

О сложных системах простыми словами.
В шпаргалке на высоком уровне рассматриваются такие вещи, как протоколы коммуникации, DevOps, CI/CD, архитектурные паттерны, базы данных, кэширование, микросервисы (и монолиты), платежные системы, Git, облачные сервисы etc. Особую ценность представляют диаграммы — рекомендую уделить им пристальное внимание. Полагаю, шпаргалка будет интересна всем, кто хоть как-то связан с разработкой программного обеспечения и, прежде всего, веб-приложений. Буду признателен за помощь в уточнении/исправлении понятий, терминологии, логики/алгоритмов работы систем (в рамках того, что по этому поводу содержится в оригинале), а также в обнаружении очепяток.
Выражаю благодарность Анне Неустроевой за помощь в редактировании материала.
Возможно, немного другой формат шпаргалки покажется вам более удобным.
-
Протоколы
- REST и GraphQL
- gRPC
- Webhook
- Производительность API
- HTTP 1.0 -> HTTP 1.1 -> HTTP 2.0 -> HTTP 3.0 (QUIC)
- SOAP, REST, GraphQL и RPC
- Сначала код и сначала API
- Коды статусов HTTP
- Шлюз API
- Эффективное и безопасное API
- Инкапсуляция TCP/IP
- Почему NGINX называют "обратным" прокси?
- Алгоритмы балансировки нагрузки
- URL, URI и URN
-
CI/CD
-
Архитектурные паттерны
-
База данных
-
Кэш
-
Микросервисная архитектура
-
Платежные системы
-
DevOps
-
Git
-
Облачные сервисы
-
Инструменты, повышающие продуктивность разработки
-
Linux
-
Безопасность
- Принцип работы HTTPS
- OAuth 2.0 простыми словами
- 4 наиболее распространенных механизмов аутентификации
- Сессия, куки, JWT, SSO и OAuth
- Безопасное хранение паролей в базе данных и их валидация
- JWT (JSON Web Token) простыми словами
- Принцип работы Google Authenticator и других типов двухфакторной аутентификации
-
Реальные системы
- Технический стек Netflix
- Архитектура Twitter по состоянию на 2022 год
- Эволюция архитектуры Airbnb в течение последних 15 лет
- Монорепозиторий и микрорепозитории
- Архитектура Stack Overflow
- Почему Amazon Prime Video Monitoring перешел с бессерверной архитектуры на монолит? Как это может сэкономить 90% стоимости?
- Как Disney Hotstar удалось собрать 5 миллиардов смайлов во время турнира?
- Как Discord хранит триллионы сообщений?
- Как работают прямые видеотрансляции на YouTube, TikTok Live или Twitch?
Протоколы
Архитектура (дизайн) определяет, как разные компоненты приложения взаимодействуют друг с другом. Она обеспечивает эффективность, надежность и легкость интеграции с другими системами путем предоставления стандартного подхода к проектированию и разработке API. Наиболее популярными архитектурами являются следующие:

- SOAP:
- зрелый, всесторонний, основанный на XML
- хорошо подходит для корпоративных приложений
- REST:
- популярный, легкий в реализации, основанный на методах HTTP
- хорошо подходит для веб-сервисов
- GraphQL:
- язык запросов (query language), позволяющий запрашивать данные избирательно (частично)
- меньше нагрузка на сеть, более быстрые ответы от сервера
- gRPC:
- современный, высокопроизводительный, основанный на буферах протоколов (protocol buffers)
- хорошо подходит для микросервисов
- WebSocket:
- двусторонний, позволяет обмениваться данными в реальном времени, соединение остается открытым
- хорошо подходит для обмена данными небольшого размера
- Webhook:
- основанный на событиях и коллбэках HTTP, асинхронный
- хорошо подходит для систем уведомлений
REST и GraphQL
Сравнение REST и GraphQL:

- GraphQL – это язык запросов для API, разработанный Meta. Он предоставляет полное описание данных в API и позволяет клиенту запрашивать только то, что ему нужно
- сервер GraphQL является посредником между клиентом и сервером. GraphQL может агрегировать несколько запросов REST в один запрос (и request, и query в переводе на русский означают "запрос"). Сервер GraphQL организует ресурсы в граф (отсюда и название)
- GraphQL поддерживает запросы, мутации (модификация ресурсов) и подписки (получение уведомлений о модификациях)
gRPC

RPC (Remote Procedure Call – удаленный вызов процедур) называется "удаленным", поскольку обеспечивает взаимодействие между удаленными сервисами, когда они находятся на разных серверах в микросервисной архитектуре. С точки зрения пользователя это выглядит, как вызов локальной функции.
На диаграмме представлен поток данных (flow) gRPC:
- Клиент отправляет REST-запрос. Тело запроса (request body) содержит данные в формате JSON (как правило).
2-4. Сервис заказов (order service) (клиент gRPC) получает запрос, преобразует его и отправляет запрос RPC сервису оплаты (payment service) (сервер gRPC). gRPC кодирует данные клиента в двоичный формат и отправляет их в низкоуровневый транспортный слой (transport layer). - gRPC отправляет пакеты данных (data packages) по сети с помощью HTTP2. Благодаря двоичной кодировке и сетевым оптимизациям gRPC может быть до 5 раз быстрее JSON.
6-8. Сервис оплаты получает пакеты данных по сети, декодирует их и вызывает серверное приложение.
9-11. Результат, полученный от серверного приложения, кодируется и отправляется в транспортный слой.
12-14. Сервис заказов получает пакеты данных, декодирует их и отправляет результат клиентскому приложению.
Webhook
Сравнение Polling (опроса) и Webhook:

Предположим, что у нас есть электронный магазин. Клиенты отправляют заказы в сервис заказов через шлюз API (API Gateway), а сервис заказов обращается к сервису оплаты для выполнения денежных транзакций. Сервис оплаты, в свою очередь, обращается к внешнему провайдеру сервиса оплаты (Payment Service Provider, PSP) для завершения транзакции.
Существует 2 способа взаимодействия с внешним PSP.
1. Короткий опрос
После отправки платежного запроса PSP, сервис оплаты продолжает опрашивать PSP о статусе платежа (путем периодической отправки запросов) до тех пор, пока PSP не сообщит о завершении операции.
Короткий опрос имеет следующие недостатки:
- постоянные запросы статуса расходуют ресурсы сервиса оплаты
- внешний сервис взаимодействует напрямую с сервисом оплаты, что создает уязвимости безопасности
2. Веб-хуки
Веб-хук регистрируется во внешнем сервисе. Мы как бы просим внешний сервис сообщить нам об изменениях по запросу по указанному URL. После выполнения операции, PSP отправляет запрос HTTP для обновления статуса платежа.
Ресурсы сервиса оплаты больше не расходуются на опрос.
Веб-хуки часто называют реверсивными (reverse) API или push-API, поскольку сервер отправляет запрос HTTP клиенту, а не наоборот.
При использовании веб-хуков следует уделять пристальное внимание следующим вещам:
- API должно быть правильно спроектировано для взаимодействия с внешним сервисом
- в шлюзе API должны быть установлены определенные правила безопасности
- во внешнем сервисе следует регистрировать правильный URL
Производительность API
5 распространенных способов улучшения производительности API:

Пагинация
Эту оптимизацию применяют в случае большого объема данных. Результат отправляется клиенту по частям (чанкам — chunks) для улучшения отзывчивости сервиса.
Асинхронное логирование
Синхронное логирование работает с диском при каждом вызове и может замедлить систему. Асинхронное логирование отправляет логи в буфер без блокировки (lock-free buffer) и сразу возвращается. Логи записываются на диск с определенной периодичностью. Это существенно снижает нагрузку на ввод/вывод.
Кэширование
Мы можем сохранять часто запрашиваемые данные в кэше и возвращать их клиентам без повторного обращения к базе данных. Доступ к данным, хранящемся в памяти Redis, например, гораздо быстрее, чем доступ к БД.
Сжатие полезной нагрузки
Запросы и ответы могут сжиматься с помощью GZIP и других алгоритмов сжатия. Чем меньше размер данных, тем быстрее они передаются по сети. Таким образом, сжатие ускоряет загрузку и скачивание данных.
Пул подключений
При доступе к ресурсам нам часто приходится загружать данные из БД. Открытие нового подключения к БД – дорогая операция, с точки зрения производительности, поэтому для доступа к БД следует использовать пул открытых (набор существующих) подключений (connection pool). Пул подключений отвечает за управление жизненным циклом соединений.
HTTP 1.0 -> HTTP 1.1 -> HTTP 2.0 -> HTTP 3.0 (QUIC)

- HTTP 1.0 был завершен и полностью задокументирован в 1996. Каждый запрос к серверу требует отдельного соединения TCP
- HTTP 1.1 был опубликован в 1997. TCP-соединение может оставаться открытым для повторного использования (постоянное подключение), но проблема блокировки HOL (head-of-line) остается. Блокировка HOL означает, что когда исчерпан лимит параллельных запросов, новые запросы ждут завершения предыдущих
- HTTP 2.0 был опубликован в 2015. Он решает проблему HOL путем мультиплексирования запросов на уровне приложения (application layer), но HOL остается на транспортном уровне (transport layer, например, TCP). Как видно на диаграмме, HTTP 2.0 представил концепцию "потоков" (streams) HTTP — абстракция, позволяющая разным запросам HTTP использовать одно соединение TCP. Потоки могут отправляться в разном порядке
- первый черновик HTTP 3.0 был опубликован в 2020. В качестве нижележащего транспортного протокола вместо TCP в нем используется QUIC, что решает проблему HOL в транспортном слое
QUIC основан на UDP. Он обеспечивает первоклассную поддержку потоков в транспортном слое. Потоки QUIC используют одно соединение QUIC, поэтому не требуется затрат на рукопожатия (handshakes) и холодные запуски для создания новых соединений. Потоки QUIC доставляются независимо, поэтому в большинстве случаев потеря пакетов в одном потоке не влияет на пакеты в другом потоке.
SOAP, REST, GraphQL и RPC
Существуют разные архитектурные стили API, каждый со своими паттернами и стандартами обмена данными:

