
В серии статей по теме DevOps мы рассказываем о проверенных инструментах выстраивания инфраструктуры, которыми с недавнего времени пользуемся сами. В первой части мы остановились на основных предпосылках внедрения и выбранном подходе. В этой статье вместе с Lead DevOps инженером департамента информационных систем ИТМО Михаилом Рыбкиным рассмотрим подробнее фундамент нашей инфраструктуры — Kubernetes.
Разумеется, статей об этом оркестраторе огромное множество, и можно на протяжении всей карьеры узнавать о нем что-то новое. Сразу уточним — в этой части мы не планируем копать глубоко. Попытаемся дать основы, описать Kubernetes так, чтобы сложилось базовое представление об этом инструменте.
Что такое Kubernertes
Начнем с официального определения, а дальше перескажем его простыми словами. Заходим на сайт kubernetes.io, и первое, что видим, — заголовок:
Production-Grade Container Orchestration
Контейнерная оркестрация промышленного уровня
Разберем по порядку. Что такое контейнеры, вы, вероятно, знаете (если нет – см. docker.io), а дальше идет страшное слово "оркестрация". На входе в DevOps тяжело прочувствовать, что это значит. Понимание приходит, только когда вы сами какое-то время побыли этим самым оркестратором.
Что такое оркестратор на примере сетевого магазина
Предположим, у нас есть сетевой продуктовый магазин. Каждый контейнер — это отдельная точка. Таких точек много: есть в соседнем подъезде, а еще через улицу и в соседнем городе. DevOps — это CEO сетевого магазина, который управляет всеми вопросами.
С точки зрения CEO в нашей ситуации к управлению есть два подхода.
Первый подход — без оркестратора: CEO лично занимается каждым магазином. Находит помещение (мощности), ремонтирует под себя (описывает конфиг контейнера), налаживает доставку товаров (ci/cd процессы), а потом стоит на кассе и пробивает чеки (следит за стабильной работой).
Второй подход — найм кризис-менеджера (установка оркестратора). Между CEO и реальными проблемами появляется прослойка, которой можно делегировать все задачи управления. Теперь наш CEO просто формирует ТЗ, а за реализацию отвечает промежуточный менеджер. Если нужно открыть новую точку в городе N, оркестратор сам найдет подходящие площади (мощности) из выделенного ему пула, развернет на них контейнер, разберется, где взять товар, наймет продавцов.
Фактически, оркестратор, как и кризис-менеджер, дает нам единое окно для решения всех задач, связанных с управлением инфраструктурой. Мы можем прийти с конкретным запросом: что таких-то контейнеров надо развернуть 50 штук, и Kubernetes возьмет на себя вопросы размещения, балансировки, управления доступами, сертификатами — в общем, почти все, что мы раньше делали руками. При этом Kubernetes делит все на понятные уровни абстракции, как бы обещая, что если "под капотом" вся инфраструктура (сервера, настройки) работает, то и все, что развернуто внутри, также будет работать.
Kubernetes имеет смысл внедрять там, где контейнеризованных рабочих нагрузок действительно много. Потому что если у нас сеть из трех магазинов в соседних домах, нет никакой необходимости в развертывании дополнительных отделов менеджеров — мы потратим на них больше денег и времени, чем на решение самих рабочих вопросов. В прошлой статье мы уже об этом говорили, но это важный дисклеймер, который сэкономит вам время, силы и деньги.
Kubernetes — не единственный доступный оркестратор. Но раз уж мы говорим о том, что выбрали для себя, подробнее на аналогах останавливаться не будем. Kubernetes — самый популярный из них, де-факто это стандарт отрасли. На конференциях часто можно услышать фразы о том, что Kubernetes — это новый Linux, поскольку он действительно лег в основу индустрии облачных вычислений, как в свое время нишу серверов захватили дистрибутивы Linux.
