
Привет! Меня зовут Михаил, я Java Backend Developer в Simbirsoft. В этой статье хочу поделиться своим опытом создания миграций файлов с большим списком данных при помощи Liquibase. Cтолкнувшись с такой задачей на проекте, я был сильно удивлен тому, как мало материалов написано по этой теме, даже на английском. Поэтому описал то, что удалось собрать и проверить на собственном опыте.

Навигация
Эта задача решалась на одном из проектов, который предполагал цифровизацию открытия счетов для банка. Задача звучала так: реализовать фичу, где клиент может выбрать отделение банка, к которому будет привязан счет. Для этого он выбирает город, а затем офис. Из-за того, что существующий сервис не удовлетворял нашим требованиям, было принято решение создать свой список офисов и городов. Для этого мне предоставили excel-документ, в котором находилось более 10 тысяч записей. С ними и предстояло работать. Поскольку с заказчиком было подписано NDA, я покажу немного упрощенные примеры и варианты решения, но со всеми тонкостями.
Итак, я создал следующий excel-документ со списком офисов Simbirsoft:
1. Решение задачи
Если попытаться описать эту статью одной фразой, то получится учебное пособие по документации Liquibase, ознакомиться с ней можно здесь. Конечно, специалист с опытом решения подобных задач взглянет на документацию и сразу всё поймет. Но у программиста, который впервые занимается миграцией, сразу появится вопрос: а как заставить это работать? К тому же есть много мелочей, зная которые заранее, можно сэкономить себе много сил и времени, а мне кажется, для этого и существует Хабр.
Так, например, когда я уже реализовал и загрузил задачу, то миграции вроде бы проходили и ошибок не было, но таблицы были пустыми. Проблема была в том, что при запуске проекта сначала начинают выполняться change set’ы Liquibase, где в таблицы мигрировались данные, а уже потом Hibernate создает таблицы, куда надо мигрировать. Да, хорошем тоном является создание таблиц с помощью Liquibase, что позже мы и сделали, когда после нескольких прототипов начали реализовывать приложение. Но на практике знание такой тонкости мне бы не помешало.
2. Генерация csv-файла из Excel
Для начала немного теории. Liquibase для миграции данных из файлов необходимо, чтобы этот файл был в формате CSV.
Данные в файле разбиты по строкам, как и в таблице. Каждое значение огорожено запятой, а в первой строке описаны названия столбцов.
В документации Liquibase сказано, что импортируемые данные необходимо передавать в csv-формате в кодировке UTF-8. Кодировку, конечно, можно указать и другую параметром encoding, но зачем, если у Excel есть функция перевода в СSV UTF-8. Она нам отлично подойдет.
В excel вы не заметите разницу, но если открыть файл в текстовом редакторе, то будет следующая картина:

3. Нормализация данных
После того как мы перевели наш список в csv-формат, нужно еще и привести в порядок данные, чтобы этим списком можно было удобно пользоваться и изменять. Для этого надо решить несколько проблем.
3.1 Выбор основного ключа
Сначала надо выбрать поле, которое станет основным ключом. Наша главная задача здесь сделать так, чтобы легко было обновить список. Главная проблема в том, что, наверное, уже везде существует несколько контуров. По самому минимуму это dev и prod. Если для обновления списка придется менять вручную что-то в базе данных на проде — это, во-первых, очень неэффективно, а во-вторых, получить доступ к ней если и возможно, то очень долго. А оставлять себе возможность обновить список надо абсолютно всегда. Клиент может говорить, что этот список точно меняться не будет, или он список промежуточный и скоро мы от него избавимся. Но в бизнесе всё что угодно может поменяться в последний момент.
Чтобы получить возможность обновить список, есть два варианта:
Более предпочтительный — с помощью уникального поля. В списке уже есть поле, которое уникально для каждого элемента таблицы. К сожалению, когда список состоит из 1000+ элементов, такое редко бывает. В моей задаче у каждого офиса был номер, однако возникали сложности: либо рядом был другой офис рядом с таким же номером, но другим адресом, либо был один офис с одним адресом, но дополнительные параметры были разные, и поэтому выводилось несколько почти одинаковых строчек. Но для 1000+ офисов разобраться на месте, как все организовано, невозможно, и у команды часто нет возможности узнать, почему так. Поэтому обращаемся ко второму варианту.
