relation id="2839278" version="1" timestamp="2013-03-25T13:56:31Z" changeset="15491865" uid="322785" user="BCNorwich">
<member type="way" ref="74424273" role="outer"/>
<member type="way" ref="4950089" role="inner"/>
<member type="way" ref="212392511" role="inner"/>
<member type="way" ref="212392522" role="inner"/>
<tag k="leisure" v="park"/>
<tag k="type" v="multipolygon"/>
</relation>
member — участники отношения;
type — тип объекта (node, way, relation);
ref — ссылка на id объекта;
role — роль объекта в отношении.
В данном примере описывается мультиполигон (multipolygon) — парк с внутренними областями (это могут быть, например, пруды, поляны или наоборот места с растительностью).
Примечание: далеко не все мультиполигоны так описаны.
Несмотря, на вроде-бы высокие функциональные возможности, отношения в OSM используются мало. Хотя есть попытки применять отношения к разным объектам. Например, такой сугубо точечный объект как автобусная остановка, по данным внутренней статистики OSM (статистика ведётся для большинства объектов) представлен: 1572243 точками, 2479 линиями и 1140 отношениями.
Объекты и теги (tag)
Объект — это элемент (точка, линия, отношение) с набором тегов (атрибутов). Тег (tag) определён как k=«ключ» v=«значение». Если элемент не имеет тегов, то он не является объектом, а входит в состав других объектов (с тегами тоже может входить).
Обязательных тегов у объекта нет. Нет обязательных требований по количеству, содержанию и порядку следования тегов. Тот кто вносит данные в OSM, сам определяет состав и содержание тегов (Перечень рекомендованных к использованию общепринятых тегов).
В разных странах, регионах или областях одинаковые объекты могут значительно различаться по составу и содержанию тегов. Например, город (city) может быть обозначен точкой или линией (полигоном). В OSM-статистике видны явные региональные предпочтения.
Города, отмеченные точками:
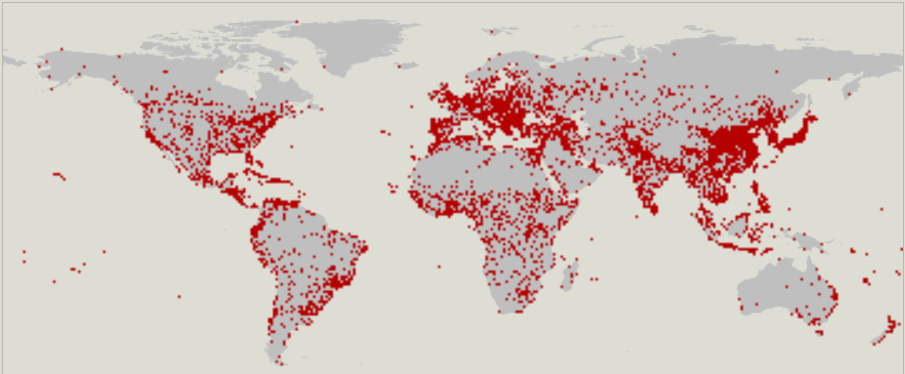
Города, отмеченные линиями:
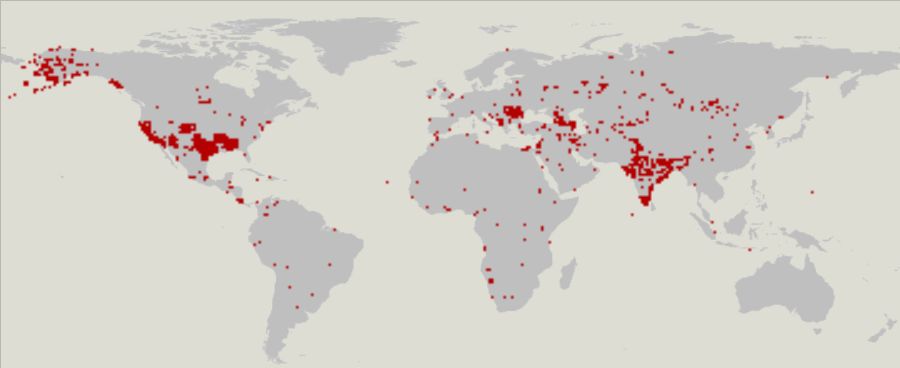
Поэтому, прежде чем использовать новый объект, желательно его исследовать на предмет того, какие теги, фактически, в нём используются.
