

Недавно я реализовал языковой сервер для языка программирования Ü. В этой статье я хочу поведать, как я это сделал. Данное повествование будет полезно для общего понимания, что есть такое языковой сервер. Также статья может быть полезна как руководство для написания языкового сервера для своего языка программирования.
Что такое языковой сервер
Когда-то, давным-давно, код писался на бумаге и/или выбивался на перфокартах. Программирование таким образом было мучительным процессом. Потом появились терминалы и компьютеры с долговременной памятью, код для которых можно было уже набивать на клавиатуре и тут же сохранить и возможно даже скомпилировать. Это было уже лучше.
Несколько позже стало понятно, что простого текстового редактора не достаточно. Хотелось бы, чтобы код можно было тут-же запустить и отладить, чтобы некоторые слова/конструкции языка подсвечивались специальным образом, чтобы по коду можно было перемещаться в соответствии с семантикой языка программирования и в конце концов чтобы компьютер сам помогал писать код. И постепенно текстовые редакторы научились всё это делать и таким образом развились до интегрированных сред разработки (IDE).
В те далёкие времена популярных языков программирования было не сильно много. И у каждого языка была своя IDE — TurboPascal, QuickC, VisualBasic и прочие. Каждая IDE содержала код для облегчения написания программ на специфичном для этой IDE языке. Но со временем количество языков росло и стало понятно, что иметь под каждый из них свою IDE — уж больно расточительно. Так стали появляться IDE с поддержкой более одного языка. В таких IDE уже было несколько программных модулей, ответственных за поведение IDE для различных языков.
Количество IDE и текстовых редакторов, приравненных к ним, тоже со временем только становилось больше. И в каждой IDE хотелось иметь поддержку как можно большего количества языков программирования. И тут уже встала вырисовываться проблема масштабирования. Количество кода, которое нужно написать, для того, чтобы в M IDE была поддержка N языков программирования пропорционально MxN.
В процессе разработки очередной IDE — Visual Studio Code разработчики также, как и их предшественники, столкнулись с проблемой трудоёмкости написания кода поддержки множества языков программирования. Чтобы облегчить себе задачу, они создали некоторый общий интерфейс для общения кода текстового редактора с кодом, специфичным для поддержки каждого языка программирования. В какой-то момент они осознали, что этот общий интерфейс может быть полезен не только в их IDE, но и в других. И тогда они решили сделать этот интерфейс открытым стандартом.
Таким образом родился Language Server Protocol, сокращённо LSP. Данный протокол упрощает разработку множества IDE, путём снижения сложности с поддержки N языков в M IDE (MxN) до реализации N языковых клиентов (для каждой IDE) и M языковых серверов (для каждого языка) (M+N).
Как устроен LSP
IDE (или текстовый редактор), а если быть точнее, компонент IDE, называемый языковым клиентом, запускает для каждого нужного ему языка отдельный процесс языкового сервера. Коммуникация с этим процессом происходит посредством посылки JSON сообщений. В процессе работы пользователя над документом IDE посылает оповещения, посылает запросы и получает на них ответы. Также запросы и оповещения может посылать сервер.
Важной частью LSP является понятие документа. IDE оповещает языковой сервер об открытии, изменении, закрытии документа. Запросы IDE относятся к документу — ко всему или для определённой позиции в нём. Сервер, соответственно, должен открывать/изменять/закрывать документы и соответствующим образом как-то организовывать их внутреннее представление, чтобы должным образом отвечать на запросы IDE.
Начало разработки языкового сервера Ü
По своей сути языковой сервер — это компонент, который очень тесно завязан на логику языка программирования. Соответственно, логично использовать ту же кодовую базу, что использует компилятор данного языка, в том числе и для языкового сервера. Именно таким образом я и поступил. Код языкового сервера Ü строится на библиотеках, на которых строиться компилятор Ü.