Более сложный — с помощью id. Когда ни один столбец не может уникально обозначить один элемент, есть следующее решение. В теории можно использовать композитный основной ключ. Но практика показала — если есть огромные списки, в них может поменяться все, и если в таблице поменять одно из полей, то где-то в таблицах сломается ссылка. Поэтому лучшим вариантом будет создать в файле новый столбец, в котором будет лежать id. Важно, чтобы id были проставлены заранее в файле, а не отданы на генерацию тогда, когда заливаются данные в таблицу. В идеале сделать id цифровым значением, например, от 0. Таким образом, на всех стендах будут одинаковые ссылки, что позволит обновлять список, просто создав заполнение таблицы новым списком. Это позволит легко коммуницировать в команде, когда речь заходит о том, что и где конкретно нужно обновить. Намного проще обновить элемент 500, чем огромный uuid или его кусок. Да и элементы добавляются только вручную, их почти всегда будет меньше, чем вместимость int’a.
3.2 Перевод данных к требованиям типов
Далее надо просмотреть таблицу и проверить ее на совпадения типов. Например, поле Основной офис является Boolean, которое в Liquibase принимает значение «t и «f», а в CSV «да» и «нет».
3.3 Фильтрация данных
Так как список огромный, там наверняка будут встречаться ошибки, например, лишние запятые, которые ломают формат csv. В этом случае можно вместо excel воспользоваться другим конвертером, чтобы заменить символ «разделитель с запятой», например, на «точку с запятой». Но это далеко не всё, что может пойти не так. Так что лучший способ профильтровать ошибки — на локальной среде пытаться провести у себя, залив в базу данных, находя и исправляя ошибки, на которые ругается Liquibase. Проще всего будет это сделать, воспользовавшись grep’ом в линуксе, а на винде воспользоваться wsl или docker-контейнером с персептивной папкой. Но это тема для отдельной статьи :)
В результате у нас получается один из двух вариантов таблиц:
Таблица, где основным ключом будет поле Город
Таблица, где основным ключом будем поле id, которые мы сами и добавили
4. Настройка проекта
Я не буду здесь описывать стандартную инструкцию по добавлению hibernate и liquibase, хочу лишь заострить внимание на одной настройке hibernate в yaml-конфиге под названием ddl-auto. Чтобы все миграции сработали правильно, необходимо, чтобы значение у этой настройки было validate.
spring:
jpa:
hibernate:
ddl-auto: validate5. Создание таблиц
Мы определились, что у нас будет представлять основной ключ, теперь дело техники — создать change set на создание таблицы. Я для удобства приведу здесь пример с добавленным полем id.
5.1 Загрузки данных в таблицу
Структура проекта для хранения разных версий списка
Так как Liquibase по сути является git’ом для структуры БД, то csv у нас будут накапливаться, и как-то это надо хранить в структуре проекта. Общепризнанную структуру мне найти не удалось, поэтому приведу пример, как делаю я.
По умолчанию Liquibase ищет миграции по пути src\main\resources\db\ changelog. Я организую внутри этой папки вот так:

Описание команды loadData
databaseChangeLog:
- logicalFilePath: db/changelog/migrations/db.changelog-0.2-importToSimbirsoftOfficesTable.yaml
- changeSet:
id: 002_import_csv_to_simbirsoft_offices_table
author: TreatHunter
changes:
- loadData:
columns:
- column:
index: 4 # индекс обозначает порядковый номер столца csv
name: id # название столбца таблицы в базе данных
- column:
header: Город # вместо индекса можно и использовать название столбца в csv
name: city
- column:
index: 1
name: index
- column:
index: 2
name: address
- column:
index: 3
name: is_head
tableName: simbirsoft_offices
encoding: UTF-8 # кодировка csv файла если она UTF-8 можно этот параметр не ставить
separator: ',' # символ, разделяющий столбцы в файле. Если это запятая, то параметр можно пропустить
quotchar: '"' # в какие кавычки будет экранироваться элемент, строки если в нем есть знак, разделяющий столбцы. По умолчанию "
file: "db/changelog/csv/changelog-0.2-importToSimbirsoftOfficesTable/Список офисов Simbirsoft с добавленным основным ключом.csv"Как мне кажется, стоит добавить, что порядок элементов column не важен, можно их создавать в порядке csv, таблицы или в любом другом.
