
Допустить незначительную ошибку в конфигурации — очень просто. Однако, череда таких некритических уязвимостей может привести к компрометации системы. Поэтому, даже если других дел тоже очень много, нужно уметь не допускать таких ошибок, то есть изначально настраивать инфраструктуру безопасно.
Собственно этим мы и занимаемся. Мы, это Артемий Богданов и Илья Горбунов. Делаем продукты экосистемы Start X для безопасной и эффективной работы в цифровой среде. Артемий выполняет роль хакера: находит уязвимости и помогает их закрывать, а Илья занимается инфраструктурой и Ops-процессами. У наших клиентов мы видели много некритичных ошибок в инфраструктуре, которые приводили к серьёзным последствиям. Мы сделали собирательный образ этих уязвимостей, о котором расскажем на примере компании E-CORP.

Все наши истории мы разбили на 4 темы:
«Потеря» или «кража» домена;
Атаки на цепочки поставок;
Патч-менеджмент;
Небезопасная настройка сервисов.
Для удобства повествования мы выделили 4 роли участников E-CORP:
Васян — очень «ответственный» исполнитель;
Алекс — менеджер проекта с «великолепными» идеями;
Антон — безопасник;
Хакер — человек, который устроил им всем весёлую жизнь.
«Потеря» домена
Неоплаченный хостинг/сервис
Компания E-CORP разрабатывает свои CRM и сайты, соответственно, часто нужны промо. Так, у Алекса рождается идея: максимально быстро создать промо-лэндинг, который партнёр-разработчик будет делать и хостить. Хостинг партнёром может выступать Tilda, Netify и прочее. Всё, что нужно сделать E-CORP — настроить DNS.
Чтобы испортить сладкую жизнь разработчикам, хакер начинает разведку: с этого этапа — рекогносцировки — начинается любая его атака. Его задача — собрать как можно больше информации из открытых источников. В случае E-CORP хакер знает, что при добавлении своего домена на хостинг вам нужно его валидировать, например через DNS. Обычно достаточно проверить и добавить записи, но не все хостинги требуют повторной валидации домена при настройке его в профиле, если он уже был валидирован. Поэтому первое, что ищет хакер — это поддомены и различные сервисы на них. Для этого ему достаточно лишь использовать следующие способы:
Специальные google-dork запросы типа: site:*.example.com;
Если компания использует letsencrypt для выписки сертификатов на поддомены, тогда можно весь список поддоменов взять из transparency log;
Подбор поддоменов по словарю наиболее часто используемых поддоменов с помощью, например, утилиты типа subfinder.
Хакер проходит по данным методикам и останавливается на том, что через transparency log находит валидированный, но не привязанный к проекту домен, прибитый к Tilda.
Дальше тактический смех — чтобы его получить к себе, хакер регистрирует реальный аккаунт в Tilda и настраивает домен как свой. После чего на домене висит заглушка с валидным HTTPs.
В реальной жизни злоумышленник будет использовать этот домен для фишинга, мошенничества или с целью эксплуатации уязвимостей на других ресурсах компании.
Антон словил всю эту историю и начал разбираться. Вместе с командой безопасников они пришли к тому, что нужно:
Провести инвентаризацию ресурсов, к которым относятся не только железо и виртуалки, но также домены, почтовые сервисы и вообще всё, что используется в проекте;
Мониторить ресурсы. Даже простой баш-скрипт, написанный на коленке, может диггать доменную зону, искать тексты о компании, чтобы дать вам возможность увидеть аномалии с вашими сайтами;
Больше не направлять поддомены на левые хостинги, а использовать только свои ресурсы. В таком случае даже если вы облажаетесь и случится ситуация выше, то попадете всё равно на свои же ресурсы.
S3 — ошибки прав и статический веб-сайт
Однако, история на этом не заканчивается. К Васяну приходит Алекс и говорит, что нужен бакет для обмена данными с партнёром, причём сделать его нужно как можно скорее. Менеджер советует исполнителю не делать авторизацию под предлогом, что не будет никаких приватных данных, только UID, которые синхронизируют данные, да и партнёр не очень умный. Вася отвечает: «ОК, но policy с ходу не напишу», и идёт на Stack Overflow. В первом поиске он находит:

Васян берёт S3-бакет, подключает блок public access, если он вдруг выключен, потому что иначе не сможет прикрутить public policy. В конце он вешает policy из соседнего комментария:
{
"Version":"2012-10-17"
"Statement": [{
"Sid":"AddPerm",
"Effect": "Allow",
"Principal: "*",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource":[
"arn:aws:S3:::your—bucket—arn-here/*"
]
}]
}Но в то же самое хакер чекает DNS-записи найденных им доменов, чтобы посмотреть, если какой-нибудь из них ссылается на S3-бакет. Так просто у него найти не получается, поэтому он использует различные способы.
Самый сложный способ заключается в том, чтобы использовать имя бакета как поддомен при обращении к AWS S3 по HTTP. Если бакет существует, то хакер получит один ответ от AWS S3, если его нет, то ответ будет другим. Таким образом можно понять существует ли бакет. Чтобы упростить задачу, можно собрать словарь часто используемых поддоменов или имён, которые в бакетах используются, а также словарь ключевиков, которые относятся к конкретной организации. Затем используется brute-force, например, Intruder из Burp Suite для того, чтобы быстро пробежаться по всем этим поддоменам и найти бакеты, которые в действительности существуют.

Также существует куча онлайн-сервисов, которые позволяют найти эти бакеты. Бакеты там уже заранее проиндексированы. Поэтому хакеру достаточно просто зайти туда, ввести пару ключевых слов и он увидит список бакетов.

Дополнительно можно искать по контенту внутри бакета.

Там могут находиться, например, скриптовые файлы, содержащие в себе интересные секреты, которые, например, могут позволить получить доступ к AWS.
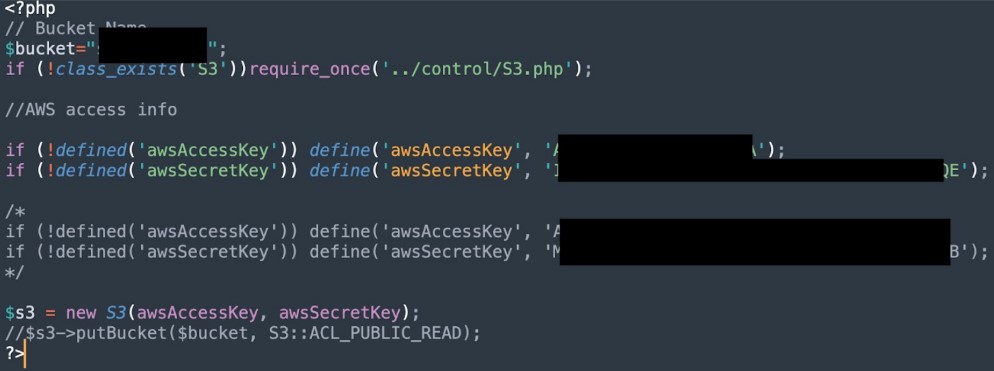
Кроме того, там могут быть ключи, например, к SSH-серверу:

Найдя такой ключ, хакер может тут же завладеть сервером компании. И всё это возможно с помощью одного лишь Гугла. Однако, у хакера может и не получиться скачать файлы через публичный доступ, то есть он может натолкнуться на ответ AccessDenied от AWS S3 API. В таком случае хакер постарается достать эти файлы через консольную утилиту AWS CLI. Для этого он просто регается в AWS, получает свой API Key и вместе с ним пытается обратиться к чужим бакетам.

Если политики настроены неверно, то будет возможность, например, вызвать листинг директорий, посмотреть, что там внутри, скачать какие-нибудь файлы, и в самом плохом случае отредактировать и залить уже обновлённый файл на бакет. Соответственно, если какой-то поддомен организации ссылается на этот бакет, хакер сможет контролировать всё, что этот поддомен выдаёт, например, эксплуатировать различные XSS или другие уязвимости, которые завязаны на этот конкретный поддомен.
Чтобы избежать подобных сценариев в дальнейшем, Антон предлагает своим коллегам из E-CORP следующее:
Не использовать больше public policy на бакетах. Все кто пользуют AWS знают, что с конца марта block public access policy будет дефолтный для всех бакетов. Это сделано специально, чтобы неумные люди не могли сделать таких косяков.
Делать политики безопасности известными, понятными для всех. Это не бумажная безопасность, которая существует только ради того, чтобы сдать документацию. О ней должны знать и исполнять, даже если PM что-то хочет очень быстро.
Атаки на цепочки поставок
Умышленное добавление зловреда разрабом
Разработчики пишут CRM на Python. Код растёт, качается, деплоится, иногда падает, благо, что Васян успевает поднять. Но после апдейта код вообще не поднялся! Вася с командой потом узнали, что в связи с последними политическими событиями создатели некоторых популярных библиотек добавили зловредную функциональность. При запуске с российских или белорусских IP адресов она может, например, удалить файлы на машине запуска.

