

Хранение данных — это всегда боль, у которой может быть больше 50 оттенков: железо, кэш, гарантии, производительность, скорость восстановления при проблемах, удобство и прочее. Как решить большинство из них, при этом получив что-то легко обслуживаемое, да ещё бесплатно? Сегодня поговорим про файловые системы на примере не совсем дефолтной OpenZFS.
Меня зовут Георгий Меликов, я работаю в VK Cloud, являюсь руководителем направления IaaS разработки. Мы занимаемся не только хранилищами, но и программными сетями. Но так как у нас в проде ещё нет ZFS, то я пишу в качестве контрибьютора проекта OpenZFS. Контрибьючу я в него с 2016 года. И всё потому, что ооочень люблю свои данные. Прямо очень. По этой причине на моём ноутбуке только ZFS с Linux.
Поговорим про файловую систему в контексте того, какие задачи наши стораджи должны решать. Они, конечно, должны как-то масштабироваться, а мы после этого как-то переживать отказы оборудования. А оборудование, даже если не отказало, может очень сильно врать нам. Например, записав не то, что попросили. Решив эти проблемы, нам надо как-то жить с нормальной производительностью и при этом ещё давать какой-то функционал. В конечном итоге за любым проектом стоит комьюнити. Потому что если код есть, а людей нет, он очень быстро теряет актуальность.
О ZFS
У ZFS очень долгая история — ему уже больше 22 лет, а за это время он немало пережил. Всё началось с компании SUN Microsystems в 2001 году. В 2005 ZFS успешно релизнули в качестве части операционной системы Open Solaris, после этого очень быстро появилось много форков не только в Linux, но и в других операционных системах. В некоторых местах за счёт совместимых лицензий оно попало даже в дефолтные ФС. Но в 2010 году SUN Microsystems поглотила компания Oracle.
Может быть, это и было хорошо с точки зрения развития бизнеса, но с точки зрения развития open source проекта всё уже не так радужно, потому что исходный код ZFS закрыли, как и Open Solaris. Исходный код стал жить в виде отдельных форков на разных операционных системах.
В 2013 году была создана отдельная организация — OpenZFS, чтобы эти форки развивали всё-таки одну и ту же файловую систему, а не различные форки со своим функционалом.
Файловые системы и стораджи
Достаточно ли нам только лишь одной файловой системы, чтобы строить какой-либо сторадж?
Начнём мы с того, какие типы стораджей бывают. Для простоты рассмотрим два:
-
Локальная система, у которой железо находится непосредственно под собой.
-
Распределённая, когда система нарезана на много железок, всё это ходит по сети, и наши клиенты к нам тоже ходят по сети с других отдельных железок.

Отличия у этих подходов также два:
-
По задержкам. На локальном оборудовании, конечно, всё очень быстро. На распределённых системах задержки будут значительные, потому что мы ходим по сети.
-
По масштабируемости. Локальную систему вы значительно не отмасштабируете. Можно залить это железо деньгами, купить какой-нибудь мейнфрейм. Но, к сожалению, это будет стоить вагон денег и всё равно будет иметь потолок по производительности. При этом распределённые решения при наличии нужной архитектуры весьма хорошо масштабируются. Может быть, даже неограниченно.

В этой статье мы будем говорить в основном про локальные решения: EXT4, XFS, NTFS и ZFS.
База данных
Наверняка у каждого из нас в проде есть какая-то очень важная база данных, от которой зависит бизнес. Когда бизнес растёт, база данных тоже растёт. Конечно, одного жёсткого диска не хватает. По этой причине мы в какой-то момент хотим поставить туда больше одного диска.

Но нужно помнить про разграничение ответственности: разработчики баз данных и так решают большое количество проблем, и брать ответственность за файловую систему или стораджи — это дополнительная бОльшая нагрузка.
Здесь нужно применять решение, которое позволит вам получить единый блочный volume. который уже сможет использовать операционная система. Обычно это RAIDs — независимый набор дисков, объединенных в один виртуальный пул.
RAID даёт возможность ограниченного масштабирования. Мы можем подставить еще сколько-то дисков, получить больше пространства. Но также мы должны решить задачу избыточности, чтобы не потерять весь пул при вылете одного из дисков.
Одной из первых мыслей может быть: «А давайте просто купим нужную железку?». Она решает данные задачи. Всё вроде хорошо. Вопрос решён! Но, к сожалению, тут очень много нюансов. Эта железка стоит не в каждом ПК нашего мира. Она выпускается в ограниченном масштабе. Прошивка для неё пишется с учётом этого. Так у вас появляется проприетарная прошивка и, к сожалению, у нее бывает очень много проблем. По этой причине есть железка, к которой вам надо подобрать конкретную версию прошивки, чтобы не было проблем при работе.
Дальше можно говорить про производительность, потому что мы не хотим, чтобы эта железка стоила как сам сервер или еще дороже. Соответственно, оборудование в ней будет стоять более дешёвое. Например, ARM. Можно компенсировать это наличием батарейки, которая позволит нам кешировать синхронную запись.
Но самая большая беда — это отказ. В случае отказа этой железки, а железо когда-то всё равно сдохнет, вам придётся не просто найти аналог, а найти (в худшем случае) именно ТУ САМУЮ железку с ТОЙ САМОЙ прошивкой (но в лучшем случае может подойти свежая железка от того же производителя). У другой железки будет другая логика построения RAID, и у вас просто не сойдется массив, так как железка не будет знать, как его собрать.
Наравне с этим есть и другая проблема. Та самая батарейка, которую мы вставляли для увеличения производительности, в случае отказа даст дикую деградацию производительности. А ведь это конкретная, специфичная, а не обычная «пальчиковая» батарейка.
По этой причине в настоящее время классическое решение — программные рейды. И мы рассмотрим этот вопрос на примере линуксового стека. В нём есть подсистема MD, которую мы обычно конфигурируем через утилиту Mdadm. Этим наименованием мы и будем оперировать дальше.

