
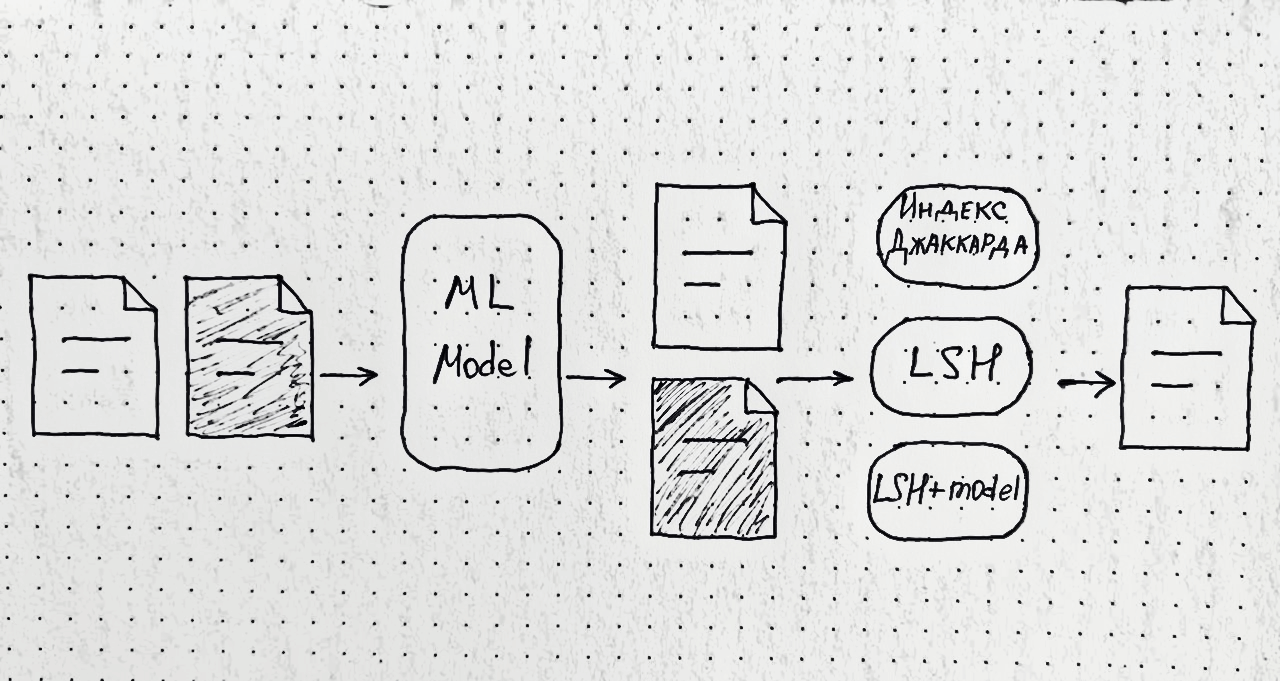
Нам надо искать неполные дубликаты.
При анализе данных могут возникнуть проблемы, если в DataFrame присутствуют дубликаты строк.
Самый простой способ выявить и удалить повторяющиеся строки — это дропнуть их с помощью Pandas, используя метод drop_duplicates(). Но как найти неполные дубликаты, не размечая при этом всех текстовых пар и избегая ложноположительных ошибок?
Нам нужен был такой алгоритм ML, который хорошо масштабируется и работает с пограничными случаями, например, когда разница в парах текстов — только в одной цифре.
Я занимаюсь задачами обработки естественного языка в Газпромбанке. Вместе с DVAMM в этом посте расскажем, какие методы дедупликации мы используем и с какими проблемами столкнулись на практике при детекции неполных дубликатов.
Semantic Text Similarity VS Near-duplicates Detection
Любая задача поиска неполных дубликатов — это всегда задача STS. Но далеко не каждая задача STS — это задача выявления неполных дубликатов.
В чём же различие?
STS — это про поиск пар текстов, которые по смыслу будут похожи друг на друга. Они могут быть по-разному структурированы, иметь словарные различия, но их будет объединять общая тематика.
