
Эволюция тензорных ядер NVIDIA: От Volta До Blackwell
Ссылка на первоисточник: https://semianalysis.com/2025/06/23/nvidia-tensor-core-evolution-from-volta-to-blackwell/
В нашей статье AI Scaling Laws конца прошлого года мы обсудили, как несколько стеков законов масштабирования ИИ продвигают индустрию ИИ вперед, обеспечивая больший, чем закон Мура, рост возможностей модели, а также соразмерно быстрое снижение удельных затрат на токены. Эти законы масштабирования обусловлены оптимизацией и инновациями обучения и инференса, но достижения в вычислительных возможностях, выходящих за рамки закона Мура, также сыграли решающую роль.
В статье AI Scaling Laws, мы пересмотрели десятилетние дебаты о масштабировании вычислений, вспоминали о конце масштабирования Деннарда в конце 2000-х годов, а также конец классического закона Мура, когда темп уменьшения стоимости транзистора снизился к концу 2010-х годов. Несмотря на это, вычислительные возможности продолжали улучшаться быстрыми темпами, при этом эстафета была передана другим технологиям, таким как Advanced Packaging, 3D-stacking, новые типы транзисторов и специализированные архитектуры, такие как GPU.

Когда дело доходит до искусственного интеллекта и глубокого обучения, скорость роста вычислительных возможностей графического процессора опережает закон Мура, обеспечивая из года в год увеличение производительности в соответствии с «Законом Хуанга». Технология, которая является основным стимулом этого улучшения — это тензорные ядра.
Хотя тензорные ядра, несомненно, является базой, на которой построен фундамент современного искусственного интеллекта и машинного обучения, они не очень хорошо изучены даже многими опытными специалистами в этой области. Быстрая эволюция архитектуры графического процессора и моделей программирования, которые работают на этой архитектуре, означает, что исследователям и ученым машинного обучения становится все сложнее идти в ногу с последними изменениями в тензорных ядрах и понимать способы применения этих изменений.

В этой статье мы представим ключевые характеристики популярных графических процессоров для дата-центров, и начнём с основных принципов проектирования, направленного на извлечение производительности (performance engineering). Затем мы рассмотрим эволюцию архитектур и моделей программирования Tensor Core от Nvidia, укажем на причины этих изменений. Наша конечная цель — предоставить ресурс для понимания архитектуры графических процессоров Nvidia и предоставить интуитивное понимание их архитектурных улучшений. Только после объяснения каждой архитектуры мы сможем объяснить красоту тензорного ядра Blackwell и его новую иерархию памяти.
Важно отметить, что уверенное понимание компьютерной архитектуры является обязательной для понимания многих пунктов и обсуждений в этой статье. В этой статье предоставлен краткий раздел о программировании CUDA, скорее как напоминание, а не объяснение основополагающих концепций архитектуры графических процессоров. Вместо этого мы будем уделять максимум внимания на новые изыскания о тензорных ядрах, расширяя понимание этой передовой технологии, документируя то, что в настоящее время является знанием только узкого круга лиц, в доступное, структурированное и подробное объяснение.
Подобно тому, как в университете преподают 101 курс, а также курсы 4000 уровней, различные статьи на SemiAnalysis будут рассчитаны на разные уровни понимания предмета, а также на читателей с разными профессиями и специализациями.
Мы хотели бы поблагодарить наших помощников:
· Jay Shah, Colfax Research: Terrific CUTLASS tutorials and numerous meetings meticulously checking the technical details
· Ben Spector, Stanford Hazy Research: Offered great insights into programming model change and writing advice
· Tri Dao, Princeton and Together AI: Reviewed drafts and gave detailed feedback
· Neil Movva, Together AI: Reviewed drafts and offered insights into GPU kernel writing
· Charles Frye, Modal: Pedagogical GPU Glossary and general review of the draft
· Simon Guo, Stanford PhD student: Illustrated the cover picture and reviewed the draft
NVIDIA: Общий контекст вокруг прогресса дизайнов Tensor Core. Команды включают в себя:
· Ian Buck, Inventor of CUDA
· Jonah Alben, Head of GPU Architecture and Engineering
· Many other GPU wizards
Основные принципы производительности
Закон Амдала
Для фиксированного размера задачи, закон Амдала определяет максимальное ускорение, которое можно получить путем распараллеливания с большим количеством вычислительных ресурсов. Если быть точнее, масштабирование вычислительных ресурсов снижает только время выполнения параллельной части, поэтому улучшение производительности ограничено последовательной частью. Чтобы количественно оценить это, максимальное улучшение производительности составляет:

где S — время выполнения параллельной работы, а p — ускорение параллелизуемой работы. В идеальном мире, где параллельная часть идеально распараллелена, ускорение p может быть числом процессорных единиц.
Сильное и слабое масштабирование
Сильное и слабое масштабирование описывает повышение производительности масштабирования вычислительных ресурсов для различных задач. Сильное масштабирование относится к масштабированию вычислительных ресурсов для ускорения решения задачи фиксированного размера, и закон Амдала количественно определяет ускорение сильного масштабирования. С другой стороны, слабое масштабирование относится к масштабированию вычислительных ресурсов для решения более крупных задач за то же время. Например, обработка в 4 раза большего изображения за то же время, используя в 4 раза больше вычислительных ресурсов. Мы рекомендуем этот пост в блоге для более подробных объяснений.