Mdadm позволяет собрать в единое виртуальное устройство очень много дисков. Но, конечно, мы не хотим это единое устройство использовать на всё. Мы хотим его нарезать — отдельная файловая система для root директории системы, отдельная для home директории, отдельная для базы данных.
По этой причине у нас появляется логическое разделение. Делается это обычно через logical volume manager (LVM).
И только тогда мы получим возможность создать файловую систему поверх всего этого!
Основная беда этого подхода в том, что здесь уже немало слоёв, и они друг про друга ничего не знают. Они должны предоставлять друг другу похожие интерфейсы. В конечном итоге из LVM выходит то же самое блочное устройство.
Но проблема усложняется. Давайте вспомним, что мы хотим менеджерить и администрировать. Нам нужно сначала как-то настроить диски, поработать с ними, и для этого нам требуется целый набор утилит для каждого слоя:

Что даёт ZFS
ZFS — это не просто файловая система, но и менеджер томов. То есть это единое решение, позволяющее делать всё в рамках единого ZFS pool’a. Конечно, этот пул, а точнее ZFS, тоже сам по себе логически устроен из подкомпонентов.
Например, у нас есть отдельный компонент, который отвечает за логическую нарезку на сущности, то есть получение тех самых итоговых файловых систем. В парадигме ZFS это dataset.
Тут также есть очень интересный нюанс касательно того, что ZFS – это объектное хранилище!
Получив эти объекты, мы можем начать оперировать их группой в рамках dataset’ов, которые и дают нам итоговые POSIX-совместимые файловые системы. Далее у нас должен быть подкомпонент, который будет отвечать за избыточность данных:

С помощью этого компонента мы хотим получить те самые аналоги зеркалирования, raid5 или более хитрые кейсы, например, distributed raid (dRAID).
Говоря о менеджменте хранилища, в ZFS всё сильно лучше классических решений:

Вам нужны всего лишь две утилиты: ZPOOL и ZFS, при этом ZPOOL нужна очень редко. Она используется для работы с дисками: создать пул, удалить диск, добавить диск и прочее. Дальше вам нужно управлять теми самыми dataset’ами. Это чисто логическая сущность. Для этого используется команда ZFS — что-то настроить в них, создать, удалить.
Есть ещё третья команда — ZDB, которая используется для дебага. Но если вы с ней знакомы, то у вас уже есть о чём поговорить с комьюнити openZFS, потому что она вам не должна понадобиться никогда просто так :)
Остановимся подробнее на dataset’ах.
Вся их фишка в том, что по лёгкости использования и по легковесности создания они аналогичны работе с обычной директорией, аналогично mkdir. Вы также делаете zfs create some/dataset. И на выходе получаете сущность, которая является для операционной системы той самой отдельной файловой системой. И всё это даёт вам возможность очень гибко настраивать эту файловую систему, конкретный dataset.
Например, есть данные вашей базы данных:
По паттерну доступа — это обычно дикий рандом с маленьким блоком, стоит выставить блок поменьше, использовать какую-то компрессию полегче. Например, LZ4, и всё будет хорошо.
Дальше, у большинства баз данных есть WAL логи – write ahead логи:
Они пишутся последовательно. Их лучше писать с большим размером блока. Это позволит их эффективнее сжимать, да и метаданных будет меньше. И можно поставить, к примеру, более эффективную компрессию. Какую-то помедленнее, но с более эффективным сжатием.
В конечном итоге никто вам не мешает на этот же пул писать и обычные файлы:
И для них мы можем сделать ещё больший размер блока, какие-то более хитрые настройки. Например, полностью отключить запись atime (access time). Также, если нам не нужно давать строгих гарантий, то можно включить игнорирование синхронной записи (sync=disabled). То есть мы в худшем случае потеряем последние Х секунд синхронной записи, зато хранилище начнёт прикидываться оперативной памятью, а состояние пула всё равно останется консистентным.
Вот мы и затронули вопрос отказов.
Отказоустойчивость
Наш дефолтный случай должен быть работой системы при деградации оборудования.
Для начала посмотрим на классические решения. Например, у вас вылетел 20 терабайтный жёсткий диск, вы его вытащили и вставили на его место новый. Вспоминаем, что это отдельные слои, mdadm ничего не знает про данные. Все 20 терабайт нужно полностью синхронизировать.
И на время ребилда массива, пока вы синхронизируете все 20 терабайт, у вас будет деградация производительности на ту самую базу данных, работающую поверх. На тот же промежуток времени вы получите увеличенный риск отказа всего массива, потому что одновременно может вылететь ещё один диск, и данные вы не соберете.
Теперь посмотрим на ZFS и вспомним его основное отличие — что он всё знает про данные. Если этот 20 терабайтный диск вообще пустой, то нам ничего синхронизировать не надо. Если там лежал терабайт, то мы синхронизируем его и в 20 раз уменьшим время деградации производительности, в 20 раз снизим продолжительность риска того, что весь пул развалится из-за вылета еще одного диска.
Давайте посмотрим еще глубже. В классическом варианте мы можем использовать зеркалирование данных. У нас есть два или более диска, и мы на них просто дублируем данные, то есть имеем N копий.
Но это тоже не самый худший случай. Самый худший случай, когда у нас произошла ещё и потеря питания.

Беда в том, что мы не можем параллельно записать те же самые данные на два диска. В любом случае где-то будет какой-то рейс. Эта операция не атомарна, то есть она не может либо пройти, либо нет. Таким образом у вас может получаться промежуточное состояние, когда желая записать 1МБайт вы успели записать 0,5Мбайт только на один диск, и у вас где-то получилась тыква в виде разницы этих 500 килобайт.

Метаданные
Когда я говорю про данные, то говорю и про метаданные в том числе, а не только про данные файлов. Давайте посмотрим, из чего они состоят.
Для начала нам нужно хранить информацию: где же этот файл у нас в файловой системе лежит? Т.е. путь до него (он же — ключ).
Нам нужно хранить дополнительную информацию — какой у него размер, какие даты изменения и какие права (мы работаем в рамках операционных систем с большим числом пользователей, и хотим честную изоляцию).
/home/user/file.txt- путь, имя = ключи
- мета объекта: размер, даты, права
Можно ли надеяться на то, что данные на диске будут всегда расположены последовательно? Нет. Это реальный мир. Мы хотим, чтобы наш бизнес рос, и база данных наша тоже когда-то вырастет. Фрагментация для нас — это базовый случай. Другого просто не будет, и маппинг блоков каждого файла тоже надо как-то хранить.
Становится ясно, что нам нужно решать вопрос обеспечения целостности метаданных.
Классический вариант — это использование журналирования или тех же самых WAL логов, то есть мы последовательно пишем наши изменения. Когда у нас кусок кончается, мы просто начинаем писать сначала. У нас всегда есть более целое предыдущее состояние, и мы можем на него откатиться. Но у этого подхода есть минус. По факту всё, что мы журналируем, мы дублируем. А это очень неприятно:

Еще у вас может произойти — потеря питания.
Когда в ЦОД возвращается питание, хост с основной базой данных начинает загружаться, и мы применяем журнал на файловую систему. А параллельно должны провести операцию fsck — file system check. И она в случае большого объема данных может затянуться на часы. Вопрос администраторов, которые отключают автоматический fsck при загрузке — это отдельный вопрос. Здесь мы его обсуждать не будем :)
Что даёт ZFS
В ZFS журнал для целостности вообще не нужен. Он использует более хитрый подход, который называется Copy on Write, то есть CoW сокращённо.