Сначала код и сначала API
Разница между подходами к разработке "Сначала код" и "Сначала API" (Code First, API First):
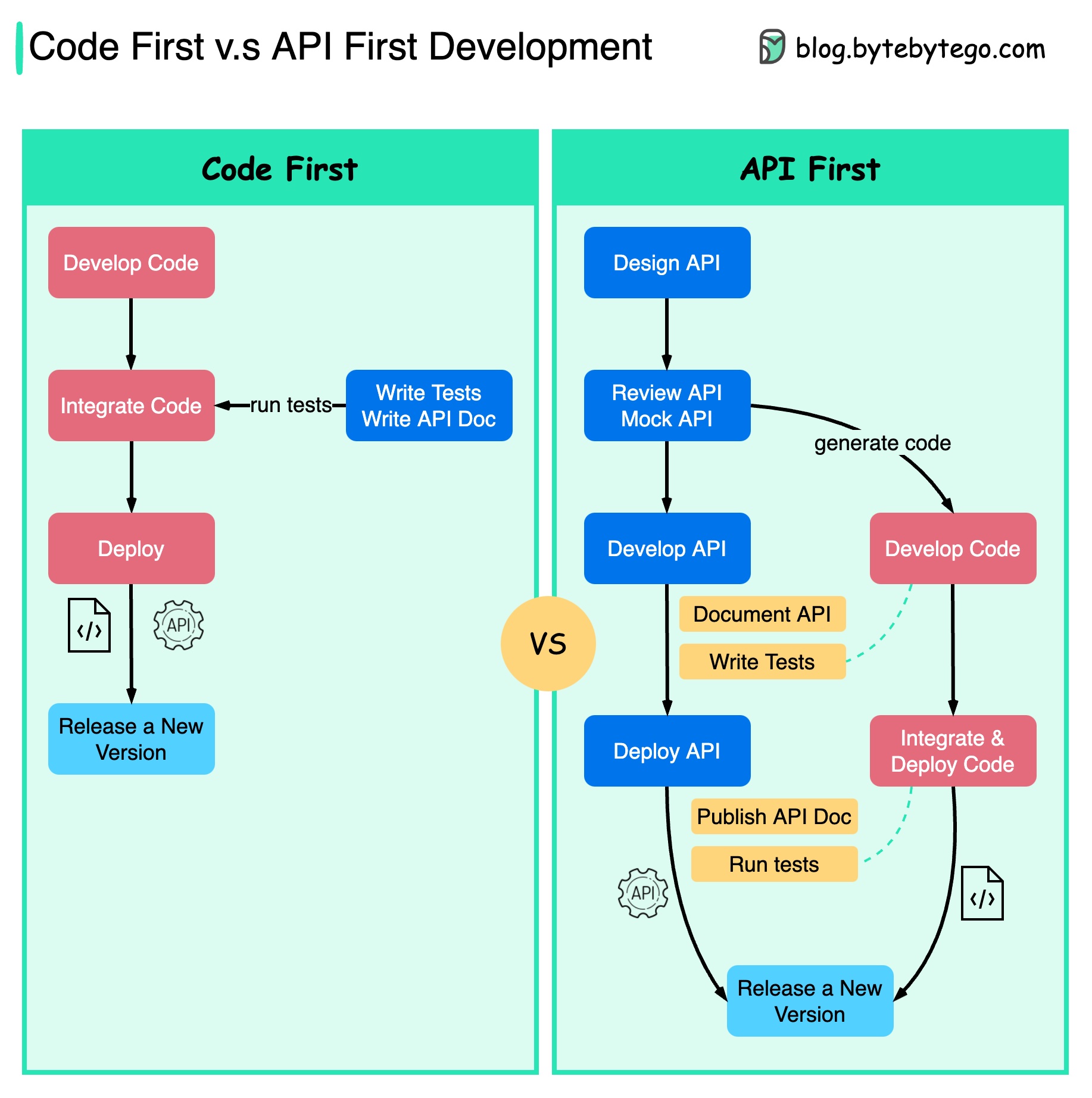
- Микросервисы повышают сложность системы. Разные функции системы обслуживаются отдельными сервисами. Хотя такая архитектура облегчает разделение обязанностей, реализация взаимодействия между сервисами является дополнительным вызовом.
При написании кода следует помнить о сложности системы и аккуратно определять границы (зоны ответственности) сервисов.
- Отдельные команды разработчиков должны говорить на одном языке. Каждая команда отвечает только за свои компоненты и сервисы. Рекомендуется заранее проектировать дизайн API на уровне организации.
Для валидации дизайна API перед написанием кода можно использовать фиктивные запросы и ответы.
- В целом, микросервисная архитектура повышает качество ПО и продуктивность разработчиков. Грамотно спроектированное API позволяет быстрее запускать проект и делает процесс разработки более плавным.
Улучшается опыт разработки, поскольку разработчики могут сосредоточиться на реализации функционала вместо того, чтобы постоянно заниматься настройкой и интеграцией.
Снижается вероятность возникновения неприятных сюрпризов на последних этапах жизненного цикла проекта.
Наличие спроектированного API позволяет писать тесты, не дожидаясь разработки. Отсюда один шаг к разработке на основе тестов (Test Driven Design, TDD).
Коды статусов HTTP
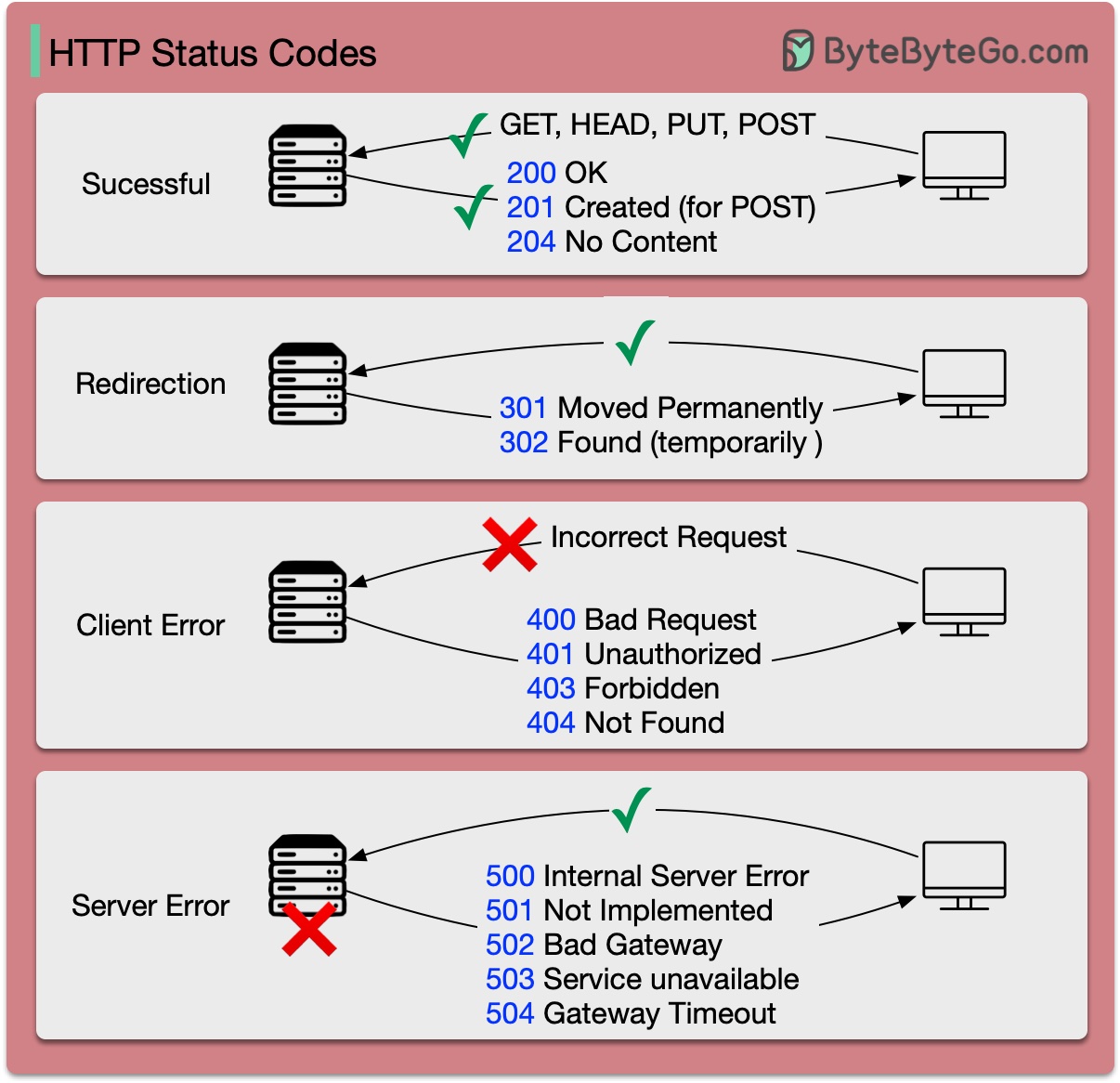
Коды ответов(статусов) HTTP делятся на 5 категорий:
- Информационные (100-199).
- Коды успеха (200-299).
- Коды перенаправления (300-399).
- Коды ошибок на стороне клиента (400-499).
- Коды ошибок на стороне сервера (500-599).
Шлюз API

- Клиент отправляет запрос HTTP в шлюз API (API Gateway).
- Шлюз разбирает (парсит) и проверяет атрибуты запроса.
- Шлюз выполняет проверки по белому/черному списку ресурсов.
- Шлюз обращается к провайдеру идентификации (поставщику удостоверений – Identity Provider) для аутентификации и авторизации.
- К запросу применяются правила ограничения частоты запросов (rate limit). При превышении лимита запрос отклоняется.
6 и 7. После выполнения проверок шлюз определяет сервис, совпадающий с путем роута (route path). - Шлюз преобразует запрос в подходящий протокол и передает его серверным микросервисам.
9-12. Шлюз отвечает за обработку ошибок, а также провалов, связанных с тем, что решение проблемы требует больше времени (разрыв цепочки — circuit break). Для логирования и мониторинга здесь также может использоваться стек ELK (Elastic-Logstash-Kibana). Здесь же можно реализовать кэширование данных.
Эффективное и безопасное API
Типичные проекты/схемы API на примере корзины товаров:

Обратите внимание, что дизайн API – это не только дизайн URL. Необходимо правильно выбирать названия ресурсов, идентификаторы и паттерны путей (path patterns). Также важно устанавливать правильные заголовки HTTP и эффективные правила ограничения частоты запросов (rate limit).
Инкапсуляция TCP/IP
Как данные передаются по сети? Почему в сетевой модели OSI (Open Systems Interconnection – взаимосвязь открытых систем) так много уровней?

На диаграмме показано, как данные инкапсулируются и распаковываются при передаче по сети.
- Когда устройства А передает данные устройству Б по протоколу HTTP, сначала на уровне приложения (application layer) в запрос добавляется заголовок HTTP.
- Затем к данным добавляются заголовки TCP или UDP. Они инкапсулируются в сегменты TCP на транспортном уровне (transport layer). Заголовок содержит порт источника (source port), порт назначения (destination port) и номер последовательности (sequential number).
- Затем на сетевом уровне (network layer) добавляется заголовок IP. Он содержит адреса IP источника/назначения.
- На уровне связи данных (data link layer) в датаграмму (datagram) IP добавляется заголовок MAC с MAC-адресами источника и получателя.
- Инкапсулированные кадры (фреймы – frames) попадают на физический уровень (physical layer) и передаются по сети в двоичном виде.
6-10. При получении битов по сети устройство Б выполняет процесс распаковки, обратный процессу инкапсуляции. Заголовки удаляются слой за слоем, после чего устройство Б может читать данные.
У каждого уровня своя задача. Каждый уровень извлекает инструкции из соответствующего заголовка, что избавляет от необходимости владеть полной информацией о данных.
Почему NGINX называют "обратным" прокси?
Разница между прямым (forward) и обратным (reverse) прокси:
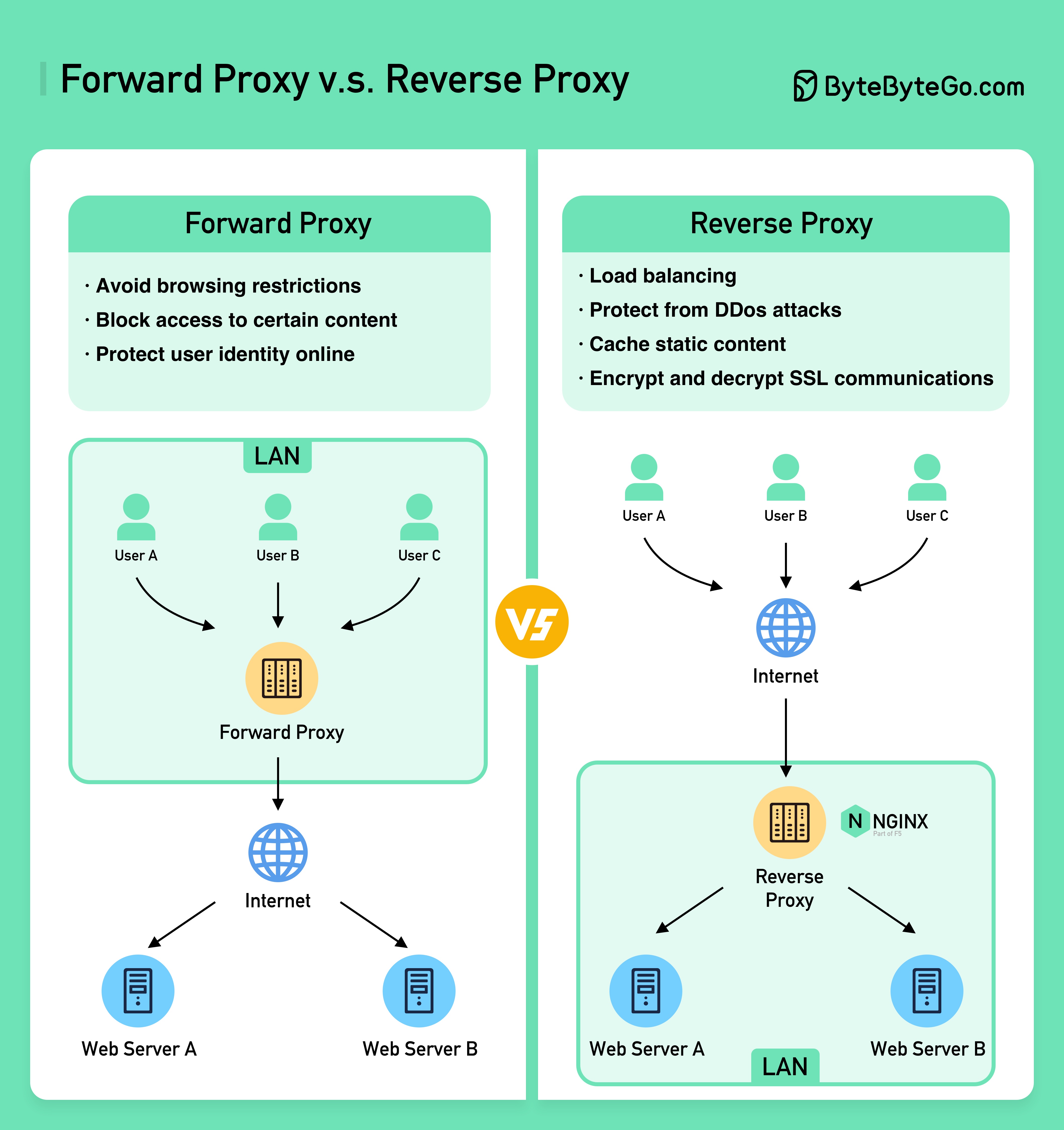
Прямой прокси – это сервер, находящийся между пользователем и Интернетом.
Прямой прокси обычно используется для:
- Защиты клиентов.
- Преодоления ограничений браузера.
- Блокировки доступа к определенным ресурсам.
Обратный прокси – это сервер, принимающий запросы от клиента, передающий их веб-серверу и возвращающий результат клиенту после обработки запроса сервером.
Обратный прокси хорошо подходит для:
- Защиты сервера.
- Балансировки нагрузки.
- Кэширования статических ресурсов.
- Кодирования и декодирования подключений SSL.
Алгоритмы балансировки нагрузки
6 наиболее распространенных алгоритмов балансировки нагрузки:

Статические алгоритмы
- Циклический (round robin) – запросы клиента передаются разным экземплярам сервиса по порядку. Как правило, сервисы не владеют состоянием (stateless).
- Липкий (sticky) циклический – улучшение циклического алгоритма. Если первый запрос Алисы передается сервису А, последующие запросы Алисы также передаются этому сервису.
- Взвешенный (weighted) циклический – администратор присваивает веса каждому сервису. Чем больше вес, тем больше запросов может обработать сервис.
- Хэш – данный алгоритм применяется функцию хэширования к IP или URL входящего запроса. Хэш определяет сервис, которому передается запрос.
Динамические алгоритмы
- Наименьшее количество соединений (least connections) – новый запрос передается экземпляру с наименьшим количеством параллельных подключений.
- Наименьшее время ответа (least response time) – новый запрос передается экземпляру с наименьшим временем ответа.
URL, URI и URN
Сравнение URL, URI и URN:

URI
URI расшифровывается как Uniform Resource Identifier (единый идентификатор ресурса). Он определяет логический или физический ресурс в вебе. URL и URN являются подтипами URI. URL определяет локацию (местонахождения) ресурса, а URN — название ресурса.
URI состоит из следующих частей:
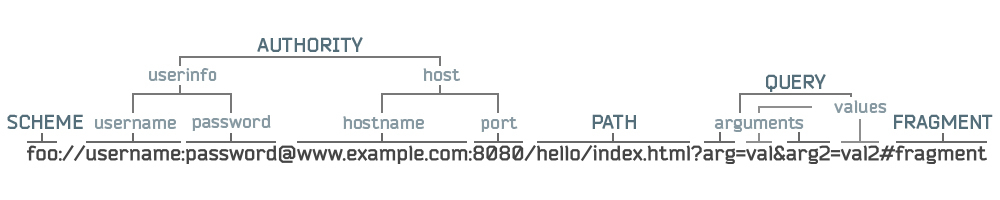
URL
URL расшифровывается как Uniform Resource Locator (единый указатель ресурсов) и является ключевой концепцией HTTP. Он представляет собой уникальный адрес ресурса в вебе. URL может использоваться с другими протоколами, такими как FTP и JDBC.
URN
URN расшифровывается как Uniform Resource Name (единое имя ресурса). URN не могут использоваться для локализации ресурса. Простым примером является сочетание пространства имен (namespace) и специфичной для него строки.
URIs, URLs, and URNs: Clarifications and Recommendations 1.0.
CI/CD
CI/CD простыми словами

SDLC с CI/CD
SDLC (software development life cycle – процесс разработки ПО) состоит из нескольких основных этапов: разработка, тестирование, деплой и поддержка. CI/CD автоматизирует и интегрирует эти этапы для обеспечения более быстрых и надежных релизов.
Отправка ("пуш") кода в репозиторий запускает сборку и тесты. Запускаются тесты непрерывной цепочки (End-to-end, e2e) для валидации кода. Если тестирование проходит успешно, код автоматически разворачивается в стейдже/продакшне. В противном случае, код возвращается на доработку. Эта автоматизация обеспечивает получение быстрой обратной связи разработчиками и снижает риск попадания багов в продакшн.
Разница между CI и CD
Continuous Integration (CI) (непрерывная интеграция) автоматизирует процессы сборки, тестирования и объединения ("мержа"). Она запускает тесты при каждой фиксации ("коммите") кода для обнаружения проблем с интеграцией на ранних стадиях. Это способствует частой фиксации кода и быстрой обратной связи.
Continuous Delivery (CD) (непрерывная доставка) автоматизирует процессы релиза, такой как изменение инфраструктуры и деплой. Она обеспечивает надежность релизов в любое время с помощью автоматизированного конвейера. CD может также включать необходимость ручного тестирования и подтверждения ("апрува") перед деплоем в продакшн.
Конвейер CI/CD
Типичный конвейер (pipeline) CI/CD состоит из нескольких этапов:
- разработчик фиксирует изменения в коде
- сервер CI регистрирует изменения и запускает сборку
- код компилируется и тестируется (юнит-тесты, интеграционные тесты etc.)
- отчет о тестировании отправляется разработчику
- при успешном тестировании артефакты разворачиваются в промежуточной среде (стейдж)
- перед релизом могут запускаться дополнительные тесты
- система CD разворачивает утвержденные изменения в продакшне
Технический стек Netflix (конвейер CI/CD)

Планирование: инженеры Netflix используют JIRA для планирования и Confluence для документации.
Написание кода: основным серверным языком является Java, другие языки используются для разных целей по мере необходимости.
Сборка: для сборки в основном используется Gradle, для поддержки разных случаев разработаны специальные плагины Gradle.
Упаковка: пакет и зависимости помещаются в Amazon Machine Image (AMI) для релиза.
Тестирование: подчеркивает направленность культуры продакшна на создание инструментов хаоса.
Деплой: Netflix использует собственный Spinnaker для деплоя.
Мониторинг: метрики мониторинга аккумулируются в Atlas, а для обнаружения аномалий используется Kayenta.
Отчет об инциденте: инциденты сортируются по приоритету, для обработки инцидентов используется PagerDuty.
Архитектурные паттерны
MVC, MVP, MVVM, MVVM-C и VIPER

- MVC, самый старый паттерн, появился почти 50 лет назад
- каждый паттерн имеет "view" (V), отвечающий за отображение содержимого и обработку пользовательского ввода
- большинство паттернов включает "model" (M) для управления данными
- "controller", "presenter" и "view-model" являются посредниками между слоем отображения и моделью
18 основных архитектурных паттернов
Паттерны – это многократно используемые решения распространенных проблем дизайна, обеспечивающие более плавный и эффективный процесс разработки. Они являются проектами/схемами для разработки лучших структур ПО. Наиболее популярными паттернами являются следующие:

- Abstract Factory (абстрактная фабрика): создатель семьи – создает группы связанных элементов
- Builder (строитель): мастер лего – создает объекты поэтапно, разделяет создание и отображение
- Prototype (прототип): создатель клонов – создает копии полностью готовых объектов
- Singleton (одиночка): единственный и неповторимый – специальный класс, который может иметь только один экземпляр
- Adapter (адаптер): универсальный плагин – соединяет вещи с разными интерфейсами
- Bridge (мост): подключатель функций – связывает объекты с функциями
- Composite (композитор): строитель деревьев – формирует древовидные структуры из простых и сложных частей
- Decorator (декоратор): настройщик – добавляет возможности в объекты без изменения их ядра
- Facade (фасад): единый центр обслуживания – представляет целую систему с помощью одного простого интерфейса
- Flyweight (легковес): хранитель пространства – эффективно распределяет небольшие повторно используемые элементы
- Proxy (прокси): запасной актер – представляет другой объект, управляет доступом к нему или выполнение операций с ним
- Chain of Responsibility (цепочка ответственности): эстафета запроса – запрос обрабатывается цепочкой объектов
- Command (команда): обертка задачи – преобразует запрос в объект, готовый к выполнению операции
- Iterator (итератор): исследователь коллекций – предоставляет доступ к коллекции элементов по одному
- Mediator (посредник): коммуникационный хаб – упрощает взаимодействие между разными классами
- Memento (запоминатель): капсула времени – сохраняет и восстанавливает состояние объекта
- Observer (наблюдатель): издатель новостей – уведомляет классы об изменениях других объектов
- Visitor (посетитель): умелый гость – добавляет новые операции в класс без его модификации
База данных

Выбор правильной БД для проекта – задача не из простых. Изучение огромного количества возможностей БД, рассчитанных на решение конкретных задач, может быстро утомить.
Надеемся, что наша диаграмма, как минимум, облегчит начало вашего пути в этом направлении.
8 структур данных, улучшающих работу баз данных
Ответ на этот вопрос зависит от того, как БД используется. Индексы данных могут храниться в памяти или на диске. Форматы данных могут быть разными: числа, строки, географические координаты etc. Система может часто читаться или писаться (write-heavy, read-heavy). Все эти факторы влияют на выбор формата индексов БД.

Наиболее популярные структуры данных, использующиеся для индексации:
- Skiplist: индексы хранятся в памяти. Используется в Redis
- Hash index (хэшированный индекс): популярная реализация структуры данных "Карта" (или "Коллекция") (map)
- SSTable: иммутабельная (неизменяемая) реализация "Карты", хранящаяся на диске
- LSM дерево: Skiplist + SSTable. Хорошо подходит для частой записи
- B-дерево: индексы хранятся на диске. Согласованная производительность чтения/записи
- Inverted index (инвертированный индекс): хорошо подходит для индексации документов. Используется в Lucene
- Suffix tree (суффиксное дерево): хорошо подходит для поиска строковых паттернов (string patterns)
- R-дерево: разнонаправленный поиск, такой как поиск ближайшего соседа
Выполнение инструкции SQL в базе данных
Разные БД имеют разную архитектуру. Некоторые общие подходы:

- Инструкция SQL отправляется в БД через транспортный протокол (например, TCP).
- Инструкция передается парсеру команды (command parser), который выполняет ее синтаксический и семантический анализ и генерирует дерево запроса (query tree).
- Дерево запроса передается оптимизатору (optimizer). Оптимизатор создает план выполнения (execution plan).
- План выполнения передается исполнителю (executor). Исполнитель извлекает данные для выполнения.
- Методы доступа (access methods) предоставляют логику получения данных, необходимых для выполнения, извлечения данных из движка хранилища (storage engine).
- Методы доступа определяют, является ли инструкция доступной только для чтения. Если да (SELECT), инструкция передается менеджеру буфера (buffer manager) для дальнейшей обработки. Менеджер буфера ищет данные в кэше или файлах.
- Если инструкцией является UPDATE или INSERT, она передается менеджеру транзакций (transaction manager) для дальнейшей обработки.
- В ходе транзакции данные блокируются (lock mode). За это отвечает менеджер блокировки (lock manager). Блокировка обеспечивает соответствие транзакции принципам ACID.
Теорема CAP
Теорема CAP является одним из самых известных терминов в компьютерной науке, но разные разработчики понимают ее по-разному.