Также у column есть 3 параметр type. В этом параметре указывается тип формата данных, который лежит в csv. Но библиотека Liquibase достаточно умная, чтобы сама понимать, что лежит, так что его можно не писать. Единственное, где она может не понять — это в ситуации с датами или временем. Но нужно смотреть в документации, какой конкретно тип надо ставить. Я решил упомянуть про этот параметр, так как у него есть интересное значение SKIP, которое заставляет пропустить значения из столбца в csv-файле и в таблице расставить null.
Я использовал не все параметры, которые есть в документации Liquibase, но указал те, которые будут использованы в 80% ситуаций. Мне самому не пригодились параметры encoding, separator и quotchar.
Вот результат отработки Liquibase:

6. Как обновить данные при помощи loadUpdateData. Примеры
А теперь поговорим про обновление списка. Представим, что приходит клиент и говорит, что в справочнике есть ошибка, и надо обновить список. Так как изначально мы подготовили csv, то мы просто его скидываем и просим поправить этот файл, при необходимости объяснив структуру csv. Когда мы получаем файл и пробуем написать еще один change set c методом loadData, вылетает ошибка при запуске проекта — нельзя вставить новые данные в таблицу, так как в таблице уже есть записи с такими основными ключами. Также Liquibase не даст удалить все записи в таблице методом delete, сказав, что на эту таблицу ссылаются другие таблицы. Осознавая ситуацию, мы понимаем две вещи:
Насколько классный Liquibase, что не дает нам ничего сломать.
Нужно найти другой метод.
Таким методом является loadUpdateData. В моем примере я прибавил ко всем номерам домов 50.
databaseChangeLog:
- logicalFilePath: db/changelog/migrations/db.changelog-0.4-updateOfficesWithLoadUpdateData.yaml
- changeSet:
id: 004_update_simbirsoft_offices_table_with_LoadUpdateData
author: TreatHunter
changes:
- loadUpdateData:
columns:
- column:
index: 4
name: id
- column:
header: Город
name: city
- column:
index: 1
name: index
- column:
index: 2
name: address
- column:
index: 3
name: is_head
tableName: simbirsoft_offices
primaryKey: id # названия столбца таблицы, а не файла csv, по которому будет проверяться наличие данной строки
file: "db/changelog/csv/changelog-0.4-updateOfficesWithLoadUpdateData/Список офисов Simbirsoft с добавленным основным ключом v2.csv"Этот метод почти такой же, как и loadData, но надо еще указать столбец таблицы, по которому Liquibase будет понимать какие строчки на какие заменять, если совпадения нет, то он просто добавит новую. Логично что нужно указывать основной ключ.
Вот ссылка на официальную документацию этого метода, но она настолько плохая, что в параметрах вообще ничего нет о параметре primaryKey, и в примере этот параметр указан неправильно (на время написания этой статьи).
Вот как будет выглядеть данные в таблице после успешной миграции.
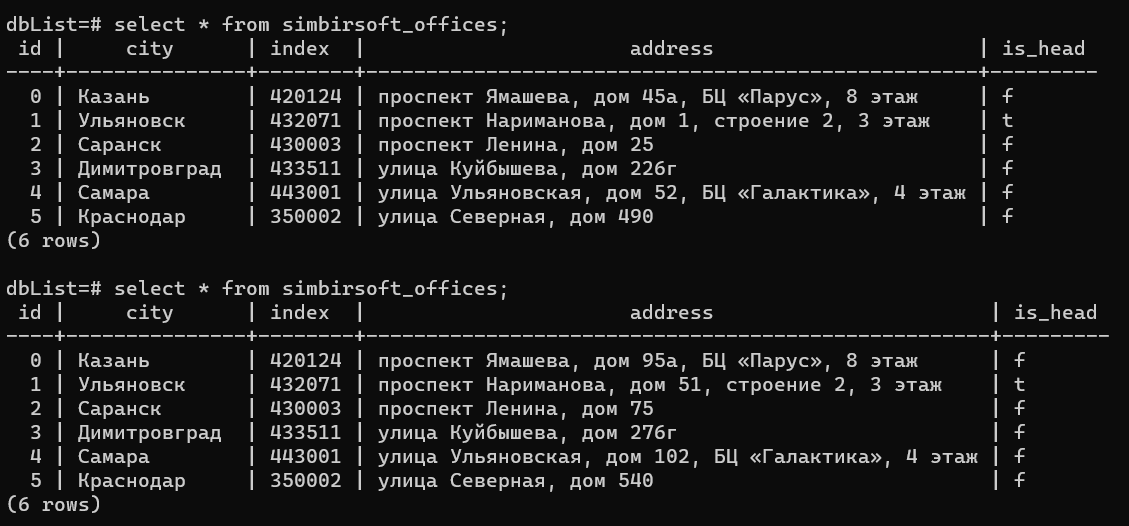
Для тех, кому не хватило статьи и хочется «потрогать» все руками, предлагаю перейти на github, где размещен проект, в котором я описал все примеры и добавил простенькую логику, чтобы можно было поиграться и понять, как все работает на практике. Можно пройти по ссылке сюда или сюда.
