
В последние 20 лет архитекторы программных и аппаратных систем перепробовали различные стратегии, которые позволили бы решать проблемы, связанные с большими данными. Пока программисты усердно переписывали код, приспосабливая его для горизонтального масштабирования на множество машин, железячники впихивали на каждый чип всё больше и больше транзисторов и ядер, чтобы увеличить объём работы, осуществимый на каждой машине.
Как подтвердит любой, кому когда-либо доводилось проходить собеседование по программированию, при наличии арифметической и геометрической прогрессии геометрическая всегда возобладает. При горизонтальном масштабировании расходы растут линейно (арифметически). Но по закону Мура вычислительные мощности со временем растут экспоненциально (геометрически). Это означает, что можно несколько лет ничего не делать, а затем масштабировать систему вертикально и получать улучшение на порядки. За двадцать лет плотность транзисторов возросла в 1000 раз. Это значит, что такая задача, для решения которой в 2002 году потребовались бы тысячи машин, сегодня выполнима всего на одной.

При таком драматичном росте аппаратных мощностей уместно спросить: «А существуют ли до сих пор те условия, которые в 2003 году позволяли решать проблемы масштабирования»? В конце концов, мы сильно усложнили наши системы и привнесли в них множество издержек. Правда ли всё это до сих пор нужно? Если вы теперь можете выполнить задачу на единственной машине, то не лучше ли такая альтернатива?
В этом посте мы подробно разберём, почему практика горизонтального масштабирования стала доминирующей, проверим, актуальны ли до сих пор эти обоснования, а затем исследуем некоторые преимущества архитектуры с вертикальным масштабированием.
Зачем вообще требуется горизонтальное масштабирование
Сначала немного развернём контекст. Двадцать лет назад Google столкнулся с проблемами масштабирования, когда они разослали своих пауков по всемирной сети, стремясь её проиндексировать. Как правило, с этим справлялись, покупая более дорогие машины. К сожалению, на тот момент у Google было не так много денег, и, независимо от издержек, им всё равно предстояло уткнуться в пределы возможного, так как сам «веб-масштаб», в свою очередь, рос по экспоненте.
В Google, стремясь проиндексировать любой сайт в каждом уголке Интернета, изобрели новую вычислительную модель. Применяя функциональное программирование и алгоритмы для распределённых систем, Google стал почти беспредельным, но при этом не приходилось покупать «баснословно дорогого железа». Google не покупал больших компьютеров, а просто связывал множество сравнительно небольших при помощи умно разработанного ПО. Это было «горизонтальное масштабирование» на множество машин, а не «вертикальное масштабирование» на более крупные машины.
Google очень быстро опубликовал одну за другой три статьи, которые полностью изменили всеобщие взгляды на то, как следует строить и масштабировать софтверные системы. Это были следующие статьи: GFS (2003), в которой была разобрана тема хранилищ данных, MapReduce (2004), посвящённая вычислениям и BigTable (2006), в которой затрагивались рудименты базы данных.
Дуг Каттинг, реализовавший описанные в этих статьях приёмы и выложивший их в свободный доступ, сказал: «Google на несколько лет заскочил в будущее и посылает нам оттуда весточки». (К сожалению, Google не преуспел в конструировании времялётов, и основным достигнутым пока результатом остаётся изрядно барахлящий телепортатор козлов).
Впервые читая статью о MapReduce, я ощущал, что Google как будто изобрёл совершенно новый способ мышления. Я поступил на работу в Google в 2008 году, надеясь приобщиться к этому волшебству. Вскоре после того я подключился к выводу их движка запросов Dremel в продакшен – и его требовалось горизонтально масштабировать. Вскоре он был переименован в BigQuery.
Сложно переоценить, какое огромное влияние оказали на индустрию те изменения, что были провозглашены при революционном переходе на горизонтальное масштабирование. Сегодня, если вы выстраиваете «серьёзную» инфраструктуру, вам придётся горизонтально масштабировать её через сложную распределённую систему. Это привело к популяризации новых технологий – в частности, протоколов консенсуса, новых способов развёртывания ПО, а также к более спокойному принятию нестрогой согласованности. Вертикальное масштабирование сохранилось лишь при работе с базами унаследованного кода, прочно связанного со старыми одноузловыми архитектурами.