Компоненты Kubernetes
Для простоты понимания снова рассмотрим аналогию. Представим, что DevOps-специалист – это водитель, а Kubernetes – его автомобиль. Как и автомобиль, kubernetes можно условно разделить на два набора компонентов – “под капотом” и “в салоне”. Водителю не обязательно глубоко знать устройство двигателя – при возникновении проблем он поедет на СТО, где с этим будут разбираться профессионалы. Тем не менее, ему важно понимать, чем шина отличается от диска. А вот в рычагах управления в салоне водитель должен разбираться хорошо – как и когда переключать передачи, где включается климат-контроль.
В рамках этой статьи мы рассмотрим оба набора, но погружаться глубоко в первый не будем, предполагая, что проблемы с администрированием k8s будут решать системные администраторы или облачный провайдер.
Kubernetes “под капотом”

Эта популярная фраза как бы намекает, что K8S — маленький и простой инструмент. Действительно, он состоит из всего пяти бинарных файлов и пары внешних плагинов. Попробуем в них разобраться:
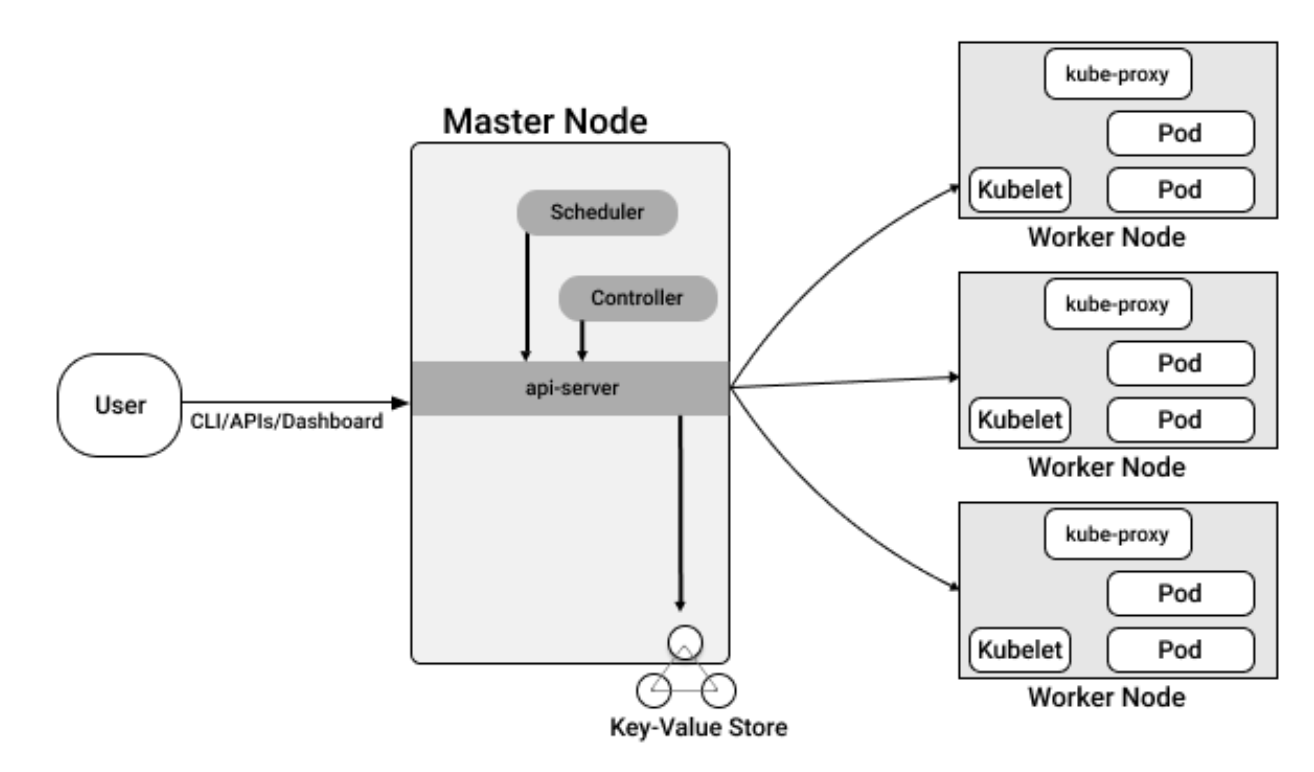
Условно поделим компоненты на две части: master и worker.