В таком случае у нас всегда есть иерархия метаданных и в основе — блоки данных, на которые наша мета и ссылается. Особенность CoW (в переводе «копирование при записи») в том, что мы никогда не перезапишем данные поверх. Мы всегда будем записывать их в новое место.
Если мы изменили 1 байт, то мы скопируем предыдущий блок и запишем его в новое место. В настоящий момент у нас новые блоки будут где-то лежать, но пока мы про них ничего не знаем, на дисках ещё нет метадаты.
Дальше мы строим всю иерархию метадаты, на вершине которой будет т.н. UberBlock.

В терминологии ZFS это самый главный блок, который ссылается на состояние ВСЕЙ файловой системы. Мол, «смотри, она вот здесь». На слайде мы видим уже два состояния файловой системы. Предыдущий UberBlock, который представляет UberBlock 1, и следующий – UberBlock 2. Пока мы еще успешно не записали UberBlock 2, мы всегда можем откатиться на предыдущее состояние. Таким образом, мы обеспечиваем здесь абсолютную атомарность!
И запись UberBlock не зависит от того, сколько у нас данных под ним было. Все происходит один раз и без перезаписи!
Есть ещё один большой плюс. Мы можем перезатереть все старые данные в будущем, когда посчитаем нужным. Таким образом мы можем получить бесплатные снапшоты, которые будут ссылкой на предыдущее состояние. То есть «вот эти данные, пожалуйста, не трогай, они мне нужны в будущем». Это вся стоимость снапшотов в ZFS! Да, стоит отметить что удаление уже не нужных блоков всё же требует какой-то работы, но её в CoW придётся заплатить в любом случае.
Целостность
Как я упоминал ранее, кейс с отказом диска — это ещё относительно простой случай. Наиболее неприятно, когда оборудование начинает врать. Вы, например, пишете одно, а получаете другое.
Давайте рассмотрим более интересный кейс.

Есть более эффективный вариант по полезному пространству записи и избыточности. RAID5 и его аналоги. Когда на разных дисках есть уникальные данные, а, например, на третьем, как на картинке, лежат данные чётности. Это результаты какой-то операции над данными. Вы можете видеть, что картинка 3 очень похожа на обе картинки. Она и является честной операцией XOR над этими картинками.
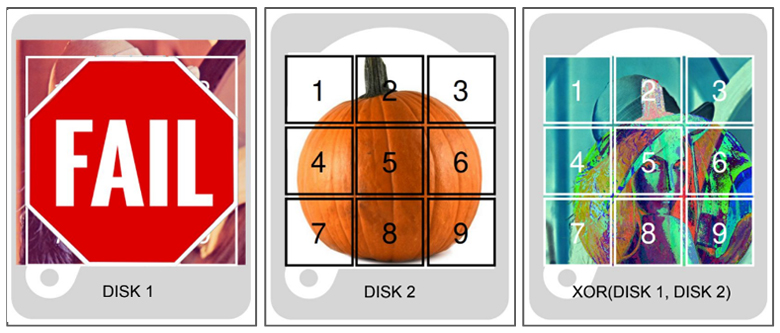
Технически, при отказе одного из дисков вы можете с помощью диска-2 и диска-3 получить содержимое диска-1.
Питание
Но и тут есть очень неприятная ситуация. При потере питания данные чётности и основные данные могут отличаться. В худшем случае вы вместо данных с первого диска получите, например, мою фотографию. Всякое бывает.

У этой проблемы есть отдельное название — RAID write hole. К сожалению, большинство реализаций RAID (даже софтварных) подвержено этой проблеме в дефолтных настройках.
Также нельзя забывать про наших любимых друзей — частицы из космоса, которые могут прилететь очень удачно в конкретную ячейку памяти и произвести в ней bit flip, то есть инвертирование значения вашего бита.
Два реальных примера. Вы проходите спид ран какой-то игры и подпрыгнули не на метр, а на десять — теперь вас никто никогда не обгонит.
Второй кейс: проходят выборы, bit flip, изменение чисел и кандидату достается плюс миллион голосов.
С этим, конечно, тоже можно бороться. В классическом Unix Way, где есть слои, мы добавляем ещё один слой, который начинает делать что-то ещё. Например, он считает хэши от данных. Но он должен обеспечивать те же самые гарантии, что и все остальные слои. Вы хотите атомарность, синхронность, что-то ещё, каждый слой должен это поддерживать.
Что даёт ZFS
Да, ZFS тоже считает хэш-суммы. Это один из наиболее простых вариантов проверить целостность. Есть результат расчета хеш суммы данных с ранее записанной хеш суммой, но дальше происходит хитрая штука.

Мы не только хешируем блоки с данными, мы считаем хэши от самих хэшей! И в итоге у нас есть самый главный хэш, который пишется рядом с убер-блоком, который и представляет собой состояние всего пула. Имея всего одну строчку, мы всегда знаем состояние вообще всего в системе. При наличии той самой избыточности, о которой мы говорили ранее, у нас получается ситуация, когда мы всегда знаем, какая из копий верна.
Если что-то не так пошло с данными, мы всегда явно об этом узнаем, а, при наличии избыточности, мы можем провести и self-healing, то есть полечить данные автоматически. Вы как администратор узнаете об этом не в 3 утра из звонка о вставшем проде, а из статистики как факт починки. Также ничто не мешает проверить данные и вручную с помощью ZFS Scrub.
Вся схема с круговым хешированием называется Merkle Tree.
Merkle Tree используется и в git’е. То есть хэш любого коммита в git’е является подобием Merkle Tree. Он всегда использует предыдущий хэш предыдущего коммита для своего вычисления. И тут я считаю, что ZFS – это git в мире файловых систем. Такой же подход часто используют и в блокчейнах.