Пожалуй, моя рабочая нагрузка не уместится на одной машине
Первый и основной фактор, стимулирующий горизонтальное масштабирование, таков: людям кажется, что для обработки их данных требуется множество машин. Однажды я написал длинный пост, в котором аргументировал, что «большие данные мертвы» (перевод на Хабре — прим. пер.), вернее, что множества данных сейчас становятся мельче, чем принято думать, а рабочие нагрузки — ещё меньше, поэтому значительная часть данных вообще не используется. Если у вас нет «больших данных», то вы почти наверняка не нуждаетесь в горизонтально масштабируемых архитектурах. Не хотелось бы пересказывать эти аргументы здесь.
Можно начать с простой диаграммы, демонстрирующей, насколько укрупнились со временем инстансы AWS. Сегодня широкодоступны машины, на которых по 128 ядер и по терабайту ОЗУ. Столько же ядер, сколько на инстансе Snowflake XL, но вчетверо больше памяти.

В статье o Dremel приведено несколько бенчмарков, расставленных при работе 3 000-узловой системы Dremel на датасете размером 87 ТБ. Сегодня эквивалентную производительность можно получить на единственной машине.
В то время казалось, что Dremel просто не сможет работать, не опираясь на индексы или предвычисленные результаты. Все прочие игроки, занятые разработкой баз данных, пытались обойтись без сканирования таблиц, но в Google решили: «Не, мы просто будем сканировать таблицы реально быстро, каждый запрос превратим в проход». Бросая машины пачками на решение задач, удалось достичь такой производительности, как будто тут не обошлось без колдовства. Пятнадцать лет спустя можно добиться подобной производительности, не прибегая ни к какой магии, ни даже к распределённым архитектурам.
В приложении к этой статье математически разберём, как можно достичь такого уровня производительности на единственном узле. На этой диаграмме показаны различные ресурсы, сравниваемые с аналогичными показателями из вышеупомянутой статьи. Чем выше планка — тем лучше.

Здесь видим, что одна машина может обеспечить такую производительность, как кластер Dremel на 3000 узлов при «горячих» и «тёплых» условиях кэша. Это логично, учитывая, что во многих горизонтально масштабируемых системах и, в частности, в Snowflake, для кэширования применяются твердотельные диски — ради повышения производительности. Если данные были «холодными» (лежали в таком объектном хранилище как S3), мы всё равно можем добиться требуемой производительности, но для этого нам потребуется инстанс другого типа.
Можно было бы масштабироваться вертикально, но чем больше машины, тем они дороже
Вертикальное масштабирование — это резкий рост расходов. Хотите машину вдвое мощнее? Она может обойтись вам в несколько раз дороже имеющейся.
В облаке всё выполняется на виртуальных машинах, представляющих собой сравнительно мелкие доли гораздо более крупных серверов. Большинство пользователей не интересует, каковы именно размеры этих сегментов, так как мало найдётся таких рабочих нагрузок, для которых требовалось бы задействовать всю машину. В наши дни аппаратное обеспечение настолько мощное, что счёт ядер зачастую идёт на сотни, а память измеряется терабайтами.
В облаке не приходится доплачивать за «крутое железо», поскольку вы и так на нём работаете. Нужна только долька покрупнее. Тарификация у облачных вендоров не растёт пропорционально растущему размеру, так что стоимость использования машины на единицу вычислительной мощности не меняется, на каком бы инстансе вы ни работали — крошечном или гигантском.
Эту задачу проще представить с точки зрения того, сколько стоит выйти на заданный уровень производительности. Ранее более крупные серверы обходились дороже на единицу вычислительной мощности. Сегодня в современных облаках AWS цена за конкретный объём вычислительной мощности остаётся постоянной, пока вы не выйдете на очень большие размеры.

Второе преимущество при работе с облаком — вы избавлены от необходимости держать под рукой запасное оборудование. За это отвечает ваш облачный провайдер. Если ваш сервер откажет, то AWS заново запустит вашу рабочую нагрузку на новой машине, и вы, возможно, этого даже не заметите. Кроме того, провайдер постоянно обновляет аппаратное обеспечение в датацентре, и множество важных улучшений выполняется совершенно без вашего участия.
Архитекторы, работающие с облаками, также обеспечивают разделение хранилищ данных и вычислительных узлов, и именно поэтому на вычислительных инстансах часто хранится минимум данных. Таким образом, в случае отказа можно очень быстро поднять инстанс на замену, и никаких данных при этом перезагружать не придётся. Так снижается потребность в горячем резервировании.
Горизонтальное масштабирование надёжнее вертикального
Архитектуры с горизонтальным масштабированием в целом считаются более надёжными; они проектируются с расчётом на сохранение работоспособности даже в условиях различных отказов. Но в системах с горизонтальным масштабированием не удалось серьёзно повысить надёжность, а при вертикальном масштабировании они обычно отличаются солидной надёжностью.
