
Сталкивались ли вы с проблемой возникновения багов из-за пересечения включенных фичей в приложении? Или, возможно, была необходимость одновременно проводить большое число A/B-экспериментов в одном компоненте?
Некоторое время назад команда Почты Mail.ru решала задачу управления сложным состоянием приложения с большим количеством фичей и источников данных с помощью конечных автоматов. Нужно было ускорить разработку и тестирование, поддерживая возможность проведения более чем 20 А/В-экспериментов. На тот момент, я работал там над проектами портальной навигации и главной страницы.
Меня зовут Денис Стасьев. В этой статье расскажу о том, как мы внедряли машину состояний в одном из компонентов главной страницы Mail.ru — блоке новостей, что получили на выходе и ещё подробнее о том, почему в итоге остановились на XState.

Главная страница Mail.ru и блок новостей
Главная страница Mail.ru — это сервис, которым пользуются миллионы людей каждый день. Помимо решения основной задачи, а именно предоставления удобного доступа к своему почтовому ящику на Mail.ru, там можно посмотреть уведомления из соцсетей, прогноз погоды, актуальный курс валют.

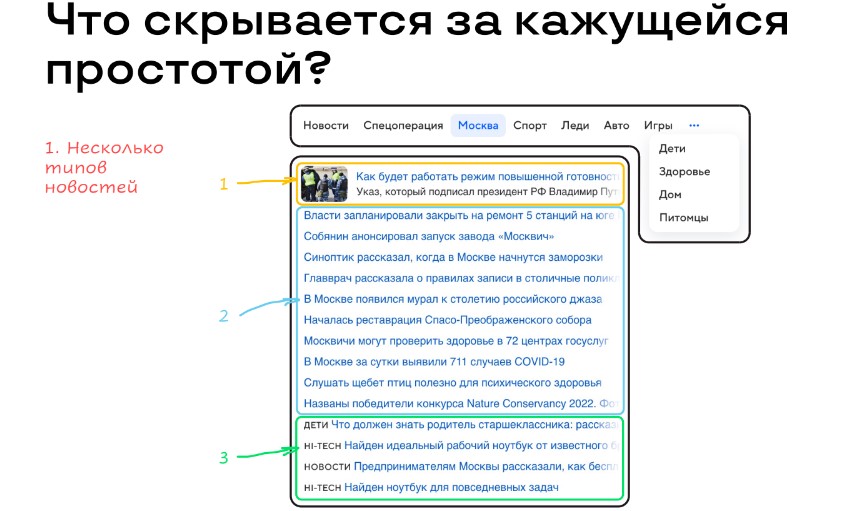
Также на главной доступны новости. Внешне этот блок выглядит просто: есть набор табов, в каждом из них загружается список из 15 новостей.

Однако, технически всё устроено сложнее, так как в разработке важно учитывать некоторые продуктовые особенности:
Все новости разные. В сервисе, как минимум, три типа новостей: основная новость (картинка и описание), обычные новости (только заголовок), ряд новостей внизу (шильдик).
Источники новостей. Новости нужно откуда-то получать, синхронизировать данные и собирать всё вместе. Эта задача решается на бэкенде, мы её пропустим.
Аналитика. Когда мы внедряем некоторую новую фичу (просмотр новостей), необходимо понять как пользователь с ней взаимодействует. Для этого собираем аналитику.
Спецификации новостей. В списке табов есть спецификация по регионам: для каждого региона как свой таб с актуальными новостями, так и разные новости в некоторых общих табах.
Анимации. Например, появление новости из забеления, или синяя подсветка, которая показывает свежие новости.
Скелетоны. С их помощью мы боремся со сдвигами контента страницы при загрузке новых новостей.
Адаптивная верстка. Это значит, что на разных разрешениях экрана пользователь видит разное количество новостей.
Service Site Rendering (SSR).
Мониторинг ошибок. Необходимо как следить за клиентскими ошибками, так и за корректностью данных.