Сильное и слабое масштабирование подразумевает различные улучшения производительности в разных задачах. Сильное масштабирование обеспечивает ускорение для любых размеров задач, в то время как слабое масштабирование гарантирует улучшение производительности только тогда, когда мы используем больше вычислительной мощности для решения задачи большего размера.

Перемещение данных — это главный недостаток
Перемещение данных является недостатком, потому что с точки зрения времени выполнения и масштабирования, вычисления — дешевы, а перемещение данных - дорого. Перемещение данных в основном медленнее, потому что современные ячейки DRAM работают в течение десятков наносекунд, в то время как транзисторы переключаются со скоростью, значительной меньшей 1 наносекунды. Что касается масштабирования, в то время как увеличение скорости вычислений замедлилось с 2000-х годов, скорость памяти развивалась еще медленнее, создавая memory wall эффект.
Эволюция архитектуры Тензорных ядер
Обзор поколений Тензорных ядер
В этом разделе мы представляем основные архитектуры графических процессоров Nvidia, которые используют Тензорные ядра, а именно Tesla V100, A100, H100, а также Blackwell. Мы также включили раздел Pre-Tensor Core для повторения модели программирования CUDA. Мы кратко рассмотрим основные функции и изменения, которые имеют отношение к пониманию тензорных ядер, и мы укажем ссылки на другие источники с большими подробностями, указанные в каждом подразделе.
Pre-Tensor Core
Модель программирования PTX
Parallel Thread Execution (PTX) — это виртуальный набор инструкций, который абстрагируется от поколений графического процессора. Программа PTX описывает kernel функцию, которая выполняется на большом количестве трэдов GPU, которые выполняются на execution блоках графического процессора, т.е. ядрах CUDA. Нити (thread, трэд) образуют грид (grid), а грид состоит из совместных трэдовых массивов (CTA - cooperativethread arrays). PTX трэды могут обращаться к различным пространствам памяти, которые являются областями хранения данных с различными характеристиками. В частности, каждая нить имеет выделенные регистры, нити в CTA имеют общую память (SMEM - shared memory), и все нити могут получить доступ к глобальной памяти (GMEM - global memory). Для получения дополнительной информации, ознакомьтесь с этим разделомдокументации CUDA.

Машинная модель PTX
Архитектура GPU построена вокруг массива потоковых мультипроцессоров (SM – streaming multiprocessor). SM состоит из ядер скалярной обработки, многопоточный блок инструкций и общей памяти (Shared Memory). SMотображает каждую нить на ядро скалярной обработки (также известное как CUDA-ядро), а многопоточный блок инструкций управляет нитями в группах из 32 параллельных нитей, называемых варпами (warp).
Во время выдачи инструкций, блок инструкций выбирает варп и выдает инструкцию тредам соответствующего варпа. Этот способ выполнения называется SIMT – single instruction multiple thread (одна инструкция несколько нитей). Подобно SIMD – single instruction multiple data (одна инструкция несколько данных), SIMT управляет несколькими элементами обработки с помощью одной инструкции, но в отличие от SIMD, SIMT указывает поведение одной нити вместо всего вектора. Для получения дополнительной информации, пожалуйста, ознакомьтесь с этим разделом документации CUDA.

Streaming Assembler
Streaming Assembler (SASS) — это набор инструкций, специфичный для архитектуры, который генерируется из абстрактного PTX-кода. Дополнительную информацию см. CUDA binary utilities documentation. К сожалению, SASS плохо задокументирован из-за того, что NVIDIA скрывает детали своей архитектуры ISA от своих конкурентов.
Volta
Почему NVIDIA добавила Тензорные ядра
По мере того, как глубокое обучение стало более распространённым, в отрасли заметили, что рабочие нагрузки машинного обучения нуждаются в аппаратном ускорении. В начале 2015 года Google развернул TPUv1 для ускорения своих внутренних рабочих нагрузок ML, а в 2017 году Nvidia представила специальное оборудование для матричной математики. Хотя графические процессоры потребляют небольшое количество энергии при выдаче (issue) инструкций (~30pJ) из-за их простого аппаратного конвейера, базовые операции с плавающей запятой, такие как HFMA (16-битное fused multiply add), потребляют еще меньше энергии (~1,5pJ). Это создает 20-кратные накладные расходы, необходимые для инструкций, по сравнению с самой операцией с плавающей запятой. В результате выполнение большого количества операций с плавающей запятой для умножения матрицы неэффективно. Чтобы амортизировать накладные расходы на инструкции, нам нужно использовать сложные инструкции, которые могут выполнять больше вычислений за инструкцию. С этой целью Nvidia разработала инструкцию по умножению и накоплению матрицы с половинной точностью (HMMA), специализированную инструкцию, которая выполняет умножение матриц половинной точности. Соответствующим специализированным блоком для выполнения этой инструкции является Tensor Core (тензорное ядро), представленное в графическом процессоре Tesla V100 архитектуры Volta в 2017 году. Тензорное ядро Volta было добавлено очень поздно в разработку архитектуры Volta, всего за несколько месяцев до тейпаута, что является свидетельством того, как быстро Nvidia может вносить изменения свою архитектуру.

