
Задача детекции объектов на видео или фото — это распространенная задача, для решения которой уже есть множество решений. Но она становится чуть труднее, если мы хотим сделать это в режиме реального времени на не самом мощном мобильном устройстве. В данной статье мы делимся своим опытом создания приложения для детекции атомобилей на мобильном устройстве в режиме реального времени, разработанного на C++ с использованием TensorFlow-Lite и Qt.
TensorFlow-Lite
TensorFlow-Lite — это библиотека, созданная Google, для разворачивания различных моделей на мобильных устройствах, микроконтроллерах и других устройствах. Библиотека поддерживает несколько языков программирования: C++, Java, Swift, Objective-C, Python.
Для TensorFlow-Lite мы можем использовать, как уже готовые модели, например, TensorFlow-
Hub, так и собственные модели, которые были конвертированы в TensorFlow-Lite модель. Во втором случае, возможно, понадобится оптимизировать модель.
Модели делятся на два типа:
Модели с метаданными. Модель с метаданными может использоваться в библиотеке TensorFlow-Lite Support. Там содержатся различные решения многих задач. Например, там есть решение для задачи детекции объектов. Библиотека сама сделает необходимые операции над входным изображением и предоставит ответ в виде специального класса.
Модель без метаданных. Для модели без метаданных мы должны будем сами обрабатывать изображение и считывать ответ по указателю.