Таких задач ещё несколько десятков. Несмотря на кажущуюся сложность, все они успешно решались.
Большой трафик
Все продуктовые фичи в сервисе раскатываются через тестирование — A/B-, A/B/С-, … эксперименты. Это позволяет плавно выкатывать обновления, которые влияют на пользовательский опыт. Только после тщательного изучения аналитики по новой фиче, она включается на более высокий процент пользователей.
Одновременно в сервисе может быть включено несколько A/B-тестов с разным набором включённых фичей. Это пересечение будет важно далее в статье.
Новые задачи
Несколько лет назад мы задумались, как сделать главную страницу удобней, так одним из направлений стало улучшение персонализации. Появились задачи:
Создать и внедрить новые системы рекомендаций новостей, чтобы лучше подстраиваться под интересы пользователей.
Добавить больше вариантов отображений новостей, чтобы понять, в каком виде пользователям удобнее взаимодействовать с продуктом.
Внедрить новые типы новостей, которые бы обновлялись (отображались) особенным способом, для учёта более широкого набора интересов
Сигналы скорого бедствия
Мы получили задачу внедрить новую систему рекомендаций. Для упрощения можно считать, что для разработки эта система рекомендаций является новым источником данных. Фичу нужно было запустить как можно быстрее. Чтобы этого достичь, было решено её реализовывать с минимальными изменениями кодовой базы, следуя ранее принятому подходу, который уже успешно решал описанные выше задачи. Рассмотрим его детальнее на абстрактном примере.
Надо отметить, что проект сделан на Svelte, в котором есть свой шаблонизатор Htmlx. Поэтому пример ниже будет использовать именно его.

В примере через each написан цикл в массиве, выводящий каждую новость, и есть условие isLoading, добавляющее класс news-item_loading, который добавляет анимацию.
Разные типы новостей также влияют на исходный код. Поэтому используя поддержку типов, мы добавляем некоторые условия.

Если тип у конкретной новости равен определённому, например, с картинкой, то в шаблоне добавится image и описание. Конечно, здесь и ниже в ряде мест логику можно написать оптимальнее, но для упрощения объяснения проблемы, специально оставим её в таком виде.
Можно составить список условий, которые влияли на отображение новостей:
тип новости;
статус загрузки;
тип анимации: появления/обновления;
признак «Новость на главном табе»;
показывали ли такую новость ранее;
другие параметры.
Забегая вперёд, хочется задать вопрос: «Всё ли хорошо с этими условиями?». Позже в статье мы вернёмся к ответу на этот вопрос. MVP: быстро и дёшево через if...else
Вернёмся к решению новой задачи — внедрению новой системы рекомендаций. Для этого в шаблон мы добавили условие (3-я строка на рисунке), откуда приходят новости. Отмечу, что не все типы рекомендаций могут отдавать все виды новостей. В частности, видно, что один тип рекомендаций может отдавать новости двух видов, а другой — только второго вида.

Всё выглядело логично: мы применили подход «if … else», реализовали фичу и очень быстро запустили её минимальными силами. Задача выполнена. Но возникла проблема, которую мы изначально не заметили, которая лишь со временем начала влиять — ухудшение метрики Time To Market (TTM).
Проблемы с метрикой Time To Market

Выбирая такой подход для реализации, мы понимали, что это приведёт к долгому тестированию. Мы не могли изолировать фичи друг от друга, поэтому было необходимо тестировать все комбинации включённых фичей. Поясню на примере.
Есть фича, которая может быть в двух состояниях, если она boolean-переменная. Если таких фичей две, то имеем уже 4 состояния, 3 переменных — 8 состояний. Получаем экспоненциальный рост времени тестирования в зависимости от количества фичей, что является проблемой, так как у нас десятки фичей. Хотелось бы сделать эту зависимость более линейной. Отметим, что несмотря на наличие автотестов, их число тоже растёт экспоненциально, поэтому как увеличивается время прогона (что не очень критично), так и время написания автотестов (что значительно дороже). То есть вместе с ростом времени тестирования стало расти и время разработки.

