
В предыдущей части мы разобрали, как можно улучшить качество предсказаний SAM и ускорить её работу. Мы уже упоминали, что SAM — это фундаментальная модель, а значит, она может использоваться не только для сегментации, но и легко адаптироваться для решения других задач компьютерного зрения. Сегодня мы рассмотрим, как SAM может применяться для решения таких задач, как inpainting, tracking, 3D-сегментация и 3D-генерация, а также увидим, как SAM работает на датасетах из медицинской сферы и сравним дообученую модель с базовыми весами. А еще мы поделимся своим опытом и расскажем, как SAM облегчила нам разметку данных при сборе датасета бьитюфикации изображений.
Grounded Segment Anything
Как упростить работу с моделью SAM?
Первое, что приходит в голову, это немного автоматизировать процесс выделения интересующих объектов. Вместо того чтобы выделять каждый объект по отдельности для получения масок, можно использовать модель детекции.
В работе Grounded Segment Anything авторы предложили идею использовать модель Grounding DINO для детекции всех интересующих нас объектов, описанных в промпте. Все боксы подаются на вход SAM, и на выходе мы получаем маски для всех наших объектов, которые мы запросили.
Архитектура Grounding DINO состоит из 2-х основных блоков:
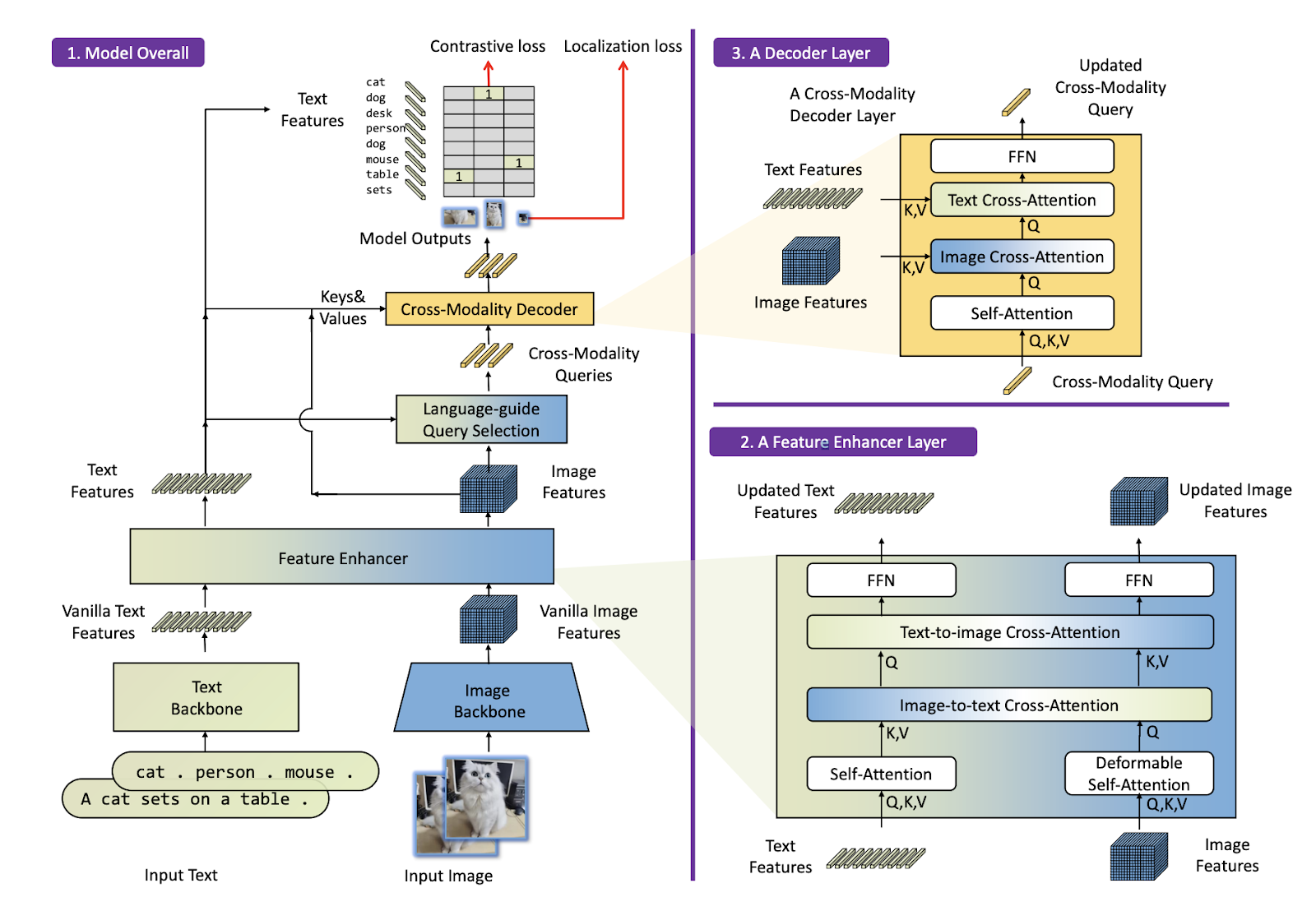
Feature Enhancer Layer соотносит признаки изображения с признаками текста с помощью подряд идущих Cross Attention механизмов. На слое Image-to-text Cross-Attention из изображения берутся запросы, а ключи и значения — из текста, тем самым из признаков текста берется информация об объекте. На следующем слое Text-to-image Cross-Attention происходит то же самое, только наоборот — теперь признаки изображения берутся для текста. На выходе мы получаем новые признаки текста и изображения, насыщенные информацией друг о друге.
Decoder Layer получает на вход Cross-Modality Query, эти запросы включают в себя информацию о нахождении объектов на изображении и их локализации. Осталось только соотнести это с информацией из текста, и мы получим фичи искомого объекта, а далее можем предсказать его обрамляющий прямоугольник (bounding box).
С эти подходом вам больше не придётся тратить время, выделяя каждый объект по отдельности, за вас все сделает Grounding DINO.