Что касается задачи поиска неполных дубликатов (англ. — near-duplicates detection) — это поиск дублирующих друг друга текстов с незначительными изменениями. Но что мы имеем в виду под незначительными изменениями? Понятие достаточно размытое, и фактически это установка, которую необходимо определить разработчику совместно с бизнесом при решении конкретной задачи. Далее под «дубликатом» будут подразумеваться именно неполные дубликаты.
Получается, что эти задачи похожи, но методы, которые работают в STS, приводят к очевидно высокому количеству ложно-положительных предсказаний в задаче дедупликации.
Поиск неполных дубликатов нам нужен для:
- Дедупликации датасетов.
- Дедупликации выдачи модели.
- Дедупликации огромного массива текстов для обучения LLM.
Дедупликация датасета
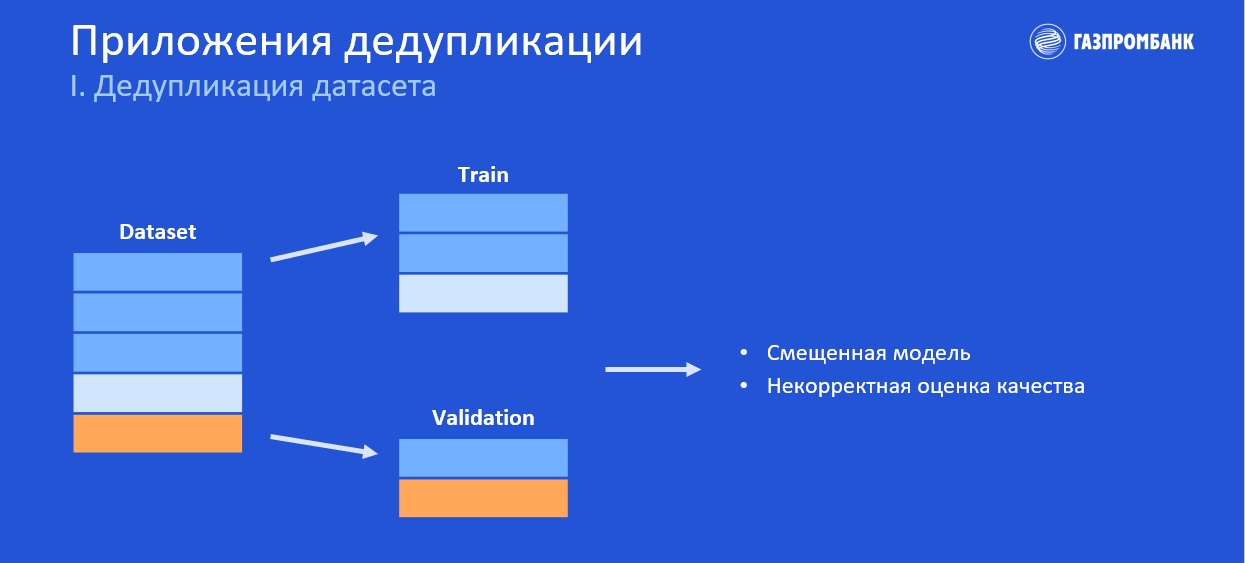
Давайте рассмотрим пример. У нас есть датасет, в котором присутствуют дубликаты (три полоски одинакового цвета).
По классике мы случайным образом разобьём датасет на обучающую и валидационную выборки (train и validation) и видим, что в обучающую выборку попало два дубликата. Это может привести к тому, что наша модель будет в какой-то степени смещена в сторону этих самых дубликатов, поскольку фактически при обучении модель эти примеры видит чаще, чем другие (как если бы мы дали этому примеру больший вес в нашей функции потерь). Как результат — итоговая генерализация, вероятно, будет хуже.
Также мы видим, что один из дубликатов попал в валидационную часть. Это говорит нам о том, что частично мы будем оценивать нашу модель на (почти) тех же данных, на которых мы обучались. Но это, очевидно, некорректно и приведёт к завышению метрик оценки качества.