Теорема CAP утверждает, что распределенная система не может одновременно соответствовать всем трем критериям.
Consistency (согласованность): все клиенты видят одни и те же данные, независимо от того, к какому узлу (node) они подключены.
Availability (доступность): любой клиент, запросивший данные, получает ответ, даже если какие-то узлы вышли из строя.
Partition Tolerance (устойчивость к разделению): разделение означает нарушение коммуникации между двумя узлами. Устойчивость означает, что система продолжает работать, несмотря на разделения.
Формулировка "2 из 3" может быть полезной, но также может вводить в заблуждение.
- Выбор базы данных – нелегкая задача. В данном случае нельзя опираться только на теорему CAP. Например, компании не выбирают Cassandra для приложений чата просто потому, что Cassandra является системой AP. Однако Cassandra имеет характеристики, которые делают ее неплохим выбором для хранения сообщений (см. историю Discord в конце).
- CAP ограничивает лишь небольшую часть возможностей: идеальная доступность и согласованность при наличии разделения, которое встречается довольно редко.
- Теорема утверждает, что возможна 100% доступность и согласованность. На самом деле, речь чаще всего идет о выборе между задержкой и согласованностью при отсутствии сетевого разделения. См. теорему PACELC.
Является ли теорема CAP полезной?
Я думаю, что да, поскольку она открывает дискуссию о компромиссах, но это лишь часть всей истории. При выборе БД нам необходимо погружаться в детали с точки зрения функционала приложения.
Типы памяти и хранилищ данных

Визуализация запроса SQL

Инструкции SQL выполняются БД следующим образом:
- разбор инструкции и ее валидация
- преобразование SQL во внутренний формат, такой как реляционная алгебра (relational algebra)
- оптимизация внутреннего представления и создания плана выполнения (execution plan) на основе индексации
- выполнение плана и возвращение результата
Выполнение инструкции SQL является сложным процессом, включающем множество соображений, таких как:
- использование индексов и кэшей
- порядок объединения таблиц
- управление конкурентностью
- управление транзакциями
Язык SQL
SQL (Structured Query Language – язык структурированных запросов) был стандартизирован в 1986. В течение следующих 40 лет он стал доминирующим языком для систем управления реляционными базами данных. Последний стандарт называется ANSI SQL 2016.

SQL включает в себя 5 основных компонентов:
- DDL: data definition language (язык определения данных) — CREATE, ALTER, DROP
- DQL: data query language (язык запроса данных) — SELECT
- DML: data manipulation language (язык манипуляции данными) — INSERT, UPDATE, DELETE
- DCL: data control language (язык управления данными) — GRANT, INVOKE
- TCL: transaction control language (язык управления транзакциями) — COMMIT, ROLLBACK
Разработчик бэкенда должен хорошо знать все эти компоненты. Аналитик данных может ограничиться DQL. Все зависит от того, чем вы занимаетесь.
Кэш
Кэширование данных
Кэширование данных в типичной архитектуре:

Кэширование данных выполняется на нескольких уровнях:
- Клиентские приложения: ответы HTTP могут кэшироваться браузером. Мы запрашиваем данные по HTTP в первый раз, данные возвращаются с политикой истечения срока действия (expiry policy) в заголовке HTTP. Мы запрашиваем данные повторно, клиентское приложение пытается извлечь данные из кэша браузера.
- CDN (Content Delivery Network – сеть доставки контента): CDN кэшируют статические веб-ресурсы. Клиенты могут извлекать данные из ближайшего узла CDN.
- Балансировщик нагрузки (Load Balancer): балансировщик нагрузки также может кэшировать данные.
- Брокер сообщений (Message Broker): брокер сначала записывает сообщения на диск, потребители извлекают их по необходимости. Данные кэшируются в кластерах Kafka, например, в течение времени, определяемого политикой удержания (retention policy).
- Сервисы: в сервисах существуют разные уровни кэша. Если данные не кэшированы в кэше CPU, сервис пытается извлечь данные из памяти. Иногда имеется второй слой кэша с хранением данных на диске.
- Распределенный кэш (Distributed Cache): Redis, например, хранит в памяти пары ключ-значение для различных сервисов. Операции чтения/записи в Redis выполняются значительно быстрее по сравнению с базой данных.
- Полнотекстовый поиск (Full-text Search): Elastic, например, хорошо подходит для поиска документов или отчетов (логов). Поисковый движок выполняет индексацию копии данных.
- БД: в БД существуют разные уровни кэша:
- WAL (Write-ahead Log – журнал упреждающей записи) – данные записываются в WAL перед построением B-дерева
- Bufferpool – область памяти, выделяемая для кэширования результатов запросов
- материализованное представление (Materialized View) – предварительное вычисление результатов запросов и их сохранение в таблицах БД для повышения производительности
- журнал транзакций (Transaction Log) – фиксация всех транзакций и обновлений БД
- журнал репликации (Replication Log) – фиксация состояния репликации кластера БД
Причины высокой производительности Redis

- Redis – это хранилище данных, основанное на RAM. Доступ к оперативной памяти как минимум в 1000 раз быстрее доступа к диску.
- Для повышения эффективности выполнения запросов в Redis используется мультиплексирование ввода/вывода и однопоточный цикл выполнения.
- В Redis используется несколько эффективных низкоуровневых структур данных.
Другим популярным решением для хранения данных в памяти является Memcached.
Случаи использования Redis

Redis может использоваться не только для кэширования.
- Сессии – распределение сессии пользователя между разными сервисами
- кэш — кэширование объектов или страниц
- распределенная блокировка (Distributed Lock) – строка Redis может использоваться для блокировки распределенных сервисов
- счетчик – подсчет количества лайков или чтений статьи
- ограничение частоты запросов (Rate Limit) – ограничение частоты запросов на основе IP пользователя
- генератор глобальных идентификаторов
- корзина товаров – хэш Redis может использоваться для представления пар ключ-значение в корзине товаров
- вычисление вовлеченности пользователя (User Retention) – Bitmap может использоваться для представления ежедневного входа пользователя в систему и его вовлеченности
- очередь сообщений (Message Queue)
- ранжирование–- для сортировки статей может использоваться ZSet
Стратегии кэширования
Проектирование крупномасштабных систем обычно предполагает правильных выбор стратегии кэширования. Топ-5 самых популярных стратегий:

Микросервисная архитектура
Типичная микросервисная архитектура
Типичная микросервисная архитектура состоит из следующих частей:
- балансировщик нагрузки (Load Balancer) – распределяет входящий трафик между сервисами
- CDN (Content Delivery Network — сеть доставки контента) – группа географически распределенных серверов, содержащих статический контент для быстрой доставки. Клиенты сначала запрашивают данные из CDN и только после этого обращаются непосредственно к сервису
- шлюз API (API Gateway) – обрабатывает входящие запросы и передает их соответствующим сервисам. Он общается с провайдером идентификации (Identity Provider – поставщик удостоверений) и другими службами
- провайдер идентификации – обработка аутентификации и авторизации пользователей
- реестр служб (Service Registry) – отвечает за регистрацию микросервисов для использования другими компонентами системы, такими как шлюз API
- управление — мониторинг сервисов
- микросервисы – проектируются и разворачиваются в разных доменах (domains). У каждого домена своя база данных. Шлюз API общается с микросервисами через REST или другие протоколы, микросервисы одного домена общаются между собой через RPC
Преимущества микросервисов
- могут быстро проектироваться, разворачиваться и масштабироваться горизонтально
- каждый домен может независимо поддерживаться отдельной командой
- бизнес-требования могут кастомизироваться под каждый домен и, как следствие, лучше поддерживаться
Лучшие практики микросервисов
9 лучших практик разработки микросервисов:

- У каждого микросервиса должно быть свое хранилище данных.
- Код каждого сервиса должен быть примерно на одном уровне завершенности.
- Каждый сервис должен собираться независимо от других.
- У каждого сервиса должно быть своя зона ответственности.
- Сервисы должны разворачиваться с помощью контейнеров.
- Сервисы не должны хранить состояние (должны быть stateless).
- Должен применяться доменно-ориентированный дизайн.
- Микрофронтенды.
- Окрестрация сервисов.
Типичный технический стек микросервисов

Препродакшн
- Определение API – определение коммуникации между фронтендом и бэкендом. Для этого может использоваться Postman или OpenAPI.
- разработка – для разработки фронтенда чаще всего используется React, для разработки бэкенда — Python/PHP/Java/GO etc. Шлюз API (API Gateway) конфигурируется в соответствии с определением API.
- непрерывная интеграция (Continuous Integration, CI) – для автоматизированного тестирования часто используется JUnit и Jenkins. Код упаковывается в образ Docker и разворачивается в виде микросервисов.
Продакшн
- Для балансировки нагрузки часто используется Nginx. Cloudflare предоставляет CDN (Content Delivery Network — сеть доставки контента)
- шлюз API
- облачная инфраструктура — микросервисы разворачиваются в облаке: AWS, Microsoft Azure, Google GCP etc. Для кэширования данных чаще всего используется Redis, для полнотекстового поиска – Elastic Search
- взаимодействие между сервисами -–для этого используются брокеры сообщений (Message Broker) вроде Kafka или RPC
- хранение данных – реляционные, нереляционные базы данных, облачные хранилища etc.
- управление и мониторинг — для управления микросервисами используются такие инструменты, как Prometheus, Elastic Stack, Kubernetes etc.
Причины высокой производительности Kafka
На производительность Kafka влияет множество архитектурных решений. 2 основных:

- Последовательный ввод/вывод (Sequential IO).
- Принцип нулевого копирования (Zero Copy Principle).
Диаграмма иллюстрирует, как данные передаются между производителем (producer) и потребителем (consumer), а также что означает принцип нулевого копирования.
1.1-1.3. Производитель записывает данные на диск.
- Потребитель читает данные без нулевого копирования.
2.1. Данные загружаются с диска в кэш операционной системы.
2.2. Данные копируются из кэша ОС в приложение Kafka.
2.3. Приложение Kafka копирует данные в буфер сокета (socket buffer).
2.4. Данные копируются из буфера сокета на сетевую карту.
2.5. Сетевая карта отправляет данные потребителю. - Потребитель читает данные с нулевым копированием.
3.1. Данные загружаются с диска в кэш ОС.
3.2. Кэш ОС копируется сразу на сетевую карту с помощью командыsendfile().
3.3. Сетевая карта отправляет данные потребителю.
Нулевое копирование — это сохранение нескольких копий данных в контекстах приложения и ядра (kernel).
Платежные системы

Почему кредитную карту называют "самым выгодным продуктом банка"? Как VISA/Mastercard делают деньги?
Экономическая составляющая оплаты товара с помощью кредитной карты:

- Держатель карты платит 100$ за товар.
- Продавец получает более высокие продажи и должен компенсировать банку-эмитенту (банку, выпустившему карту) и карточной сети (card network) расходы на обеспечение сервиса оплаты. Банк-эквайер (банк, которому принадлежит платежный терминал) устанавливает продавцу комиссию, которая называется "комиссией за скидку продавца" (merchant discount fee).
3-4. Эквайер удерживает 0,25$ в качестве эквайринговой наценки (acquiring markup) и 1,75$ выплачиваются эмитенту в качестве комиссии за обмен (interchange fee). Комиссия за скидку продавца должна покрывать комиссию за обмен. Комиссия за обмен устанавливается карточной сетью, поскольку согласование эквайером комиссии с каждым продавцом было бы неэффективным. - Карточная сеть согласовывает сетевые оценки и комиссии с каждым банком, который оплачивает расходы сети каждый месяц. Например, VISA взимает оценку 0,11% плюс 0,0195$ за каждую операцию.
- Держатель карты платит банку-эмитенту за его услуги.
- Эмитент платит продавцу, даже если держатель карты не платит эмитенту
- эмитент платит продавцу перед тем, как держатель карты платит эмитенту
- эмитент несет другие операциональные расходы, такие как управление аккаунтами потребителей, предоставление инструкций, обнаружение мошенничества, управление рисками, клиринг и расчеты etc.
Принцип работы VISA