Здесь аналогии не заканчиваются. В ZFS есть аналог git commit. Он называется transaction group. Мы так же, как в git’e, группируем записи в одно единое. У нас получается последовательная атомарная запись. Технически это тоже транзакция. Мы можем сделать revert, как и в git’е, и нам не нужен журнал.
Также есть аналоги git-хуков. То есть операции, которые вы можете дополнительно произвести над данными при записи. Например, сжать данные. Git за вас это сделает, как и ZFS, по умолчанию. Вы можете посчитать контрольные суммы, сделать нативное шифрование данных, дедуплицировать их. Даже имплементировать и сделать что-то новое — это открытый продукт.
По сути, у нас происходит батчинг (группировка) записи. Мы превращаем любую рандомную запись в последовательную. Не важно, что и где изменяли, мы последовательно запишем это на диск. Но в этом есть и минус. При превращении рандомной записи в последовательную мы и чтение часто превращаем в рандомное. В ZFS любое чтение примерно рандомное, к сожалению.
Теперь давайте рассмотрим вопрос, как при всем функционале нам выдерживать производительность? Нам нужно как-то её поддерживать на нужном уровне.
Функционал + производительность
Copy on write это дорого. Появляется очень много метаданных. Но с ними можно жить. Во-первых, в отличие от других операционных файловых систем, в которых размер блока 4 или 8 килобайт, то есть весьма маленький, у нас дефолтный размер блока — целых 128 килобайт! С одной стороны, он может показаться весьма большим, но по задержкам не так уж плохо. Плюс вы можете сэкономить на размере метаданных, эффективнее сжимать эти данные и метаданные. Они потрясающе жмутся. А по дефолту в ZFS они жмутся с помощью очень быстрого LZ4.
Также нельзя забывать и про проблему с фрагментацией.

В классических файловых системах мы решаем это двумя путями.
При аллокации данных. Например, мы выделили пространство заранее, но это приводит к тем самым проблемам с атомарностью. Мы же растём, у нас база данных увеличивается, этот подход не будет работать вечно.
Второй подход, который доступен в Microsoft Windows, в NTFS — можно дефрагментировать данные. Но проблема с дефрагментацией в том, что если у вас есть фоновый процесс, на который вы завязаны по производительности, то когда-то он может очень больно выстрелить, и ваша дефрагментация просто никогда не закончится.
И тут не только ZFS, но и большинство других файловых систем в том же Linux, не занимаются дефрагментацией, то есть фрагментация — это данность, с которой надо жить. Мы можем её как-то обходить, но всё равно от этого никуда не денемся. В случае с ZFS у нас всегда всё плохо. У нас copy on write, и по-другому мы не работаем. Но, честно говоря, зебра должна быть полосатой, на то она и зебра. Потому что наш худший случай — это дефолтный случай, и мы всегда учитываем наши проблемы.
К тому же на запись можно оптимизироваться. Мы группируем запись в рамках TXG, и весь рандом в рамках ограниченного времени может происходить только в оперативной памяти, не сбрасываясь постоянно на диск.
Фрагментация
Но самая большая проблема возникает на чтении. И не только в ZFS, а вообще во всех файловых и операционных системах. Есть ещё один слой — memory cache, через который проходит вообще всё чтение (по дефолту).
В Linux используется pagecache. У него least recently used (LRU) подход. Есть список во главе которого наиболее свежие данные по доступу, а в конце — самые старые кандидаты на вытеснение. Проблема в том, что когда вы, например, делаете бэкап, а он размером больше, чем ваш кэш, вы данные из кэша можете эффективно вымыть (т.е. вытеснить). А у вас была рабочая база, вы хотели рабочие данные, вроде они были горячими. С этой проблемой можно бороться, но принципиально она у LRU кэша существует всё равно.
В ZFS проблема рандомного чтения есть всегда. По этой причине нам нужно что-то более хитрое. На самом деле в ZFS своя реализация кэша. Там есть не только least recently used подход. Там ещё используется и most frequently used (MFU) подход.
MFU основывается на отдельном списке, который мы сортируем по частоте. Самые часто используемые данные у нас всегда будут самыми главными и горячими. И эффективность MFU кеша значительно выше чем LRU. Можете мне не верить! Ниже есть статистика с моего ноутбука за несколько недель. Целых 94% попаданий в MFU кэш!

Да, реализация ZFS'ного кэша может быть в какой-то мере медленнее, но за счёт большего количества попаданий мы всё равно здесь выигрываем.
Часто, когда говорят про чтение, забывают вопрос prefetch’а (предвыборки) данных.
Как мы обычно работаем с данными? Читаем какой-то байтик, потом следующий и так далее. Вроде чтение последовательное, но, к сожалению, любая дополнительная операция доступа для нас что-то стоит. Например, те же самые syscall’ы. Чтобы каждый не реализовывал предвыборку данных, большинство файловых систем, как и ZFS, делает prefetch данных. Они за вас заранее выгружают эти данные в in-memory кэш. И для ZFS prefetch очень важен. Просто статистика: если вы работаете побайтово, то вы работаете ровно в 1 000 раз медленнее, чем покилобайтово!

Также ZFS позволяет выгружать ваш кэш и на NVME диск. У вас кончились слоты оперативной памяти? Доставайте NVME, можете пользоваться ими. Если ваши данные сжимаемые, никто вам не мешает (и ZFS это поддерживает) держать их сжатыми и в ОЗУ.
Если ваши данные сжимаются в три раза, то у вас получится виртуально х3 памяти на кэш! И это прекрасно.
Сжатие
А как вообще совместимы оперативная память и сжатие? Одно быстрое, другое медленное. И тут нам на помощь приходят очень эффективные, быстрые современные алгоритмы сжатия.

