
За звание лучшего переводчика сегодня поборются
Google Translate - в представлении не нуждается. Я воспользуюсь официальным API, которое стоит $20 за миллион символов.
DeepL - конкурент Google Translate. У него тоже есть API, цена использования которого примерно такая же.
GPT-3.5. Я буду использовать OpenAI Chat API. Подробнее о работе с ним вы можете почитать в моих предыдущих статьях.
GPT-4. У меня есть доступ к GPT-4 API (сейчас его предоставляют по вейтлисту). Вызов GPT-4 не отличается от вызова GPT-3.5; модель умнее, но гораздо дороже.
MarianMT - семейство моделей для различных языковых пар, которые зафантюнили специалисты из Helsinki-NLP. Модели можно скачать с Hugging Face и бесплатно запускать на своих ресурсах (однако, придется немного заморочиться с запуском). В зависимости от языковой пары, доступна либо большая модель (~ 500 MB), либо стандартная (~ 300 MB). Есть модели, которые работают с несколькими языками сразу. Я буду использовать большие модели, где это возможно.
Код для перевода через GPT-3.5/GPT-4 API
import openai
import os
def translate(sentence, source_lang, target_lang, model = "gpt_3.5-turbo"):#source_lang, target_lang are names of the languages, like "French"
openai.api_key = os.environ.get("OPENAI_API_KEY") #or supply your API key in a different way
completion = openai.ChatCompletion.create(
model=model,
messages=[
{
"role": "system",
"content": f"Please translate the user message from {source_lang} to {target_lang}. Make the translation sound as natural as possible."
},
{
"role": "user",
"content": sentence
}
],
temperature=0
)
return completion["choices"][0]["message"]["content"]Поэкспериментировать с промтом и параметрами API можно в плейграунде (не забудьте выставить температуру в 0).
Я выбрал 12 популярных языков: испанский, китайский (мандарин), русский, французский, немецкий, японский, португальский, корейский, голландский, хинди, индонезийский и арабский. Для каждого из них я буду тестировать перевод на английский и с английского каждым из кандидатов.
Есть пара исключений:
DeepL поддерживает только 29 языков, среди которых нет хинди и арабского
-
MarianMT модель для перевода с английского на корейский сломана, она генерирует бред даже в демо на Hugging Face
В качестве метрики качества перевода я буду использовать золотой стандарт - метрику BLEU-4.
Сбор данных
Я собрал собственный набор данных на основе датасета Tatoeba: для каждой языковой пары я взял по 50 или 100 самых длинных параллельных предложений, которые были добавлены позже сентября 2021.
Брать необходимо только новые предложения, чтобы бороться с data contamination - известно, что обучающая выборка для GPT-3.5/GPT-4 заканчивается сентябрем 2021.
MarianMT модели обучались на датасете OPUS, сами разработчики тестируют их на Tatoeba, так что здесь никаких проблем нет.
Я специально взял самые длинные предложения, чтобы усложнить задачу. На коротких предложениях очень часто возникает ситуация, когда все переводы годные, и побеждает тот, который случайно оказался ближе всего к переводу человека.
Сравнение качества перевода
Я оптимизировал промт для GPT-3.5/GPT-4 способом, который я описал в предыдущей статье.
Получилось, что лучше всего в системное сообщение написать
Please translate the user message from {src} to {tgt}. Make the translation sound as natural as possible.
Второе предложение очень важно - без него сильно ухудшается BLEU.
Я также пробовал использовать few-shot примеры. Оказалось, что на этой задаче добавление примеров чаще всего ухудшает метрики. Да, можно перебирать наборы примеров и найти те, которые улучшают, и выбрать среди них оптимальный. Однако, это больше похоже на переобучение модели на стиль Tatoeba-предложений. Поэтому я решил не использовать примеры, промт состоит только из системного сообщения и сообщения для перевода. Такое решение, вдобавок, потребляет гораздо меньше токенов и поэтому дешевле.
В итоге у меня получились следующие результаты: https://github.com/einhornus/prompt_gpt/tree/main/data/translation/reports. Каждый файл в этой папке содержит .json-отчет по конкретной языковой паре для одной из моделей. В каждом отчете предложения отсортированы по убыванию BLEU - легко анализировать самые худшие переводы.
Я визуализировал распределение BLEU для каждой языковой пары в виде ящиков с усами. Жирная линия посередине ящика означает медиану, границы ящика показывают 25-й и 75-й перцентили. Треугольный вырез в центре называется "notch" и показывает доверительный интервал для медианы.
Ссылки под графиками ведут на соответствующие .json-отчеты.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
Перевод с испанского на английский - не очень сложная задача, и все модели справляются очень хорошо. Похожая ситуация наблюдается и с другими романскими языками.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
В самых худших переводах у MarianMT происходит полная потеря смысла, чего не скажешь про остальные модели.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
На русском GPT-3.5 и GPT-4 демонстрируют наихудшие результаты по BLEU относительно других моделей. Вероятно, это объясняется проблемами с токенизацией кириллицы.
На этот раз даже в самых худших переводах MarianMT корректно передает смысл.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
MarianMT иногда генерирует нереально кривые предложения на русском:
Вот скриншот их страницы магазина за неделю назад, и вот как это выглядит сегодня. У них точно такие же цены, но текущий утверждает, что они все на 50%. Странно, не так ли? (Here's a screenshot of their store page from a week ago, and here's what it looks like today. They have the exact same prices listed, but the current one claims they're all 50% off. Strange, isn't it?)
О, парень! Это конечно прекрасное утро здесь! На самом деле, я не могу дождаться, чтобыхух? Что случилось? "Как дела, Линк?" "Моршу, что происходит?" "Ха, просто. Со всеми деньгами, которые я сделал на моем успешном бизнесе и моей успешной карьере битбокса, я разбогател!" "Вау, так что вы устроили нам вечеринку?" "Ха, нет. Безопасность, возьми этих ублюдков." (Oh boy! It sure is a beautiful morning around here! In fact, I can't wait to–huh? What happened? "What's up, Link?" "Morshu, what is going on?" "Hah, simple. With all the money I made from my successful businesses and my successful beatboxing career, I got rich!" "Wow, so you threw us a party?" "Hah, nope. Security, get those motherfuckers out.")