И это не единственный риск. Существует множество хакеров, которые специально делают зловредные зависимости в публичных репозиториях, используя технологии тайпсквоттинга. Если разработчик буквально одним символом ошибется при добавлении такой зависимости, он может скачать зловред вместо библиотеки. К тому же ещё существует социальная инженерия. На разработчиков популярных библиотек регулярно ведутся атаки. Если кто-то с помощью фишинга, например, завладеет их аккаунтом, он сможет подменить библиотеку, которая расположена в репозитории, и таким образом доставить зловредную нагрузку на сервер компании.
Антон со своей командой проанализировал эту ситуацию и предложил несколько принципов, которых стоит придерживаться в целях безопасности:
→ Принцип минимальной необходимости.
Если библиотека не нужна, почти не используется или её функциональность содержится в другой библиотеке проекта, то её лучше вовсе удалить.
→ Выбор зависимостей по критериям.
Исчерпывающего списка нет, то есть подборка от Антона:
Чем больше звёзд, форков и скачиваний, тем больше сообщество разработчиков следит за этой библиотекой. Они быстрее находят недочёты, уязвимости и прочее, и докладывают об этом разработчикам библиотеки;
За трендовыми библиотеками, пристальное внимание разработчиков и секьюрити-сообщества. Соответственно, все проблемы в них решаются быстрее;
Известные авторы типа Google, MS, FB вызывают большее доверие;
Если разработчик/мейнтейнер действительно регулярно обновляет код, следит за ним, реагирует на тикеты, которые к нему приходят, это говорит о том, что библиотека не брошена, уязвимости закрываются;
Хорошая документация может говорить о хорошем качестве кода;
Если библиотека содержит небольшую функцию, но в целом весит достаточно много, значит, разработчик где-то поленился или добавил чего-то лишнего. С такой библиотекой можно затащить ненужные зависимости, код разрастётся, а чем больше кода, тем больше места для уязвимостей.
→ Следуйте правилам добавления зависимостей в проект или обновления уже существующих.
И снова советы Антона:
Проверяйте известные уязвимости у каждой зависимости. Это можно сделать с помощью встроенных утилит пакетных менеджеров, например, npm audit/bundler-audit/pip-audit/etc или с помощью сторонних средств, например, OWASP depcheck, DependencyTrack и прочего. Они позволяют разработчику, просто вбив название библиотеки, найти уязвимости её самой свежей версии;
Если в компании уже есть средства для статистического анализа кода, их стоит использовать ещё на этапе добавления новой библиотеки, чтобы как можно раньше найти проблемы. Если статистического анализатора ещё нет, можно найти его и добавить. Есть множество бесплатных утилит, которые решают эту задачу, например: rubocop, nodejsscan, prospector;
Тестовый контур нужно организовать в любом случае. Но также в вопросе с зависимостями тестовый контур поможет протестировать изменения поведения приложения после обновления библиотеки. Речь идёт об аномальных активностях, странных запросах во внешнюю сеть, повышении нагрузки.
Если в компании есть команда пентестеров, то с ними нужно сотрудничать и привлекать каждый раз при добавлении чего-то нового или релиза.
→ Фиксировать зависимости (lock-файлы).
После проверки на то, что библиотека конкретной версии не содержит уязвимостей, нужно зафиксировать её, то есть использовать именно её в проде.
→ Локальные кэширующие репозитории.
Поставьте локальный кэш, чтобы кэшировать проверенные пакеты. Это, как минимум, вас немного успокоит.
Локальные и глобальные зависимости
Допустим, команда E-CORP хочет переиспользовать некоторые свои модули в других проектах. Рано или поздно у разработчиков появляется локальный репозиторий, который они добавляют в пакетный менеджер языка программирования (например package.json) как дополнительный (external).
Хакер каким-то образом узнаёт название этой приватной библиотеки. Например, компания упомянула его в одной из публичных реп своего проекта. Тогда хакер создаёт зловред и публикует его с таким же именем в публичном репозитории. В зависимости от настройки пакетного менеджера возможна ситуация неверных приоритетов репозиториев. Тогда будет скачан этот зловред и проект окажется собран с ним. Похожие истории происходили даже с крупными компаниями типа Apple, Microsoft:
Похожая история может случиться из-за плохой (кешер пойдет в публичную репу за пакетом) настройки кэша.
Антон узнал об этом и сказал Васяну давать приоритет своим локальным репозиториям. Если говорить про продукт на Python, то нужно:
Никогда не использовать --extra-index-url;
Использовать --index-url, который будет указывать из какой репы брать данные, а из какой — нет;
Забанить свои пакеты на репе-прокси. Сделать это несложно: почти все прокси имеют роутинг. Например, Nexus:

Policy rules позволяют по каким-то паттернам заблокировать или разрешить пакеты. Поэтому Алекс запихал туда все паттерны внутренних пакетов компании и добавил в проксирующую репу (в данном случае) NPM.

Даже если команда где-то сильно накосячит, их кеширующая репа не обратится за пакетом в паблик. Может быть при этом сборка упадёт, CI/CD ругнётся, но зато всё обойдётся без уязвимости.
Docker образы
Коллеги из E-CORP стали думать насчёт использования Docker для удобства и доставки. Но Антон нашёл в интернете множество исследований о безопасности Docker-контейнеров:
Оказалось, что достаточно много контейнеров содержат в себе какую-то зловредную функцию:

Более того, есть целая категория хакеров, которые используют тайпсквоттинг, чтобы обманом заставить разработчиков добавить зловредный образ. Такой образ может содержать какие-то криптомайнеры, воровать секреты из образа или выполнять какие-то иные вредные функции.
Разработчики не стали долго в этом разбираться и пришли к тому, что нужно:
→ Подходить к выбору образа как к зависимостям кода.
Есть куча сервисов и возможностей, даже встроенных в Docker, позволяющих потестить хотя бы образ CVE, например, docker scout cves, Snyk. Кроме того, можно использовать Linux Malware Detect для поиска базовых malware в образах. Ещё есть бесплатный антивирус ClamAV. Эти простые утилиты уберут, как минимум, 90% потенциальных проблем.
→ Понимать продукт и не плодить сущности.
Есть проекты с кучей контейнеров, в котором каждый разраб пытается затащить разные Nginx. Когда Васян посмотрел на это, он подумал: зачем, ведь достаточно взять один контейнер и нормально его настроить. Не стоит таскать с собой кучу вариаций одного ПО, в которой сложно разобраться, потому что если что-то пойдёт не так, то разбор проблемы отнимет уйму времени.
→ Использовать Rootless мод.
Root в контейнере — одна их критичных уязвимостей, особенное если к нему идёт такая штука в compose:
-v /var/run/docker.sock:/var/run/docker.sock,
Если уж тут возникнет проблема, то скорее всего, такая что всё умрёт. Поэтому режим rootless — самый простой способ избежать трудностей.
→ Перечитать на досуге родной секьюрити Docker.
Вот хорошая документация для тех, кто плохо знает Docker. Там почти всё описано и есть много примеров, как точно делать нельзя.
Секреты в GitHub
Однажды, великолепный исполнитель Васян подумал: «Ага, мы новый код залили, нужно секреты положить, но они кажется какие-то не очень продуктовые(критичные). Положу их в .env!»
Но в таком случае хакер ещё на этапе разведки (рекогносцировки) сможет с лёгкостью найти все эти секреты, просто вбив супер-банальные Google-дорки в GitHub:

Поэтому, когда Антон услышал идею Васи, он дал ему лопатой по голове и прочитал наставление: секреты — не так секретны, как можно подумать. Это не зависит от платформы: GitLab, GitHub и прочего. Если секреты лежат в репе, то есть высокие шансы, что они всплывут. Поэтому есть небольшие простые решения, которых нужно придерживаться:
Использовать branches protection rules: разрешать мержить только с pull request и смотреть, что туда реквестят;
.env и все подобные файлы конфигурация надо покрывать функционалом CodeOwners’ом, чтобы Dev/Ops’ы это посмотрели и, если что, выкинули. Это позволит, как минимум, снизить количество утечек важных параметров. Хотя бывает и такой хард-код, который никто не найдёт, потому что он находится в 33 модулях в 33-й папке, и всплывёт только по приходу пентеста;
GitLab и GitHub точно поддерживают OIDC провайдера. Он позволяет входить в инфру (в облачную и в личную, если есть OIDC провайдер) бесключевым доступом, только используя OIDC роли и OIDC конфигурации. Это, как минимум, уберёт секреты Amazon/Azure/OpenStack и прочее из вашей репы;
Хранить секреты в другом месте. Есть много вариантов, начиная от Volt, кончая встроенными Azure Secret Manager, AWS Secret Manager, Яндекс-секретами;
Правильно использовать секреты в GitHub. У него есть хорошая документация;
Не использовать структурированные данные в качестве секретов. Антон видел ребят, которые хранили в одном секрете массив JSON с порядка 40 параметрами. Это очень удобно и парсится классно, но любая ошибка выдаёт секрет в ouput workflow. Такая ошибка — классика жанра;
Если говорить про GitLab и GitHub, все важные данные, которые используются в Workflow, нужно регистрировать как секреты. Для примера: нам этого нужно запросить JWT токен от внешнего сервиса, который является текстовой строкой. В обычно случае он будет виден в output как есть, но при использовании маскирования - нет. Так делают в больших энтерпрайзах;
Проводить аудит того, как команда работает с секретами;
Использовать УЗ с минимальными правами. Это позволит одновременно уменьшить количество прав и максимально ограничить использование этой роли другим человеком. При правильной настройке OIDC можно сделать матчер уровня «репозиторий, с которого используется доступ», «организация, которая пытается просить этот доступ у OIDC». То есть сделать максимальное ограничение доступа какой-то репой;
Нужно не забывать менять сами секреты, хотя бы раз в 3 месяца. Разработчики E-CORP видели секреты на Amazon, которые висят порядка 3-х лет, и их никто не менял. За это время сменилась куча разрабов, PM, CI/CD, а секреты всё те же самые;
Ограничить доступ к секретам с помощью функционала protected branches и environments. Логика такая, что только определённая ветка будет иметь доступ к секретам своего окружения. Соответственно, с любой другой ветки чуваки не смогут получить секреты защищённого окружения (продакшен). А в продакшене будут иметь доступ только “полтора инвалида”, которые, как минимум, понимают, что происходит.
Патч-менеджмент
Сервисы, забытые на внешнем периметре
Проводя очередную рекогносцировку, хакер обнаружил, что некоторые сервисы, в частности Jenkins, были публично доступны без необходимости авторизации. То есть, чтобы посмотреть списки джоб, не нужно было иметь учётную запись. Кроме того сервис Jenkins E-CORP обладал забавным свойством пропадать и появляться день через день.
Это же обнаружил и Антон, он стал подбирать варианты, что мог сделать исполнитель:
Классическое раздолбайство;
Автодеплой CI-ноды как части стека приложения, когда каждое окружение тащит свою CI-ноду, которая при неудачной настройке может стать публичной;
Внешний подряд, которому по запросу включают и выключают доступ в Jenkins;
Кто-то решил, что умеет в манифесты и ingress, и, из-за ошибки конфигурации, открыл внутренний Jenkins наружу;
Возможно, что в связи с ковидом Алекс работал из дома, но оказалось срочно нужно сходить в Jenkins из-за критических проблем на проде, поэтому он попросил открыть сервис. Но без инвентаризации никто не увидел, что сервис открыт и его надо закрыть после работ.
Дальше Антон решил посмотреть, является ли такой случай нормой. Он использовал самый простой Google dork, который пришёл в голову:

Так Антон нашёл множество открытых Jenkins. Причём некоторые из них тоже оказались без авторизации. В них можно было посмотреть список джобов и их параметры:

Иногда там же можно было увидеть в логах какие-то секреты, которые были плохо прокинуты в джобе. Также можно было увидеть артефакты, которые появлялись в процессе, в том числе, исходный код приложения.

