
Всем привет, меня зовут Катя Гущина, я Android-разработчик hh.ru. Хочу поделиться нашим опытом отказа от kapt в пользу ksp для обработки аннотаций и ускорения скорости сборки в большом проекте. В этой статье расскажу, что такое ksp, почему мы решили на него перейти, как проводили исследование и что из этого получилось.

Спойлер результатов
Было много боли, но у нас получилось ускорить сборку на 10%.

Сейчас будет немного теории
Расскажу совсем немного о ksp. Ksp — Kotlin Symbol Processing — это API Kotlin, с помощью которого можно написать свой плагин для компилятора. Также можно рассмотреть ksp как API для препроцессинга кода на Kotlin — такой подход мне нравится немного больше.
Чтобы получить информацию о коде с помощью ksp, нам нужно реализовать свой процессор. Внутри этого процессора мы можем получить информацию о файлах, классах, функциях, свойствах и тд, а также о любых символах, помеченных аннотацией. Однако, стоит иметь в виду, что мы не сможем узнать о том, что происходит внутри метода, так как это API не дает никакой информации на уровне выражений.
А ещё, в отличие от полноценных плагинов компилятора, мы не сможем изменить код. Однако, на основе полученных данных, мы можем сгенерировать новый код — например, записать помеченные аннотацией классы в файл.
Какие преимущества есть у ksp перед kapt? Прежде всего, хочется отметить, что kapt — это Kotlin-плагин для работы с apt. Так как apt все равно работает с Java, появляется вынужденный этап генерации Java stubs (заглушек) для Kotlin-классов. API ksp, напротив, заточено и оптимизировано под Kotlin, но при этом достаточно гибко, чтобы в будущем можно было использовать этот подход и на других платформах.

Для того, чтобы наглядно понять преимущества ksp перед kapt, в качестве примера посмотрим на наш build scan на CI. На нем можно увидеть, что таска kapt-а для генерации заглушек занимает второе место по времени выполнения. По сути, она является своеобразным бутылочным горлышком для сборки, от которого как раз может помочь ksp.
При этом ksp — это не единственный вариант избавления от генерации заглушек. Есть и другие подходы — например, napt. Автор этой идеи подробно рассказал в своём видео о том, зачем генерируются заглушки и как можно от них избавиться.
Некоторое время назад мы исследовали возможность внедрения napt в наш проект и даже получили хороший прирост скорости сборки, порядка 17%. Однако приняли решение пока не внедрять, поскольку даже такой хороший результат не окупал все риски и затраты на исправление проблем. Например, мы ловили ошибки от Room, Toothpick, ломался configuration cache.
Возвращаясь к ksp, хотелось бы отметить утверждение, указанное в официальной документации. Авторы считают, что процессоры аннотаций, написанные на ksp, в теории могут работать в два раза быстрее, чем на kapt. В реальности всё выглядит немного иначе, например, в одном из разделов документации можно увидеть результаты для Glide — скорость сборки выросла на 25%. Очень захотелось проверить на практике, какой результат получится у нас.
Почему мы решили попробовать перейти на ksp
Наш проект довольно крупный: примерно 400 модулей на два приложения. В большинстве из них используется Toothpick, которому, в свою очередь, необходим kapt. В некоторых модулях мы использовали библиотеку ClassIndex на kapt, а также Room, Glide и Permission Dispatcher. В некоторых старых модулях ещё осталась Moxy, которой тоже требуется kapt.
Оценив ситуацию, мы обнаружили множество мест, которые можно оптимизировать с помощью ksp. Надеясь на высокие результаты, мы всё же были настроены немного скептически, поэтому поставили себе планку прироста скорости сборки в 10%. Наш настрой был обусловлен тем, что обещанное ускорение в 25% и выше — это локальное ускорение в рамках кодогенерации. Пусть кодогенерация и занимает много времени, но нельзя забывать и про другие этапы сборки, в которых она не участвует. В любом случае, переездом мы их не затронем. Поэтому прогноз на общее ускорение сборки был меньше указанного в документации процента.