Вообще, для Ü существует два компилятора — Компилятор0, написанный на C++, и Компилятор1, написанный на самом Ü. Если быть точнее, это фронтенды. Бекенд у обоих из них — это библиотека LLVM, написанная на C++. Для написания языкового сервера я взял за основу код Компилятора0. В принципе можно было бы написать языковой сервер и с использованием Компилятора1 (на Ü), но это было бы несколько сложнее, ввиду того, что для языкового сервера нужны ещё некоторые вспомогательные компоненты (вроде JSON-парсера), которые в случае реализации на Ü пришлось бы писать самому, а так получилось использовать готовые C++ компоненты.
Код компилятора логически делится на три части-этапа. Этап 1 — разбивка входного текста на лексемы (лексический анализатор). Этап 2 — построение синтаксического дерева (синтаксический анализатор). Этап 3 — главная логика фронтенда компитяора, в которой осуществляется построение LLVM кода и много чего ещё (построитель кода). В языковом сервере используются все вышеназванные компоненты.
Итак, с основой понятно. Что же нужно, чтобы создать минимальный работающий (но пока что бесполезный) языковой сервер? Для этого нужно читать и парсить сообщения от клиента и слать ответные сообщения. Про умолчанию для обмена используются stdin и stdout. В соответствии с протоколом сервер должен как минимум отвечать на запросы initialize и shutdown. Особое внимание стоит обратить именно на запрос initialize. В ответе на этот запрос должен содержаться список функционала, который поддерживает языковой сервер. Кроме того нужно обрабатывать оповещения об открытии/изменении/закрытии документов, чтобы поддерживать внутреннюю таблицу документов, которая необходима для выполнения других запросов.
Символы документа
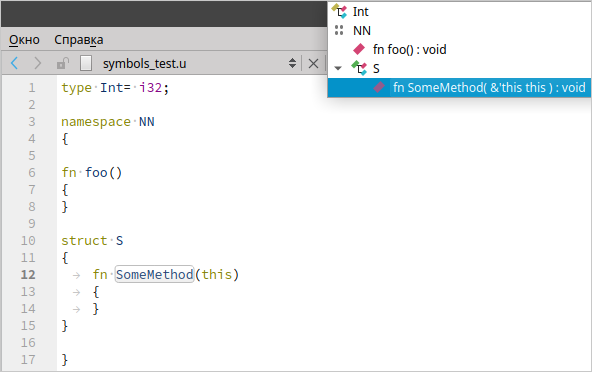
Один из самых простых (в реализации) запросов от IDE — это запрос символов документа (textDocument/documentSymbol). Это могут быть функции, типы, классы и т. д. Каждый символ — это некое имя, вид символа (функция, класс или что-то ещё), диапазон. Символы могут также содержать список вложенных символов. Результат этого запроса различные IDE используют по-разному, как правило, отображают в заголовке документа некий ComboBox с текущим символом или же отображают весь список где-то сбоку.
Итак, как же реализовать построение символов? Я решил эту задачу следующим образом: для документа запускается лексический и синтаксический анализ. Результат синтаксического анализа — синтаксическое дерево. Из этого дерева достаточно прямолинейно строится дерево символов документа.
Этот подход настолько прост и прямолинеен, что я его использовал ещё задолго до написания языкового сервера — в плагине Ü для QtCreator, который был когда-то давно написан и почти что заброшен. Соответственно, для языкового сервера я просто взял и адаптировал уже существующий код. А из плагина для QtCreator я его удалил, т. к. он теперь не нужен, когда тем же самым занимается языковой сервер.
Пример отображения символов документа:
Поиск позиции определения
Более сложный запрос — поиск позиции определения (textDocument/definition). Это когда пользователь кликает по имени в определённом месте в документе и просит перейти к месту, где соответствующий этому имени символ программы определён. Языковой сервер должен найти позицию определения и вернуть соответствующую позицию в документе.