Время разработки первой фичи вначале было очень маленьким (синий график), а скорость — высокая. Со временем скорость стала резко снижаться, однако нам хотелось бы выровнять график и сделать так, чтобы и десятая фича по скорости реализации не сильно отставала от первой. Так при добавлении новых фич, следуя выбранному ранее подходу, перешли от быстрой разработки и быстрого тестирования к долгой разработке и долгому тестированию. При этом ощущали себя как на тонущем судне.
Признаки проблемы c TTM в MVP
Пересечение экспериментов стало «болью» всей команды.
Логика в шаблоне начала расти — появилась смесь работы с системами рекомендаций и отображением.
Наверное, основная причина, почему возникла проблема с Time to Market, связана с тем, что вёрстка и данные по-настоящему не были изолированы. Но тогда не понятно, почему ранее, до внедрения новой системы рекомендаций, внедрение новой фичи не занимало столько времени?
Если мы ещё раз взглянем на условия, которые изначально влияли на отображение новостей, то заметим, что все они полностью изолированы:
тип новости;
статус загрузки новости;
тип анимации: появления/обновления;
признак «Новость на главном табе»;
показывали ли такую новость ранее;
Статус загрузки новости и её тип не влияют друг на друга.
Какие ошибки были допущены
Некоторые условия стали зависеть от других. И с ростом системы проблема усугубляется.
Когда мы запустили фичу с рекомендацией новостей, где появилась зависимость между типом рекомендательной системы и типом новости, которую видит пользователь, некоторые условия стали зависимыми. Это не стало бы такой большой проблемой, если бы фичей было 1-2, но когда их десятки, возникают большие проблемы.
Вот пример «зависимых» условий. Допустим, в коде есть некоторые переменные:
isExist — существование;
isEnabled — включение (без существования);
isLoading — загрузка (без включения).
Тут хочется задать вопрос — какой смысл у состояния, когда идёт загрузка ресурсов выключенной фичи? Кажется, что из-за того, что смысла такой бизнес-логики нет, надо как-то ограничивать число возможных состояний, комбинации переменных и системы.
Кто-то может предположить, что enum решит проблему, но всё равно, даже с enum, эта проблема в какой-то момент возникнет снова.
Логика в шаблоне начала расти, без нее невозможно понять, что происходит.
Проблему растущей логики хотелось бы минимизировать, потому что она влияет на скорость чтения кода. Однако на ней подробно останавливаться не будем, можно лишь отметить, что, например, data-driven подход успешно решает данную проблему.
Круг спасения: внедрение машины состояний
Кругом спасения стало внедрение машины состояний. Мы построили решение, основанное на двух принципах:
Ограничить число валидных состояний в системе.
Полностью отделить данные от вёрстки.
Для соответствия второму принципу изолирования данных от отображения внедрили MVC архитектуру.
Новая архитектура — Model–View–Controller (MVC)
В архитектуре MVC три основных компонента:
Модель — набор данных, валидность состояний которого и надо ограничивать.
Вид — вёрстка, которая не должна знать о данных.
Контроллер — некоторое единое место-обработчик сигналов для обновления данных в модели.

{kind=link}
State Machine
Перейдём к решению проблемы ограничения числа валидных состояний. Когда мы говорим об ограничении числа состояний, сразу же кажется логичным использовать машину состояний.
Несколько переформулированное определение из Википедии:
Машина состояний (или автомат, State Machine) — математическая абстракция, основанная на модели дискретного устройства: один вход, один выход, и в каждый момент времени — одно состояние из множества возможных.

{kind=link}
Важно отметить, что это некоторая абстракция, которую вы дальше как-то реализуете в коде.
Дополнительно пара определений:
Машина состояний конечна, когда число внутренних состояний конечно.
Машина состояний детерминирована, когда новое состояние однозначно определяется текущим состоянием и входом, который мы ей посылаем.
В научных статьях машину состояний представляют совокупностью некоторых множеств и функций:

На практике чаще используется два основных представления:
Таблица переходов, которая описывает переходы между состояниями.
Граф переходов.
На графе остановимся подробнее.