В пользу перехода на ksp также сыграло и то, что kapt периодически флакует, из-за чего приходится пересобирать проект. И немаловажным фактором стало активное развитие ksp силами JetBrains и Google. Kapt же сейчас находится в режиме вялой поддержки — критические обновления всё ещё выходят, но никакой новой функциональности больше добавлять не планируется. В документации JetBrains открыто мотивирует разработчиков переходить на более эффективный инструмент в лице ksp.
Исследование перехода на ksp
Прежде чем делать полноценный переход, хотелось быть абсолютно уверенными в том, что мы не потратим время впустую. Поэтому сначала решили провести исследование, и уже по его результатам выносить вердикт — будем ли мы проводить миграцию или нет.
Нашей целью было как можно быстрее и жестче собрать проект, безотносительного того, как при этом приложение работало в рантайме, поскольку нам было необходимо получить высокоуровневую оценку профита.
В рамках исследования мы хотели:
Оценить эффективность замены kapt на ksp, понять, соответствует ли она ожидаемым результатам
Составить список библиотек, которые можно перевести на ksp: либо уже есть версия на ksp, либо быстро можно перевести на ksp самостоятельно
Понять, какие доработки библиотек потребуются
Выявить возможные сложности в реализации
Оценить времязатраты, а также соответствия потраченного времени с получаемым профитом
Для оценки эффективности мы использовали специальный план на CI, который замеряет время сборки с помощью gradle-profiler.
Сначала этот план делает несколько разогревающих прогонов, которые не учитывает в дальнейших расчётах. Для минимизации расхождений все сборки прогоняются на одной машине. У нас имеется три сценария сборки:
чистая сборка;
инкрементальная сборка core-модуля;
инкрементальная сборка feature-модуля.
Мы использовали именно такие варианты по ряду причин. Чистая сборка наиболее показательна, так как проект пересобирается полностью, и build cache не используется. При инкрементальной сборке пересобирается только часть модулей, например, для feature-модуля только он сам, а для core-модуля пересобирается ещё и та часть модулей, что от него зависит. Таким подходом мы покрываем почти все варианты сборки. В итоге для каждого выбранного коммита собирается полная статистика — среднее, медиана, по перцентилям etc.
По итогам исследования мы получили около 10-15% ускорения сборки, что было оценено нами как успешный результат. Был составлен план, какие библиотеки и в какой последовательности мы можем перевести, а также какие доработки нам для этого потребуется сделать. Помимо этого были оценены трудозатраты и риски.
Полученные результаты исследования были представлены коллегам на обсуждение, после чего мы все-таки решили мигрировать с kapt на ksp.
Последовательная реализация перехода
Переход мы решили осуществлять последовательно, разбив на несколько частей. В первой части — библиотеки Toothpick + ClassIndex, во второй — Room, Glide и Permission Dispatcher. В дальнейшем ещё думали потихоньку уходить от Moxy. Тут сразу стоит подчеркнуть, что мы уже давно не используем эту библиотеку в новых фичах, просто пока что она осталась в некоторых старых.
Из важных моментов, которые хотелось бы отметить, мы решили либо переводить модуль полностью на ksp, либо оставлять kapt, так как если использовать и ksp, и kapt вместе, мы рискуем только замедлить сборку.
В этой главе подробнее расскажу о первой части, в которой мы внедряли ksp версию Toothpick и реализовывали аналог ClassIndex на ksp.
Toothpick — это runtime DI фреймворк, и поскольку на проекте он используется почти повсеместно, мы решили начать именно с него. Библиотека для процессинга на ksp для Toothpick уже была — её реализовала компания Bedrock Streaming, автор Baptiste Candellier. Хочется выразить ребятам благодарность за классную библиотеку и оперативность в принятии пул-реквестов.
В процессе исследования и работы над переходом в библиотеке было выявлено несколько багов, которые мы уже поправили и законтрибьютили в библиотеку, так что если вы тоже используете Toothpick, можете смело внедрять обкатанный нами Toothpick ksp.
Считаю важным отметить один момент, который очень помогал при исправлении багов в библиотеке — это unit-тесты. Крайне удобно было писать их в библиотеке, чтобы вносить изменения и быстро проверять — так как заново запускать сборку всего проекта это довольно дорого. Первое время мы не до конца понимали, что именно работает некорректно и как это пофиксить, поэтому частые пересборки проекта были бы неизбежны.