Давайте рассмотрим LZ4. Он на один поток сжатия работает на скорости больше 800 мегабайт в секунду в среднем, а на разжатие – больше, чем 4,5 гигабайта в секунду. Это всего лишь в несколько раз медленнее, чем базовая операция MEMCPY!
Вы можете использовать ZSTD от того же автора. Он будет более медленный, но более эффективный.
Есть ещё отдельный интересный кейс. Если наши данные сжимаемые, мы заплатим эту стоимость в виде нагрузки на CPU, и это будет выгодно. Так как IO доступ до дисков всё ещё происходит за огромное количество циклов вашего процессора. А если данные не сжимаемые, что нам прыгать и постоянно переключать сжатие ВКЛ/ВЫКЛ?
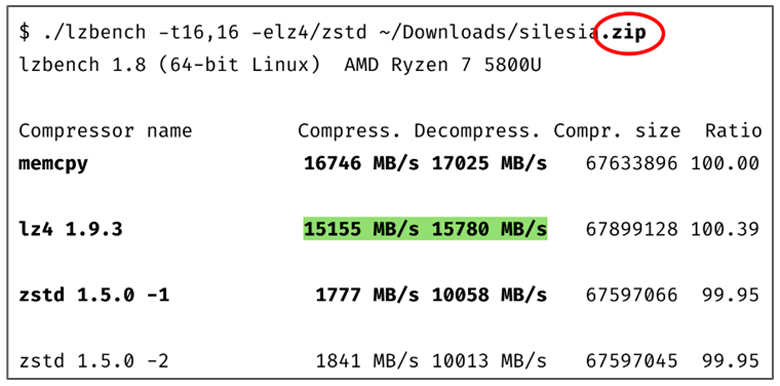
Спешу вас обрадовать. LZ4 содержит эвристику и на этот случай. Он такие данные будет просто пропускать. Стоимость LZ4 примерно равна MEMCPY в данном кейсе. Это очень классно. ZSTD тоже пытается здесь оптимизироваться, но не настолько выигрышно. Так что я немного соболезную пользователям BTRFS. Они внедрили ZSTD и посчитали, что этого хватит. Но как дефолт ZSTD всё-таки медленнее.
Конечно, мы можем реализовать это в классическом стеке, но это будет ещё один слой.

Когда я считаю количество слоёв, и что мне надо будет делать, чтобы это администрировать, либо просто у себя поднять локально, получается очень много действий и потеря производительности, потому что у вас очень много чего повторяется.
Мы можем говорить про функционал ещё очень долго, но вернёмся к истории и тем, кто её творит — людям.
Комьюнити
Мы остановились на том, что в 2013 году образовалась организация OpenZFS, которая основывалась на последней доступной кодовой базе openSolaris. Через 5 лет наиболее активным форком оказался проект ZFSonLinux, и мы объединились под его единой кодовой базой, переименовавшись в OpenZFS.
И всё дошло до того, что мы из этой же кодовой базы сейчас можем собирать модуль ZFS и для FreeBSD. Таким образом мы получаем абсолютно тот же функционал уже на двух операционных системах.
На очереди и другие форки. Они тоже могут влиться в апстрим. Получается OpenZFS — это претендент на наиболее кроссплатформенную файловую систему с идентичным функционалом на разных ОС, собираемую из единой кодовой базы. Но организация OpenZFS, в первую очередь, создавалась для объединения разных форков. Конечно, мы можем добавлять функциональность и будет версия не v5, а v6, например. Но когда у нас очень много форков, мы хотим как-то поддерживать их в виде одной совместимой файловой системы. По этой причине были придуманы feature flags (флаги функциональности). Вы разработали новую фишку и навесили feature flag. Если он не поддерживается в другом форке, вы создаете пул без этого флага, и становитесь на 100% совместимы. На выходе — рабочая кроссплатформенность.

К сожалению в Linux, ZFS все еще не «не из коробки», потому что у нас лицензии не совсем совместимые с ядром. Но, честно говоря, я считаю, что это даже хорошо. Мы не завязаны на цикле разработки ядра, можем жить отдельно, решать наши проблемы и придумывать что-то новое. Плюс тут есть очень интересные сайд эффекты. Например, мы можем поддерживать весьма старые ядра. Вам не нужно иметь bleeding edge ядро и как-то гнаться здесь за функционалом. Вы просто загружаете нужные модули ядра и получаете весь новый функционал.
То, что не в дефолте, не значит, что оно далеко. В большинстве дистрибутивов вы можете просто набрать apt install или аналог, и ZFS у вас будет. Плюс во многих дистрибутивах оно уже позволяет ставить систему на рутовый раздел с ZFS. И в том же FreeBSD это одна из дефолтных файловых систем.
Уже есть форк и для MS Windows! В ближайших перспективах он также будет залит в единую кодовую базу. И когда-то, если мне понадобится MS Windows, я поставлю его именно на ZFS :)
Итоги
В наше комьюнитки входят не только компании, чей бизнес основан на ZFS, но и просто инициативные люди. Они состоят не только в этом комьюнити. Вы можете встретить их и в комьюнити Linux kernel, FreeBSD, Lustre FS, проекте systemd и многих других. Да, эта файловая система написана на С. Нам же нужен перфоманс и модуль ядра. Но вокруг Сишного ядра кода всегда очень много обвязки. Те же самые тесты написаны на чём-то другом, фреймворки, утилиты (*sh, python). В конечном счёте есть документация, которая, конечно, не содержит Си. И тут я, как мейнтейнер документации, с удовольствием посаппорчу, если вы захотите в этом поучаствовать. Документация позволяет проникнуться духом комьюнити!
Надеюсь, мне удалось показать вам, что в не-дефолтных вещах можно делать много всего интересного, и результат получится сильно проще во многих смыслах. Да, к сожалению, серебряной пули все еще нет, но из-за этого только интереснее экспериментировать!
Буду рад вашим комментариям. Связаться со мной можно в Телеграме gmelikov. Еще ссылки на русскоязычные стораджевые комьюнити в телеграме t.me/ru_zfs и t.me/sds_ru.
Комментарии (59)


ivankudryavtsev
30.10.2023 11:01+1Но самая большая беда — это отказ. В случае отказа этой железки, а железо когда-то всё равно сдохнет, вам придётся не просто найти аналог, а найти именно ТУ САМУЮ железку с ТОЙ САМОЙ прошивкой. У другой железки будет другая логика построения RAID, и у вас просто не сойдется массив, так как железка не будет знать, как его собрать.
Это мягко говоря неправда, например, вся линейка LSI вперед совместима нормально, Adaptec тоже. Я даже заводил R1 на Adaptec от LSI (Broadcom), хотя это галиматья. Просто держите в зип относительно новый Broadcom и будет вам счастье. Само собой куча всякого экзотического железа типа Nytro или Areca.
Проблемы несколько иные: факт, что массивы на hw raid требуют очень надежных и именно серверных дисков и тем не менее разваливаются куда чаще. А, например, RAID HPE может не принять в рейд диск другой серии или большего размера легко.
У zfs плюсов много, но, например, я никогда не поставлю zfs вместо mdamd + lvm + ext4 для томов VM, ну просто потому, что это нафиг не надо.

fshp
30.10.2023 11:01Что используется в качестве загрузчика у вас на ноутбуке?
У меня было на примете 3 варианта:
1) Ядро и initramfs лежат на ESP, что ужасно, т.к. fat32.
2) ZFSBootMenu, который так же лежит в ESP на fat32, но уже ядро может лежать на ZFS. Меня смущает тут kexec, т.к. могут быть проблемы с оборудованием.
3) EFI драйвера https://efi.akeo.ie/. К сожалению я так и не смог с помощью них увидеть ZFS в efi shell. Но на мой взгляд это лучший вариант. На ESP будет лежать только драйвер.

