
пролог и ссылка на оригинал
Это перевод-адаптация https://renegadeotter.com/2023/09/10/death-by-a-thousand-microservices с вкраплениями моих собственных мыслей. Я не профессиональный переводчик, просто во многом согласен с изложенным.
Церковь Великой Сложности
Начнём со скетча, в котором инженер объясняет менеджеру проекта как сильно переусложнённый лабиринт микросервисов работает, чтобы получить дату рождения пользователя - и ему не удаётся. Эта сцена точно показывает абсурдность текущего состояния технической культуры. Мы смеёмся, но поднятие этой темы в серьёзном профессиональном разговоре равносильно профессиональной ереси, делающей вас практически непригодным к трудоустройству.
Как мы к этому пришли? Как мы стали вместо решения наших задач, тратить кучи денег на решение проблем, которых у нас нет?
Предупреждение
Автор не обвиняет JavaScript или NodeJS и не пытается сделать их источником всех проблем, как может показаться из первого абзаца статьи.
Идеальный шторм
Существует несколько событий в недавней истории, которые, возможно, внесли свой вклад в текущее положение вещей.
Во-первых, целая армия разработчиков пишущих на JavaScript для браузера начали самоидентифицировать себя как "фул-стек", погружаясь в серверную разработку и асинхронный код. Javascript он и в африке Javascript. так ведь?
Какая разница что вы создаёте - пользовательские интерфейсы, серверы, игры или встроенные системы? Правда? Node была всё ещё чем-то вроде учебного проекта одного человека и ранний JavaScript был глубоко проблемным выбором для серверной разработки. Указание на это всё ещё зелёным серверным разработчикам обычно приводило к большому нагреву и подгораниям. Это всё что они знали, в конце концов. Мир вне Node будто бы не существовал, путь Node был единственным путём и так это стало причиной упрямого догматического мышления, с которым мы имеем дело по сей день.
А затем непрерывный поток ветеранов FAANG начал объединятся с рекой стартапов, обучая новоприбывших и впечатлительных молодых сервер-сайд JavaScript инженеров. Апостолы Церкви Великой Сложности настойчиво твердили, что "то, как они делают вещи в Гугле" это неоспоримо и правильно - даже если это не имеет никакого смысла при нынешнем контексте и размере проекта. Что значит, что ты не хочешь отдельный User Preferences Service? Это просто не скейлится, братан!
Но легко обвинять ветеранов и новоприбывших во всём. Что происходило ещё? Ах да - лёгкие деньги.
Что вы делаете, когда вас залили инвестициями? Вы не гонитесь за прибылью, конечно же! Не раз я получал письмо от менеджеров, просящих всех быть в офисе, прибраться на столах и выглядеть занятыми, так как прогноз обещает облако инвесторов прямо там. Инвесторы должны увидеть взрывной рост, но не в прибыльности, нет. Они просто должны увидеть как быстро компания может нанять ультра-дорогих инженеров чтобы сделать... что-нибудь.
И вот у вас есть эти программисты, что вы будете с ними делать? Ну, они могли бы построить более простую систему, которую легче развивать и поддерживать, а могли бы и вообразить монструозное созвездие "микросервисов", которое никто реально не понимает.
Микросервисы - новый путь написания скейлящихся программ! Будем ли мы притворяться, что концепция "распределённых систем" никогда не существовала? (Давайте опустим все нюансы насчёт того, что микросервисы не являются реальной распределённой системой)
В давние времена, когда IT индустрия ещё не была таким раздутым фарсом, распределённые системы уважали, боялись и в целом избегали - оставляя лишь как оружие последней надежды для редких кривых задач. С распределёнными системами всё становится более сложно и времязатратно: разработка, отладка, развёртывание, тестирование, надёжность. Но я не знаю, может быть это теперь супер легко с новым туууулингом?
Нет стандартного набора инструментов для разработки основанной на микросервисах - нет общего фреймворка. Работа над распределёнными системами стала лишь незначительно проще в этом десятилетии. Докеры и контейнеры не убрали магически присущую распределённым системам сложность.
Я люблю ссылаться на этот обзор 5 лет аудита стартапов, так как он наполнен выводами со здравым смыслом:
... среди стартапов, которые мы исследовали, лучшие обычно при разработке почти нагло придерживались принципа 'Keep It Simple' . Усложнение ради усложнения жестко каралось. С другой стороны, компании, в которые мы заходили с возгласами "вау, эти парни чертовски умные" в основном исчезли.
В целом, серьёзные грабли на которые многие наступили - преждевременный переход на микросервисы, архитектуры, основанные на распределённых вычислениях или на посылке большого количества сообщений
Буквально - "сложность убивает".
Этот аудит раскрыл интересную закономерность - стартапы испытывали что-то типа коллективного синдрома самозванца, создавая прямолинейные, простые, производительные системы. Вне зависимости от задачи, не решать её с помощью микросервисов с первого дня выглядит чем-то неприемлемым.
"Все делают микросервисы, а у нас один Django монолит, поддерживаемый всего несколькими инженерами да инстанс MySQL - что мы делаем не так?". Ответ почти всегда - "ничего".
от автора перевода
Лично для меня микросервисы на Python звучат как оксюморон. Язык, скрипты на котором должны заканчиваться до того как программа становится "макро" и для неё начинают иметь смысл такие понятия как архитектура используют, чтобы писать микросервисы, которые имеют хоть какой-то смысл, когда проект уже далеко не маленький.
К тому же очень часто опытные инженеры испытывают нерешительность и недоумение в нынешнем IT, и хорошие новости в том, что нет - проблема возможно не в вас. Команды часто притворяются, что занимаются "веб масштабированием", прячась за библиотеками, ORM и кешами - уверенные в своей экспертизе (они порешали этот Leetcode!), в то время как они даже не в курсе основ индексирования в базах данных. Вы работаете в море неоправданного самомнения, расточительства и Даннинга-Крюгера, так кто тут реальный самозванец?
Нет ничего плохого в монолите
Идея того, что вы не можете развиваться без системы, которая выглядит как печально известный слайд военной стратегии войны в Афганистане это миф

Dropbox, Twitter, Netflix, Facebook, GitHub, Instagram, Shopify, StackOverflow - эти и другие компании начали как монолиты. Многие имеют монолит до сих пор. StackOverflow считают за предмет гордости то, как мало железа им нужно для работы массивного сайта. Shopify всё ещё на монолите Ruby on Rails, используя проверенный и надёжный Resque для обработки миллиардов задач
от автора перевода
Некоторые компании умудряются сделать одновременно микросервисы физически и монолитную кодовую базу для них всех, в которой даже на уровне идеи версионирование отдельных частей отрицается
То есть для разработчика это всё ещё остается монолитом, а микросервисы лишь добавляют своих проблем.
Возможно, заявлять, что ваша конкретная задача требует массивной сложной распределённой системы и открытого офиса, забитого турбо-гениями это просто высокомерие, а не гениальность?
Не решайте проблемы, которых у вас нет
Это простой вопросы - что за проблему вы решаете? Масштабирование? Откуда вы знаете как разбить систему так, чтобы не растерять масштабирование и производительность? Имеете ли вы достаточно данных, чтобы понять что должно быть отдельным сервисом и почему? Распределённые системы строятся с учётом размера и устойчивости. Может ли ваша система масштабироваться и быть устойчивой одновременно? Что произойдёт если один из сервисов упадёт или будет перегружен? Просто масштабируете его? Что будет с другими сервисами, на которые пойдёт трафик? Проводили ли вы учения с бесконечными перестановками вещей, которые могут пойти не так? Есть ли защитные механизмы? Автоматические выключатели? Очереди? Jitter? Разумные таймауты для каждого ендпоинта?Существуют ли надёжные меры защиты, гарантирующие, что простое изменение не обвалит всю систему? Бесчисленные переключатели, за которыми нужно следить, и все они зависят от особенностей использования системы и конкретной нагрузки.
Правда в том, что большинство компаний никогда не достигнут такого размера, который потребует построения реальной распределённой системы. Ваш косплей Amazon и Google - без их размеров, экспертизы и бесконечных ресурсов - скорее всего просто вопиющая растрата денег и времени. Религиозное следование всем шагам из статьи названной "Десять утренних привычек очень успешных людей" не сделает вас миллиардером.
Единственная вещь сложнее распределённой системы - ПЛОХАЯ распределённая система

"Но команды... но раздельное... но API..."
Пытаться засунуть распределённую топологию в структуру вашей компании это благородное усилие, но оно почти всегда приводит к обратным результатам. Общий подход - разбирать проблему на мелкие части и решить их одну за другой. Итак, кажется будто из этого следует, что если вы разобьёте сервис на много сервисов, то всё станет легче.
от автора перевода
Как по мне, главное заблуждение тут в том, что для разделения команд и ответственностей в реальности не нужно физическое разделение программы на части. Вместо того чтобы писать отдельный микросервис с АПИ, почему бы не написать класс с интерфейсом. Может даже выделить под это команду.
Тогда как в нынешней разработке делают по микросервису на класс, а вызов функций заменяют на http запросы, причём пишут на это на С++ и считают, что код каким то магическим образом будет производительный просто потому что это С++, игнорируя то что они сделали буквально всё, чтобы от скорости света в вакууме их программа зависела больше, чем от выбранного языка программирования
Теория проста и элегантна - каждый микросервис хорошо поддерживается отдельной командой, скрытый за прекрасным, обратно-совместимым версионированным API. Он настолько незыблем, что вы даже редко коммуницируете с его командой - как если бы микросервис поддерживался третьесторонним вендором. Это просто!
Если это не кажется знакомым, это потому что так бывает редко. В реальности, каналы наших месседжеров забиты сообщениями от команд, сообщающих о релизах, багах, обновления конфигурации и breaking changes. Все должны знать всё и всегда. И если это ещё не выглядит совсем прекрасно, какая-то команда вовсе забросила почти все микросервисы и работает над одним, а остальные микросервисы постоянно меняют "ответственных", по мере того как люди приходят и сбегают.
В попытках победить гонку мы вместо строительства одного хорошего гоночного автомобиля строим флот дерьмовозок

вольный перевод картинки
Вопрос: Может ли монолит быть также эффективен как микросервисная архитектура?
Ответ: Нет, ему никогда не стать настолько же медленным
Что вы теряете
Создание микросервисов это минное поле и зачастую оно недооценивается или игнорируется. Команды тратят месяца, разрабатывая сильно кастомизированный инструментарий и изучая уроки, не относящиеся к самому продукту. Вот часто упускаемые из виду аспекты....
Попрощайтесь с DRY
После десятилетий обучения разработчиков написанию не повторяющегося кода(DRY), кажется мы вообще перестали об этом говорить. Микросервисы по дефолту не DRY, так как каждый сервис наполнен бесполезным бойлерплейтом. очень часто оверхед такого "заполнения" настолько велик, а размер микросервиса столь мал, что средний мкросервис имеет больше обслуживающего кода, чем "продуктового". Как насчёт общего кода, который можно выделить?
Есть общая библиотека?
Как обновлять общую библиотеку? Сохранять разные версии везде?
Форсить обновления регулярно, создавая десятки пулреквестов по всем репозиториям?
Сложить всё в один монорепозиторий? Это идёт со своим собственным набором проблем.
Разрешить некоторое дублирование кода?
-
Забудьте, каждая команда изобретёт колесо с нуля. Каждый раз.
Каждая компания пройдёт этот путь, встречая эти проблемы и тут нет хорошего "эргономичного" решения - вам придётся выбирать вашу версию боли.
Эргономика разработчиков ухудшится
"Эргономика разработчиков" - это трение, количество усилий, которое программист должен приложить, чтобы сделать что-нибудь. реализовать новую фичу или найти баг.
С микросервисами, инженер должен иметь ментальную модель всей системы, чтобы понимать какой сервис должен сделать конкретную задачу, к каким командам обращаться, с кем говорить и о чём. Принцип "Ты должен знать всё, перед тем как сделать хоть что-то". Как поддерживать это знание? Spotify, многомиллиардная компания, потратила вероятно не незначительное количество внутренних ресурсов для построения Backstage, приложения для категоризации их бесконечных систем и сервисов.
Это должно по крайней мере дать вам понимание, что эта игра не для всех и цена поездки высока. Так что насчёт тууулинга? Те-Кто-Не-Spotify остаются со своими решениями, о надёжности и портабельности которых вы можете вероятно догадаться.
И сколько команд на самом деле упрощают процесс создания YASS - "yet another stupid service"? Это включает:
Доступы разработчиков на Github/GitLab
Переменные окружения и конфигурации по умолчанию
CI/CD
Проверки качества код
Настройки код-ревью
Правила и защита бранчей (github)
Мониторинг и наблюдаемость
Тестирование
Infrastructure-as-code
И, конечно, умножьте этот список на количество языков, используемых во всей компании. Может быть у вас есть хороший шаблон или инструкция? Может быть, простая однокликовая система для запуска нового сервиса с нуля? Выковать такую автоматизацию занимает месяцы. Так что, вы можете либо решать свою задачу, либо создавать туууулинг.
Интеграционные тесты? ЛОЛ
Если ежедневного микросервисного гринда было недостаточно, вы также потеряете спокойствие ума, даруемое хорошими интеграционными тестами. Один микросервис прошёл юнит тесты, но прогоняются ли тесты после каждого коммита?(в каждый сервис!) Кто отвечает за общий набор интеграционных тестов, в Postman или где-нибудь ещё? Есть такая команда?
Интеграционные тесты в распределённой системе это почти неразрешимая проблема, так что в основном все сдаются и заменяют другим - Наблюдаение. Также как "микросервисы" это новые "распределённые системы", "наблюдение" это новый "дебаг в проде", Вы не пишите реальный код, если вы не делаете "наблюдение"!
от автора перевода
Просто совет, если на собеседовании вас просят написать код на листочке, добавляя что "не всегда у вас будет дебагер", то бегите. У них реально нет дебага и единственный способ что-то узнать, это отладка в проде + логи. А сломанный дизайн своей системы, из-за которой невозможен становится дебаг, они компенсируют биокомпьютерами, собеседование на один из которых проходите вы.
Наблюдаемость стала отдельным сектором и вы заплатите за неё и деньгами и временем разработчиков. И это тоже не идёт из коробки, вам придётся понять и реализовать канареечные релизы, флаги фич и так далее. Кто это сделает? Тот самый итак перегруженный инженер?
Что насчёт "сервисов"?
Почему сервисы должны быть "микро"? Что случилось с просто сервисами? Некоторые стартапы дошли до создания сервиса на каждую функцию, и да, "это как Лямбда чтоль?" валидный вопрос. Это раскрывает глаза на то, как далеко этот неконтролируемый карго культ зашёл.
Ну и что нам делать? Начать с монолита это очевидный выбор. Во многих случаях также может сработать паттерн “trunk & branches”, в котором главный "котлетка с пюрешкой" монолит пользуется вспомогательными сервисами. Вспомогательный сервис может заниматься легко отделяемой и масштабируемой работой. CPU-затратный СервисРесайзаИзображений имеет гораздо больше смысла, чем СервисРегистрацииЮзеров. Или вы получаете так много запросов на регистрацию в секунду, что это требует отдельного горизонтального масштабирования?

Маятник качнулся назад
Хайп, однако, кажется спадает. Поток денег венчурных фондов перекрывается, так что бизнесу под гнётом здравого смысла и рынка придётся делать выбор, осознавая, что возможно тратить деньги на масштабируемую веб архитектуру, когда у них нет проблем с веб масштабированием это невыгодно.



В конечном счёте, когда вам нужно поехать из Москвы в Петербург у вас как минимум две опции: попытаться сконструировать замысловатый космолёт для орбитального спуска к месту назначения или купить билет на <мне не платили за рекламу> и долететь за час. Вот в чём проблема.
от автора перевода
Я бы, конечно, не стал сравнивать поделки на микросервисах с космическим кораблём, ведь строятся они в основном не инженерами космолётов, а нанятыми по дешёвке слесарями, которые позавчера узнали о том как называется инструмент которым они крутят гайки(в их компании это называется "поднял 20 кг на собеседовании - и гайки крутить научится"), а производительность они исключительно теряют
Комментарии (265)


Thomas_Hanniball
08.12.2023 13:16Надо было перевести текст со всех картинок, а то где-то есть, а где-то нет.
Сама же тема отличная, т.к. многие забыли принцип - Чем проще, тем лучше. Начитались книжек от гугла и теперь пытаются это внедрять у себя, не понимаю корневых причин, почему именно так было решено сделать в гугле.

K0styan
08.12.2023 13:16А это вообще общая проблема. Не только в разработке, но и в дизайне, и общепродуктовых вопросах. Заимствовать что-то, даже не попытавшись проанализировать контекст, в котором возникло заимствуемое.

ImagineTables
08.12.2023 13:16ОСОБЕННО, когда речь идёт про Гугл. У Джоэля есть колонка, где он рассказывает про свой опыт в Джуно и Мифическую Личность некоего постоянно отсутствующего директора:
For months later, we would have meetings where people would say things like “Charles [the CEO] doesn’t like dropdown list boxes,” because of something he had edited without any thought, and that was supposed to end the discussion. You couldn’t argue against this fictional Charles because he wasn’t there; he didn’t participate in the design except for hit and run purposes. Ouch.
Так вот, Гугл успешно заменяет в этой роли Чарльза во многих компаниях. Обсуждается какой-нибудь вопрос типа code convention, кто-то встаёт и говорит: а в Гугле делают так. И… “that was supposed to end the discussion”. Проблема в том, что, как и Чарльза, никого из Гугла при этом нет, и не то, что спорить не с кем, некого даже спросить, а в чём смысл такого решения. А смысл может быть в том, что это удобно в компании с зиллионами разработчиков по всему миру, не менее половины из которых имеют образование на уровне PhD, но совершенно не подходит для свеклоперерабатывающего завода в Вышнем Волочке.

Kelbon Автор
08.12.2023 13:16Смысл этих технологий как раз в том, чтобы управлять "стандартизованными разработчиками модели А51", которые несильно знакомы с инструментами, которые используют, а не наоборот
ImagineTables
08.12.2023 13:16Ну, я не специалист по Гуглу, и не берусь судить, в чём у них обычно смысл ))) Примеры привёл от фонаря.
Мой поинт в том, что настоящий гуглер, вполне возможно, сам бы сказал в подобной ситуации, мол, вам это не подходит, у вас условия другие.

Vladimirsencov
08.12.2023 13:16Микросервисы решают проблему горизонтального масштабирования, создавая кучу проблем взаимодействия и обеспечения консистентности данных. Хотя в большинстве случаев нагруженной будет лишь небольшая часть функционала. И то часто проще поднять несколько экземпляров монолита.

AlexeyPolunin
08.12.2023 13:16Ой да, я 6 лет назад так огребал за монолит, что ток в путь... Аргумент «не надо переусложнять, так-как это дорого» парировался — «ну так найдите денег и сделайте все по нормальному». Когда я говорил, что «ORM тоже не всегда нужен» ответ был «вы не понимаете в программировании».