Обзор инструкции MMA
Инструкция умножения и накопления (ММА) вычисляет D = A * B + C:
· A — это матрица размера M на K
· B — это матрица размера K на N
· C и D — это матрицы размера M на N
Мы обозначаем размеры матриц как mMnNkK или MxNxK.
Чтобы выполнить полное вычисление, мы сначала загружаем матрицы A, B и C из SMEM в трэдовые регистры, так, что каждый трэд содержит фрагмент матрицы. Далее, мы выполняем инструкцию MMA, которая считывает матрицы из регистров, выполняет вычисления на тензорных ядрах и сохраняет результат в трэдовые регистрах. Наконец, мы выгружаем результаты из регистров обратно в SMEM. Полный расчет выполняется несколькими нитями, что означает, что каждый шаг требует синхронизации между всеми участвующими в исполнении нитями.

Тензорное ядро 1-го поколения
SM графического процессора Tesla V100 содержит 8 ядер Tensor, сгруппированных в по два в каждой PU(Processing unit). Каждое тензорное ядро способно выполнять матричное умножение 4x4x4 за цикл, что составляет 1024 FLOPs за цикл на SM.

NVIDIA настроила PTX mma, так чтобы она дробилась на несколько инструкций HMMA более низкого уровня. В архитектуре Volta инструкция MMA выполняет умножение матрицы 8x8x4, и квадро-пара из суммарно 8 нитей участвует в каждой операции, вместе храня входные и выходные матрицы. Здесь T0 относится к нити 0, [T0, T1, T2, T3] и [T16, T17, T18, T19] являются группами нитей, а 2 группы нитей образуют квадро-пару.

Volta Tensor Cores поддерживают входные значения FP16 с накопителем FP32 в соответствии с методом обучения смешанной точности NVIDIA. Этот метод показал, что можно обучать моделей с меньшей точностью без потери качества модели.
Чтобы полностью понять строение MMA, обратитесь к статье Citadel по микробенчмаркингу «Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking». Чтобы увидеть переплетенную схему расположения трэдов для Volta Tensor Core MMA, прочитайте слайды Programming Tensor Cores: Native Tensor Cores with CUTLASS. Для получения дополнительной информации об архитектуре Volta, пожалуйста, обратитесь к техническому документу NVIDIA Tesla V100 GPU Architecture.
Turing
Архитектура Turing получила Тензорные ядра 2-го поколения, улучшенную версию Volta Tensor Cores, добавив поддержку INT8 и INT4. Они поддерживают новую синхронную MMA на уровне варпа, которую мы обсудим в следующем разделе. Эти ядра позволили внедрить Deep Learning Super Sampling (DLSS), что ознаменовало начало применения NVIDIA глубокого обучения в игровой графике. Заинтересованные читатели могут обратиться к сообщению в блоге NVIDIA NVIDIA Turing Architecture In-Depth и техническом документе по архитектуре Turing.
Ampere
Asynchronous Data Copy
В поколении Ampere NVIDIA представила асинхронное копирование данных, способ загрузки данных непосредственно из глобальной памяти в общую память без явной синхронизации. Чтобы загрузить данные из глобальной памяти в общую память на Volta, трэды сначала должны загрузить данные из глобальной памяти в регистровый файл, а затем сохранить их в shared memory. Однако, инструкции MMA требуют много памяти и одновременно с операциями загрузки данных нагружают регистровый файл, что вызывает высокое давление на регистры и забивает шину доступа к регистровому файлу и из него.
Асинхронное копирование данных решает эту проблему путем получения данных из глобальной памяти (DRAM) и непосредственно загружая их в общую память (с опциональным доступом к L1), освобождая больше регистров для инструкций MMA. Загрузка и вычисления данных могут происходить асинхронно, что сложнее с точки зрения модели программирования, но открывает более высокую производительность.
Эта функция реализована как PTX-инструкция на уровне нити cp.async (документация). Соответствующей SASS инструкцией является LDGSTS – асинхронное копирование из глобальной памяти в общую. Точные методы синхронизации — это механизмы завершения на основе асинхронных групп и mbarrier, подробно описанные здесь.

Тензорное ядро 3-го поколения — синхронное MMA на уровне варпа
Ampere имеет 4 тензорных ядра на каждой SM, и каждое ядро способно выполнять 512 FLOPs за цикл, что составляет 2048 FLOPs за цикл на SM, что в два раза выше, чем производительность Volta.
В то время как Volta требует квадро-пару из 8 нитей для участия в операции MMA, Ampere требует полный варп из 32 нитей. То, что теперь MMA это варповая операция – упрощает расположение операндов по трэдам и снижает нагрузку на регистровый файл. Вот пример трэдов и данных для смешанной точности с плавающей точкой формы 16x8x16:

NVIDIA представила ldmatrix в Ampere — улучшенную операцию векторной загрузки операндов. Как и mma, ldmatrix- варповая операция, что означает, что целый варп сразу загружает матрицу. Это позволяет не использовать несколько инструкций загрузки операндов, что снижает загрузку регистрового файла. Для получения дополнительной информации см. документацию CUDA.
Ldmatrix загружает данные в регистры по шаблону расположения элементов, который соответствует расположению данных тензорного ядра. По сравнению с перемешанным расположением в Volta (смотритеProgramming Tensor Cores: Native Tensor Cores with CUTLASS), более простое расположение трэдов и данных значительно улучшает эргономику программирования. Посмотрите выступление GTC Developing CUDA Kernels to Push Tensor Cores to the Absolute Limit on NVIDIA A100, чтобы узнать больше о том, как именно загрузка памяти Ampere согласуется с тензорным ядром.
Ampere MMA получил новый формат с плавающей точкой (BF16), который стал стандартом для типов данных с половинной точностью. BF16 обеспечивает ту же 8-битную экспоненту, что и FP32, но с 7-битной мантиссой, что даёт диапазон уровня FP32 потребляя вдвое меньше места. BF16 также устраняет необходимость в функции масштабирования потерь при обучении со смешанной точностью.
Hopper
Кластер блоков нитей
По мере увеличения количества SM разница в размерах между SM и всем графическим процессором увеличивалось. Чтобы дать возможность более тонкого управления между CTA (маппинг их по SM) и grid(маппинг на весь графический процессор), на Hopper NVIDIA добавила новый уровень иерархии нитей — кластер нитей, который мапится на группу SM, физически расположенных в том же кластере графической обработки (GPC). Кластер блоков нитей также называется кооперативным грид массивом (CGA) и называется кластером в документации CUDA (см. здесь для получения дополнительной информации).
CTA в кластере блока нитей гарантированно будут совместно запланированы на SM в том же GPC и распределены по одному CTA на SM по умолчанию. Разделы общей памяти этих SM образуют распределенную общую память (DSMEM). Любая нить может получить доступ к общей памяти из другого SM с низкой задержкой по выделенному каналу SM-to-SM (без прохода через кэш L2). Добавление аппаратного блока GPC в модель программирования дал программистам возможность уменьшить объём обмена данных и улучшить локальность данных.

Ускоритель тензорной памяти
Для повышения эффективности извлечения данных NVIDIA добавила Tensor Memory Accelerator (TMA) к каждому SM в поколении Hopper. TMA — это специальное аппаратное устройство, которое ускоряет асинхронную передачу больших объемов данных между глобальной и общей памятью (bulk asynchronous copy).
Одна нить в CTA может инициировать операцию копирования TMA. TMA освобождает нити для выполнения другой независимой нагрузки, например, для работы с адресами, и давая дополнительные преимущества, такие как обработка выхода за пределы массива. В PTX соответствующая инструкция iscpcp.async.bulk, подробно описанная в этом разделе документации CUDA.
Однако для небольших запросов нагрузки TMA имеют более высокую задержку, чем обычное асинхронное копирование данных из-за накладных расходов на обработку адресов. Поэтому NVIDIA рекомендует программистам использовать TMA для больших копий данных для уменьшения накладных расходов. Например, в инференсе LLM TMA не подходит для рабочих нагрузок, которые загружают KV-кэш малыми фрагментами, но хорошо работает, когда каждый фрагмент кратен 16 байтам. Более конкретные примеры этого см. в разделеSGLang prefix caching, статью FlashInfer секцию 3.2.1, статью Hardware-Efficient Attention for Fast Decoding section 4.2, и ThunderKittens MLA decode.
TMA также поддерживает режим загрузки данных, называемый многоадресной рассылкой, при котором TMA загружает данные из глобальной памяти в общую память нескольких SM внутри одного кластера блоков нитей, заданных многоадресной маской. Вместо того, чтобы выдавать несколько загрузок из глобальной памяти, загружая один и тот же фрагмент данных несколько раз несколько SM, многоадресная рассылка завершает ее за одну загрузку. В частности, несколько CTA в кластере блоков нитей загружают часть данных в соответствующие SMEM и обмениваются данными через DSMEM. Это уменьшает трафик кэша L2 и впоследствии уменьшает трафик HBM. Мы рекомендуем прочитать учебник Jay Shah’s TMA tutorial для получения более подробной информации.

Тензорное ядро 4-го поколения — асинхронное MMA на уровне группы варпов
NVIDIA представила новый тип MMA с Hopper, warpgroup-level MMA (wgmma). wgmma является инструкцией группы варпов, что означает, что группа из 4 варпов совместно выполняет операцию MMA. wgmma поддерживает более широкий диапазон форм. Например, MMA со смешанной точностью поддерживает m64nNk16, где N может быть кратным 8 — от 8 до 256. wgmma.mma_async образует новый набор SASS инструкций: GMMA. В другом примере, инструкции wgmma с половинной точностью образует HGMMA. См. этот раздел документации CUDA для получения подробной информации о формах и типах данных MMA.
В то время как все нити в варпгруппе коллективно удерживают выходную матрицу на своих регистрах, тензорные ядра Hopper могут напрямую загружать операнды из общей памяти вместо регистров, экономя место в регистровом файле и его пропускную способность. В частности, матрица операнда A может находиться либо в регистрах, либо в общей памяти, в то время как матрица операнда B доступна только через общую память. См. раздел документации CUDA wgmma для получения подробной информации о механизме завершения wgmma, макете SMEM и многом другом.