Master
Это часть Kubernetes, которая хранит в себе все состояния, управляет командами. Фактически это "голова" кластера Kubernetes.
Master состоит из:
API-server — то самое "единое окно", которое принимает все запросы на управление и распределяет их в нужных направлениях. У Kubernetes есть несколько интерфейсов взаимодействия, и все их команды приходят сюда. Можно направлять запросы непосредственно в API, можно работать через консольную утилиту kubectl, можно использовать удобные дашборды — по итогу все запросы всё равно приходят в API-server.
ETCD — это внешний плагин, key-value хранилище, в котором содержится полная информация о состоянии всего кластера. Для простоты понимания можно сравнить его с Redis, MongoDB или PostgreSQL.
Scheduler — компонент, отвечающий за назначение контейнеров на сервера. Он проверяет, какие есть узлы, сколько на них свободных ресурсов, сколько нужно контейнерам по нашему запросу (и можем ли мы выделить заявленные ресурсы). Scheduler также следит за тем, чтобы соблюдались принципы отказоустойчивости – чтобы одинаковые поды по возможности не разворачивались на одном и том же сервере или на серверах в одной зоне.
Controller Manager — набор контроллеров, которые наблюдают за состоянием кластера и обрабатывают внутренние абстракции K8S (их мы рассмотрим ниже). Это и есть "мозги" кластера.
Worker
Это "рабочие руки" кластера — узлы, на которые распределяется рабочая нагрузка.
Master-ноды в зависимости от настроек также могут быть worker-ами.
На Worker у нас есть следующие компоненты:
Kubelet — агент Kubernetes, который принимает и обрабатывает все запросы на управление подами.
Kube-proxy — небольшой отдельно вынесенный компонент, который обеспечивает сетевую связность в кластере.
Container Runtime — внешний плагин, обеспечивающий запуск контейнеров. kubelet на самом деле взаимодействует не напрямую с контейнером, а именно с Container Runtime, который в свою очередь и запускает контейнер.
Container Runtime могут быть разными, в частности, это может быть и знакомый всем Docker. Выбор конкретного CR обычно зависит от провайдера. В облаке Яндекса, например, используется containerd. Его, кстати, под капотом использует и сам Docker.
Благодаря грамотному разделению компонентов Kubernetes может без усилий управлять тысячами контейнеров на сотнях узлов.
На старте формирования системы к нам как-то поступил вопрос — выдержит ли K8S наши нагрузки. Тогда я наткнулся на issue на гитхабе в репозитории популярного дашборда для Kubernetes

Если упрощать, то схему взаимодействия между компонентами оркестратора можно представить так. Когда мы хотим развернуть в Kubernetes контейнер, то отправляем команду в API сервер, тот взаимодействует с Controller Manager, который дает сигнал в Scheduler. Scheduler определяет, на какой узел должен быть направлен этот контейнер, и далее взаимодействует с Kubelet этого узла, направляя ему команду подъема контейнера. Kubelet транслирует эту команду в Container Runtime, где и разворачивается контейнер.
Доступность настроек компонент зависит от варианта развертывания Kubernetes. В локальном кластере Master-компоненты, очевидно, будут доступны. А вот в случае с managed Kubernetes все это может быть спрятано под капотом сервиса. Например, мы работаем с Яндексом и доступа к Master-узлам у нас нет (в их кластере Master-узлы в целях безопасности находятся в закрытом контуре).