Дедупликация выдачи модели
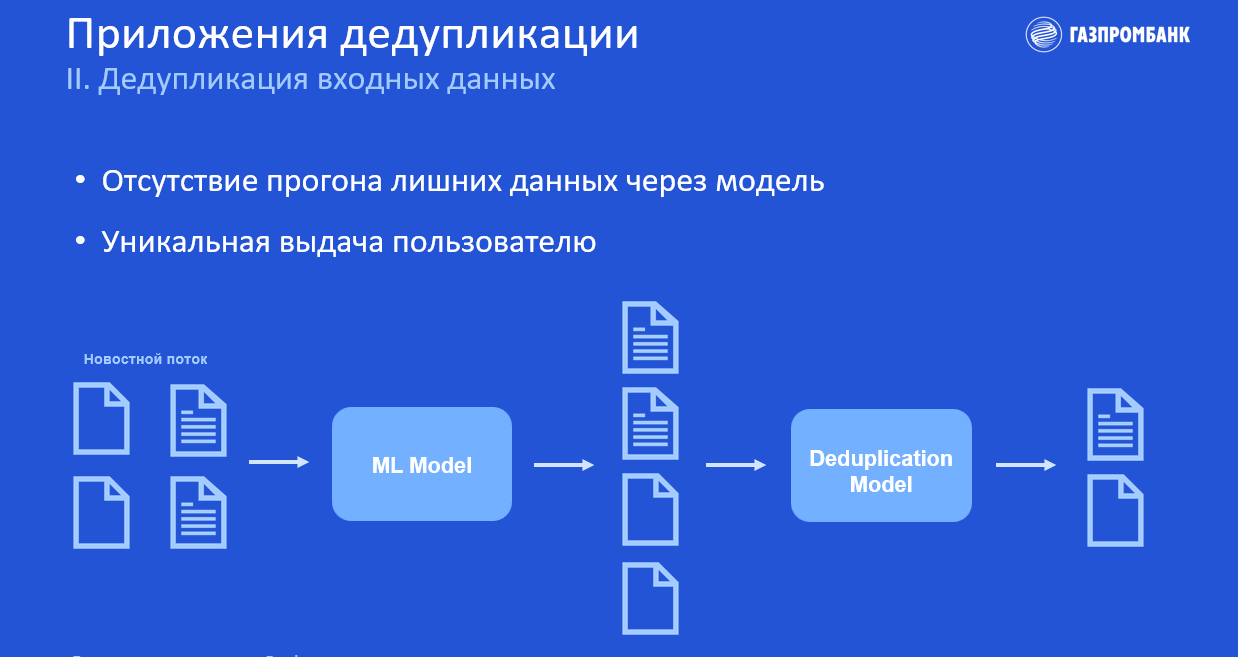
Представим, что у нас есть новостной поток, который мы прогоняем через модель машинного обучения. В результате этого получаем отсортированный, например, по релевантности поток.
Это задача ранжирования ленты новостей, т. е. выделения самых важных новостей.
В выходных данных всё так же есть дубликаты, от которых необходимо избавиться, чтобы сделать выдачу модели уникальной для пользователя.
Поэтому мы можем прогнать этот поток ещё через одну модель, которая выдаст нам две уникальные новости. Собственно, это одно из основных приложений дедупликации, которым мы активно занимаемся.
Дедупликация для LLM
Это дедупликация тех самых огромных массивов текста, на которых обучаются все GPT подобные модели. И при этом внутри этого массива зачастую есть большое количество неполных дубликатов.
Удаление этих дубликатов сэкономит ресурсы и сократит время обучения больших языковых моделей.
