
Это данные оплаты различных штрафов, пошлин, налогов и так далее. Такая информация потенциально может быть полезна для разных банковских сервисов. Например, если человек часто платит штрафы ГИБДД, значит, у него есть автомобиль, и это полезно знать для многих вещей вроде кредитного скоринга или понимания, что он может легко уехать в соседний регион и сделать «нетипичную» транзакцию в банкомате. Это позволяет, к примеру, эффективнее проводить фрод-мониторинг по картам и нетипичному месту проведения операции, что привлекательно и для банка, и для клиентов. Таких классов — сотни, то есть в идеале надо пытаться понять по документам платежа смысл действия.

Сначала мы просто искали слова вроде «авто» правилами, а потом перешли на NLP-подходы.
Natural Language Processing чаще всего используется в банках для автоматизации обработки заявок и анализа входящих документов, чтобы их маршрутизировать или классифицировать.
Конечно, это можно было бы делать и руками, но тогда это стало бы очень долго и дорого.
Я ведущий аналитик-исследователь Управления алгоритмов машинного обучения. Расскажу о том, как с помощью ML- и NLP-технологий, а также огромного массива только платёжных данных можно получить полезную информацию для банковских сервисов: скоринг клиентов, кредитование — в целом широкий спектр моделей, где клиентов нужно как-то оценивать.
Добросовестным пользователям такой подход тоже приносит ощутимую пользу, т. к. есть возможность получить от банка ровно те предложения, которые могут им пригодиться.
Как было
Данные витрины с платежами, про которую я писала выше, разбивались по нескольким базовым категориям, и на данный момент именно такая информация используется в банке, принося свою пользу. Это были составленные вручную простые правила, например, если в тексте платёжки есть слово «авто», значит, документ относится к категории «Автомобили».
Причём, если появлялся запрос от внутреннего заказчика, выгрузка по категориям создавалась вручную. И когда появлялся новый заказчик, которому была нужна какая-то новая информация по этим же данным, вся процедура ручной выгрузки повторялась. Проблема была в том, что каждому заказчику нужны разные категории рисков, другие категории распределения данных.
И если эти категории новые, то нам приходилось вручную это всё прописывать, прорабатывать и категории, и данные.
Существующая разметка данных была неидеальной, поскольку ориентировалась на пословное совпадение. Из-за этого возникали ошибки. Например, могли неправильно категорироваться платёжки, где были опечатки или использовались синонимы.
Со временем стало понятно, что такой подход негибкий, и мы решили применить к таким данным NLP. В информации о платежах есть текст, и эти тексты можно как-то анализировать для того, чтобы автоматизировать процесс выгрузки нужной заказчикам информации.
Преимущество технологии NLP состоит в том, что она может обработать любой тип текстовой информации (структурированный/неструктурированный), даже если в платёжных документах одна и та же тема написана по-разному и используются совершенно разные слова при описании одного и того же события, и учитываются опечатки в словах.
Что решили делать
Вначале у нас стояла довольно непростая задача — агрегировать информацию по клиентам, по разным категориям платежей и более широкому набору категорий. То есть надо было создавать крупную разбивку данных на основе правил — она используется в рисках, в автокредитовании, в других моделях, где нужно оценивать клиентов.
Мы решили попробовать, чтобы платёжный документ описывался как можно более широко с помощью различных, в том числе новых категорий. Этим мы хотели покрыть максимальное количество потенциальных запросов наших заказчиков вне зависимости от того, каким бы обширным такое описание ни получалось. Т. е. нужно было минимизировать необходимость ручной доработки при выполнении запроса.
С помощью различных методов мы сделали классификатор (на основе логистической регрессии и градиентного бустинга). Когда мы его применили, сначала в некоторых моментах он ошибался, и полученное решение не совпадало с существующим решением авторазметки на основе правил.
Такие кейсы мы выгружали отдельно и смотрели, что в них происходит и почему классификатор не мог чётко определить категорию транзакции.