В салоне Kubernetes
Мы рассмотрели, как наша машина едет, теперь пора посмотреть, какие у нас есть рычаги управления. Это и будут наши основные инструменты, поэтому здесь важно во всем хорошо разобраться.
Сущности этого уровня абстракции Kubernetes удобнее разделить на четыре большие категории: workload, config, network и storage.

Workload
В эту категорию мы включили набор абстракций, которые работают непосредственно с контейнерами — полезной нагрузкой, запускаемой в кластере.
Минимальная единица рабочей нагрузки в абстракциях Kubernetes называется Pod — под. Под — это один или несколько контейнеров, которые имеют общие настройки сети и хранилища. Именно поды и составляют основу всех вычислений в Kubernetes, поскольку в них и запускается наша полезная нагрузка. Однако сам по себе под не дает никакой отказоустойчивости и масштабируемости, это просто контейнер(-ы).
Для управления настройками запуска подов есть пять дополнительных абстракций:
ReplicaSet (rs) — контроллер, отвечающий за поддержание заданного количества подов. Он обрабатывает все операции изменения этого количества – отслеживает, сколько работает в каждый момент времени, посылает сигналы на остановку и запуск, перезапускает “упавшие” поды.
DaemonSet (ds) — похожий на replicaset контроллер, но его задача — поддерживать по одному поду на каждом сервере кластера. Пример применения — сервисные поды: сборщики логов, метрик, сервисы, обеспечивающие монтирование к узлам внешних хранилищ. Нам не обязательно вручную направлять их на каждый узел, достаточно будет описать в daemonset целевые сервера и шаблон пода, K8S сделает все остальное за нас.
StatefulSet (ss) — контроллер, отвечающий за работу stateful приложений. По умолчанию наши приложения в кластере запускаются в stateless-режиме — они не хранят никаких данных в файловой системе, и мы можем без потерь перезапустить их в другом кластере. Задача StatefulSet — управлять теми приложениями, которые все-таки должны работать с данными внутри кластера.
Deployment (dp) — этот контроллер управляет процессами обновлений, конфигурируя ReplicaSet’ы. Как правило, значительная часть нагрузки в Kubernetes запускается через deployment. Он хранит историю изменений конфигурации, а также в зависимости от заданных параметров может управлять стратегией развертывания – например, создавать новый rs, поднимая количество реплик, и понемногу снижать кол-во реплик в старом rs, опираясь на статус свежих подов. Таким же образом deployment может управлять процессом отката изменений (rollback).
Job — контроллер, который запускает поды по триггеру. Это может быть как запуск по расписанию (за него отвечает отдельный контроллер CronJob), так и по событию (например, при деплое).

Config
Абстракции блока config предназначены для конфигурации запускаемого софта.
Для начала разберем два основных объекта этой категории:
ConfigMap — хранит конфиги в открытом виде – например, сюда можно положить nginx.conf или переменные окружения DEBUG или ENVIRONMENT. В общем, любые несекретные данные.
Secret — хранит секреты. Здесь хорошо хранить доступы к БД, API-ключи.
Эти абстракции очень похожи друг на друга — обе хранят текстовые данные в key-value формате. Несмотря на это важно понимать, что есть большая разница в назначении и связанном с этим функционале. Например, можно подключить сторонний драйвер секретов и синхронизировать их с внешними хранилищами, такими как hashicorp vault.
Примером применения абстракций блока config будет необходимость работы с одним контейнером в нескольких окружениях — develop, staging и production. При этом конфигурация деплоймента может быть одинаковой, а изменяться между окружениями будет только содержимое секретов/конфигмапов.
Поды могут работать с этим объектами несколькими способами — ключи можно монтировать в контейнер как переменные окружения или как файлы в нужную директорию.
