
Каждая компания непрерывно производит и хранит кучу данных, и это вызывает множество проблем. Объёмы хранилищ не бесконечны, как и ресурсы железа. Вот только оптимизация обработки и хранения данных не всегда приносит желаемые результаты. Как всё настроить так, чтобы значительно сократить объём занимаемый ими на диске?
У нас получилось! Мы снизили количество данных на диске в 3 раза, при этом ускорив их обработку. И сейчас расскажу как. Меня зовут Александр Маркачев, я Data Engineer команды Голосовой Антифрод в beeline. В статье затронем тему форматов ORC и Parquet, как их правильно использовать и хранить, чтобы всем было хорошо.

Данные и форматы
Всего в мире на текущий момент 97 зеттабайт данных и ежедневно генерируется ещё порядка 220 Тбайт. К 2025 году ожидается двукратный рост текущих данных.

В этом плане билайн не исключение. У нас растут данные как за счёт новых данных, так и за счёт обработки и обогащения старых. Одна из задач дата-инженера — эффективно управлять этими данными для того, чтобы они занимали мало места и в то же время были легкодоступны. Поэтому важно уметь работать с форматами данных.
Всего форматов огромное множество: JSON, CSV, Aura и многие другие, но не все они подходят для хранения и быстрого доступа. Они либо занимают слишком много места, либо работа с ними идёт очень медленно. Бывает и то, и другое.
Однако среди них выделяются два формата — ORC и Parquet. Они прекрасно подходят как для хранения, так и для обработки данных, но у них свои плюсы и минусы. Поэтому мы задали несколько метрик качества, по которым можно их оценивать — исходя из того, как мы используем обычно данные, ваши метрики могут быть другими. Вот основные из них:
Считывание отдельных столбцов;
Статистика по столбцам;
Изменение порядка столбцов;
Добавление столбцов;
Поддержка типов данных;
Скорость доступа;
Сжатие.
Структура
Чтобы понимать, как устроены форматы и как их правильно использовать, необходимо определиться со структурой.
Структура файла Parquet
Parquet был создан в марте 2013 года и изначально поддерживал многие языки программирования (не только JVM-подобные) и сам поддерживался многими системами. На текущий момент его используют такие гиганты, как Amazon, Cloudera, Netflix, Apple, билайн.
Структура файла Parquet на официальном сайте выглядит так:

Есть заголовок, группы строк, участки колонок и страниц. Чтобы не путаться в этом страшном графике, разберём его подробнее:

Начинается файл с File Header. Он содержит магическое число PAR1, которое позволяет прочитать и определить, что это Parquet-файл для его дальнейшей оптимизации.
Заканчивается File Footer’ом, который содержит:
Метаданные (определение схемы, информация о группах строк, метаданные о столбцах);
Дополнительные данные, например, местоположение словаря для столбца;
Статистику по столбцам.
Между File Header и File Footer находятся группы строк — Row-group. Это разбиение одного конкретного файла на множество маленьких блоков для того, чтобы в случае необходимости не приходилось вычитывать весь огромный файл. Предположим, вы записали в него 17 Гб. Чтобы ради 10 строк не вычитывать весь файл, мы разбиваем его на группы и читаем только первую.
Но и этого мало. В Parquet есть также разбиение по колонкам — Column Chunk. Каждую колонку можно прочитать отдельно, что важно для широких таблиц.
Колонки же делятся на группы страниц — Page. Это уже физическое представление данных, набор значений для каждого столбца в файле. Page имеет собственное описание схемы данных, которое указывает на тип данных, размер конкретной страницы и способ кодирования. Также как в Row-group, там возможны ссылки на словарь для того, чтобы декодировать данные.
Структура файла ORC
ORC был создан на месяц раньше, чем Parquet, но ему не повезло. Он поддерживал только JVM-языки и был предназначен именно для Hive. В 2016 году его доработали, он стал поддерживать C-подобные клиенты и сам стал поддерживаться многими системами. Сейчас ему внедрили поддержку в Impala. У него очень расширился диапазон применения и пользы. Создатели его постоянно совершенствуют. Им пользуются такие гиганты как Facebook, Twitter, Netflix, Amazon, билайн. Вы могли заметить, что некоторые компании повторяются. Дело в том,что в зависимости от ситуации используются разные форматы. Абсолютно правильного решения нет.
Структура ORC выглядит ещё страшней, чем структура Parquet:

Тут также есть заголовки, страйпы (они же полосы), участки колонок и страниц, а ещё postscript.