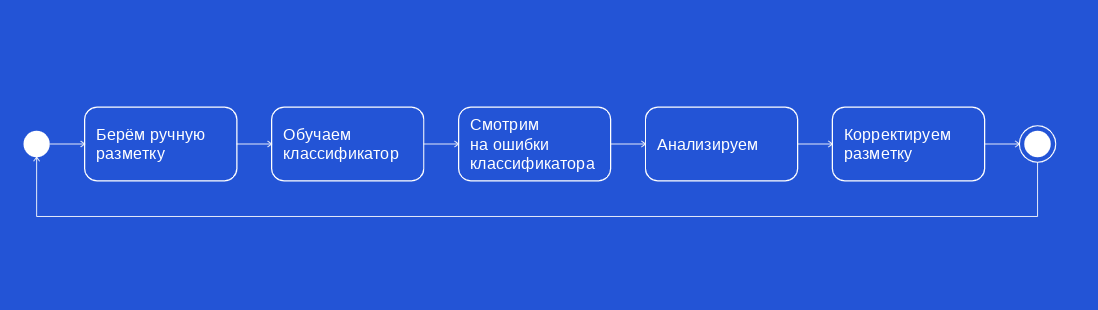
С помощью такой классификации мы смогли производить автоматическую разметку данных и создавать более выгодный их набор (dataset). Этот подход предоставил нам возможность с помощью машинного обучения выделить те классы, которые было нельзя найти вручную, и сформировать итоговый список категорий. Это позволило нам оставлять несколько меток, находить редкие случаи, сокращать ручной труд и экономить время.

Изначально у нас платёжки и административных штрафов, и по постановлению судьи по какому-либо протоколу относились просто к административному штрафу. Сейчас мы можем выделить более конкретизированную информацию. По тексту платёжного документа мы можем определить, что это оплата по протоколу, допустим, за хранение оружия. Данные платежей остались теми же самыми, но мы о них знаем больше и можем получать более детальную информацию о плательщике.
Так модель позволила находить новые классы на стыке уже имеющихся, удалось также выделить ошибки в разметке на регулярных выражениях.
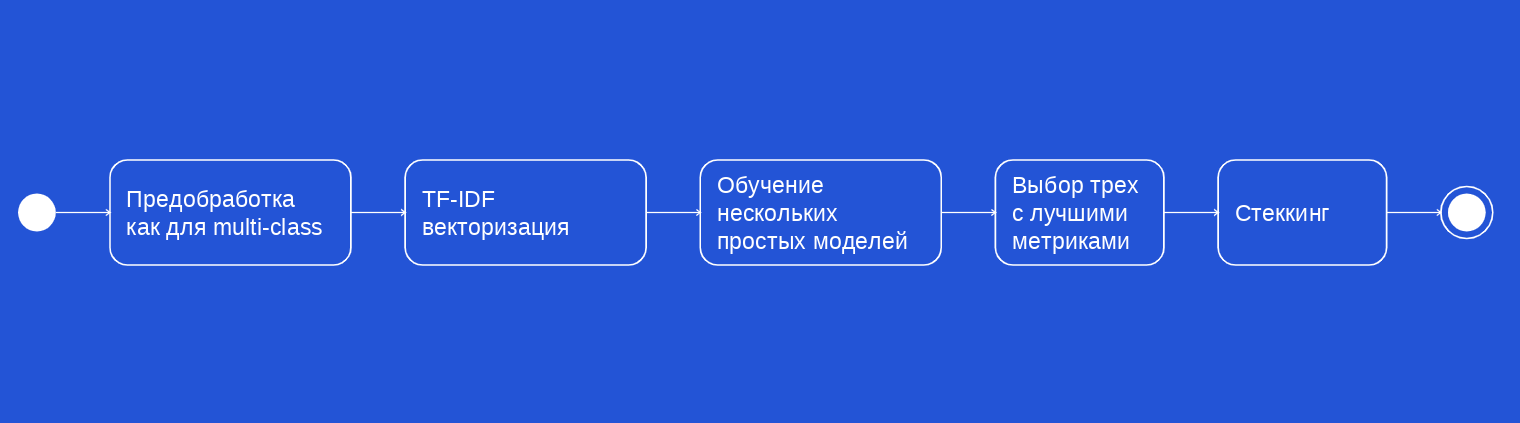
После проведения нескольких итераций, найдя определённое количество ошибок, новых категорий, какой-то детализации, мы перешли к реализации метода многоклассовой классификации с пересекающимися классами (multi-label classification).