Также в этот блок можно отнести еще три абстракции, с которыми вы, скорее всего, на первых этапах не столкнетесь. О них просто полезно знать:
Pod Disruption Budget (PDB) — конфигурирует доступные опции автоматических остановок подов при технических работах. Например, если количество реплик деплоймента 1 и в PDB задано minAvailable=1, единственный работающий под при обновлении кластера или переконфигурировании узла остановлен в автоматическом режиме не будет. При этом, если replicas=2 и minAvailable=1, Kubernetes самостоятельно сначала перенесет один под (второй будет работать), удостоверится, что он поднялся, а затем перенесет второй (т. е. одномоментно всегда будет работать один под, что удовлетворяет условию minAvailable=1)
Limit Range и Resource Quota — две абстракции, управляющие ограничениями на уровне Namespace. Они позволяют задавать лимиты на весь ns как на физические ресурсы (например, подам внутри ns нельзя потреблять больше 4 ядер и 4 ГБ ОЗУ), так и на объекты (например, в этом ns не может быть больше 10 подов или 15 сервисов). Также с помощью этих абстракций можно задавать настройки по умолчанию для объектов внутри ns.
Horizontal Pod Autoscaler (HPA) — компонент, позволяющий организовать автоматическое горизонтальное масштабирование подов. В нем можно задать селектор целевых подов, а также пиковые значения нагрузки, после превышения которых нужно запускать дополнительные реплики. Например, если потребление ОЗУ больше 70% от заданных лимитов, HPA запустит дополнительный под, который подключится в балансировку и примет часть нагрузки на себя.
Важно отметить, что, помимо горизонтального масштабирования, в K8S можно реализовать и вертикальное — в случае достижения условий поду будут "подниматься" лимиты доступных ресурсов. Однако, в отличие от HPA, который по умолчанию присутствует в любом кластере, для реализации вертикального масштабирования нужно установить сторонний компонент — vertical pod autoscaler.
Network
Абстракции этой категории отвечают за сетевую составляющую. Их довольно много, мы разберем самые главные из них:
Service — абстракция, отвечающая за балансировку нагрузки между подами. Поскольку количество подов может изменяться, нужна единая точка входа, запросы в которую бы автоматически распределялись между активными подами. Такой точкой входа и является service. В нем задаются правила выбора целевых подов, и ее контроллер формирует внутри кластера выделенный IP (по необходимости) и фиксированное доменное имя. Запросы, поступающие на сервис, автоматически балансируются между подами в соответствии с выбранным механизмом.
Ingress — объект, который отвечает за маршрутизацию трафика. В нем мы описываем, по какому домену/пути в какой сервис проксировать запросы. В отличие от остальных объектов конфигурации, "из коробки" ингресс работать не будет — ему нужен контроллер. Ингресс контроллер — это приложение, которое администратор устанавливает в кластер, и именно оно занимается проксированием трафика согласно конфигурациям, описанным в объектах ingress. В роли ингресс-контроллера может выступать знакомый всем администраторам nginx, например.
Ingress class — по сути, идентификатор ингресс-контроллера. В кластере может работать сразу несколько ИК, для того, чтобы понять, какой из них должен "принять" конкретный ингресс в нем и указывается ссылка на ингресс-класс определенного контроллера.
Storage
Объекты storage отвечают за персистентное хранилище. Мы бегло пройдем по абстракциям этой категории, потому что для kubernetes более нативным считается stateless-подход.
Storage Class — объекты, которые создают администраторы/облачные провайдеры. Эта абстракция определяет тип хранилища, которое можно использовать — будет это NFS, HDD или SSD-диски. Самый базовый Storage class — это Host storage — т.е. хранилище непосредственно на том же хосте, на котором запускается нагрузка. Для некоторых кейсов это подходит, но в большинстве случаев это не самый лучший вариант, потому что при падении хоста данные мы потерям.
Persistent Volume Claim (PVC) — это объект, описывающий шаблон запрашиваемого хранилища. В нем указываются объем, ссылка на storage class, который нужно использовать, название создаваемого волюма и другие настройки. После применения из этого PVC будут генерироваться Persistent Volumes.