Определяющую роль для доступности облака часто играют внешние факторы. Например, кто-то может ткнуть не ту клавишу при конфигурировании и обнулить размер кластера (несколько лет назад такая ситуация ненадолго сложилась в BigQuery). Может нарушиться сетевая маршрутизация (именно так случился исторический отказ Google, при котором обвалилось сразу много сервисов). Может лечь сервис авторизации, от которого вы зависите, т.д. Конкретный уровень производительности, задаваемый в SLA, может зависеть преимущественно от этих факторов, и, следовательно, возможны сочетанные отказы (correlated failures), происходящие сразу во множестве систем и продуктов.
Как показывает практика, провайдеры облачных горизонтально масштабируемых баз данных и сопутствующей аналитики обеспечивают SLA уровня 4-9 (доступность в 99,99% случаев). С другой стороны, те, кто работает с собственными вертикально масштабируемыми системами, в течение долгого времени поддерживают не меньший уровень надёжности. Многие банки и другие предприятия пользуются критически важными системами уровней 5- и 6-9, и эксплуатируются эти системы именно на вертикально масштабируемом оборудовании.
Надёжность также зависит одновременно от долговечности и доступности. Критические стрелы в адрес вертикально масштабируемых систем направлены, в частности, на то, что в случае отказа вам потребуется откуда-то взять реплику данных. В принципе, эта проблема решается разделением вычислительных узлов и хранилищ данных. В ситуации, когда конечным пунктом назначения для данных является не та машина, на которой они вычисляются, уже можно не беспокоиться, сколько прослужит данная вычислительная машина. Базовая инфраструктура с разделяемыми дисками, предлагаемая облачными провайдерами, например, EBS или Google Persistent Disk, под капотом опирается на крайне долговечные хранилища. Поэтому можно гарантировать значительную долговечность приложений, не вмешиваясь в их работу.
Как перестать беспокоиться и полюбить одиночные системы
Итак, выше мы рассмотрели, что три основных довода в пользу горизонтального подхода — масштабируемость, стоимость и надёжность — уже не столь весомы, как десятилетия назад. У вертикального масштабирования также есть некоторые подзабытые преимущества, и их мы обсудим ниже.
KISS: KEEP IT SIMPLE, STUPID
Простота. Горизонтально масштабируемые системы значительно сложнее строить, развёртывать и поддерживать. При том, насколько разработчики любят рассуждать о достоинствах Paxos в сравнении с RAFT или CRDTs, сложно что-либо возразить на то, что с внедрением этих технологий система сильно усложняется как в сборке, так и в поддержке. Нам, простым смертным, сложно судить об этих системах, разбираться, как они работают, что происходит при их отказе, и как их восстанавливать.
Вот взятая из Википедии сетевая диаграмма, описывающая «простой» путь Paxos (алгоритма распределённого консенсуса) — отказов здесь не показано. Если вы строите распределённую базу данных и хотите обрабатывать операции записи более чем на один узел, то у вас должно получиться нечто подобное:

Сам протокол здесь не столь важен, как тот факт, что это простейший случай одного из самых элементарных алгоритмов, обеспечивающих распределённый консенсус. На одноузловой системе эти алгоритмы в принципе не нужны.
Писать программы для распределённых систем тупо сложнее, чем для одиночных. В распределённых базах данных приходится предусматривать переброску данных между узлами для объединений, о выравнивании данных по определённым узлам. Одноузловые системы гораздо проще: для объединения данных в такой системе просто создаётся хеш-таблица и ставятся разделяемые указатели. Не будет невзаимосвязанных отказов, после которых пришлось бы восстанавливаться.
Недостатки сложности ощутимы не только для программистов, которые собирают системы. Абстракции текут, поэтому за такие вещи, как согласованность в конечном счёте, сегментирование хранилища и работа с областями отказов приходится отвечать разработчикам и конечным пользователям. CAP-теорема — это реальность, поэтому пользователям распределённых систем приходится искусно лавировать между согласованностью, доступностью, а также иметь план на случай сетевых отказов.
Развёртывать и поддерживать одиночные системы, как правило, гораздо проще. Такая система активна или неактивна. Чем больше в ней динамических элементов, тем больше неполадок может случиться с более высокой вероятностью. В одиночной системе есть всего один узел, на котором приходится искать проблемы, и диагностировать их проще.