Далеко не все используют Toothpick в своих проектах, поэтому хочется немного упомянуть и другие DI framework-и. Если посмотреть в сторону Dagger, пока четких новостей нет, но работа над переводом на ksp потихоньку ведется, контрибьюторы Dagger уже рассказывают о том, как надо будет подготовить кодовую базу, чтобы переход на ksp в будущем прошел без проблем.
Соответственно, в Hilt пока тоже нет поддержки ksp, а вот Koin может похвастаться данным бонусом.
Следующий шаг — реализовать свой аналог библиотеки ClassIndex на ksp. По сути, она представляет собой обработчик аннотаций для получения в runtime-е списка классов из проекта по какому-либо критерию. Мы использовали эту библиотеку, чтобы найти в проекте все эксперименты. Ранее мы рассказывали об этом подробно в статье о feature-флагах.
На примере этой библиотеки ClassIndex мы немного погрузимся в детали реализации, чтобы получить представление о том, как написать свой процессор.
Пишем свой ksp-процессор (на примере библиотеки для обработки аннотаций)
class AnnotationProcessorProvider : SymbolProcessorProvider {
override fun create(environment: SymbolProcessorEnvironment): SymbolProcessor {
return AnnotationProcessor(environment)
}
}Точкой входа при написании своего обработчика является реализация провайдера для процессора (SymbolProcessorProvider), который создаст нам экземпляр нашего процессора (SymbolProcessor).
class AnnotationProcessor(val environment: SymbolProcessorEnvironment) : SymbolProcessor {
override fun process(resolver: Resolver): List<KSAnnotated> {
...
}
}Внутри основного метода процессора у нас есть доступ к классу Resolver, через который можно получить информацию о деталях компилятора, например, о символах.
В целом, на ksp было бы достаточно просто найти все классы, помеченные аннотацией, использовав всего один метод —getSymbolsWithAnnotation, но для нас он немного не подходил. У нас был базовый интерфейс, помеченный аннотацией, и мы хотели найти все его реализации. Для этого мы получили все классы, и у каждого проверяли всех родителей в цикле, до того момента, пока не найдем родителя с нашей аннотацией. А полученные результаты записывали в файл.
Наш пример — собираем все подклассы
private fun Resolver.findSubclasses(): Map<KSClassDeclaration, List<KSClassDeclaration>> {
return getAllFiles()
.map { it.declarations }
.flatten()
.filterIsInstance<KSClassDeclaration>()
.mapNotNull {
val annotatedParent = it.getAnnotatedParent()
if (annotatedParent != null) {
annotatedParent to it
} else {
null
}
}
.groupBy(
keySelector = { it.first },
valueTransform = { it.second }
)
}Разберем код нашего примера. Здесь мы с помощью Resolver получаем все файлы, и затем уже работаем просто со списком этих файлов — получаем декларацию и фильтруем список, получив только классы.
Если мы хотим проверить, помечен ли класс аннотацией, можем воспользоваться методом isAnnotationPresent:
declaration.isAnnotationPresent(CollectSubclasses::class)И затем мы пишем имена полученных классов в файл с помощью SymbolProcessorEnvironment.:
val file = environment.codeGenerator.createNewFile(
dependencies = Dependencies(
true,
*sourceFiles.toList().toTypedArray(),
),
packageName = "META-INF/services",
fileName = getFileName(parentClass),
extensionName = ""
)
file.write(fileText.toByteArray())Как видите, API у ksp достаточно простое и интуитивно понятное, по крайней мере для базовых задач.
Статус перехода
На первом этапе мы перевели большую часть модулей на ksp, ещё раз измерили прирост и продолжили работу над дальнейшим переходом. Через некоторое время мы перевели на ksp почти все оставшиеся библиотеки: Room, Glide и Permission Dispatcher, и получили ещё немного прироста в скорости сборки. На текущий момент непереведенными остаются только модули на Moxy — мы посчитали нецелесообразным переводить их только для ускорения скорости сборки. Сейчас они ждут подходящего момента — когда потребуется рефакторинг, например, будет редизайн или частичное изменение функциональности.