Мне очень нравится эта доска, но одна из самых разочаровывающих вещей здесь - это количество плакатов, у которых есть серьезное непонимание любой формы юмора и которые, следовательно, относятся к вещам слишком серьезно. Это настоящее раздражение, но с ним нужно жить. (I like this board a lot, but one of the most frustrating things about it is the amount of posters here who have a serious lack of understanding of any form of humour and who consequently take things too seriously. It is a real annoyance but one has to live with it.)
Вот те же самые предложения от GPT-3.5 (смысл передан верно, грамматических ошибок формально нет, но первые два предложения выглядят неестественно)
Вот скриншот их страницы магазина на прошлой неделе, а вот как она выглядит сегодня. Они указали точно такие же цены, но на текущей странице написано, что все товары со скидкой 50%. Странно, не так ли?
Ого, какое прекрасное утро здесь! На самом деле, я не могу дождаться - что случилось? "Что случилось, Линк?" "Моршу, что происходит?" "Хах, просто. Со всеми деньгами, которые я заработал благодаря своим успешным бизнесам и успешной карьере битбоксера, я разбогател!" "Вау, так ты устроил нам вечеринку?" "Хах, нет. Охрана, выкиньте этих ублюдков."
Мне очень нравится этот форум, но одна из самых раздражающих вещей здесь - это количество пользователей, которые не понимают юмора и слишком серьезно относятся к вещам. Это действительно раздражает, но приходится с этим жить.
В целом, от переводов GPT-3.5 иногда попахивает машинностью, но прямо совсем треша я в них не вижу; когда как результаты MarianMT местами совсем неприемлемы для использования в проде. Это немного странно, учитывая что медианный BLEU у них близок.
Вот те же предложения в переводе Google Translate:
Вот скриншот их страницы в магазине, сделанный неделю назад, и вот как она выглядит сегодня. У них указаны одинаковые цены, но текущая утверждает, что все они со скидкой 50%. Странно, не так ли?
О, парень! Здесь, конечно, прекрасное утро! На самом деле, я не могу дождаться… а? Что случилось? — Что случилось, Линк? — Моршу, что происходит? «Ха, просто. Со всеми деньгами, которые я заработал на своем успешном бизнесе и успешной карьере битбоксера, я разбогател!» — Вау, так ты устроил нам вечеринку? «Ха, нет. Охрана, вытащите этих ублюдков».
Мне очень нравится эта доска, но одна из самых неприятных вещей на ней — это количество постеров, которые серьезно не понимают ни одной формы юмора и, следовательно, слишком серьезно относятся к вещам. Это действительно неприятно, но с этим нужно жить.
К первому переводу никаких вопросов, но во втором и третьем есть явные ошибки (Oh boy! → О, парень!, вытащите ублюдков, board (форум) → доска). Если проигнорировать ошибки, то в целом текст написан более естественно, чем у GPT-3.5. Кажется, в этом и заключается причина разницы в BLEU - большое количество мелких ошибок у GPT-3.5 сильнее снижает BLEU, чем небольшое количество грубых у Google Translate.
Я сортировал все предложения по возрастанию разницы BLEU между переводом GPT-3.5 и Google Translate. Вот 3 примера из начала этого списка:
Образцовый перевод |
GPT-3.5 |
Google Translate |
BLEU1 BLEU2 |
Дин Лижэнь — новый чемпион мира по шахматам. На тай-брейке первые три партии закончились вничью, а четвертую, когда Дин вел черными в испанском дебюте, сенсационно выиграл китайский дракон, который таким образом победил русского медведя Яна Непомнящего. У вершины шахматной вселенной новое лицо. |
Дин Лирен - новый чемпион мира по шахматам. В тай-брейке первые три игры закончились вничью, а четвертая, в которой Дин играл черными фигурами в испанском открытии, была сенсационно выиграна китайским драконом, который таким образом победил русского медведя Яна Непомнящего. В вершине шахматной вселенной появилось новое лицо. |
Дин Лижэнь — новый чемпион мира по шахматам. На тай-брейке первые три партии закончились вничью, а четвертую, когда Дин вел черными в испанском дебюте, сенсационно выиграл китайский дракон, который таким образом победил русского медведя Яна Непомнящего. У вершины шахматной вселенной новое лицо. |
0.326 1.000 |
И сказал им Ангел: не бойтесь; я возвещаю вам великую радость, которая будет всем людям: ибо ныне родился вам в городе Давидовом Спаситель, Который есть Христос Господь; и вот вам знак: вы найдете Младенца в пеленах, лежащего в яслях. И внезапно явилось с Ангелом многочисленное воинство небесное, славящее Бога и взывающее: слава в вышних Богу, и на земле мир, в человеках благоволение! |
И сказал им Ангел: "Не бойтесь, ибо возвещаю вам великую радость, которая будет для всего народа: ныне родился вам Спаситель, Который есть Христос Господь, в городе Давидовом. И вот вам знак: вы найдете Младенца, пеленанный и лежащий в яслих". И вдруг явилось с Ангелом множество воинственной армии небесной, славящей Бога и говорящей: "Слава Богу на высоте, и на земле мир, воля к людям благоволение". |
И сказал им ангел: не бойтесь, ибо вот, я возвещаю вам великую радость, которая будет для всех людей. Ибо родился вам ныне в городе Давидовом Спаситель, Который есть Христос Господь. И это будет вам знамением; Младенца найдёте в пеленах, лежащего в яслях. И внезапно явилось с Ангелом многочисленное воинство небесное, славящее Бога и взывающее: слава в вышних Богу, и на земле мир, в человеках благоволение. |
0.346 0.716 |
По мнению Тома, теория эволюции путем случайных мутаций и естественного отбора неубедительна по нескольким причинам, самой важной из которых является существование ДНК. Среди прочих неприемлемых пунктов, добавляет Том, эта теория утверждает, что человеческий разум – Сократа, Платона, Аристотеля, Галилея, Ньютона, Шекспира, Декарта, да Винчи, Моцарта, Эйнштейна, самого Дарвина – развился из разума неизвестного примата, который якобы был нашим предком. |
По словам Тома, теория эволюции случайных мутаций и естественного отбора неубедительна по нескольким причинам, наиболее важной из которых является существование ДНК. Среди других неприемлемых моментов, Том добавляет, что эта теория утверждает, что человеческий разум - Сократ, Платон, Аристотель, Галилео, Ньютон, Шекспир, Декарт, да Винчи, Моцарт, Эйнштейн, сам Дарвин - развился из разума неопределенной приматы, которая была бы нашим предком. |
По словам Тома, теория эволюции путем случайных мутаций и естественного отбора неубедительна по нескольким причинам, важнейшей из которых является существование ДНК. Среди прочих неприемлемых моментов, добавляет Том, эта теория утверждает, что человеческий разум — Сократа, Платона, Аристотеля, Галилея, Ньютона, Шекспира, Декарта, да Винчи, Моцарта, Эйнштейна, самого Дарвина — развился из разума неопознанного примата, который будет нашим предком. |
0.386 0.756 |
Вывод GPT-3.5 выглядит немного хуже, но он все равно правильно передает смысл и почти не содержит грамматических ошибок; хотя если судить по BLEU, результаты Google Translate должны быть на голову выше.