Как TensorFlow-Lite оптимизирует модели
Оптимизация — важный этап для успешного запуска модели на мобильном устройстве и не только. Благодаря ей мы можем уменьшить:
Вес самой модели. Это позволит разворачивать модель быстрее;
Использование оперативной памяти;
Время вывода модели и, следовательно, уменьшить энергопотребление.
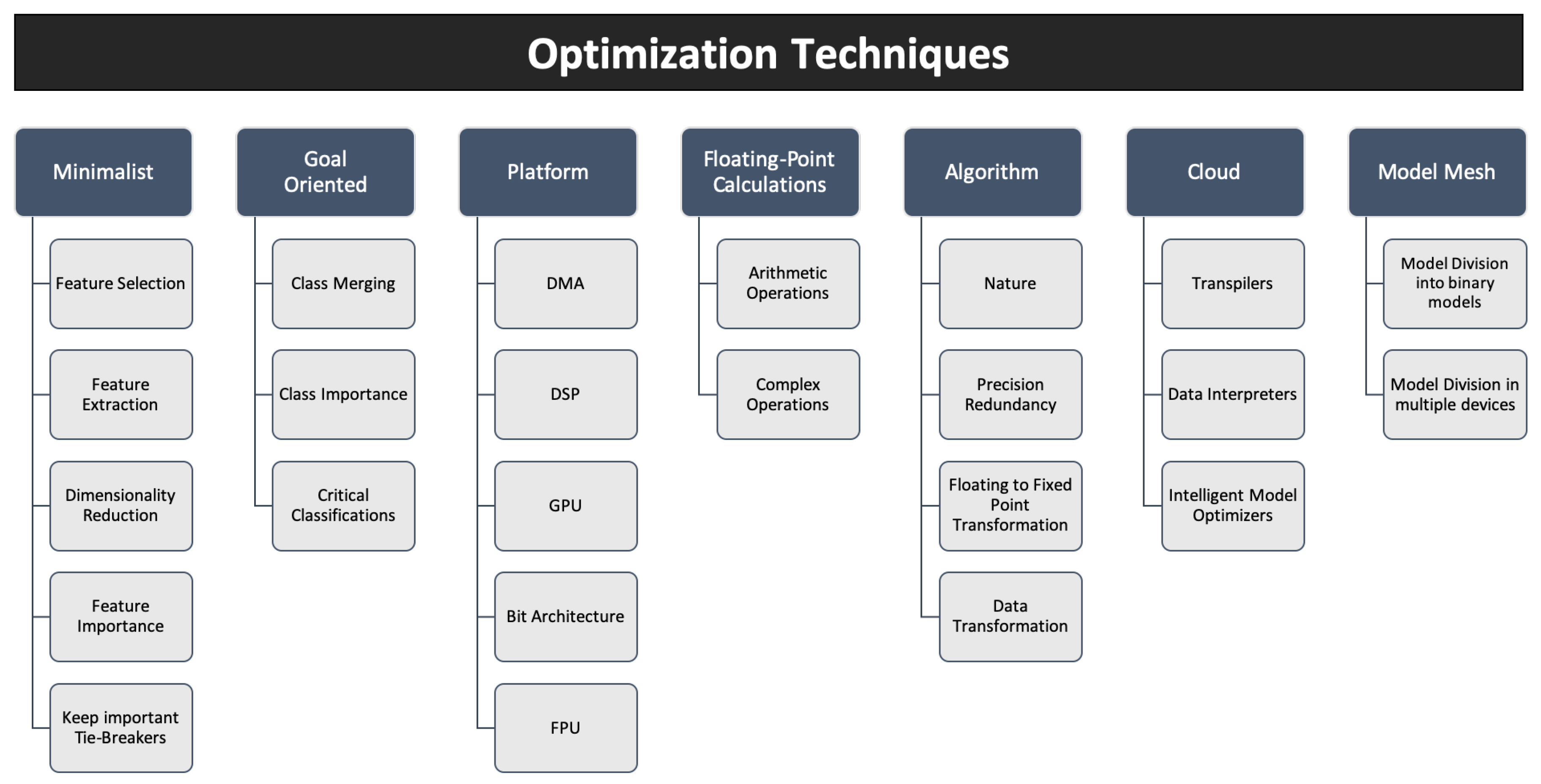
Существует множество различных методов оптимизации и каждый из них стоит изучить. При использовании уже обученной модели, мы можем использовать только некоторые техники, например:
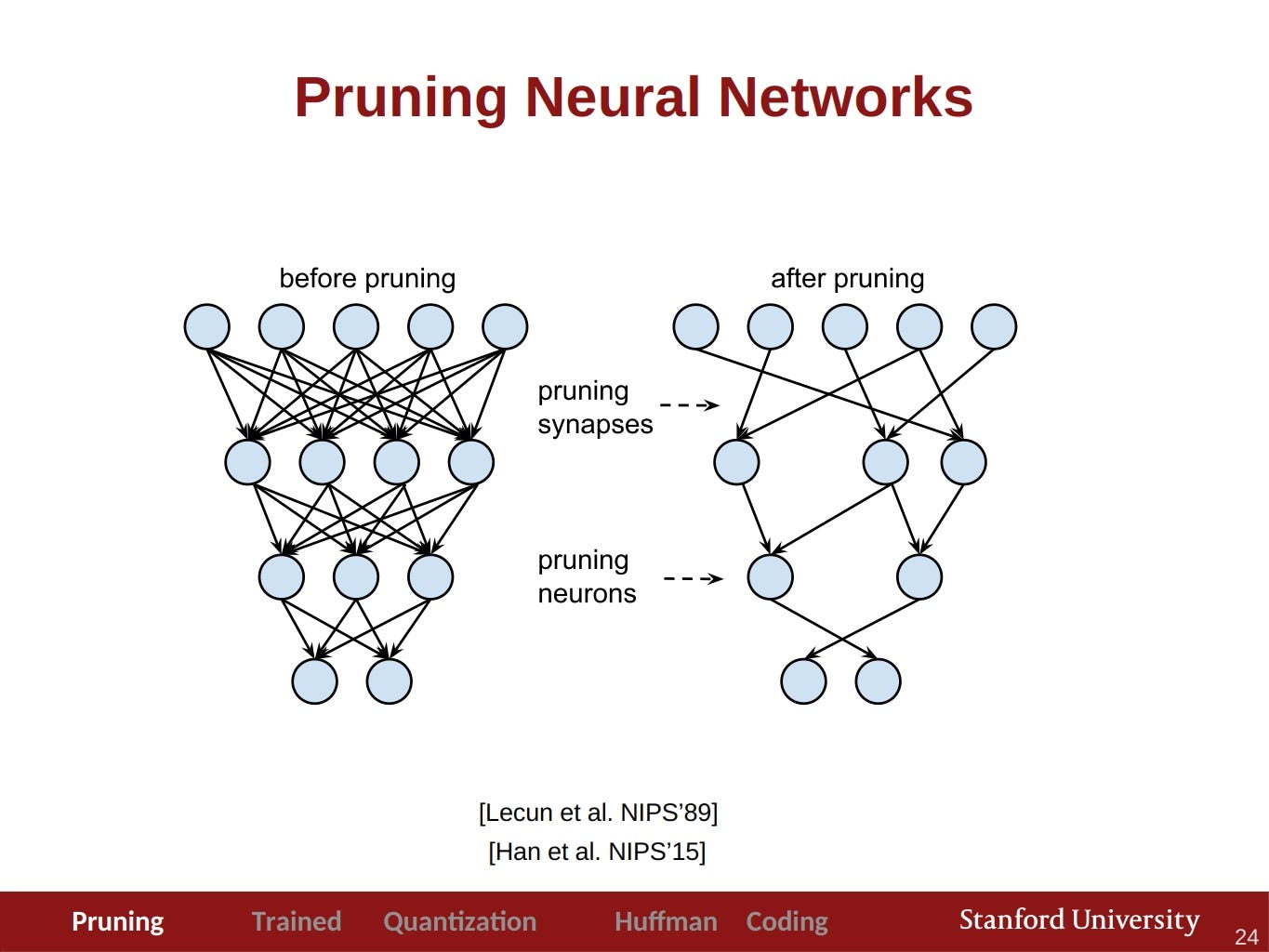
Pruning — обрезание избыточных частей сети для ускорения inference без потери точности. Посмотреть про него можно здесь, а почитать здесь.
Кластеризация весов — это метод уменьшения объема хранения вашей модели путем замены многих уникальных значений параметров меньшим количеством уникальных значений.

Квантизация — это процесс уменьшения точности чисел, используемых для представления весов модели (обычно представленных в формате float32), путем преобразования их в целочисленный тип. Но из-за неё мы теряем точность. Немного подробнее можно прочесть в этой статье Master the Art of Quantization: A Practical Guide Exploring and Implementing Quantization Methods with TensorFlow and PyTorch