Для реализации этого запроса только построения синтаксического дерева документа не достаточно. Нужно как-минимум построить таблицы символов и точно знать, что в таком-то месте программы нужно делать выборку из такой-то таблицы символов (для нужного пространства имён, класса, блока функции), чтобы найти правильный символ, а не какой-то другой символ, имеющий то же имя, но объявленный в другом месте. Более того, одних только таблиц символов не достаточно. Для перехода к точке определения поля класса, к которому происходит обращение через ".", нужно знать тип переменной-класса, что не так то просто и по сути требует вычисления типа всего выражения до ".".
Таким образом для выполнения этого запроса нужна вся мощь той части кода компилятора, которая это всё может сделать — построителя кода. Для целей поиска позиции определения я доработал его. Теперь он может в каждом месте, где происходит выборка символа по имени, запомнить в некоторой внутренней таблице соответствие точка использования -> точка определения. Для целей выполнения запроса языковой сервер выполняет лексический и синтаксический разбор, запускает построение кода, после чего просто делает выборку из вышеупомянутой таблицы.
Вышеописанный подход относительно надёжен. Он точно возвращает нужную точку определения, с учётом нужного пространства имён и сокрытия одних имён другими. Правда у него есть кое-какие недостатки, но об этом позже. Доработанный построитель кода при этом строит таблицу точек использования/определения только в случае запуска из языкового сервера. В обычной компиляции эта таблица не строится, т. к. в ней нету нужды.
Поиск всех использований
Также в LSP существует запрос на поиск всех мест использования какого-либо символа (textDocument/references). Как оказалось, для выполнения этого запроса можно использовать код, написанный для запроса позиции определения.
Для начала запускается поиск позиции определения. Далее, таблица точка использования -> точка определения сканируется и в ней ищутся все точки использования, соответствующие данной точке определения. Альтернативный вариант — пользователь кликнул на символ в точке определения и тогда первый этап пропускается.
Переименование
В LSP существует также запрос на переименование (textDocument/rename), который настолько схож с поиском всех мест использования, что внутри языкового сервера Ü для них используется один и тот-же код. Единственное существенное отличие — запрос на переименование может вернуть ошибку, если новое имя символа неверно.
Важно отметить, что само переименование реализует IDE. Языковой сервер только указывает, где это нужно сделать. Реализовано это так затем, чтобы синхронизация изменения документов работала только в одну сторону — от IDE к серверу.
Подсветка всех использований
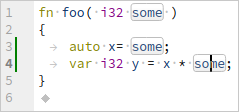
Есть и такой запрос — вернуть все места в документе, соответствующие именам символа под курсором (textDocument/documentHighlight). По сути это тот же запрос поиска всех использований, с тем отличаем, что возвращаются только символы в одном (указанном) документе.
Пример подсветки символов:
Оповещения об ошибках
Сервер может посылать IDE оповещения-диагностики (textDocument/publishDiagnostics). Языковой сервер Ü с помощью них сообщает IDE о синтаксических и семантических ошибках в коде документа. Такое оповещение бывает весьма полезно — позволяет программисту сразу исправить проблемные места, не запуская компиляцию. Как минимум, несколько мгновений это экономит.
Пример сообщения об ошибке:

Автодополнение
Автодополнение — возможность IDE подсказать пользователю, как он может дальше продолжать написание кода. Например, когда пользователь вводит символ a, IDE в зависимости от контекста может подсказать пользователю ключевое слово auto. Или при вводе nam IDE может подсказать пользователю ввести namespace и даже ввести за него открывающие и закрывающие скобки. Ещё один вариант — подсказать имя символа по уже введённым буквам или показать список доступных символов после оператора "." (доступ к члену класса) или "::" (доступ к члену пространства имён или класса).