На схеме выше видно, как устроена лампочка, если её представить моделью машины состояний. У лампочки два состояния: свет горит и выключен (on, off). Если в выключенном состоянии на вход подать сигнал в виде условной строки TURN_ON, то состояние изменится на on — лампочка включится. Если проделать аналогичное при включенном состоянии, то ничего не произойдёт, так как из состояния on нет никакого выхода с событием TURN_ON. При этом, если лампочке, находящейся в состоянии on, отправить событие TURN_OFF, она выключится.
Этот граф необязательно рисовать вручную. Он стандартизирован и есть вспомогательные инструменты. В частности, его можно нарисовать даже в UML, как представлено на схеме.
Выбор библиотеки для FSM
Если вы планируете реализовывать обычную машину состояния, про которую шла речь выше, то библиотека не нужна. Достаточно сделать обёртку над любым стейт-менеджером, которая бы запрещала некоторые переходы. В частности, мой бывший коллега Сергей Володин ранее рассказывал о том, как написать такую обертку поверх связки React/Redux.
Ещё есть ряд библиотек, например, robot3, которая весит порядка 1kB и реализует машину состояний. Более мощные библиотеки, о которых поговорим чуть позже, для таких машин состояний не нужны. Их применение избыточно.
Реализация FSM
Вся реализация FSM сводится к разработке графа. Это универсальный инструмент для документирования и реализации, который полезен всей команде. Менеджеры могут понять состояние, бизнес-логику, когда какие-то события отправляются в систему, а тестирование по графу ориентируется в том, что происходит, чтобы тестировать новые фичи.
При таком подходе в нашем блоке новостей было более 10 состояний в момент реализации. Посмотрим на примерах, как можно делать FSM для новостей.