Координаты и расстояния
Точные географические измерения довольно сложны. Надо учитывать: то что Земля не является идеальным шаром, высоту над уровнем моря, рельеф, разные модели проекций для отображения шарообразной Земли на плоскость.
В интернет картах используется проекция EPSG:4326 – WGS-84, которая базируется на широте и долготе спутниковой GPS навигации. Градусы указываются в десятичном виде: широта (lat=52.2600355), долгота (lon=0.0172928).
Например, есть две точки (вулканы на острове Тристана-да-Кунья):
1. Вулкан «Green Hill» (id=2079122352, lat=-37.1324274, lon=-12.3096104);
2. Вулкан «Red Hill» (id=2079124574, lat=-37.1200039, lon=-12.2383527).
Длина одного градуса широты: 1852 * 60 = 111120 м. (Длина одного градуса долготы: 1852 * 60 * COS(угла широты)).
Таким образом координаты точки в OSM (0.0000001) указаны с точностью ~ 1 см.
Расстояние между вулканами «Green Hill» и «Red Hill»:
?v((37.1324274 — 37.1200039)? + (12.3096104 — 12.2383527)?) = ?v0.00523200316154 ? 0.072332587 (или 0.072332587 * 111120 ? 8037.6 метров)
37.1324274 = 37°
Десятичный остаток в минуты: 0.1324274° * 60 = 7.945644'
Десятичный остаток в секунды: 0.945644' * 60 = 56.73864" ? 57"
Итого: 37.1324274° ? 37°07'57"
В десятичный вид:
37°07'57" = 37° + 7/60 + 57/3600 ? 37 + 0.11666667 + 0.01583333 ? 37.1325°
С учётом всех округлений, погрешность составила:
37.1325° — 37.1324274° = 0.0000726° (или 0.0000726 * 111120 ? 8 метров)
Откуда загрузить OSM-данные
Данные OSM хранятся в базе данных (БД). На регулярной основе происходит подготовка снимка БД в XML-формате в файл planet.osm. Заархивированный bzip2 файл занимает 45Gb, в распакованном виде — более 600Gb. Кроме этого есть зеркала planet.osm и ссылки на интернет-ресурсы, откуда можно скачать OSM-данные порезанные по регионам.
Для примеров публикации данные взяты с сервера geofabrik. Данные удобно порезаны по регионам и выложены, для выгрузки, в разных форматах: Shape-файлы (shp.zip), PBF-файлы (osm.pbf), XML-файлы (osm.bz2). В примерах публикации используются XML-файлы.
При чтении XML надо учитывать:
— Все объекты представлены в XML-файле один раз.
— Все ссылки на id объектов будут присутствовать в XML-файле (например, при описании линии не будет ссылок на несуществующие точки).
— Если объект частично выходит за границы описываемой области, он всё-равно будет описан полностью. Поэтому в двух XML-файлах, описывающих граничные области, возникают дубликаты объектов, которые переходят из одной области в другую. Например, если дублируется relation, то дублируются и way, и node и relation, которые в него входят.
<node id="231477" lat="52.2600355" lon="0.0172928" version="2" timestamp="2011-02-27T02:33:27Z" changeset="7406582" uid="39894" user="markpeers"/>
Пример следования XML-атрибутов gis-lab:
<node id="36725955" version="7" timestamp="2012-02-05T19:48:59Z" uid="237247" user="masta" changeset="10597500" lat="43.0735049" lon="47.4662786"/>
<way id="243383077" version="1" timestamp="2013-10-25T08:52:05Z" uid="371711" user="knockpenny" changeset="18532019">
<nd ref="2508041246"/>
<nd ref="2508041226"/>
<nd ref="2508041210"/>
<nd ref="2508041208"/>
<nd ref="2508041246"/>
<tag k="building" v="yes"/>
</way>
Пояснения к примерам
В публикации рассматривается два примера получения данных:
1. node-объекты (страны, города с миллионным населением, вулканы);
2. way-объекты (пустыни).
Типы данных выбраны так, чтобы, после обработки полных OSM-данных, был получен понятный и наглядный контент, но, при этом, файлы результатов не были бы слишком большими и их можно было показать на карте.