VISA, Mastercard и American Express выступают в роли карточных сетей (card networks) для клиринга и расчета средств. Банк-эквайер и банк-эмитент могут быть (и часто являются) разными банками. Если бы банки выполняли транзакции одну за другой без посредника, каждый банк должен был бы устанавливать транзакцию с другими банками. Это неэффективно.
На диаграмме показана роль VISA в процессе оплаты с помощью кредитной карты. Этот процесс на самом деле состоит из двух процессов. Когда пользователь использует карту, запускается процесс авторизации. Когда продавец хочет получить деньги в конце дня происходит процесс захвата и расчетов (capture and settlement).
Авторизация
- Эмитент предоставляет карту потребителю.
- Держатель карты хочет совершить покупку и прикладывает карту к торговому (Point of Sale, POS) терминалу в магазине.
- POS отправляет транзакцию эквайеру, которому принадлежит терминал.
3 и 4. Эквайер отправляет транзакцию в карточную сеть, которая также называется карточной схемой (card scheme). Сеть отправляет транзакцию эмитенту для подтверждения.
4.1, 4.2 и 4.3. Эмитент замораживает деньги при подтверждении транзакции. Подтверждение или отказ отправляются эквайеру, а также – в терминал.
Захват и расчеты
1 и 2. Продавец хочет получить деньги в конце дня, он нажимает "захват" (capture) на терминале. Транзакции отправляются эквайеру группой (batch). Эквайер отправляет группу в карточную сеть.
- Сеть выполняет клиринг для транзакций от разных эквайеров и рассылает файлы разным эмитентам. Клиринг — это процесс, при котором учитываются взаимозачетные транзакции, поэтому общее количество транзакций уменьшается. Сеть берет на себя бремя общения с каждым банком и получает взамен комиссию за обслуживание (service fee).
- Эмитенты подтверждают корректность клиринговых файлов и переводят деньги эквайерам.
- Эквайер переводит деньги в банк продавца.
DevOps
DevOps, SRE и Platform Engineering
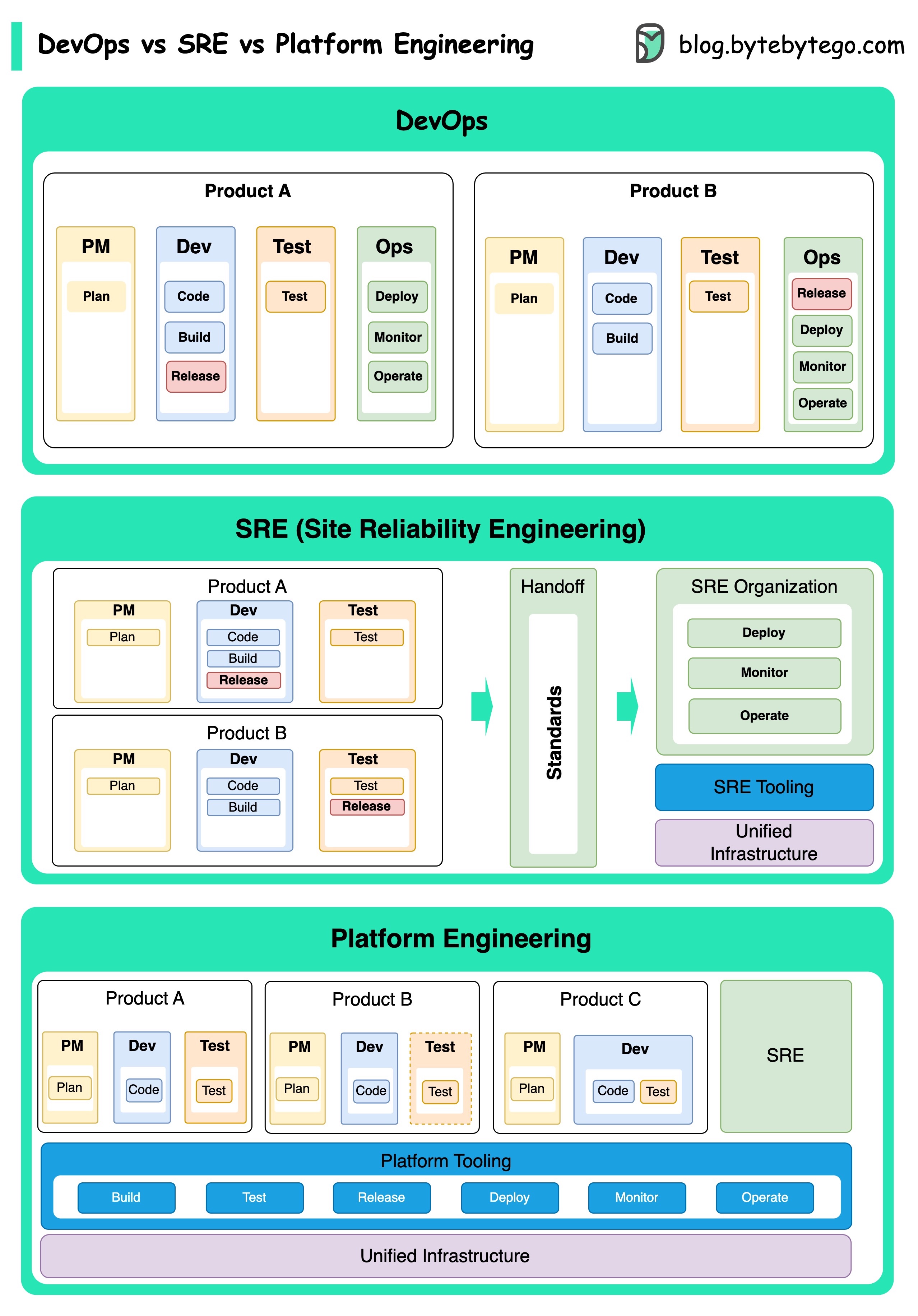
Концепция DevOps была представлена в 2009 Patrick Debois и Andrew Shafer на конференции "Agile". Они стремились сократить разрыв между разработкой ПО и его эксплуатацией, продвигая культуру сотрудничества и общую ответственность за весь жизненный цикл разработки ПО.
Концепция SRE, или Site Reliability Engineering (проектирование надежности объекта), была впервые разработана компанией Google в начале 2000-х для решения операционных задач управления крупномасштабными и сложными системами. Google разработала методы и инструменты SRE, такие как система управления кластерами Borg и система мониторинга Monarch, чтобы повысить надежность и эффективность своих сервисов.
Platform Engineering (разработка платформ) — это более новая концепция, основанная на SRE. Считается, что это расширение практик DevOps и SRE с упором на предоставление комплексной платформы для разработки продуктов, которая поддерживает всю бизнес-логику.
Все эти концепции связаны с тенденцией улучшения совместной работы, автоматизации и эффективности разработки и эксплуатации ПО.
Что такое Kubernetes?
Kubernetes (K8s) – это система оркестрации контейнеров. Она используется для деплоя и управления контейнерами. Ее дизайн во многом вдохновлен Borg – внутренней системой Google.

Кластер (cluster) K8s состоит из набора рабочих машин (worker machines), называющихся узлами (nodes), которые запускают контейнеризованные приложения. Каждый кластер имеет хотя бы один рабочий узел.
На рабочих узлах размещаются модули (pods), которые являются компонентами рабочей нагрузки приложения. Контрольный уровень (control plane) управляет рабочими узлами и модулями в кластере. В продакшне уровень управления обычно работает на нескольких компьютерах, а в кластере, как правило, работает несколько узлов, что обеспечивает отказоустойчивость и высокую доступность.
Компоненты уровня управления
- Сервер API – общается со всеми компонентами кластера. Все операции над модулями выполняются через него.
- Планировщик (Scheduler) — следит за полезной нагрузкой модулей и загружает создаваемые модули.
- Менеджер контроллеров (Controller Manager) – запускает контроллеры, включая Node Controller, Job Controller, EndpointSlice Controller и ServiceAccount Controller.
- Etcd – хранилище ключ-значение, используемое в качестве резервного хранилища данных всех кластеров.
Узлы
- Модули. Модуль – это группа контейнеров и наименьшая единица, которой оперирует K8s. Модули имеют один IP-адрес, применяемый ко всем контейнерам модуля.
- Kubelet – агент, запускающийся на каждом узле кластера. Он обеспечивает запуск контейнеров в модуле.
- Kube Proxy – сетевой прокси, запускающийся в каждом узле кластера. Он перенаправляет трафик, приходящий в узел из сервиса. Он перенаправляет запросы для обработки в нужные контейнеры.
Docker и Kubernetes

Что такое Docker?
Docker – это опенсорсная платформа, позволяющая упаковывать, распределять и запускать приложения в изолированных контейнерах. Она фокусируется на контейнеризации, предоставлении легковесных окружений, инкапсулирующих приложения и их зависимости.
Что такое Kubernetes?
Kubernetes, часто именуемый K8s, – это опенсорсная платформа для оркестрации контейнеров. Она предоставляет фреймворк для автоматизации деплоя, масштабирования и управления контейнеризованными приложениями посредством кластера узлов.
Отличия
Docker действует на уровне отдельных контейнеров на одном хосте операционной системы. Мы должны вручную управлять каждым хостом, устанавливать сети, политики безопасности и хранилище для нескольких связанных контейнеров, что может представлять некоторую сложность.
Kubernetes действует на уровне кластера. Он управляет несколькими контейнеризованными приложениями через несколько хостов, обеспечивая автоматизацию таких задач, как балансировка нагрузки, масштабирование и обеспечение ожидаемого состояния приложений.
Если быть кратким, то Docker фокусируется на контейнеризации и запуске контейнеров на отдельных хостах, а Kubernetes специализируется на управлении и оркестрации контейнеров в масштабе посредством кластера хостов.
Принцип работы Docker
На следующей диаграмме представлена архитектура Docker и то, что происходит при выполнении команд docker build, docker pull и docker run:

Архитектура Docker включает в себя 3 основных компонента:
- клиент (client) – клиент общается с демоном (daemon)
- хост (host) – демон регистрирует запросы API и управляет объектами, такими как образы (images), контейнеры, сети и тома (volumes)
- реестр (registry) – место хранения образов. DockerHub — публичный/открытый реестр образов
В качестве примера рассмотрим процесс выполнения команды docker run:
- Из реестра извлекается соответствующий образ.
- Создается контейнер.
- Контейнеру выделяется область файловой системы для чтения/записи.
- Создается сетевой интерфейс, контейнер подключается к дефолтной сети.
- Контейнер запускается.
Git
Принцип работы команд Git
Важно, где хранится наш код. Обычно предполагается, что он хранится либо на удаленном сервере, таком как Github, либо на нашей локальной машине. Но это не совсем так. Git поддерживает 3 локальных хранилища на нашей машине, так что наш код может быть обнаружен в 4 местах:

- Рабочая директория (working directory) – место редактирования файлов
- промежуточная область (staging area) – временная локация для хранения файлов до следующей фиксации (commit)
- локальный репозиторий – содержит зафиксированный код
- удаленный репозиторий – удаленный сервер, на котором хранится код
Большинство команд Git осуществляет перемещение кода из одной локации в другую.
Принцип работы Git
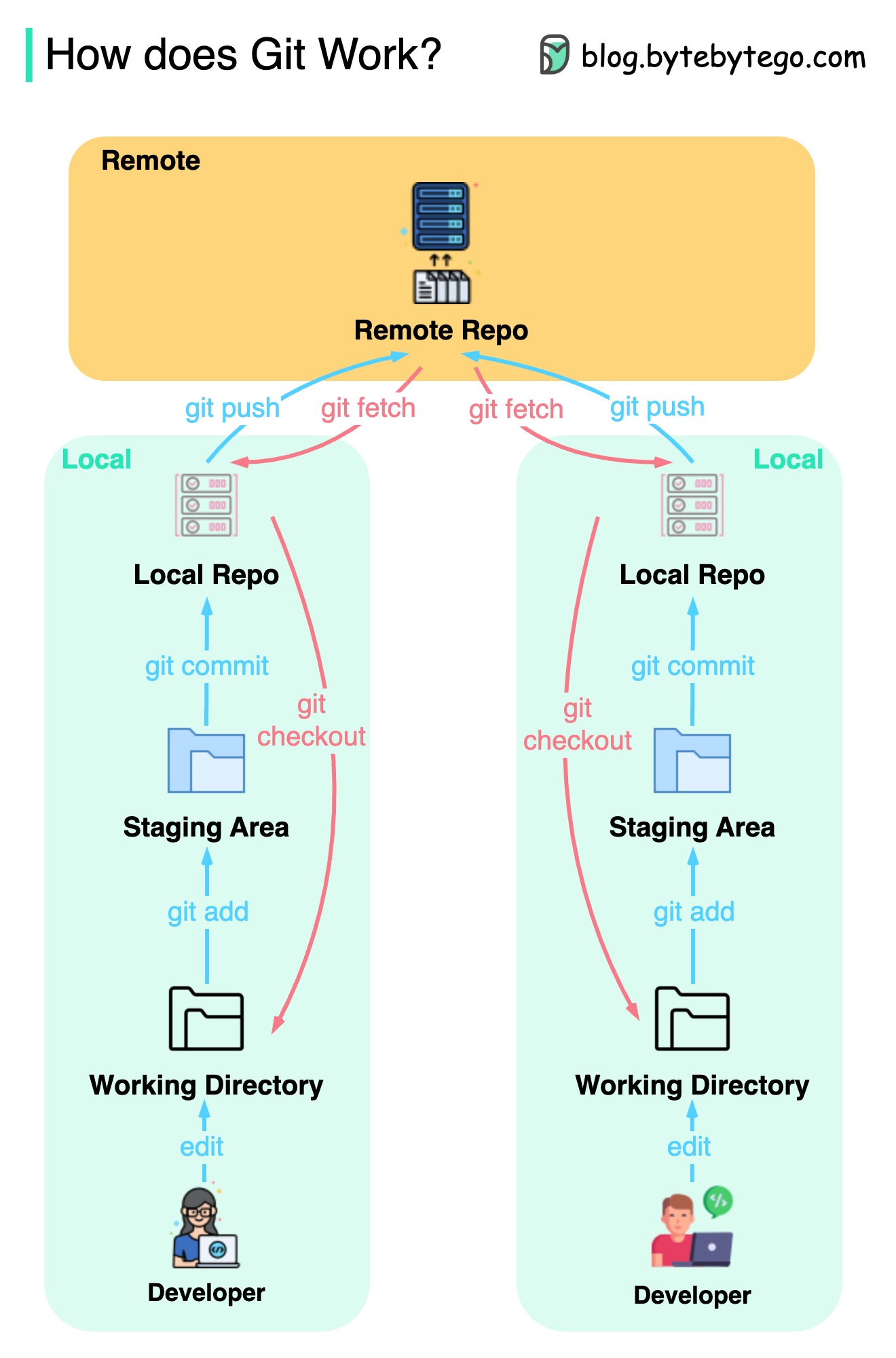
Git – это распределенная система контроля версий.
Каждый разработчик поддерживает локальную копию основного репозитория, редактирует и фиксирует (commit) локальную копию.
Фиксация является очень быстрой, поскольку эта операция не затрагивает удаленный репозиторий.
Если с удаленным репозиторием что-то случилось, файлы могут быть восстановлены из локальных репозиториев.
Git merge и git rebase
Разница между командами git merge и git rebase:

Когда мы вливаем (merge) изменения из одной ветки (branch) в другую, мы можем использовать git merge или git rebase.
Merge
Данная команда создает новый коммит G в основной (main) ветке. G содержит историю как основной, так и функциональной (feature) ветки.
Merge является недеструктивным (non-destructive) – ни основная, ни функциональная ветка не модифицируются.
Rebase
Rebase перемещает историю функциональной ветки в начало (head) основной ветки. Это приводит к созданию новых коммитов E, F и G для каждого коммита функциональной ветки.
Преимуществом rebase является линейная история фиксации изменений (коммитов).
Rebase может быть опасным при нарушении "золотого правила rebase", которое гласит "никогда не используй rebase для публичных веток".
Облачные сервисы
Популярные облачные сервисы по состоянию на 2023 год

Облачная нативность
Диаграмма показывает эволюцию архитектуры и процессов с 1980-х:

Организации могут создавать и запускать масштабируемые приложения в публичных, приватных и гибридных облаках с помощью нативных облачных (cloud native) технологий.
Это означает, что приложения проектируются под возможности облака, что делает их устойчивыми к нагрузке и легкомасштабируемыми.
Облачная нативность включает 4 аспекта:
- Процесс разработки – эволюционировал от водопада (waterfall) до Agile и DevOps.
- Архитектура приложения – архитектура эволюционировала от монолитов к микросервисам. Каждый сервис является небольшим, адаптируемым к ограниченным ресурсам облачных контейнеров.
- Деплой – сначала приложения разворачивались на физических серверах. В 2000-х приложения нечувствительные к задержке стали разворачиваться на виртуальных серверах. Облачная нативность позволяет упаковывать приложения в образы Docker и разворачивать их в контейнерах.
- Инфраструктура приложения – приложения массово разворачиваются в облачной инфраструктуре вместо локальных серверов.
Инструменты, повышающие продуктивность разработки
Визуализация файлов JSON
Файлы JSON, содержащие вложенные структуры, сложно читать.
JsonCrack генерирует граф данных на основе файла JSON, что сильно облегчает изучение его структуры.
Сгенерированные диаграммы можно скачивать в виде изображений.

Автоматические преобразование кода в архитектурные диаграммы

Возможности Diagrams:
- визуализация архитектуры облачной системы с помощью Python
- рендеринг диаграмм в Jupiter Notebook
- инструменты проектирования не требуются
- поддерживаются следующие провайдеры: AWS, Azure, GCP, Kubernetes, Alibaba Cloud, Oracle Cloud etc.
Linux
Файловая система Linux
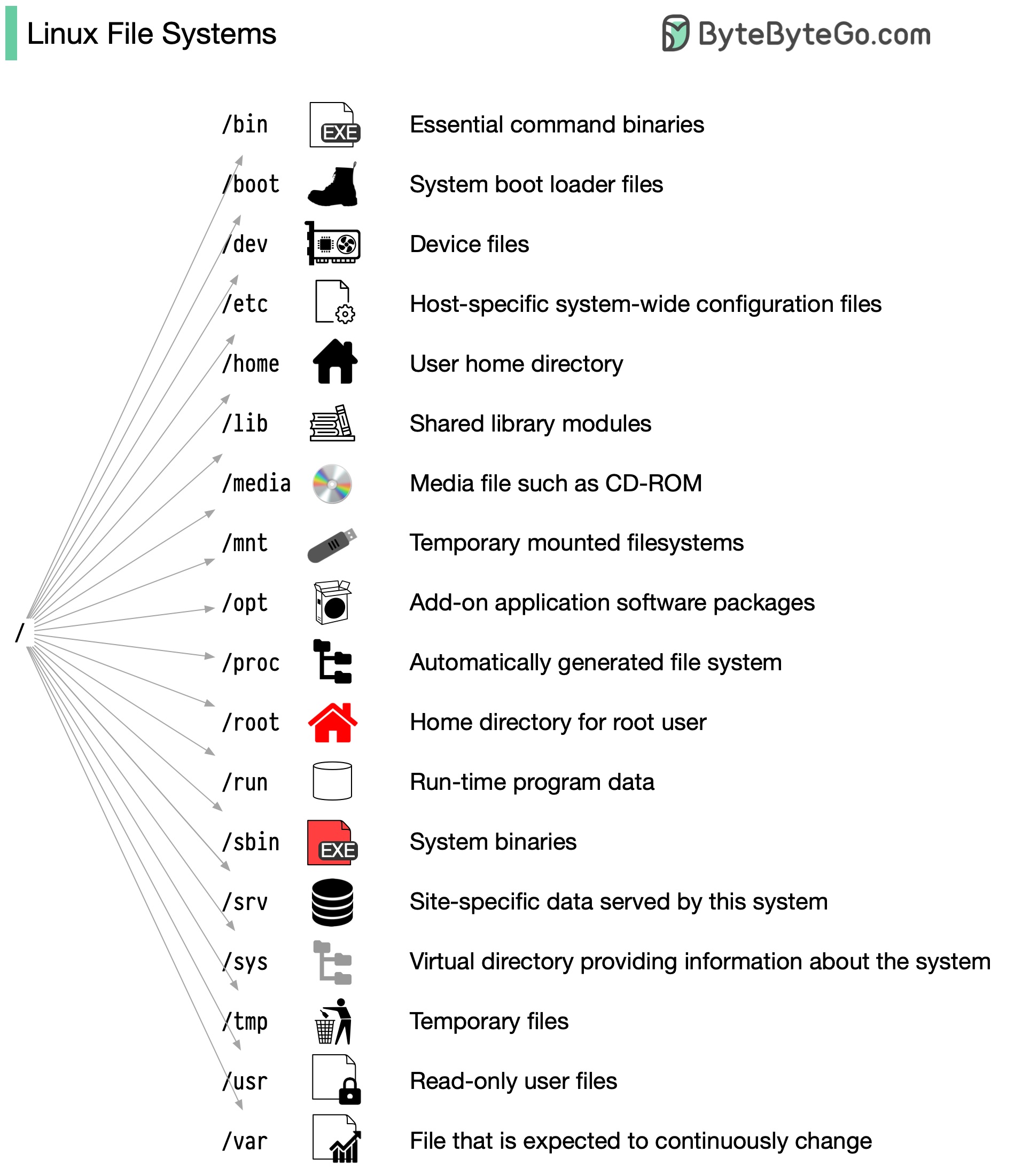
Файловая система Linux раньше напоминала неорганизованный город, где люди строили свои дома там, где им заблагорассудится. Однако в 1994 был введен стандарт иерархии файловой системы (Filesystem Hierarchy Standard, FHS) Linux.
Внедряя такой стандарт, как FHS, ПО может обеспечить единообразную структуру в разных дистрибутивах Linux. Тем не менее, не все дистрибутивы Linux строго придерживаются этого стандарта. Они часто включают уникальные элементы или рассчитаны на удовлетворение конкретных потребностей. Начните с изучения названного стандарта. Используйте такие команды, как cd для навигации и ls для просмотра содержимого каталога. Представьте файловую систему в виде дерева, которое начинается с корня (root, /). Со временем это станет для вас второй натурой, превратив вас в опытного администратора Linux.
18 основных команд Linux
Команды Linux – это инструкции для взаимодействия с операционной системой. Они помогают управлять файлами, директориями, системными процессами и другими аспектами системы. Для эффективной работы с основанными на Linux системами необходимо уверенно владеть этими командами.
Популярные команды Linux:

-
ls– показывает список файлов и директорий -
cd– меняет текущую директорию -
mkdir– создаёт директорию -
rm– удаляет файлы или директории -
cp– копирует файлы или директории -
mv– перемещает или переименовывает файлы или директории -
chmod– меняет разрешения файла или директории -
grep– ищет паттерн в файлах -
find– ищет файлы или директории -
tar– управляет архивными файлами Tarball -
vi– редактирует файлы с помощью текстовых редакторов -
cat– показывает содержимое файлов -
top– показывает процессы и используемые ресурсы -
ps– показывают информацию о процессе -
kill– завершает процесс с помощью сигнала -
du– вычисляет используемое пространство файла -
ifconfig– настраивает сетевые интерфейсы -
ping– тестирует соединение между хостами
Безопасность
Принцип работы HTTPS
Hypertext Transfer Protocol Secure (безопасный протокол передачи гипертекста, HTTPS) – это расширение Hypertext Transfer Protocol (протокола передачи гипертекста, HTTP). HTTPS передает зашифрованные данные с помощью Transport Layer Security (безопасность транспортного уровня, TLS). Если данные будут перехвачены, все, что получит злоумышленник, — это двоичный код.

Как шифруются и расшифровываются данные?
- Клиент и сервер устанавливают соединение TCP.
- Клиент отправляет серверу приветствие (client hello). Сообщение содержит необходимые алгоритмы шифрования (наборы шифров – cipher suites) и последнюю поддерживаемую версию TLS. Сервер отвечает приветствием (server hello), сообщающим, поддерживает ли он данные алгоритмы и версию TLS. Затем сервер отправляет клиенту сертификат SSL. Сертификат содержит открытый ключ, название хоста, дату истечения срока действия etc. Клиент валидирует сертификат.
- После проверки сертификата SSL клиент генерирует ключ сессии (session key) и шифрует его с помощью открытого ключа. Сервер получает зашифрованный ключ и расшифровывает его с помощью закрытого ключа.
- Теперь, когда клиент и сервер имеют один и тот же ключ сессии (симметричное шифрование), данные могут передаются по защищенному двунаправленному каналу.
Почему HTTPS переключается на симметричное шифрование при передаче данных?
На это существует 2 основные причины:
- Безопасность – асимметричное шифрование работает только в одном направлении. Это означает, что любой сможет расшифровать данные, передаваемые сервером клиенту, с помощью открытого ключа.
- Экономия ресурсов сервера: асимметричное шифрование добавляет много расходов на вычисления. Оно не подходит для передачи данных в длительных сеансах.
OAuth 2.0 простыми словами
OAuth 2.0 — это мощная и безопасная платформа, которая позволяет приложениям безопасно взаимодействовать друг с другом от имени пользователей без передачи их конфиденциальных учетных данных:

Сущностями, участвующими в OAuth, являются пользователь, сервер и поставщик удостоверений/провайдер идентификации (Identity Provider, IDP).
Токен OAuth
При использовании OAuth мы получаем токен OAuth, который представляет нашу личность и разрешения (permissions). Этот токен может делать несколько важных вещей:
- Single Sign-On (единый вход, SSO) – токен OAuth позволяет войти в несколько служб или приложений, используя всего один логин, что делает жизнь проще и безопаснее
- авторизация в разных системах – токен OAuth позволяет распределять права авторизации или доступа в разных системах, поэтому нам не нужно выполнять вход в каждую систему по-отдельности
- доступ к профилю пользователя – приложения с токеном OAuth могут получить доступ к определенным частям профиля пользователя согласно предоставленным разрешениям.
OAuth 2.0 предназначен для обеспечения безопасности данных пользователя, а также обеспечения бесперебойной и легкой работы с различными приложениями и сервисами.
4 наиболее распространенных механизмов аутентификации
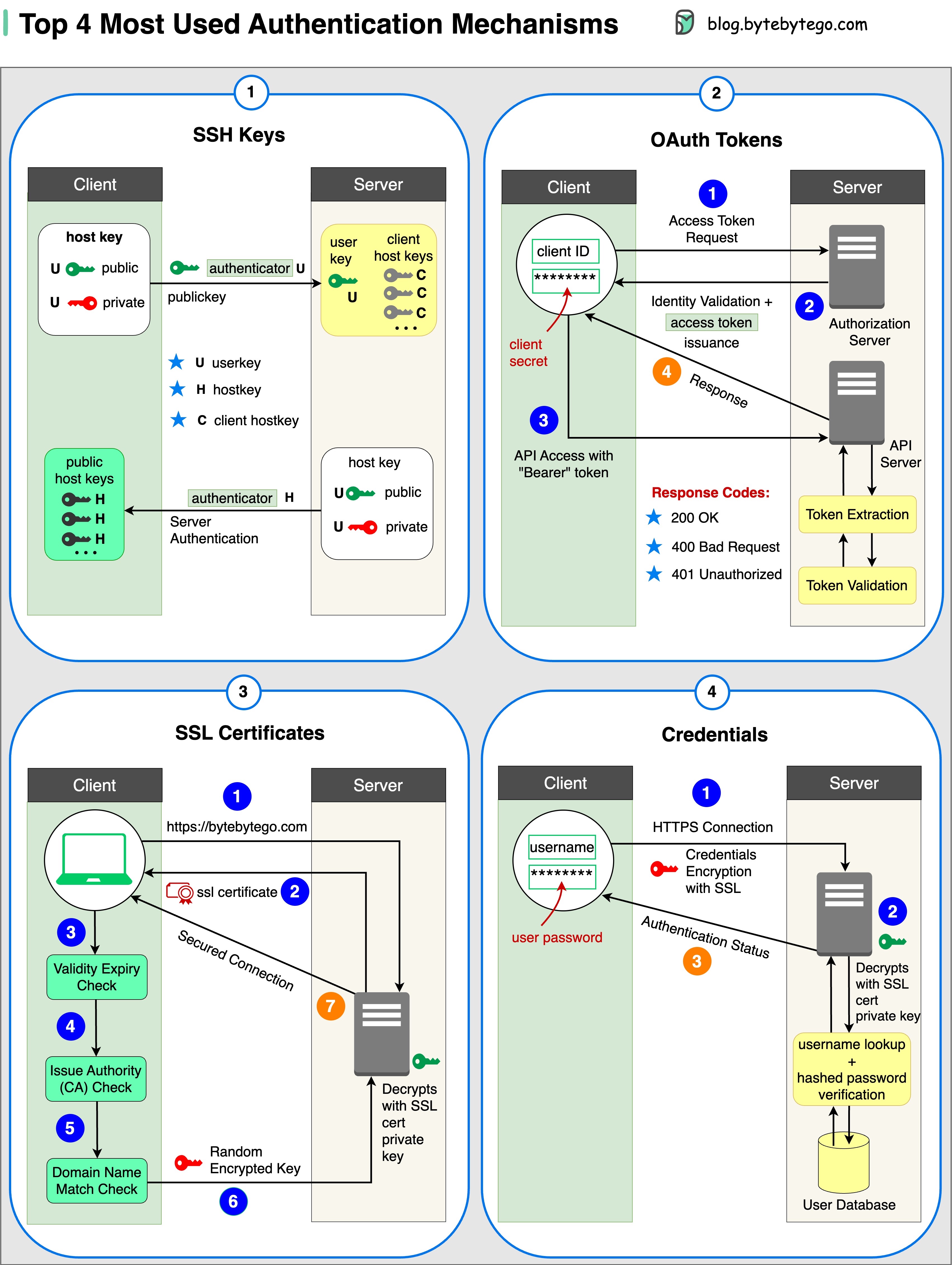
- Ключи SSH – криптографические ключи, которые используются для безопасного доступа к удаленным системам и серверам.
- Токены OAuth – токены, предоставляющие ограниченный доступ к пользовательским данным сторонним приложениям.
- Сертификаты SSL – цифровые сертификаты, которые обеспечивают безопасную и зашифрованную связь между серверами и клиентами.
- Реквизиты для входа (credentials) – информация, предоставленная пользователем, которая используется для проверки и предоставления доступа к различным системам и сервисам.
Сессия, куки, JWT, SSO и OAuth
Все эти термины относятся к управлению идентификацией пользователей. При посещении сайта мы указываем, кто мы (идентификация). Наша личность проверяется (аутентификация), и нам предоставляются определенные разрешения (авторизация). На сегодняшний день существует множество решений и этот список продолжает расти.

- WWW-аутентификация – самый простой метод. Браузер запрашивает имя пользователя и пароль. Из-за невозможности контролировать жизненный цикл авторизации сегодня этот способ используется редко
- контроль жизненного цикла авторизации выполняется с помощью файлов куки (cookie), содержащих данные сессии. Сервер поддерживает хранилище сессий, а браузер сохраняет идентификатор сессии. Файлы куки обычно не подходят для мобильных приложений
- для решения проблемы совместимости можно использовать токены. Клиент отправляет токен на сервер, а сервер проверяет его. Недостатком является то, что токен необходимо шифровать и расшифровывать, что может занимать много времени
- JWT (JSON Web Token) – это стандартный способ представления токенов. Такие токены можно проверить и им можно доверять, поскольку они содержат цифровую подпись. Поскольку JWT содержит подпись, нет необходимости сохранять информацию о сессии на стороне сервера
- SSO (Single Sign-On – единый вход) позволяет войти в систему один раз для авторизации на нескольких сайтах. Для хранения межсайтовой информации в нем используется CAS (Central Authentication Service — центральная служба аутентификации)
- OAuth позволяет предоставлять доступ к определенной части наших учетных данных сторонним приложениям
Безопасное хранение паролей в базе данных и их валидация

Плохие практики
- хранение паролей в виде обычного текста – плохая идея, поскольку любой, у кого есть внутренний доступ, может их увидеть
- непосредственное хранения хэшей паролей является недостаточным с точки зрения безопасности, поскольку оно подвержено атакам с предварительными вычислениями (precomputation attacks), таким как радужные таблицы (rainbow tables)
- для смягчения атаки с предварительным вычислением при хэшировании паролей используется соль (salt)
Соль
Согласно рекомендациям OWASP, "соль – это уникальная, случайно сгенерированная строка, которая добавляется к каждому паролю в процессе хэширования".
Хранение пароля и соли
- Результат хэширования должен быть уникальным для каждого пароля.
- В БД записывается результат выполнения функции
hash(password + salt).
Валидация пароля
- Клиент вводит пароль.
- Система извлекает соль из БД.
- Система добавляет соль к паролю и хэширует его. Получаем хэшированное значение H1.
- Система сравнивает H1 и H2, где H2 — это хэш, хранящийся в БД. Если H1 и H2 совпадают, введенный пользователем пароль является валидным.
JWT (JSON Web Token) простыми словами

Представьте, что у нас есть специальная коробка под названием JWT. Внутри этой коробки лежит три вещи: заголовок (header), полезная нагрузка (payload) и подпись (signature).
Заголовок похож на этикетку на внешней стороне коробки. Он сообщает нам, что это за тип коробки и как она защищена. Обычно он записывается в виде JSON, который представляет собой всего лишь способ организации информации с помощью фигурных скобок ({}) и двоеточий (:).
Полезная нагрузка – фактическое сообщение или информация, которую мы хотим отправить. Это может быть наше имя, возраст или любые другие данные, которыми мы хотим поделиться. Он также записывается в формате JSON, поэтому его легко понять и с ним легко работать.
Подпись – это то, что делает JWT безопасным. Это как особая печать, известная только отправителю. Подпись создается с использованием секретного кода (пароля). Подпись гарантирует, что никто не может изменить содержимое JWT без ведома отправителя.
При отправке JWT на сервер, мы помещаем в поле заголовок, полезную нагрузку и подпись. Затем мы отправляем его на сервер. Сервер читает заголовок и полезную нагрузку, чтобы понять, кто мы и что хотим сделать.
Принцип работы Google Authenticator и других типов двухфакторной аутентификации
Google Authenticator используется для входа в учетную запись, когда включена двухфакторная аутентификация.
Google Authenticator – это программный аутентификатор, реализующий службу двухэтапной проверки.

Данный процесс состоит из 2 этапов:
- Пользователь включает двухэтапную аутентификацию Google.
- Пользователь использует аутентификатор для входа в систему etc.
Стадия 1
1 и 2. Боб открывает веб-страницу, чтобы включить двухэтапную проверку. Страница запрашивает секретный ключ. Служба аутентификации генерирует секретный ключ для Боба и сохраняет его в базе данных.
- Служба аутентификации возвращает URI клиенту. URI состоит из эмитента ключа (key issuer), имени пользователя и секретного ключа. URI отображается в виде QR-кода на странице.
- Боб использует Google Authenticator для сканирования сгенерированного QR-кода. Секретный ключ записывается в аутентификатор.
Стадия 2
1 и 2. Боб хочет войти на сайт с двухэтапной проверкой Google. Для этого ему нужен пароль. Каждые 30 секунд Google Authenticator генерирует шестизначный пароль, используя алгоритм TOTP (Time-based One Time Password – одноразовый пароль на основе времени). Боб использует пароль для входа на сайт.
3 и 4. Клиент отправляет пароль, введенный Бобом, на сервер для аутентификации. Служба аутентификации считывает секретный ключ из базы данных и генерирует шестизначный пароль, используя тот же алгоритм TOTP, что и клиент.
- Служба аутентификации сравнивает два пароля, сгенерированные клиентом и сервером, и возвращает результат сравнения клиенту. Боб может продолжить процесс входа в систему, только при совпадении паролей.
Может ли другое лицо получить секретный ключ?
Секретный ключ должен передаваться по протоколу HTTPS. Клиент-аутентификатор и БД сохраняют секретный ключ, поэтому он должен быть зашифрован.
Может ли хакер угадать шестизначный пароль?
Очень маловероятно. Пароль состоит из 6 цифр, поэтому сгенерированный пароль имеет 1 000 000 потенциальных комбинаций. Плюс пароль меняется каждые 30 секунд. Если хакеры хотят угадать пароль за 30 секунд, им необходимо вводить 30 000 комбинаций в секунду.
Реальные системы
Технический стек Netflix
Диаграмма основана на исследованиях многих инженерных блогов Netflix и проектов с открытым исходным кодом.

Для разработки нативных мобильных приложений используется Swift и Kotlin, для разработки веб-приложений – React.
Для взаимодействия клиента и сервера используется GraphQL.
Для разработки сервисов бэкенда используется ZUUL, Eureka, фреймворк Spring Boot и другие технологии.
В качестве БД используются EV Cache, Cassandra, CockroachDB и другие.
Для сообщений и потоковой передачи данных используются Apache Kafka и Fink.
В качестве хранилища видео используются S3 и Open Connect.
Для обработки данных используются Flink и Spark. Данные визуализируются с помощью Tableau. Для обработки структурированной информации хранилища данных используется Redshift.
Для процессов, связанных с CI/CD, используются такие инструменты, как JIRA, Confluence, PagerDuty, Jenkins, Gradle, Chaos Monkey, Spinnaker, Atlas и другие.
Архитектура Twitter по состоянию на 2022 год
Это настоящая архитектура Твиттера. Она опубликована Илоном Маском и перерисована нами для лучшей читабельности.

Эволюция архитектуры Airbnb в течение последних 15 лет
Архитектура Airbnb прошла через 3 основных стадии:

Монолит (2008-2017)
Airbnb начинался как простая торговая площадка для гостиниц и гостей. Она была разработана с помощью Ruby on Rails в виде монолита.
Недостатки:
- отсутствие постоянной команды разработчиков + бесхозный код
- медленный деплой
Микросервисы (2017-2020)
Ключевые сервисы:
- сервис получения данных
- сервис бизнес-логики
- сервис рабочих процессов
- сервис агрегации UI (User Interface — пользовательский интерфейс)
Каждый сервис разрабатывается и поддерживается отдельной командой.
Недостатки:
- сотнями сервисов и зависимостей сложно управлять
Микро- и макросервисы (2020-настоящее время)
Гибридная модель микро- и макросервисов фокусируется на унификации API.
Монорепозиторий и микрорепозитории
Что лучше? Почему разные компании выбирают разные варианты?