Также приведем полезную статью по оптимизации моделей, там также есть объяснение этих способов. TensorFlow предоставляет свой toolkit для оптимизации моделей и в него уже входят эти способы. В данном проекте мы будем рассматривать уже оптимизированную модель для мобильных устройств.
Разработка приложения
Как уже говорилось ранее мы разрабатываем приложение на Qt с использованием Qt Quick и TenosrFlow-Lite.
Про сборку TensorFlow-Lite можно почитать в этой статье и в официальной документации. Но у нас будут некоторые отличия. Мы не будем использовать qmake и opencv, как сделано в указанной статье. Вместо qmake мы будем использовать cmake, а вместо opencv мы будем использовать инструменты из Qt. Также мы будем по-другому собирать gpu делегаты. Их можно собрать используя эту команду
bazelisk build -c opt --config android_arm64 tensorflow/lite/delegates/gpu:libtensorflowlite_gpu_delegate.so
После того как мы скомпилировали библиотеки, нам необходимо их подключить.
Сначала добавим заголовочные файлы. В нашем случае мы добавили TensorFlow, как git submodule, тогда мы можем подключить их с помощью include_directories(...).
include_directories(
headers/
third-party/tensorflow
third-party/flatbuffers/include
)
Теперь необходимо подключить сами библиотеки. Сначала добавим их используя add_library.
add_library(tensorflowlite SHARED IMPORTED)
add_library(tensorflowlite_gpu_delegate SHARED IMPORTED)
После этого нам необходимо указать путь к каждой библиотеки через set_property.