В языковом сервере Ü я реализовал пока что только вариант с подсказкой имён. Данный тип подсказки имеет высокую ценность для программиста, т. к. позволяет по-быстрому узнать, какие имена доступны, не открывая самостоятельно место в коде с точкой объявления класса, пространства имён, функции. Первый тип я считаю не столь полезным, ибо программист, хотя бы в небольшой степени знакомый с конструкциями языка, не испытывает нужны в таких подсказках.
Так вот, как же реализовать автодополнение имён? Для этого надо в точке, где программист осуществляет ввод, сделать выборку всех доступных имён и выбрать из них те, которые неким образом подходят под частичное имя, введённое программистом. Ну или выбрать все доступные имена при обращении через "." или "::". На первый взгляд кажется, что для осуществления подобной подсказки можно использовать таблицы символов, построенные в ходе последнего построения кода документа. Но проблема в том, что таблицы символов сохраняются только для глобальных пространств (классов, пространств имён). Таблицы символов для внутренностей функций не сохраняются. И сохранять из было бы практически невозможно, т. к. нужно их не только сохранять, но и версионировать, чтобы символы, объявленные после точки внутри функции, в которой происходит вычисление автодополнения, не попали в список автодополнения.
Для реализации автодополнения в Ü посему я выбрал другой, достаточно хитрый подход. При запросе автодополнения текущий документ разбивается на лексемы. Для текущей позиции курсора ищется лексема и её тип заменяется на специальный тип лексемы-автодополнения. Далее запускается синтаксический анализ. Он доработан таким образом, чтобы при встрече лексемы-автодополнения строились узлы синтаксического дерева специальных типов для автодополнения, вроде выборки имени с автодополнением, выборки члена класса с автодополнением и т. д.
Далее, можно было бы передать результат синтаксического анализа построителю кода, построить код с обработкой элементов синтаксического дерева с автодополнением специальным образом и забрать результат. Но так просто сделать нельзя. Проблема заключается в том, что в момент автодополнения текст документа почти никогда не является синтаксически-корректным. Синтаксический анализ такого текста возвращает сильно неполный/неправильный результат (наряду с ошибками, естественно), попытка запустить построение кода для которого приведёт к тому, что таблицы символов будут сильно не полны, в них, например, может не быть глобальных символов, объявленных после места поломки синтаксиса.
Над решением этой проблемы я долго раздумывал, и пришёл к следующему. Можно предположить, что при выполнении запроса автодополнения текст документа синтаксически-корректен по крайней мере до того места, для которого запускается автодополнение. Тогда результат синтаксического анализа будет содержать дерево, в котором путь от корня до места автодополнения корректен — включает в себя корректное пространство имён, класс, функцию и т. д. Это предположение истинно не всегда, но достаточно часто, чтобы на его основе можно было реализовать автодополнение.
Так вот, имея такое неполное, но всё-же полезное синтаксическое дерево можно в нём найти синтаксический элемент, соответствующий ранее упомянутой лексеме автодополнения, включая также путь от корня дерева (пространство имён, класс, функцию). Далее используется одна хитрость. Используется построитель кода с внутренним состоянием, созданным из некой предыдущей, синтаксически-корректной версии документа. Для него запускается соответствующий метод, который строит код для переданного синтаксического элемента из нового состояния программы (включая путь от корня). В недрах построителья кода синтаксические элементы автодополнения обрабатываются особым образом — для них заполняется список подходящих в данном контексте символов, после чего этот список возвращается коду языкового сервера, а тот в свою очередь строит из него ответ на искомый запрос.
Вышеописанный подход позволяет абсолютно корректно выдавать подсказки символов как в глобальном пространстве (вне функций), так и внутри функций, с учётом доступных в данной точке переменных. Также работают подсказки для "." и "::", выдавая правильный результат с учётом всего типа выражения.