PERF: последний фронтир
Если приходится выбирать между быстрым и медленным вариантом, почти наверняка будет выбран быстрый. Одноузловые системы серьёзно выигрывают у распределённых в производительности. Если размышлять о них вне контекста, то с каждым лишним сетевым переходом система определённо будет работать медленнее, чем без него. Если добавить в систему такие вещи, как протоколы согласованности, эта тенденция только усугубится. В одноузловой базе данных транзакция может совершиться за миллисекунду, тогда как в распределённой на такую операцию могут уходить сотни миллисекунд.
Распределённые решения действительно могут улучшать общую пропускную способность, когда система зависит от сети, но они также оказывают на сеть серьёзную дополнительную нагрузку при нетривиальной работе. Например, если требуется объединить два распределённых множества данных (а они при этом не были аккуратно поровну сегментированы), то при перетасовке данных возникнет значительная задержка. В распределённых системах попросту невозможно выполнять произвольные объединения столь же быстро, как на одиночной системе.
В качестве примера, демонстрирующего, почему распределённая архитектура обычно ограничивает производительность, рассмотрим следующую стилизованную архитектурную схему BigQuery:

Петабитная сеть, связывающая все узлы, казалось бы, должна работать быстро, но это всё равно узкое место, поскольку у нас слишком много операций, при которых требуется передавать данные по сети. Большинство нетривиальных запросов зависят от сети. В одноузловой системе потребуется передавать гораздо меньше данных, так как не требуется их перетасовывать.
Надежда на мистера Мура
Мы рассмотрели доводы в пользу горизонтального масштабирования и убедились, что теперь они гораздо менее актуальны, чем когда-то.
Мощность. Современные одноузловые системы огромные и могут справиться почти с любыми рабочими нагрузками.
Надёжность. Горизонтально масштабируемая система необязательно получается более надёжной.
Стоимость. Облачные вендоры не берут дополнительной платы за укрупнение виртуальных машин, так что расти только выгоднее.
Также мы обсудили некоторые достоинства вертикального масштабирования:
Простота. Простые системы легче строить, эксплуатировать и улучшать.
Производительность. Распределённая система всегда характеризуется повышенной задержкой (особенно хвостовой) по сравнению с нераспределённой.
Допустим, сейчас вы не уверены, пойти ли на горизонтальное масштабирование. Но что будет через пять лет, когда машины станут на порядок больше?
Мы готовы к новому поколению решений, которые выведут на новый уровень производительность одноузловых конфигураций. Инновации ускорятся, а вы сможете сосредоточиться на решении задач, а не на координировании сложных распределённых систем.
Приложение. Кратко о Dremel
В этом приложении сравним результаты, полученные в статье Dremel, с прогоном похожей рабочей нагрузки на крупной машине, оснащённой современным оборудованием. Притом, что хорошо было бы получить и продемонстрировать практический результат, о многом можно судить по данным бенчмарков, в том числе, насколько честное сравнение у нас получается. Мы продемонстрируем, что по плечу современному железу.
Авторы статьи работали с кластером Dremel на 3000 узлов. Для справки: такой массив оборудования в BigQuery стоил бы вам более $1M в год. Сравним его с инстансом i4i.metal на AWS, который стоит $96k в год, имеет 128 ядер и 1 терабайт оперативной памяти. Запустим их «по соседним дорожкам» и посмотрим, кто кого.
Вот отрывок из статьи, в котором описано, как были вычислены контрольные точки для сравнения с MapReduce:
Задача 1: SELECT SUM(CountWords(txtField)) / COUNT(*) FROM T1
На следующем рисунке на логарифмической шкале показано, как долго выполняются два задания MapReduce и Dremel. Оба задания MapReduce распределены на 3000 исполнителей. В то же время, для выполнения задачи 1 задействуется 3000-узловой инстанс Dremel. Dremel и колоночная версия MR считывают примерно по 0,5 ТБ сжатых колоночных данных — сравните этот показатель с 87 ТБ, прочитанными строковой версией MR.