gmelikov Автор
30.10.2023 11:01+1Я использую консервативный grub2 и ESP , примерно аналогичный гайду https://openzfs.github.io/openzfs-docs/Getting Started/Debian/Debian Bookworm Root on ZFS.html . Grub имеет ограниченный readonly zfs драйвер, который вычитывает ядро с отдельного BOOT пула (чтобы уменьшить на нём количество активных feature flags).

khajiit
30.10.2023 11:01Да вроде №1 не так уж и страшен:
❯ ls -l /boot/esp/EFI/Linux total 65M -rwxr-xr-x 1 root root 32M июл 28 12:13 6.4.8.zen1-1-linux-zen_BACK.efi -rwxr-xr-x 1 root root 33M сен 27 16:11 6.5.9.zen2-1-linux-zen.efiСкрипты mkinitcpio сохраняют одно предыдущее ядро, размер uki небольшой — даже в дефолтные виндовые 100МБ влезет.
Проверку целостности файла можно возложить на secureboot (или дублировать на зеркало).fshp
30.10.2023 11:01У меня сейчас как раз uki, правда без initramfs, самосборный. Несколько мегабайт весит. Тут задача не практическая, а скорее развлекательного характера.


quartz64
30.10.2023 11:01+4Я сам очень люблю ZFS, но мне кажется, что странных утверждений в статьях стоит избегать.
Дальше можно говорить про производительность, потому что мы не хотим, чтобы эта железка стоила как сам сервер или еще дороже. Соответственно, оборудование в ней будет стоять более дешёвое. Например, ARM.
Производительность актуальных сейчас контроллеров Broadcom и Adaptec в 99% случаев упирается не в процессор контроллера, а в PCIe или диски (если это, конечно, не несколько NVMe).
Можно компенсировать это наличием батарейки, которая позволит нам кешировать синхронную запись.
Та самая батарейка, которую мы вставляли для увеличения производительности, в случае отказа даст дикую деградацию производительностиWrite back — это не «кэширование синхронной записи». Для системы RAID-контроллер презентует свои тома в виде блочных устройств. Система может писать туда синхронно, и с Write Back контроллер будет подтверждать запись блока сразу после помещения его в кэш, в отличие от Write Through (поместили в кэш, но дождались записи на диски).
Защита кэша при аварийном отключении питания уже давно не основана на продолжительном питании от литиевой батареи — вместо этого используются ионисторы, питающие модуль лишь на время, необходимое для копирования содержимого DRAM на флеш. Модули защиты с ионисторами тоже попадают в гарантию, но там AFR порядка 0,1% и связан с браком, выходом из строя других компонентов, а не с деградацией ионисторов. Первые модули (ZMCP у Adaptec, CV у LSI/Broadcom) работают уже больше 10 лет, там давно уже сами серверы морально устарели.
Прирост производительности WB дает только на медленных дисках, т.е. HDD. На томах из SSD (во всяком случае на нескольких последних поколениях Broadcom и Adaptec) будет быстрее Write Through.
найти именно ТУ САМУЮ железку с ТОЙ САМОЙ прошивкой
Не угадали. Про это уже писали.
для этого нам требуется целый набор утилит для каждого слоя
Для ZFS не нужно иметь дело со smartctl и nvme-cli?
С этим, конечно, тоже можно бороться. В классическом Unix Way, где есть слои, мы добавляем ещё один слой, который начинает делать что-то ещё.
dm_integrity надо использовать поверх накопителей, а не поверх md/LVM, иначе в нем никакого смысла нет.
gmelikov Автор
30.10.2023 11:01+1Спасибо за фидбек!
Производительность актуальных сейчас контроллеров
Прирост производительности WB дает только на медленных дисках, т.е. HDD
Всё верно, вы отлично подсвечиваете нюансы. Оригинальный доклад, как и этот обзор, я целил как общий обзор среднестатистических хранилищ на не только свежем железе, и секция про железо претендует на отдельную статью. Кейс с максимально производительным аппаратным стораджем - один из возможных.
Для ZFS не нужно иметь дело со smartctl и nvme-cli?
Кстати, сейчас появилась удобная возможность использовать
zpool statusс флагом-с, напримерzpool status -c smartподмешает информацию по smart устройства. Также есть zed агент, который умеет оповещать о проблемах с носителями пула.
olegkrutov
30.10.2023 11:01Вот только zed агент крашится, если минимум один из критических vdev любого zpool недоступен при импорте на старте системы. После этого zpools, даже живые, неюзабельны, там что-то ещё ломается. Это грустно, поэтому пришлось писать свой импортёр на питоне, чтобы анализировать vdev и не импортировать пулы, которые такое вызовут.
gmelikov Автор
30.10.2023 11:01Заводили тикет? Плюс полгода назад я правил его systemd сервис, он сейчас должен рестартиться автоматически, т.е. в вашем кейсе сейчас хоть и через авторестарт, но проблема должна была решиться.
khajiit
30.10.2023 11:01+1state: DEGRADED status: One or more devices could not be used because the label is missing or invalid. Sufficient replicas exist for the pool to continue functioning in a degraded state. action: Replace the device using 'zpool replace'. see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-4J scan: resilvered 27.7G in 00:04:28 with 0 errors on Mon Oct 23 22:51:07 2023 config: NAME STATE READ WRITE CKSUM health temp nvme_err ata_err realloc rep_ucor cmd_to pend_sec off_ucor warmsands DEGRADED 0 0 0 mirror-0 DEGRADED 0 0 0 nvme-INTEL_SSDPEKNU010TZ_PHKA121304MD1P0B-part2 ONLINE 0 0 0 PASSED 35 0 - - - - - - 4460342986653721468 UNAVAIL 0 0 0 was /dev/disk/by-id/usb-Realtek_RTL9210_NVME_012345678907-0:0-part2 - - - - - - - - - errors: No known data errorsЭто просто песня )


outlingo
30.10.2023 11:01+3В использовании MDADM на текущий момент необходимости нет - соответствующие функции также реализованы в LVM (lvcreate --type mirror -m 1 ...). Оно оставлено скорей для тех, кому идеологические причины не позволяют использовать LVM.
DM-integrity также уже штатно используется в LVM (lvcreate --raidintegrity y ...)
А что про ZFS - то оно, конечно, интересный продукт - но не для случаев, когда надо "зубами выгрызать" каждый десяток микросекунд в латенси.

sdy
30.10.2023 11:01Многие считают, что для ZFS нужна обязательно память с ECC. Поэтому, они применяют системы с поддержкой ECC, а это процы с контроллером памяти ECC, материнки и плашки памяти специальные.
Также в некоторых чипах LPDDR4,5 появилась возможность внутреннего аппаратного контроля ECC, что избавляет от необходимости разводки дополнительных чипов памяти и применения процессоров с поддержкой ECC. Получается, что с применением таких чипов памяти как LPDDR4,5, оснастить ECC можно будет любую систему, даже ту, в которой контроллер памяти проца не поддерживает ECC.
Насколько это вообще важно чтобы система, на которой устанавливается ZFS, поддерживала аппаратный контроль ECC?