Я предвижу следующий вопрос читателей — почему бы не адаптировать синтаксический анализатор и сделать его более толерантным к программам с синтаксическими ошибками, чтобы результат синтаксического анализа текста программы с недописанной строкой где-то в середине отличался бы от правильного результата минимальным образом? Тогда можно было бы напрямую отдавать этот результат построителю кода и получить ответ, не производя предварительного построения кода для некой старой, но корректной версии документа и избегая шага поиска элемента в синтаксическом дереве. Тут есть сразу несколько проблем.
Во-первых, я не знаю, как можно было бы написать синтаксический анализатор таким образом, чтобы он умел переваривать условные "недописанные" строки и надёжно выдавал близкий к правильному результат. Я буду благодарен читателю, если тот поведает о таком подходе/поделится ссылками.
Во-вторых, проблема заключается ещё и в том, что построение кода всей программы слишком долго, чтобы его можно было запускать на каждый запрос автодополнения. Построение на большом документе может занимать до пары секунд, тогда как автодополнение должно работать почти моментально (доли секунды). Подход с построением кода всего документа заранее и построением только небольшой части для автодополнения даёт хороший по скорости результат. Да, при каждом запросе автодополнения запускается ещё и синтаксический анализ, но он относительно быстр — занимает около 50 миллисекунд на достаточно объёмном документе, что ощущается как мгновение.
О выборке имён для автодополнения
В случае, когда осуществляется автодополнение для частично-введённого имени, происходит выборка доступных имён, для которых частично-введённое имя является подстрокой. При этом игнорируется регистр символов (правда только для ASCII, игнорирование регистра для случаев вроде ß -> SS это слишком сложно). В результирующем списке приоритезируются символы, в которых вхождение введённого частичного имени приходится на начало. К примеру, для введённой части имени "дом" будут возвращены сначала результаты вроде "домашний", "домоводство" и только потом "управдом".
Также осуществляется фильтрация имён при автодополнении по контексту. Например, в инициализаторе структур будут предлагаться только имена полей, но не методов.
Пример автодополнения:

Обратите внимание, что предлагаются только доступные в данном контексте имена.
Отображение одного состояния документа на другое
Как уже было упомянуто ранее, языковой сервер не запускает внутри себя построение кода на каждый запрос. Код строится только время от времени, если документ синтаксически-корректен и какое-то время не менялся. При этом возникает следующая проблема — входные и выходные позиции в документе, с которыми работает языковой сервер, не соответствуют таковым в последней построенной версией документа. Данное несоответствие может приводить к тому, что запросы отрабатываются неверно — возвращают неверные диапазоны или вовсе не находят результата.
Дабы справиться с этой проблемой, я реализовал в языковом сервере отображение позиции в документе из текущего состояние в состояние, соответствующее хранящейся построенной версии и наоборот. Как же это делается?
А делается это на удивление просто. Надо только понять, как хранить изменения. IDE сообщает языковому серверу изменения в документе итеративным образом, в виде "с такой-то позиции по такую-то позицию содержимое заменилось на такую-то строку". Можно сохранять эту информацию в простейшей структуре из трёх чисел — начало/конец строки документа, подвергшейся изменению и количество изменённых символов. На основе такой структуры можно произвести пересчёт старой позиции в новую и наоборот. Ну или не произвести, если позиция приходится на изменённую часть документа. Данные изменения можно накапливать и производить на их основе пересчёт для целой цепочки изменений.
Приведу пример, как это используется. В запросе всех точек использования приходит такая-то позиция (строка/колонка). Эта позиция переводится в линейный вид (смещение в текущем тексте документа). Потом при помощи обхода изменений от новых к старым находится соответствующая линейная позиция для последней построенной версии документа. Далее на основе этой пересчитанной линейной позиции строится внутренняя структура позиции в программе, для которой уже осуществляется поиск всех точек использования (в построенной ранее для этого таблице). После этого происходит пересчёт результатов в обратную сторону — в позиции для текущей версии документа, которые уже и возвращаются IDE.