Также, как Parquet, ORC начинается с File Header. Только этот File Header уже содержит магическое число ORC, что позволяет нам прочитать его как ORC-файл. Но в отличие от Parquet ORC заканчивается postscript, потому что он содержит не все метаданные, а только информацию для интерпретации чтения всего файла. В том числе длину метаданных, длину колонтитула, тип сжатия и тип версии.
После postscript идет File Footer, который содержит все метаданные, что и Parquet, но уже в сжатом виде, чтобы сэкономить крупицу места на дисках за счёт сжатия. В то же время это позволяет ORC быстро отсеивать ненужные файлы. В File Footer хранятся имена колонок, названия, количество строк каждого страйпа, статистика, информация о каждом страйпе, а ещё словари и многое другое.
Между File Header и File Footer содержатся stripe‘ы. Это аналог Row-group в Parquet, то есть просто разбитие одного большого файла на множество маленьких внутри, невидимое для глаз простого человека.
В свою очередь stripe’ы делятся на блоки. Они содержат индексы, сами данные и Stripe Footer — это аналог File Footer. Он содержит все метаданные для конкретного stripe’а и позволяет прочитать его очень быстро. В отличие от Parquet, если другие stripe’ы были повреждены, вы можете прочитать независимо от них. Так вы не потеряете все данные одного файла, а только их часть, если такое уже случилось.
Блок Index Data в свою очередь содержит метаинформацию конкретного столбца и конкретного stripe’а, то есть такие данные: как минимум, максимум, сумму и количество строк в конкретном столбце.
Между Index Data и Stripe Footer содержатся сами данные — Row Data, их физическое разделение на колонки, что позволяет прочитать один маленький блок конкретного страйпа.
Колонки, в отличие от Parquet, делятся на блоки индексов и блоки данных. В каждом блоке индексов содержится метаинформация для прочтения конкретного небольшого блока. Этот небольшой блок по умолчанию равен 10000 элементов, что позволяет не грузить лишний раз жёсткий диск и процессор для того, чтобы десериализовать данные.
Объем и скорость доступа
Представим таблицу на 80+ колонок с 500 миллионов записей. Она будет занимать:
в CSV — 204,1 Гб
в Parquet (без дополнительного сжатия) — 47 Гб
в ORC ещё сильнее сожмем, и получим всего лишь 35 Гб
Кроме встроенного сжатия у этих форматов есть алгоритмы. Например, SNAPPY и ZSTD поддерживаются обоими форматами, но только у Parquet есть возможность сжимать в GZIP, LZO, LZ4. ORC сжимает только в ZLIB.
Вот пример бенчмарка алгоритмов сжатия без привязки к формату:
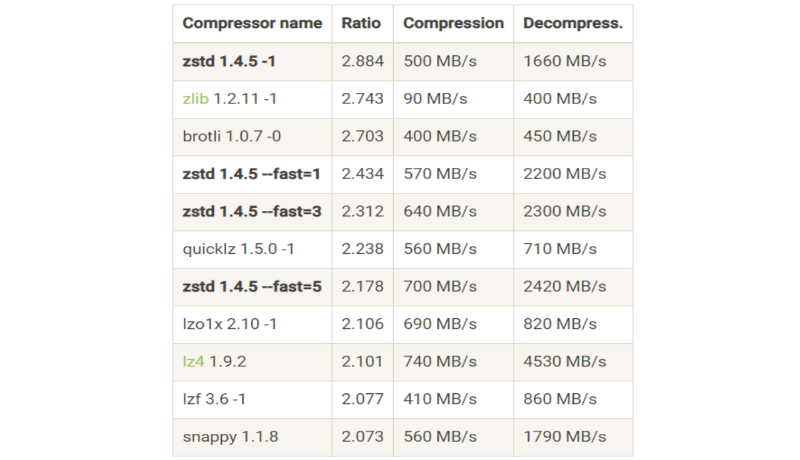
Остановимся на некоторых из них подробнее:
SNAPPY достаточно старый алгоритм для форматов. Он поддерживается уже многие годы и всё ещё входит в список лучших форматов для сжатия. Это стабильный среднячок.
LZ4 сжимает намного слабее, чем SNAPPY или другие представленные тут алгоритмы, но делает это крайне быстро, что позволяет нам не только быстро сжать, но и быстро прочитать.
ZSTD один из новейших алгоритмов, его не так давно добавили в ORC и Parquet. Он имеет 23 настройки/степени сжатия. В представленном бенчмарке видно 4 из них. Можно заметить, что чем сильнее сжимает ZSTD, тем медленнее он это делает. В то же время слабое сжатие позволяет быстрее прочитать файл.
ZLIB забрал лучшее от GZIP, LZ4 и от себя самого, благодаря чему он может быстро читать, записывать без потери качества сжатия. Так как ZLIB взял метрики от разных форматов, он не доходит по скорости до LZ4, но, тем не менее, остаётся прекрасным выбором для ORC.
Настройка ORC
Мы с командой провели огромное количество тестов, чтобы убедиться, что лучше для долгосрочного хранения и аналитики, и пришли к выводу, что в большинстве случаев у ORC больше преимуществ, чем у Parquet.
Вот, например, та же таблица на 500 миллионов записей и 80 колонок с метриками:

Parquet в SNAPPY в худшем случае показывает 33 Гб при сжатом формате, а в лучшем случае 21,1 Гб, в то время как ORC при сжатии ZLIB показывает 10,8. Однако, это верно только для оптимизированного ORC. Посмотрим, что это значит на других таблицах.
В примерах я привязываюсь к количеству записей в таблице или партиции, а не к их реальному объёму, потому что от этого зависит настройка индексов. Если у вас количество индексов становится слишком большим, вы очень сильно увеличите нагрузку на кластер, потому что вам будет нужно прочитать эти индексы.
Маленькая таблица
, < 100000 элементов")
Как маленькую таблицу не оптимизируй, всё будет одинаково. Разница буквально в десятки килобайт. Поэтому оптимизация маленьких таблиц (100-200 тысяч элементов) не имеет никакого смысла. Но если очень хочется, если счёт реально идет на миллисекунды, то можно отключить индексы и отсортировать данные.

Отключаются индексы с помощью опции 'orc.create.index'=false, но не во всех версиях и не всегда. Почему так происходит, к сожалению, неизвестно. Но даже после включения этого индекса в файле можно увидеть такой список:
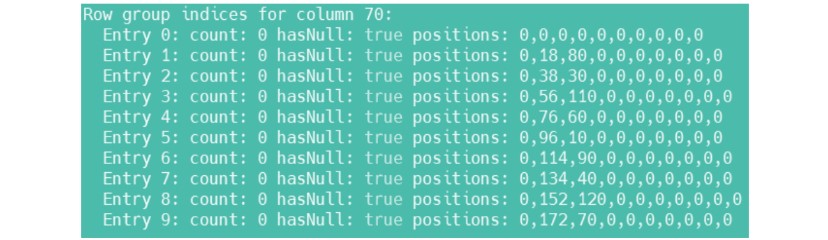
Он означает, что у вас всё ещё 10 блоков индексов, то есть те самые 10000 элементов по умолчанию. Тогда мы можем сделать этот блок индексов очень большим, чтобы он был больше таблицы. Если размер блока индексов больше, чем число элементов в таблице — будет создан только 1 блок индексов. Так фактически и физически мы отключим эту индексацию.
Средняя таблица
, < 100 млн. элементов")
Если говорить про нагрузку на кластер, то простая сортировка таблицы позволяет в 3 раза уменьшить нагрузку, если делать выбор по отсортированному полю. На картинке видно, что нагрузка на кластер без сортировки — 18000ms, а с сортировкой — 6000ms, но есть неучтенные данные. Это нагрузка на оперативную память, на диски и, в конце концов, на сеть, которая есть в период всего задействования кластера.
Также вместо того, чтобы читать все блоки индексов, достаточно выбрать только один конкретный небольшой блок, за счет чего произойдет тройное уменьшение нагрузки на CPU. Немаловажный, но небольшой бонус в том, что еще сократится занимаемое место на диске.
Получается, что:
● Индексы позволяют прочесть меньше данных из таблицы, поэтому для средних таблиц не стоит их удалять;
● Сортировка существенно ускоряет запрос.