Sheti
08.12.2023 13:16вот про ORM я бы послушал

vavp123
08.12.2023 13:16С учетом специфики того, чем занимается @AlexeyPolunin, ORM там действительно выглядит лишней (на мой взгляд).
Кратко - набор таблиц, их колонок и прочих настроек в определенной степени настраивается самим пользователем системы из своего рода админки. А ORM правило хочется использовать, когда моделируешь какую-то конкретную систему с конкретным набором таблиц и их ограничений. Плюс там есть определенный упор на производительность, поэтому может хотеться проектировать запросы самостоятельно.
Но может были и совсем другие причины
HemulGM
08.12.2023 13:16ОРМ не всегда нужна и с четким набором таблиц и полей. Часто нужно собирать информацию с большого количества таблиц основываясь на многих динамически формируемых джоинов и условий.
Я это на собственном опыте испытал. Хотя, конечно, все равно в итоге все в скорость упирается, а это вы упомянули.
Я сейчас процессе переделки целого бэкенда, написанного на Питоне с ОРМ.
Мой инструмент, конечно, не самый популярный, но я по всем запросам получил ускорение ответа в 2-15 раз. А потребление оперативной памяти в 20 раз меньше. Прирост скорости обусловлен не только тем, что язык теперь компилируемый, но и отказ от ОРМ. Все же на работу с бд больше всего времени уходит.

SergioT4
08.12.2023 13:16ORM тоже не всегда нужен
Не всегда, но если его нету, то часто появляется что-то типа:
SqlCommand command = new("SELECT * FROM Users;", connection); SqlDataReader reader = command.ExecuteReader(); if (reader.HasRows) { while (reader.Read()) { string accountName = reader.GetString(4); string email = reader.GetString(7); ...В пет проекте это ок. Но когда это проект даже среднего размера, то чревато боком. Тем более что появиться это может на ровном месте. Приняли на работу нового человека, а он "так видит". Можно конечно про код ревью и организационные мероприятия говорить, но когда есть технические решения для предотвращения подобного, то лучше постараться это решить на этом уровне.

mrsantak
08.12.2023 13:16Это ложная дихотомия, ORM и сырые prepared statement'ы - это не единственные способы работы с sql.
SergioT4
08.12.2023 13:16Было бы интересно увидеть пример того про что вы говорите, чтобы понять про что речь идёт.
mrsantak
08.12.2023 13:16Я не силён в шарпе, так что примеры будут для java. По-сути в вашем примере есть 3 проблемы:
Много boilerplate кода между самим sql запросом и началом фактической обработки result set'а.
Маппинг результатов запроса на объекты ЯП. Индексация по номерам колонок ненадежна, очень легко ошибиться, особенно когда мы достаём звёздочку, а не конкретный набор колонок, сложно рефакторить. Нет никакой типобезопасности.
Запрос в виде строки. Большие, иногда нужно формировать разные запросы в зависимости от параметров (например когда нужно отфильтровать результаты только если пользователь ввел фильтры и только по тем колонкам которые указал пользователь.)
Первая проблема в мире java решается просто, вместо сырого jdbc используем какой-нибудь spring jdbcTemplate, по-сути всё тоже самое, просто синтаксис короче:
jdbcTemplate.query("SELECT * FROM Users", new UserMapper());Где UserMapper может быть задан как-то так
public class UserMapper implements RowMapper<User> { @Override public User mapRow(ResultSet rs, int rowNum) throws SQLException { return new User( rs.getInt("ID"), rs.getString("FIRST_NAME"), rs.getString("LAST_NAME"), rs.getString("EMAIL") ); } }Проблемы 2 и 3 всё еще толком не решены.
И тут приходят более сложные библиотеки, например mybatis. В простых случая достаточно создать интерфейс типа такого:
public interface UserMapper { @Select("SELECT * FROM Users WHERE ID = #{id}") User selectUser(int id); }И либа сгенерит вам объект который реализует этот интерфейс и выполняет запрос. В более сложных случаях нужно писать конфиг маппера (какие колонки на акие поля объекта мапить), если запросы большие то их тоже целесообразно утащить в xml конфиг. Есть более-менее вменяемый шаблонизатор для составляения sql запросов, которые не сводятся к preparedStatement'ам. Есть библиотеки типа Spring Data JDBC, в которых вы просто создаёте интерфейс типа
interface UserRepository extends CrudRepository<User, Long>, WithInsert<User> {}и либа опять таки сгенерит для вас объект с кучей методов. Есть довольно странный функционал который позволяет сформировать запрос на основании названия метода (т.е. если у вас будет метод
selectByEmail, то либа сгенерит для него запрос типаselect * from Users where Email = ?), можно самому указать запрос в виде аннотации, и т.д. В общем, всё очень похоже на уже упомянутый mybatis.Ну и лично мой люьимец - это jooq, содержит в себе dsl на java который легко мапится в sql, т.е. вместо
select * from Users where id = ?мы пишем что-то типаselectFrom("Users").where(eq("id", id)). Это прикольно, позволяет легко и безопасно прогрмано собирать запросы не боясь иньекций. Также позволяет переиспользовать части запросов. Еще можно использовать возможности языка, чтобы прикрутить синтаксический сахар к sql. Например, если вам нужно написать insert в таблицу с 10 колонками, то в класическом sql вы вынуждены сначала перечислить все колоники, а потом перечислить все значения в том же порядке, и удачи вам нигде не перепуать порядок. Тут же можно сделать insert с update-like синтаксисом:insertInto("Users") .set("id", userId) .set("name", name) .set("country", country) .set("role", user.role)И развернётся всё это в обычный sql запрос.Но реально мощь этой либы раскрывается за счет того, что можно сгенерить классы описывающие вашу схему. И тогда у вас появляется возможность ссылаться на эти классы вместо того чтобы называть колонки/таблицы строками, т.е. вышепреведенный запрос будет выглядеть вот так:
insertInto(Users) .set(Users.id, userId) .set(Users.name, name) .set(Users.country, country) .set(Users.role, role)Где класс Users - генерится во время сборки, а значит если вы переименуете колонку в бд и забудете обновить запрос, то узнаете вы это на этапе компиляции. Более того, при генерации у вас колонкам будут присвоены типы, и вы можете эти типы кастомизировать. В данном случае name может быть только типа String, userId только типа UserId, а role типа Role. И это всё будет проверяться на этапе компиляции. Тоже самое и с select запросами. Вот такой код
selectFrom(Users) .where(eq(Users.id, userId)) .fetchOne(new UserMapper())вернёт объект User и потребует вот такой маппер:
class UserMapper implements RecordMapper<UsersRecord, User> { @Override public User map(UsersRecord record) { return new User( record.id, record.name, record.country, record.role ) } }где UsersRecord - это опять таки сгенерённый класс.

buldo
08.12.2023 13:16Последнее уже почти догоняет Entity Framework, который вроде как ORM.
mrsantak
08.12.2023 13:16Тут 3 ключевых отличия:
Вы всё еще вынуждены сами писать sql запросы, пусть и с кучей сахара.
Вы всё еще вынуждены сами мапить то что возвращает либа на ваши data классы.
Это всё работает только с плоскими объектами. Вытащить обхект и все его связи можно только в ручном режиме.

dph
08.12.2023 13:16Jooq все-таки уже добавляет лишнюю абстракцию и еще один "язык написания запросов".
SpringJDBCTemplate, на мой взгляд, дает лучшую абстракцию.

Vitimbo
08.12.2023 13:16В таком случае это уже больше похоже на dapper, который получает sql запрос и пытается впихать его в указанный объект.

PuerteMuerte
08.12.2023 13:16Где UserMapper может быть задан как-то так
Коллега, это называется ORM :)
mrsantak
08.12.2023 13:16Нет, для ORM эти мапперы - это лишь вершина айзберга. Основная идея ORM не в том, что за вас result set мапят на ваши объекты, а в том, что вы вообюще работаете не с таблицами в базе данных, вместо этого вы работает только с объектами вашего ЯП. По-сути ORM пытается сделать вид, что у вас под капотом не какой-нибудь postgres, а некая бд в которой прям ваши дата классы лежат.

Kano
08.12.2023 13:16ORM это наследник подхода DDD, где мы работаем с доменными моделями сущностями, где маппинг с физической бд скрыт за слоем абстракций.

GospodinKolhoznik
08.12.2023 13:16Только на практике получается, что как-бы работаете с доменными моделями, а в уме все равно приходится постоянно помнить о том, как оно там устроено в бд на самом деле, как реализован маппинг из бд в доменную модель и учитывать это, иначе рискуете где ни будь нарваться на чрезмерное потребление памяти или очень большое время работы.
В итоге все получается как в анекдоте "лучше не стало, только писанины прибавилось".

bert2000
08.12.2023 13:16сколько я написал ORM-ядер, ни разу мне не приходилось думать о вышеописанном. ЧЯДНТ?
Может быть "странно", но мои ОРМки вполне сами справлялись со всем маппингом, в т.ч. всех связей. И т.к. бизнес-модель и модель БД генерируемые, и отражающие мает описание бизнес-модели, то и нет ни малейшей вероятности отличия этих моделей друг от друга.
Зачем вам лишний "DLL Hell" в голове? Что мешает точно "бит в бит" зеркалить модели?

funca
08.12.2023 13:16В DDD популярн паттерн Repository. Но в природе есть ещё ActiveRecord, который тоже ORM.

Raspy
08.12.2023 13:16Всё хорошо работает, пока не нужно делать проектные расширения с поддержкой блю грина и расширением базовых моделей и сценариев работы с ними. У нас есть продуктовая коробка + десятки заказчиков, у каждого своя специфика. Сделано по классической ЕАV модели. Добавление новых атрибутов к моделе происходит без затрагивания основного продукта, в случае же с орм и генерацией под каждого заказчика пришлось бы иметь свою ветку и очень дорогие апгрейды. Там где не очень критично, используем документно ориентированные базы с полем аддишенелПропертис Мап<стринг, обжект>
mrsantak
08.12.2023 13:16В случе с jooq то что вы можете генерить модель для вашей схемы базы не сзначит что вы к ней привязаны. Т.е. вы можете просто ссылаться на таблицы/колонки по именам - в таком случае вы просто потеряете типобезопасность (которая впрочем и так далека от идеала). Более того, вы можете в параллель несколько моделей держать, или, если хочется, создавать их прям в рантайме (так например мы делаем для сложных вычислимых полей). Ну т.е. штуки типа:
insertInto("Users") .set("id", userId) .set("name", name) .set("country", country) .set("role", user)никак вас не ограничивают, вам доступны все расширения вашей СУБД, весь её синтаксис, просто sql запрос собирается не строкой, а вот таким dsl, который позволяет получить базовый комплишен в ide и минимальные проверки синтаксиса на этапе компиляции (например не получится случайно воткнуть where после groupBy и т.д.).
dph
08.12.2023 13:16Ну, EAV - это, скорее, антипаттерн для работы с БД.
Реализацию кастомизации можно сделать и кучей других способов, не так роняющих производительность.
От jsonb до просто SQL

pavelsc
08.12.2023 13:16Лучше когда есть команда разработчиков БД, вы им тикет - они вам функу. Остаётся написать прямой и обратный автомаппер на 10 строчек. А любой бойлерплейт всегда можно вынести в класс работы с БД.
bert2000
08.12.2023 13:16Команда разработчиков бд?
У меня 5 собственных ормок. И никаких команд. Ормки сами всё делают

mayorovp
08.12.2023 13:16От того, что вы вынесли бойлерплейт в другой класс - вы не избавились от необходимости его написать.

ItsNickname
08.12.2023 13:16Мммм вынос бизнес логики в СУБД. Скажите где вы такое пишите, чтобы случайно туда не попасть?
funca
08.12.2023 13:16Функции в БД это не обязательно бизнес логика. Часто это контроль целостности данных (логических инвариантов), маппинг в удобном для приложения виде, аудит доступа и т.п.

microuser
08.12.2023 13:16Что мешает эти инварианты проверять в приложении?
PuerteMuerte
08.12.2023 13:16Обычно - историческое наличие зоопарка других приложений, которые шарят одну и ту же БД, и должны ещё и некоторые бизнес-правила шарить.

MaxKitsch
08.12.2023 13:16Тут всё начинает зависеть от языка. ORM если не появились, то расцвели в Java, которая является весьма специфичным языком. Там как-то иначе сделать сложно.
Однако на том же Node, смысл именно ORM несколько теряется. Достаточно обертки над СУБД, которая умеет в экранирование запросов их выполнение.
Я видел достаточно большой проект, написанный без чего либо ещё, и он даже вполовину не был так плох, как можно было бы подумать.
Опять таки Query Builder != ORM. Нам не нужен гидрированный объект, который умеет себя сохранять, вытаскивать данные по внешним ключам и делать ещё бог весть что, если вся его короткая жизнь — это пролететь через пару редьюсеров, и дальше попасть в тело ответа сервера (которому вся эта гидрация и близко не нужна).
Тут главное, отказавшись от ORM, «словно в насмешку над собой» не написать свой собственный, кривой и нестандартный.
GospodinKolhoznik
08.12.2023 13:16Не обязательно так, можно и чтобы появилось что-то типа:
result <- withConn $ \conn -> query conn qry (rawEmail, rawPassw) pure $ case result of [(uId, isVerified)] -> Just (uId, isVerified) _ -> Nothing where qry = "select id, is_email_verified from auths where email = ? and pass = crypt(?, pass)"Это если нужно убедиться, что в результате выполнения запроса есть только одина строка и вернуть её, либо же вернуть специальное значение Nothing в противном случае. А если надо вернуть просто результат выгрузки безо всяких проверок то всё гораздо проще:
withConn $ \conn -> query conn qry (rawEmail, rawPassw) where qry = "select id, is_email_verified from auths where email = ? and pass = crypt(?, pass)"Это Haskell и в нём обычно не используют ORM ибо во первых нет объектов)) а во вторых типы данных в языке и сам язык достаточно выразительны и математизированы, так-же как и базы данных, чтобы реализовать соответствие между ними.
Да и если быть честным, я не могу сказать, что предоставленный код идеален и совершенен, в нём есть свои минусы, но если выбирать между ним и аннотациями в Java... Да что угодно лучше аннотаций в Java!
mrsantak
08.12.2023 13:16Да что угодно лучше аннотаций в Java!
Вы таки забыли про EJB до версии 3. По сравнению с той жестью не то что аннотации прекрасны, там народ с любовью xml конфиги принимал лишь бы не заниматься противоестественным сексом с этим монстром.


maximw
08.12.2023 13:16Микросервисная архитектура это не столько про технические решения, сколько про административные решения. Если команда маленькая - монолит предпочтительнее, проще, быстрее (и в разработке, и в большинстве случаев в перфомансе), экономичнее. Если коллектив большой насколько, что есть с десяток небольших команд со своими зонами ответственности, то нужны микросервисы, чтоб все вместе взлетело.
Kelbon Автор
08.12.2023 13:16В статье про это говорится(в примечаниях переводчика), зачем разбивать физически программу, если можно разбить только на логические части, которые потом соберутся в одну программу? Возможная причина - команды работают на разных языках. Но тогда у вас какие то другие проблемы, "исторически сложилось" так сказать.
Другая возможная причина это реальная логическая необходимость делать нечто отдельное, но зачем это тогда называть микросервисом, а не просто например "база данных" или ещё как-нибудь, от меня ускользает
foal
08.12.2023 13:16>если можно разбить только на логические части, которые потом соберутся в одну программу
Практически нельзя. Да можно договорится, что мы все будем писать независимые логические части, но на практике даже программа, написанная одним человеком за год, два разработки обрастает неявными внутренними связями. Что говорить о проектах, на которых работают 20-30 программистов в течении лет пяти.
Иногда удивляешься, сколько таких зависимостей вылезает из относительно простого и логичного стройного монолитика при попытке выделить часть его функционалиты в отдельный логический модуль.
Микросервисы хороши при разумном использовании, для меня это тот самый "тулинг", который следит за отсутствием неявных зависимостей.
Kelbon Автор
08.12.2023 13:16отсутствием неявных зависимостей.
а что если сервис таки неявно ходит по интернетику куда-то нетуда? Ну так, разок, всего один http запросик налево?)
foal
08.12.2023 13:16Отличие вашего примера от моего в том, что при написании монолита необходимо прилагать усилия, что бы не было неявных связей в коде программы. В вашем же случае необходимо приложить усилие для их появления.
И то и то реально. Но на долгой дистанции результат разный.

PrinceKorwin
08.12.2023 13:16Что говорить о проектах, на которых работают 20-30 программистов в течении лет пяти.
Я участвовал в проекте на Java. Монолит. Делался в течение 15 лет. Разработчиков - больше 300 человек в сумме.
Все там было нормально с изолированием и параллельной разработкой.
Если архитектор(-ы) нормальные, то все будет хорошо.
Потом этот продукт переписывали на микросервисы. Получили проблемы в полный рост:
На порядки больше железа нужно
Нужно на порядок больше инженеров сопровождения
Сложность взаимодействия между командами возрасло
Скорость E2E упало
foal
08.12.2023 13:16А зачем? По моему опыту бизнес очень неохотно спонсирует такие вещи если нет реальных проблем в продукции.
И... 15 лет. 300 разработчиков. Один продукт. И все "нормально с изолированием и параллельной разработкой". Вау! Завидую :) У меня такого на было ни разу за 30 лет работы. Ну может немного в TogetherSoft/Borland, но там было бы странно, если бы Java IDE не была монолитом с нормальным процессом разработки.
PrinceKorwin
08.12.2023 13:16Зачем?
Мода... Заказчики этого продукта стали часто слышать слово - облака, микросервисы, скалирование... И стали требовать этого.
По факту - все стало дорого и сложно, но всем пофиг. Платят деньги :)
funca
08.12.2023 13:16С технической стороны здесь ключевым аргументом служит баланс между надежностью решения (Reliability) и его стоимостью (TCO). Причина простая: у типичного железа uptime не может вечным - оно ломается, необходимы окна для сервисного обслуживания.
С гарантиями по availably > 99.9 вы неизбежно приходите либо к надёжным как космические корабли мейнфреймам, либо к распределенной архитектуре - в зависимости от допусков по отзывчивости.
Это не то, что вам нужно для типичного стартапа. Но в некоторых специфичных доменах (из области медицины, обработки платежей и т.п.) все уже зарегулировано и у вас нет выбора с самого начала.

sukhe
08.12.2023 13:16С гарантиями по availably > 99.9 вы неизбежно приходите либо к надёжным как космические корабли мейнфреймам, либо к распределенной архитектуре - в зависимости от допусков по отзывчивости.
А всегда-ли нужна такая надёжность? Есть же миллионы бизнесов, которые работают по 8 часов в день. Рискну даже предположить, что таких бизнесов на нашей планете - подавляющее большинство. Соответственно, в нерабочее время можно всё что нужно обновить / обслужить. Зачем тащить решения уровня Гугла / Амазона куда-нибудь в шаурмячную или на мебельную фабрику? Понятно, что "так мы слона не продадим" и стартап не сделаем.
Но не всем-же быть стартапами. Кто-то ведь и работать должен.SergioT4
08.12.2023 13:16Зачем тащить решения уровня Гугла / Амазона куда-нибудь в шаурмячную или на мебельную фабрику?
Да про это есть хорошая статья "вы не гугл".
Есть мнение что aws и ко. приложили руку к тому чтобы эта мода возникла. Сколько отдельных серверов крутится на подобных проектах, на радость акционерам амазона.

mvv-rus
08.12.2023 13:16С гарантиями по availably > 99.9 вы неизбежно приходите либо к надёжным как космические корабли мейнфреймам, либо к распределенной архитектуре - в зависимости от допусков по отзывчивости.
Отнюдь не неизбежно. Есть промежуточный вариант - Fault-Tolerant Cluster. В MS Windows Server, например, он ещё лет 15 назад стал народным, т.е. перестал требовать особого вендорского железа и дорогих старших редакций ОС. То есть это - куда дешевле, чем мейнфрейм, даже на Windows - а уж за прошедшие годы наверняка и на Linux то же сделали: я не интересовался, но ничего сложного, какого-то особого ноу-хау, там нет. Что до надежности, то MS тогда рекламировала аж пять девяток, но даже сделав поправку на рекламу, получим четыре девятки и отсутствие (ну, снижение) плановых постоев на установку обновлений.
Запускать на кластере можно не обязательно что-то распределенное, специальной архитектуры: в принципе, любую серверную программу можно доработать, иногда - без помощи разработчиков. Я, например, для прикола так кластеризовывал сервер MS DNS. Даже статью про это написал - потому что на некоем старом зеленом форуме "кластер DNS" был местной хохмой, для его старожилов я и писал.