Для типов данных wgmma Hopper представил 8-битные типы данных с плавающей запятой (E4M3 и E5M2) с накопителем FP32. На практике накопитель был реализован в виде внутреннего 22-битного формата с фиксированной точкой (13-битной мантиссы, бит знака и 8 бит экспоненты), ограничивая диапазон по сравнению с истинным 32-битным накоплением. Из-за пониженной точности тензорного ядра каждое N_c накопление должно происходить в ядре CUDA, чтобы предотвратить ограничение точности при обучении. (См. раздел 3.3.2 этого документа). Это снижение точности повышает эффективность, но происходит за счет точности.
Для получения дополнительной информации об архитектуре Hopper см. следующее:
· GTC talk: Inside the NVIDIA Hopper Architecture
· NVIDIA blog post overview: NVIDIA Hopper Architecture In-Depth
· Whitepaper: NVIDIA H100 Tensor Core GPU Architecture
· Microbenchmarking: Benchmarking and Dissecting the Nvidia Hopper GPU Architecture
· Microbenchmarking: Dissecting the NVIDIA Hopper Architecture through Microbenchmarking and Multiple Level Analysis
Для примеров программирования Hopper GPU, смотрите:
· GTC talk: Optimizing Applications for Hopper Architecture
· CUTLASS talk: Developing Optimal CUDA Kernels on Hopper Tensor Cores
· Colfax blog post: CUTLASS Tutorial: Fast Matrix-Multiplication with WGMMA on NVIDIA Hopper GPUs
Blackwell
Tensor Memory
Высокая нагрузка на регистровый файл не закончилась на Hopper, что спровоцировало создание TensorMemory (TMEM), новый блок памяти, специализированный для операций тензорных ядер. На каждой SM - TMEM имеет 128 строк и 512 столбцов по 4 байта в каждой ячейке, общей площадью 256 КБ, что равно суммарному размеру регистровых файлов на SM.
TMEM имеет определённый шаблон доступа к памяти. Для доступа ко всей TMEM требуется группа варпов, и каждый варп в группе может получить доступ только к своему набору строк. Ограничивая схему доступа к памяти, можно уменьшить количество портов доступа, что экономит место на кристалле. С другой стороны, эта также означает, что для работы эпилога требуется группа варпов. В отличие от SMEM, программисты должны явно управлять TMEM, включая аллокацию, деаллокацию и копирование данных в память и из неё.

CTA пара
Два CTA в кластере блоков образуют пару CTA, если их ранги CTA в кластере блоков нитей отличаются последним битом, например, 0 и 1, 4 и 5. Пара CTA размещается на один TPC, который состоит из двух SM и образует с другими TPC — GPC. Когда тензорные операции Blackwell выполняются над парой CTA, то CTA могут совместно делить входные операнды. Это снижает как загруженность SMEM, так и требования к пропускной способности.
Tensor Core ММА 5-го поколения
Инструкция MMA 5-го поколения (tcgen05.mma в PTX) полностью отошла от использования регистров для хранения матриц. Операнды теперь находятся в SMEM и TMEM.
Предположим, что MMA вычисляет D = A * B + D: Отказ от использования регистрового файла убирает сложные шаблоны хранения данных и освобождает место для других операций, таких как эпилоги. В отличие от wgmma, использующей warpgroup для инициирования операции MMA, tcgen05.mma имеет семантику одной нити, что означает, что одна нить инициирует операцию MMA. Это убирает роль варпа в исполнении MMA.

Одним из интересных вариантов MMA является MMA.2SM, который использует 2 SM для коллективного выполнения операции MMA. MMA.2SM выполняется на уровне пары CTA, и поскольку tcgen05.mma имеет семантику одной нити, одна нить в ведущем CTA из этой пары запускает MMA.2SM. Здесь показана схема расположения данных A. Здесь видно что в MMA.2SM размер M матриц удвоен по сравнению с версией на одной SM (пример D), поэтому две SM загружают разные сегменты матрицы A и D. Кроме того, MMA.2SM разделяет матрицу B между SM, что вдвое уменьшает объем загружемых данных.

Матрица B является общей для двух SM, что означает, что сегменты B0 и B1 должны передаваться через DSMEM. DSMEM и SMEM обладают разной пропускной способностью, но влияние на согласование оказывается минимальным, потому что мы загружаем малые по объёмам сегменты. Тем не менее, мы подозреваем, что на Blackwell пропускная способность между SM в TPC выше, чем у DSMEM, поэтому MMA.2SM использует это для достижения максимальной производительности.
Тензорные ядра 5-го поколения также могут выполнять свертки в дополнение к стандартному перемножению матриц. tcgen05.mma поддерживает константные веса благодаря буферу, который кэширует матрицу B для повторного использования. Для получения дополнительной информации, пожалуйста, обратитесь к документации CUDA и соответствующей инструкции по ММА с константными весами.
Что касается поддерживаемых типов данных, Blackwell поддерживает форматы плавающей запятой (MXFP), включая MXFP8, MXFP6 и MXFP4. Подробности см. в этом документе. Blackwell также поддерживает свой собственный формат NVIDIA NVFP4, который более точен, чем MXFP4. Вероятно, это связано с меньшим размером блока, различным форматом масштабирования и двухуровневым методом квантования (см. подробнее на GitHub). См. эту статью для сравнения форматов данных.
В Blackwell, поскольку FP8 и FP6 имеют одинаковую теоретическую пропускную способность, мы считаем, что они исполняются на одних и тех же блоках. Напротив, CDNA4 имеет пропускную способность FP6 в 2 раза выше в сравнении с FP8, потому что FP6 переиспользуют логику с FP4. Мы считаем, что UDNA вместо этого FP6 будет использовать логику FP8.
Примечание: Structured Sparsity
В Ampere добавили поддержку разреженных матриц 2:4, которая теоретически удвоила пропускную способность тензорных ядер. Это достигается путем зануления элементов весовой матрицы таким образом, что на каждые 4 элемента 2 из них равны нулю. Таким образом матрица сжимается путем удаления нулевых элементов, а дополнительная матрица индексов запоминает их положения, это вдвое сокращает использование памяти и нагрузку объём передаваемых данных.
Согласно этой статье о микробенчмаркинге китайских инженеров, sparsity может дать двухкратное ускорение для ММА для матриц большого размера на уровне инструкций. Это также показывает, что в Hopper инструкции со sparsity wgmma могут достигать двухкратного ускорения и экономить вдвое пропускную способность памяти для загрузки весов.
К сожалению, ядра GEMM с разреженными матрицами 2:4 не могут достичь двухкратного ускорения по сравнению с их плотными аналогами на Hopper. Это связано с трудностями в прунинге при условии сохранения точности модели, неоптимизированными ядрами cuSPARSELt и ограничениями TDP. За исключением китайских лабораторий искусственного интеллекта и ограниченного количества экспериментальных западных исследовательских работ, большинство лабораторий искусственного интеллекта игнорируют разреженные 2:4 матрицы для инференса и сосредоточены на квантовании и дистилляции. Мета(запрещена в России) экспериментирует с этим в Llama, но во многих случаях это также тупиковое направление.
Кроме того, отсутствуют закрытые или открытые модели, которые показали улучшение производительности с разреженностью 2:4 FP8 или 4:8 для FP4 при сохранении нулевой потери точности и общего отсутствия ресурсов, предназначенных для прунинга. Мы советуем NVIDIA прекратить использовать «Математику Хуанга» и хитрые цифры FLOPs при разреженных матрицах в своих выступлениях и маркетинговых материалах, пока они не начнут стабильно показывать, что открытые модели SOTA могут воспользоваться преимуществами разреженности для инференса. Хорошим первым шагом было бы сделать поддержку разреженности в DeepSeek, а также показать, что производительность может складываться с другими техниками, такими как дистилляция и квантование NVFP4.