Результаты
Результаты на соискательском приложении
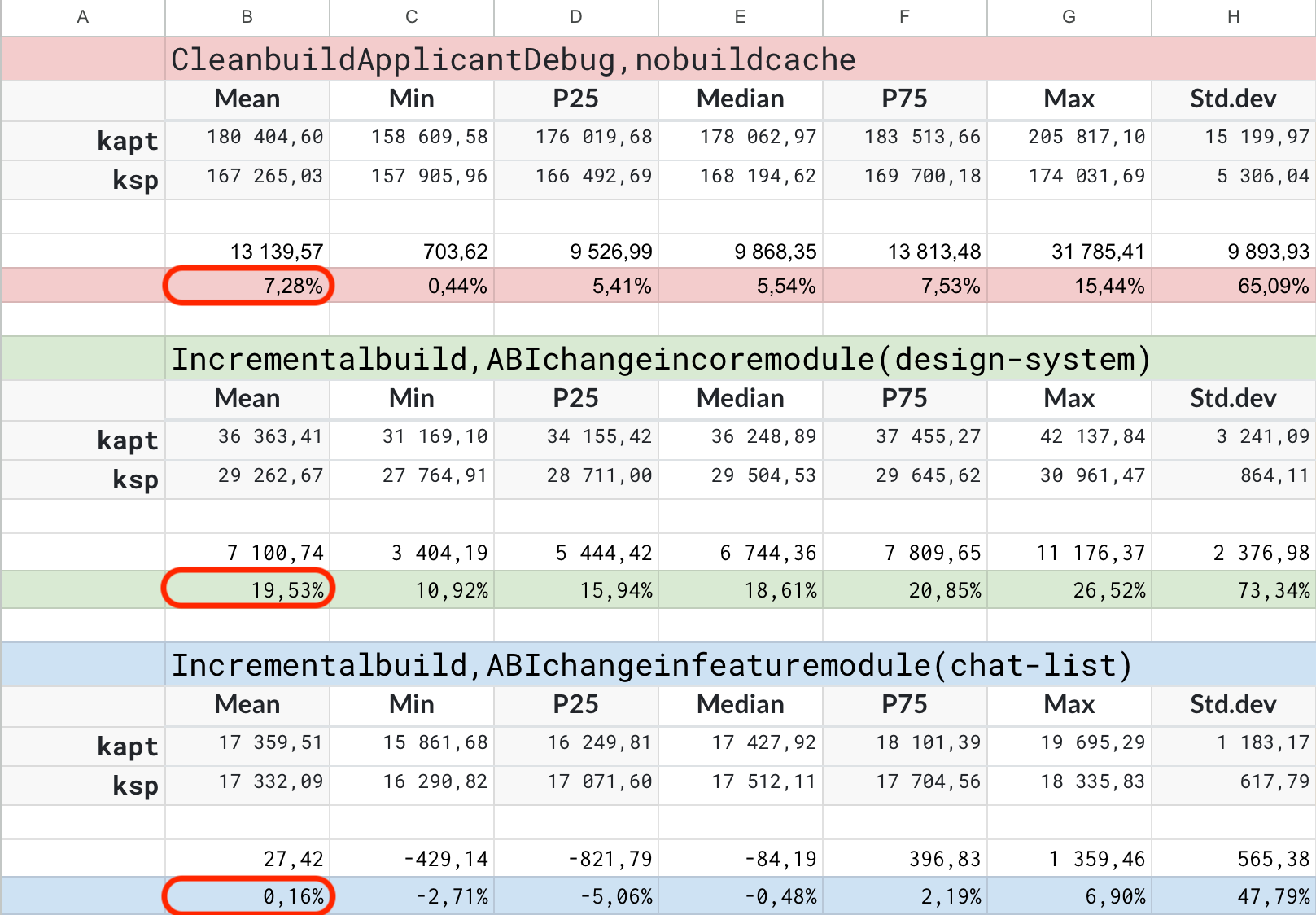
Рассмотрим среднее значение полученных результатов в разрезе нескольких сценариев сборки и двух приложений. Например, в соискательском приложении мы получили прирост в скорости около 7% на чистой сборке. Предположительно, такой невысокий прирост связан с тем, что в этом приложении ещё осталось некоторое количество модулей с Moxy. Если посмотреть на инкрементальную сборку core-модуля, то здесь мы уже получили результат порядка 19,5%. А вот в инкрементальной сборке feature-модуля результат был равен почти нулю. Скорее всего, в обоих случаях — с core-модулем и feature-модулем — имел место некоторый выброс.