Areso
08.12.2023 13:16У обработки платежей главная задача не продолбать данные, а вот про доступность никто не говорил - некоторые банки, которые не работают целиком с пятницы вечера до понедельника, я уже успел встретить на жизненном пути
K0styan
08.12.2023 13:16О, так то знаменитый банковский день, легаси бумажного документооборота)
Впрочем, с учётом того, что часть транзакций положено проводить через комплайенс, к рабочему дню белковых микросервисов привязка будет по-любому.
foal
08.12.2023 13:16Хмм... Ну не знаю. У нас заказчики это бизнес, который зарабатывает деньги не на разработке софта. Его модой не приведёшь. Клиентам (B2С) важна бесперебойная работа приложений и отделений. Им пофиг на чем все это едет.

SergeyZerg
08.12.2023 13:16Работал на монолитном проекте которому 20 лет. 500+ разработчиков. И все было хорошо.
Архитекторы реально были там крутые и очень суровые. И вообще очень адекватный менеджмент. Может именно поэтому проект столько лет успешно прожил и продолжает жить.

cross_join
08.12.2023 13:16В идеальном мире при любой архитектуре нет неявных зависимостей. Там, например, на каждый чих меняется версия API, а микробаза данных у каждого микросервиса своя. Жаль, автор не стал описывать стоимость поддержки N баз данных и распределенных транзакций.
foal
08.12.2023 13:16А я про реальный мир. Что касается стоимость поддержки N баз данных и распределенных транзакций, то у нас хорошо ложится Кафка, которая постепенно вытесняет зоопарк из MongoDB, Redis, ES. Да топиков может быть очень много, но проблема одного топика не волнует поддержку если работает вся Кафка. Проблема одного топика ложится на разработчиков. Распределенные транзакции - тут тоже все не плохо. После переосмысления потоков данных выяснилось, что бизнесу они нужны в очень ограниченной области. К тому же эта область не критична ко времени выполнения и поток данных там на порядки меньше (реально тысячи против миллионов). В остальном мы можем позволить себе кратковременно потерять синхронизацию, а то и все данные на уровне микросервиса.
dph
08.12.2023 13:16Хм, кафка никак не решает проблемы распределенных транзакций, только добавляет еще проблем с транзакционностью отправки сообщений. Ну и бизнесу обычно как раз нужны гарантии выполнения бизнес-операций (хотя бы в конечном итоге), так как бизнес обычно думает в категориях как раз распределенных транзакций.
Да, эти проблемы решаются, но 90% имеющихся решений ужасны, а оставшиеся 10% - дорогие в использовании и эксплуатации.
PuerteMuerte
08.12.2023 13:16Да можно договорится, что мы все будем писать независимые логические части, но на практике даже программа, написанная одним человеком за год, два разработки обрастает неявными внутренними связями
Микросервисы эту проблему никак не решают, просто выносят на уровень, требующий намного больше железа. Сложность и неочевидность зависимостей между микросервисами по мере роста системы ничуть не уступает той, что внутри монолита.
foal
08.12.2023 13:16Да, вы правы. Очень часто некорректно сравнивают сложность монолита и отдельного микросервиса, в то время как надо сравнивать хотя бы монолит и экосистему всех микросервисов которые выполняют его функции. Вот только потенциал у второй сложной системы намного больше. Я с трудом представляю потенциальный ИИ, который можно прикрутить к управлению монолитом. В случае с микросервисами - легко.

Ares_ekb
08.12.2023 13:16можно договорится, что мы все будем писать независимые логические части, но на практике даже программа, написанная одним человеком за год, два разработки обрастает неявными внутренними связями
Я думаю, что для монолита гораздо проще контролировать зависимости между модулями. Если каждый модуль - это отдельный проект, то зависимости между проектами явно прописаны. Уже в design-time видно что от чего зависит. Ещё можно всё это покрыть архитектурными тестами, чтобы проект просто не собирался при появлении лишних зависимостей. А для микросервисов фиг знает куда какие запросы они отправляют - нужно или запросы анализировать или код, так сходу за минуту не разберешься что от чего реально зависит.
Возможно для микросервиса заранее не знаешь где он будет использоваться и стараешься спроектировать хорошее API. Но то же самое верно и для модулей в монолите.
На мой взгляд, никаких микросервисов не существует, земля плоская, рептилоиды и масоны управляют нами, инопланетяне уже давно посещают нашу планету... Ой, ChatGPT выдал какую-то ересь на мой промпт, ну, ок, не буду удалять ради рофла. Короче, я думаю, что микросервисы - это тупо отдельные приложения со своим назначением, своей командой разработки и своими накладными расходами по интеграции всего этого.
Если у компании несколько автономных команд разработки, которые вольны в своих микросервисах делать что угодно, если есть ресурсы на интеграцию всего этого, то наверное микросервисы ок. А если команда разработки одна или если решения по используемым технологиям, по схеме данных и т.д. принимаются централизованно, то хз на сколько все эти накладные расходы на обеспечение целостности данных, на сопровождение этого дайверсити, использующего разные ЯП, СУБД и т.д. оправданы.
foal
08.12.2023 13:16Я думаю, что для монолита гораздо проще контролировать зависимости между модулями. Если каждый модуль - это отдельный проект, то зависимости между проектами явно прописаны.
Да, так можно делать, я сам для DAO (или сервисов) всегда создавал два модуля, один с интерфейсами, второй с реализацией. На второй зависимость со скопом runtime. Вот только часто вы такие проекты видели? Я нет.
Если у компании несколько автономных команд разработки.
Да, разговор именно о них. Стартапу заморачиваться с микросервисами (если только это не цель их идеи) нет смысла.
dph
08.12.2023 13:16Практически - легко.
Модули, библиотеки, ArchUnit - очень много разных инструментов для гарантий отсутствия неявных связей. И, собственно, так обычно и писали монолиты в приличных компаниях. Я видел огромные проекты на чистом SQL с жестко расписанными интерфейсами между разными модулями, так что дело только в качестве программистов.

Kelsink
08.12.2023 13:16Проблема в CICD. Если он действительно CD. Если это не модный монорепо. Одна из команд ломает что-то. А это обязательно произойдет. Чем больше монолит - тем чаще. Происходит фриз, делается откат. Все ждут. В ветках ломаются тесты, надо подтягивать изменения и т.д. Это не критично, но не весело.
dph
08.12.2023 13:16Хм, а в чем тут проблема с CD? И с монорепой?
Ну сломала команда что-нибудь - так это выяснится на тестах до мержа в монолит и до выкладки и даже до тестов уровня монолита. Еще и проверить быстрее.
nlog
08.12.2023 13:16Зависимости могут быть не только compile time от модулей, но и от публикуемых в каком-нибудь Nexus артефактов. И в монорепе вполне возможна ситуация, когда в одной ветке все было хорошо, в другой какой-то контракт поменялся, и в итоге в main ошибка компиляции. Но все проверки на CI прошли успешно.
dph
08.12.2023 13:16Хм, а при чем тут монорепа?
Взяли ветку, забрали туда мастер, прогнали тесты, смерджили - где тут может быть ошибка компиляции? Только в момент между "забрали мастер" и "смерджели", но та же фигня может быть и в мультирепе, никакой разницы.
bert2000
08.12.2023 13:16Эти части называются модули. Ну иногда это сервисы. Но точно не микросервисы!
MaxKitsch
08.12.2023 13:16Вы сейчас убедительно доказали невозможность существования крупных десктопных приложений.
maximw
08.12.2023 13:16Я нигде не утверждал и не доказывал возможноть или невозможность существования чего-либо. Я сказал, для чего нужны микросивисы как инструмент. В основном это про решение административных задач взаимодействия больших команд проект-менеджеров, программистов, аналатиков, QA, девопсов. В меньше степени про масштабируемость, быстродействие и т.п.
bert2000
08.12.2023 13:16А просто сервисы хотя бы нельзя? Зачем микро то?
И не от команды это зависит вовсе. Ваша аргументация больше тянет на распил бюджетов
maximw
08.12.2023 13:16Микро/немикро - это вопрос терминологии. Я лично не могу сказать, где проходит граница между ними. "Микросервисы" просто устоявшийся термин и все примерно понимают о чем реь.
Я не знаю, где вы в моих словаях увидели распил бюждетов. Но если вы работали в команде хотя бы 20 разрабочиков, то знаете, как в случае монолита сложно поддерживать контракты (интерфейсы) между различными частями продука. Хорошо, если можно поощаться с коллегой когда он за соседним столом или хотя бы в соседнем кабинете. А если это десяток офисов в разных часовых поясах, начинается геморр. И это уже именно административная проблема. Которую позволяет решить разделение на микросервисы (или сервисы, если хотите) и дает возможность довольно четко поддерживать контракты, минимизируя общение и количество согласований между командами, т.е. ускорять разработку. И кроме кодинга есть еще куча вопросов - тесты (не юниты, а итеграционные или е2е), QA, CI/CD, который у каждой команды может быть свой.
bert2000
08.12.2023 13:16Административная задача (менеджмент) вдруг стала решаться программно? Сервисами? Интерфейсов и тестов с документацией мало? Вы о чём вообще?
GospodinKolhoznik
08.12.2023 13:16Административная задача (менеджмент) вдруг стала решаться программно?
А вы никогда не присутствовали на совещаниях, где топ менеджеры (не айтишники, а юристы с экономистами) обсуждают архитектуру системы (вплоть до того, какие будут таблицы в бд и как будет организовано версионирование в них) не из соображения логики работы системы и заветов дядюшки Боба, а из соображений как разграничить периметр взаимодействия модулей системы, чтобы все рисковые операции вынести в смежные департаменты, а все безрисковые операции оставить за собой?
bert2000
08.12.2023 13:16Бог миловал. Но опыт подобных инжекций "был". К примеру один московский заказчик спускал нам таблицу где были поля fa, im, ot. Когда их стало не хватать (ну дамы меняют же фамилии), он добавил поля fa2, im2, ot2, fa3, im3, ot3 и т.д.
а т.к. система была связана с бабками , то были ещё и кучи полей типа p1, p2, p3 и т.п. В общем что такое нормализация БД этот заказчик даже не слышал.
maximw
08.12.2023 13:16Взаимодействие множества команд - административная задача. Конечно, она влияет на архитектуру разработки и ахритектуру системы.
Интерфейсов и тестов с документацией мало? Вы о чём вообще?
Вы про интерфейсы в рамках одного ЯП? А что если для разных частей системы нужны разные технологические стеки. Я намеренно не использовал термин "интерфейс", а писал про контракты, чтоб не путать с интерфейсами в ЯП.
bert2000
08.12.2023 13:16Разные стеки всё равно можно синхронизировать между собой, это обычная интеграционная задача, и многие тут её решали.
Проще всего описать "формат взаимодействия" (некий обменный формат данных) утвердить его с обеих сторон и придерживаться его. Обычная задача стандартизации.
Да, можно (и нужно) обернуть модули ETL сервисами и обмениваться данными по Сети, но это не микро сервисы. Сервисы как сервисы, выполняющие только сериализацию и десериализацию по сути, на стыке разных стеков.
Есть ещё тут один секрет. Когда стэки разные, а команды нет, (команда одна) ну или команды умеют общаться между собой как единое целое, то можно перейти к метапрограммированию и генерации кода. Тогда вопросов стандартизации вообще не возникает, точнее они уходят на уровень мета-генерации и описания метаданных.
Административные задачи никак не влияют на архитектуру. Она изначально должна правильно проектироваться на первых же этапах, дабы не было мучительно больно всё потом рушить до основания.


ruomserg
08.12.2023 13:16Самое интересное, что на курсах архитектов открыто предупреждают о сложности и опасности микросервисных архитектур. Но задания надо делать как ? Правильно - микросервисы в облаке. :-( Потому что все заказчики спят и видят что если год назад у них был 1 пользователь, а сейчас 100, то через год будет 10к, а через два 1М. И требуют масштабируемое решение. А так-то в статье написано правильно - они сдохнут каждый первый при попытке выйти с 10k, и никакого масштабирования не понадобится.
Kelbon Автор
08.12.2023 13:16Не думаю что многие архитекторы из мира JS проходили какие-то курсы, но также не вижу почему масштабируемость может быть достигнута исключительно микросервисами, может я что-то упускаю...
maximw
08.12.2023 13:16Монолиты тоже могут горизонтально масштабироваться не хуже, имея при этом большее быстродействие, т.к. лишены части сетевого взаимодействия.
ruomserg
08.12.2023 13:16Теоретически - могут. Но тут возникает такая проблема, что этот монолит тогда должен быть специально спроектирован для того чтобы горизонтально масштабироваться. Потому что два экземпляра будут между собой синхронизироваться как ? Через базу данных. А это значит что обычные для монолитов практики кеширования в коде (когда монолит предполагает что только он пишет в базу) перестают работать. Я не скажу что это нерешаемая задача - но если выбрать случайным образом монолит, засунуть в контейнер и запустить два экземпляра - начинаются чудеса...
Опять-таки, если мы масштабируем монолит - то мы масштабируем его весь. В том числе и те части, которые никому особо не нужны. При хорошем разбиении на микросервисы - мы бы масштабировали только то, что нужно.
Но мы опять выходим на философское обобщение (которое всем известно с самого начала) - что хорошо спроектированная система работает хорошо, а плохо спроектированная - плохо. И согласен, плохо спроектировать микросервисы намного проще чем монолит. Потому что в монолите можно потом замазать дырку в архитектуре пользуясь тем, что все лежит в общей памяти - и это костыльно и воняет, но работает. А вот если людям удалось криво расписать распределение данных в микросервисах - то это уже навсегда (или до major system redesign).
cross_join
08.12.2023 13:16Проблема когерентности кэшей перпендикулярна сервисности или монолитности архитектуры, она начинается с N=2
ruomserg
08.12.2023 13:16Давайте скажем аккуратно - она перпендикулярна, но удивительно коррелирована. Потому что монолит обычно пишут имея в уме вертикальное масштабирование: быстрее, выше, сильнее. А когда у тебя есть память, и есть понимание что все пути записи в shared storage тебе же и подконтрольны - ну грех такое не использовать для ускорения работы-то!
В микросервисах (если разработчик и архитект дружат с головой) у всех уже есть понимание, что кеширование - это отдельная ответственность. И сколько у тебя в каждый момент активно экземпляров - ты больше не контролируешь, а за тебя авто-скейл решает. Соответственно - уже при проектировании закладываются другие паттерны работы с кешем. Те же key-val in-memory БД (с погляда моей невысокой колокольни) выросли именно потому что потребовалось вытащить кэши из конкретного экземпляра сервиса и сделать их разделяемыми. В монолите внешний key-val был... Ну что-то вроде пресловутого анекдота: "Мама, а как правильно пишется - 'флякончик', или 'флюкончик' (redis vs memcached) ? // Вот бог дуру в дочери мне послал! Напиши уже 'пизирёк' (ConcurrentHashMap) и ложись спать!". :-)

DarthVictor
08.12.2023 13:16В микросервисах (если разработчик и архитект дружат с головой) у всех уже есть понимание, что кеширование - это отдельная ответственность. И сколько у тебя в каждый момент активно экземпляров - ты больше не контролируешь, а за тебя авто-скейл решает.
В монолитах на NodeJS, например тоже. Тупо потому что Нода однопоточная и любое приложение запускается в нескольких экземплярах. Подозреваю, что на Python, ROR и PHP обычно также работают. Нормально в одном экземпляре веб-приложение может работать разве что на .NET, JVM и возможно Go. Но это не делает типичное приложение на Express микросервисным.

ris58h
08.12.2023 13:16С чего вы решили, что монолит отменяет шардирование и у него не может быть несколько запущенных инстансов?