Упомяну ещё раз — пересчёт не всегда возможен, если он происходит для затронутых изменениями мест. Но это не сильно страшно. Да и рано или поздно всё равно произойдёт обновление внутренней версии документа и изменения зачтутся.
Поддержка Юникода и прочие тонкости
При разработке языкового сервера пришлось решить ещё ряд проблем.
Например, обмен позициями в документе происходит в формате строка + колонка.
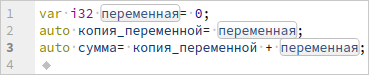
Колонка при этом — это номер UTF-16 слова. В свежих версиях LSP это настраиваемо, но поддержка формата с UTF-16 так или иначе является обязательной. При этом внутри языкового сервера и в целом в недрах библиотек компилятора текст хранится в UTF-8. Менять код компилятора для работы с UTF-16 накладно и нецелесообразно, посему был реализован пересчёт смещений в UTF-16 в смещения в UTF-8 и наоборот. К счастью, это быстро, т. к. требует пересчёта только от начала строки, а не всего документа.
Пример подсветки не-ASCII имён:
Также есть такой неприятный нюанс — некоторые IDE под Windows до сих пор любят подкладывать грабли, используя \r\n в качестве комбинации конца строки. А некоторые IDE вообще могут только \r использовать. В LSP эти комбинации, наряду с привычным \n, сочтены корректными символами конца строки. Поэтому мне пришлось адаптировать код для корректной работы с ними. Ранее код компилятора считал за символ конца строки только единственный \n.
Ускорение за счёт многопоточности
По-началу языковой сервер работал предельно простым образом — синхронно вычитывал сообщения и выполнял соответствующие действия. Но этот подход имел ряд недостатков и поэтому был изменён.
В таком синхронном подходе возникает проблема с медленно-выполняющимися запросами. Если запрос выполняется слишком долго, IDE может послать сообщение об его отмене, т. к. запрос перестал быть более актуальным. Но в случае с синхронным чтением сервер отменить запрос не может. Решил я эту проблему с помощью разделения кода сервера на два потока. Первый читает сообщения, второй их обрабатывает. Сообщения от первого ко второму потоку передаются через очередь. Этот подход позволяет реализовать отмену запроса, если он ещё не был извлечён из очереди. При этом всё ещё невозможна отмена запроса, который уже выполняется, но это всё же лучше, чем совсем не уметь отменять запросы.
Другая проблема, которую понадобилось решить — медленная перестройка документа. Она блокировала поток выполнения запросов на какое-то время, что ощущалось пользователем как тормоза. Решил я эту проблему за счёт выноса кода построения в фоновый поток. Пока документ перестраивается, все ещё возможно выполнение запросов к другим документам и даже этому документу. Возможна даже параллельная перестройка нескольких документов, коль скоро для этого достаточно ядер процессора.
Пока что нерешённые проблемы
Текущая версия языкового сервера все ещё не идеальна. Наличествуют ряд проблем.
- Поиск точки определения кривовато работает для перегруженных функций — ищется не то. Аналогично с поиском использований перегруженной функции. Решить проблему можно, но надо подумать, как обойти хитрые случаи.
- Поиск всех использований ограничен текущим документом и импортируемыми им файлами. По-хорошему надо как-минимум искать ещё в других открытых документах или даже открывать файлы в той же директории для осуществления поиска в них. Но читать файлы и компилировать их долго. Да и не понятно, в каком объёме их читать. Так что пока это не реализовано.
- Механизм построения таблицы точка использования -> точка определения имеет некоторый изъян. Это таблица не заполняется для кода, для которого построение не запускалось. А это может произойти, например, для шаблонного кода, который объявлен в этом документе, но в нём не инстанцирован. То же касается пропущенных ветвей static_if и функций, отключенных через enable_if. По-идее, можно как-то обрабатывать шаблоны особым образом, например инстанцируя их с какими-то аргументами-заглушками. Но у этого подхода есть кое-какие подводные камни, поэтому он пока не реализован.
