

Привет! Меня зовут Игорь Латкин, я сооснователь и системный архитектор в KTS. Сегодня расскажу про Grafana Mimir — одно из хранилищ данных для системы мониторинга Prometheus.
Что будет в статье:
Откуда взялся Mimir
Это сравнительно молодой проект, запущенный в прошлом году. Mimir входит в экосистему Grafana, которая, уверен, знакома многим пользователям. Решение основано на Cortex — это проект, которым пользовалась и который развивала Grafana до запуска собственной системы.
Grafana Mimir — удаленное хранилище данных для Prometheus, аналогичное Victoria Metrics, Thanos и вышеупомянутому Cortex. В качестве источников данных Mimir может использовать Prometheus, Grafana Agent, OpenMetrics, InfluxDB, Datadog и другие. Использовать то, что напушили в Grafana Mimir, можно очевидными способами: просматривать метрики в Grafana, формировать алерты с помощью алерт-менеджера и других алертингов и использовать такие инструменты Grafana Cloud, как Grafana Machine Learning и Reporting.
На мой взгляд, фишка Grafana Mimir именно в его новизне: сам Prometheus появился в 2016 году, примерно в одно время (в 2019) появились Victoria Metrics, Thanos и Cortex. Это значит, что весь опыт эксплуатации Prometheus, наработанный за это время, все требования к хранилищам данных легли в основу нового инструмента.
Если зайти на сайт Prometheus, там можно увидеть достаточно большой список удаленных хранилищ. Но на мой взгляд, самые популярные сегодня — это именно Thanos, Victoria Metrics, Mimir, Cortex.
Mimir, по сути, — финальный кусочек пазла в Grafana Observability Stack — это набор инструментов для просмотра метрик и работы со всем Observability. В него ещё входят:
Grafana Loki (управление просмотром, пушем и хранением логов)
Grafana Tempo (хранение трейсов и анализ трейсинга)
В нём не хватало компонента именно для хранения метрик, и теперь он появился, а вместе с ним у Grafana появилась возможность предоставлять полный спектр услуг по обзервабилити.
Архитектура
Архитектура Grafana Mimir очень похожа на Loki и Tempo, поэтому если у вас уже есть опыт с этими инструментами, Mimir будет вам понятен. Как и в любой системе хранения, в Mimir есть два основных пути данных:
на запись, когда мы пушим метрики
на чтение, когда мы эти метрики читаем.
Запись. Здесь у нас есть два основных компонента — distributor и ingester.
ingester — это stateful-компонент, который хранит метрики локально и постепенно пушит их в удалённое объектное хранилище. В качестве объектного хранилища может выступать любой S3-совместимый сервис. Так же как в Thanos, это может быть AWS, Google Cloud, MinIO.

Задача distributor — обеспечить высокую доступность. distributor получает метрики на вход и отправляет их в несколько ingester, и они сохраняются в объектном хранилище. Это позволяет уберечься от падения всех ingester: если что, хотя бы один точно запишет данные. Задача же компактора — периодически улучшать эффективность хранения данных и удалять старые метрики, согласно настройкам retention.
Чтение. Здесь все перекликается с Victoria Metrics и Thanos: есть основной компонент, который занимается исполнением запросов — это querier. Он взаимодействует с ingester и с object storage через store-gateway. Querier забирает метрики из объектного хранилища, а в ingester могут лежать те данные, которые ещё не записались в объектное хранилище. Querier все это соединяет.

