
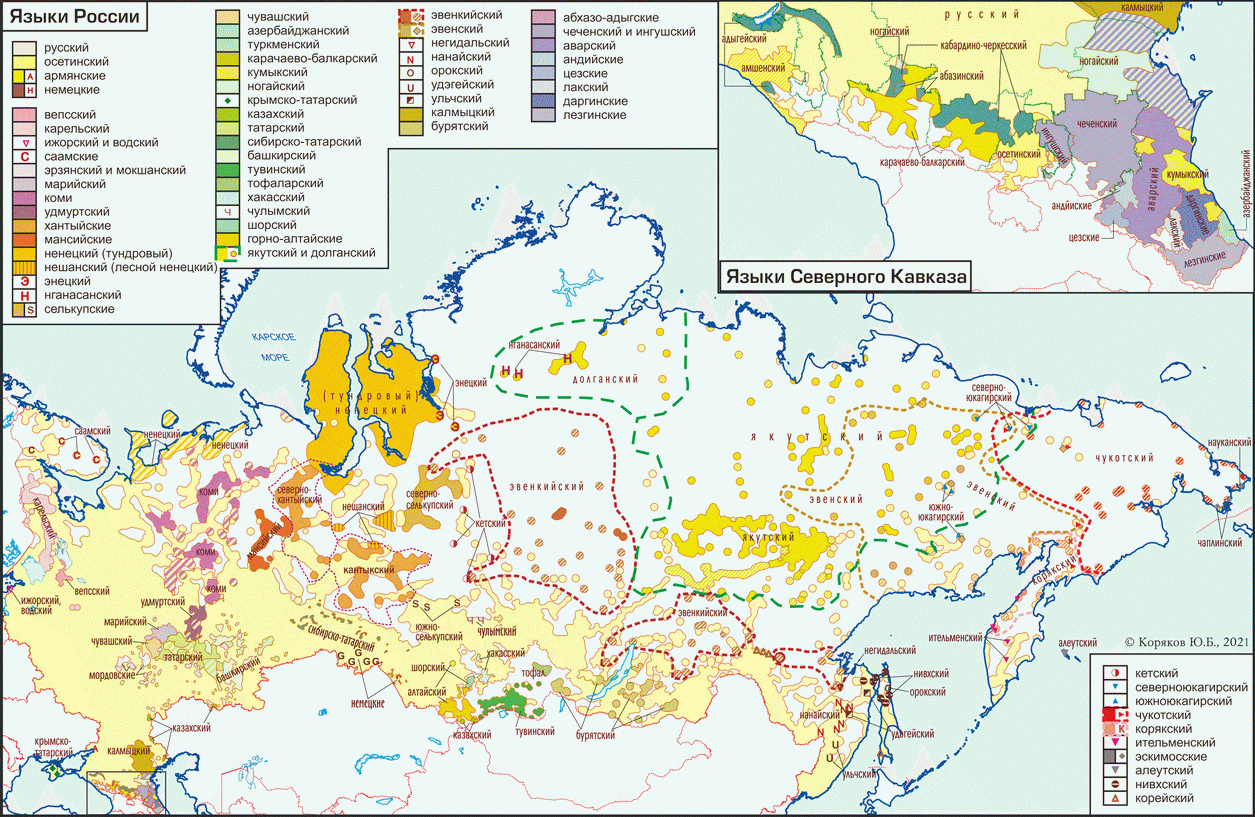
Источник карты — Проект «Языки России» Институт языкознания РАН, 2021 год
Давненько мы не выпускали новых статей про наш синтез речи! В прошлый раз мы добавили синтез на 9 языках народов Индии, существенно улучшили автоматическую простановку ударений, добавили 1 русский голос и "наследовали" SSML для всех моделей.