Концепция монорепозитория не нова; Linux и Windows были разработаны с использованием этой концепции. Чтобы улучшить масштабируемость и скорость сборки, Google разработал специальную внутреннюю цепочку инструментов и строгие стандарты качества кодирования, чтобы обеспечить единообразие разработки и деплоя.
Amazon и Netflix являются основными представителями философии микросервисов. При таком подходе код сервиса естественным образом разделяется на отдельные репозитории. Он масштабируется быстрее, но в дальнейшем могут возникнуть проблемы с управлением многочисленными сервисами.
В монорепозитории каждый сервис представляет собой директорию, и каждая директория имеет конфигурацию BUILD и контроль разрешений OWNERS. Каждый участник сервиса несет ответственность за свою директорию.
С другой стороны, в микрорепозитории каждый сервис отвечает за свой репозиторий, при этом конфигурация сборки и разрешений обычно устанавливаются для всего репозитория.
В монорепозитории зависимости распределяются по всей кодовой базе, поэтому при обновлении версии любой зависимости обновляется версия всего кода.
В микрорепозитории зависимости являются уникальными для каждого репозитория. Версии зависимостей обновляются в соответствии с графиками сервисов.
В монорепозитории есть стандарт регистрации. Процесс проверки кода Google известен тем, что устанавливает высокую планку, обеспечивая единый стандарт качества для монорепозитория, независимо от сервиса.
Микрорепозиторий может либо использовать собственный стандарт, либо принять общий стандарт, включив в него лучшие практики. Для сервиса он может масштабироваться быстрее, но качество кода может быть немного другим. Для управления микросервисами инженеры Google разработали Bazel, а Meta – Buck. Среди инструментов с открытым исходным кодом можно называть Nix, Lerna и другие.
С годами у микросервисов появилось больше поддерживаемых инструментов, включая Maven и Gradle для Java, NPM для NodeJS, CMake для C/C++ и другие.
Архитектура Stack Overflow
Какая архитектура реализована в Stack Overflow?
Если ваш ответ – локальные серверы и монолит, вы, скорее всего, провалите собеседование, но именно так оно и устроено!

Ожидание
- Для разделения системы на небольшие компоненты используются микросервисы
- у каждого сервиса своя база данных, активно используется кэш
- сервисы сегментированы (sharded)
- сервисы взаимодействуют друг с другом асинхронно через очереди сообщений
- сервисы реализованы с использованием источников событий (Event Sourcing) с CQRS
- широко используются распределенные системы, такие как итоговая согласованность (eventual consistency), теорема CAP etc.
Реальность
Stack Overflow обрабатывает весь трафик с помощью всего 9 локальных веб-серверов, и это монолит! Никакие облачные решения в нём не используются.
Почему Amazon Prime Video Monitoring перешел с бессерверной архитектуры на монолит? Как это может сэкономить 90% стоимости?
Сравнение архитектуры до и после перехода:

Что такое служба видеомониторинга Amazon Prime?
Сервису Prime Video необходимо следить за качеством тысяч прямых трансляций. Инструмент мониторинга автоматически анализирует потоки данных в режиме реального времени и выявляет проблемы с качеством, такие как повреждение блоков (block corruption), зависание видео и проблемы с синхронизацией. Это важный процесс для удовлетворения клиентов.
Мониторинг состоит из 3 компонентов: медиаконвертер, детектор дефектов и сервис уведомлений в реальном времени.
Недостатки старой архитектуры
Старая архитектура была основана на Amazon Lambda, который позволял быстро создавать сервисы. Однако использование архитектуры в больших масштабах было нерентабельным. Две самые дорогостоящие операции:
- Рабочий процесс оркестрации – пошаговые функции (step functions) AWS взимают с пользователей плату за переходы состояний, а оркестрация выполняет несколько переходов состояний каждую секунду.
- Передача данных между распределенными компонентами — промежуточные данные хранятся в Amazon S3, чтобы их можно было загрузить на следующем этапе. Чем больше объем данных, тем дороже загрузка.
Монолит экономит 90% стоимости
Монолитная архитектура предназначена для решения проблем стоимости. Компонентов по-прежнему 3, но медиаконвертер и детектор дефектов развертываются в одном процессе, что экономит затраты на передачу данных по сети. Удивительно, но изменение архитектуры привело к экономии средств на 90%!
Это интересный и уникальный пример, поскольку микросервисы сегодня являются популярным и модным выбором в техноиндустрии. Разделение компонентов на распределенные микросервисы сопряжено с дополнительными расходами.
Технический директор Amazon Вернер Фогельс сказал следующее: "Создание эволюционирующих программных систем – это стратегия, а не религия. Поэтому необходимо периодически непредвзято пересматривать архитектуру системы".
Бывший вице-президент Amazon по устойчивому развитию Адриан Кокрофт: "Команда Prime Video следовала по пути, который я называю "Сначала бессерверные"… Я не сторонник только бессерверных технологий".
Как Disney Hotstar удалось собрать 5 миллиардов смайлов во время турнира?

- Клиенты отправляют смайлы через стандартные HTTP-запросы. Вы можете думать о Golang Service как о типичном веб-сервере. Golang выбран потому, что он хорошо поддерживает параллелизм. Потоки в Golang легкие.
- Поскольку объем данных очень велик, в качестве буфера используется Kafka (брокер сообщений).
- Смайлы агрегируются службой потоковой обработки под названием Spark. Он собирает данные каждые 2 секунды (интервал настраивается). В зависимости от интервала приходится идти на некоторые компромиссы. Более короткий интервал означает, что смайлы доставляются другим клиентам быстрее, но это также означает, что требуется больше вычислительных ресурсов.
- Агрегированные данные записываются в другой Kafka.
- Потребители PubSub (издатель/подписчик) извлекают агрегированные смайлы из Kafka.
- Смайлы доставляются клиентам в режиме реального времени через инфраструктуру PubSub. Инфраструктура PubSub интересна. Hotstar рассмотрела следующие протоколы: Socketio, NATS, MQTT и gRPC и остановилась на MQTT.
Похожий подход к архитектуре применяется LinkedIn, который обрабатывает миллион лайков в секунду.
Как Discord хранит триллионы сообщений?
Эволюция хранения сообщений в Discord:

MongoDB ➡️ Cassandra ➡️ ScyllaDB.
В 2015 первая версия Discord была построена на основе одной реплики MongoDB. Примерно в ноябре 2015 MongoDB хранила 100 миллионов сообщений, и оперативная память больше не вмещала данные и индексы. Задержка стала непредсказуемой. Возникла необходимость переместить хранение сообщений в другую базу данных. Была выбрана Cassandra.
В 2017 у Discord было 12 узлов (nodes) Cassandra, на которых хранились миллиарды сообщений.
На начало 2022 было 177 узлов с триллионами сообщений. На этом этапе задержка стала непредсказуемой, а выполнение операций по техническому обслуживанию стало слишком дорогим.
Причин возникновения такой ситуации несколько:
- Cassandra использует дерево LSM для внутренней структуры данных. Чтение обходится дороже, чем запись. На сервере с сотнями пользователей может выполняться множество одновременных операций чтения, что приводит к образованию горячих точек
- обслуживание кластеров, например сжатие SSTables, влияет на производительность
- паузы в сборке мусора могут приводить к значительным скачкам задержки
ScyllaDB – это база данных, совместимая с Cassandra, написанная на C++. Discord изменил свою архитектуру, включив в нее монолитный API, сервис данных, написанный на Rust, и ScyllaDB в качестве основного хранилища данных.
Задержка чтения p99 в ScyllaDB составляет 15 мс по сравнению с 40-125 мс в Cassandra. Задержка записи p99 составляет 5 мс по сравнению с 5-70 мс в Cassandra.
Как работают прямые видеотрансляции на YouTube, TikTok Live или Twitch?
Прямая трансляция отличается от обычной потоковой передачи данных, поскольку видеоконтент отправляется по сети в режиме реального времени, обычно с задержкой всего в несколько секунд.
Вот что делает это возможным:

- Необработанные (raw) видеоданные захватываются микрофоном и камерой. Данные передаются на сервер.
- Видеоданные сжимаются и кодируются. Например, алгоритм сжатия разделяет фон и другие элементы видео. После сжатия видео кодируется в соответствии со стандартами, такими как H.264. Это сильно уменьшает размер видеоданных.
- Закодированные данные делятся на мелкие части (чанки — chunks), обычно длиной в несколько секунд, поэтому для их загрузки или потоковой передачи требуется гораздо меньше времени.
- Сегментированные данные отправляются на сервер потоковой передачи (streaming server). Сервер потоковой передачи должен поддерживать различные устройства и условия сети. Это называется "адаптивной потоковой передачей битрейта" (Adaptive Bitrate Streaming). Это означает, что на шагах 2 и 3 необходимо создать несколько файлов с разным битрейтом.
- Данные потоковой передачи в реальном времени передаются на пограничные серверы (edge servers), поддерживаемые CDN (Content Delivery Network – сеть доставки контента). Миллионы зрителей могут смотреть видео с ближайшего пограничного сервера. CDN значительно снижает задержку времени передачи данных.
- Устройства зрителей декодируют и распаковывают видеоданные и воспроизводят видео в плеере.
7 и 8. Если видео необходимо сохранить для повторного воспроизведения, закодированные данные отправляются в хранилище, откуда впоследствии извлекаются без обращения к CDN.
Стандартные протоколы для прямой трансляции:
- RTMP (Real-Time Messaging Protocol – протокол обмена сообщениями в реальном времени) – изначально был разработан Macromedia для передачи данных между Flash-плеером и сервером. Теперь он используется для потоковой передачи видеоданных через Интернет. Обратите внимание, что приложения для видеоконференций, такие как Skype, используют протокол RTC (Real-Time Communication – связь в реальном времени) для снижения задержки.
- HLS (HTTP Live Streaming — прямая трансляция по HTTP) — этот протокол требует кодировки данных в H.264 или H.265. Устройства Apple поддерживают только это протокол
- DASH (Dynamic Adaptive Streaming over HTTP – динамическая адаптивная потоковая передача данных через HTTP)
И HLS, и DASH поддерживают потоковую передачу с адаптивным битрейтом.
Комментарии (11)


volchenkodmitriy
30.10.2023 07:20Спасибо за статью! Все кратко четко и полезно! Для меня новой была информация про HTTP 3 Не ожидал что планируется такая революция.

bcwd
30.10.2023 07:20+2шпаргалка - отличный формат подачи информации без лишней воды, побольше такого !

CTheo
30.10.2023 07:20+3Почему то как речь заходит о System design, там одни веб сервера. Как будто других систем не делают, скажем CAD, 3д редакторы или игровые движки.

calculator212
30.10.2023 07:20+2Думаю дело в том, что большая часть программистов с этим работает, т.к. очень много софта который нужен для обмена данными по сети, для балансировки нагрузки, для синхронтзации этих данных. А вероятность с нуля разрабатывать CAD или игровой движок в реальном проекте намного ниже, чем с нуля разработать проект на SOA или микросервисах.

beskov
30.10.2023 07:20+1да, по факту это скорее internet systems design, у information systems design пока немного другие паттерны, но они сближаются постоянно

BigDflz
30.10.2023 07:20откуда вывод, что websocket для не больших сообщений? практика говорит, что и большие бинарные файлы можно передавать. а текстовые тем более
странная таблица сравнения. чем отличается передача xml по soap от передачи того же xml по wedsocket? и чем лучше rest для веб-сервисов от websocket?
и чем меньше нагрузка на сеть GraphQL по сравнению с websocket?
вот интересно - тут написано,<двусторонний, позволяет обмениваться данными в реальном времени, > а в комментариях к https://habr.com/ru/companies/otus/articles/770256/ сомневаются в реал тайм ws :)

ggo
30.10.2023 07:20откуда вывод, что websocket для не больших сообщений? практика говорит, что и большие бинарные файлы можно передавать. а текстовые тем более
скажем, эффект от использования вебсокетов больше, когда взаимодействие построено на большом количестве мелких запросов/ответов.

vialz
30.10.2023 07:20Пардон за занудство, но все таки soap это протокол (в оглавлении) или архитектурный стиль (по тексту)?
К слову, нередкий вопрос на собесах аналитиков, важно помнить что rest(ful) это стиль проектирования апи (который часто не соблюдается в http api), а soap, grpc и далее по списку - протоколы, то бишь инструменты. При остром желании можно soap over http api даже сделать :)

grisha0088
Отличная статья, чтобы освежить знания. Большое спасибо)