Если опираться на пример с лампочкой, мы просто заменим состояние «on/off» на состояние «показ новостей/загрузка». В состоянии загрузки мы ждём вызов сетевого запроса, и как только данные загрузились, система отправит событие SHOW_NEWS и покажет новости.
Новая система рекомендации новостей, которую мы внедрили, является новым источником новостей. В частности, на второй схеме есть два состояния showingBase и updatingBase, которые посвящены одному состоянию, и вся вторая часть этого графа относится к другой рекомендательной системе Extra. При загрузке всей страницы мы попадаем в состояние idle и смотрим на набор некоторых фичей. Если фича с показом Extra-новостей включена, то попадаем в правую часть графа и движемся уже внутри неё.
Здесь мы не учли переключение новостей между разными табами.
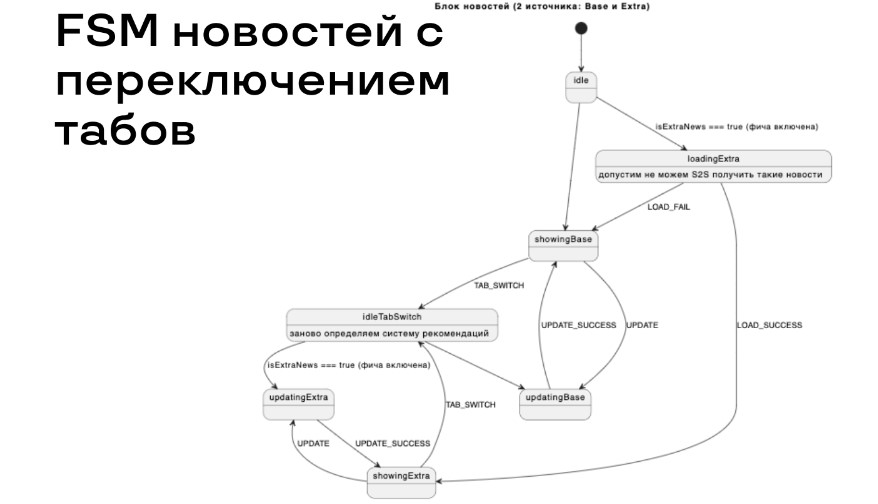
Для переключения новостей добавили новое состояние idleTabSwitch, куда можно переходить, посылая событие TAB_SWITCH в систему. Попадая в это состояние, мы возвращаемся в показ новостей, опять же с помощью проверки некоторых флагов фичей.
Результат реализации FSM и с какими сложностями мы столкнулись
Кажется, что светлое будущее наступило. Этот подход позволил некоторым образом ограничить число валидных состояний в системе:
Успешно запустили более 10 A/B-экспериментов. Эксперименты стало легче разводить, код стал проще.
Строгая документация. У нас появилась строгая документация в виде графа, понятная всем членам команды.
Разделение вида и модели ускорило тестирование за счёт независимого тестирования экспериментов на отображение и экспериментов, влияющих на данные.
Снизился Time To Market.
State Explosion/Проблемы FSM
Казалось, что всё хорошо и какое-то время нам нравилось. Но по мере развития системы и добавления новых фичей граф стал резко увеличиваться в размерах. Эта проблема широко известна в концепции машин состояния, и называется State Explosion, или взрыв машины состояния — State Explosion.
Попытаемся разобраться, в чём проблема.
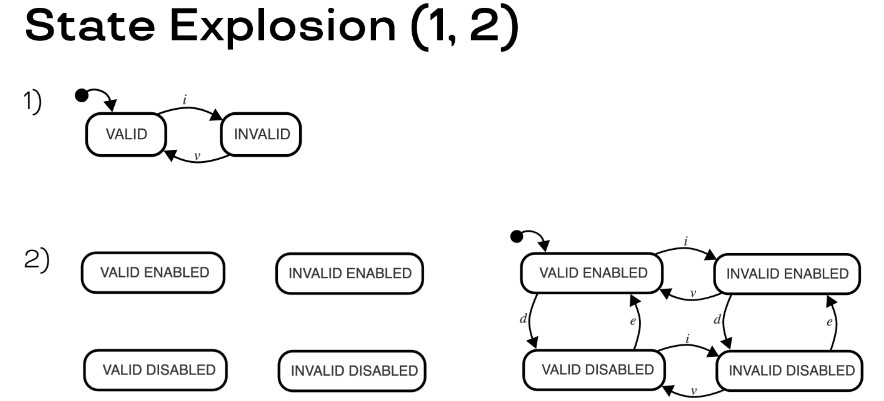
Допустим, в приложении только одна фича, условно — «валидность». В таком случае у нас два состояния: система либо валидна, либо не валидна. Соответственно, два состояния, два события на переход между этими состояниями, проблем нет.
Добавим ещё одну фичу, которую назовём «включённость». Так для двух фичей появляется 4 состояния — 4 разных комбинаций переменных, про которые ранее рассказывал, и 8 рёбер в графе.
Если у нас 3 фичи, то получается целых 8 состояний и 24 ребра в графе.