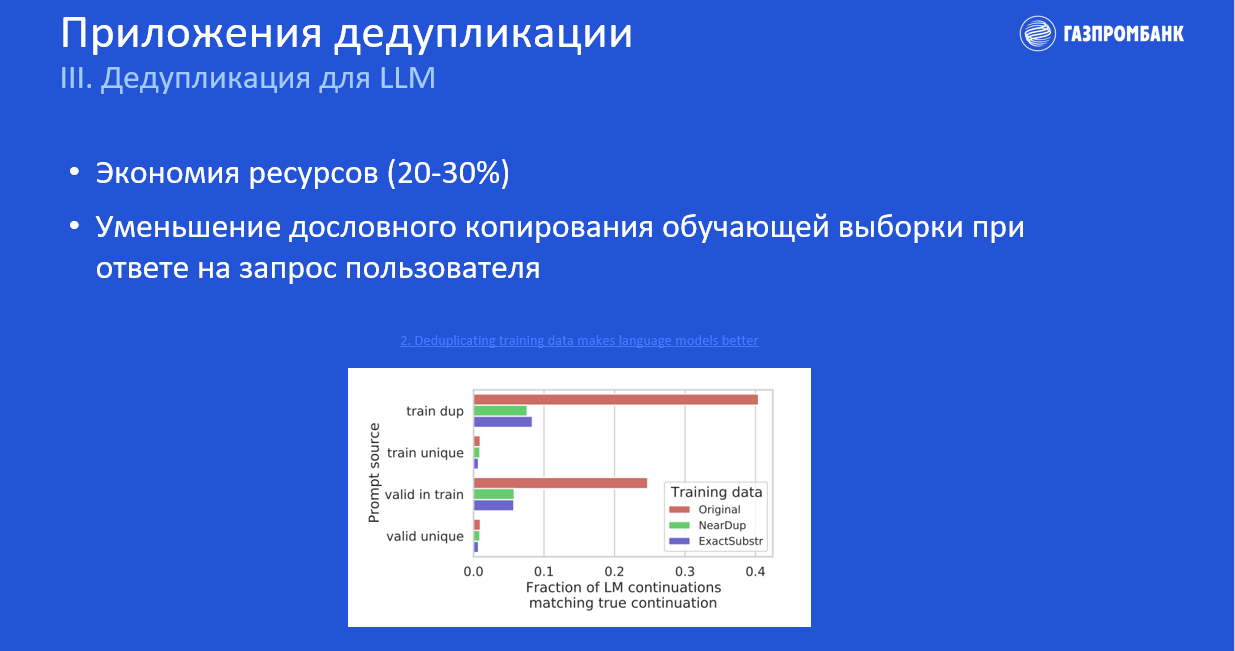
Также необходимо учитывать, что LLM, обученная на данных со множеством дубликатов, при выдаче ответа с большей вероятностью будет практически дословно копировать сгенерированный контент из обучающих данных.
Ниже представлен график из недавней статьи Google Research, где показано, что если генерировать текст без каких-либо последовательных подсказок, то около 40 % случаев выдаст дословно скопированный текст с данных, на которых обучалась модель.
И если мы хотим уменьшить количество дословных повторений, то необходимо создать такую модель, которая будет обучаться на дедуплицированном датасете.
Какие методы есть для решения этой задачи?
Первый метод — это оценка двух текстов на схожесть с помощью Индекса Джаккарда. Фактически это пересечение множества слов между двумя текстами.

Берём слова, которые есть в текстах А и В, и делим их на общее количество уникальных слов в этих текстах. Получаем некоторую метрику (J) от нуля до одного. Чем ближе индекс к единице, тем более похожи два текста.
В тех случаях, когда текст А является полной подстрокой В (весь текст А есть в тексте В плюс какая-то дополнительная информация), можно модифицировать метрику для корректного учёта подобных случаев. Для этого необходимо делить на наименьший размер множество уникальных слов среди обоих текстов.
Плюсы такого метода: простота и интуитивность. Минусы: невозможно масштабировать на большое количество текстов из-за квадратичной временной сложности, так как необходимо сравнить все пары текстов, которые у нас есть.
Второй метод основан на хешировании. Это чуть более продвинутый метод, который рассмотрим на примере Locality-sensitive hashing (LSH).