Дело в том, что если мы берём все данные для прочтения, то вычитываем весь блок метаданных. Затем смотрим страйпы с потенциально нужными значениями и только потом отфильтровываем и забираем искомое. Но на самом деле это не имеет большого смысла. Если отсортировать в самом начале, то мы прочитаем ровно один страйп, в котором содержится нужная информация. Разумеется, если у вас не один элемент, а 100000 или миллион, и они расположены в разных страйпах, вы прочтёте каждый из них. Но это всё равно будет быстрее, чем прочитать всю таблицу.
Большая таблица

Параметр 'orc.row.index.stride'='60000‘ — это изменение блока индексов для страйпа. Также ещё один важный параметр 'orc.bloom.filter.columns'.
, > 100 млн. элементов")
Если настроить просто с сортировкой, мы можем получить ухудшение производительности при реально больших таблицах, допустим, на 500 миллионов записей. Это происходит из-за того, что мы вынуждены прочитать все блоки индексов. В данном случае их будет порядка 50000. Если настроить до 60000 элементов, то в 3 раза сократится нагрузка на кластер.
В случае с выбором элементов, если не сортировать, то выберется весь блок. Приятный бонус в 2 раза сократится место, занимаемое на диске данной таблицей.
Ключевые действия
→ Сортировка ускоряет запрос, она действительно важна.
Это ключевой элемент оптимизации всех таблиц, неважно, ORC или Parquet. Нужно понимать, какие данные вы храните, как их будут использовать. Если вариантов использования много, выбирайте тот, который будет использоваться чаще всего.
→ Настройка индексов существенно уменьшает требуемые ресурсы и время.
Индексы обязательны для настройки, если работать с большими таблицами. Это важно, потому что иначе вы не раскроете потенциал формата.

→ Порой стоит использовать фильтр Bloom.
Фильтр Bloom — это специальный алгоритм вероятностного поиска, который используется для определения принадлежности элемента множеству. Он способен выдавать ложноположительный, но не ложноотрицательный результат, что позволяет гарантированно выбрать нужные значения. В то же время он может выбрать те значения, которые не нужны. Тем не менее это позволяет уменьшить объём читаемых данных и нагрузку на кластер.
Вот пример:

Разница получается значительная.
→ Поддержка ACID.
Это не та поддержка, которая есть в реляционках, хотя очень похоже. В случае с ORC, когда мы хотим заменить какие-то данные в таблице, он создаёт дополнительный файл, в котором сказано, какое новое значение у определённой строки. Чтобы их каждый раз не перезаписывать, при необходимости поменять 100-200-300 значений можно добавить новые значения итеративно. Если файлов станет так много, что они будут тормозить систему, то тогда можно их перезаписать.
Parquet vs. ORC: итоги

→ Структура.
Оба формата являются колончатыми, имеют статистику, и к каждому из них можно добавить столбцы.
При тестах в Parquet можно менять местами столбцы, а в ORC нельзя. Это особенно важно на период разработки, когда часто меняется схема данных. Невозможность добавить куда-то в середину столбец может оказаться очень критичной. Понятно, что можно добавить в конец и потом просто в select поменять, но это не всегда удобно. Поэтому на период разработки очень удобно использовать Parquet.
→ Сжатие
ORC сам по себе сжимает лучше, а Parquet поддерживает более слабые алгоритмы сжатия.
→ Поддержка типов данных
У ORC большая поддержка типов данных, потому что он изначально был предназначен именно для Hive и всех его форматов.
→ Скорость доступа.
Если настроить таблицу под ORC, то скорость доступа будет выше, чем у Parquet.
→ Другое.
Есть маленькие приятные бонусы. У Parquet это поддержка спецсимволов в именах. Допустим, вы хотите назвать колонку @стул. В Parquet вы это можете сделать, в ORC нет. Но у ORC есть поддержка Bloom-фильтров и ACID.
У ORC также есть несколько параметров, которые мы не затронули в данной беседе:
orc.bloom.filter говорит о том, как часто bloom-фильтр будет ошибаться. Чем ниже значение, тем реже он будет ошибаться, но тем больше на это потребуется времени;
transactional — поддержка ACID;
orc.mask и orc.encrypt. Позволяют задать маску и кодирование для конкретной колонки. Только те люди, у которых будет доступ к ключу, смогут узнать, какие данные там хранятся.
Заключительное слово
Возвращаясь к начальной таблице, с ORC мы сократили объём, занимаемый на диске, в 3 раза. Также ускорили обработку Hive в 30 раз в случае с выбором единичных элементов. В случае с группировкой, в 3 раза. В случае со Spark прирост двукратный.