# Setup tensorflowlite property
set_property(TARGET tensorflowlite PROPERTY
IMPORTED_LOCATION ${CMAKE_SOURCE_DIR}/lib/tensorflow-lite/arm64/libtensorflowlite.so)
# Setup tensorflowlite deleagte property
set_property(TARGET tensorflowlite_gpu_delegate PROPERTY
IMPORTED_LOCATION ${CMAKE_SOURCE_DIR}/lib/tensorflow-lite/arm64/libtensorflowlite_gpu_delegate.so)
И подключить их используя target_link_libraries. Также библиотеки нужно скопировать в ${CMAKE_BINARY_DIR}/android-build/libs/arm64-v8a/. В этой папке содержатся библиотеки, которые затем будут добавлены в apk.
file(GLOB libraries
"${CMAKE_SOURCE_DIR}/lib/tensorflow-lite/arm64/*")
file(COPY ${libraries}
DESTINATION ${CMAKE_BINARY_DIR}/android-build/libs/arm64-v8a)
Выбор модели
Одно из мест, где можно найти модель — TensorFlow Hub. Там уже содержатся модели, подготовленные для мобильных устройств. Мы остановились на EfficientDet-Lite0. У данной модели есть несколько версий: обычная, квантованная int8, с метаданными. Мы использовали, как обычную, так и квантованную. Также мы сравнили эти две модели.
Model\Time inference ms. |
avg |
min |
max |
|---|---|---|---|
Default |
103.809090909091 |
58 |
444 |
Quant |
93.1909090909091 |
55 |
275 |
В итоге наблюдений было замечено, что квантованная модель работает стабильнее, т.е нет скачков времени при inference. В обычной модели это было более выражено. Также не будем исключать, что возможно проблема находится в тестовом устройстве (тестировалось на Realme 8i).
Анонс от TensorFlow-Hub
На момент написания статьи мы использовали TensorFlow Hub для поиска моделей. Но с 15 ноября модели будут находится в Kaggle Models. Подробнее про это можно почитать в их анонсе.
TensorFlow-Lite в коде
Рассмотрим как использовать данную библиотеку. Сначала объявим необходимые переменные.
std::unique_ptr<tflite::Interpreter> mInterpreter;
std::unique_ptr<tflite::FlatBufferModel> mModel;
tflite::ops::builtin::BuiltinOpResolver mResolver;
TfLiteDelegate *mDelegate;
uchar *mInput;
Дальше мы создадим саму модель.
// Init model
mModel = tflite::FlatBufferModel::BuildFromFile(pathToModel.c_str());
// Build the interpreter
tflite::InterpreterBuilder builder(*mModel, mResolver);
// If set to the value -1, the number of threads used
// will be implementation-defined and platform-dependent.
builder.SetNumThreads(-1);
auto status = builder(&mInterpreter);
qDebug() << "TensorflowModel::TensorflowModel. Builder status ok?:"
<< (status == kTfLiteOk);
// Allocate tensors if previously state is ok
if (status == kTfLiteOk) {
status = mInterpreter->AllocateTensors();
qDebug() << "TensorflowModel::TensorflowModel. Tensors allocated?:"
<< (status == kTfLiteOk);
}
if (status == kTfLiteOk)
mInput = mInterpreter->typed_input_tensor<uchar>(0);
Сделать inference мы можем следующим образом.
/**
* Performs the forward pass of the TFModel using the given QImage.
* @param image The input image to be processed by the model.
* @return A std::map<int, float> containing the model's output.
*/
std::map<int, double> TFModel::forward(const QImage &image) noexcept {
if (mInput == nullptr) {
qWarning() << "TensorflowModel::forward(const QImage &image)."