saboteur_kiev
08.12.2023 13:16Но тут возникает такая проблема, что этот монолит тогда должен быть специально спроектирован для того чтобы горизонтально масштабироваться.
А типа микросервис не должен быть специально спроектирован для горизонтального масштабирования?
Единственная проблема монолита в этом, что если он изначально таковым не был, то переделать сложно, а новый микросервис запилить быстро.
Но если мы делаем новый монолитный проект, то не будет никаких проблем.bert2000
08.12.2023 13:16К сожалению проблемы будут всё те же. Вопрос кеширования данных довольно серьезный и далеко не все смогут его обойти. Более того, если нет версионности в структуре данных, то кеши вообще не смогут понять и выявить проблему.
Если добавить версионность, то можно извне управлять кешем, т.е. По сути синхронизировать их.
Проблема эта решаемая в общем да. Но далеко не все умеют её решать.
Им вон микросервисы легче запилить

rdo
08.12.2023 13:16Опять-таки, если мы масштабируем монолит - то мы масштабируем его весь. В том числе и те части, которые никому особо не нужны.
Это как раз не проблема, код, который не выполняется не загружает процессор.
ris58h
08.12.2023 13:16Есть ещё стадия инициализации. Видел, например, как контекст спринга минуту стартует для кода, который не будет выполняться. Так что, в некоторых случаях минусы есть. Опять же - это не повод распиливать монолит, если это не приносит проблем.
mrsantak
08.12.2023 13:16Видел, например, как контекст спринга минуту стартует для кода, который не будет выполняться.
Для этого боженька придумал Lazy бины :)
bert2000
08.12.2023 13:16А кто сказал что монолит надо целиком масштабировать? Попилить его на модули или крупные сервисы нельзя чтоль?
Если грамотно проектировали монолит, то он минимум на 10 подсистем пилится обычно.
А вообще надо исходить из поставленной задачи. И решать её без лишней теории и фантазии.
Это написано кстати и в статье.
Очень часто хотелки бывают необоснованны, а проблемы придуманными и высланными из пальца
foal
08.12.2023 13:16Нет хуже. Гораздо хуже. Вы просто рассказываете о идеальном монолите, написанном как надо. А у нас есть реальный монолит. Знаете в чем его основная проблема при масштабировании? Сетевое взаимодействие. Всё упирается в сеть. Либо все копии тянут данные независимо (а данных для монолита надо много!) и кладут дата-соурс. Либо мы используем распределённый кэш. Помогло ненадолго, потому что апологеты монолита встроили его куда? Правильно в сам монолит. И теперь у нас загибаются 10Гиб свитчи на пиковой нагрузке при синхронизации кэша.
Kelbon Автор
08.12.2023 13:16Всё упирается в сеть.
так вы не устраивайте из сети шаренную память, а передавайте лишь нужное. По такой логике как раз микросервисы жрут больше сети, ведь им нужно постоянно через неё общаться
foal
08.12.2023 13:16так вы не устраивайте из сети шаренную память, а передавайте лишь нужное
В этом и есть различие между вашим идеальным монолитом и реальной программой, написанной большим коллективом людей. А так да - идеальный монолит гораздо лучше распределённой системы. Примерно, как утопия лучше и приятнее реальной жизни.

georgevp
08.12.2023 13:16м.б. в реальном монолите изначальна была ошибка в его архитектуре? Без претензий. Просто, как предположение.
foal
08.12.2023 13:16Да! Но не изначально, а она накапливалась там годами, помноженными на количество разработчиков. Ведь тот же кэш надо было делать отдельным Hazelcast кластером, что сняло бы львиную долю нагрузки с сети и решило проблему с источниками данных. Но было сделано, что сделано, тогда это казалось разумным, а текущие требования к нагрузке никто не мог представить.
Вот только монолит не откатить лет на семь назад, чтобы легко поправить это. И таких проблем там не мало. Каждая ошибка (как и хорошее решение) в архитектуре за несколько лет обрастает кодом. И исправить её ой как не просто. А грубой силой исправить (масштабировать) этого монстрика ну очень сложно :)
K0styan
08.12.2023 13:16А у любой сложной системы, которая живёт хотя б лет 5, есть ошибки в архитектуре. Точнее, не ошибки - несоответствования требованиям. Хотя бы потому, что бизнес-требования меняются, и те данные, которые при первоначальном проектировании были не особо нужны, становится нужным раздавать куче конечных клиентов.
bert2000
08.12.2023 13:16Ошибки архитектуры зачастую бывают ошибками нулевого дня.
Очень многие, приступая к реализации проекта, не видят дальше своего носа и не предполагают проблем роста. Притом типичных проблем, описанных сотни раз и с готовыми решениями, известными уже по полвека.
Потом приходится ломать такие проекты до основания и писать их практически заново и с нуля под "новые" требования ТЗ.
Модульная архитектура помогает снижать риск таких проблем в разы.
А том числе возможно переписывание/правка только одного или нескольких модулей.
K0styan
08.12.2023 13:16Есть куча сценариев. Есть преждевременная оптимизация, когда вливают кучи бабла в супергибкую архитектуру, но не отбивают на тоненьком стартовом потоке клиентов. Есть вроде бы умеренная, разумная оптимизация, но не того. А бывает просто игнор будущего, да. И самое подставное - заранее нереально понять, в который из этих путей вы ввязались.
Так-то я сам за модульность, но иногда её тоже оказывается мало. Когда в пандемию ритейлы бегом побежали обрабатывать новую бизнес-задачу онлайн-покупок, понадобилось переделывать примерно всё.
bert2000
08.12.2023 13:16кучу бабла вливать сразу не надо, это глупо.
тем не менее не надо "плевать на каноны" программирования.
на старте можно вполне создать допустим 5 модулей / слоёв, и реализовать их "на коленке" каждый. Но строго с изоляцией слоёв, дабы сразу не превратить стройную систему в "месево" и кусок не пойми чего.
В дальнейшем с развитием проекта каждый модуль обязан жить отдельной жизнью и развиваться строго отдельно (т.е. сохраняя изоляцию). По итогу модули/уровни абстракции могут добавляться, что даёт проекту дополнительную гибкость (раз) и позволяет на том же ядре запускать другие (похожие) проекты с незначительными доработками (два). Т.е. это обыкновенные канонизированные повторное использование кода и рефакторинг.
Это всё та же суть паттернов SOLID, DRY, KISS, MVC, плагины, многозвенка.
Получившееся ядро позволит запускать практически любые проекты, и интегрировать разные подсистемы бизнеса в единую платформу.
ПыС и ещё раз. Главное не забывать основные каноны программирования и не забивать на них. К сожалению очень многие вообще плюют на архитектуру и с первого дня начинают лепить тя-ляп. Да и лиды (очень часто сталкиваюсь с таким) вообще не имеют компетенций архитекторов и соответствующего опыта. Это прям бич какой-то в индустрии.
bert2000
08.12.2023 13:16похоже на малопродуманную монолитную двузвенку, и данные - это прям коннект до базы? Помнится в виртуалках запускали копии на одном сервере именно по этой причине.
А по сути решения проблемы, архитектура конечно в корне неверная тут. Да и базу можно (и возможно нужно) порезать в зависимости от функционала.
Хотя ясно что этот монолит такое уже не позволит, и его "необходимо пилить", или вообще рушить и писать на его месте что-то грамотное и более-менее гибкое, в том числе умеющее создавать "витрины".
nlog
08.12.2023 13:16Никогда не видел зрелого монолита, который бы быстро стартовал, возможно они и есть. Медленный старт -> медленное горизонтальное масштабирование при всплеске траффика -> лаги у пользователей -> разочарование.
bert2000
08.12.2023 13:16А такую задачу "быстрого старта" кто-то ставил вообще?
Может если её поставить перед разрабами, то они её решат?
Может такую задачу никто и не ставил только потому, что её решение не нужно?nlog
08.12.2023 13:16Как без быстрого старта решать проблему быстрого реагирования на увеличение трафика в 1.5-2 раза? Всегда держать Х2 экземпляров "на всякий случай"? Или масштабировать вручную перед рассылками и промо-акциями, когда ожидается предсказуемое повышение нагрузки?
PrinceKorwin
08.12.2023 13:16Всегда держать Х2 экземпляров "на всякий случай"?
Обычная практика - это поднимать столько инстансов которых хватает на 1.5 пиковой нагрузки (цифра исперическая). И новые инстансы поднимаются не тогда, когда уже система не держит NFR'ы, а заранее.
Поэтому скорость старта новых под не так важна.Что важно - это чтобы они на старте не ели много CPU. Т.к. это может только усугубить ситуацию и вызвать каскад последствий.
bert2000
08.12.2023 13:16лучше как раз х2, хотя мат статистика говорит что лучше "х3" (точнее число E = 2.72)
поэтому рост нагрузки в 1,5-2 раза это мелочь обычно, рост в 3 раза вполне прогнозируемый. Остальное уже надо решать и закладывать дополнительные мощности, возможно виртуальные.PrinceKorwin
08.12.2023 13:16Уточню. В 1.5 от медианного значения предыдущих пиковых нагрузок.
bert2000
08.12.2023 13:16не могу уже тут писать - некий "бан" получил, замедление аля огрызок
в корневом комменте я написал что "такую задачу не ставили".Если её поставить - она решаема, и вполне может быть решена.
В частности для ускорения запуска всего "программного комплекса" его можно разбить на отдельные подсистемы ("сервисы", если хотите, но не микро) и запускать их параллельно. Тогда появляются вполне уже решённые индустрией вопросы управления всем этим зверинцем, и балансированием нагрузки.
В общем всё решаемо и решено (изобретено) "задолго до нас".PrinceKorwin
08.12.2023 13:16Иногда для решения этого приходится уходить с основного стека. Пример java/springboot. У этого фреймворка не самое лучшее время старта.
Как вы пишете одно большое попили на много мелких - стало стартовать ещё медленнее. Т.к. спринг ест очень много cpu на старте и этого CPU уже стало не хватать.
Решение - вливать бабло и брать больше cpu. Хотя это новое купленное CPU будет просто простаивать и не использоваться в работе.
Можно уйти со спринга на, как пример, кваркус.
Можно выделить наиболее критичные части и переписать их на Go.
Решений - море.
Никто не говорит, что их нет.Но вот часто бывает так, что решения и не нужно придумывать.
В моем примере выше проблему медленного старта решили за счёт 1.5 большего железа + упреждающее скалирование + scaledown.
В этом же и фишка облачных решений. Не нужно решать программистами девопс задачи.
Ares_ekb
08.12.2023 13:16Потому что все заказчики спят и видят что если год назад у них был 1 пользователь, а сейчас 100, то через год будет 10к, а через два 1М. И требуют масштабируемое решение.
Есть один проект с миллиардом просмотров в месяц. Похоже его создатели всё это время были в анабиозе и не слышали про микросервисы. А если бы добавили хотя бы десяток-другой микросервисов, сагу и это всё, то наверное вообще всё летало бы.
PrinceKorwin
08.12.2023 13:16Но. По вашей ссылке же как раз микросервисная архитектура:
Microservice - Web Service ( отскалирован в 9 под)
Microservice - Tags Engine (3 поды)
Отдельные для этих MS базы данных
Отдельно стоящие Redis кэши
Отдельно стоящий эластик для поиска
У них микросервисная архитектура. Другое дело, что т.к. это просто форум, то и они не стали сильно его дробить - ибо не нужно.

shornikov
08.12.2023 13:16КМК, вынесенная на отдельную машину ДБ не делает проект микросервисным.
Первые 2 пункта - может быть.
foal
08.12.2023 13:16Я еще добавлю - просмотра относительно статической информации. Плюс некритичной ко скорости обновления. Ваш новый вопрос/ответ может легко появится в общем доступе секунд через 20-30 после его добавления. Не удивлюсь, что и позже — это некритично для этого сервиса.
Ares_ekb
08.12.2023 13:16Картинка оттуда:
На сколько я понимаю, у них одна база данных для stackoverflow + одна резервная. И одна база для всего остального + одна резервная. Это уже сомнительный подход по меркам микросервисной архитектуры. Redis, Elastic Search тоже не сделают монолитное приложение микросервисным, всё таки в них нет никакой бизнес-логики.
Монолитное приложение ведь не означает, что в нём должно быть всё реализовано с нуля и запускаться как одно приложение. Например, у нас на одном проекте приложение включает: фронт, бэк, БД, API gateway, Keycloak, БД Keycloak, Apache Directory, Prometheus, Grafana. Но это всё равно монолит. Скука лютая, здесь даже Сагу некуда прикрутить.
Всё-таки для микросервисов нужно именно бизнес-логику пилить на части. 1) Микросервис просмотра ответов на stackoverflow отправляет 2) в микросервис личного кабинета пользователей информацию о голосах за вопросы и ответы этого пользователя, 3) отправляет это в микросервис определения баджиков, 4) который в свою очередь отправляет информацию о баджиках в микросервис личного кабинета 5) если у вопроса слишком много голосов против, то отправляется запрос в микросервис анализа отрицательных оценок, 6) который отправляет запрос в микросервис модерации, 7) который отправляет запрос в микросервис подбора наиболее подходящих модераторов, 8) всё это отправляет запросы в микросервис рассылки push-уведомлений и 9) в микросервис рассылки уведомлений по email.
И всё по фэншую, каждый микросервис пилит отдельная команда. Если какие-то микросервисы отвалились, ну, остальные-то работают. Баджики, например, перестали отображаться или push-уведомления приходить, ну и фиг с ними, вопросы всё равно можно просматривать. Или те же базы данных, сейчас у них 4 жалких MS SQL сервера, два из которых резервные - это просто смешно. А могло бы быть штук 20 или 30 разных серверов! Монго там всякие и т.д. Это бред для всего приложения использовать одну СУБД. Хотя у них и не одна: Redis, видимо у Tag Engine и Elastic Search тоже свои базы. Значит не всё потеряно, хотя, блин, работай я в stackoverflow, чувствовал бы свои права ущемленными, я думаю, что для многих задач графовая база данных или Монго зашли бы гораздо лучше, или допустим я в файлах хочу хранить какие-нибудь вещи. Хмм... эти данные могут понадобиться кому-нибудь ещё за пределами моего микросервиса? - Ну напишу им апишечку для доступа к этим данным, в чем проблема, какая им разница как они у меня хранятся. У данных странная структура и они вообще не бьются с данными в других микросервисах? - Ну, во-первых, Сага должна была гарантировать целостность данных, во-вторых, что мешает создать отдел базистов, пусть пишут ETL-процедуры, мне удобнее хранить данные в графовой базе, почему я должен подстраиваться под разработчиков из других команд. И вообще мне нужно фичи поставлять в прод, а не схему данных согласовывать.
Если учесть что у них там ещё всякие компании, вакансии, какие-то команды, дискуссии, опросы, рекомендации похожих ответов и т.д. ну блин, ладно не стали делать полсотни микросервисов, но штук 5 можно было сделать хотя бы ради дайверсити, аджалити, скейлабилити?!! Это в принципе не такое маленькое приложение как выглядит на первый взгляд. Можно было бы создать столько независимых команд разработки, такую инфраструктуру развернуть! А текущая инфраструктура вызывает просто смех.
PrinceKorwin
08.12.2023 13:16Всё-таки для микросервисов нужно именно бизнес-логику пилить на части
Всё верно. Архитекторы SO разбили логику на 2 микросервиса. Вы - на 9.
Нет чётких правил как именно нужно разбивать логику на микросервисы. Каждый делает это на свой вкус и по наитию.
То, что у них 2 микросервиса - не означает, что они сделали монолит.
SO сделало ставку на вертикальную масштабируемость (это видно по количеству выделенного CPU и памяти под инстансы). В их случае это сработало.
Они молодцы на самом деле, что не повелись на бушлит и не стали клепать по микросервису на каждый чих.
Ares_ekb
08.12.2023 13:16Это не микросервисы, а разные инстансы одного монолитного приложения.
PrinceKorwin
08.12.2023 13:16Смотрите из чего я исхожу говоря, что у SO всё таки микросервисная архитектура. Их монолитные приложения:
спроектированы и готовы для горизонтального скалирования
используют внешнее key/value хранилище чтобы хранить там контекст/состояние (пользовательскую сессию)
используют локальную память для кэширования (благо у них большинство данных read-only)
разные части логики находятся в разных "монолитных приложениях" (да, их всего 2, тем не менее это так)
Т.е.это всё то, за что любят микросервисы. Единственное у них отличие - это у них очень крупные и совсем не микро микросервисы. Но т.к. как нет единого мнения/стандарта как правильно разбивать логику на микросервисы и что такое "микро", то это не имеет принципиального значения.
В своё время я видел как большой монолит дробили очень мелко. Их архитекторы гордо держали флаг - одна фича = один микросервис. Видел как они сделали распределенный монолит и потом сливали один микросервис в другой.
SO нашли свою золотую середину - они молодцы. Тем не менее именно архитектура решения - это микросервисы.
Ares_ekb
08.12.2023 13:16разные части логики находятся в разных "монолитных приложениях"
У них не разные части логики запущены на разных серверах, там одинаковая логика. Просто stackoverflow самый крупный из их проектов, поэтому для него выделен отдельный сервер. Скорее всего, на втором сервере у них запущены десятки экземпляров этого же приложения (для каждого проекта - math.stackexchange.com, cs.stackexchange.com, ...). Но это всё монолиты, они особо не взаимодействуют между собой.
Например, мы делаем инструмент моделирования. Масштабируется он очень просто - для каждого заказчика или для каждого подразделения или даже для каждого большого репозитория моделей можно тупо запустить отдельный экземпляр приложения на отдельном сервере. Но это не делает архитектуру микросервисной. Обычный монолит. Одна и та же бизнес-логика просто реплицируется на множестве серверов. Вот, если дробить бизнес-логику на части: раздел моделирования, раздел анализа моделей, сервис генерации отчетов и т.д. и они как-то взаимодействуют между собой, то это уже можно назвать микросервисной архитектурой.
Более того, некоторые модули для части заказчиков не нужны. Их можно просто не включать в сборку. Т.е. разные экземпляры этого монолита могут включать разный набор модулей. А чтобы архитектура стала микросервисной нужно сделать очень простую вещь - каждый модуль должен запускаться отдельно. У нас много всего запускается отдельно - СУБД, Keycloak, Grafana и т.д., но это не модули приложения.
Иначе большинство приложений можно назвать микросервисными, практически везде есть СУБД, фронт и бэк запускаются отдельно, для аутентификации, мониторинга и т.д. тоже используются отдельные системы - но это тупо отдельные приложения с разным назначением, разрабатываемые разными компаниями.
На мой взгляд критерий микросервисной архитектуры очень простой - если данные, транзакции, пользовательские сценарии распределены по отдельно запущенным службам и чтобы всё это работало требуется координировать транзакции, то значит это микросервисы. А в stackoverflow все запросы обрабатываются одним монолитным приложением.
И вообще чем дольше я пишу этот комментарий, тем больше прихожу к тому что эта тема "монолит vs микросервисы" - просто высосанный из пальца маркетинговый булшит. Потому что не существует ни монолитов в чистом виде, ни микросервисов, в которых каждая функция запускается отдельно. У меня граница между этими двумя архитектурами проходит по наличию или отсутствию распределенных транзакций. Хотя и в монолитах они бывают.
PrinceKorwin
08.12.2023 13:16Посмотрите на их схему. Они выделили 2 домена - тэги с сам форум. Каждый деплоится и скалируется отдельно. Как обычные микросервисы.
... маркетинговый булшит. Потому что не существует ни монолитов в чистом виде, ни микросервисов, в которых каждая функция запускается отдельно.
Именно!
У меня граница между этими двумя архитектурами проходит по наличию или отсутствию распределенных транзакций. Хотя и в монолитах они бывают.
В моем понимании - монолит, это то, что может работать только целиком. Если вы попили все на сотню микросервисов, но падение любого из них приводит к неработоспособности большинства E2E сценариев - то у вас монолит. Не смотря на масштабируемость, независимость команд, распределенных транзакций и прочее.
PuerteMuerte
08.12.2023 13:16В моем понимании - монолит, это то, что может работать только целиком. Если вы попили все на сотню микросервисов, но падение любого из них приводит
Микросервисы от монолита отличаются как раз уровнем связности компонент, а не количеством независимых инстансов. Если у вас клубок из сотни софтин, общающихся по хттп, и падающих из-за падения одного, это всё ещё микросервисы. А если у вас кластер из десятка одинаковых инстансов, но каждый из которых самостоятельно обслуживает запросы, это монолит.
saboteur_kiev
08.12.2023 13:16Громкие цифры про миллиарды просмотров в месяц...
Вы же догадываетесь, что перформанс проектов следует рассматривать не в просмотрах в месяц?Ares_ekb
08.12.2023 13:16Нет, не догадываюсь :) А вы же догадываетесь, что нашей планетой управляют рептилоиды?.. Я думаю, что уровень пассивной агрессии и аргументации в моём комментарии вполне достаточен и соответствует вашему ;) Но мне всё-таки стало интересно, решил посмотреть статистику.
1,3 млрд. в месяц - это в среднем 30 тыс. запросов в секунду. В пике наверное бывает и больше. Можно сравнить с другими проектами (источники этой статистики не самые достоверные, но я и не научно-исследовательскую работу здесь провожу):
Google - 8,5 млрд. запросов в сутки или 6 млн. запросов в секунду
Яндекс - 1,6 млрд. запросов в сутки или 1 млн. запросов в секунду
Авито - 384 млн. наверное всё-таки просмотров, а не пользователей в месяц или 9 тыс. запросов в секунду
По сравнению с Google и Яндекс, да, не очень много, но у них и инфраструктура совершенно другого порядка. Кстати, интересно через какое количество микросервисов проходит каждый поисковый запрос, на сколько сложные там распределенные транзакции...
У Авито, на сколько я понимаю, как-раз всё на микросервисах. На 5:20 прикольный момент: если вы не хотите быть маленькой компанией, видите стратегический рост, хотите быть как Авито, то делайте труЪ микросервисы. Хотя цитата конечно вырвана из контекста, и наверное спикер не имел в виду, что всем срочно нужно переходить на микросервисы, а высказывался против shared database, но тем не менее прикольный момент.
Возвращаясь к исходной теме. Да, я считаю, что 30 тыс. запросов в секунду - это достаточно много. И подавляющему большинству проектов такая нагрузка даже близко не светит. Было бы интересно увидеть проект на труЪ микросервисах с распределенными транзакциями, Сагой и этим всем, у которого нагрузка выше. Возможно Amazon, но они пишут достаточно интересные статьи:
Scaling up the Prime Video audio/video monitoring service and reducing costs by 90%
The move from a distributed microservices architecture to a monolith application helped achieve higher scale, resilience, and reduce costs.
funca
08.12.2023 13:16Они изначально писали на Lambda Step Functions. Это довольно специфичная разновидность микросервисов, где каждая функция выполняется как отдельный инстанс. Наиболее простое решение в разработке, но костам получается самое дорогое.
saboteur_kiev
08.12.2023 13:16Миллиардов запросов в гугл и миллиардов просмотров заглавной страницы гугла - очень разные вещи. И у меня не было никакой агрессии, я указывал, что непонятно чего миллиард.