В тензорных ядрах пятого поколения NVIDIA представила sparsity 4:8 для NVFP4. В этой схеме каждые восемь элементов сгруппированы в четыре пары, и ровно две из них должны содержать ненулевые значения, в то время как оставшиеся две обрезаются. Поскольку NVFP4 является суббайтовым типом данных, мы считаем, что это ограничение побудило NVIDIA воспользоваться шаблоном 4:8. Хотя разрежённость 4:8 и может показаться более свободным форматом, чем прошлый 2:4, однако так как работа идёт с парами элементов, а не с каждым элементов индивидуально, то на практике это не является более смягченным форматом для инженеров, которые стремятся сохранить точность модели при урезании значений.

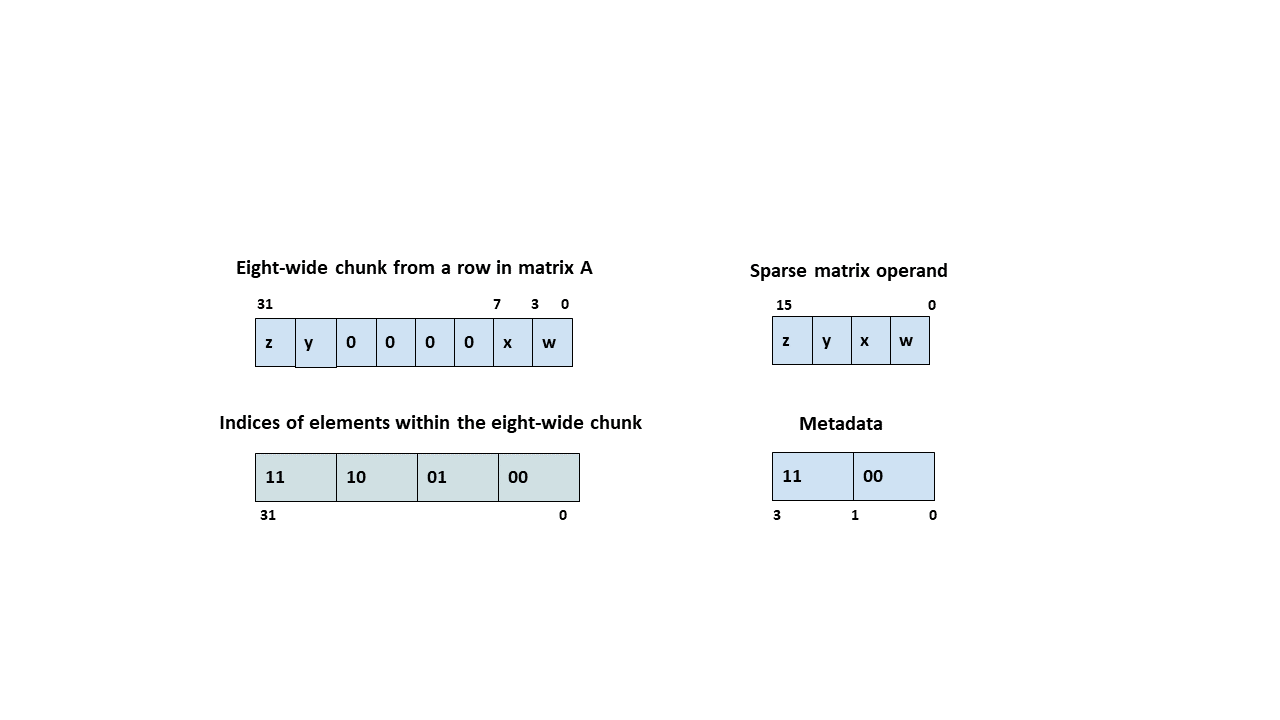{kind=link}
Tensor Core Size Increases

На протяжении поколений NVIDIA масштабировала размер тензорных ядер более агрессивно, чем их количество. NVIDIA предпочла масштабирование размера тензорного ядра, а не количества ядер, потому что это лучше способствует характеристикам производительности матричного умножения. В частности, при масштабировании размера задачи вычисление умножения матрицы увеличивается кубически, но движение данных растет квадратично, что означает, что арифметическая интенсивность растет линейно. O(n) арифметическая интенсивность в сочетании с тем фактом, что перемещение данных дороже, чем вычисления, стимулировало увеличение размера тензорного ядра.