Если с состояниями ещё можно что-то понять, то с переходами между ними уже не так легко.
Дополнительно к проблеме роста графа возникли другие:
Некоторые состояния хотелось сгруппировать и изолировать.
Мы хотели явно изолировать состояния, связанные с первой и со второй фичей, в разные группы, чтобы в любой момент времени легко понимать какие новости на экране (без детализации их состояния: грузятся они или просто отображаются). На графе ранее визуально разделяли их пунктирными линиями для понятности. Однако этот подход имел недостаток: необходимо было контролировать состояния вручную.
Невозможность асинхронного обновления части новостей.
Когда мы говорим о FSM, то имеем в виду некоторое состояние, которое меняется только при переходах. Когда мы хотим асинхронно менять часть данных в приложении, то в классической модели состояний это сделать нельзя.
Это сподвигло нас к отказу от FSM.
Отказ от машины состояний и чем её заменили
Мы перешли на использование абстракции Statechart, по-другому — диаграмму состояний. Главное её отличие на схеме ниже:
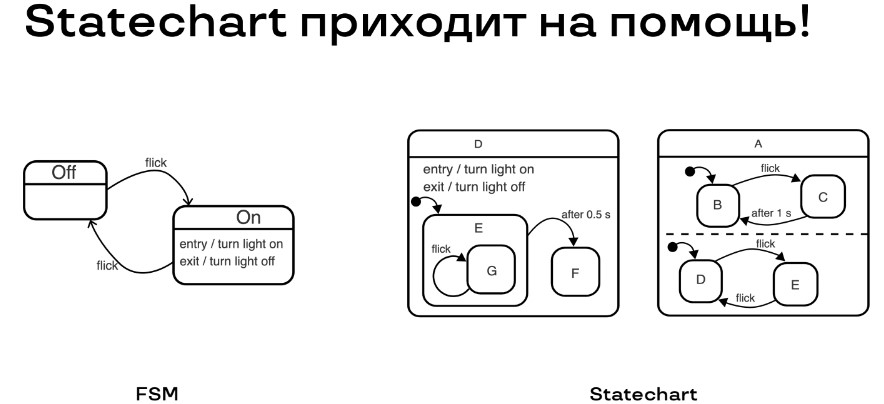
Если в классической модели все состояния общаются между собой, то в Statechart некоторые состояния вложены. Поговорим про это подробнее.
Сущности Statechart
Statechart добавляет некоторые сущности в машину состояний:
Контекст (Context).
Охраняемые условные переходы (Guarded transitions).
Действия на вход, выход и переход (Actions).
Параллельные состояния (Orthogonal, parallel states).
Вложенные состояния (Hierarchical, nested states).
Историческое состояние (History).
Коротко остановимся на каждой из них.
Контекст и действия
У нас появляется некоторый контекст:
Помимо текущего состояния (строки), можно хранить и набор данных.
Если в FSM состояние — это условно одна переменная, то здесь мы можем хранить набор различных данных.
При отправке события можно отправлять данные — действия будут принимать данные и обновлять контекст.
Помимо этого, когда мы переходим из одного состояния в другое, то можем вызывать условные коллбэки, которые называются действиями. Эти действия как-то обрабатывают события и модифицируют контекст.
Но об этом мы говорим, только когда уже перешли в состояние. А если мы хотим ограничить переходы, можно накладывать некоторые условия. Это называется концепцией условных переходов.
Условные переходы
Действия реагируют на переход в состояние.
Для предотвращения входа в состояние можно добавлять условия.
Теперь перейдём к двум основным концепциям Statechart.
Вложенные состояния
Ниже пример из документации к библиотеке XState, о которой поговорим чуть позже.
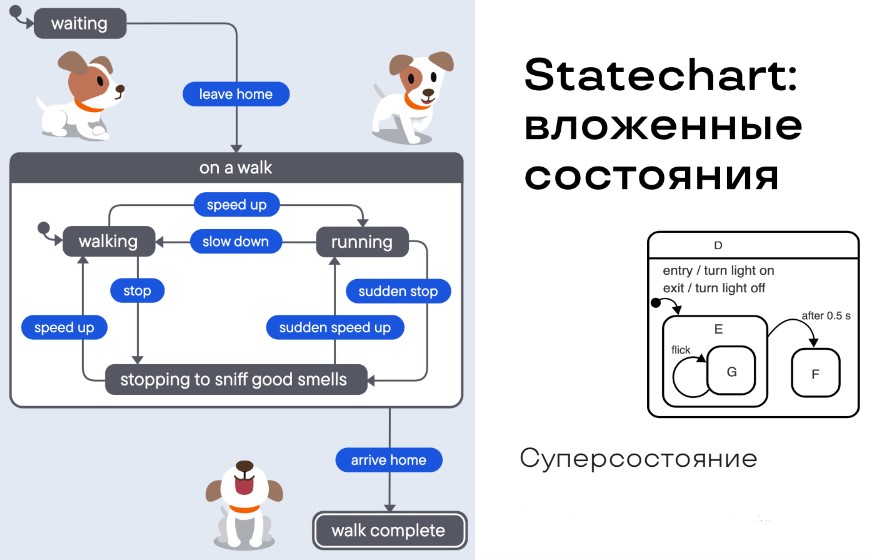
Рассмотрим собаку, которая изначально находится в состоянии waiting, она ждёт чего-то. Если мы подадим команду «покинуть дом» (leave home), то она перейдёт в состояние «в прогулке» (on a walk). Потом она может «прибыть домой» (arrive home), если мы такое событие посылаем, и прогулка завершится (walk complete). Но когда собака находится на прогулке, она может просто идти, остановиться, а может побежать. Состояние в прогулке инкапсулирует в себе три других состояния (walking, running, slow down). Тем самым находясь в одном супер-состоянии, собака может менять эти вложенные состояния.
Из вложенных состояний сразу же рождается вторая концепция.
Параллельные состояния
Вложенных состояний может быть не одно, а несколько. Например, у собаки есть хвост, и она им может вилять и не вилять — это ещё два состояния. Тут появляется вторая вложенная условная машина состояний с двумя состояниями для хвоста.