<< "Model input equal nullptr.";
return {};
}
const auto transformedImage = transform(image);
const auto *inputImage = transformedImage.bits();
if (inputImage == nullptr) {
qWarning() << "TensorflowModel::forward. Image equal nullptr.";
return {};
}
std::memcpy(mInput, inputImage, constants::model::size);
if (const auto status = mInterpreter->Invoke(); status == kTfLiteOk)
return processOutput();
qWarning() << "TensorflowModel::forward. Cannot make forward;";
return {};
}
В данном фрагметне можно увидеть метод transform. Он позволяет уменьшить размер изображения до нужного нам, а также поменять его формат.
QImage TFModel::transform(const QImage &image) const noexcept {
QImage inputImage{image.scaled(constants::model::inputWidth,
constants::model::inputHeight)};
// For these model imgFormat equal `QImage::Format_RGB888`.
// Important set the correct image format, otherwise ower predictons will
// be wrong.
inputImage.convertTo(constants::model::imgFormat);
return inputImage;
}
С помощью метода ниже мы можем получить предсказания модели.
/**
* Retrieves the predictions from the model output.
* @return A map of predicted classes and their max confidence scores.
* If no predictions were made, an empty map is returned
* If on image detected few objects of the same class,
* then only the max score from it will be returned
*/
std::map<int, double> TFModel::processOutput() const noexcept {
// Model output:
// detection_boxes: Bounding box for each detection.
// detection_classes: Object class for each detection.
// detection_scores: Confidence scores for each detection.
// num_detections: Total number of detections.
// Get the total number of detected objects
const int countDetected{static_cast<int>(std::floor(*getOutput<float>(3)))};
// Get the detected classes and scores
const auto detectedClasses{getOutput<float>(1)};
const auto detectedScores{getOutput<float>(2)};
// Check if the detectedClasses and detectedScores are valid
bool itUsable{detectedClasses != nullptr};
itUsable &= detectedScores != nullptr;
// Initialize the map to store the predictions
std::map<int, double> predictions;
// Iterate over the detected objects
// In this model, countDetected cannot be more than 25.
for (int i = 0; itUsable && (i < countDetected); i++) {
const auto &classId = static_cast<int>(std::floor(detectedClasses[i]));
const auto &score = static_cast<double>(detectedScores[i]);
const bool itDetected{score >= constants::model::threshold};
// If the object is detected with a high enough confidence score
if (itDetected) {
// Add the class to the predictions map if it doesn't exist
predictions.try_emplace(classId, 0);
// Update the max score for the class if necessary
predictions[classId] = std::max(predictions[classId], score);
}
}
return predictions;
}
В данном фрагменте можно заметить метод getOuput. Данный метод эквивалентен mInterpreter->typed_output_tensor<type>(numOutput) и был введен для улучшения читаемости кода.
С какими проблемами мы столкнулись
Одна из проблем, с которой мы столкнулись — камера. Она работала без всяких проблем на настольных системах, но не на мобильных. Во многих релизах она просто не работала и приложение аварийно завершалось. Пример ошибки на версии 6.5.2.
W ImageReader_JNI: Unable to acquire a buffer item, very likely client tried to acquire more than maxImages buffers
W ImageReader_JNI: Unable to acquire a buffer item, very likely client tried to acquire more than maxImages buffers
E AndroidRuntime: FATAL EXCEPTION: CameraBackground
E AndroidRuntime: Process: org.qtproject.example.camera, PID: 16762
E AndroidRuntime: java.lang.IllegalStateException: maxImages (10) has already been acquired, call #close before acquiring more.