2. Данные результатов должны быть представлены в форматах CSV и geoJSON;
3. Очень хорошо, если будет обеспечена работа на любом (от минимального до полного) объёме OSM-данных;
4. Очень хорошо, если будет обеспечена очистка данных от дубликатов;
5. Очень хорошо, если будет обеспечена работоспособность на разных ОС;
6. Примеры должны быть полностью функционально-завершёнными и работоспособными.
Обработка OSM-файлов
OSM-XML берётся прямо из заархивированных bzip2 файлов (*.osm.bz2). Для работы с архивом используется библиотека SharpZipLib. При обработке файлов большого размера, проблем не было обнаружено.
//..
// Директории для входных и выходных файлов
//
string dirIn = @".\in\"; // где лежат файлы (*.osm.bz2)
string dirOut = @".\out\"; // куда сохранять результат
//..
// если директории для результатов нет - создать
//
if (!Directory.Exists(dirOut))
Directory.CreateDirectory(dirOut);
//..
// обработать все *.osm.bz2 файлы во входной директории
//
foreach (string fileFullName in Directory.GetFiles(dirIn, "*.osm.bz2"))
{
FileInfo fileInfo = new FileInfo(fileFullName);
using (FileStream fileStream = fileInfo.OpenRead())
{
using (Stream unzipStream = new ICSharpCode.SharpZipLib.BZip2.BZip2InputStream(fileStream))
{
XmlReader xmlReader = XmlReader.Create(unzipStream);
while (xmlReader.Read())
{
if (xmlReader.Name == "node")
OSM_ProcessNode(xmlReader.ReadOuterXml());
else if (xmlReader.Name == "way")
OSM_ProcessWay(xmlReader.ReadOuterXml());
else if (xmlReader.Name == "relation")
OSM_ProcessRelation(xmlReader.ReadOuterXml());
}
}
}
OSM_WriteResultToFiles(); // Записать данные в форматах csv и geojson
}
private static void OSM_ProcessWay(string xmlWay)
{
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.LoadXml(xmlWay);
long wayId = Int64.Parse(xmlDoc.DocumentElement.Attributes["id"].Value);
foreach (XmlNode wayTag in xmlDoc.DocumentElement.ChildNodes)
{
if (wayTag.Name == "tag" && wayTag.Attributes["k"].Value == "natural" && wayTag.Attributes["v"].Value == "desert")
{
//.. логика обработки для найденного типа
}
}
}
Для поиска другого объекта надо просто указать другую Key:Value пару значений или несколько пар, если одновременно надо найти несколько объектов разных типов.
// Country
//
static StringBuilder sbCsvCountry = new StringBuilder();
static StringBuilder sbGeojsonCountry = new StringBuilder();
// City
//
static StringBuilder sbCsvCity = new StringBuilder();
static StringBuilder sbGeojsonCity = new StringBuilder();
static int numPopulationCityFiltr = 1000000; // фильтр для атрибута Population (показывать города >= numPopulationCityFiltr)
// Volcano
//
static StringBuilder sbCsvVolcano = new StringBuilder();
static StringBuilder sbGeojsonVolcano = new StringBuilder();
В примере обработки node-объектов все way- и relation-объекты учитываются для статистики (которую можно посмотреть в журнале).
// структуры хранения
//
class NodeAttrItem // для node-тегов (здесь только node, которые входят в way и имеют собственные теги)
{
public long NodeId = 0;
public double Lat = 0;
public double Lon = 0;
public string Type;
public string Name;
public string NameEn;
public string NameRu;
public string Attrs;
}
class WayAttrItem // для way-тегов
{
public long WayId = 0;
public string Type;
public string Name;
public string NameEn;
public string NameRu;
public string Attrs;
}
class WayToNodeItem // для определения линий
{
public long WayId = 0;
public long NodeId = 0;
public double Lat = 0;
public double Lon = 0;
}
// данные результатов хранятся в виде списков
//
static List<NodeAttrItem> nodeAttrList = new List<NodeAttrItem>();
static List<WayAttrItem> wayAttrList = new List<WayAttrItem>();
static List<WayToNodeItem> wayToNodeList = new List<WayToNodeItem>();
Фактически, когда надо выбрать много объектов (например, береговые линии, дороги), могут возникать ошибки типа «Out of memory». Для устранения таких ошибок достаточно периодически записывать полученные данные в файлы результатов (например, после обработки очередного файла).