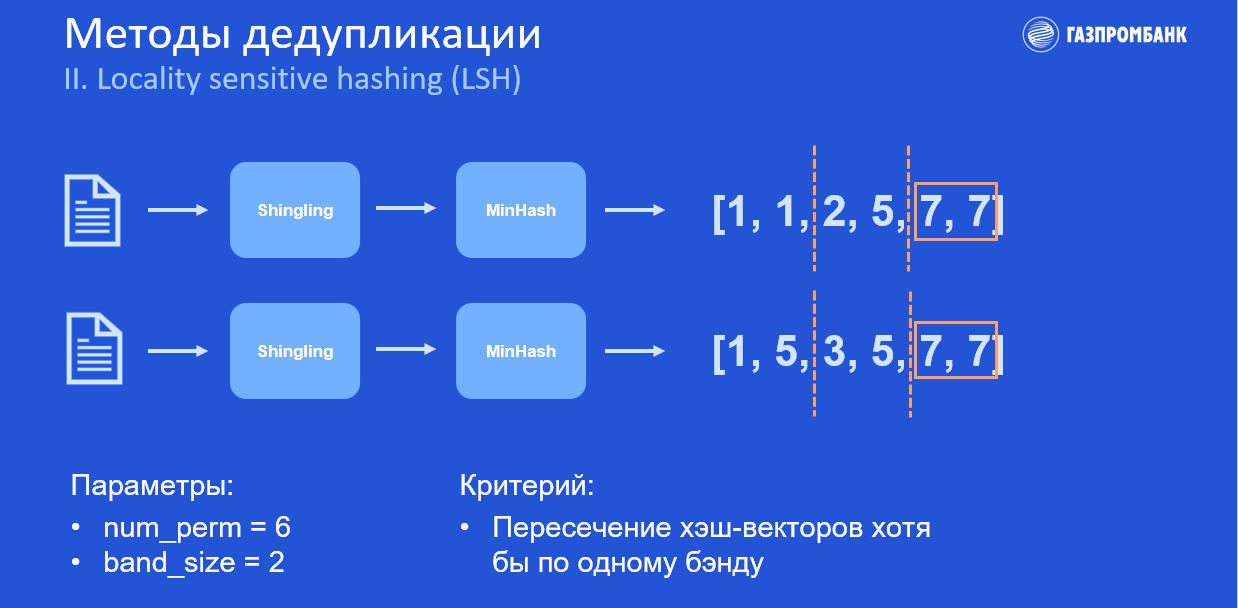
Представим, что у нас есть два дублирующих документа. Мы проводим их через shingling, т. е. разбиваем текст на токены: словесные n-граммы и шинглы (символьные n-граммы).
И, разбив оба текста, подаём их в хеш-функцию MinHash, которая пытается максимизировать количество коллизий в хешах.
Так появляется первый гиперпараметр num_perm — это фактически длина выходного хеш-вектора (или количество хеш-функций, применяемых к каждому тексту). Оба текста отхешировались, и мы получили из них хеш-векторы, состоящие из шести цифр.
Затем мы вносим ещё один дополнительный гиперпараметр — band_size — и задаём значение, например, равное двум. Нам необходимо поделить эти векторы на бэнды одинаковой длины, поэтому каждый вектор делим на три бэнда.
При пересечении хотя бы по одному из бэндов выявляется принадлежность этой пары к дубликатам. Последний бэнд — одинаковый: вероятно, это пара дубликатов.
В книге LSH «Mining of Massive Datasets» математически показано, что индекс Джаккарда, рассчитанный на хеш-векторах текстов, приближает реальное значение индекса на исходных текстах, поэтому в дальнейшем можно посчитать его приближённое значение и отфильтровать нашу выдачу от случайного мусора, возникшего из-за рандомизированности хеш-функции данного алгоритма.
Проблемы, с которыми мы столкнулись на практике
Первая проблема — это сложность оценки при использовании этого алгоритма.