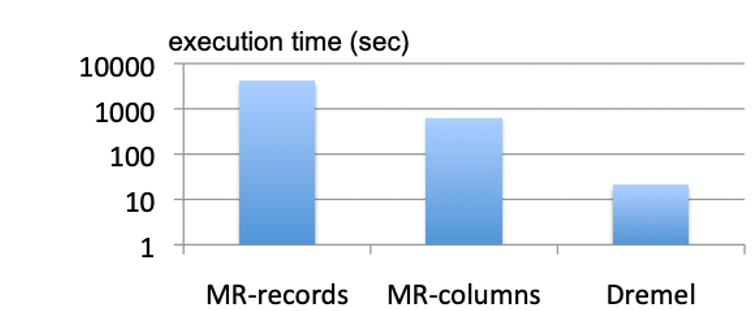
В статье по Dremel главный результат по производительности показал, что система способна примерно за 20 секунд просканировать и агрегировать запрос размером более 85 миллиардов записей, и в ходе этой работы считывается полтерабайта данных. На порядки быстрее, чем в системах, основанных на MapReduce. Кроме того, всё это значительно превосходит результаты, которых можно было бы добиться на традиционных вертикально масштабируемых системах того времени.
Чтобы сравниться с уровнем производительности, приведённым в этой статье, требовалось бы сканировать 4,5 миллиарда строк и считывать 25 гигабайт данных в секунду.
ЦП
В блоге SingleStore когда-то выходил пост, в котором утверждалось, что их система может сканировать более 3 миллиардов строк в секунду на ядро. Соответственно, на машине размером с нашу I4i можно было бы обрабатывать 384 миллиарда строк в секунду, то есть, почти на два порядка больше, чем чтобы угнаться за Dremel. Даже если требуется в 50 раз больше вычислительной мощности, чтобы подсчитать слова в текстовом поле, запас мощности всё равно достаточно комфортный.
ПАМЯТЬ
Полоса передачи данных на единственном сервере, вероятно, будет исчисляться терабайтами в секунду, так что здесь проблем не ожидается. Поскольку данные лежат в памяти «под рукой», мы должны с лёгкостью прочитывать 500 ГБ за 20 секунд. Столбцы, используемые в запросе, займут примерно половину памяти на машине, поэтому, если заранее их кэшировать, у нас в распоряжении останется примерно полтерабайта памяти для обработки данных или для хранения неактивного кэша. Но кажется, что это не совсем честно, ведь здесь требуется заранее знать, сколько именно столбцов понадобится для хранения запроса в памяти.
ЛОКАЛЬНЫЙ ДИСК
А что, если хранить нужные нам данные на локальном SSD? Во многих базах данных, например, Snowflake, локальные SSD-диски служат оперативным хранилищем локальных данных. На серверах I4i суммарно есть 30 ТБ энергонезависимой экспресс-памяти в SSD. Таким образом, на твердотельный диск можно кэшировать в 30 раз больше данных, чем в памяти, и в 60 раз больше, чем для рассматриваемого здесь запроса. Вполне рационально попробовать кэшировать активные столбцы данного запроса именно на SSD.
Если вместимость не проблема, то что насчёт пропускной способности? Диски с энергонезависимой экспресс-памятью работают быстро, но достаточно ли? В описываемых случаях позволяют выполнять суммарно 160 тысяч IOPS-операций в секунду, где максимальный размер каждой операции — 256 КБ. Таким образом, можно читать со скоростью 40 ГБ/с, то есть в 25+ раз больше, чем нам требуется. Запас не так велик, но модель работоспособна.
ОБЪЕКТНОЕ ХРАНИЛИЩЕ
Наконец, что если бы мы захотели работать в «холодном» режиме, где никакие данные не кэшируются? В конце концов, одно из основных достоинств Dremel заключалось в возможности считывать данные прямо из объектного хранилища. Здесь мы сталкиваемся с ограничением: сетевая мощность у инстанса I4i ограничена 75 гигабит/с или примерно 9 ГБ/с. Это примерно треть из того, что нам потребовалось бы напрямую считывать из объектного хранилища.
Есть инстансы, обладающие гораздо большей пропускной способностью (по памяти): так, у инстансов TRN1 по 8 100-гигабитных сетевых адаптеров. Таким образом, можно работать со скоростью 100 ГБ/с, что значительно превышает нашу потребность.
Конечно, сам факт доступности нужного оборудования на машине ещё не означает, что оно будет равномерно доступно, и что производительность будет расти линейно с увеличением числа ядер. Операционные системы не всегда качественно справляются со множеством ядер, блокировки плохо масштабируются, а программы нужно писать очень грамотно, чтобы где-нибудь не врезаться в стену.
Суть не в том, чтобы сравнивать относительную эффективность различных систем; в конце концов, эти замеры производились 15 лет назад. Но, надеюсь, мне удалось показать, что при приближении рабочих нагрузок к датасету размером около 100 ТБ разумнее оперировать ими на нераспределённой системе.