В этот раз мы сделали следующее:
- Ускорили все
v4модели в 3-4 раза; - Существенно повысили качество синтеза в 8 kHz;
- Обновили и пересобрали нашу модель для русского языка;
- Обновили модель для 9 языков народов Индии с 17 голосами;
- Добавили единую модель для 22 языков с кириллическим алфавитом с 31 голосом;
- Прекратили поддержку моделей романо-германских языков (старые модели будут доступны для скачивания без изменений);
- Обновили модели для языков народов СНГ: узбекского и украинского (татарский и калмыцкий были "поглощены" единой моделью);
Как попробовать модель
Дублировать примеры кода из прошлых статей не буду, глобально ничего не меняется, просто приложу ссылки. Попробовать модель можно:
- В нашем репозитории;
- В колабе;
- Все кириллические модели также доступны в нашем боте;
Новая кириллическая модель
В этом релизе мы добавили модель для следующих языков со следующим набором голосов:
| Speaker_ID | Язык | Пол |
|---|---|---|
| b_ava | Аварский | F |
| b_bashkir | Башкирский | M |
| b_bulb | Болгарский | M |
| b_bulc | Болгарский | M |
| b_mrj | Горномарийский | M |
| kz_M1 | Казахский | M |
| kz_M2 | Казахский | M |
| kz_F3 | Казахский | F |
| kz_F1 | Казахский | F |
| kz_F2 | Казахский | F |
| b_kalmyk | Калмыкский | M |
| kalmyk_erdni | Калмыкский | M |
| kalmyk_delghir | Калмыкский | F |
| b_krc | Карачаево-балкарский | M |
| b_kpv | Коми-зырянский | M |
| b_lez | Лезгинский | M |
| b_mhr | Марийский | F |
| b_nog | Ногайский | F |
| b_oss | Осетинский | M |
| b_ru | Русский | M |
| b_tat | Татарский | M |
| marat_tt | Татарский | M |
| b_tyv | Тувинский | M |
| b_udm | Удмуртский | M |
| b_uzb | Узбекский | M |
| b_kjh | Хакасский | F |
| b_che | Чеченский | M |
| b_cv | Чувашский | M |
| cv_ekaterina | Чувашский | F |
| b_myv | Эрзянский | M |
| b_sah | Якутский | M |
Поскольку все кириллические алфавиты довольно "фонетические", не представляет сложности использовать единый набор токенов для всех языков: !,-.:?iµöабвгдежзийклмнопрстуфхцчшщъыьэюяёђѓєіјњћќўѳғҕҗҙқҡңҥҫүұҳҷһӏӑӓӕӗәӝӟӥӧөӱӳӵӹ.
При предобработке данных нам пришлось отказаться от использования совсем малых и редких языков (сотни или тысячи носителей), из-за совсем специфичных символов, сильно увеличивающих размер словаря. Также пришлось убрать совсем редкие буквы, и у некоторых символов были проблемы с кодировкой. Также у некоторых языков отсутствует единый чётко устоявшийся алфавит. Например, у пары диалектов свои небольшие вариации алфавита, а в интернет-общении используется некая средняя упрощенная версия. Самый близкий аналог такого — это буква ё и литературные кавычки в русском языке.
Если мы пропустили какие-то важные буквы в вашем языке — обязательно напишите об этом.
У такого подхода есть очевидный минус. На все языки мы не смогли найти достаточное количество данных с ударениями, и поэтому модель ставит ударения "по наитию". Очевидным способом улучшения модели является краудсорсинг ударений хотя бы для использованных датасетов. Если вы сможете помочь нам расставить ударения для большей части представленных языков, то мы сможем также опубликовать модель с ударениями, когда наберется достаточное количество языков.
Будем также признательны, если соотечественники владеющие какими-то из этих языков как родными (или если у вас в семье кто-то говорит) оценят качество и правильность произношения. Данные на вход именно этой модели были местами шумноватые.
В статью же, чтобы всё было не так серьёзно, я добавлю озвучку одной и той же фразы Волк слабее льва и тигра, но в цирке он не выступает! всеми этими голосами. По словам носителей нескольких языков, с кем мы общаемся, голоса "говорят" на русском с акцентом, похожим на настоящий акцент носителей языка (чтобы загрузился виджет, может потребоваться VPN):
Ускорение моделей
Тут всё довольно просто, публичные модели v4 стали примерно в 3-4 раза быстрее по сравнению с v3 моделями:

RTS на данном графике — это число синтезируемых секунд аудио в секунду на указанном количестве потоков процессора.