RNZ
30.10.2023 11:01Распространение ОЗУ без ECC и является недоразумением. В ОЗУ должен быть ECC.
sdy
30.10.2023 11:01Причем здесь недоразумение, существуют системы с избыточностью и без. Вопрос был насколько реально нужна избыточность для ZFS. В чем выигрыш при установке ZFS на систему с избыточностью в плане кодирования?

blind_oracle
30.10.2023 11:01+2Встроенный ECC в DDR5 не равноценен обычному ECC - он не end2end и данные всё ещё могут побиться вне чипа памяти, по пути в процессор и т.п.
sdy
30.10.2023 11:01данные и на кристалле могут побиться. На мой взгляд, вероятности ошибок на плате и на кристалле одного порядка при условии, что плата разведена соответствующим образом. Так что это не панацея.
blind_oracle
30.10.2023 11:01Все кеши в процессоре тоже покрыты ECC, так что полноценный ECC в RAM с 72-бит шиной между модулем и процом даёт неплохую защиту от повреждений (ну, или по крайней мере детектирует их).
sdy
30.10.2023 11:01Это все таки разные уровни хранения данных, для которых ECC считаются отдельно.
blind_oracle
30.10.2023 11:01+1Это не важно. При обнаружении ошибки в кеше уровня N данные просто копируются с уровня N+1. Верхний уровень кеша CPU в этом случае скопирует данные из RAM - если она ECC, то получается полное e2e покрытие от RAM до регистров.
gmelikov Автор
30.10.2023 11:01+1Насколько это вообще важно чтобы система, на которой устанавливается ZFS, поддерживала аппаратный контроль ECC?
Не важнее, чем для любой другой ФС. Более того, ZFS во многих случаях сможет явно сказать о проблемах сильно раньше потери данных и пула. Я когда-то развлекался с разгоном ОЗУ, приводил данные к корраптам, после сброса настроек ОЗУ к дефолту данные просто восстановил реинсталлом пакетов, этот пул до сих пор жив и используется :)
sdy
30.10.2023 11:01получается, что ECC дает лишь небольшой выигрыш, но так или иначе, ничего абсолютного не произойдет, если система будет без аппаратного ECC
blind_oracle
30.10.2023 11:01+1Произойдёт.
Данные могут побиться в процессе записи из памяти на диск и никакой ZFS от этого не спасёт - контрольные суммы будут посчитаны уже для битых данных.
Поэтому ECC как по мне - это must-have для любой системы, где важна хоть какая-то надёжности и сохранность данных. Тем более что цена сейчас на такие модули практически равна обычным, а всякие AMD десктопные поддерживают ECC.
sdy
30.10.2023 11:01На практике только одиночные ошибки исправляются (в большишнстве случаев), и абсолютной надежности и сохранности все равно не будет. Так что для определенных задач может ECC аппаратный не так и нужен будет, а для других более ответственных задач и существующих аппаратных способов защиты не хватит.
Было бы здорово все таки понять где та грань когда реально нужна аппаратная поддержка ECC, а когда нет. Опять же, где та грань между встроенными механизмами ECC у LPDDR и внешними схемами с дополнительной памятью.
Пока что видится, что реальных аргументов нужна ли аппаратная поддержка ECC или не нужна, так и нет. Одни слова.
blind_oracle
30.10.2023 11:01+1Есть официальный документ: https://openzfs.github.io/openzfs-docs/Project and Community/FAQ.html#do-i-have-to-use-ecc-memory-for-zfs
Я бы на него ориентировался. Ну и опять же - как по мне экономить копейки на ECC смысла нет. Лучше с ним, чем без.
gmelikov Автор
30.10.2023 11:01+1Я как мейнтейнер этой доки подсвечу продолжение оттуда: "For
home users the additional safety brought by ECC memory might not justify
the cost".
Если ECC есть - хорошо, если нет - ситуация не хуже чем для любой другой ФС. Для "enterprise environments" для любой инсталляции и ФС рекомендуется ECC.sdy
30.10.2023 11:01Другими словами, для домашнего применения можно и без ECC. Думаю, что вполне разумный подход и достаточно четкое деление.
blind_oracle
30.10.2023 11:01Я бы не делил на домашние и не-домашние. Просто зависит от того, ценны ли тебе твои данные или ты допускаешь что в каком-то из тысяч JPEG-ов домашней коллекции у тебя что-то побьётся (что, в принципе, не страшно).
У меня было довольно прилично случаев, когда какие-то старые фотки (10-15 лет) уже не открывались после нескольких миграций между разными хранилищами. Или имели много артефактов (видно, например, только половину). Иногда может побиться что-то важное.
Поэтому для своих NAS я выбрал ZFS+ECC и при миграции на новый делаю проверки контрольных сумм.
sdy
30.10.2023 11:01Во, спасибо за наводку, то что искал. Насчёт копейки тут не совсем так. Это вопрос не только железа, но и времени на проектирование и целесообразности использования существующих разработок. Особенно актуально для всякого рода мобильных систем
blind_oracle
30.10.2023 11:01Ну я даже не знаю что там проектировать. Если есть возможность - ставишь ECC. Если нет - ну, значит нет.
Можно ещё вот почитать: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/35162.pdf
About a third of all machines in the fleet experience at least one memory error per year (see column CE Incid. %) and the average number of correctable errors per year is over 22,000.
Так что это не редкие явления, при этом сильно зависит от оборудования судя по всему.

nagual2
30.10.2023 11:01При переразгоне как правило комп уходит в ребут не успев ничего записать на винт, а вот автор англоязычной стать потерявший данные из-за глючной памяти, которая вспоминала часто не то и не так как записывалось, очень горько плакал над своими потерянными данными, в его случае менялись иногда отдельные биты данных и происходило это не часто, что привело к порче метаданных у его ZFS. Так что установка zfs на ноутбук это всё ещё рисковое мероприятие, хотя если это ryzen там можно включить сквозное шифрование памяти и любая ошибка приведет к тому что данные не расшифруются, что если произойдёт, то будет замечено сразу...
blind_oracle
30.10.2023 11:01А, кстати, есть уверенность что при шифровании памяти используется какой-либо HMAC для проверки целостности? Я не изучал, но не уверен в этом... а без него ошибок расшифровки не поймать.