В первом случае вывод Google Translate полностью совпал с ожидаемым, что похоже на data contamination.
Во втором примере у Google Translate на второй половине предложения открылось "второе дыхание", и он начал переводить слово-в-слово. Однако, обвинять модель в data contamination на библейском примере довольно глупо :)
Еще одним доказатеством data contamination у Google Translate служит перевод фразы "This is a proxy conflict between the former president and the former vice president, William A. Galston, a senior fellow in Brookings' Governance Studies program, told VOA as ballots were being cast on Tuesday." как 'Это опосредованный конфликт между бывшим президентом и бывшим вице-президентом, - сказал "Голосу Америки" Уильям А. Галстон, старший научный сотрудник программы исследований управления Брукингса, во время голосования во вторник.' (от перевода человека отличается только типом кавычек). В данном случае человек допустил ошибку, не упомянув про VOA. GPT-3.5 при переводе данной фразы VOA не забывает.
Теперь посмотрим на результаты DeepL.
Вот скриншот страницы их магазина недельной давности, а вот как она выглядит сегодня. На них указаны точно такие же цены, но на текущей странице утверждается, что на все товары действует скидка 50%. Странно, не правда ли?
О, Боже! Какое прекрасное утро! На самом деле, я не могу дождаться... а? Что случилось? "Что случилось, Линк?" "Моршу, что происходит?" "Хах, все просто. Со всеми деньгами, которые я заработал на своем успешном бизнесе и успешной карьере битбоксера, я разбогател!" "Вау, так ты устроил нам вечеринку?" "Ха, неа. Охрана, выведите этих ублюдков".
Мне очень нравится этот форум, но одна из самых неприятных вещей в нем - это количество постеры, которые имеют серьезное непонимание любой формы юмора и, следовательно, воспринимают все слишком серьезно. Это действительно раздражает, но с этим приходится жить.
Есть очень грубая ошибка: "количество постеры, которые имеют серьезное непонимание любой формы юмора".
Я давно использую DeepL, и в целом у меня сложилось впечатление, что его переводы на русский более естественны, чем у Google Translate.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
Вот тут Google Translate совсем сломался. Предложение 「漢字って、どうやったら簡単に覚えられますか?」「簡単には覚えられないよ。人それぞれだとは思うけど、覚えたいなら面倒でも書くのが一番だと思うよ」он переводит как "How can you easily memorize kanji?" вместо "What's the easiest way to learn kanji? "I don't think there is an easy way. It probably varies from person to person, but I think if you really want to learn, the best option is to just write them, even if it's a hassle.". В файле можно найти еще много подобных кейсов.
Для MarianMT перевод с японского оказался непосильной задачей: уже на медианных предложениях результаты не только выглядят криво, но еще и искажают смысл.
GPT-3.5 и GPT-4 показывают себя очень хорошо на этой языковой паре.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
MarianMT не способна работать на этой языковой паре: даже самый лучший перевод с BLEU=0.1 представляет собой треш.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
На корейском предложения были относительно короткими (что сильно упрощает задачу), но GPT-3.5 и даже MarianMT нормально передают их смысл.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
Возможно, такие плохие метрики связаны с какими-то особенностями корейского языка. Переводы с нулевым BLEU у всех моделей обычно не искажают смысл.
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
DeepL
Google Translate
GPT-3.5
GPT-4
MarianMT
Анализ стоимости API
Google Cloud Platform Translation API стоит $20 за 1 миллион символов.
DeepL API стоит $4.5 в месяц фиксированно + $18 за 1 миллион символов. Однако, есть большая проблема с доступностью этого API: нужно иметь карту, выпущенную в США, ЕС, Великобритании, Японии, Канаде, Швейцарии, Сингапуре, Лихтенштейне или Мексике. Тесты для статьи были проведены на бесплатном триале с помощью ключа, который предоставила знакомая автора из Японии (огромное спасибо ей за помощь). Собственно, данное гео-ограничение и послужило толчком для написания статьи: вдруг с помощью GPT-4 API (которое без проблем оплачивается с армянской карты) можно добиться по крайней мере такого же качества перевода, как и у DeepL?
Стоимость OpenAI API рассчитывается более сложно: тут вы платите не за символы, а за "токены". Токен - это слово или часть слова, соотношение числа символов на один токен зависит от языка.
Видно, что у языков с латиницей это соотношение выше → использование API дешевле (плюс, сама модель работает лучше из-за более удачной токенизации). Есть два исключения: китайский и японский. Да, соотношение символы/токены для них очень низкое, но зато сами тексты занимают гораздо меньше символов.
