
Приветствуем читателей Хабра! Мы, дата-сайентисты и дата-аналитики компании «ДатаЛаб»* (ГК «Автомакон»), делимся своим опытом решения актуальных проблем, с которыми сталкиваются ML-команды.

Эта статья будет особенно полезна тем, кто хотел бы решить вопрос управления и отслеживания изменений в процессе разработки. Нередки ситуации, когда над одним проектом работает несколько команд. В этом случае важно позаботиться о сохранении истории изменений, чтобы следующие команды разработчиков могли получить информацию о том, что было сделано до них.
Мы подробнее рассмотрим применение такого инструмента, как DVC.
DVC (Data Version Control) – открытый инструмент для управления версиями данных и моделей в проектах машинного обучения. DVC предоставляет средства для отслеживания и управления изменениями в данных, коде и конфигурации моделей, а также обеспечивает воспроизводимость результатов экспериментов.
Версионирование экспериментов в ML: что такое и зачем?
Версионирование экспериментов обеспечивает сохранение истории изменений, позволяя исследователям и разработчикам вернуться к предыдущим состояниям моделей и данных, а также легко переключаться между различными вариантами экспериментов. Это особенно полезно в случаях, когда необходимо проанализировать эффект изменений параметров обучения, протестировать различные архитектуры моделей или сравнить результаты разных подходов. Оно также способствует воспроизводимости результатов. Каждая версия эксперимента содержит информацию о параметрах, коде, используемых данных и других важных факторах, которые позволяют точно воссоздать эксперимент заново. Исследователи и другие заинтересованные стороны могут проверять результаты, повторять эксперименты и проводить сравнительные анализы для проверки стабильности и достоверности полученных результатов.
В best-practices принято декларировать гиперпараметры экспериментов в файлах конфигураций. Это своего рода Dependency Injection – паттерн программирования, который позволяет управлять зависимостями между компонентами приложения. Он представляет собой способ организации кода таким образом, чтобы зависимости внедрялись в компонент извне, а не создавались самим компонентом. Рассмотрим несколько фреймворков, предоставляющий схожий подход:
PyTorch Lightning
PyTorch Lightning – фреймворк для PyTorch, избавляющий разработчика от рутины писать пайплайны для обучения DL-моделей. Команда разработала собственный стандарт для декларирования компонентов экспериментов. Приведем пример из документации проекта:

Catalyst
Catalyst – аналогичный инструмент. Пример с github-репозитория проекта:

Преимущество подхода в том, что для проведения экспериментов практически не нужно писать никакого кода на Python. Все стандарты уже учтены в фреймворке, разработчику остается лишь собрать эксперимент, подобно конструктору.
Несмотря на то, что оба инструмента предоставляют широкий спектр инструментов возможностей для разработчика, все вращается вокруг DL и в частности фреймворка PyTorch. А что делать, если мы хотим использовать другие фреймворки и пользоваться схожими подходами?
DVC
DVC – активно развивающийся продукт с широким набором возможностей. Рекомендуем ознакомиться с достойным курсом от команды DVC по организации экспериментов и пайплайнов для машинного обучения. Также узнаете, какие встречаются проблемы и как их помогает решить DVC. Курс будет полезен как начинающим специалистам — объяснит, что к чему, так и средним специалистам — разложит все по полочкам. Тем, кто не планирует использовать DVC, стоит пройти обучение для изучения best practices.
Далее подробнее расскажем о своем опыте использования данного инструмента и как мы расширили его возможности.
DVC Pipeline Configuration
DVC использует YAML-файлы для декларирования параметров экспериментов. При этом не существует привязанности к каким-либо стандартам. Это может быть любой YAML-файл, а стандарт можно обсудить внутри команды. Можно использовать описанные выше фреймворки и их аналоги в сочетании с DVC, который будет брать версионирование экспериментов на себя.
Рассмотрим пример конфигурирования файла params.yaml в изоляции от сторонних фреймворков:

Здесь объявляются какие-то параметры датасетов, моделей и метрик, которые затем передаются в качестве аргументов в Python для инициализации Python-объектов:

Мы решили применить опыт работы с фреймворками, которые позволяют декларировать сущности внутри файла конфигураций, написав собственный инструмент-обертку над стандартным PyYAML-парсером. Не остановились на этом и пошли дальше декларирования параметров — к декларированию сущностей, описывая инициализацию сущностей непосредственно в файле конфигураций вместе с нужными параметрами:

Чтобы в методе main получить уже готовые к работе сущности:

Таким образом, в код передаются уже инициализированные сущности, с которыми можно работать. При этом ничего не мешает выделить работу с этими компонентами в отдельную сущность и также задекларировать её.
Но есть и другая проблема – если пайплайны содержат много сущностей с множеством гиперпараметров, конфигурации становятся слишком большими. Это решается разделением одного YAML-файла на несколько небольших и добавлением в парсер возможности импорта YAML-файлов:


Так получается, что у нас может быть единый YAML-файл со структурой эксперимента, который импортирует другие YAML-файлы с большими сущностями.
Это может быть полезно в случаях, когда нужно использовать одни и те же сущности в разных файлах конфигураций. Вы можете импортировать сущности, которые лежат в отдельном файле из одного эксперимента в другой. Например, если в какой-то другой конфигурации нам необходимо получить UserKNN-модель, мы можем сделать это двумя способами:
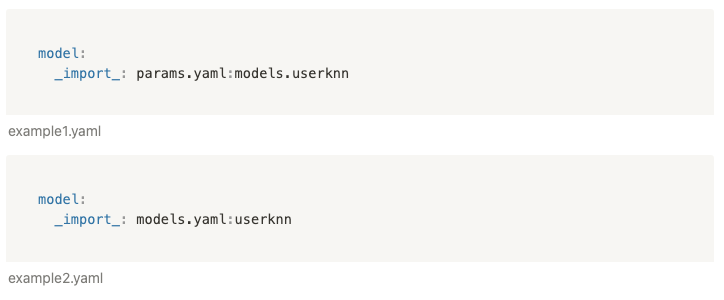
Есть возможность динамически задавать параметры внутри конфигурации, обращаясь к соседним сущностям:

Или другой способ с использованием «частичной инициализации»:

Все сводится к описанию кода сущностей и методов, их единому декларированию в YAML-файлах и переиспользованию в различных местах. Каждый объект системы, что экземпляр модели с заданными параметрами, что датасет — это файл конфигурации.
Задавайте свои вопросы в комментариях или расскажите о вашем опыте в области версионирования экспериментов с использованием DVC. Мы открыты к обсуждению, готовы ответить на ваши вопросы и предложения.
*«ДатаЛаб» — команда профессионалов в области аналитики, больших данных, разработки программного обеспечения, машинного обучения и искусственного интеллекта.