Задача query frontend и query scheduler в том, чтобы пошардировать тяжелый запрос. Допустим, вы хотите вычислить какую-либо метрику с периодом один год. Ее можно посплитить, например, на интервалы по месяцу и отправить, в данном случае на 12 querier. Ваш запрос обработается примерно в 12 раз быстрее. Звучит утопично, но плюс-минус позволяет распределять нагрузку таким образом.
Способы запуска
Запустить Grafana Mimir можно тремя способами:
Монолитный режим. Мы сделали демку, в которой используется этот способ. В нём все компоненты Mimir запускаются в единственном процессе. Это позволяет очень просто запустить и эксплуатировать инструмент, что полезно, если у вас небольшой поток метрик. Все запросы на чтение и запись вы отправляете в этот один единственный инстанс и подключаете его к object storage. Grafana Mimir умеет работать без объектного хранилища, а без S3 использовать локальную файловую систему, но этот режим не поддерживается в более распределенных деплоях. Вы можете это использовать только в монолитном режиме — так же как и в Loki.
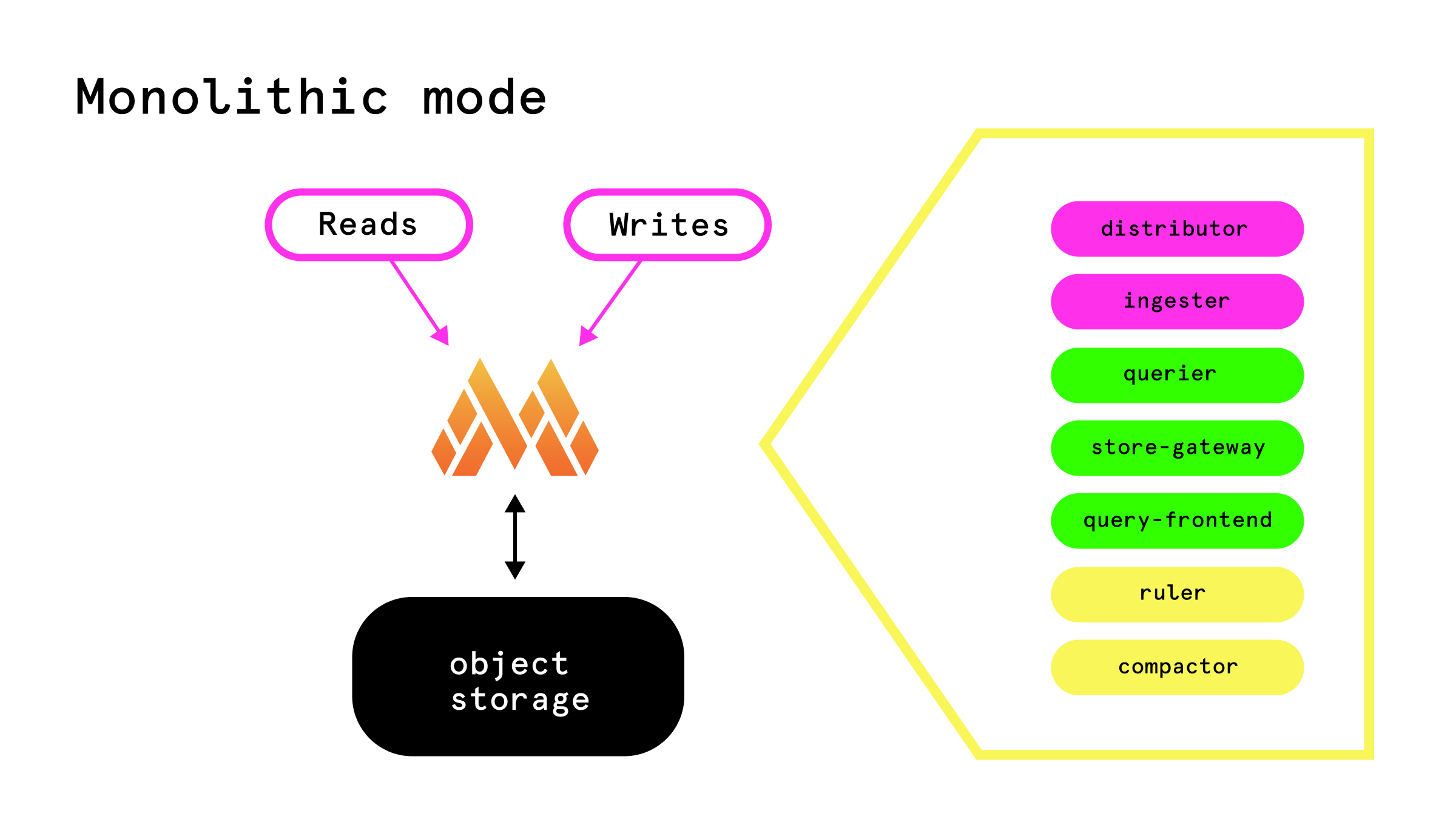
В этом режиме получается единая точка отказа: инстанс упал, метрик нет, они не пишутся и не читаются. Чтобы это поскейлить, мы можем запустить Grafana Mimir в нескольких репликах, поставить перед ними балансировщик, и все запросы на чтение на запись будут равномерно распределяться по всем инстансам. Тут важно подключить это все к одному объектному хранилищу. Все инстансы Grafana Mimir найдут друг друга: это нужно будет описать в конфиге, но, тем не менее, они будут знать о существовании друг друга и смогут взаимодействовать и организованно работать с одним объектным хранилищем.

