

Kubernetes, как и любая другая рабочая среда, не лишен уязвимостей. Поэтому наряду с развитием проектов в нем администраторы или DevOps-инженеры должны уделять внимание и безопасности использования кластеров. Для этого нужен надежный инструмент, который может работать с любыми политиками и валидировать действия клиентов в кластерах Kubernetes.
Я — Александр Прохоров, программист компании VK Cloud. Моя команда отвечает за кластеры Kubernetes и их безопасность. На примере наших кейсов покажу, какие есть уязвимости при эксплуатации Kubernetes-кластеров, как с ними помогает бороться Open Policy Agent Gatekeeper и какие проблемы могут встретиться при интеграции Gatekeeper в production-среду.
Материал подготовлен на основе моего выступления на конференции VK Kubernetes Conf «Gatekeeper в production: полезные практики и шаги, которые не стоит допускать».
Базовые меры обеспечения безопасной работы с кластерами
Политик безопасности может быть много, но зачастую в соблюдении лучших практик они похожи друг на друга. Например, к числу базовых мер обеспечения безопасности при работе с кластерами относят:
- использование образов только из доверенных registry;
- запрет на использование тега Latest в образах;
- обязательное использование limits и requests;
- запуск привилегированных контейнеров;
- запрет на использование hostPID и hostIPC.
Помимо этих практик компаниям часто надо создавать свои политики и правила валидации, а значит, нужен отдельный инструмент, который умеет:
- работать с политиками;
- валидировать действия;
- настраивать не только кластеры Kubernetes, но и другие сервисы или приложения.
Нам нужен был именно такой инструмент. Под наши требования подошел Gatekeeper.
OPA (Open policy agent) и Gatekeeper
Open Policy Agent — универсальный инструмент, который интегрирован с различными сервисами и позволяет настраивать политики по их использованию.

Gatekeeper — специфическая реализация Open Policy Agent для Kubernetes, которая работает в качестве Webhook для валидации манифестов. Этот инструмент предназначен для аудита и автоматического применения к ресурсам Kubernetes политик безопасности, написанных на языке Rego.
Gatekeeper встраивается между сервером API Kubernetes и OPA в качестве admission-контроллера, принимает все поступающие в кластер запросы на создание каких-либо объектов от kube-apiserver и в реальном времени проверяет их на соответствие предварительно настроенным политикам безопасности.

Условно алгоритм работы со встроенным Gatekeeper следующий:
- При создании объекта в Kubernetes запрос попадает в KubeAPI.
- Для проверки отправителя и его прав выполняется аутентификация и авторизация пользователя.
- После авторизации и аутентификации выполняется мутация данных: к объекту добавляются новые поля или значения в них меняются.
- Объект валидируется на соответствие валидационной схеме: проверяется наличие ключей, корректность значений и другие параметры.
- Далее следует этап validation admission, на котором отрабатывают настроенные пользователем политики Gatekeeper. Например, проверяется, есть ли запуск привилегированных контейнеров или контейнеры, у которых в образах есть тег Latest.
- После успешной проверки объект сохраняется в etcd-хранилище.

Исходные проблемы нашего Kubernetes
До внедрения Gatekeeper пользователи нашего Kubernetes сталкивались с рядом проблем. Среди них:
- неравномерное распределение нагрузки на ноды;
- несанкционированное выселение с ноды приоритетных подов;
- невозможность Cluster autoscaler правильно оценить загруженность нод и корректно выделить новые ресурсы для запуска пода.
Мы проанализировали проблемы и обнаружили, что с трудностями, как правило, сталкиваются пользователи, которые не выставляют контейнер-лимиты и реквестов.
Почему важно соблюдать практику limits/requests
В кластере Kubernetes за размещение подов на конкретной ноде отвечает KubeScheduler. Этот компонент работает по определенному алгоритму, который включает фильтрацию и ранжирование:
- Сначала KubeScheduler выбирает список нод, у которых есть ресурсы для запуска пода.
- Потом ноды ранжируются с учетом доступных ресурсов: чем больше ресурсов, тем больше очков получает нода.
- Новый под размещается на ноде с большим количеством очков.