cross_join
08.12.2023 13:16Тесно перекликается с написанной 4 года назад "Блеск и нищета микросервисов"

mozg3000tm
08.12.2023 13:16Мне кажеться микросервисы это доведённая до апофеоза следующая мысль.
Есть такие запросы к апи, время выполнения которых тратится по большей части на выполнение кода фреймворка, а на выполнение целевого кода очень мало.Т.е. если N время выполнения кода фремворка при запросе апи, а M время выполнения кода в экшене (бизнес логики), то для некоторых запросов к апи отношение M/N -> 0 (стремится к нулю). Т.е. полезного кода почти не выполняется.
И естейственно тут возникает идея уменьшить код фреймворка настолько чтобы уменьшить N до нуля, т.е. чтобы выполнялся только полезный код программы, а не что-то ещё.
Получается для запросов у которые M/N маленькое (т.е. полезного кода мало) ускорение ответа апи упирается в этот предел (скорость фреймворка) и использование микрофремворка помогает в его преодолении.
А дальше уже большие дяди придумали распределённую систему, и в итоге забыли ради чего всё было затеяно...
Kelbon Автор
08.12.2023 13:16И как же это помогает... Если микрсервисы вызывают функции через интернет, передавая аргументы джсонами...
mozg3000tm
08.12.2023 13:16Раз. во внутренней сети между хостами может быть очень быстрое соединение.
Два. это может быть вообще один хост.
Три. это может быть передача данных через редис, через сокеты, и т.д., а не через сеть.
Но я не про парижскую коммуну, а про идею революции.
Kelbon Автор
08.12.2023 13:16очень быстрое соединение.
прям вот весь стек операционной системы, сериализация данных, десериализация и отправление по сети быстрее, чем разложить на стеке аргументы + инструкция call?
mozg3000tm
08.12.2023 13:16разложить на стеке аргументы + инструкция call
это синоним монолита? далее допускаю что да.
прям вот [...] ?
допустим если фрейморк на php выполняется за 160 ms, то думаю да, можно добиться что по сети будет быстрее на микрофреймворке который будет отрабатывать за 60 ms. Сделать соединение которое будет быстрее 100 ms думаю не так сложно...
Вообще существует много чего в этом плане. Оптоволокно, соединение через PCI (Express) чуть ли не со скоростью оперативки. Сетевые технологии раньше веба возникли и в корпоративных сетях ещё в конце 90х использовали много чего побыстрее Ethernet. А сейчас если используется виртуализация или докер, то тоже сетевой интерфейс очень быстрый.
Kelbon Автор
08.12.2023 13:16допустим если фрейморк на php выполняется за 160 ms
что такое "фреймворк выполняется" и куда пропадут эти затраты при создании микросервиса?
mozg3000tm
08.12.2023 13:16при создании микросервиса
А вы читали то что я писал? Я писал про микрофреймворк, а не про микросервис. И говорил про сеть лишь как один из вариантов. И в этом смысле я лишь отвечаю на тот вопрос который интересен вам, поэтому минусуя вы лишь говорите, что не хотите общаться на тему которая интересна вам. Я бы не стал использовать сеть интернет (как минимум).
что такое "фреймворк выполняется"
Для php это как вариант то, что показывает xdebugger profiler для функции main.

куда пропадут эти затраты при создании микросервиса?
почему вы меня это спрашиваете? Я вам предлагал делать микросервис или что? Я высказал вполне конретную мысль.
Есть такие запросы к апи, время выполнения которых тратится по большей части на выполнение кода фреймворка, а на выполнение целевого кода очень мало.
[...]
И естейственно тут возникает идея уменьшить код фреймворка настолько чтобы уменьшить N до нуля, т.е. чтобы выполнялся только полезный код программы, а не что-то ещё.
Получается для запросов у которые M/N маленькое (т.е. полезного кода мало) ускорение ответа апи упирается в этот предел (скорость фреймворка) и использование микрофремворка помогает в его преодолении.
Мне не хочется участвовать в деструктивной дискусии на неопределённую тему за которую меня ещё и минисуют, поэтому давайте уточним о чём мы сейчас говорим? Вы прореагировали на мой ответ на другой вопрос где тоже упоминается микросервисы, о которых я не упоминал, и не хочется уходить в дискусию на тему, которой для меня не было.
mozg3000tm
08.12.2023 13:16т.е. ещё раз моя мысль.
если вы используте фреймворк Symfony, то перейдя на микрофреймворк Slim или Silex при прочих равных вы выграете в скорости ответа просто потому что у вас будет выполнятся меньше кода фремвока, который должен быть запущен для того чтобы сработал ваш бизнес код. Всё. @Kelbon
Kelbon Автор
08.12.2023 13:16я не эксперт в микро и нанофрейморках, зато вижу как активно пропагандируется написание микросервисов на С++, где весь этот "код фреймворка" будет столько же отжирать в любом случае(только с микросервисами в большем количестве программ)
mozg3000tm
08.12.2023 13:16написание микросервисов на С++
Вроде бы сначала для CGI использовали Cи, поэтому это возвращение к истокам))). История замкнулась. Сперва делали без фреймворков на скриптах (в случае Си скомпиленных), потом перешли к фреймам, а сейчас опять переходят к скриптам только распределённым по микросервисам.
"код фреймворка" будет столько же отжирать в любом случае
более коректно сравнивать ЯП, а не фреймы в данном контексте.
Я лишь хотел поделиться мыслью которая как мне кажется коррелирует с микросервисами (использование микрофреймворков для лёгких запросов). И для микросервисов логично использовать именно микрофреймворки для уменьшения накладных расходов на исполнение кода. Хотя конечно сетевые задержки тут определяющие, но зачем прибавлять к ним больше чем минимально необходимо, раз уж вы решили делать распределённую систему.

Flying
08.12.2023 13:16Извините, но вынужден вас поправить. Ваша стрелочка на картинке для <main> должна всё-таки на колонку "Own time" ("Сама" в вашем случае) т.к. то, куда указываете вы, очевидно, собственное время выполнения + время выполнения всего, что оттуда было запущено.
Вы ведь, очевидно, видите, что сумма значений в первой колонке явно больше 100 т.е. значения там просто не могут быть составными частями общего времени выполнения.
Как раз наоборот, из вашего скриншота явно видно, что лидеры по потреблению времени - это 2-я и 4-я строки, а <main> относительно них занимает очень мало, как и должно быть.
mozg3000tm
08.12.2023 13:16собственное время выполнения + время выполнения всего, что оттуда было запущено.
Я предположил что вызов первой функции main (кстати, это файл index.php) и всего что было вызвано дальше можно выдать за "что такое "фреймворк выполняется". Мне нужно было пояснить именно этот момент.
лидеры по потреблению времени - это 2-я и 4-я строки
Кстати это получается два автозагрузчика классов. Один движка php, другой фрейма.
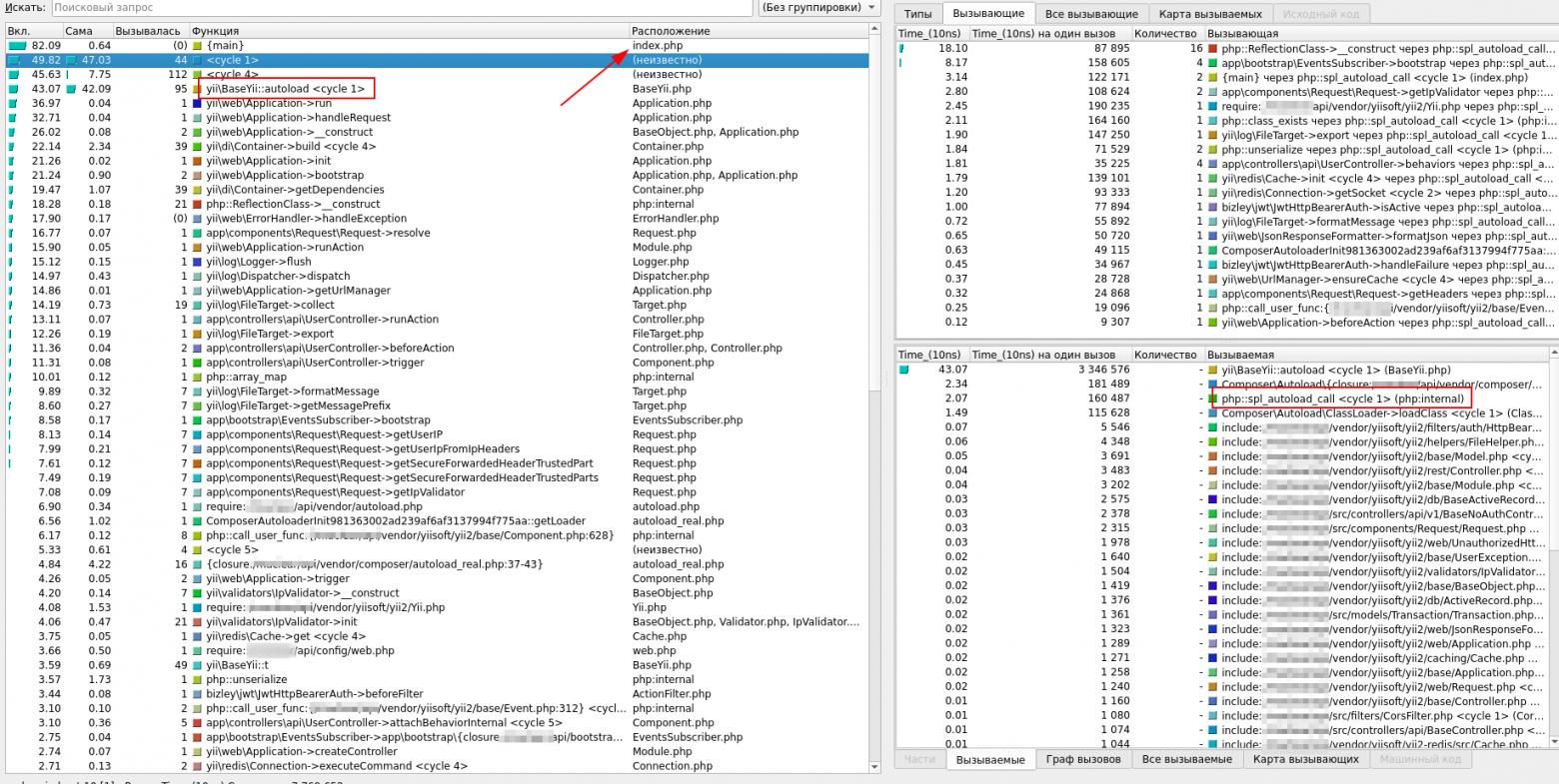
bert2000
08.12.2023 13:16если это один хост, зачем вообще тогда гонять туда-сюда данные, создавая по-сути лишние их копии,и тупо поедая ресурсы? Притом поедается как и память на хранение лишних копий данных, так и процессорное время на сериализацию и десериализацию данных, зачастую не бинарных.
mozg3000tm
08.12.2023 13:16зачем вообще тогда гонять туда-сюда данные
На этот счёт мне припоминается, что если есть две программы на компе (линукс), то передать между ними данные можно только через что то внешнее, типа сокетов или файлов. Напрямую ОСь не даст вам шарить память между прогами (там наверное есть варианты всякие, но я не про это...).
Т.е. я имел ввиду что у вас есть как минимум два движка. Один допустим на Symfony, другой на Slim (микрофрейворк) для лёгких запросов или как в статье упоминается для чего-то тяжолого типа перекодировки картинок. Соответственно вам нужно их связать.
mvv-rus
08.12.2023 13:16На этот счёт мне припоминается, что если есть две программы на компе (линукс), то передать между ними данные можно только через что то внешнее, типа сокетов или файлов. Напрямую ОСь не даст вам шарить память между прогами
У меня - друугие сведения: https://www.man7.org/linux/man-pages/man7/shm_overview.7.html
mozg3000tm
08.12.2023 13:16(там наверное есть варианты всякие, но я не про это...)
Допустим.
Согласно вашим сведениям я могу произвольно связать так два приложения, особенно если это скрипты на рантайме?
Допустим я запускаю два скрипта на ноде
node ./server-1.js node ./server-2.jsя смогу расшарить память для них?
и даже если смогу не будет ли это слишком большая привязка к оборудованию?
mayorovp
08.12.2023 13:16Сможете, однако в случае с JS вы один фиг не сможете обойтись без сериализации.
Потому что JS умеет шарить лишь буферы, но не объекты.


funca
08.12.2023 13:16Everything Should Be Made as Simple as Possible, But Not Simpler
Делайте всё как можно проще, но не слишком упрощайте.
Я согласен, что польза от микросервисов переоценена и в эту повестку было вложено много облачного маркетинга. Но если у вас паранойя это ещё не значит, что нужно их бояться.
Monolith-first может быть хорошей тактикой в определенных ситуациях. Например, если вы делаете с нуля и пока не вполне понимаете, что именно вам нужно. Или собираете PoC. Но если ключевые критерии уже известны, то нужно проектировать подходящее решение.
mrsantak
08.12.2023 13:16Но если ключевые критерии уже известны, то нужно проектировать подходящее решение.
Проблема этой фразы в том, что она неявно противопоставляет монолит и подходящее решение. А это противопоставление ложно, очень часто именно монолит является оптимальным решением.
funca
08.12.2023 13:16Проблема этой фразы в том, что она неявно противопоставляет монолит и подходящее решение.
Нет, я имел ввиду, что монолит это не единственный вариант. (хотя, в этой фразе уже два противопоставления. .. А в этой - одно. ;) Подходящее решение может быть монолитом, а может и не быть.
Архитектура в большей степени зависит от нефункциональных требований. Решения на 10 и 1 000 000 пользователей это принципиально разные решения, как по технологиям, так и по деньгам. Eсли у вас 1 000 000 пользователей, то нет смысла делать на 10 - и наоборот.
bert2000
08.12.2023 13:16Стоп стоп стоп. Объясните мне глупому, что мешает в первый же день (нулевой) заложить в архитектуру "монолита" 5-10 слоёв? Отделить сразу мух от котлет? Ну хотя бы из уважения к SOLID, KISS, DRY и MVC ??
Зачем изначально закладывать в проект бомбу замедленного действия?
Можно ведь разделить слои данных, логики и морд, в первый же день проектирования всего приложения.
Какие могут быть оправдания игнорированию базовых архитектурных требований?
ioncorpse
08.12.2023 13:16Никто не отрицает. Даже для PoC в первый же день слоев 5-10 появится. Думаю это не написано т.к. очевидно.
bert2000
08.12.2023 13:16Не не не. Это либо не очевидно, либо "не те слои".
Нормальная архитектура, модульная, как раз позволяет нормально порезать прилу на кучу слоёв, и потом менять и заменять их.
Сейчас же в отрасти очень много "фейков", и подмены понятий, в т.ч. отсутствие правильного понимания паттернов проектирования, и их подмена. Что в итоге приводит именно к тому самому "монолиту" (слипшемуся куску), в котором гибкости ноль и распилить его просто невозможно. Я об этом.Все программные компоненты монолитной системы взаимозависимы из-за использования встроенных механизмов обмена данными внутри системы. Модификация монолитной архитектуры возможна лишь частично и занимает много времени, поскольку даже небольшие изменения затрагивают большие области базы кода.
(Амазон) Ключевые отличия монолитной архитектуры от микросервисов
Если же мы ведём речь о нормальном гибком проекте, с модульной архитектурой, тогда назвать его "монолитом" уже язык не поворачивается. Пилится на куски такой проект довольно легко, и модули легко заменяются или правятся.
Собрать из такого проекта какой-то "новый", с небольшим допилом, тоже вполне тривиальная задача.
Даже в статье Амазона о монолитах и микросервисах много лукавства. Хотя и фактов тоже полно. Очевидно отражена бОльшая сложность микросервисной архитектуры, и неимоверная сложность её отладки.
В плюсы микросервисов же скопом засунули "все недостатки" "монолитов". Т.е. изначально из крайности в крайность.
Гибкой модульной архитектуры Амазон даже не предполагает. И либо неделимый монолит (без модулей и изоляций) либо "волшебные" (на деле ни разу) микросервисы.Из крайности в крайность в общем. О чём я и пишу уже в сотый раз.
Истина же в том, чтобы не впадать в крайности и следовать канонам программирования, известным уже более полувека.PuerteMuerte
08.12.2023 13:16Все программные компоненты монолитной системы взаимозависимы из-за использования встроенных механизмов обмена данными внутри системы. Модификация монолитной архитектуры возможна лишь частично и занимает много времени, поскольку даже небольшие изменения затрагивают большие области базы кода.
Когда вы находите подобные определения, имейте же в виду, что их пишут чуваки, которые продают свою работу. Не суть важно, как продают, на широком рынке, или там топ-менеджерам внутри своей компании, но продают. А когда продаёшь, надо хвалить своего слона, умалчивать про его недостатки, и преувеличивать недостатки других слонов.