Inpaint Anything
Сегментация объектов — это, конечно, круто, но что делать с этими сегментами дальше?
Например, заменить этот объект на какой-нибудь другой. Авторы работы Inpaint Anything: Segment Anything Meets Image Inpainting сделали гениальную и простую вещь — с помощью модели LaMa (Large Mask Inpainting), дополнительного промпта и масок из SAM можно заменять сегмент на изображении на другой. Либо заменить фон, инвертируя маску, либо же совсем удалить объект с изображения. К сожалению, одним промптом сделать это нельзя, от пользователя требуется сначала выделить нужный объект, а потом уже написать промпт для Inpainting-модели.
Идея очень вариативна, вы можете вместо базового SAM использовать любую архитектуру на его основе, о некоторых мы рассказали в первой части статьи. А вместо модели LaMa можно использовать Stable Diffusion, обученные на задаче Image Inpainting.

Segment And Track Anything
На этом идеи не заканчиваются. Если мы умеем сегментировать нужные нам объекты на изображении, то мы можем и сегментировать их на видео, а ещё лучше — трекать их! Именно с такой идеей и была написана работа Segment And Track Anything, в пайплайне которой три модели. Но давайте по порядку.

Для начала нам нужно выделить интересующий нас объект или несколько объектов. Это можно сделать либо вручную, с помощью бокса и кликов, либо используя текстовый промпт, с помощью которого модель Grounding DINO предскажет боксы всех интересующих объектов. Всё решение можно разделить на два этапа:
Для первого кадра от пользователя требуется выбрать все интересующие объекты, с помощью которых SAM предскажет маски. Далее эти маски передаются на вход DeAOT вместе со следующим кадром — для предсказания его масок.
После сегментации первого кадра трекинг работает в автоматическом режиме, используя подсказки, полученные для первого кадра. Маски, предсказанные SAM, комбинируются с предсказаниями DeAOT с помощью алгоритма Comparing Mask Results (CMR).


SAM3D
Одними 2D-изображениями использование SAM не ограничивается. Модель также успешно применяется для работы с 3D-данными: в SAM3D: Segment Anything in 3D Scenes авторы используют SAM для предсказания маски для 3D-облака точек.
SAM3D работает следующим образом:
С помощью оригинального SAM для каждого отдельного фрейма сцены, представленного в виде RGB-изображения, предсказывается 2D сегментационная маска. Если один пиксель покрывается несколькими масками, то ему присваивается маска с наибольшим IoU;
2D-маска проецируется в 3D, согласно глубине каждого пикселя, полученного из RGB-D-изображения;
Все 3D-маски отдельных частей сцены (фреймов) постепенно объединяются в 3D-маску всей сцены целиком: на каждом шаге сливаются маски сопряженных фреймов при помощи алгоритма Bottom-Up merging.
Примечательно, что подход SAM3D не требует дополнительного обучения SAM: используются веса оригинальной модели.