Здесь возникает проблема: все запросы на чтение и запись идут равномерно по всему кластеру. К сожалению или к счастью, все профили нагрузки разные, и зачастую они неравномерные. Поэтому эти два пути хотелось бы разделить. В таком случае можно поставить мощные сервера на большой поток на запись, мощные сервера для хранения и обработки метрик, и отдельную группу серверов только для чтения. Если у вас есть такая необходимость — вам в следующий режим.
Микросервисный режим. В нём вы, по сути, запускаете каждый из компонентов — ingester, distributor, frontend query — независимо. У Mimir есть helm chart, которым это можно задеплоить в Kubernetes. Конечно, задеплоить это всё руками напрямую на виртуальных машинах тоже можно. Всё подключается к единому object storage. Мы достигли цели — разделили путь на запись и путь на чтение. Такой деплой — максимально гибкий, можно максимально гибко контролировать каждый из компонентов, требуемые и выделяемые ресурсы, количество реплик каждого ресурса и каждого сервиса. Из минусов — это тяжело эксплуатировать: нужно четко понимать, что делает каждый из компонентов и что каждому из них нужно.

Read-write режим. Здесь, наверное, первое отличие от Loki в плане архитектуры: в Loki read-write-режим уже production-ready и рекомендованный, здесь — только экспериментальный. По сути, Mimir может разделить все процессы на три вида: read, write и все остальное — бэкенд. И скейлитьwrite и read процессы можно независимо. В таком случае Grafana Mimir сам разберётся, который из них где запущен, если в нём будет запущен один или несколько query frontend. Всё это подключается к одному object storage. Такой деплой гораздо проще, по крайней мере, в Loki. Надеемся, что этот режим дойдет до продакшена, и про микросервисный режим можно будет забыть.

Расчёт ресурсов
Я был приятно удивлен тому, что у Mimir есть инструкция по подсчету мощностей. На мой взгляд, две самых сложных для оценки и одновременно самых важных:
ingester. Примерно 1 CPU, 2.5 GB RAM и 5 GB диска на 300 000 метрик в памятиquerier. 1 CPU на десять запросов в секунду
Это приближённые значения, и вам так или иначе придется наблюдать за кластером. Но от них можно отталкиваться.
Вывод
Thanos, Cortex, Victoria Metrics, Mimir — все эти инструменты очень похожи, и вопрос только в том, который из них больше подходит вам функционально, насколько легко его можно интегрировать в вашу инфраструктуру, эксплуатировать, сколько опыта у вашей команды. Например, если вы уже работаете с Loki и Tempo, попробовать Mimir логично. Конечно, прикрутить в эту связку можно и Victoria Metrics, но все-таки Grafana предлагает экосистему, которой имеет смысл пользоваться, если вы уже внедрили в работу ее отдельные элементы.
Что ещё почитать по Mimir:
Приходите учиться DevOps! Недавно мы открыли для всех желающих наш курс «Деплой приложений в Kubernetes». Это курс для разработчиков, где мы рассмотрим самые важные концепции, необходимые для взаимодействия с кластерами Kubernetes, и научим применять эти знания на практике.
???? Посмотреть подробнее, что будет в программе, можно на странице курса.
Другие статьи про DevOps для начинающих:
Другие статьи про DevOps для продолжающих:
Комментарии (5)

alecx
06.12.2023 10:34+2Mimir неплох, но имеет пару жирных минусов:
нет управления rules и alerts из CRD (только свое api)
довольно прожорливый на ресурсы
нет downsampling для исторических данных, а если попытаться сделать его на rules, то можно разориться s3
NavY
Grafana Agent - это одна сущность, запятая наверное лишняя.
igorcoding Автор
Да, спасибо, поправил
saboteur_kiev
Так victoria metrics и influx это одного поля ягоды.
Зачем нужен мимир, если можно просот использовать базу данных напрямую? Не совсем понял смысл
igorcoding Автор
Это так же, как в victoria metrics можно писать метриками инфлюкса или statsd. То есть ставим любимый инструмент, например, Victoria Metrics или Grafana Mimir и пишем в него разными способами (системы порой бывают разнородные, поэтому приятно иметь возможность интегрировать существующую инфру с новым инструментом мониторинга)