При этом KubeScheduler получает информацию о загрузке нод из etcd-хранилища, где хранится значение суммы всех контейнеров по лимитам и реквестам для каждого пода. Соответственно, если limits/requests не указаны, KubeScheduler будет распределять нагрузки «вслепую», и они станут неравномерными — возникнут проблемы.
Pod Quality of Service
Также наличие limits/requests влияет на контейнеры Pod Quality of Service, среди которых выделяют три класса:
-
Guaranteed-класс. Самый надежный класс качества. Выдается подам, у которых контейнеры имеют лимиты и реквесты по CPU и Memory.
-
Burstable-класс. Имеет в поде минимум один контейнер, у которого заданы реквесты и лимиты по CPU и памяти. Причем значение реквестов ниже значения лимитов.
- Best effort-класс. Присваивается всем подам, контейнеры которых не имеют ограничений по лимитам ресурсов — limits/requests не заданы.
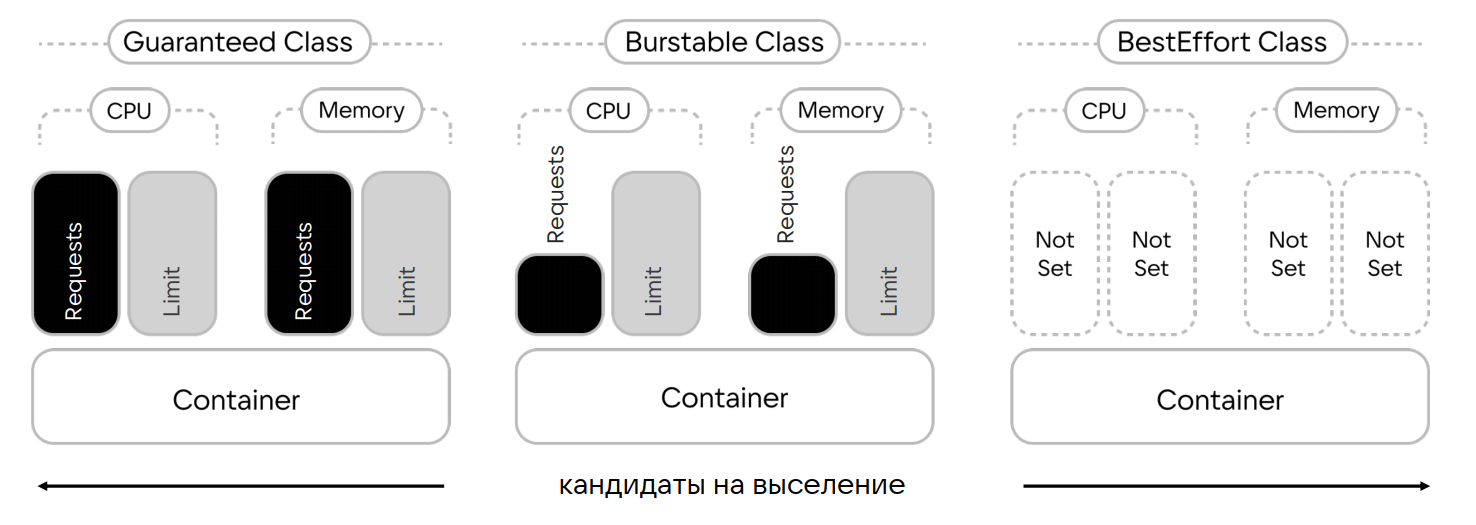
Best effort-класс самый уязвимый: если при росте нагрузки на ноды не будет хватать ресурсов, Kubernetes начнет освобождать место, выселяя в первую очередь поды с классом best effort. То есть отсутствие limits/requests может стать причиной несанкционированного выселения с ноды приоритетных подов.
Таким образом, соблюдение практики limits/requests:
- обеспечивает равномерность распределения нагрузки на ноды;
- исключает выселение с ноды под с высоким приоритетом;
- помогает Cluster autoscaler понимать, сколько ресурсов нужно выделить для размещения ноды.
Чтобы нативно разобраться с этой проблемой и бесшовно перевести всех клиентов на обязательное соблюдение практики limits/requests, мы решили использовать политику Gatekeeper. Она обязывает пользователей при запуске подов во всех контейнерах указывать лимиты и реквесты. Но после небольшого тестового периода мы выяснили, что такое обновление только усложняет работу пользователей: не все клиенты соблюдают практику limits/requests. Причин несколько:
- на добавление limits/requests во всех запускаемых контейнерах нужно время;
- Helm-чарты в репозитории по умолчанию не содержат limits/requests;
- нужно все правильно подсчитать.
То есть мы не могли применить конкретную политику, обязывающую пользователей выставлять limits/requests. Вместо нее мы решили применить стандартную политику Kubernetes — LimitRange.
LimitRange и Shell-operator
LimitRange — политика ограничения распределения ресурсов (лимиты и запросы), которые можно указать для каждого применимого типа объекта (например, Pod или PersistentVolumeClaim) в пространстве имен.