Hixon10
30.10.2023 11:01Меня зовут Георгий Меликов, я работаю в VK Cloud, являюсь руководителем направления IaaS разработки. Мы занимаемся не только хранилищами, но и программными сетями. Но так как у нас в проде ещё нет ZFS, то я пишу в качестве контрибьютора проекта OpenZFS.
Спасибо за статью. Есть ли у вас уже предположения, для каких нагрузок вы могли бы использовать OpenZFS в VK? Так кажется, что большинство современных БД (sql/очереди/s3) делают много аналогичных вещей - также считают чексуммы данных, пишут WAL, делают репликацию данных и тд. Выглядит так, что используя вместе с ними OpenZFS мы будем часто делать операции дважды.
Я слышал, что люди используют OpenZFS для тестовых стендов вместе с PostgreSQL, чтобы за счет COW получить за бесплатно идентичные базы данных. Есть ли какие-то еще интересные места для использования данной FS?
gmelikov Автор
30.10.2023 11:01+2Если говорить про использование внутри облаков -то вот интересный кейс https://www.youtube.com/watch?v=fqQ95LlwOGg&list=PLaUVvul17xSdUK50FR3zXkGLa7hxzKIgA&index=8 https://docs.google.com/presentation/d/1fZcVvGNtG5V4JyKG7IlpzZR37YtZdI0-/edit#slide=id.p1
А если говорить про использование поверх облаков внутри виртуалок (кроме перечисленного вами) - есть много интересных кейсов, например в mailing lists openzfs видел как кто-то zfs юзает для сжатия поверх локальных дисков. Вообще ZFS под базами имеет смысл, если важнее оказывается итоговый объём, а не выжимание последних iops (такой кейс знаю у крупных игроков на российском рынке).

13werwolf13
30.10.2023 11:01если бы у btrfs существовал аналог zvol я бы про zfs забыл навсегда..
в теле статьи говорится что без zfs для многотомных требуется много уровней абстракции (причём не понятно почему на пикче lvm находится под mdadm а не над ним), но сама zfs тоже предлагает "лишнюю" абстракцию ввиде zdev без которой btrfs и bcachefs обходятся но делают всё то же самое (и даже гибче, в zfs ты не можешь поменять raid10 на raidнапример6 без дополнительных дисков, а в btrfs можешь).

mpa4b
30.10.2023 11:01И ещё бы шифрование в btrfs и устойчивость к битфлипам. Последний раз когда тестил raid5/6 в btrfs, оно портило и не восстанавливало все данные, openzfs восстанавливало всё целиком даже если один из трёх дисков в raidz1 (raid5 по-zfs'ски) полностью перезаписать из /dev/urandom.

RNZ
Чётка FS, но с ZVOL проблемы (под Linux) и давно...
SergiusR12
А какие с Zvol проблемы, напишите плиз? Интересно.
RNZ
https://habr.com/ru/companies/vk/articles/770300/#comment_26108856
khajiit
Тоже интересно, потому как ни на виртуалках через qemu/kvm, ни с lio, ни даже с кроссдедупликацией экспортированного через lio ntfs-тома и обычного zfs dataset никаких проблем, не говоря уже про проблемы-проблемы, выявлено не было.
RNZ
https://habr.com/ru/companies/vk/articles/770300/#comment_26108856
khajiit
0.7 давно устарела, проблему надо проверять на свежих версиях. Увеличение vm.min_free_kbytes решало на 0.x.x большую часть проблем с подвисанием при интенсивном io, по крайней мере, для каджита.
Swap внутри zvol не работает, как ожидается, да.
gmelikov Автор
А есть информация о проблемах? Будем рады тикетам https://github.com/openzfs/zfs/issues !
ZVOL от dataset некоторое время отличался производительностью на большом количестве потоков, но в релиз v2.2 вошло не малое количество патчей как раз об улучшении его перформанса. Известных багов не помню.
vazir
Была какая то бага что приводила к дедлоку если сделать swap на ZFS. Не знаете починили или все еще кейс?
https://openzfs.github.io/openzfs-docs/Project and Community/FAQ.html#using-a-zvol-for-a-swap-device-on-linux
gmelikov Автор
По вашей ссылке есть тикет, куда стоит прикреплять проблемы со SWAP https://github.com/openzfs/zfs/issues/7734 , пока рекомендация не изменилась, дедлоки всё ещё возможны.
RNZ
https://github.com/openzfs/zfs/issues/9172 - и эта проблема и похожие - закрыты автоматически за неактивностью, а не по исправлению. Это как сказал один из пользователей github:
it's like sweeping dirt under the carpet(https://github.com/openzfs/zfs/issues/9693#issuecomment-882027592)gmelikov Автор
Увы без репродьюсера на свежей версии часто очень сложно отдебажить проблему, stalebot как раз призывает авторов тикетов подтвердить актуальность. Плюс никто не против переоткрыть тикет при репродьюсе.
RNZ
Насчёт производительности, если вот эти проблемы решены:
https://github.com/openzfs/zfs/issues/14346
https://coda.io/@ff0/zvol-performance-issues
https://github.com/openzfs/zfs/issues/11933
, то гуд, если нет, то ждёмс...
gmelikov Автор
https://github.com/openzfs/zfs/issues/14346 речь вроде не о ZVOL, плюс там явно указано про проблему с SMR дисками, что относително ожидаемо
https://github.com/openzfs/zfs/issues/11933 тут в конце накидано ссылок на патчи по теме, автор тикета не отписался об их проверке
RNZ
Есть ещё интересные фокусы с zvol, видел как iostat кажет на группе nvme накопителей загрузку около 1%, а на /dev/zd0 (raidz на эти самые nvme накопители, сам volume выставлен FC target'ом на другой хост) - 100% и скорость записи втрое ниже чем на Solaris с HDD (ZStorage). Но насколько актуальны эти фокусы, относительно версии драйвера и ядра linux, не уточню - не я производил сетап хоста и не я эксплуатирую.