- Пока что языковой сервер можно повесить constexpr вычислениями.
- С опциями сборки не всё понятно. Чтобы языковой сервер работал точно как при настоящей сборке, нужно знать некоторые параметры цели (целевую архитектуру и среду, флаги сборки). Кроме того надо задавать директории для поиска import файлов. В каком-нибудь C++ за это отвечает IDE, разбирая файлы проекта и предоставляя нужные параметры языковому серверу. Языковой сервер Rust может просто найти carto.toml файл и на его основе понять, что как должно собираться. Ни того, ни другого в Ü пока что нету. В качестве временной меры реализовано задание рядя параметров сборки через аргументы командной строки.
Все вышеописанные проблемы заметны, но не фатальны и в перспективе решаемы. В дальнейшем, надеюсь, они будут исправлены.
Кроме того, в процессе разработки языкового сервера я обнаружил некоторые неоптимальности кода фронтенда компилятора. Он несколько медленноват (хотелось бы большей скорости) и потребляет значительный объём памяти. Построение кода исходников Копилятора1 в языковом сервере занимает более секунды времени (на каждый значительный файл) и потребление памяти составляет около сотни мегабайт на документ. Эти неоптимальности для собственно компиляции не являлись и не являются проблемами, т. к. потребление процессорного времени и памяти в обычной компиляции главным образом происходит в бекенде. Даже оптимизация фронтенда в 0 не дала бы значительного увеличения производительности. Но вот в языковом сервере эти проблемы уже более существенны.
Главное моё подозрение, что может потреблять много времени и памяти — это построение typeinfo структур. typeinfo в языке Ü — это оператор, который возвращает для переданного типа разветвлённую constexpr структуру с описанием свойств типа. На каждый вызов typeinfo сейчас в компиляторе создаются множество классов — для описания элементарных свойств типа а также для перечислений вложенных типов, полей, методов и т. д. Получается, что на один класс в исходном коде, для которого был вызван typeinfo, создаётся множество внутренних служебных классов. У каждого из них имеется как минимум деструктор, сложно-закодированное имя, таблица символов, куча свойств и т. д. В итоге видимо и набегают те самые мегабайты памяти и сотни миллисекунд времени сборки. У меня есть некоторые идеи, как это можно подсократить и тем самым улучшить производительность языкового сервера, но пока что эти идеи не воплощены в коде.
Заключение
Всё вышеописанное было реализовано где-то за месяц. В итоге у языка Ü появился более-менее функционирующий языковой сервер. Да, он ещё не идеален и предстоят доработки, но уже сейчас им можно пользоваться и он даёт приличный результат.
Работа языкового сервера Ü была проверена с несколькими разными IDE. В QtCreator работает весь его функционал. В Kate вроде тоже всё работает, хоть там и пришлось исхитриться, чтобы заставить его работать — эта IDE как-то странно настраивается и не имеет прямолинейной настройки для ассоциации языкового сервера с расширением файла. В Notepad++ я проверил работу языкового сервера с помощью стороннего плагина языкового клиента. Плагин не очень удобный, но тем не менее функционал сервера и с ним работает должным образом.
Интересующийся читатель может самостоятельно проверить работу языкового сервера Ü в своей IDE и поделиться результатом в комментариях.
Оглядываясь назад, я удивляюсь теперь, почему я реализовал языковой сервер только сейчас. Это можно было бы сделать ещё году в 2020-м. LSP уже тогда был хорошо распространён. И тогда бы его наличие могло бы мне несколько облегчить разработку Компилятора1. Но так или иначе, лучше поздно, чем никогда.
Ссылки
Страница проекта. Там же есть ссылки на сборки Ü (включая компилятор и языковой сервер).
Web-demo языка. К сожалению в нём языковой сервер пока что не используется.