Итоговый выход классификатора — результат стеккинга трёх классических моделей машинного обучения (случайный лес, k ближайших соседей и классификатор на основе стохастического градиентного спуска) и векторизации с помощью TF-IDF. Этот метод отличается от обычной классификации тем, что каждому объекту может соответствовать несколько меток классов. Для нас было изначально важно, чтобы была именно подробная информация о платежах, которая позволяла бы гибко отличать их друг от друга, распределять и категорировать.
В результате нам удалось добиться, что каждая платёжка получает некоторый список категорий. Это фиксированный список, но при необходимости он может расширяться, чтобы заказчик мог получить необходимую ему информацию. Т. е. мы теперь по-другому описываем данные.
Преимущества по сравнению с базовой ситуацией
Ранее при обработке данных мы выделяли какую-то одну категорию. Т. е. система находит что-то определённое — слово или словосочетание, — записывает это в условное совпадение и затем определяет в категорию. Категории не были чётко разделены, и из-за этого их трудно было описать какими-либо правилами, даже сложными. Было трудно выделять несколько категорий, потому что они были смешаны: в одну и ту же относились и штрафы, и пошлины, и плата по постановлению суда. К тому же нужно учитывать, что тексты платёжек со временем могут меняться и построчные совпадения просто перестают работать.
Правилами невозможно описать все возможные категории и отношения между ними, особенно учитывая, что у всех заказчиков — разные интересы. Кроме того, одна и та же платёжка может относиться сразу к нескольким категориям.
Ещё правилами не учитывался контекст. К примеру, слова «штраф» или «авто» могут быть в названии организации. В этом случае, если человек проводил любую оплату такому предприятию, эти данные автоматически записывались в категорию «Штрафы», хотя, по сути, таковыми не являлись. Или ещё такой пример: фамилия плательщика Загранец определялась как пошлина за загранпаспорт. Подобные случаи невозможно определить простыми правилами.
К тому же простые правила не покрывают каких-то категорий, непонятных человеку, который эти правила пишет. Кроме того, невозможно вручную отловить очень редкие примеры: там миллионы записей, и, естественно, проанализировать их все невозможно.
Такие правила не учитывают и опечаток как я писала выше: система просто игнорирует слова, где буквы стоят не в том порядке. Перебрать и учесть все сочетания невозможно. Мы уже сталкивались с этим, это не разовая история.
Новый подход, использующий технологии NLP, анализирует, какие вообще слова или словосочетания могут относиться к определённой категории. Он может оценивать похожие слова: похожие по буквенным сочетаниям, по значениям, по смыслу. Это даёт возможность минимизировать ошибки, ложные попадания в неправильную категорию и увеличить итоговое нахождение всех классов.

Источник
Если при прежнем подходе, основанном на правилах, ничего ни по одному шаблону в тексте не нашлось, то система просто отправляет документ в категорию «Прочее», и эта платёжка игнорируется при итоговой выгрузке задач, когда собираются данные (например, за 2022 год больше 500 тысяч записей ушло в «Прочее» при крупной разбивке на правилах).
В результате новая модель на основе многоклассовой классификации с пересекающимися классами позволила минимизировать категорию «Прочее» до 40 тысяч, стала находить больше вхождений в другие категории и тем самым получать больше полезной информации.
Автоматическая разметка осуществлялась на основе ручной с помощью метода One vs Rest с логистической регрессией в качестве классификатора.
Предложенный подход даёт возможность для каждой транзакции сделать перечень категорий, которые можно использовать в других моделях в качестве эмбеддингов. На сегодняшний день уже получены неплохие результаты на крупной разбивке для рисков и Авто CRM. Сейчас планируется сделать более детальное разбиение для гиперперсонализации.