Повышение качества синтеза для 8 kHz
Тут тоже все довольно просто, раньше для 8 kHz как бы использовалась отдельная ветка модели, и она была заметно ниже по качеству.
Но после ускорения моделей аудио в 8 kHz создается из аудио в 24 kHz, что звучит сильно лучше. Это привело к падению скорости синтеза в 8 kHz, но одновременно с ускорением это падение не должно чувствоваться.
Разработки вне публичного домена и что не получилось
Мы не стали выносить в публичный домен следующие разработки:
- Модели повышенного качества;
- Модели для русского языка, работающие на основе фонем и модели автоматической конверсии из букв в фонемы;
- ONNX-версии моделей;
- Смешанные фонемные модели для нескольких языков.
Из целей мы решили отказаться от решения следующих задач:
- Расстановка ударений для омографов (модель ставит самый частотный вариант для ~1000 омографов);
- Квантизация моделей синтеза для дальнейшего ускорения хоть в итоге и завелась, но она приводила к деградации качества звучания, времени и фокуса на quantization-aware тренировку моделей не нашлось.
Дальнейшая поддержка и развитие
Мы не планируем останавливаться на достигнутом и собираемся продолжать поддерживаться и развивать наш синтез:
- Добавлять новые языки по возможности;
- Дальше развивать фишки по управлению эмоциями, интонацией речи и произношением;
- Разрабатывать и внедрять новые модальности "синтеза речи", такие как ревойс (speech-to-speech, voice-to-voice, revoice, ревойс как мы его называем). Ревойс кстати уже тоже можно попробовать в нашем боте.
Комментарии (15)

foxairman
17.08.2023 10:03+3Круто, а можно сделать такую модель чтобы она смогла петь песни как Vocaloid Hatsune Miku?
И еще хотел спросить есть ли какие-то ограничения по запуску модели или технические требования к ПК? Типа нужно 1Гб памяти, до 1000 слов на вход и т.д?

snakers4 Автор
17.08.2023 10:03+1Там вручную фонемы рисуются, а тут как бы модель сама всё придумывает. Тут цель чтобы само работало, а там руками рисовать в интерфейсе как бы. Возможно вам нужен ревойс.
Особых требований нет, только чтобы был PyTorch.

Mingun
17.08.2023 10:03+1А зачем ваш бот требует подписаться на какой-то канал новостей для своей работы? Буквально вчера пробовал им воспользоваться и напоролся на это. Что это за серая схема по привлечению подписчиков?
snakers4 Автор
17.08.2023 10:03+1Это не "серая схема", это схема борьбы с мошенниками, которые притворяются с нами.
Когда бот набрал популярность, появились жулики, собирающие деньги от нашего имени и занимающиеся разными другими прекрасными вещами (травля, газлайтинг, вымогательство денег, шантаж).
Поскольку в телеграме саппорт работает на общественных началах, а report / abuse жалобы даже от десятков-сотен членов приватного комьюнити остаются неотвеченными, другого способа мы не нашли.
И да, сразу отвечая на вопрос, уже 8 месяцев ждем аппрува верификации нашего бота. Отправляли заявку через верификацию ВК + наш сайт, там идет разворот на саппорт. Когда появилась вторая ссылка … отменить заявку нельзя, надо ждать первую. А первая упала вникуда.
Mingun
17.08.2023 10:03Ну так в FAQ можно же хотя бы написать, для чего это надо и что ждёт подписчика? И всё равно это будет выглядеть серой схемой. Потому что я не понимаю, что мешает мошеннику подписаться и дальше продолжать свои мошеннические схемы — ему то вообще пофиг, на кого подписываться. И как эта подписка защищает от этих схем.
snakers4 Автор
17.08.2023 10:03+2Пока телеграм (и если) не дает галку, у нас на порядок-два больше подписчиков на канале. Мошенник после введения этой схемы сдулся.
Ну так в FAQ можно же хотя бы написать, для чего это надо и что ждёт подписчика?
Никто не читает FAQ. Не понимаю в чем проблема. Не хотите - не пользуйтесь. Или попользуйтесь 5 минут, потом отпишитесь. Это же не скамный бот с рекламой каждое сообщение или где надо подписаться на 10 каналов каждый день.