В отличие от других API, в OpenAI API вы платите как за токены промта, так и за токены ответа. Для GPT-3.5 цена этих токенов одинакова и равна $0.002 за тысячу токенов. У GPT-4 токены промта стоят $0.03 за тысячу, а токены ответа - $0.06 за тысячу.
Я визуализировал примерную стоимость перевода сообщения в 500 символов для разных языковых пар с учетом всего вышесказанного.
В большинстве случаев GPT-3.5 API стоит в 5-15 раз меньше Google Cloud Platform Translation API, тогда как GPT-4 API обойдется в 1.2-4 раза дороже. Реальное соотношение цен зависит от языковой пары.
Скорость
Google Translate и DeepL сильно выигрывают у OpenAI по скорости. Кроме того, их API сейчас гораздо стабильнее: сервера OpenAI находятся под большой нагрузкой, запросы иногда возвращают ошибки, и их приходится отправлять заново (надеюсь, они это пофиксят). Проблемы со скоростью частично нивелирует тот факт, что ответ модели можно стримить постепенно, токен за токеном.
Скорость работы MarianMT зависит от ваших ресурсов, но в целом модель не очень быстрая. Кроме того, вам нужно будет хранить на диске и загружать в память каждую модель отдельно.
Кастомизируемость
Большое достоинство перевода с помощью GPT-3.5/GPT-4 в том, что вы можете дальше его кастомизировать на свой вкус:
Можно поменять промт и делать переводы в каком-то определенном стиле
Можно генерировать множество разных переводов с помощью разных промтов и/или установив температуру >0; затем можно выбирать наилучший перевод по какому-то критерию (например, по семантическому сходству с оригиналом, которое вычисляется другой нейронкой)
Выводы
Метрики подтверждают интуитивное ощущение, что DeepL переводит лучше, чем Google Translate.
Относительное положение GPT-3.5/GPT-4 по метрике BLEU сильно зависит от языковой пары: эти модели могут как побеждать даже DeepL, так и сильно проигрывать Google Translate. Нужно изучать графики по конкретным языковым парам. Видимо, эта особенность связана с особенностями токенизации для разных языков.
-
GPT-3.5 переводит немного "машинно", но в целом результаты приемлемы в проде почти всегда. Даже в самых худших сценариях GPT-3.5 сохраняет смысл и генерирует результаты с минимумом грамматических ошибок (чего не скажешь про Google Translate и тем более про MarianMT). Вкупе с низкой стоимостью, это делает GPT-3.5 подходящим для использования во множестве реальных кейсов.
У меня есть гипотеза, что провалы GPT-3.5 по BLEU на некоторых языках объясняются токенизацией: из-за этого модель делает много мелких стилистических ошибок (в результате текст звучит немного неестественно), а метрика BLEU устроена таким образом, что она очень сильно наказывает подобное поведение; тогда как Google Translate и DeepL делают меньше ошибок, но эти ошибки более грубые.
Также видно, что у части результатов Google Translate завышен BLEU из-за data contamination.
С учетом того, что большинство бенчмарков для перевода делаются на BLEU, практически неизбежен подбор гиперпараметров в специализированных нейронках именно для оптимизации этой метрики; тогда как в GPT-3.5 решении на оптимизицию BLEU подобран только промт.
GPT-4 показывает себя гораздо лучше GPT-3.5, по BLEU она в целом наравне с Google Translate (но в реальности она лучше Google Translate по причинам из предыдущего пункта), и иногда даже бьет DeepL. Однако, ее цена выше, чем у Google Translate.
MarianMT своими результатами не впечатляет, но было бы наивно полагать, что маленькая и бесплатная модель сможет на равных конкурировать с проприетарными гигантами. Однако, результаты MarianMT приемлемы на простых языковых парах. Не стоит использовать MarianMT на сложных языках (таких как китайский, японский, корейский, арабский, хинди; частично это относится и к русскому) - модель может сильно искажать смысл, порождать тексты с кучей грамматических ошибок, а иногда и вовсе генерировать бред.
Комментарии (47)

rPman
27.05.2023 17:40+1Интересно, как большие языковые модели типа bloomz или opt на поприще перевода? как минимум bloomz можно до файнтюнить, мультиязычные и multitask начинается с 7b и 13b (ну а запускать 175B было бы слишком дорого), мало того, можно дофайнтюнить именно на перевод.
p.s. про llama тем более молчу, оно в multitask очевидно лучше себя ведет, а 65b даже с квантизацией 4b работает не на много хуже gpt35

einhorn Автор
27.05.2023 17:40+1Производные от LLAMA пока слабоваты: в репе предыдущего комментатора есть тесты alpaca7B-4bit и alpaca30B-4bit. На eng->rus у первой 14.19 BLEU, у второй - 24.0 BLEU - очень скромно. Основная проблема - у LLAMA обучающий сет большей частью был на английском, в другие языки она не очень может.
OpenAssistant на куче языков учат - вот его потестить на перевод было бы интересно.
rPman
27.05.2023 17:40+27b llama нельзя использовать без finetuning под узкую задачу, почему берут самую слабую версию достаточно мощной модели, делают на ее основе мультизадачные тесты и получив закономерно плохой результат делают поспешные выводы?