Ключевые ошибки
Изначально мы допустили ошибку, когда попробовали начать с кластеризации данных. Это подход, который позволяет разделять тексты на основе именно их смыслового или хотя бы текстового содержания, то есть похожих слов, формулировок, слов, похожих по значению. Все эти тексты как-то разделялись, и именно эти группы рассматривались отдельно друг от друга и анализировались, о чём они могут быть.
Цель — разбить платежи на кластеры и понять, что каждый из кластеров представляет собой для дальнейшей классификации. Таким образом мы хотели получить список классов, которые можно соотнести с бизнес-смыслом.

Но такой подход не привёл к желаемым результатам. Кластеризация показала плохую разделимость и смешанность кластеров. Из-за этого в ходе экспериментов не удалось выявить потенциально новых классов (неожиданных и редких, например, расторжение брака, выдача апостиля или безбилетный проезд). Пробовали разные подходы: LDA-модель от gensim, k-средних с различной векторизацией (TF-IDF, fastText).
Поставленная цель не была нами достигнута, и через несколько итераций, в которых использовались разные подходы, мы пришли к выводу, что это не работает. В итоге мы потеряли время, отрабатывая этот подход (впрочем, это поможет нам обучить модель в будущем), и лишь потом перешли к разработке классификации, используя прежнюю разметку как основу.
Чего добились
Сейчас мы максимально близко подошли к тому, что от нас требовалось, и планируем следующий этап — агрегацию результатов модели по клиентам и построение эмбеддингов. На данный момент мы уже составили список требований, вносим корректировки в разметку (для сокращения ложных срабатываний модели) и приступаем к построению эмбеддингов. Процесс будет выглядеть так:
- Получение результатов multi-label модели.
- Агрегация по клиентам (категория платежа, сумма и тд).
- Обучение полученных из пункта 2 данных на целевую переменную из других моделей департамента — построение эмбеддингов на основе скрытого слоя.
Подготовлен прототип, который будет агрегировать полную информацию по клиентам. Такие агрегированные данные будут использоваться на обновлённой витрине данных совместно с другими сведениями об этом же клиенте, полученными с помощью других моделей, работающих в банке. Информация будет передаваться заказчикам, чтобы они могли использовать её уже на своих моделях.
Комментарии (2)

mmandaliev
05.10.2023 09:35+1Являясь практически ваш коллегой, только в одном из топ 10 банков мира, не смог удержаться...
Я удивлен, что кто-то в вашем банке разрешил публично опубликовать такую статью. Был бы я вашим клиентом - уже бы закрыл бы все мои счета у вас. В силу своей работы, я отлично понимаю, насколько жизнь клиентов прозрачна для вас как банк. НО! взять и в открытом доступе пустить статью из разряда "Ну да, мы копаемся в вашем грязном белье и теперь ищем там как можно больше грязи уже с помощью NLP" - это верх не-профессионализма, либо по..изма для такого "Очень большого банка". Спасает вас, что большинство ваших клиентов вряд ли читает Хабр...
... в ходе экспериментов не удалось выявить потенциально новых классов (неожиданных и редких, например, расторжение брака, выдача апостиля или безбилетный проезд).
Мне вот честно очень интересно, а что вы как БАНК, собираетесь делать с информацией о безбилетным проходом? Социальный рейтинг вашего клиента понизите или кредит на оплату проезда предложите?
Безналичная оплата услуг девушек легкого поведения как что будете размечать?
... оружие, штрафы, пени, просрочки, налоги, граница, имущество
Вот это все, вас как банк, каким образом касается? Правовая база для анализа такой информации у вас есть? Ваши клиенты разрешали анализировать их отношения с третями лицами?
Информация будет передаваться заказчикам, чтобы они могли использовать её уже на своих моделях.
Судя по всей статьи, заказчики в основном из ФНС, ФСБ и других Ф-службах выступать будут или вы расскажете еще - кто и в каких целях эти "витрины нижнего белья" анализирует?
kovserg
Чистая прибыль российских банков в 2022 164 млрд рублей, а в 2023 2,6 трлн рублей. Что почти 1585% роста за год, ни смотря на СВО. Это конечно же благодаря NLP используем в банках? Или какие-то другие прорывные технологии используются?