Тем не менее, как масштабирование размера ядра, так и количества ядер несут за собой негативный эффект квантования. В частности, наличие большого количества ядер страдает от эффекта квантования плитки (tilequantization effect), а наличие большого размера ядра приводит к эффекту волн квантования (wave quantizationeffect). Эффект волны квантования возникает, когда количество задач не полностью делится на количество блоков, исполняющих эту задачу, что приводит к падению утилизации при обработке последней, меньшей единицы работы. Увеличение размера тензорного ядра, по сути, увеличивает размер рабочей единицы, что приводит к низкой утилизации на матрицах малого размера (см. этот пост в блоге ThunderKittens).

Линейный рост арифметической плотности также стимулирует увеличение формата ММА. Наличие более крупных форм ММА повышает степень совместного использования операндов. В частности, запуск меньшего количества больших по размеру матриц увеличит повторное переиспользование данных, что экономит потребляемую памяти и пропускную способность RF и SMEM. Для архитектур до Blackwell это привело к постепенному увеличению количества нитей для общего выполнения операции MMA, от 8 нитей (Volta) до варпа из 32 нитей (Ampere), а затем группа варпов из 128 нитей (Hopper).
Увеличение размера памяти

Общая память увеличивалась почти с каждым поколением, в то время как размер регистрового файла оставался неизменным. Причина этого заключается в том, что увеличение пропускной способность тензорного ядра требует более объёмного промежуточного буфера.
Поскольку тензорные ядра потребляют данные гораздо быстрее, чем глобальная память может загружать их, мы используем промежуточную память для буферизации данных, поэтому загрузка данных из памяти может выполняться до исполнения операции MMA. Пропускная способность тензорных ядер удваивалась с каждым поколением, но задержка загрузки из глобальной памяти не уменьшалась, а фактически увеличивалась. В результате нам потребовалось увеличить размер промежуточного буфера для большего количества данных. Для реализации этого NVIDIA выбрала общую память в качестве промежуточной памяти для тензорных ядер, что объясняет, почему shared память увеличилась, а размер регистрового файла оставался постоянным.
Тем не менее, размер общей памяти Blackwell не увеличился по сравнению с Hopper. Это связано с тем, что tcgen05 MMA может использовать 2 SM, поэтому shared память каждого SM должна загружать только половину операндов. Таким образом, размер общей памяти Blackwell фактически удвоился.
Выбор промежуточной памяти NVIDIA также объясняет, почему расположение операндов постепенно перемещалось из регистрового файла в общую память. Тем не менее, NVIDIA добавила TMEM на Blackwell для поддержки увеличенной пропускной способности тензорного ядра. Поскольку TMEM расположен ближе к ним, он может быть более энергоэффективным. Кроме того, наличие отдельной памяти увеличивает общую пропускную способность памяти для насыщения тензорных ядер.
В отличии от остальных операндов матрица D всегда хранится в TMEM. Мы можем пользоваться энергоэффективностью TMEM, так как к матрице D чаще обращения, чем к матрицам A и B. Например, чтобы вычислить подматрицу в наивном умножении матрицы, обращений к матрице D было 2Kt раз (Kt чтений, Kt записей, где Kt: Количество подматриц вдоль размера K), в то время как обращений к матрице A и B было только один раз.

Асинхронность инструкции MMA

«H» в UTCHMMA, HGMMA, HMMA означает половину точности, так как это 16-битный формат, в то время как «Q» в QGMMA, UTCQMMA означает четверть точности (8 бит), так как 8 бит — это четверть полной точности (32 бита). «O» означает «Octal», что означает одну восьмую из 32 бит, так как UTCOMMA — это FP4.
Инструкции MMA постепенно становились асинхронными на уровне SASS из-за необходимости перекрывать инструкции LDSM.
На уровне SASS операция MMA включает в себя выполнение одной инструкции LDSM для загрузки матриц из shared памяти в регистровый файл, а затем двух инструкций HMMA для выполнения MMA. Во время выполнения две инструкции HMMA выдаются асинхронно и блокируют использование регистра из-за аппаратных блокировок. Поскольку аппаратные блокировки не допускают перекрывающие инструкции LDSM, последовательное выполнение одной инструкций LDSM и двух инструкций HMMA создает небольшой простой в конвейере. Тензорные ядра стали настолько быстрыми, что этот простой вызывает ощутимую потерю производительности, что требует асинхронного механизма завершения для MMA.
Hopper поддерживает асинхронный механизм завершения и барьер для wgmma. Когда выдаются инструкции HGMMA, нет никаких аппаратных блокировок, защищающих использования регистра. Вместо этого компилятор планирует LDSM для следующего MMA и использует инструкцию FENCE, чтобы дождаться инструкции HGMMA. С Blackwell операция MMA полностью асинхронна. Все инструкции по загрузке в Tensor Memory (tcgen05.ld / tcgen05.st / tcgen05.cp) явно асинхронны.