Мне нравится использование мультизадачной языковой модели, в т.ч. для перевода, ей можно давать инструкции, корректирующие решение. Например варианты перевода (в примере ниже этого нет), стилистику, разрешить или запретить фантазировать и т.п.
p.s. я в качестве эксперимента настроил скрипты перевода фентезийного романа с английского на русский с помощью llama 65B, не скажу что результаты хорошие, там явно есть проблемы, но вполне пользоваться можно.Достаточно плохой пример:Forest. It was strangely calming to be in the presence of the woods, and Lumoof soon found himself taking a leisurely stroll through the woods. None of the animals approached us, though we could feel their eyes on Lumoof. Instead, they scurried away and ran as soon as we even approached.
llama65b:Лес. Странно успокаивающе находиться в присутствии леса, и Лумуф скоро нашел себя в неспешной прогулке по лесу. Ни один из животных не подходил к нам, хотя мы могли чувствовать их глаза на Лумуфе. Вместо этого они скатывались и бежали, как только мы даже приблизились.
open assistent rlhv llama30b-2 7k:Лес. Странно успокаивающе было быть в присутствии леса, и Люмоф быстро нашел себя делающим прогулку по лесу. Ни одно животное не подходило к нам, хотя мы чувствовали их взгляды на Люмофе. Им с трудом удавалось остаться на месте; они всегда отрывались от того места, где мы находились.
googleЛес. Находиться в лесу было странно успокаивающе, и вскоре Люмуф обнаружил, что неторопливо прогуливается по лесу. Ни одно из животных не приблизилось к нам, хотя мы чувствовали их взгляды на Люмуфе. Вместо этого, они разбежались и убежали, как только мы подошли.
deeplЛес. Находиться в окружении леса было странно успокаивающе, и вскоре Лумуф обнаружил, что не спеша прогуливается по лесу. Никто из животных не приближался к нам, хотя мы чувствовали их взгляды на Лумуфе. Вместо этого они разбегались и убегали, как только мы приближались.
einhorn Автор
27.05.2023 17:40+2Не знаю, я бы 7B не тестил.
Но 30B выдает 24 BLEU, что все равно очень плохо.

janvarev
27.05.2023 17:40+2Я автор репы выше.
На самом деле там довольно навороченные примеры перевода подаются на вход, поэтому у 30B такой невысокий результат. На простых фразах многие движки дают относительно нормальный перевод - и у Лламы это вообще круто, что она как-то дает перевод. Просто в сравнении с более сложными движками - а сейчас, видимо, самая продвинутая локальная это FB NLLB - она проигрывает. А FB NLLB на 1.3B можно запустить на 8Gb VRAM, а с квантизацией - и на 2 GB, и результат будет приближаться к Google Translate, вот что круто.
Мне самому было интересно, что выдают LLM, поэтому и гонял. На 7B - что выдает при приличной скорости? На 30B - что возможно при относительном максимуме? (на 65B не гонял, да) 30B и так давало 40 секунд на перевод, так что я ограничился небольшим тестом.
Но вообще - если будет время - можете скачать мою репу (там есть one click installer под Windows), и прогнать тест на модельку 65B. У меня есть коннектор к KoboldAPI/OpenAI API, так что если запускаете через text-generation-web или koboldcpp, то должно сконнектиться. Тесты на BLEU там запускаются одним файликом, ничего специально делать не надо, только настроить, на каком плагине его оценивать.
einhorn Автор
27.05.2023 17:40Жаль, что я про FB NLLB не знал. Лучше было nllb-200-3.3B взять в качестве бесплатной модели. Она тяжеловата, правда (зато обслуживает все языковые пары, не нужно отдельно модели качать).
janvarev
27.05.2023 17:40Кстати, я делал мерялку - 3.3B практически не выигрывает у 1.3B (почему - не очень понятно). Так что можно взять 1.3B-distilled - она даже на видеокарту может нормально влезть, и дает около 1-2 перевода в секунду в этом случае.
einhorn Автор
27.05.2023 17:40+1
Я бы сказал, что 2-3% BLEU в подобных тестах - это уже заметный выигрыш.
janvarev
27.05.2023 17:40Хм... да, может быть. Я-то рассматриваю больше с точки зрения практики - т.е. совокупности скорости перевода + качества; имхо, тут выигрыш маловат, к тому же, как вы правильно говорите, не всегда BLEU корректирует с качеством (как в примере с ChatGPT историей). Но так да, если нужно максимальное качество, наверное, имеет смысл взять 3.3B.
einhorn Автор
27.05.2023 17:40Не всегда BLEU корректирует с качеством
да, вот в этом большая проблема
у меня появилась идея, как еще можно измерить качество - что если попросить GPT-4 покритиковать перевод, а потом на основании ее критики попросить оценить численно (chain of thoughts)rPman
27.05.2023 17:40+1в лучших традициях методологии RLHF тюнинга LLM, нужно обучить модель оценки перевода и использовать ее для оценки.