LimitRange также позволяет выставлять лимиты и реквесты по умолчанию для всех контейнеров, которые запускаются в этом неймспейсе.
В нашем кейсе после применения LimitRange-манифеста в неймспейсе значения лимитов и реквестов стали автоматически добавляться в контейнеры пользователей, даже если эти значения не указаны. Это упростило работу, но только в рамках одного неймспейса.
Чтобы динамически применять настройку LimitRange на все неймспейсы, которые потенциально может создать клиент, мы применили Shell-operator компании «Флант». Shell-operator позволяет подписаться на события в Kubernetes и настроить на них запуск кастомных скриптов, в том числе хуков. Мы подписались на событие по созданию неймспейса и настроили скрипт, который применяет к нему LimitRange.
Дополнительные меры безопасности
Помимо централизованного внедрения политик Gatekeeper также помог нам закрыть некоторые «дыры» в базовой системе безопасности Kubernetes. Например, в k8s есть директива hostPath, через которую клиент может реализовать много уязвимостей. Например, через hostPath можно:
- монтировать Docker, CRI-O сокета в под и получить доступ ко всем контейнерам: запускать, удалять, создавать новые;
- найти kuberconfig с правами Cluster admin и завладеть им;
- смонтировать собственный файл с авторизационными ключами и получить неограниченный доступ к кластеру;
- примонтировать файл /etc/shadow и взломать хеши.
Чтобы закрыть все уязвимости hostPath, мы использовали hostfilesystem. Это политика Gatekeeper, которая позволяет указывать список директорий, доступных для монтирования, а также выставлять для них права на чтение.
Кроме hostPath, в своих кластерах мы также ограничиваем настройки hostPID и hostIPC, благодаря уязвимостям в которых злоумышленники могут:
- получать доступ к процессам на хосте;
- просматривать все переменные окружения подов, которые запущены на хосте;
- просматривать файловые дескрипторы.
Gatekeeper помог и в этом случае: закрыть уязвимости hostPID и hostIPC мы смогли с помощью готовой политики hostnamespace.
Отдельно стоит отметить, что Gatekeeper предоставляет большой набор политик, которые можно использовать в разных кластерах. Причем многие из них легко модифицировать под конкретные кейсы, немного дополнив код. Например, чтобы изменить политику Gatekeeper из репозитория, которая работает на весь кластер, достаточно добавить одну строку:
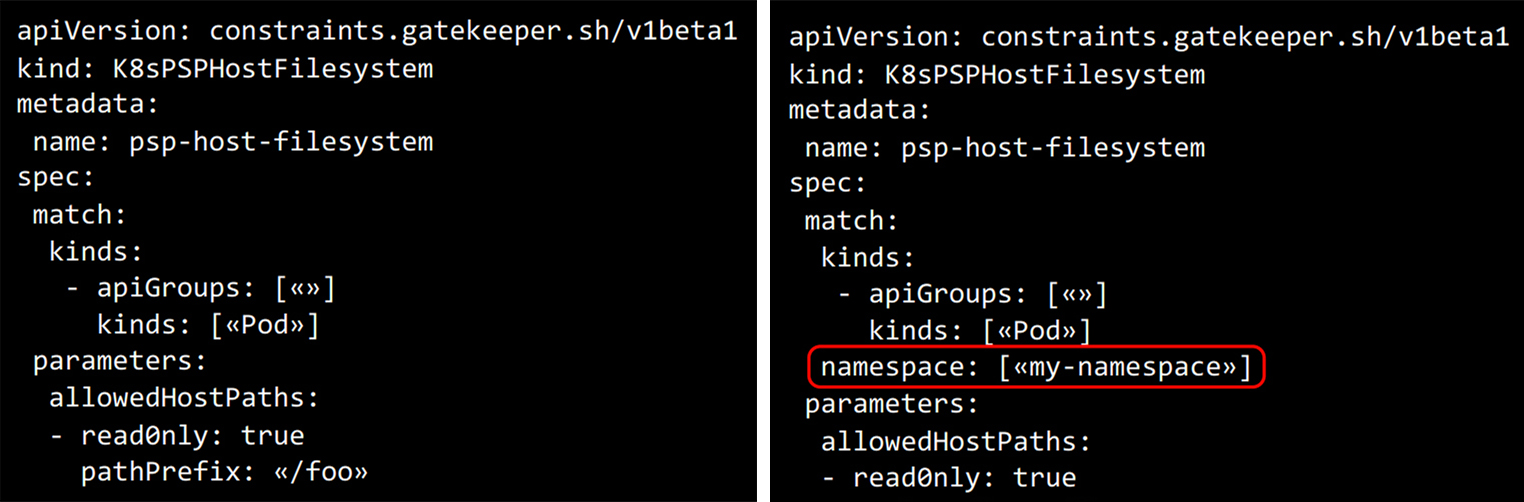
После этого кластерная политика превратится в политику, которая работает относительно неймспейса.
Подводные камни, с которыми мы столкнулись
В теории работать с политиками просто: достаточно взять политику из репозитория, применить ее и пользоваться. На практике же нередко возникают трудности. Мы столкнулись с некоторыми из них.
-