CSV и geoJSON
Формат CSV компактен и удобен для записи большого количества данных, которые потом можно легко импортировать, например, в БД.
Формат geoJSON, напротив, избыточен и «многословен» по структуре, но удобен тем, что данные сразу готовы для показа на карте. В примерах, для визуализации, используется возможность GitHub по отображению геоданных (файлы с расширением geojson).
// Глобальный заголовок - достаточно иметь один для всего файла
//
string geojsonHeader = "{\"type\":\"FeatureCollection\",\"features\":[";
string geojsonFooter = Environment.NewLine + "{}]}";
// Заголовок для каждого нового объекта (way или node)
//
string geojsonFeatureBegin = Environment.NewLine + "{" + Environment.NewLine + "\"type\":\"Feature\"," + Environment.NewLine + "\"geometry\":";
string geojsonFeatureEnd = Environment.NewLine + "},";
// Описание node
//
string geojsonPointBegin = "{\"type\":\"Point\",\"coordinates\":";
string geojsonPointEnd = "},";
// Описание way (в данном случае Polygon)
//
string geojsonPolygonBegin = "{\"type\":\"Polygon\",\"coordinates\":[[";
string geojsonPolygonEnd = "]]}";
// Описание тегов
//
string geojsonPropBegin = Environment.NewLine + "\"properties\":{";
string geojsonPropEnd = "}";
Переносы строк, при подготовке geojson, используются для удобства просмотра. Иногда в OSM-XML встречаются комбинации символов, которые могут сделать geoJSON невалидным. Это происходит, когда XML-данные корректны, а, после парсинга, JSON воспринимает их как ошибку (причины ошибок приходится искать в довольно больших файлах). Например, надо исправлять двойные кавычки ["], если они встречаются в тегах. В примере двойные кавычки исправляются на одинарные [']. Или широта/долгота могут указываться как, например, «32.» (исправляется на «32.0»).
Для того, чтобы линии не терялись на карте, они помечаются точками, которые хорошо видны (в примере каждая линия помечается точечным объектом, теги которого взяты у линии — функция OSM_WriteResultToFilesGeojson).
Пояснения по работе с XML
xmlDoc.DocumentElement.Attributes["lat"].Value;
xmlDoc.DocumentElement.Attributes["lon"].Value;
// первое чтение - для определения искомого объекта
//
foreach (XmlNode nodeTag in xmlDoc.DocumentElement.ChildNodes)
{
if (nodeTag.Name == "tag")
{
if (nodeTag.Attributes["k"].Value == "place" && nodeTag.Attributes["v"].Value == "country")
{
string strAttrs = "";
bool isAttr = false;
// повторное чтение - для сохранения всех тегов
//
foreach (XmlNode nodeTag in xmlDoc.DocumentElement.ChildNodes)
{
if (nodeTag.Name == "tag")
{
if (isAttr)
strAttrs += ",";
else
isAttr = true;
strAttrs += String.Format("\"{0}\":\"{1}\"", nodeTag.Attributes["k"].Value, nodeTag.Attributes["v"].Value.Replace('\"', '\''));
}
}
}
}
}
Полный состав тегов нужен, например, если надо проанализировать состав всех тегов по новому объекту. У некоторых объектов (большие города, страны) тегов может быть очень много. Полный состав тегов сохраняется только в CSV-файле.
Быстродействие и дубликаты
Факторы, которые оказывают влияние на быстродействие:
Необходимость двойного чтения вызвана тем, что в XML-файле сперва идут node-, и только за ними way-объекты. В данном случае двойное чтение просто упрощает алгоритм, позволяя избежать применения промежуточных структур для хранения широты и долготы точек.
В примере с пустынями (для Африки) разница во времени обработки — без индексного массива (useIndexedCheck = false) ? 3.5 часа, с индексным массивом (useIndexedCheck = true) ? 1 час. Но, если, например, надо выбрать все дороги или береговые линии на полных данных OSM, то без индексации время обработки может растянуться на дни и даже недели (чем больше количество выбранных объектов — тем больше расход времени), а с индексацией — всё время займёт немногим более суток.
Как это работает?
Если, при каждом новом парсинге node или way, знать — был ли объект с таким id уже обработан раньше?, то становится просто выявлять дубликаты.