kazimir17
08.12.2023 13:16Например у меня сложилось впечатление что такая +/- известная в Мск компания "Утконос" погибла из-за попытки переписать огромный монолит на SAP (который разрабатывали 15 лет) на пучок микросервисов на Java. Что повлекло за собой многократное увеличение отдела разработки и вероятно дыру в бюджете. Грустно было наблюдать это изнутри.
shornikov
08.12.2023 13:16Сервера стоят дешевле, ага.
Приятель прислал скрин, где вся UX-консоль в ядрах CPU и на всех 0-1%. И, удивительно!, гораздо дешевле платить за этот оверхеад, чем нанять девопса, который за собой еще неизвестно, что потянет (вспомним статьи типа "как я оказался должен AWS $200K").

titan_pc
08.12.2023 13:16Квантовые сервисы нужны. Которые берут лучшее из обоих миров - монолитов и микросервисов.
Ну а вообще, микросервисы - это легко. Сложного там ровным счётом ничего. Просто люди обленились и делать работу не хотят. И когда приходит новый спец говорит примерно следующее: "Ой тут какой-то криворукий мастер делал. Наусложнял всё. Мне нужно 500к за в месяц и 20 лет на переделку"

hVostt
08.12.2023 13:16Хейтить микросервисы теперь также модно, как не так давно хайповать на этом. Примеры и тезисы просто прекрасные: надо выбрать максимально неудачные ситуации, или обстоятельства, где это изначально было не применимо.
Всё верно. Микроскоп хуже молотка. Ой, только не надо про гвозди! Просто хуже. Поверьте. У соседа сарай развалился, потому что он микроскоп использовал.
PuerteMuerte
08.12.2023 13:16Хейтить микросервисы теперь также модно, как не так давно хайповать на этом.
Потому что их много. Слишком много.
Всё верно. Микроскоп хуже молотка.
Плохая аналогия подобна котёнку и всё такое.
hVostt
08.12.2023 13:16Посыл не верный. Из-за безумного хайпа микросервисы начали внедрять туда, где им не место. Из-за безумного хейта, микросервисы теперь будут бояться применять, где им место. Оба тренда вредные, потому что несут деструктивные и глупые черно/белые идеи. Если вы видите перед собой адепта микросервисов или адепта монолитов, эти оба два паршивые специалисты, их нужно отстранить от участия в разработке архитектуры.
Kelbon Автор
08.12.2023 13:16Да, конечно категоричное мнение обычно ведёт к неправильному выводу, но зачем вообще называть что-то микросервисом? Ну вот есть сервер-клиент, они называются не сервис1, сервис2, а сервер и клиент. По их назначению, они не просто так разделены и в этом есть смысл. Также и в целом - есть какая-то архитектура, в ней есть какие то модули, почему они называются не осмысленно, а "микросервис1, микросервис2" или так, как могли бы называться просто функции/классы? Вот где беда. Встретить адекватную архитектуру где что-то называется микросервисом это какое-то чудо
hVostt
08.12.2023 13:16Ну вот, если разобраться в отличиях архитектур, то проблем не будет. У нас есть монолит из 12 отдельных приложений. Одно из них реализует только одну небольшую функцию. Но никакого отношения к микросервисам это не имеет. Разработка из единой кодовой базы, общие компоненты, интерфейсы, релизный цикл единый, команда одна, БД общая. Ни одно из приложений без остальных не имеет смысла. Монолит.
bert2000
08.12.2023 13:16Не не не. Микросервис вполне осмысленное понятие. Из области одна функция= один микросервис.
Более масштабные решение уже сервисы или мини сервисы хотя бы.
Но вы правы с том, что очень многие уже наелись с микросервисами, с крайность этой, и возвращаются к золотой середине в виде сервисов .
У микросервисов есть своя ниша и свои плюсы. Но использовать их надо очень аккуратно и по минимуму.
PuerteMuerte
08.12.2023 13:16Посыл не верный. Из-за безумного хайпа микросервисы начали внедрять туда, где им не место. Из-за безумного хейта, микросервисы теперь будут бояться применять, где им место.
Фишка в том, что мест для микросервисов в общем-то не так чтобы сильно много. Я не считаю тренд на отказ от микросервисов вредным, наоборот, в тех случаях, где микросервисы внедрены успешно, где в них есть потребность, никто от них отказываться не будет. Но я не ошибусь, что если даже 100% стартапов не будут использовать микросервисы, ничего плохого не произойдёт. Потребность в серьёзном масштабировании в любом случае возникает далеко не на начальном этапе развития бизнеса.
hVostt
08.12.2023 13:16Судя по комментариям, плюсам и минусам, я лично наблюдаю типичную "охоту на ведьм". Любой подробный тренд исключительно и абсолютно вредный для инженерной дисциплины. Это не мир мод, платьев в горошек и красных трусов.
Микросервисы это не обязательно "потребность в масштабировании". Монолиты вполне себе масштабируются. Вообще, если взять любой аспект работы ПО, то он может отлично работать и в той и в другой архитектуре.
А вот статьи типа "компания А использовала микросервисы и прогорела", это желтушная подача. Какие ошибки были допущены, как вот здесь это плохо работает и почему, с выкладками? Нет. Нет времени объяснять, микросервисы просто плохие. Прими это, потому что думать и владеть информацией не модно. А если считаешь иначе, лучше не отсвечивать со своим мнением -- загнобят. Так как сейчас иная позиция это моветон.
Выглядит как цирк с конями. Только вместо коней монолиты и микросервисы.
bert2000
08.12.2023 13:16Согласен. Инженерные технологии это не мир мод. Тут надо руководствоваться опытом и расчетами, а не сказками и слухами.
Но кто чем руководствуется каждый решает сам. И сам обязан отвечать за свои модные, но не оправданные, решения.
PuerteMuerte
08.12.2023 13:16Судя по комментариям, плюсам и минусам, я лично наблюдаю типичную "охоту на ведьм".
Но ведьмы-то настоящие в данном случае. Весь этот "обратный хайп" - прямое следствие того, что индустрия внедряла это налево и направо, и ... теперь оно и слева, и справа работает хреново.
А вот статьи типа "компания А использовала микросервисы и прогорела"
Я вот прямо сейчас подрядчик хрестоматийного примера компании В, пытаюсь сделать так, чтобы она не стала компанией А. Компания В получила когда-то инвестирование, и начала делать продукт Р. Продукт Р в принципе не уникальный, рынок В2В, но и конкурентов не так, чтобы много. Делалось дорого-богато - три команды субподрядчиков, у каждой россыпь микросервисов, всё тип-топ, масштабирование, кубернетис и т.д. Но вот сейчас деньги инвесторов слегка совчсем подзакончились. Компания ещё только-только на рынке, у неё свой поток небольшой. А вот инфраструктура под весь этот колхоз жрёт как не в себя. И вот мы сейчас и занимаемся тем, что ищем, что выкинуть и что можно объединить.
И знаете что? Я вряд ли ошибусь, если скажу, что подавляющее большинство компаний А прогорело потому, что неправильно сопоставили свои затраты своим инвестициям/капиталу, а значительную роль в размере их затрат и на разработку, и на эксплуатацию, сыграли наши друзья-микросервисы.
ItsNickname
08.12.2023 13:16Каждая компания хочет быть FAANG, но почему-то денег есть только на ведро карасей.
Я всегда предлагаю сначала кидать деньги на тупое наращивание мощности сервера в лоб. В облаках ещё проще, давайте просто использовать модель "плати за ресурсы". И знаете часто оказывается что затраты на разработку феншуя будут соить как 100 лет аренды самых дорогих лухари решений в Ажуре или AWS.
bert2000
08.12.2023 13:16Хайпы и хейты это вопросы базовой психологии человека. Обычно человека в первую необразованного! Т.е. далеко не инженера!! Человека, который подвержен прежде всего мимолётным эмоциям, а не здравым рассуждениям.
Инженеры основываются в своей работе знанием, расчётами и опытом, а не модными фичами и хайпами с хейтами.
Да и любые хайпы грамотные инженеры, прежде чем запускать их в работу, сначала проверят на себе (если дураки и учатся на своих ошибках), ну или посмотрят реальные "успешные" истории других (или неуспешные, учиться надо на чужих ошибках). Изначально любые новшевства (так уж природой заложено) обязаны восприниматься в штыки, пока не доказана их явная польза.
Вопрос же в том, что индустрия вся поголовно отказалась от мозгов и инженерных подходов, и полезла хайповать хрен знает куда. А теперь распробовав сей горький (но вполне предсказуемый) вкус (по сути отсутствия пользования могом) начинается вполне закономерный хейт. Ведь по-сути вся индустрия "в дураках", и "повелась" на "модные фичи".
А ведь это программирование, а не мир фейшена.hVostt
08.12.2023 13:16Сталкивался с двумя крайностями.
Микросервисы:
На собесе кандидат спрашивает, а у вас микросервисы? Если нет, я к вам не пойду!
при разработке крупного проекта, начали делать микросервисы, не понимая абсолютно зачем, какую задачу этим решают. Через полтора года разработка проекта провалена, все сроки сорваны, результат "конь не валялся". Потому что не решали бизнес задачу, а делали микросервисы.
Монолит.
Ярый адепт монолита, ведущий сеньор-помиидор, реализовал задачу, которая как раз должна была быть микросервисом, прям в монолите. Задача сделана, через пол года начались проблемы разного характера, зависимость, простои в релизах, и даже аварийные ситуации, так как функция не должна была влиять на общий проект, но чудес не бывает. Потом конские затраты на выпиливание таки в отдельный микросервис. Финансовые и репутационнве потери. Почему? Потому что фанатик мАнАлитов отдал предпочтение своей религии, а не разуму.
И все это, результат трендов. Вместо адекватных статей, описывающих когда, где, что уместно применять и почему, обычные лозунги: вот это -- плохо! а это хорошо! И да, люди и целые компании на это легко ведутся.
Зачем же мы поддерживаем такие тренды? Неужели мы тупые? Не надо так.
bert2000
08.12.2023 13:16да, это именно крайности. И в них впадать нельзя.
золотая середина (и давно) - это гибкая архитектура, но без фанатизма.вот не знаю зачем такие тренды поддерживаются. Но как по мне, всё это от отсутствия знаний и опыта.

remendado
08.12.2023 13:16Создание микросервисов это минное поле // все что остается, если из поста выжать воду.

werevolff
08.12.2023 13:16Какая-то странная мода пошла: оформлять однобокое мнение кликбейтными заголовками. Например, "Почему вам точно нужны микросервисы" и на другом ресурсе "Смерть от микросервисов". А если эти статьи будет выпускать один и тот же автор с разницей в неделю, будет ещë забавней.
К чему это приводит? Раньше были комплексные статьи или книги, в которых, в большинстве случаев, описывались плюсы и минусы подходов. Приводились списки факторов для удачного выбора технологии. И это было прекрасно! Сейчас, на рынке есть специалисты которые выступают ЗА определëнную технологию/дизайн системы потому, что читали статью "100500 причин, почему вы обязаны выбрать этот подход", и спецы, которые выступают ПРОТИВ технологии (дизайна системы) потому, что читали статью "вы будете страдать, если начнëт использовать эту технологию".
Я лично за здравый смысл.

rukhi7
08.12.2023 13:16Сейчас, на рынке есть специалисты которые выступают ЗА определëнную технологию/дизайн системы ... и спецы, которые выступают ПРОТИВ технологии (дизайна системы)
Настоящую технологию (дизайн системы) для решения технических задач вряд ли можно выразить в одно какое-то слово, например "микросервисы". Но одно слово очень подходит для технологий манипуляции сознанием, мне кажется.
Мне это что-то напоминает... Что-то из прошлых времен. Перефразируя одно очень известное высказывание из прошлого века:
Что такое счастье — это каждый понимал по-своему. Но все вместе люди знали и понимали, что надо честно жить, много трудиться и крепко любить и беречь эту огромную счастливую технологию, которая зовется Микросервисы/Монолит/... <подставьте свое>.
werevolff
08.12.2023 13:16Ну, как бы MSA - это вполне себе оформленный поход к дизайну. С точки зрения docker + оркестратор (DevOps), MSA - технология. С точки зрения архитектора - дизайн архитектуры. Не понимаю, что вы ещë хотите вместить в это слово. MSA, как и другие подходы к дизайну систем, может быть уместной, неуместной, хорошо или плохо реализованной. Единственное, в чëм я нахожу логику статьи: монолитные стартапы имеют больше шансов на успешный запуск, поскольку, в большинстве кейсов, монолит лучше отвечает определению MVP, нежели MSA. Но это не всегда корректно. Есть кейсы, в которых SOA/MSA нужны прямо на старте. Например, когда монолит сразу выглядит слишком сложным решением. Например, при автоматизации процессов предприятия, где можно выделить конкретные домены: документооборот, CRM, закупки и т.д. здесь проще закрывать потребности по-одной, чем пилить "супер-киллер-мега-портал-убийца-Битрикса-666".
Kelbon Автор
08.12.2023 13:16документооборот, CRM, закупки и т.д. здесь проще закрывать потребности по-одной
вы решили весь мир назвать микросервисвной архитектурой, ведь я использую браузер, отдельно использую какой-то steam и тд? Это абсолютно разные программы, они никак между собой не связаны и это никак не относится к микросервисам. Так и в вашем примере, решается это банально разными программами
werevolff
08.12.2023 13:16Вы утрируете. Я говорю о применении Закона Конвея, а вы - об использовании вами браузера и steam.
rukhi7
08.12.2023 13:16Все что вы перечислили очень здорово и замечательно. Только подавляющая часть софта в использовании сделана уже 20 лет назад, когда этих слов и аббревиатур в помине не было. Представляете, тогда никто не рассуждал про
монолит , MVP, MSA , docker + оркестратор (DevOps) , ...
И многое из того что тогда было сделано до сих пор используется и работает. Да! Тогда были модными другие слова и аббревиатуры, кто их теперь помнит? Почему то никто не рассуждает как сделано то что работает, модно рассуждать о том что является современной технологией, вообще не вспоминая о задачах предметной области, которые, вообще говоря, уже неоднократно были решены. Все! Может кроме некоторых ответвлений вероятностного анализа, который модно называется исскуственным интелектом.
Расскажите чем концепция компонент хуже чем концепция микросервисов? Или в чем там новизна, что там есть такого, что не было известно 20 лет назад?
werevolff
08.12.2023 13:16Вы ещë коктейль "три пшика" вспомните и приплетите. Если есть что сказать по делу - буду рад обсудить. Если на ностальгической философии ваши рассуждения заканчиваются, то это вам к друзьям в гараж с коньяком.

RichardMerlock
08.12.2023 13:16Постойте! Настала пора макросервисной архитектуры! Все тесноработающие микросервисы засовываются в один контейнер и общаются по сети, которая не покидает контейнер!

Sunrise33g
08.12.2023 13:16Как раз в этом есть смысл на ранних этапах разработки и внедрения продукта. Как с организационной стороны, так и с перспективами на будущее масштабирование.
Как только ресурсов одного сервера начинает не хватать - самые нагруженные сервисы выносятся на другие серверы. Как только продукт теряет пользователей и, соответственно, нагруженность - отдельные сервисы снова переезжают на одну машину. И так там и остаются до закрытия продукта.
В итоге затраты получаются минимальны, код отдельных сервисов можно без переиспользовать в других продуктах, а инфраструктуру можно раздувать и сдувать за короткое время без особого труда.

mrise
08.12.2023 13:16Мне кажется, что макросервисы - это немного другое. Если микросервисы - это про выделение маленьких кусков функциональности и засоввывании их в отдельные масштабируемые сервисы, то макросервисы - это про выделение больших независимых блоков функциональности в отдельные немасштабируемые монолиты на основе технической необходимости.
Притом в предельном случае макросервисная архитектура должна быть возможна с единственным монолитом, если все блоки функциональности взаимозависимы, и нет технической необходимости их разделять.
А то, что вы написали, очень напоминает OSGi (только там "контейнеры" не общаются по сети).
bert2000
08.12.2023 13:16а зачем им общаться по сети (туда-сюда гонять данные и тратить память на копии и проц на упаковку/распаковку данных), если их можно сразу друг на друга завязать в едином модуле / сервисе?
RichardMerlock
08.12.2023 13:16Можно было бы общаться через общую память, но по ходу это давно в прошлом...

Lavrofff
08.12.2023 13:16Попробуйте пописать на плюсах какой-нибудь большой проект и потом при каждом изменении все пересобирайте. Хоть на скольки ядрах. Сервисы которые можно просто собрать (или либы для них) намного предпочтительнее. Сборка минуту и сборка часы при любом изменении это очень сильная разница.
Kelbon Автор
08.12.2023 13:16Во-первых, адекватно написанный проект на плюсах пересобирается после изменений за несколько секунд + линковка, в прям modern C++ помогают ещё и модули
Во-вторых, отдельным репозиторием представленная библиотека собирает вовсе только свои тесты и их запускает, а проект её использует как зависимость.
Вкратце:
Попробуйте пописать на плюсах какой-нибудь большой проект и потом при каждом изменении все пересобирайте.
а вы не всё пересобирайте

gandjustas
08.12.2023 13:16Чтобы ускорить сборку С++ нужны микросервисы?