Внедрение политик без подготовки может нарушить работоспособность рабочей среды Kubernetes. В нашем случае внедрение практики обязательного указания limits/requests сказалось на доступности нод клиентов, одновременно с этим многие пользователи были просто не готовы быстро и корректно указать limits/requests. Чтобы не допустить подобного нужно внедрять политики постепенно или искать альтернативный способ, который позволит применять ограничения нативно.
-
Install job зачастую используют директиву hostPath и монтируют к себе в контейнер файлы, которые помогают развернуть тот или иной Helm-чарт. Установка чартов из Helm-репозитория может быть несовместима с используемыми политиками. Например, в нашем случае после установки политики hostPath была нарушена работа всех используемых Helm-чартов, а именно Install job в них — совместимость просто не была обеспечена. Чтобы решить проблему, мы выделили Install job Helm-чартов в отдельный KubeSystem.
-
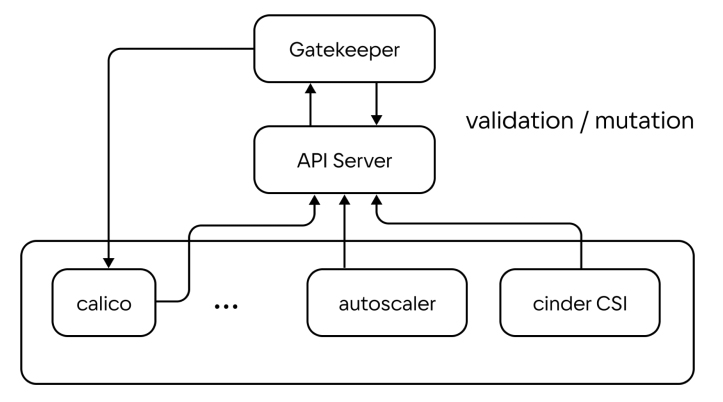
При интеграции Gatekeeper нельзя применять политики к namespace KubeSystem и включать валидацию данного namespace Gatekeeper. Мы знали о таком запрете и не реализовывали его в production, но сделали небольшой тест: при включенной валидации в кластере с CNI-плагином Calico последний не сможет провалидировать свои действия, поскольку APIServer «поднимается» позже. В итоге Calico ждет, когда поднимется Gatekeeper, а Gatekeeper ждет, когда поднимется Calico, — кластер может «не завестись» вовсе. Избежать проблем помогает отключение валидации и отсутствие политик в отношении namespace KubeSystem.
Выводы из нашего опыта
- Настройка кластеров для безопасного использования — обязательное требование для всех проектов на любом уровне развития. Это связано с тем, что у Kubernetes «из коробки» больше бэкдоров, чем фич, которыми эти бэкдоры можно закрыть.
- При работе с кластерами Kubernetes не стоит игнорировать best practice — их несоблюдение может дорого обойтись компании и потребовать много времени на приведение кластеров к соответствию правилам.
- При настройке Gatekeeper следует отключать валидацию неймспейса KubeSystem, в противном случае кластер может «не завестись».
- При использовании политик важно учитывать наличие Helm-чартов и их тип — политики безопасности Gatekeeper надо выбирать и настраивать так, чтобы они не влияли на работу Helm-чартов.
Присоединяйтесь к Telegram-каналу «Вокруг Kubernetes», чтобы быть в курсе новостей из мира K8s! Регулярные дайджесты, полезные статьи, а также анонсы конференций и вебинаров.
А также пробуйте наш Kubernetes aaS — новым пользователям для тестирования начисляем 3 000 бонусных рублей.
Комментарии (2)

HunterXXI
22.06.2023 10:39И еще надо особенно следить за работоспособностью gatekeeper - если он упадет, webhook не отработает и будет отказ api сервера в применении манифеста даже если он корректный
Reversaidx
Тоже внедрял Gatekeeper, я не понимаю зачем они сделали такой полугошный синтаксис, сложные условия просто очень больно писать