E AndroidRuntime: at android.media.ImageReader.acquireNextImage(ImageReader.java:501)
E AndroidRuntime: at android.media.ImageReader.acquireLatestImage(ImageReader.java:386)
E AndroidRuntime: at org.qtproject.qt.android.multimedia.QtCamera2$4.onImageAvailable(QtCamera2.java:157)
E AndroidRuntime: at android.media.ImageReader$ListenerHandler.handleMessage(ImageReader.java:812)
E AndroidRuntime: at android.os.Handler.dispatchMessage(Handler.java:108)
E AndroidRuntime: at android.os.Looper.loop(Looper.java:166)
E AndroidRuntime: at android.os.HandlerThread.run(HandlerThread.java:65)
По этому багу уже ведется работа и qt уже о нем известно. Сам тикет на баг.
bugreports.qt.io
Этот баг можно поправить, но потребуется пересобирать qt для этого. Один из вариантов — это сменить версию qt. Мы попробовали 6.2, 6.3, 6.4, 6.5. Из этих версий только в 6.4 камера работала без всяких проблем.
Также мы столкнулись с ещё одной проблемой. В вертикальном положении изображение было растянуто. Это удалось исправить самостоятельно указав соотношение сторон.
Захват картинки с камеры
Рассмотрим, как захватить изображение с камеры и на что стоит обратить внимание. Захват изображения мы будем делать с помощью Qt Quick и QtMultimedia.
MediaDevices {
id: mediaDevices
}
CaptureSession {
camera: Camera {
id: camera
cameraDevice: mediaDevices.defaultVideoInput
active: true
focusMode: Camera.FocusModeInfinity
}
videoOutput: preview
}
VideoHandler {
id: handler
videoSink: preview.videoSink
}
VideoOutput {
id: preview
property double aspectRation: 1
anchors.centerIn: parent
height: parent.height
width: aspectRation * height
fillMode: VideoOutput.Stretch
onFrameUpdated: {
aspectRation = preview.videoSink.videoSize.height / preview.videoSink.videoSize.width
}
}
Рассмотрим это фрагмент кода. В нем: MediaDevice позволяет выбрать камеру, CaptureSession делает захват изображения, VideoOutput делает превью нашего видео потока, а VideoHandler — это наш класс, который нужен, чтобы получить картинку с видео потока и отправить её в модель.
Получить изображение можно следующим образом mVideoSink->videoFrame().toImage(), где mVideoSink — QPointer<QVideoSink>. Именно его мы установили в VideoHandler.
Здесь есть пара замечаний. Работу с моделью будет лучше вынести в отдельный поток, чтобы избежать застывание изображения. Также лучше проводить inference модели не каждое обновление кадра, а с промежутками. Для этого мы создали таймер с интервалом в 1 секунду. В результате каждую секунду мы делали inference модели.
Делегаты
Делегаты позволяют ускорить inference модели за счет использования GPU и DSP. В TensorFlow-Lite существуют несколько типов делегатов.
GPU делегаты. Поддерживаются android и ios.
NNAPI и Hexagon делегаты. Поддерживают только android.
Core ML делегаты. Поддерживают только ios.
Более подробно про них можно почитать в документации.
TensorFlow Lite Delegates
В нашем проекте мы использовали GPU делегаты. Но мы столкнулись с небольшой проблемой. В Выбранной нами модели, были кастомные операторы. В результате этого только часть операций выполнялась на GPU и это не принесло значительных улучшений. Это также можно заметить в benchmark-е к нашей модели.
1 CPU (ms) |
4 CPU (ms) |
GPU (ms) |
EdgeTPU (ms) |
|---|---|---|---|
49.92 |
36.77 |
48.48 |
29.26 |
Заключение
Мы рассмотрели один из способов работы с TensorFlow-Lite на C++ с использованием Qt. Сравнили время inference разных моделей. И также рассмотрели способы оптимизации моделей и использование делегатов. Хотелось бы отметить, что использовать данную связку для разработки приложения возможно, но будьте готовы встретиться лицом к лицу возникающими сложностями: часть из них мы описали в этой статье, с другой же чатью придется справиться самостотельно. Весь наш проект можно посмотреть на github.
tm1218
Есть ли проблемы аппаратной совместимости GPU делегатов, будут ли они работать на, к примеру, Android 5.1.1?