Заключение
Написав первую версию этой статьи, я понял что у меня получилась недодокументация, не раскрывающая всех важных деталей, которые мне как разработчику приходилось учитывать на проекте. Тогда я обратился к опыту ведения своего небольшого Youtube-канала, где записывал для друзей и одноклассников пошаговые руководства о том, как настраивать и запускать сервера для Minecraft.
Поэтому в итоге в этот туториале появились все этапы создания и поддержки больших списков в базе данных, чтобы вы могли понять не только концепт в вакууме, но и то, какие проблемы предстоит решить. Также я привел набор хороших, на мой взгляд, решений. Поэтому если вы смогли использовать этот туториал для решения подобной задачи у себя в проекте, не гугля ничего дополнительно, значит, у меня получилось добиться своей цели.
Спасибо за внимание!
Авторские материалы для backend-разработчиков мы также публикуем в наших соцсетях – ВКонтакте и Telegram.
Комментарии (4)

Andrey_Solomatin
30.06.2023 09:01+3Как скормить базе данных список из 10К офисов
10K это очень маленькие данные для базы данных.Liquibase is an open-source database schema change management solution
По факту это инструмент для миграции, а не для данных.
Если заголовок прочитать, как: Сделать миграцию 10K записей, через Liquibase" то норм.
А так, я заглянул посмотреть, что это за база такая, где для вставки пары мегабайт данных нужно статью писать.

APXEOLOG
30.06.2023 09:01Cтолкнувшись с такой задачей на проекте, я был сильно удивлен тому, как мало материалов написано по этой теме, даже на английском
Мне кажется обычно люди используют обычные SQL changeset'ы. Поэтому вся задача по сути - наколеночным скриптом перегнать excel файл в sql команды
Andrey_Solomatin
30.06.2023 09:01Также у column есть 3 параметр type. В этом параметре указывается тип
формата данных, который лежит в csv. Но библиотека Liquibase достаточно
умная, чтобы сама понимать, что лежит, так что его можно не писать
Явное лучше неявного. Лучше пишите.Так как изначально мы подготовили csv, то мы просто его скидываем и
просим поправить этот файл, при необходимости объяснив структуру csvЕсли у вас есть экспертиза в вебе, то возможно CRUD будет быстрее сделать. Пусть клиенты сами всё правят.
Так что лучший способ профильтровать ошибки — на локальной среде
пытаться провести у себя, залив в базу данных, находя и исправляя
ошибки, на которые ругается Liquibase.Ну лучший, но простой. В клиентских данных может быть много проблемы и просто формальной верификацией схемы это можно не поймать.
Я их мира Питона, там есть хороший инструментарий для этого (Pandas). Конечно тестирование с базой это не заменяет, но понять, что за данные и почисить их можно намнгого быстрее (если есть опыт работы с инстументами).
Akina
Какие лишние запятые, Вы о чём? на свой скриншот хотя бы гляньте!
Если значение текстового поля содержит запятую, Excel однозначно и безусловно обрамляет значение двойными кавычками. А сами двойные кавычки, если они встречаются в значении - удваивает. Так что никакой проблемы не возникает.
Кроме того, у Excel ещё есть предопределённый формат экспорта в текст с использованием в качестве разделителя символа табуляции.