Persistent Volume (PV) — абстракция, описывающая физическое хранилище — примененный инстанс PVC. Иными словами, PV это реализованный запрос от PVC.
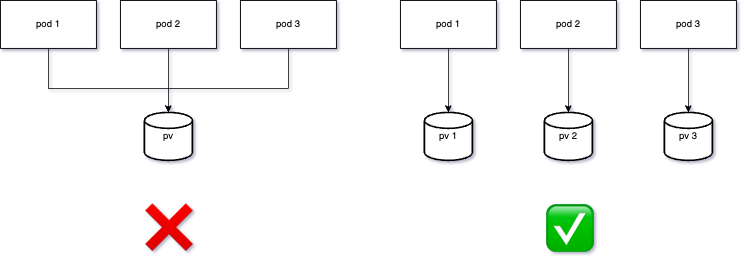
Обсуждая хранение данных, хочется сделать одну ремарку. Рано или поздно у любого DevOps или администратора появляется желание заставить все поды работать с одним хранилищем. Такой механизм выглядит проще, но на деле это крупный антипаттерн. Эта схема не просто создает единую точку отказа всего сервиса, но и устанавливает предел масштабирования вашего приложения — вы не можете примонтировать один диск к серверам в разных дата-центрах. Помните об этом, когда будете работать с персистентными хранилищами.
Хорошая практика — системы, которые умеют работать в кластерном режиме с несколькими хранилищами. Например, в формате мастер-реплика или в режиме шардирования. Главное, чтобы stateful сервис имел не один волюм на всех, а чтобы у каждого контейнера был свой волюм.
Стандартный файл конфигурации
Все перечисленные выше абстракции в Kubernetes имеют стандартный синтаксис конфигурации. Давайте разберем его на примере деплоймента:

Видим следующие поля:
apiVersion — API-версия контроллера, который будет обрабатывать этот файл конфигурации
kind — тип абстракции (любой из тех, что мы обсудили выше)
-
metadata – метаданные, описывающие объект:
name — название ресурса (должно быть уникальным среди всех объектов одного kind), оно же — его ID, ключ для всех обращений
annotations — key-value текстовые поля описания. Здесь можно оставить пометки для себя или вписать конфигурации внешних инструментов (которые будут “смотреть” на эти аннотации)
labels — ссылки/свойства, по которым можно обратиться к ресурсу.
spec — конфигурация самого ресурса (уникальная для каждого типа объектов).
Helm
Поскольку одно приложение может содержать большое количество манифестов, чтобы упростить установку существует пакетный менеджер для кубернетеса — helm. Он дает возможность разработчикам приложения шаблонизировать кубернетес-манифесты при помощи goTemplate. В результате девопс-инженеру для установки крупного приложения на сотни манифестов достаточно заполнить один конфигурационный файл со значениями полей, использующихся в шаблонах — после применения helm отрендерит все манифесты и установит их в кластер.