После этого Алекс собрал команду, чтобы разобраться в этой ситуации и прийти к решению. Они пришли к следующим выводам:
→ Непубличные сервисы нельзя публиковать наружу.
Внутренний сервис на то и внутренний, чтобы никто снаружи его не видел. В большом энтерпрайзе бывает так, когда стоит внутренний Jenkins без авторизации с доступом read only, но при этом вебхук — наружу. Хакеру потребовалось лишь 15 минут лазанья по DNS, чтобы найти вебхук и начать его ломать. А так как код вебхуков Jenkins — не идеал, то в некоторых случаях очень просто попасть внутрь сервиса.
→ Ограничить доступы только по личным УЗ.
Конечно, public read only — прикольно и всем разработчикам хорошо. Но пусть они страдают, зато вы будете знать, кто залез и зачем.
→ Аутентификация везде и вся!
Часто, когда поставлен read only, всё равно доступ остаётся открытым.
→ Использовать VPN + 2FA для выхода наружу.
Если вы сильно хотите отдать сервис в паблик, то просто закройте это дело от общего доступа. Сейчас есть тысячи вариаций VPN + двухфакторная аутентификация через приложение, СМС и прочее.
XS-leak — сервисы во внутреннем периметре
После того как Васян понял, что нужно закрывать external-сервисы, прятать их за VPN и вообще следить за внешним периметром, он совсем забыл про внутренний периметр. Ему показалось, что это уже не настолько критично, так как злоумышленник находится где-то вовне, а сервер/сервис уже наружу никак не торчит, значит хакер никак не сможет сконнектиться.
Но хакер знает ряд техник, которые позволяют ему, даже не взламывая никакие компьютеры в компании, получить туда ограниченный доступ. Некоторые из этих техник называются XS-leak. Они позволяют частично обойти same-origin policy в браузере. На сайте можно посмотреть список этих техник и проверить свой браузер на наличие уязвимости.
Большинство этих техник базируется либо на задержках при попытке доступа к какому-либо сервису по HTTP:

Либо на обработке ошибок при попытке такого доступа:

Это приводит к тому, что хакер зазывает одного из сотрудников компании на специальный сайт, который использует XS-leak техники, и пытается просканировать внутреннюю сеть.

Он будет делать запросы, анализировать их, и таким образом потихоньку поймёт, на каких IP адресах, что расположено, в том числе и веб-сервисы. Есть одна интересная особенность — многие сервисы обладают определёнными характеристиками, например, где лежит favicon, где расположен CSS-файл и как он называется. Какие есть JavaScript-файлы и какие картинки. Делая попытки обратиться к этим файлам, злоумышленник может понять какой сервис расположен на данном IP-адресе внутри организации компании. Например, тот же самый Jenkins. Кроме того, от версии к версии каждого продукта расположение этих иконок или сами файлы могут меняться, например может обновиться тема. Таким образом хакер поймёт даже версию этого продукта. Зная версию и продукт, он может доставить туда эксплойт. Поэтому он, контролируя такой сайт, может через браузер пользователя взломать сервисы внутри вашей компании.
Понятно, что у всех есть патч-менеджмент, все постоянно патчат свой паблик. Но надо понимать, что внутренние сервисы нужно патчить одновременно с внешними — это одинаковые контуры и одинаковая опасность.
Небезопасная настройка сервисов
Сервисы с дефектными паролями
Как и у всех отечественных компаний, последний год у E-CORP оказался весёлым:
Вендоры ушли с рынка;
Сервисы начали открещиваться от России и отключать русские аккаунты;
Импортозамещение: начальство приходит и говорит — на наш софт переезжайте.
Поэтому хакерам пришлось потрудиться, чтобы найти на внешнем периметре, какой сервис стал использовать E-CORP:

Это сервис для внутренних конф-коллов. Так получилось, что для того, чтобы подключиться к звонкам хакеру, к сожалению, нужна была учётная запись. Конечно, у него её не было, поэтому он начал исследовать сервис дальше и нашёл вкладку с записями звонков. Зайдя на эту вкладку и произведя поиск по этим звонкам, хакер нашёл несколько записей. Но, чтобы скачать запись такого звонка, сервис требовал ПИН-код. Нагуглив дефолтный ПИН-код в интернете, он ввёл 1234, получил записи звонков компании и мог уже слушать их внутренние разговоры.
Всё это не так страшно, пока там не всплывёт звонок директора, где он обмазывает весь директорат проблемами или который можно будет использовать для voice clonning.
Чтобы больше не допустить такого, Антон справедливо подметил пункт с истории про S3 : политики безопасности должны существовать и быть известными/понятными для всех. Они должны применяться ко всем сервисам, в том числе к тестовым и временным, даже если они запускались на полчаса, чтобы поиграться и выключить. Потому что любой сервис уязвим, если он вдруг открывается наружу. Даже внутренние непубличные сервисы, как в истории с Jenkins, должны быть максимально покрытыми политиками. Поэтому стоит зафайерволить и закрыть всё, что можно, а по возможности повесить сетевой фильтр на входе для уверенности. В таком случае если что-то уж и утечёт — потери будут минимальные.
Ошибки настроек кэширования
E-CORP пишет свою CRM и веб-сайт. Всё работало неплохо, но в какой-то момент сайт начал жёстко тормозить за реверс прокси. Команда пошла к Васе, чтобы он сделал так, чтобы «сайт не тупил». Вася решил быстро запилить кэширование как самый распространённый метод решения проблемы. Он идёт на любимый Stack Overflow и находит в принципе неплохой пример кэширования:

И всё заработало, полетело как самолёт, но до определённого момента.
Хакер нашёл некий эндпойнт на сайте компании — secret/getToken:

По этому эндпойнту пользователю выдаётся API ключ для доступа от его имени к любым сервисам этого сайта. Также хакер провёл некоторое исследование и понял, что если к пути добавить окончание .css, то обработчик такого эндпойнта не поменяется. Кроме того, если окончание заканчивается статикой, например, тем же .css, то ответ кэшируется.
Поняв это, хакер обновил ссылку, в которой кэш ещё не сохранён, использовал знак ?2, чтобы запустить Cache Buster и отправил такую ссылку авторизованному в этом сервисе человеку, сотруднику E-CORP.

Сотрудник зашёл с сессионной кукой, ему в ответе показался токен. Хакер зашёл на этот URL чуть позже. Поскольку сервер закэшировал такой ответ, то он уже без кук получил этот же токен. Таким образом злоумышленник буквально завладел учётной записью сотрудника и дальше с этим токеном может делать всё, что хочет.
Когда Антон всё это увидел, он сразу понял, что эта атака называется cache poisoning, то есть отравление кэша. После чего он побежал к Васе с вопросом: «Вася, ты вообще понимаешь, как твой реверс работает? Ну, копипаст — это хорошо, но нужно хоть чуть-чуть изучать, что ты копипастишь!». Затем он описал более подробно, что нужно:
Понимать, как работает реверс;
Не кэшировать динамические пути, что уходят в бэк. И хотя бывают случаи, когда это делать нужно, но надо понимать, с какими параметрами можно играть, чтобы ничего важного не попало в паблик;
Статику фронта/аплоад можно и нужно кэшировать, но лучше ещё и ограничить только определёнными location.
Итоги
Наверняка вы встречали некоторые из фейлов, о которых мы сегодня рассказали. Их появление зависит не от размера компании, а от её зрелости и организации процессов. Поэтому даже если вы не безопасник, то можете сделать компанию безопаснее (или нет).
Для этого можно взять на вооружение советы из этой статьи, а если вы хотите подойти к делу еще системнее — организовать обучение разработчиков. Например, мы на своей платформе Start EDU помогаем командам разработки научиться писать код без уязвимостей на примерах из реальной жизни, прямо как в этой статье.
Если у вас есть аналогичные интересные истории, пожалуйста, присылайте их нам в телеграм-бот @devops_stories_bot. Мы разберём и самые интересные опубликуем, причём вместе с решением, как можно безопасно к этой проблеме подойти.