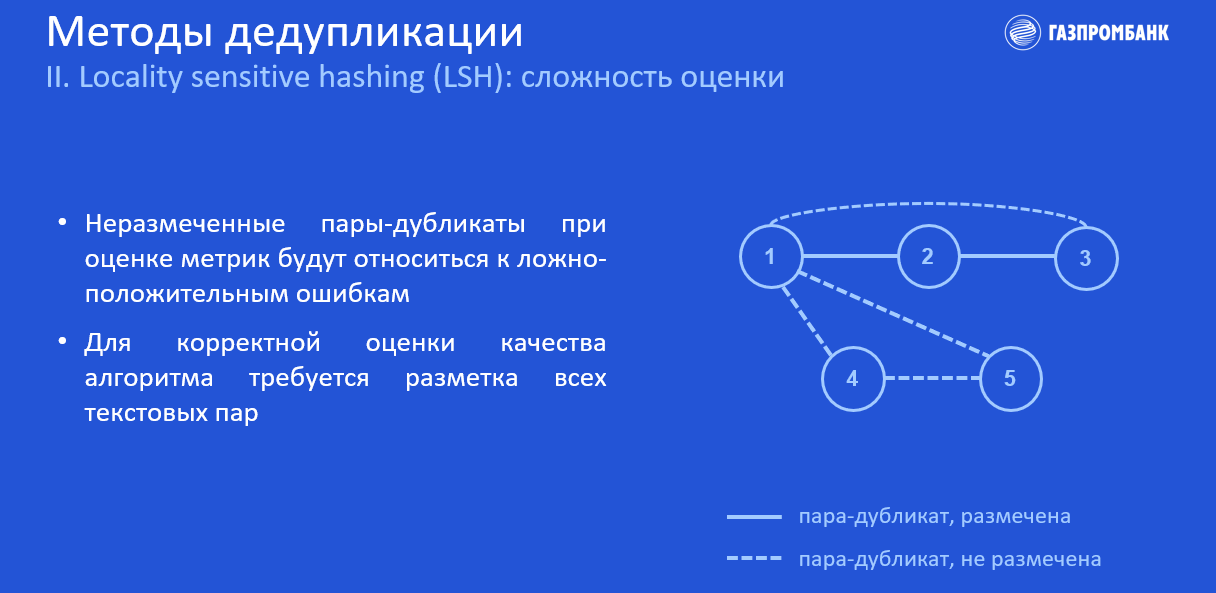
У нас есть датасет с некоторыми размеченными парами.
Прямая линия — это пары дубликатов, которые есть у нас в разметке. Пунктирная линия — пары дубликатов, которых нет в разметке. Разметка неполная, т. к. анализировать и размечать все пары среди большого количества текстов — это очень долго и дорого, поэтому рационально отобрать некоторую подвыборку текстов для разметки.
Помимо пар 1-2 и 2-3, LSH найдёт и выдаст остальные пары: 1–3, 1–4, 4-5, 1–5. Пару 1–3 мы можем найти через соседей в нашем условном графе, с ней проблем не будет. А вот остальные пары при подсчёте метрик из-за отсутствия в нашей разметке будут отнесены к ложно-положительным ошибкам.
Получается, что для корректной оценки подобных алгоритмов необходимо размечать все текстовые пары, а это не самый рациональный подход в промышленных условиях.
Вторая проблема заключается в том, что в некоторых пограничных случаях как LSH, так и Индекс Джаккарда работают не совсем корректно, и это наивным способом никак не исправить.