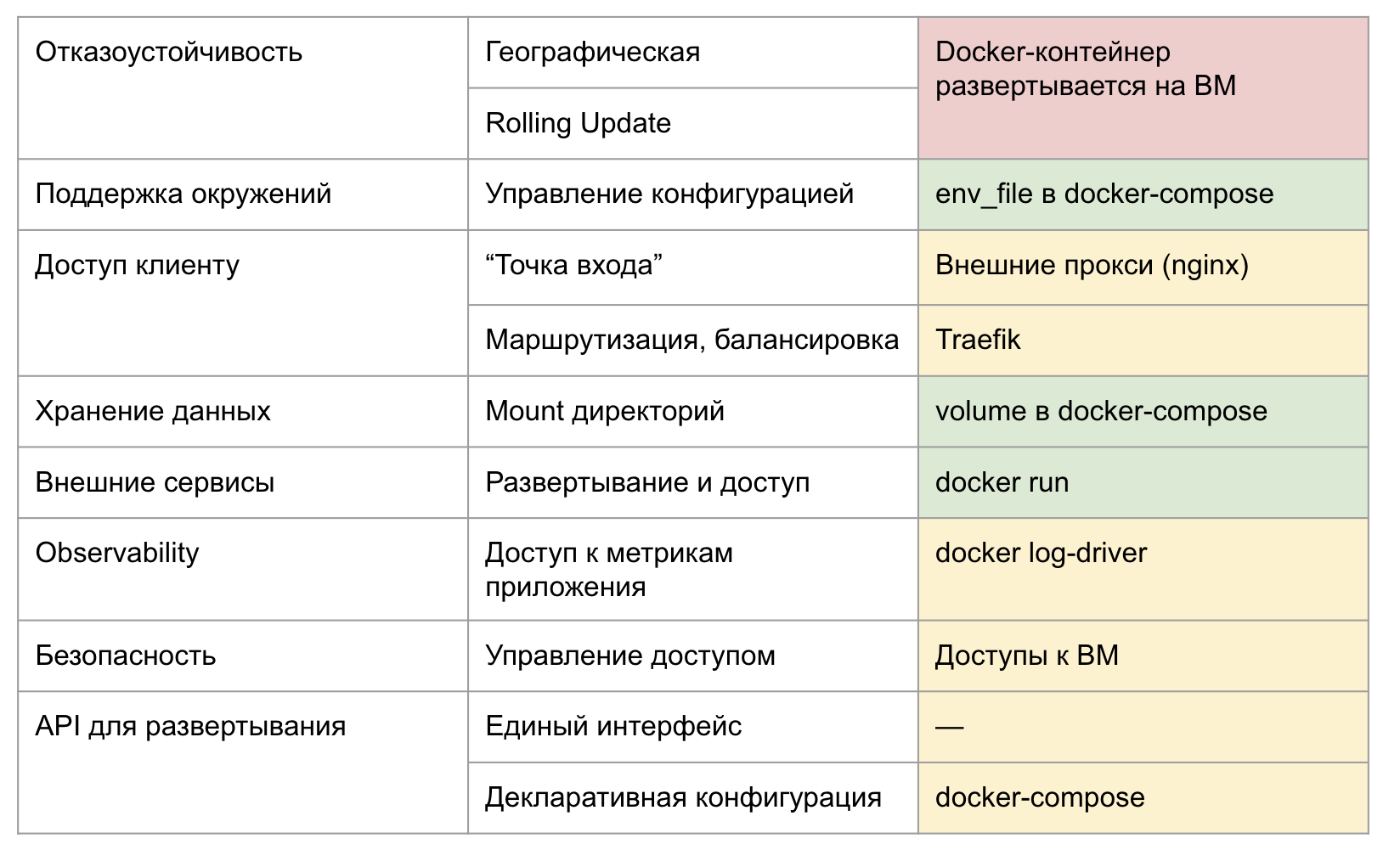
Как изменился подход с Kubernetes
До использования оркестратора:
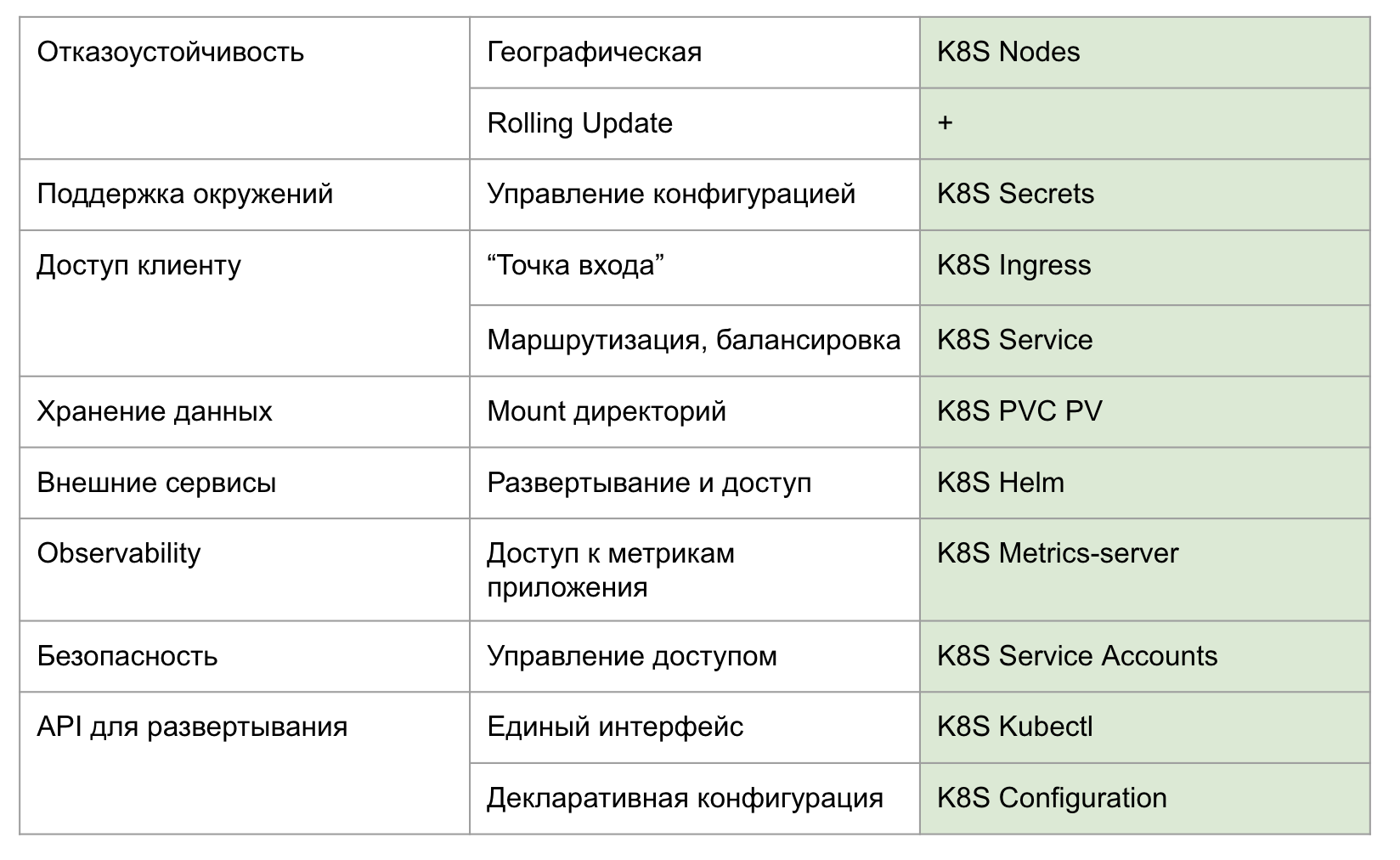
После:
Вывод
Мы рассмотрели архитектуру Kubernetes и перечислили множество доступных из коробки вариантов абстракций. Однако мы не рассмотрели одну важную особенность — API Kubernetes позволяет реализовать и собственные объекты конфигурации. По сути это расширяемая система плагинов. Любое приложение может создать свою абстракцию, используя которую мы можем конфигурировать это приложение. Так можно реализовать, например, собственный deployment, расширяющий стандартный функционал.
Объекты развиваются независимо от Kubernetes — их пишут как представители open source комьюнити, так и крупный бизнес.
Kubernetes — это не просто пять бинарей, это открытый фреймворк, набор стандартов и гайдлайнов, в которые можно встроить практически любой нужный функционал.