janvarev
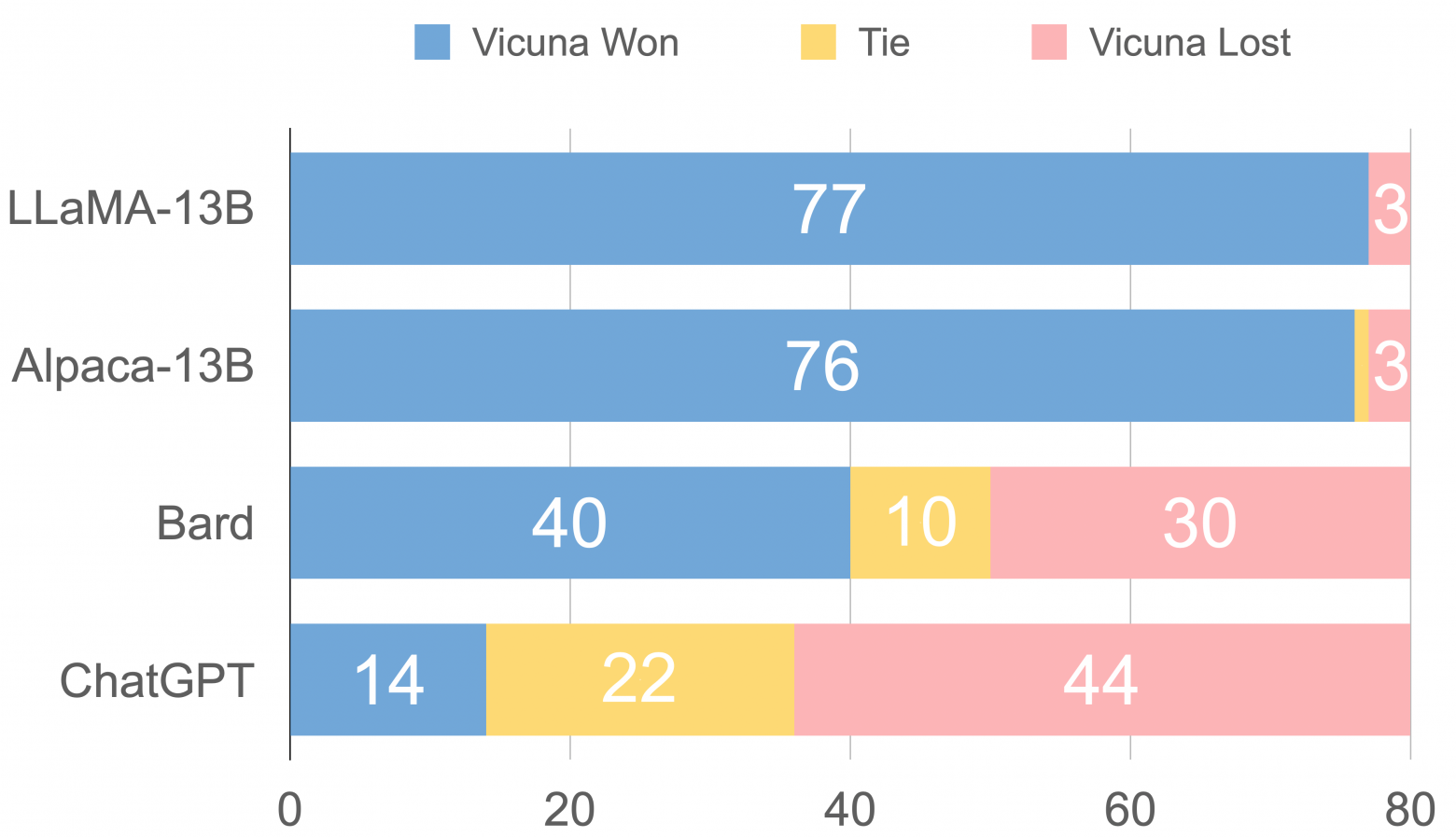
27.05.2023 17:40+1Народ делает следующий механизм - просит содержательно сравнить два перевода, дальше - оценить по 10-балльной шкале, и выявляет победителя.
Вот со странички Викуны: https://lmsys.org/blog/2023-03-30-vicuna/
janvarev
27.05.2023 17:40Кстати, я не знал, какой промт для ChatGPT лучше, поэтому результаты похуже чем у вас. Протестил бы на вашем промте еще раз (интересно, какие результаты), но только с ключом API проблемы небольшие.
einhorn Автор
27.05.2023 17:40+1Да, там прямо очень критично попросить модель "make the translation sound as natural as possible".
rPman
27.05.2023 17:40+2Добавил на скорую руку плагин локального запуска llama.cpp как приложение, использует модель llama-65b-q5_0.ggjt2
с запросом и --temp 0Получил rus->eng 40.43, eng->rus 27.5You are text translator. Keep punctuation and quotes.### Instruction:
Translate from {from_lang} to {to_lang}.
### Input:
{text}
### Output:
Я чувствую что если заниматься тюнингом запроса, причем не вручную а воспользоваться prompt tuning, то можно получить заметно лучше результаты.
И еще, различия в переводе, исходя из метрики BLEU не кажутся мне всегда плохими, но да оценить численно это сложноjanvarev
27.05.2023 17:40Спасибо за тесты!
Да, userlang->en пара показывает обычно значительно лучше результаты, чем обратно (даже 7B дает 32). Мне было интересно именно на проблемной паре - перевод на язык.
Тюнингом, конечно, надо бы позаниматься - времени не было.
И еще, различия в переводе, исходя из метрики BLEU не кажутся мне всегда плохими, но да оценить численно это сложно
Да, согласен - про это в статье было - что GPT4 дает сравнимый BLEU, а по качеству ощущается лучше. Смысл в том, что за всякие допсимволы BLEU сильно наказывает, в то время как пользователем они не особо замечаются.
einhorn Автор
27.05.2023 17:40+1Смысл в том, что за всякие допсимволы BLEU сильно наказывает, в то время как пользователем они не особо замечаются.
Нет, дело не в этом. Я при измерении BLEU вообще удаляю почти всю пунктуацию. Я думаю, там причина в том, что ChatGPT более "дикая", она более машинно переводит (зато более правильно). Плюс data contamination у Google Translate (не знаю как с этим у DeepL), плюс оптимизация других моделей на BLEU.
janvarev
27.05.2023 17:40+1Вот есть довольно интересная статья со сравнением переводов ChatGPT:
Large language models effectively leverage document-level context for literary translation, but critical errors persist
https://arxiv.org/pdf/2304.03245.pdf
Там используются вроде как более интересные метрики - Bleurt, Comet; но я не нашел быстро их программной реализации, чтобы прикрутить в проект.
janvarev
27.05.2023 17:40+1Вот еще - примеры того, что BLEU не очень хорошо справляется с оценкой (но другого особо нет)
Why you shouldn’t trust BLEU according to 37 studies published over 20 years
janvarev
27.05.2023 17:40+1Неожиданно нашел нормальную библиотеку и прикрутил вычисление метрики COMET

janvarev
27.05.2023 17:40Вот, кстати, пример OpenAssistant 30B. Визуально как-то не очень.