Anything-3D
Ещё один интересный пример использования SAM для 3D-данных приведён в статье Anything-3D: Towards Single-view Anything Reconstruction in the Wild, где представлена модель, создающая 3D-реконструкцию объекта по одной RGB-картинке.
SAM используется на начальном этапе для сегментации картинки, затем BLIP используется, чтобы получить текстовое описание, а далее применяется диффузионная модель для генерации 3D-модели объекта в виде NeRF’а.
SAM никак не дообучается, используются только оригинальные веса.

Как SAM прокачал задачу сегментации в медицине
В статье How Segment Anything Model (SAM) Boost Medical Image Segmentation: A Survey сравнивают работу SAM и state-of-the-art моделей в медицинских задачах. Вот несколько случаев, когда SAM смог показать лучший результат:
SAM Meets Robotic Surgery: An Empirical Study in Robustness Perspective (Слабонервным не смотреть!!!)
В данной статье рассматривается задача сегментации хирургических инструментов во время сложных хирургических вмешательств. Для решения данной задачи были собраны два датасета — EndoVis17 и EndoVis18 — которые состоят из картинок и бинарных масок хирургических инструментов.
Авторы привели результаты нескольких моделей на архитектурах Unet и ResNet50, а также результаты модели SAM. Тесты проводились на датасете с использованием разных аугментаций для ухудшения качества исходной картинки, однако SAM смогла показать лучшие результаты с BBox-подсказкой без дообучения или изменения архитектуры.

Polyp-SAM: Transfer SAM for Polyp Segmentation
В данной статье авторы решили дообучить SAM для улучшения качества предсказанных сегментов. Было использовано два метода: заморозка энкодера и дообучение только декодера масок, либо дообучение всей сети целиком. Тесты показали, что достаточно доучить только энкодер масок для достижения хороших результатов, которые авторы привели в сравнении.

Модель тестировали на четырех датасетах, качество измеряли метриками DSC и mIoU. Из результатов видно, что полностью дообученная модель ненамного лучше, чем модель с дообученным декодером.
Результаты сравнили с другими моделями на датасете CVC-Colon DB, и модель Poly-SAM показала лучшие результаты в 0,9 DSC и 0,85 mIoU для Vit-B энкодера и 0,80 DSC и 0,82 mIoU для Vit-L энкодера соответственно.

Исходя из экспериментов, описанных в статье How Segment Anything Model (SAM) Boost Medical Image Segmentation: A Survey, можно сделать вывод, что SAM с базовыми весами справляется с задачей Zero-shot Medical Image Segmentation либо сопоставимо с другими моделями, либо хуже. SAM была обучена на огромном количестве данных и является базисной моделью, которая требует дообучения на одном или нескольких датасетах для достижения хороших результатов.
Как мы применяем SAM
SAM отлично решает задачу автоматической сегментации. Её можно использовать при разметке новых датасетов для задачи сегментации, однако фактор ошибки модели всё ещё присутствует. В сервисе разметки ABC Elementary уже используется SAM для разных задач: дополнительная полуавтоматическая разметка для последующей агрегации, а также пред-разметка для её последующей коррекции пользователем, и пред-разметка для простых задач с последующим обучением нейронных сетей.

С помощью этого сервиса был подготовлен датасет EasyPortrait для задач сегментации изображений и бьютификации, на котором мы обучили базовые модели для вырезания заднего фона и объекта переднего плана (в данном случае – человека), а также модели бьютификации (изменение цвета глаз, губ, бровей), что станет частью сервиса видеоконференций SberJazz.

Заключение
Модель SAM — это мощный инструмент для решения многих задач компьютерного зрения. Ее можно использовать в любых сферах, в том числе в медицине, но для достижения лучшего качества в поставленной задаче требуется дообучение на датасете определённого домена. С уверенностью можно сказать, что SAM позволит автоматизировать процесс ручной разметки и сегментации нужных объектов на изображении и послужит отличным помощником для решения других задач компьютерного зрения.
Подписывайтесь на нашу группу RnD CV, чтобы оставаться в курсе последних новостей компьютерного зрения и отслеживать успехи нашей команды.
Авторы
Александр Капитанов @hukenovs
Нагаев Александр @nagadit
Елизавета Петрова @kleinsbotle
Ссылки
Grounding_DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Anything-3D: Towards Single-view Anything Reconstruction in the Wild
How Segment Anything Model (SAM) Boost Medical Image Segmentation: A Survey
SAM Meets Robotic Surgery: An Empirical Study in Robustness Perspective
LaMa: Resolution-robust Large Mask Inpainting with Fourier Convolutions
EasyPortrait -- Face Parsing and Portrait Segmentation Dataset