Stan88
08.12.2023 13:16Вот вам и яркий пример почему микросервисы суют везде, даже не понимания зачем)
pavelsc
08.12.2023 13:16>>Многие имеют монолит до сих пор. StackOverflow считают за предмет гордости то, как мало железа им нужно для работы массивного сайта. Shopify всё ещё на монолите Ruby on Rails
Автор, вы вообще разработчик или "околоменеджмент", продающий бизнесу монолиты и прочие антикризисные "оптимизации" за процент?) Для вас Spotify и Shopify создаётся впечатление как будто бы одно и то же, потому что на "фай" заканчивается. Вы понимаете, что стриминговый сервис в принципе не должен быть монолитом, даже если он на 100 человек или для вас это rocket science? Это касается какого угодно сервиса, который делает что-то большее, чем перекладывание json. Неимоверно круто наверное пользователям получать фризы и зависания от апи, потому что условный ffmpeg декодер съел всю память на сервере, тупо из-за того, что кое-кто решил продавать себя с помощью сутулых аргументов вроде "олды вообще не понимают зачем нужны микросервисы и боятся их".
Kelbon Автор
08.12.2023 13:16Для вас Spotify и Shopify
это вы где нашли в приведённой цитате спотифай
стриминговый сервис в принципе не должен быть монолитом
а чем же он должен быть. Или деление на модули/запуск нескольких инстансов это уже всегда микросервисы? Да если бы кто-то умудрился сделать стриминг на том на чём сейчас пишут микросервисы с теми же "технологиями", то мы бы грузили картинки со скоростью интернета 90х

1Tiger1
08.12.2023 13:16ожидание : анализ преимуществ, недостатков и тонких моментов (микро) сервисной архитектуры. рекомендации где и когда использовать (а где нет) , на что обратить внимание и как не сделать только хуже.
реальность: ирония, ролик про тупого разработчика, кривые аналогии, ирония, чуть получше аналогии, экскурс в историю, ведро сарказма, я путаю архитектуру приложения/проекта и архитектуру кода но это не страшно, опа экономика и менеджмент, "соскучились по сарказму? ловите", начинать можно с монолита (спасибо кэп! это так неожиданно. ), "а что если вместо микросервисов использовать ООП".
хотите открою великий секрет разработки? : silver bullet не существует.
хотите второй? : каждый инструмент и подход имеет смысл в определённых условиях и будучи правильно использованным. понимание где и как их использовать и есть главный навык разработчика.
только тсс, никому, это тайна известная лишь избранным.
Kelbon Автор
08.12.2023 13:16Честно говоря у меня. после опыта работы с людьми, делающими микросервисы, ничего кроме сарказма уже не остаётся. Приводить им аргументы, анализы и графики - довольно неблагодарное дело. С другой стороны будет яркий весёлый
TikTokадепт микросервисов, который без каких-либо аргументов, зато весело и задорно, расскажет как же нужно писать код. И его услышат, его "поймут", потому что для этого думать не надо1Tiger1
08.12.2023 13:16я это слышал буквально про все. фреймворки, архитектурные приёмы, языки, инструменты, подходы. даже про ООП такое слышал, раз десять. ещё раз : отказываться от чего-то категорически, так же нелепо как и следовать чему-то категорически. мастерство программиста, его главный "опыт" это что, почему и как применить для решения задачи. есть ещё майндсет но это не относится к тебе беседы, поэтому основным будем считать этот навык.
и как не применять. с микросервисами можно накосячить. с монолитом можно накосячить (вообще легко, пару лет активной разработки на пару команд без жёстких и всем понятных стандартов и "успех" гарантирован). с архитектурой и ООП накосячить вообще легко. без них не накосячить на крупном проекте почти невозможно. но если уметь все это использовать и понимать плюсы, минусы и риски то можно не косячить. это все инструменты, и вы выбираете их в зависимости от задачи, и правильно используете. не забивайте гвозди пассатижами, не закручивайте шурупы ножом, когда используете молоток аккуратнее с пальцами, гвозди в керамичкскую плитку плохая идея. ударили себе по пальцам молотком - учитесь им пользоваться а не кричите что гвозди зло. ударили вам по пальцам - та же фигня, виноват тот. кто держит молоток а не гвозди с молотком. внезапно, да?
а что у вас за стороны? вы там что за лайки и аудиторию боретесь? где? и зачем тогда вы отзеркаливаете этого "адепта тикток" и несёте такой же неаргументированный эмоциональный поток сознания, не имеющий никакой практической и теоретической польщы? чтобы думать не надо было? в чем смысл этот "сражения"?
Kelbon Автор
08.12.2023 13:16неаргументированный эмоциональный поток сознания
во-первых, я всего лишь перевёл статью.
во-вторых, в статье вполне есть аргументы, хотя во второй её части и более слабые, чем могли бы быть
в-третьих, общественное мнение и культуру меняют не научные статьи, которые прочитали 2 гика, а "популярные" статьи, заставляющие хотя бы задуматься и оглядеться, не бояться делать "не как принято" и начать реально выбирать, думать
funca
08.12.2023 13:16общественное мнение и культуру меняют не научные статьи, которые прочитали 2 гика, а "популярные" статьи, заставляющие хотя бы задуматься и оглядеться
Постмодернизм который мы заслужили.
bert2000
08.12.2023 13:16Так у вас нет ни одного аргумента. Закидывание опытнейших олдов не аргумент совершенно. Скорее показывает ваш уровень, чем уровень олдов
1Tiger1
08.12.2023 13:16каких олдов? вы про что вообще? тут что теперь длиной опыта меряются? ну доставайте, чего уж тогда, я за линейкой схожу.
bert2000
08.12.2023 13:16Про олдов я не вам писал. Промахнулся где-то видимо. Сорри
Не смотря на то что якобы Сильвер Буллет не существует, есть вполне золотая середина, оправдывающая себя годами. И это точно не крайности в виде огромного плохо пахнущего монолита или огромного неуправляемого роя мух Аля микросервисы.

powerman
08.12.2023 13:16При всём том, что описанное в статье имеет место быть - это только половина правды. И это сильно искажает реальность. Да, микросервисы это сложно. Но ведь монолиты - это тоже сложно! И текущая ситуация (из заголовка статьи) вызвана как раз тем, что монолиты это сложно, и эту проблему попытались решить переходом на микросервисы.
Микросервисный подход не убирает сложность монолита, а перераспределяет её: частично на уровень проектирования архитектуры связей между микросервисами, частично в тулинг, частично на девопсов. Этот подход позволяет значительно уменьшить когнитивную нагрузку на разработчиков, заплатив за это увеличением нагрузки на архитекторов и девопсов. Стоит ли это того в конкретном проекте - зависит не только от того, какую нагрузку должен тянуть проект, но и от того, какие кадры доступны в этом проекте: если на проекте много сильных разработчиков, то им вполне может оказаться проще осилить монолит, а если на проекте в основном средние разработчики но есть сильный архитект, то проще написать микросервисы. Аналогично, если в компании нет необходимого для проекта количества разработчиков на одном языке, но есть на нескольких языках - написать микросервисы может оказаться проще, чем пытаться всех переучить на один язык чтобы сделать монолит.
Далее, монолит сам по себе не избавляет от значительной части тех сложностей, которые принято ассоциировать с микросервисами:
Как только в проекте появляется поддержка мобильных и/или десктопных приложений-клиентов, монолит оказывается вынужден так же поддерживать версионирование API и несколько версий API одновременно, как принято у микросервисов.
Как только вертикального масштабирования единственного инстанса перестаёт хватать или бизнес выдвигает требование гарантировать доступность проекта даже если один из серверов умер - появляется необходимость использования тех же кластерных технологий, которые обычно используются с микросервисами (реестры сервисов, распределённые конфиги, кеши в отдельных сервисах, кластерные БД, …). И если монолит изначально это не учитывал, то переделать его может оказаться очень тяжело. А если учитывал, то его изначально было писать заметно сложнее.
Помимо наших собственных микросервисов большинство проектов использует API сторонних компаний. И чтобы его корректно использовать нам даже в монолите необходимы все те сложности, которые почему-то ассоциируются только с микросервисами: версионирование API, RPC, повторы при ошибках с экспоненциальными задержками, etc. А если мы в монолите уже имеем необходимый для этого бойлерплейт, то от его использования и для наших собственных микросервисов ничего принципиально сложнее не станет.
Да, если монолит писать в виде изолированных друг от друга модулей, каждый из которых владеет собственными данными, то это позволит снизить когнитивную нагрузку на разработчиков так же, как и с микросервисами. Но эта сложность снова не исчезнет, она будет перераспределена на архитекта, которому нужно будет спроектировать все эти модули и связи между ними ровно так же, как и в случае микросервисов. И реализовать этот подход на практике можно только при условии, что тулинг (или сам язык) позволяют гарантировать, что модули в монолите будут взаимодействовать только через спроектированный архитектом API - иначе этот монолит неизбежно слипнется в большой комок грязи рано или поздно (скорее рано).
При этом разработка микросервисов в одном репо и на одном языке тоже убирает значительную часть сложности микросервисного подхода, и, по большому счёту, от модульного монолита отличается только оверхедом на RPC вместо локального вызова функций (который абсолютно не критичен для большинства проектов).
В конечном итоге выбор между обычным монолитом, модульным монолитом и микросервисами должен определяться исключительно спецификой проекта и команды разработчиков. Потому что серебряной пули - нет.
bert2000
08.12.2023 13:16Всегда есть золотая середина. И это всегда плагинно модульная архитектура. В том числе часть плагинов и модулей вы можете обернуть сервисами. Но только часть. И только если это реально необходимо.
Микросервисы же всё оборачивают сервисами что неимоверно увеличивает латентность всей системы, дублирование данных и кучу лишних манипуляций по сериализации и десериализации данных как минимум. Опять таки код надо копировать в памяти под каждым сервисом, хотя модуль мог исполнять его в одиночку.
Кривой монолит, без модулей и плагинов это крайность. Микро именно микро сервисы это тоже крайность. Истина как известно где-то между . По середине. Ну и под конкретную задачу.
А так я лично убеждён что модульная /сервисная архитектура универсальна. И модулей может быть немного. И они могут быть мелкими и смешными по функционалу. Но они обязаны быть! Их надо закладывать в архитектуру на начальном этапе проектирования.
Хотя бы для того, чтобы в будущем не переписывать весь этот монолит.
powerman
08.12.2023 13:16И только если это реально необходимо.
Не на всех языках есть техническая возможность гарантировать изоляцию модулей друг от друга. Изоляцию такого уровня, чтобы даже при остром желании срочно-быстро-грязно сделать какой-то фикс или фичу средний разработчик не мог полезть из одного модуля во внутренности или даже БД другого модуля… а если бы попытался, то получились бы такие дикие PR, что на ревью их бы 100% заметил даже самый невнимательный ревьювер. А без этого, как я уже упоминал, монолит слипнется в комок грязи и умрёт. Даже если язык даёт необходимые возможности то не везде есть достаточно хороший архитектор приложений, который реализует эту изоляцию (чтобы один модуль никак не мог, к примеру, добраться до логина/пароля к БД дающего доступ к данным другого модуля).
Если такой технической возможности нет, то её дадут микросервисы, изолируя код модулей друг от друга через сетевое API и изолируя их БД. И, не смотря на добавляемую микросервисами избыточную сложность, это - меньшее зло (по сравнению с большим комком грязи).
bert2000
08.12.2023 13:16мне кажется у вас много "теории" в микросервисах, если вы считаете их меньшим злом.
ну и языки программирования. Причём тут вообще язык? Архитектура и паттерны не зависят от языка, более того мы "реализовывали" (в т.ч. генерировали) одни и те модели на разных ЯПах. Что не исключило ни требований по архитектуре, ни изоляции уровней/слоёв.
Допускать слипания в комок конечно нельзя от слова совсем. И "студентов" (вечных джунов) тоже допускать на проект нет никакого смысла.
Тем не менее практически вся индустрия сейчас страдает от полного отсутствия архитектуры, от полного игнорирования требований, которым уже "сто лет в обед", путём разведения сказок о волшебности микросервисов. Ничего из описанного вами микросервисы не решали и не решают.
А вот архитектуру уничтожают полностью, от слова совсем. Каждый кодит как он хочет. Итогом такого подхода является полное уничтожение стройности систем, и огромнейший зверинец/зоопарк, не поддающийся ни контролю, ни управлению, ни грамотным поддержке и развитию. Цирк цирком в итоге. Притом с клоунами. Хотя нет, в цирке хотя бы дрессируют животных, а в микросервисах свободная свобода делать всё что хочешь, забив на все каноны программирования.
ПыС как архитектор может быть "не достаточно хорош" ? И как отсутствие архитектора заменяют микросервисы??? Никак! Микросервисы только усиливают проблемы при отсутствии архитектора и архитектуры! И код там "аля фулл стек" зачастую уровня "я джун (студент) и 1й день на проекте, потому мне самому стыдно" .powerman
08.12.2023 13:16мне кажется у вас много "теории" в микросервисах
Вам действительно кажется. Я пишу микросервисы с 2009 (причём тогда этот термин ещё даже не использовался), так что у меня практики хватает.
Причём тут вообще язык?
Язык определяет возможности по изоляции: всякие там публичные/приватные/защищённые/экспортируемые/не экспортируемые поля в типах/структурах/классах, "internal" пакеты/модули, которые нельзя импортировать кому угодно, etc. Без этой изоляции один модуль может получить доступ к внутренним деталям реализации другого, что и приводит к вышеупомянутому "слипанию" в комок грязи. Помимо языка иногда изоляцию может контролировать тулинг (линтеры, обычно).
Архитектура и паттерны не зависят от языка
Ну, на самом деле немного всё-таки зависят (если включить режим зануды). Но по сути - да, не зависят. Проблема в том, что если по архитектуре где-то между модулями проведена граница, которую архитект сказал не нарушать, но при этом язык предоставляет возможность любому разработчику (осознанно, чтобы сделать что-то быстро/грязно по требованию менеджера, или неосознанно, просто забыв или даже не зная про требования архитекта на этот счёт) достаточно легко нарушить эту границу - её будут обязательно нарушать. Поэтому одной архитектуры и паттернов мало, поддержка границ/изоляции необходима так же и на уровне языка или тулинга.
И "студентов" (вечных джунов) тоже допускать на проект нет никакого смысла.
Смешно.
Тем не менее практически вся индустрия сейчас страдает от полного отсутствия архитектуры, от полного игнорирования требований, которым уже "сто лет в обед", путём разведения сказок о волшебности микросервисов.
Есть такое, да. Микросервисы действительно сильно снижают требования к качеству кода отдельного микросервиса, отсюда эта сказка и идёт. Но они одновременно сильно повышают требования к архитекту проекта, и это многие упускают. А без сильного архитекта, умеющего в микросервисы, проекты нередко превращаются в "распределённый монолит", который на порядок больше боли приносит, чем даже обычный монолит, слипшийся в комок грязи.
Ничего из описанного вами микросервисы не решали и не решают.
Честно говоря, сначала я прочитал эту фразу упустив "вами", отнёс её к написанному Вами выше, и согласился. Но потом учёл "вами", и теперь согласиться с ней не могу: микросервисы однозначно решают проблему изоляции модулей, которую решить критически важно, и которую без микросервисов можно решить далеко не на каждом языке программирования.
А вот архитектуру уничтожают полностью, от слова совсем. Каждый кодит как он хочет.
С одной стороны - я понимаю, о чём Вы. Но, опять же, всё не совсем так, и это не настолько ужасно, как Вы описываете. При использовании микросервисов архитектура проекта разделяется на две части: первая определяет API и связи между микросервисами, вторая что происходит к коде самих микросервисов. И если во второй части действительно легко развести дикий бардак, то первую часть микросервисный подход как раз довольно эффективно защищает. Ну т.е. в одном месте стало лучше, в другом хуже - и результат может убить один проект или спасти другой, в зависимости от конкретной команды (в одной будет слабый архитект, который сотворит ужас при разделении функционала проектов между микросервисами и проектировании их API, а в другом будет сильный архитект, который не только API микросервисов удачно спроектирует, но и сделает отличный шаблон и/или фреймворк для всех микросервисов и будет следить за единообразием в их реализации).
В целом, архитектуру уничтожает либо отсутствие на проекте сильного архитекта либо отсутствие необходимого инструментария в языке/тулинге, а не используемый подход, будь то микросервисы или монолит.
как архитектор может быть "не достаточно хорош" ?
Элементарно: опыта мало.
Микросервисы только усиливают проблемы при отсутствии архитектора и архитектуры!
А вот тут - полностью соглашусь!
bert2000
08.12.2023 13:16Странно у вас как-то получатся. То ЯП зачем-то должен "заменять" архитекта в проекте, добавляя лишние изоляции. Ну ладно, пропустим это, хотя в наших проектах разрабу всегда давался полный доступ до всего, а СКПД уже резала клиентам доступы. Мы (разрабы) при этом чётко всегда понимали, что такое архитектура и как она важна, и нам и в голову не приходило наваять 20-50 лишних строк кода, для прямого доступа к базе или морде, если ядро предоставляет те же возможности само, и для управления фичей надо написать 1-2 строки. Бог с ним. Проехали.
То наоборот на бедного архитекта взвалена вся куча ответственности... и за кого? За кодеров - студентов. Которые про архитектуру может и слышали, да и то это не факт.
Почему-то смешно для вас не допущение этих же самых студентов на реальные боевые проекты.
Вот это для меня странно. Но сейчас индустрия именно так и выстроена, что кодят одни студенты, и тим лиды буквально вчера универ закончившие. На собесах определения разные спрашивают и кучу оторванной от практики теории. Т.е. по сути и не лиды вовсе, и даже до уровня мидлов не дотянувшие, но лиды.Сразу становится ясно, что тим лид теоретик, вгрёб кучу проблем, и пытается их решить добавляя в проект "свежую кровь". Притом пропустит он в проект таких же студентов как он сам. Т.е. ничего он по итогу не решит.
Отсюда и такие перекосы в девелопменте, ибо проектируют, архитектурят и кодят проекты, люди по-сути далёкие от программирования и вообще не обладающие необходимыми для полноценной реализации проектов навыками. Как и кто их вообще на работу взял, лично для меня остаётся загадкой.
В итоге в отрасли реально 2 крайности, одни лепят монолиты, притом стойко нарушая все базовые принципы индустрии, и ваяя по итогу тот самый нерушимый и неподдерживаемый монолит, который с каждой итерацией кодить всё дольше и сложнее (сюда же не я отношу проекты, в которых код вынесли на уровень БД в язык запросов - тот или иной SQL, забыв что ЯЗ это не ЯП).Ну либо описанные тут микросервисы, т.е. рой мух различного размера, формы и цвета, которые даже теоретически никогда не соберутся в одну единую конструкцию. Молчу уж о её "стройности" и всём остальном.
Но удручает то, что вы считаете что за весь этот хоровод и рой мух, должен отвечать лишь один архитект, и на проект можно запустить студентов, вообще без опыта и знаний. Ну тогда и результат будет вполне логичным и предсказуемым. Студенты напишут на коленке спагетти-код, разбросают его повсюду так, чтоб ты обязательно в него вляпался по полной. А самые ответственные из них напишут в коде комментарии, что им самим стыдно за то что они написали, и они дико сочувствуют всем тем, кто после них будет вынужден разбираться в этом всём "коде" (лично видел такие комменты).ПыС Если у архитектора опыта мало, кто его блин взял в архитекты??? Пусть сидит джунит тогда.
powerman
08.12.2023 13:16Если в Вашем мире джуны-студенты, которых не допускают в реальные проекты, и архитекты сразу с необходимым для текущего проекта опытом, то неясно, как из первых должны со временем получаться последние. Или опытных архитектов в проект аист должен принести? В реальном мире всё не настолько идеально.
Поэтому я и говорю, что то, насколько подходит проекту микросервисная архитектура должно определяться как спецификой проекта, так и доступными кадрами. Потому что кадры тоже не идеальны и зачастую не имеют необходимого опыта - а других, более опытных, просто нет, и проект надо делать имеющимися ресурсами.
bert2000
08.12.2023 13:16Кого где нет? Кадров полно, но проблема сейчас как раз в том, что у рулят в индустрии именно студенты-лиды, набирающие в проекты таких же студентов. Опытные разрабы им не указ! Мания величия там просто запредельная! Им почему-то кажется, что стадо из 20 студентов способно заменить одного реального гуру. По итогу (100й раз это напишу) весть проект они превращают в "кашу". То кашу из плохих микросервисов, то в застывшую кашу неподъёмного монолитного блока.
Из джунов как получаются мидлы и сеньоры? Серьёзно? Вы реально не знаете? Надо объяснить?
У меня была личная беседа не так давно с одним "мидлом" (в МТСе) , притом он сам признался что по-сути он даже не джун и ничерта не понимает в программировании, архитектуре и т.п. .Он диплом в том году получил. Да и то диплом был получен ради получения.
Не вспомню точно чем он занимается на проекте, то ли документацией и требованиями, толи каким-то тестированием, врать не хочу. Но точно помню что он на должности мидла и при этом сам на 100500% знает что даже на 1% ей не соответствует.
Кстати они там наелись микросервисов и избавляются от них полностью (с его слов).
bert2000
08.12.2023 13:16Что должно помешать обернуть пару критических модулей сервисами, и разнести их?
Зачем сразу стрелять из пушки по воробьям? Скорее даже по микроворобьям. Мухам видимо.