Но вернёмся к проблемам обычной машины состояний.

Понятно, что концепции вложенных и параллельных состояний полностью решают две последние проблемы про асинхронное обновление части стейта и про то, что некоторые состояния хотелось бы сгруппировать. Однако остаётся проблема с взрывом машины состояний.
Диаграмма Statechart была придумана как раз для решения этой проблемы. И вложенность состояний, и их параллельность — это следствие решения ситуации взрыва числа состояний.

Для решения создаются вложенные параллельные состояния для конкретно каждой из фичей. Тем самым фичи, по сути, становятся независимыми. Это позволяет сильно снизить размер графа. Таким образом, модель Statechart решила все проблемы, с которыми мы столкнулись, реализуя и внедряя машину конечных состояний.
Перейдём к реализации в коде диаграммы Statechart состояний. Самой популярной библиотекой для её реализации является XState.
XState
Библиотека XState обладает несколькими свойствами/фичами:
Создана для реализации Statechart
XState задумана как реализация математической абстракции Statechart. Она реализует контекст, условные переходы, вложенные и параллельные состояния. Библиотека опирается на научную статью, в которой Statechart и был предложен. И имеет развитую инфраструктуру: расширения для Chrome (для просмотра графа) и VS Code, а также визуализатор stately.ai/viz.
Поддерживает сохранение стейта в localStorage
При загрузке приложения можно брать сохраненный стейт из localStorage.

Здесь видно, что изначально граф, который мы нарисовали с помощью описания на языке UML, в XState представляется примерно таким же форматом. Есть некоторые особенности по преобразованию форматов, но, по сути, это то же самое. Если код из XState оформить в визуализаторе stately, то получим схему, один в один повторяющую граф, который мы изначально имели.
Как это выглядит для примера с новостями:

Внедрение диаграммы состояний позволило сгруппировать состояния (на рисунке выше), которые относятся к первой и ко второй рекомендательным системам. Появилась сущность, называемая extraNews, которая внутри обрабатывает различные типы состояний для именно этой рекомендательной системы. Также мы отдельно сгруппировали все состояния, посвященные baseNews.
Как это выглядело в коде:

Акцентирую внимание на 13 и 17 строках, где указан target. В XState есть свой синтаксис селекторов, по которым #news — это на самом деле обозначение id всей внешней машины состояний, диаграммы состояний, а следующий раздел — это вложенная сущность extraNews, либо baseNews, и уже после точки идёт внутреннее состояние внутри конкретно этого супер-состояния.
Если мы учитываем переключение табов, визуализация в stately начинает расти.

На самом деле, с размером нашего графа в продакшене stately уже не справляется — визуализация ломается от такого размера. Отчасти поэтому мы решили рисовать граф сами.
Перейдём к использованию непосредственно в коде. На примере XState и Svelte 3 это может выглядеть следующим образом:

На строчке 5 вызывается функция createMachine из XState, в которую мы помещаем описание машины состояний (описание графа). Всё использование (21-25 строки) сводится к тому, что в некоторые моменты вызывается функция send, которая посылает в систему событие (строка 21), и также исходя из текущего состояния, что-то происходит в отображении (строка 22).
Например, если кликнуть на кнопку через on:click (так пишется обработчик на клик), то вызовется событие send, оно отправит некоторое событие TOGGLE и произойдёт переключение. Ответом на событие TOGGLE в состоянии on был бы переход в состояние active. А в состоянии active на то же событие совершился бы переход в inactive. В зависимости от того, в каком состоянии мы находимся, на 22 строке происходит рендеринг либо одного текста, либо другого в простейшем примере.
Использование модели Statechart = светлое будущее?
На самом деле результаты внедрения XState нас сильно воодушевили:
Продуктовые результаты:
Успешный запуск более 20 фичей в блоке новостей и ещё больше A/B-экспериментов.
Эксперименты, связанные с отображением новостей,проходят независимо от экспериментов, связанных с данными.
Число багов снизилось до единичных случаев.
Плюс, появились дополнительные возможности, например, за счёт того, что мы лучше стали контролировать состояния, смогли добавить отрисовку скелетонов в момент загрузки блока новостей, улучшили пользовательский опыт за счёт новых анимаций.
Обновления для команды:
Добавление нового типа/источника новостей теперь сводится к созданию нового узла в графе.
Граф — понятная документация как для менеджеров, так и для разработчиков и тестировщиков.
С использованием Statechart исчезла необходимость тестирования смежных узлов в графе — только добавляемый. После того как мы выкатили финальную версию, Time To Market, в результате сравнения на похожих фичах, снизился в 3 раза по сравнению с первой итерацией блока новостей.
Задачи поменяли свою форму. Вместо создания новой фичи для конкретного таба теперь она сразу доступна на всех табах и управляется отдельным конфигом менеджерами.
Новая реализация блока новостей, основанная на диаграмме состояний, повлияла вообще на весь workflow. Если раньше задачи приходили с формулировками вроде: «давайте добавим такой-то тип новостей на такой-то таб», то теперь задачи формулируются в виде: «давайте добавим такой тип новостей, который будет так-то работать». Уже то, в каком табе будет включаться этот тип новости для рекомендательной системы, определяется в удаленном конфиге, который может «налету» править менеджер.
То, что у менеджеров появилась возможность править конфиг полностью самостоятельно, радикально влияя на набор и состав всех новостных табов, сильно снизило число задач, которые требуют разработки. Типичная задача стала выглядеть так, что нужно добавить некоторое супер-состояние, в котором будут каким-то образом инкапсулированы переходы между загрузкой новостей, их показом и т.д. В таком виде было поддержано больше, чем 25 различных состояний в блоке новостей.
Кроме множества плюсов у подхода есть и возможная проблема: c добавлением разных типов новостей увеличилась сложность разработки нового супер-состояния. Если необходимо сделать fallback из одного супер-состояния в другое, то не всегда понятно, что в этот момент должно происходить с контекстом. Возможно, эти проблемы — не в текущей реализации, а в сложности задач, которые теперь стали возможны благодаря переходу на этот подход.
Советы по использованию модели
Модель Statechart должна хранить только текущие и актуальные данные.
Если необходимо проводить кэширование, это следует делать на уровне, находящемся выше модели Statechart. Важно, чтобы состояние в модели хранило именно данные, а не занималось управлением отображением. Если, например, требуется отобразить старые новости в интерфейсе, для этого следует создать дополнительный абстрактный уровень, который занимается кэшированием.
Состояние не обязательно должно использовать один и тот же метод для получения данных.
Состояние в модели должно отражать ментальное состояние данных, а именно как приложение ведёт себя в конкретный момент. Это значит, что для разных состояний может быть предусмотрена разная реализация. Например, в состоянии «загрузка новостей» можно использовать разные транспорты, методы запроса данных.
В конце концов мы получили машину, которая выглядит как тот самый лайнер обложки статьи под названием «Wonder of the seas». Надо отметить, что он большой. Человеку, который туда первый раз попадает, нужно какое-то время, чтобы разобраться в навигации. Но как только он разберётся и поймет, как всё устроено, то сможет двигаться вперед с большим комфортом и скоростью.
Хочется закончить статью словами известного проектировщика взаимодействий:
«Суть хорошего программирования в отсроченном вознаграждении»
Алан Купер