Результаты на работодательском приложении
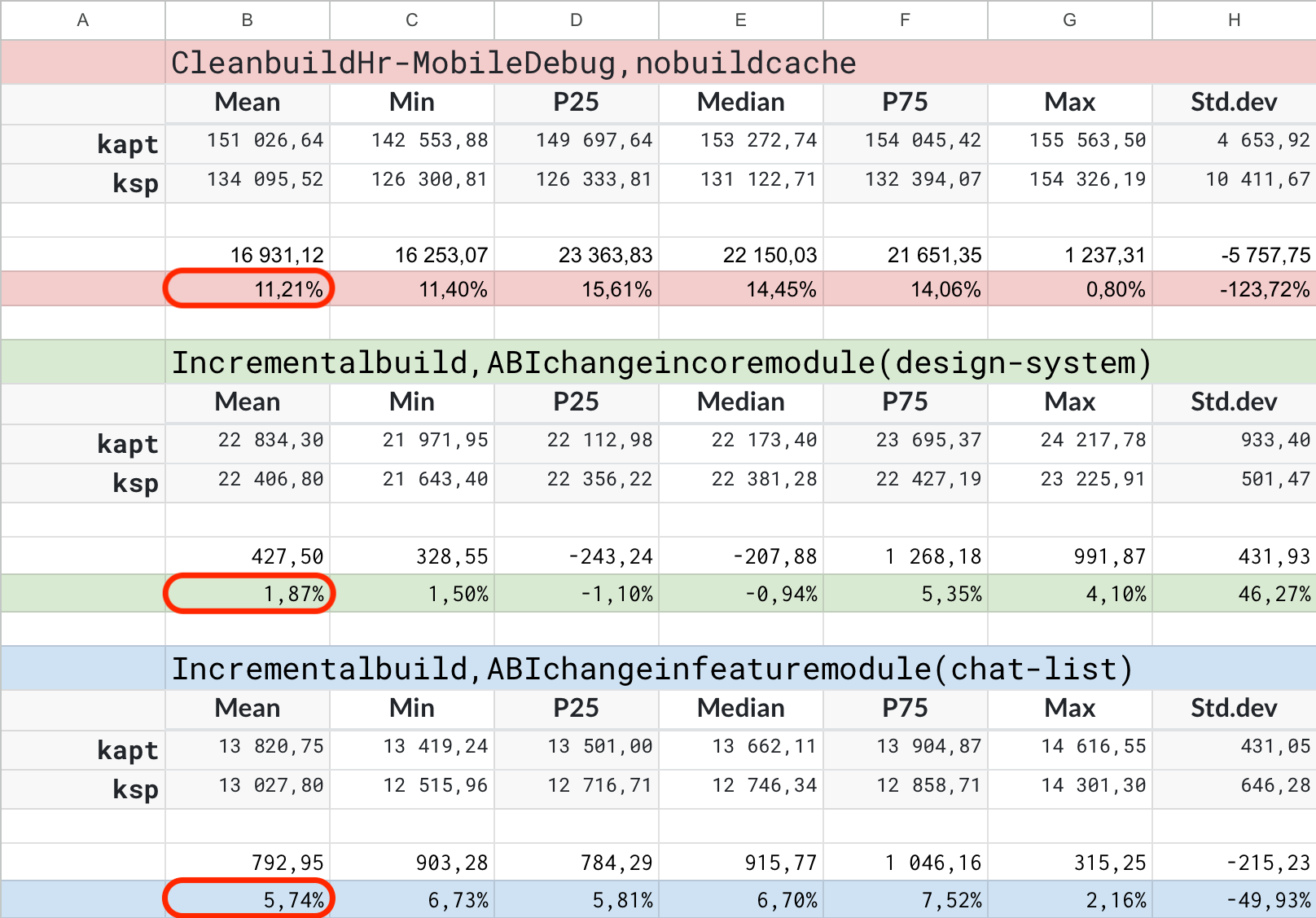
В работодательском приложении результаты несколько другие. Чистая сборка собиралась быстрее на 11% — выглядит как хороший результат. Скорее всего это связано с тем, что в работодательском приложении как раз не осталось Moxy. Инкрементальные сборки, к сожалению, уже не показали высоких результатов — 2% и 6% для core- и feature-модуля соответственно.