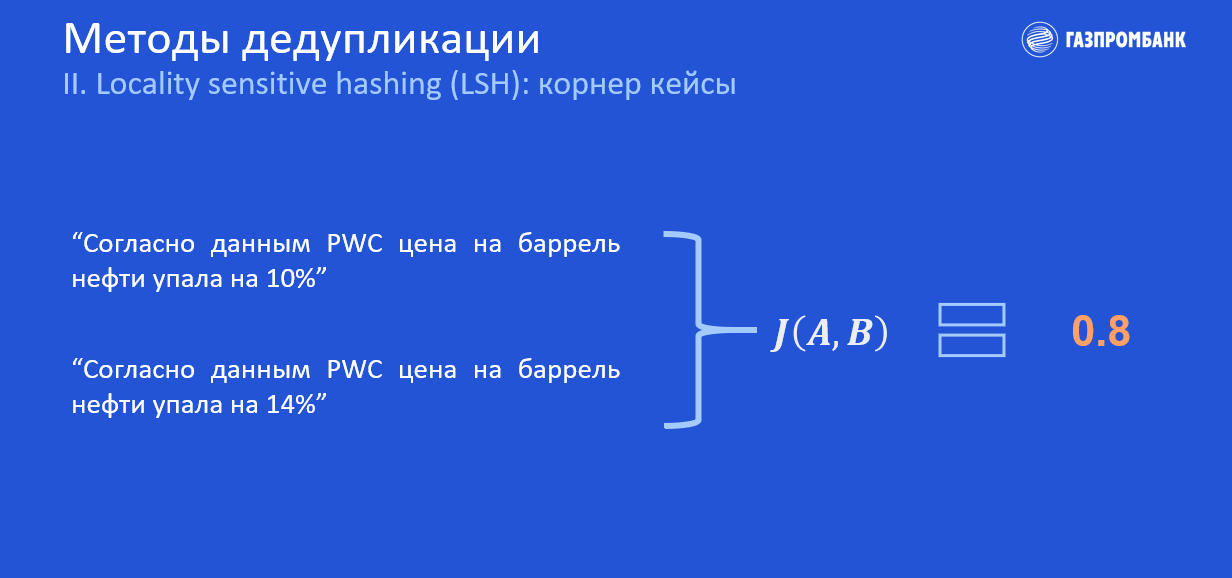
Например, разница между двумя небольшими новостями — всего лишь в одной цифре. Индекс Джаккарда достаточно высокий, поэтому, скорее всего, мы отнесём эту пару к дубликатам. Но в каких-то приложениях эта цифра может быть критической. Из этого следует, что с такими кейсами невозможно справиться ни с помощью Индекса Джаккарда, ни методами хеширования.
Как мы видим, LSH — отличный масштабируемый алгоритм, который настраивается через гиперпараметры и к тому же параллелится на ЦПУ. Но при этом его сложно оценить на неполной разметке, а с пограничными случаями он и вовсе не способен справиться корректно.
Что же делать?
Мы можем перейти к более сложному подходу — использовать LSH как первую (кандидатную) модель, которая позволит нам извлечь некоторых кандидатов, в том числе с минимальными ошибками и мусором, и затем проскорить эти пары другой, более умной моделью, которая будет обучаться на Pairwise loss, чтобы при работе на двух текстах она смогла извлекать попарные фичи и разделять сложные кейсы дубликатов от недубликатов.
Такой подход должен решить все предыдущие проблемы базовых методов, так как с помощью разметки мы сможем «зашить» в модель работу с корнер кейсами, а также оценить эту модель на неполной разметке, проскорив только имеющиеся пары.
Такой подход хорошо масштабируется и работает чуть медленнее, чем простой LSH, но качество модели значительно лучше. К сожалению, на практике мы этого ещё не проверяли, но в статье Noise-Robust De-Duplication at Scale рассказывается про большой отрыв модельного подхода от чистого LSH.
Но и здесь есть проблема: нужна качественная разметка данных. Это довольно долго и сложно, особенно для объёмных текстов.
Выводы
Поиск неполных дубликатов — это отдельная задача, отличающаяся от задачи семантической близости текстов, и подходы к их решению абсолютно разные.
Алгоритм LSH хорошо масштабируется, и его можно использовать при дедупликации огромных массивов текста для больших языковых моделей, например, GPT, где как таковое качество дедупликации не играет ключевой роли.
В свою очередь, например, при дедупликации выдачи пользователю, где обычно нет больших массивов текста и при этом необходимо высокое качество, имеет смысл использовать связку LSH + ML-модель. Эта комбинация будет хорошо масштабироваться и покажет высокое качество, обеспечивая пользователя полнотой уникальной информации.