jam12345
08.12.2023 13:16Монолит это классно и круто. До момента когда приходят к девопсу и спрашивают "Почему тесты и деплой каждой новой версии занимает 2 часа. А откат 4. А то мы тут деплоимся 10 раз в день и это занимается все наше время"
mrsantak
08.12.2023 13:16Время деплоя и время тестов не зависят от того монолит у вас или нет. От того что вы разделили приложение на N частей никакой магии не случится и тесты и деплой бегать быстрее не станут. Над этими вещами нужно работать вне зависимости от того монолит у вас или не монолит.
bert2000
08.12.2023 13:16А порезать монолит на слои / модули/ сервисы что мешает?
И зачем каждый раз собирать весь проект , а не только ту часть, которую меняли?
Да. И если вы будете пересобирать кучей все микросервисы, с чего это будет быстрее?
mrsantak
08.12.2023 13:16Я тут осознал что в этом примере прогон тестов и деплой занимают не просто 2 часа времени, а 2 часа времени девопса. Т.е. оно еще и не автоматизировано нихрена, но виновата в этом монолитная архитектура, да.
bert2000
08.12.2023 13:16Сарказм.это весело конечно. Но монолитная архитектура есть зло.
Хотя микросервисная архитектура, а точнее сказать фактически отсутствие архитектуры как таковой, ещё большее зло, как по мне.
И, повторюсь, истина где-то посередине, как по мне это модульная, плагинная архитектура + сервисы при необходимости.
Ну и собирать и тестить из этого надо только то, что трогали. Хотя если там найт билд, то вообще пофигу сколько это собирается и тестится, хоть до утра.
mrsantak
08.12.2023 13:16А что именно вы понимаете под монолитной архитектурой? В моём понимании монолит и модульность - это ортоганальные понятия. Модульность - это про то как организован код, в то время как монолит - это больше про то во что собирается проект. Т.е. ничто не запрещает иметь тонны сервисов собранные из проекта состоящего из одного огромного модуля без нормального разделения на части, и иметь монолит собранный из проекта побитого на логические модули, каждый из которых имеет свои impl и api части.
bert2000
08.12.2023 13:16Тут не совсем так, или совсем не так. Модульность и модульная архитектура изначально предполагают как раз возможность отключения модулей/плагинов, их заменяемость, а также возможность их переписать.
Монолит же зачастую (вижу это почти во всех проектах сейчас) это как раз способ "положить кое что" на архитектуру и сидеть ручками кодить кучу спагетти-легаси кода, забив на все паттерны проектирования, или исказив их до неузнаваемости.
Следствие такого подхода к программированию, т.е. игнорирование требований архитектуры, приводит именно к тому, что монолит становится именно монолитом, который практически нельзя распилить. В нём тупо нет ни одного модуля или слоя. Отделять тупо нечего. Таких проектов сейчас в продакшене очень и очень много, если не все.(Кстати микросервисы тоже страдают архитектурными проблемами.)
По сути это ежедневное игнорирование базовых архитектурных требований, что приводит в непоправимым архитектурным проблемам. Распилить такой монолит просто невозможно. И чем дольше "команда" работает с этим монолитом, тем всё становится хуже и хуже с каждым днём. Разработка всё сложнее и дольше с каждой итерацией.Если бы выполнялись базовые архитектурные требования, и приложение было бы чётко и строго разделено на различные слои в т.ч. с дополнительными уровнями абстракций (у меня в ORMке к примеру 3 уровня абстракций, как и в модулях генерации морд), то заменяемость модулей вообще не была бы проблемой. Любой модуль можно было бы совершенно безболезненно выкинуть и заменить аналогичным.
В итоге в случае необходимости нужно было бы допилить / переписать (хотя скорее просто обернуть сервисами) пару модулей и всё.
При этом это ведь требование базовых паттернов проектирования (SOLID, KISS, DRY, MVC). Но очень многие в индустрии их не понимают вообще и путают.
Недавно один герой заявил мне к примру что паттерн MVC вообще касается только ASP.Net и всё. Кайф. А ведь он тим лид и под ним команда из 20 таких же заблудших айтишников.
Резюме: Если изначально соблюдать архитектурные требования, то и софт (мягенький) можно было бы легко и быстро адаптировать под ситуацию и задачи.
Ну а если не соблюдать, то можно лепить большие монолиты или кучи мухосервисов.Что как по мне две крайности.
jam12345
08.12.2023 13:16А порезать монолит на слои / модули/ сервисы что мешает?
О поздравляю вы изобрели микросервисы). Это как они и есть. Ибо дальше будут все проблемы микросервисов из разряда как эти слои / модули/ сервисы взаимодействуют друг с другом. А потом вам потребуется что то вроде k8s что бы этим всем зоопарком управлять.
А вообще право на жизнь имеют оба подхода. Но монолит больше подходит под waterfall, а микросервисы под agile. Хотя и это не закон. Но где то так. Если нужно что то пилить долго и упорно и деплоится раз в пол года. То микросервисы даром не нужны. Если у вас пачка деплоев в день. То катить каждый раз на пару сотен серверов кусок кода размером с войну и мир будет больно.bert2000
08.12.2023 13:16у вас крайности, ау. Разрезать / разделить изначально "монолит" на 5-10 слоёв это точно не микро сервисы. И даже не сервисы.
Да и я ничего не изобретал. Всё изобретено задолго до нас.
А вам порекомендую не ударятся в крайности и находить золотую середину.
В том числе не использовать микросервисы, а и следовало, использовать модули, плагины и сервисы (не микро!), заточенные под свои нужды и задачи.ПыС я не управляю зоопарками. Я интегратор.
jam12345
08.12.2023 13:16изначально "монолит" на 5-10 слоёв это точно не микро сервисы. И даже не сервисы.Ага это фигня какая то. Ты не можешь деплоить кусок кода отдельно, если он он как то связан с другими кусками и меняет их функционал неожиданным для других разработчиков образом. А если этот кусок никак не связан то это и есть микросервис. Понятие микро оно разное. Я видел микро сервисы и по 1 гигабайту весом.
Логика по которой сервис выделяется в отдельный это вообще огромная тема для споров и тут можно целую конферецию проводить.bert2000
08.12.2023 13:16Извините, вы статью прочитали хоть? Сервис это не микросервис. Это совершенно разные понятия.
Что за неожиданные для всех изменения? Впервые слышу о подобном цирке в проекте. В проект пришёл террорист и решил бомбануть базу кода, всем нападлив? Если нет, тогда всё для всех вполне ожидаемо, продумано и обсуждается заранее.
Вам надо разжевать смысл термина микросервис? Именно микро! Прочитайте хотя бы статью.jam12345
08.12.2023 13:16Если нет, тогда всё для всех вполне ожидаемо, продумано и обсуждается заранее.
Эх не работали вы в командах на несколько тысяч разработчиков судя по всему)
ioncorpse
08.12.2023 13:16Если в монолите у каждого класса только Single Responsibility и есть слои и модули, то это всё равно "просто адекватный монолит" и к микросервисам никакого отношения не имеет. И с agile нормально существует.

mikryukovsl
08.12.2023 13:16Офигеть!!! глубоко копнул, я в ауте и так от всего этого, но такой критичный ответ очень помогает всё назвать своим именем.

amgorb
08.12.2023 13:16Иногда переход на (микро-)сервисную архитектуру вынуждает делать сам бизнес или развитие компании. Вот (почти) выдуманный пример: есть у нас компания со своим идеально вылизанным монолитом на java+mongodb, продает автомобили через сайт и моб приложение и все хорошо. Потом компания растет и вот она уже покупает другую компанию, небольшой, но успешный стартап по продаже трициклетов. А там внезапно php+mysql. А по бизнес требованиям надо чтобы оплата, регистрация и поиск были одинаковые. И письма приходили в едином стиле, в одном шаблоне. И вообще надо бы максимально теперь объединить эти проекты в один, как тут обойтись без (микро-)сервисов, без выделения регистрации, оплаты в отдельные сервисы?
Монолит классная штука, но надо понимать границы применимости такой архитектуры, как и микросервисной и я думаю, что хотя у монолита и выше скорость разработки, но у микросервисной выше скорость к слиянию с другим кодом и больше возможностей по аутсорсингу части проекта сторонним разработчикам. Да, в микросервисной большей boierplatинга и тулинга, но зато кода который надо держать в памяти (человека) и понимать как он работает - меньше.
HemulGM
08.12.2023 13:16Забрать только бизнес данные и разместить у себя, объединив не только оплату, но и всё целиком

baguwka
08.12.2023 13:16Проблема в том, что бы разрабатывать микросервисы экспертиза разработкиов должна быть высокой. Иначе ошибки допущенные при проектировании микросервисов будут стоить на порядки дороже чем те же самые ошибки в монолите. Например неправильно поделили boundaries по какому-то критерию, или не дай бог обнаруживаем что оказывается микросервисы синхронно общаются друг с другом по HTTP. Такое исправить будет на порядки сложней чем сделать обыкновенный рефакторинг в монолите.
В приведенном вами примере микросервисы не сильно помогут. Не факт что подходы которые применяли разработчики сторонней компании совместимы с вашими (всякое бывает). У меня в текущей работе тоже микросервисы, и как раз недавно купила другую компанию из той же доменной области. И у нас (asp.net) и у них (nodejs) микросервисы. Но это никак невозможно переиспользовать если мы хотим потратить какое-то разумное количество ресурсов, проще использовать их данные.jam12345
08.12.2023 13:16Должна быть высокой экспертиза проектировщика, архитектора, sre и devops. А вот экспертизу разработчиков как раз в этом случае можно понижать на каждом сервисе.
Проблема только одна. Большинство компаний про те слова что я сказал выше даже не слышали и хотят посадить разраба который будет делать все одновременно. А так оно работать никогда не будет.Собственно весь этот подход и создавался не для ООО "рога и копыта." А для гигантов IT индустрии. Где есть архитектура выйти за пределы которой нельзя. Есть пайпы которые это контролируют. И есть пачка разрабов не очень квалификации которые пишут свои микросервисы. Если какой то их отвалится и будет написан криво то и черт с ним.
powerman
08.12.2023 13:16экспертиза разработкиов должна быть высокой
Не разработчиков, а архитекта.
bert2000
08.12.2023 13:16ого. Архитект во всём крайний теперь (жаль его, застрелится же)? А вместо адекватных разрабов студентов наберём?
powerman
08.12.2023 13:16В случае микросервисов - да, квалификация разработчиков может быть ниже, чем в монолите, а квалификация архитекта должна быть выше, чем в монолите. Потому что любой бардак, который разработчики устроят в конкретном микросервисе, причинит значительно меньше ущерба, чем аналогичный бардак в монолите либо бардак в связях и API самих микросервисов. Да и переписать большинство (все те, которые реально "микро") микросервисов можно за пару недель силами одного-двух разработчиков.
bert2000
08.12.2023 13:16как у вас всё просто, выглядит прям сказочно.
Ну а я, конечно же, в сказки не верю.
Да и архитектора жалко прям. Не архитектор, а козёл отпущения прям.
Быдлокодят одни, а отвечать ему. Так себе радость.
saboteur_kiev
08.12.2023 13:16Архитектор может давать рекомендации, а разработчики могут его либо не слушать, либо не понять и написать на свое усмотрение.
Архитектор не обязательно тот, который ревьювит все коммиты во все компоненты проекта. У него могут быть совсем другие задачиpowerman
08.12.2023 13:16Нынче задачи архитекта разрослись, и привели к тому, что появились разные роли архитектов. Причём на данный момент чёткого определения названий и ответственности этих ролей ещё нет. Обычно роли с названиями вроде Enterprise/Solution/Systems Architect работают больше с бумажками, чем с кодом (причём нередко с кодом они вообще не работают!), а роли Application/Software Architect работают с бумажками и кодом примерно 50/50.
В контексте данного обсуждения я подразумевал последних - тех, кто отвечает за то, что данный конкретный проект заработает (в т.ч. "собравшись" из кучки микросервисов), будет соответствовать функциональным и нефункциональным требованиям, и усилия по его поддержке и развитию будут приемлемыми. И хотя они действительно не ревьювят все коммиты, но общий контроль над происходящем в коде они всё-таки осуществляют. Что включает в себя, в том числе, как определение общей структуры и архитектуры кода, так и проверку что всё это соблюдается разработчиками. В случае микросервисной архитектуры на их же плечи ложится разделение функционала проекта между микросервисами и определение их API. При этом контроль над архитектурой и структурой самих микросервисов вполне может ослабнуть, т.к. объём что нужно контролировать сильно возрастает, а критичность этого сильно падает.
А по части рекомендаций, которые разработчики вполне могут игнорить - это к первой группе ролей архитектов, они слишком далеки от кода.

arTk_ev
08.12.2023 13:16Добрый день, автор.
Приглашаем вас принять участие в проекте. Финансы - не проблема

santa324
08.12.2023 13:16Мне все это ассоциируется со спорами "карго-культистов", как правильно строить самолет из соломы и палок, что-бы боги прислали настоящий. Надо или не надо делать сервисы, микро они будут или макро - зависит от задачи. Почему-то часто забывают что программная система целиком - это тоже алгоритм, и его надо проектировать соответстующе.
bert2000
08.12.2023 13:16так в этом и суть и статьи и обсуждений, что по итогу микросервисы засунули везде, в 99% случаях туда где нельзя, притом сделали их не десяток или сотню, а тысячи. Но и этого было мало. Даже архиекторов не нашли под это.
Для всех этих проектов набрали толпы студентов, которые ни разу не за копейки быдлокодят просто тоннами, и кучу всего этого "кода" невозможно собрать по итогу ни во что. Зато модно! Задачи все завалены, зато весело бабло распилили (результата нет). Как то так.
Проектировать надо. Если проектировщик - инженер. Ну и "не надо" (он не сможет), если проектировщик модный студент.

dotnetchik
08.12.2023 13:16Не совсем по теме, но вставлю свои 5 копеек.
Прохожу недавно собес на сеньорскую позицию.
- Извините, но без опыта работы с микросервисами мы не можем вас взять на эту должность.
- Ваши микросервисы - это asp.net приложения на C#?
- Да.
- Микросервисы общаются по REST, grpc или через брокер сообщений?
- Да.
- У микросервисов есть поключенные БД MS SQL, PostrgeSQL или MongoDB?
- Да.
- Ну так у меня же достаточный опыт работы со всеми этими технологиями
- Но вы не работали с микросервисами, так что сорян.
sshmakov
Попытка №2 https://vk.com/wall-20629724_1537470
Kelbon Автор
но там по ссылке закрыт доступ
atomlib
Там по ссылке перевод, похожий на машинный, от пользователя, имевшего привычку размещать переводы, похожие на машинные. Так что ничего дурного в дублирующем переводе в данном случае нет.
DmitriiBelikov
Ложь. Перевод не был машинным. Оригинал сохранён на моём сайте.
atomlib
https://www.diffchecker.com/3PR8ktIY/
Слева — результат работы Google Translate. Справа — текст с вашего сайта.
Есть даже совпадающие слово в слово абзацы. Их примерно треть от числа общих.
В остальных случаях различия минимальны: «LOL»/«лол», «програмное обеспечение»/«инструментарий» и так далее. Исправлены косяки машинного переводчика, который не разбирается в техническом жаргоне.
Иногда изменения ради изменений: вместо «проще.» стоит «проще, верно?». Но вообще структура предложений полностью совпадает.
DmitriiBelikov
Вы не учли то, что этот перевод правили и пользователи Хабра тоже. Вы так же не стояли рядом и не держали свечку, когда я это делал. Поэтому ваш анализ слегка поверхностный и для меня совершенно бесполезный. С т. зр. Хабра - это контент, не более. Придирайтесь к другим. Я вас не просил. Согласовывать материал это нормально (вы этого не делаете). Работать с аудиторией это нормально. Обесценивать чужой труд, как вы это сделали, по надуманным причинам - нет.
В общем такое себе. Меня честно не сильно интересует ваше мнение как переводчика, для меня это тоже контент, я смотрю как архитектор и разработчик. Для меня это единица информации. Если бы вы поинтересовались для начала, согласовали бы материал, а не ставили перед фактом, то получили бы совершенно другую реакцию. Ну отдельное спасибо за слив кармы тому аккаунту. Было обидно...я был зол, но публично свою аггрессию не выносил.
Но приятно, что вы немного сдвинулись в этом направлении, даже сайт чуток подделали.
Kelbon Автор
вы кажется перепутали и думаете, что общаетесь с автором перевода, но опубликовал статью я
DmitriiBelikov
Нет, я знаю, с кем я общаюсь и да, это не вам. Я ранее под другим аккаунтом уже публиковал эту статью. Она набрала 33К просмотров (про репосты я даже не знал). Но поскольку она оказалась популярна в сети, то её недавно дублировали на реддит, что скорее всего и было катализатором для вашей публикации. Моя имеет более ранние корни.
SergioT4
Ну перевёл гугл транслейтом, что стесняться то и запираться? Видно же невооружённым взглядом. С соответсвующей ценностью.
Я не против гугл-транслейтов, наоборот, на данный момент они имеют вполне хорошее качество, но претендовать на "творчество" странно.
bert2000
Спасибо. Отличная статья.
sshmakov
Google Translate умеет воровать подходящие переводы из сети. То есть сейчас, когда есть уже перевод в сети, невозможно понять, перевел ли Google сам или взял перевод из сети.
bert2000
Перевод не перевод. Вам по теме есть что сказать? Микросервесы, так сейчас популярные, по-сути полнейший треш.
Реально микросервисы лишь спосбо распилить уйму бабла и сотворить никому не нужную хренотень, которую только выбросить на помойку.