По итогу общий прирост составил порядка 10%. Однако оценить его оказалось куда сложнее, чем мы думали. Разброс эффективности был довольно большим, а результаты — нестабильными и изменялись от прогона к прогону. Например, со старых данных, которые были получены в результате исследования, мы могли получить 25-30%, а в некоторых прогонах порой возникали отрицательные результаты.
Некоторое время пришлось потратить на выявление и обсуждение возможных причин такого разброса. Найти какую-то конкретную причину в ksp или в неполной миграции на него нам не удалось — выглядит так, что иногда ухудшение или прирост скорости сборки не зависит от используемого подхода. Если посмотреть на время сборки одного и того же коммита, но на разных прогонах, можно увидеть, что оно достаточно волатильно само по себе. Получается так, что Gradle в целом не выдает особо стабильных результатов. Например, потому что распараллеливание тасок всегда происходит немного по-разному.
Также мы рассматривали прогоны по таскам в build scan-е. Например, одна из чистых сборок имела около 8,5 секунд на все ksp + kapt таски, в противовес чисто kapt таскам — 10 секунд. Естественно, настолько красивого прироста на общей скорости сборки мы не видим за счёт распараллеливания, но просмотр по таскам позволил убедиться, что мы точно ничего не упустили и не получили ошибочных результатов.
Прирост скорости сборки в 10% мы считаем эффективным, так как на нашем проекте довольно много разработчиков, плюс постоянно крутится несколько планов на CI, поэтому даже не слишком большой процент кумулятивно экономит нам человекочасы каждый месяц.
Мысли на десерт
Я, как продуктовый разработчик, нечасто занимаюсь задачами такого крупного калибра. По мере работы над проектом я столкнулась с некоторыми трудностями, которыми мне хочется поделиться.
Большое количество мелочей и сложностей, не связанных с самим ksp, частенько вгоняли в дизмораль. Так как изначально в оценку мы закладывали только небольшие риски на работу с библиотеками, каждая новая проблема добавляла тревожности, поскольку увеличивала срок, потраченный на задачу. Этого можно было бы избежать, заложив большие риски изначально, так как задача крупная, и непредвиденных ситуаций может быть много. Еще снизить тревожность можно, если потихоньку учиться проще относиться к превышению сроков, ведь все мы живые люди и не можем учесть вообще всё заранее.
В таких задачах мы обычно сталкиваемся с большим количеством monkey-job, из-за которого глаз сильно замыливается. Как это можно решить: например, частично автоматизировать процесс. Однако, стоит иметь в виду, что очень важно не переборщить с автоматизацией, иначе мы рискуем получить вместо одной большой задачи целых две. В идеале стоит автоматизировать хотя бы 30%: написать простой код, который заменяет строчки, а не заморачиваться с плагином. Ещё можно разбивать такую работу на небольшие блоки. И ещё всегда лучше коммититься как можно чаще, а потом засквошить кучу коммитов в один, чем потерять половину изменений в процессе, потому что студия решила вылететь прямо посреди замены зависимостей.
Но самой важной для меня была поддержка коллег, которая не позволила погрузиться в пучину отчаяния и самобичевания. Классные и ламповые коллеги, делящиеся своим опытом — бесценно.
Работа над этой задачей многому меня научила. Несмотря на то, что после реализации чувствовалась сильная усталость и некоторое выгорание по отношению к таким крупным техническим проектам, мне всё равно было очень интересно во всё это погружаться и проводить исследования. И ещё было очень приятно получать от коллег положительные отзывы о полученных результатах.
Надеюсь, эта статья была вам полезна. Возможно, вы тоже переезжали на ksp или планируете переезд? Делитесь в комментариях своими историями. Будем на связи.
Всем легкого кодинга и быстрой сборки!