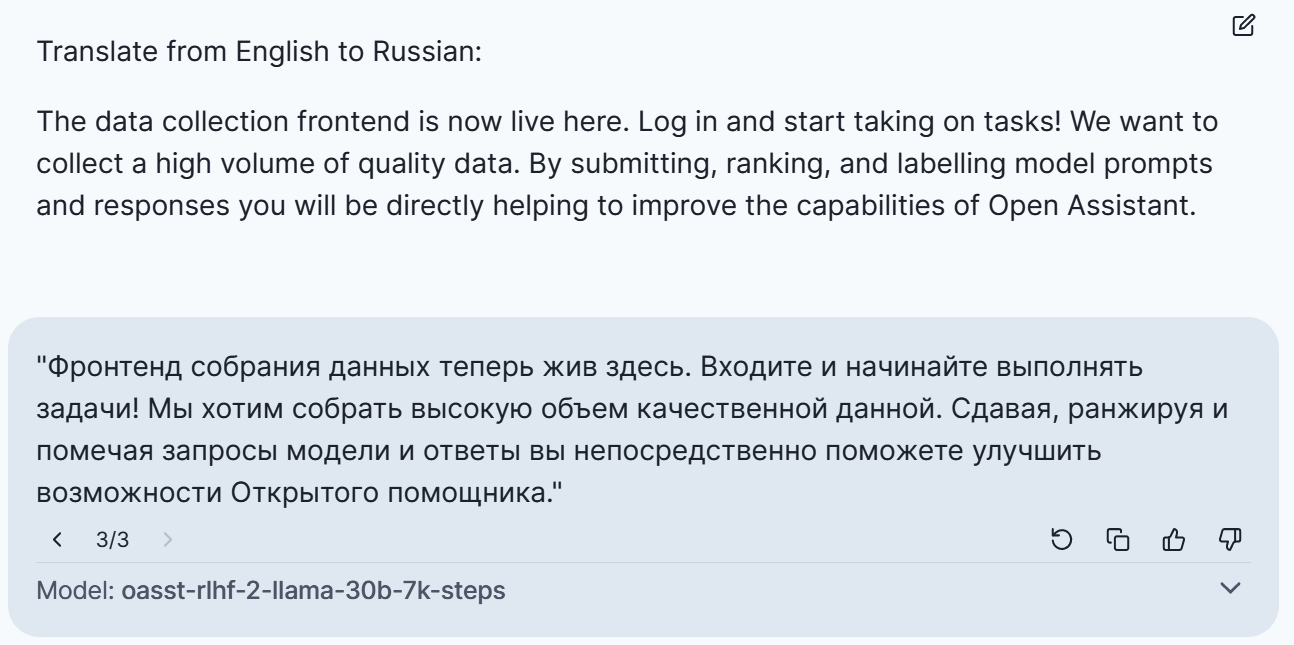
einhorn Автор
27.05.2023 17:40+1Translate the message below from English to Russian. Make the translation sound as natural as possible.
---The data collection frontend now lives here. Log in and start taking on tasks. We want to collect a high volume of quality data. By submitting, ranking and labelling model prompts and responses you will be directly helping to improve the capabilities of Open Assistant.
---(+ температуру выставил в 0)
ПолучилосьСбор данных фронтенд теперь здесь. Войдите и начните выполнять задания. Мы хотим собрать высокую скорость качественных данных. Определяя, ранжируя и описывая запросы модели ответов вы непосредственно поможете улучшить возможности Открытого помощника.
У вас лучше по смыслу, у меня - правильнее по грамматике.
Согласен, OpenAssistant пока слабоват для перевода.





Pastoral
27.05.2023 17:40Google Translate вроде переводит с языка на внутреннее представление смысла и потом излагает на другом языке. И мрака, как мне кажется, давно нет, до всяких моделей, и по логике и не может быть. А остальное выглядит как кусок переводчика который пока не доделан.
Про совсем сломался на японском - у меня сомнения. Кандзи действительно можно учить и запоминать и это не тождественные понятия, как можно учить и запоминать законы физики. Судя по ответу, имелось в виду именно запоминать и Гугол правильно, или может удачно, схватился за прямое значение.
einhorn Автор
27.05.2023 17:40+1На японском дело не в учить/запоминать, а в том, что Google Translate перевел только треть текста.

smile616
27.05.2023 17:40похоже на какой-то баг: переводится только то что в первой группе японских кавычек (「 」) и до конца абзаца/строки. Попробуйте добавить перевод строки после каждой закрывающей японской кавычки (」).

denticulus
27.05.2023 17:40+4Но внутреннее представление смысла в Google Translate скорее всего реализовано на английском языке. При переводе с русского на польский теряются род, окончания и вообще смысл.
Например, skrzynia biegów - это коробка передач. Но в переводе получаем "передача инфекции". Никак иначе, кроме как с английского "transmission", такой смысл не получить.
einhorn Автор
27.05.2023 17:40Раньше да, раньше у Гугла все работало через английский.
Сейчас, скорее всего, это уже не так - для каких-то языковых пар есть прямые модели, для каких-то через английский.



OleGrim
27.05.2023 17:40+4Я был сильно впечатлён когда GPT-3.5 перевёл фразы с санскрита (сам определил).
Мало того что перевёл, но и описал смысл фразы (философский) и достаточно точно!
Проверял по Бхагавад-гита. Глава 2. Там представлен оригинальный текст на санскрите (оригинал в романской записи) и варианты переводов разных авторов.
P.S. "Стандартные" переводчики с санскрита не переводят.
Kristaller486
27.05.2023 17:40+1Можно предложить, что в обучающей выборке GPT-3.5 было достаточно всего на санскрите с подробным описанием и толкованием текстов, да на разных языках, поэтому это скорее не перевод в традиционном смысле слова. Интереснее было бы попросить GPT перевести что-то на санскрит, а потом оценить качество полученного текста.
einhorn Автор
27.05.2023 17:40+1Я тестил GPT-4 на латыни - нормально и переводит, и общается :)
Но санскрит хардкорнее.
Kristaller486
27.05.2023 17:40+1Я скорее про то, что тексты на санскрите в подавляющем большинстве религиозные, с вытекающим из этого большим количеством разборов, интерпретаций и переводов, а значит GPT могла просто "дословно" их выучить. С обратным переводом такое не выйдет. Кстати, пару дней назад задумался насколько GPT хорош в старославянском, вот тут точно хардкор.