Данные с типами меньшей точности

На протяжении каждого последующего поколения тензорных ядер, NVIDIA продолжает добавлять типы данных с более низкой точностью, начиная от 16-битных до 4-битных. Это связано с тем, что рабочие нагрузки глубокого обучения устойчивы к низкой точности. Это особенно верно для инференса, где можно использовать даже более низкую точность, чем во время обучения. Низкая точность более энергоэффективна, занимает меньше площади на кристалле и обеспечивает более высокую вычислительную пропускную способность. В новых поколениях мы также видим, что NVIDIA удаляет поддержку FP64, чтобы отдавать приоритет типам данных с более низкой точности при ограниченных бюджетах площади кремния и потребления питания.
Интересно, что приоритизация также повлияла на поддержку целочисленных типов данных. После Hopper, типы данных INT4 устарели, и на Blackwell Ultra мы видим более низкую вычислительную мощность INT8. Это вызвано непопулярности низкоточных целочисленных типов данных на данный момент. Хотя Turing поддерживал INT8 и INT4, только 4 года спустя новые методы квантования смогли воспользоваться преимуществами компактности INT4 для инференса для LLM. Но к тому времени NVIDIA уже посчитала INT4 устаревшим в Hopper wgmma.
Далее мы поговорим о том, как развивалась модель программирования, включая переход от высокой заполняемости к одиночной занятости, увеличение явного асинхронного выполнения и о том, как эти проекты связаны с ставками NVIDIA на сильное масштабирование.
Эволюция модели программирования
Сильное масштабирование и занятость одного CTA
Традиционно программисты стремятся к высокой утилизации для достижения высокой производительности на графических процессорах CUDA. Они назначают несколько CTA одному SM (oversubscription), что позволяет SM переключать контекст между CTA, чтобы скрыть задержки, что концептуально очень похоже на hyperthreading. С точки зрения машинной модели PTX, планировщик варпов запустил несколько параллельных варпов в SM, удерживая большое количество активных варпов, т. е. высокую утилизацию.
Загруженность несколькими CTA остается верным подходом программирования для одной инструкции и нескольких нитей (SIMT). Однако NVIDIA перешла к использованию одного CTA для программирования тензорных ядер, потому что они следуют сильному масштабированию для умножения матриц. При программировании умножения матриц мы назначаем один CTA одному вычислению выходной матрицы. Если мы оптимизируем производительность в парадигме высокой загруженности, мы видим улучшения производительности только при запуске большего количества CTA, что происходит, когда мы увеличиваем размер умножаемых матриц. Улучшение производительности при увеличении размера проблемы — это слабое масштабирование. И наоборот, если мы оптимизируем производительность в парадигме занятости одного CTA, мы видим улучшения производительности для всех размеров проблемы, что является сильным масштабированием.
Асинхронное исполнение

Сильное масштабирование диктует необходимость асинхронного выполнения. Из закона Амдала можно сделать вывод, что при умножении матриц, когда мы сокращаем время выполнения MMA, другие операции, например, загрузка данных, будут ограничивать общее улучшение производительности. Асинхронное выполнение работает в обход закона Амдала. Перекрывая операции загрузки данных с MMA, мы можем сократить общее время выполнения операций, не относящихся к MMA, устраняя узкое место.

Одним из примечательных шаблонов программирования асинхронного выполнения является программный конвейер. Здесь мы объясняем на примере ядра CUTLASS GEMM. Мы создаем конвейер из нескольких этапов, включая загрузку данных из глобальной памяти в shared, загрузку данных из shared памяти в регистры и MMA.

Все архитектуры поддерживают программную конвейеризацию. В модели машины PTX несколько варпов выполняются одновременно, и с помощью инструкций по синхронизации барьеров программисты могут реализовать программную конвейеризацию (см. пример здесь). Асинхронное выполнение переключения контекста варпов неявно и не программируется пользователями. Начиная с Ampere, NVIDIA добавляла аппаратную поддержку для асинхронного выполнения, и модель программирования развивалась, чтобы быть более явно асинхронной. Ampere поддерживает асинхронное копирование данных и полноценные барьеры arrive/wait, который CUTLASS использует для явного перекрытия загрузки данных с помощью MMA для приведенного выше примера. Hopper ещё дальше ускоряет асинхронное копирование данных с TMA, асинхронным MMA с базовыми механизмами завершения и улучшенным барьером асинхронных транзакций. Blackwell дополнительно увеличивает асинхронность: инструкции семейства tcgen05 поддерживают механизмы завершения на основе mbarrier с помощью tcgen05.commit (документация). Другие источники
Если читатели хотят изучить основы модели программирования CUDA, оборудования и концепций, GPU Glossary by Modal — отличный ресурс для всего, что было до Blackwell. Чтобы понять основные идеи CUDA, мы рекомендуем все доклады Стивена Джонса GTC (плейлист здесь). Чтобы глубже понять функции памяти, доклад GTC CUDA Techniques to Maximize Memory Bandwidth and Hide Latency объясняет функции памяти Volta, Ampere и Hopper, а Advanced Performance Optimization in CUDA глубоко погружается в модели памяти. Наконец, из ресурсов, специфичных для Blackwell, мы рекомендуем доклад GTC Programming Blackwell Tensor Cores with CUTLASS, статьи Colfax research CUTLASS (последняя версия здесь) и примеры ядра CUTLASS.
Armmaster
вот это фундаментально! Отличная статья, спасибо за перевод