kryvichh
17.08.2023 10:03+1Попробовал ваши модели TTS. Применил украиноязычную модель к белорусскому тексту, с предобработкой. Получилось очень круто! Это лучший TTS синтезатор для белорусского языка из созданных до сих пор:
https://soundcloud.com/kryvich/test-be-v4_ua
Теперь немного
нытьяконструктивной критики. Предыдущая версия модели мне показалось чуть лучше звучит. В v4_ua есть едва заметное дребезжание, а с v3_ua такого нет.https://soundcloud.com/kryvich/test-be-v3_ua
Также, при запуске локально из командной строки, старая модель немного быстрее:
d:\anaconda3\python.exe tts3.py ukr.txt --- 3.139 seconds --- d:\anaconda3\python.exe tts4.py ukr.txt --- 4.150 seconds ---Запускал несколько раз, цифры примерно такие остаются.
Также новая модель выдаёт предупреждение:
d:\anaconda3\lib\site-packages\torch\nn\modules\module.py:1501: UserWarning: Converting mask without torch.bool dtype to bool; this will negatively affect performance. Prefer to use a boolean mask directly. (Triggered internally at C:\cb\pytorch_1000000000000\work\aten\src\ATen\native\transformers\attention.cpp:152.) return forward_call(*args, **kwargs)Но это возможно сам виноват, я не настоящий Python-программист.
snakers4 Автор
17.08.2023 10:03+2Отвечу по пунктам.
Также, при запуске локально из командной строки, старая модель немного быстрее:
У моделей торча есть такая особенность как "прогрев". То есть первый (и возможно несколько первых прогонов) модель "прогревается". Это должно помогать ей в будущем работать быстрее, но в реальности это к сожалению не так.
Иногда обходится через
torch._C._jit_set_profiling_mode(False)после импорта торча, но до импорта и загрузки модели.Может еще зависеть от версии установленного торча. Вообще новая модель так-то в 4 раза быстрее, если всё нормально замерять.
snakers4 Автор
17.08.2023 10:03Теперь немного
нытьяконструктивной критики. Предыдущая версия модели мне показалось чуть лучше звучит. В v4_ua есть едва заметное дребезжание, а с v3_ua такого нет.Мы столкнулись с некоторым количеством случаев нарушения лицензии наших моделей, в том числе
жуликамиоппортунистически настроенными людьми.По этой причине было принято решение опубликовать кратно более быструю модель, но с некоторым лимитом по качеству, чтобы точно было понятно, что это синтез.
По скорости - ответил ниже.
snakers4 Автор
17.08.2023 10:03+1Да еще запуск и загрузка модели занимают время. Поэтому сравнивать надо на большом числе разных генераций как бы ПОСЛЕ загрузки модели.

einhorn
17.08.2023 10:03+1При загрузке модели падает с exit code -1073740791
language = 'cyrillic' model_id = 'v4_cyrillic' sample_rate = 48000 speaker = 'cv_ekaterina' device = torch.device('cpu') model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=language, speaker=model_id)v4_ru тоже
irishmann
Заценил синтез на башкирском языке в телеграм боте. Скорость генерации поражает. В пример озвучки (русский текст) чувствуется акцент.)) Башкирский текст звучит хорошо, ударения проставлены неплохо. Только окончания предложений на гласную букву, иногда звучат так, как будто человека перебили на полуслове)
snakers4 Автор
У модели в явном виде нет inductive bias-а в виде ударений, она сама как-то их ставит. Насколько помню в башкирском и татарском вроде такой жести как в русском нет, но думаю причина как раз в этом. Но может в светлом будущем расставим ударения на все языки и станет лучше. Плюс данные шумноваты.
LeToan
Если правильно помню Зализняка, в татарском ударение на последний слог, в польском на предпоследний, а в русском промежуточное состояние при переходе от ясного состояния до, примерно, 12 века к измененному состоянию далекого будущего, результат борьбы двух сводов правил. Ну, хоть в отличии от сербского больше нет двух типов ударения.