Если быстро (без поиска) определить, что считанная точка входит в линию, то это даёт значительный выигрыш по скорости. Так как общее количество точек может быть весьма значительным (более трёх миллиардов на полных данных), то и затраты времени на поисковые операции для каждой точки (по внутренним массивам nodeAttrList, wayAttrList, wayToNodeList), с накоплением данных, превращаются в значительные. То есть — применение индексного массива помогает избавиться от «холостых» поисковых операций.
Как это организовано в коде?
Для node- и way-объектов создаются массивы размерностью не менее максимального значения id для данного объекта (для определения максимального значения id используются значения статистики). В массивах для каждого node- или way-объекта выделяется ячейка размером byte, где индекс ячейки соответствует id объекта.
bool useIndexedCheck = true; // использовать/не использовать индексный массив
// если не использовать (false), то при обработке более одного *.bz2 файла, на границах соседних областей могут появляться дубликаты объектов
// если использовать (true), то потребуется дополнительно > 4 GB RAM
//--
long wayIdxSize = 512 * 1024 * 1024 - 1;
byte[] wayIdx;
long nodeIdxSize = (2L * 1024 * 1024 * 1024 - 57 - 1);
byte[] nodeIdx1;
byte[] nodeIdx2;
//-- если использовать индексный массив, то потребуется дополнительно > 4 GB RAM
//
if (useIndexedCheck)
{
wayIdx = new byte[wayIdxSize + 1];
nodeIdx1 = new byte[nodeIdxSize + 1];
nodeIdx2 = new byte[nodeIdxSize + 1];
}
При проверке нового node или way (при парсинге XML) происходит увеличение значения в индексированной ячейке на единицу.
// проверка на дубликаты
//
if (useIndexedCheck)
{
if(OSM_WayIdxAdd(wayId) > 1)
return;
}
//..
// функция установки признака дупликата в индексном массиве
//
private static byte OSM_NodeIdxAdd(long nodeId)
{
if (nodeId <= nodeIdxSize)
return ++nodeIdx1[nodeId];
return ++nodeIdx2[nodeId - nodeIdxSize];
}
Если значение в индексированной ячейке массива больше нуля, то объект с таким id уже был считан, а само значение будет указывать на количество повторений.
// функция подсчёта дубликатов
//
private static long OSM_NodeIdxDuplCount()
{
long numDupl = 0;
for (long n = 0; n <= nodeIdxSize; n++)
{
if (nodeIdx1[n] > 2) numDupl++;
if (nodeIdx2[n] > 2) numDupl++;
}
return numDupl;
}
Работоспособность на разных ОС
Здесь главная заслуга разработчиков Mono (за что им уважение и благодарность).
Оба примера разработаны на Visual Studio Community 2015 под Windows 7. Далее, полученный EXE-файл и библиотека ICSharpCode.SharpZipLib.dll (как есть) были перенесены в Linux (проверялось на OpenSuse, Mint, Ubuntu под Oracle Virtual Box) и выполнялись под Mono (последняя версия Mono). Всё заработало сразу, без проблем и дополнительных настроек.
//..
string dirIn = @".\in\"; // где лежат файлы (*.bz2)
string dirOut = @".\out\"; // куда сохранять результат (если директории нет - создаётся автоматически)
//..
OperatingSystem os = Environment.OSVersion;
PlatformID pid = os.Platform;
if (pid == PlatformID.Unix || pid == PlatformID.MacOSX) // 0 - Win32S, 1 - Win32Windows, 2 - Win32NT, 3 - WinCE, 4 - Unix, 5 - Xbox, 6 - MacOSX
{
dirIn = dirIn.Replace(@"\", @"/");
dirOut = dirOut.Replace(@"\", @"/");
}
Для перехода на новую строку надо использовать Environment.NewLine.
string geojsonFeatureBegin = Environment.NewLine + "{" + Environment.NewLine + "\"type\":\"Feature\"," + Environment.NewLine + "\"geometry\":";
string geojsonFeatureEnd = Environment.NewLine + "},";
Примеры на GitHub
Примеры кода (шаблоны консольных программ):
Получение node-объектов
Получение way-объектов
Примеры полученных геоданных (geoJSON):
Все государства на Земле.
Все города на Земле с населением более миллиона человек.