astronom
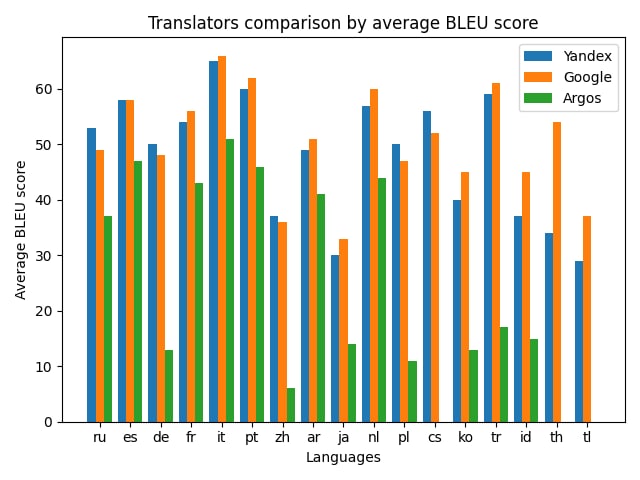
27.05.2023 17:40+3А как же Яндекс.Переводчик? У него очень хороший перевод местами), было бы интересно сравнить
Но, в любом случае, очень круто, что уже можно использовать модели у себя на ноутбуке, и они будут работать офлайн, переводить любой текст без доступа к Интернету
einhorn Автор
27.05.2023 17:40+6Я больше полутора лет назад делал похожий тест с Яндексом (на другом датасете), вот нарыл график :) (везде перевод на английский)


Denai
27.05.2023 17:40+6Делал перевод для грузинских SMS. Самому было нужно, потому что они написаны транслитом, а его надо сначала просто в грузинский перевести. Тут основная проблема была в том что у большинства API нет грузинской модели, а если есть, то она просто ужасного качества. Единственным вариантом, который более-менее всё переварил, пока стал chatGPT. Если кому-то такой переводчик SMS нужен - заходите, пользуйтесь, делитесь фидбеком: https://myroute.ge/translate/
Периодически корректирую промпт, потому что нейросеть в некоторых ситуациях всё равно несёт ахинею, либо добавляет отсебятину. Два самых главных параметра в запросе - температура 0 и очень убедительно расхвалить нейросеть и попросить выдавать результат нормально) Не попросишь - не получишь.einhorn Автор
27.05.2023 17:40+3Да, я тоже пришел к выводу, что "make the translation sound as natural as possible" сильно бустит BLEU.
Не поделитесь своим промтом?
Кстати, в подобном приложении я бы добавил опцию: переводить на русский или на английский, на английский будет поточнее.
Denai
27.05.2023 17:40You are professional translator and native speaker. You are reading Georgian SMS written using transliteration. Translate SMS text to Russian. Keep only Russian translation. Make text readable. Keep English words and links as is in English. ....
И после этого ещё несколько вариаций уточнений, которые пока меняю. Оптимальный перевод был, когда просил переводить сначала на английский, а оттуда уже на русский. Но в этом случае нейросеть постоянно теряет мысль и дробит перевод на странные куски (3.5 turbo). т.е. не получается добиться стабильности результата. Получается на 1-5 запросах прям отличный перевод, а на 2-3 каша. Иногда просто выдаёт что-то вроде "шдобиса мре аквибиси мадлоба хватули" т.е. нейросеть уносит в транслит русскими буквами грузинских букв. Транслит же? Транслит) Иногда выплёвывает результат на английском. Иногда какие-то части пропускает. Слишком много уточнений - путается. Слишком мало - фантазию проявляет. Ищу тот самый промпт, который отработает хорошо прям всегда)einhorn Автор
27.05.2023 17:40+1Не нужно мешать перевод и транслитерацию. Зачем нейронка для нормализации? Нормализуйте алгоритмом, переводите с нормального грузинского.
У вас мегасложный и архидлинный промт, GPT-3.5 на таких плохо справляется. Возьмите мой (+ можно сказать, что сообщение - это SMS).
Denai
27.05.2023 17:40Затем что есть в тексте английские слова, а есть грузинские. И те и другие написаны латинскими буквами. Отделить одно от другого пока только нейронка и может.
2. Вот с таким как раз сыпется, когда встречает странные СМС. С такого и начал
einhorn Автор
27.05.2023 17:40Можно спарсить английский и грузинский словари и классифицировать каждое слово в один из языков; затем нормализировать только грузинские слова
Denai
27.05.2023 17:40Да, в первую очередь об этом подумал. Реализовать вменяемо и быстро не вышло. СМС - странная штука. Её мало что нормально парсит. Например, случайная СМС:
MBC-shi 50,000 Laramde Avto Sesxs 7%-mde Fasdaklebit miigeb! Dgesve, Shemosavlis Dadasturebis Gareshe!
Efeqturi 23.7%-dan
NO99999плюс к тому ссылка и номер.
einhorn Автор
27.05.2023 17:40Можно посмотреть быстрые модели для распознавания языка (например, lid.176), и пихать туда фрагменты текста
Denai
27.05.2023 17:40Они в моих экспериментах плохо отрабатывали на отдельных словах и обрывках слов.
MBC-shi, 7%-mde, daibrune 2% cashback, NO91293, sesxze minus 4%. Языковая мешанина, плюс поправка на то что главный язык грузинский. С ним работает очень ограниченное число моделей и словарей в принципе.

NeoCode
27.05.2023 17:40Последнее время Google Translate (бесплатный) переводит некоторые тексты ужасно плохо - просто выкидывает части предложений, если текста много (много это скажем 6-8 предложений). Если уменьшить количество текста на входе (до 2-3 предложений), то перевод появляется...

janvarev
Ой, у меня прям сравнимая работа вот здесь: https://github.com/janvarev/OneRingTranslator - универсальный REST-сервер для переводов с возможность подключения переводчиков плагинами, и автоматической оценкой их качества через BLEU.
Хочу обратить внимание - FB NLLB прямо-таки сравнима на небольших текстах с Google Translate и Deepl - правда, скорее по BLEU метрике.