и 80+ колонками
Parquet в LZ4 по параметрам не сильно отстаёт от ORC. Однако, чтобы достичь примерно таких же показателей, как у настроенного ORC, Parquet приходится тратить в 2 раза больше ресурсов кластера. То есть если взять для ORC миллион миллисекунд, Parquet в LZ4 потребует 2 миллиона миллисекунд. В принципе, физическое время то же самое, но нагрузка на кластер в 2 раза больше.
Подводя итоги:
Сортируйте данные, и неважно, используете вы Parquet или ORC;
При больших объёмах нужно настраивать размер блоков;
Индексы — не всегда хорошо. Если их слишком много, они оказывают огромный вред для скорости обработки;
Фильтр Bloom приносит ощутимую пользу;
Настроенный ORC, пожалуй, лучше Parquet.
aalopatin
Правильно ли я понимаю, что в ORC можно вставлять новые колонки только в конец таблицы? Любые операция типа:
Вставка колонки в середину;
Запись файл в каталог с таблицей с другим порядком колонок;
Запись файлов с другим составом колонок, например, добавить в середину файла не объявленной в таблице колонки.
Например в каталоге 3 файла:
- 1ый файл - кол1, кол2
- 2ой файл - кол2, кол1
- 3ий файл - кол1, кол3, кол2
Но таблица в Hive объявлена как: кол1, кол2.
В итоге приведет нас к беспорядку, данные в таблице лягут не в те колонки и перепутаются? Т.е. только данные из 1ого файла лягут нормально, остальные данные поедут.
Решает ли эту проблему parquet? Учитывая, что вы говорите, что этот формат позволяет вставлять колонки в середину файла.
SacredDiablo Автор
Верно. В parquet можно после создания таблицы добавить потом поле в середину и это будет работать на уровне таблицы. При этом если посмотреть старые файлы, там останется всё "как было".
Данные кладутся, как их будете записывать. Если у колонок будет одинаковый тип данных - да, в таблице они перепутаются (как и в parquet, так и в orc в описанном вами случае, если просто "подкладывать" файлы).
Таблица с ORC просто не даст добавить в таблицу поле в середину - только в конец, иначе выдаст ошибку. С Parquet - даст. Но если просто класть внутрь файлы с случайным порядком колонок будет перепутано при совпадении типов или ошибка при не совпадении.
aalopatin
У parquet тоже перепутаются? По названиям колонок в файле и таблице hive не сопоставляются?
А такого решения ни с одним форматом нет, чтобы таблица находила интересующую её колонку в каждом файле не зависимо от порядка хранения колонок в файлах и правильно выводила данные?
SacredDiablo Автор
Итак, я проверил сейчас и при работе с parquet при ручном подкладывании файлов таблица сама считывает метаданные и перекладывает столбцы в правильном порядке (обратите внимание, что при чтении из файла отдельно, порядок будет "как записывали", т.е. может быть col1, col2; col2, col1; col3, col2, col1 - но в таблице будет разложено как должно).
Вот пример удачного использования для parquet: если невозможно соблюдать порядок записи столбцов. В то же время в устоявшихся витринах этот плюс не сильно нужен.
Посмотрим, что ещё реализуют в ORC2.0, возможно что они переймут удачные решения parquet =)
aalopatin
Да, согласен, что не нужен. Просто возник спор с коллегой насчёт того, что Spark ругается, когда несоответствие в составе колонок происходит. Проблему порядка колонок я обхожу тем, что в конце всех преобразований вызываю select(columns.map(col):_*)
А он предлагает подкладывать файлы в каталог и не писать через таблицу и не заморачиваться с колонками порядком колонок.
Я считаю это добавит лишних проблем: отсутствие контроля ETL, если мы без контрольно пишем файлы с любым порядком и составом колонок. Тем более ORC не позволяет этого делать. Да я и сам сталкивался с это проблемой пересоздание таблицы с другим порядком колонок, поверх существующих файлов приводит к перемешиванию данных.
Но это довольно странно на самом деле, что информация доступна о положении колонок в файле, но в таблице она не учитывается для каждого файла в таблице.