Все вулканы на Земле.
Все пустыни на Земле.
Ссылки
Объекты карты (перечень рекомендованных к использованию общепринятых тегов)
Элементы карты
Снимок базы данных Planet.osm
Схема базы данных
Модели проекций
Спецификация GeoJSON
Автоматическое отображение на GitHub данных в формате geoJSON
Данные на geofabrik
Данные на gis-lab
Программы и фреймворки для работы с OSM
Библиотека для работы с архивами (SharpZipLib)
Скачать Mono
Комментарии (12)

olen
17.11.2015 19:58> Все государства на Земле.
По вашей ссылке совершенно случайно нашел баг:
«properties»:{«Type»:«country»,«Name»:«Biblioteca Civica di Cividale del Friuli»,«Name(en)»:«No data»,«Name(ru)»:«No data»,«Population»:0}

freeExec
17.11.2015 21:07Угу, ведь это обычная библиотека
node 1706381831: 46.0910836, 13.4324346
addr:country = IT
amenity = library
name = Biblioteca Civica di Cividale del Friuli
opening_hours = Mo-Fr 14:30-19:00; Tu,Th 10:30-12:30; PH off
phone = +39 0432 710310
ref:isil = IT-UD0016
Сколько там ещё дубликатов с addr:country одному ОСМ известно.
Zverik
17.11.2015 22:49А что плохого в addr:country? Это ж просто часть адреса.
Тег ref:isil (islamic state of iraq and levant?) более подозрителен.freeExec
18.11.2015 01:48В теге нечего. Плохо что-то у автора в разборе тегов, раз у него эта библиотека идёт наравне с государствами Мира.

apelserg
18.11.2015 12:48Плохо что-то у автора в разборе тегов
Это полный список KV тегов по точке id=1706381831 (lat=46.0910836, lon=13.4324346):
«addr:country»:«IT»
«amenity»:«library»
«name»:«Biblioteca Civica di Cividale del Friuli»
«opening_hours»:«Mo-Fr 14:30-19:00; Tu,Th 10:30-12:30; PH off»
«phone»:"+39 0432 710310"
«place»:«country»
«ref:isil»:«IT-UD0016»
Ошибку вызвала KV пара: Tag:place=country, так как она является критерием отбора. По-моему это полезный и наглядный пример «небольших» недоразумений, которые могут возникать при использовании OSM.
В том, что это действительно библиотека — легко убедитсяZverik
18.11.2015 15:29Страны лучше брать из отношений boundary=administrative + admin_level=2. Точки place=country могли добавить не для каждой страны.
apelserg
18.11.2015 12:40Тег ref:isil (islamic state of iraq and levant?) более подозрителен.
Ничего подозрительного — стандартный тег: Key:ref:isil

kivsiak
17.11.2015 20:39+1Пара не больших комментариев.
Не смотря на то что xml очень наглядно дает понятие о структуре osm, и вполне уместен в статье, использовать его в реальной жизни не стоит. Pbf — на много эффективнее как по размерам так и по скорости доступа.
Работать с аналитикой лучше используя postgis — расширение postgresql для поддержки геопространственных данных на базе GDAL. wiki.openstreetmap.org/wiki/Osm2pgsql — позволит перегнать выгрузку в базу (весьма на быстрый, но одноразовый процесс) И там вам будет доступна вся мощь posgresql без проблем с весьма тяжелым (617GB — это мир на текущий момент) xml.
Zverik
17.11.2015 22:51PostGIS удобен, когда нужно сложные запросы прогонять. Для фильтрации по тегам или регионам достаточно консольных утилит из набора osmctools. Кроме того, данные в PostGIS требуют очень много места, а заливка — много времени. Поэтому если с данными нужно не постоянно работать, проще изучить overpass и osmctools.
Zverik
(shameless plug)
На этих выходных будет конференция «Открытые ГИС 2015», где треть докладов — про OSM. Я там час проведу в консультационной, где, если будут интересующиеся, покажу, как всё это получать без программирования. Ключевые слова — osmfilter и/или overpass.
В целом, спасибо за ликбез, хотя если есть моно, то есть и питон, а на нём скрипты чуть лучше читаются.
ikashnitsky
А еще есть R, который неплохо приспособлен для анализа данных и даже для простого картографирования