

Привет! Меня зовут Олег, и я работаю в Skyeng. Мы с командой разрабатываем ядро образовательной платформы, на которой проходят все онлайн‑уроки, решаются домашки, экзамены и контрольные.
Раньше на IT‑собеседованиях мне задавали один и тот же вопрос:
— Расскажи о крупнейшем фейле в твоей карьере?
Не уверен, что ответ может много рассказать о кандидате, но цель моей статьи прозрачна: поделиться опытом, чтобы предотвратить подобные инциденты в будущем.
Почему фейл крупнейший?
Я отношу упавший сервер к highload. Посудите сами:
~500 RPS;
~0,5 млрд записей в одной таблице БД;
~3 ТБ на всю БД.
Skyeng проводит в среднем 3000+ уроков в час. На полтора часа основной сегмент нашего бизнеса отключился, и ученики не могли попасть на платформу. Это стоило компании дорого.
С чего все началось: аналитика и soft delete
Не секрет, что современный софт обвешан аналитикой — каждое действие пользователя обезличивается и логируется.
Типичные события в журнале аналитиков: пользователь открыл страницу, пользователь кликнул по кнопке и так далее. Это помогает понять, на какие кнопки кликают чаще других, а какие пора выкинуть за ненадобностью. Бизнес, в свою очередь, может делать выводы, какие фичи в приложении нравятся пользователям, а какие «не взлетели».
Аналитические отчеты строятся не только по журналу действий пользователя. Например, в качестве источника информации могут использоваться продуктовые базы данных — у нас это PostgreSQL.
С последней есть один нюанс: если данные из БД задействованы в аналитических отчетах, то банальное удаление (SQL DELETE) строки из таблицы может испортить этот самый отчет. Поэтому, с одной стороны, нужно уметь удалять данные из БД, а с другой стороны, удалять их нельзя, так как портится аналитика. Как быть?
Soft delete — это паттерн, при котором записи не удаляются, а остаются в БД навсегда с пометкой об удалении. То есть вместо SQL DELETE используется SQL UPDATE c deleted_at = now.
Как вы уже догадались, моей команде потребовалось внедрить soft delete для корректной работы отчетов аналитики.
Техническое ревью
Стек технологий на целевом сервисе: PHP 8.1, Symfony 5, PostgreSQL. Soft delete отсутствует, то есть при удалении записи из БД работает SQL DELETE. Находим готовое коробочное решение для Symfony и ее ORM Doctrine — расширение SoftDeleteable.
Это позволяет включить soft delete практически без изменения кода. Достаточно добавить в проект этот пакет через composer и включить мягкое удаление в конфигурации сущностей БД. Не забудем добавить в каждую нужную таблицу новую колонку deleted_at при помощи SQL ALTER TABLE.
На этом задача выполнена? Не совсем.
В БД миллиарды записей, и для ускорения SQL-запросов мы точечно применяем индексы. После внедрения soft delete имеющиеся уникальные индексы будут мешать текущей логике, и вот почему.
Пусть есть составной уникальный индекс на две колонки: user_id и resource_id.
Рассмотрим сценарий:
Добавляем запись с
user_id = 100иresource_id = 10.Удаляем эту запись, помня про soft delete: записываем текущее время в
deleted_at. Сервис больше не видит удаленную запись, но в БД она есть.
Логика нашего приложения допускает повторную вставку записи после ее удаления. Но после внедрения soft delete мы больше не сможем вставить в БД запись с такой же парой (user_id и resource_id) из-за нарушения уникальности — БД выдаст ошибку.
На помощь приходит фича PostgreSQL — partial index. Это такой индекс, который накладывается не на все записи БД, а только на ту часть, которая подходит по предикату. В нашем случае partial index накладывается на записи, у которых
deleted_at IS NULL(это и есть предикат). Таким образом, partial index игнорирует все записи, помеченные удаленными.
Это выглядит как идеальное решение в текущей ситуации. Как только запись помечается удаленной через deleted_at, она тут же автоматически исключается из частичного уникального индекса. То есть запись, помеченная как удаленная, теперь не видна сервису и partial уникальному индексу. Поэтому повторная вставка записи с теми же значениями будет работать без проблем.
Следующий вопрос: что делать с уже имеющимися в БД старыми, не partial индексами?
Очевидно, старые уникальные индексы нужно аккуратно удалить и создать новые аналогичные partial уникальные индексы.
Удаление индекса даже на большой БД выполняется за секунды. Но создание индекса может занимать целый час на штуку, а у нас таких индексов целых 5! Если сначала удалим старые уникальные индексы, а потом начнем создавать новые — получим окно в несколько часов, когда сервис будет работать под обычной нагрузкой, но без индексов. Это автоматически приведет к падению сервиса и, как следствие, всей школы Skyeng. Мы это предвидим и так делать не будем.
Следовательно, сначала в фоне создаем новые индексы, и только после этого удаляем старые. Сразу замечаем, что SQL-запросы на удаление старых и создание новых индексов будем делать руками в продуктовой БД, так как в CI/CD подобные часовые операции не пройдут из-за лимита времени на деплой.
Наш итоговый план релиза (не делайте так!):
Добавить колонку в таблицу
deleted_atсdefault NULL(деплой миграции).Создать новый уникальный partial index (руками, закладываем 5 часов).
Удалить старый уникальный индекс (руками).
Включить soft delete в код (установить Doctrine-расширения, включить soft delete в конфигах, зафиксировать новую структуру БД через миграции).
Релиз: день 1
Первые два пункта выглядят достаточно безопасно. Они занимают больше всего времени из-за многочасового создания новых partial индексов, поэтому мы решили разделить релиз на два дня.
Как и ожидалось, первый этап прошел гладко, если не считать алерта от Миши из команды инфраструктуры — расходы файлового хранилища резко выросли:


Релиз: день 2. Как развивался инцидент
Итак, настает день икс. В очередное деплойное окно релиз продолжается.
В 12:10 я запускаю SQL-команды на удаление старых уникальных индексов в продовой БД согласно плану. Ничто не предвещает проблем с удалением старых индексов, ведь новые partial индексы уже есть, и они готовы к работе!
В 12:17 все старые индексы удалены. Судя по графику размера БД, полегчало:
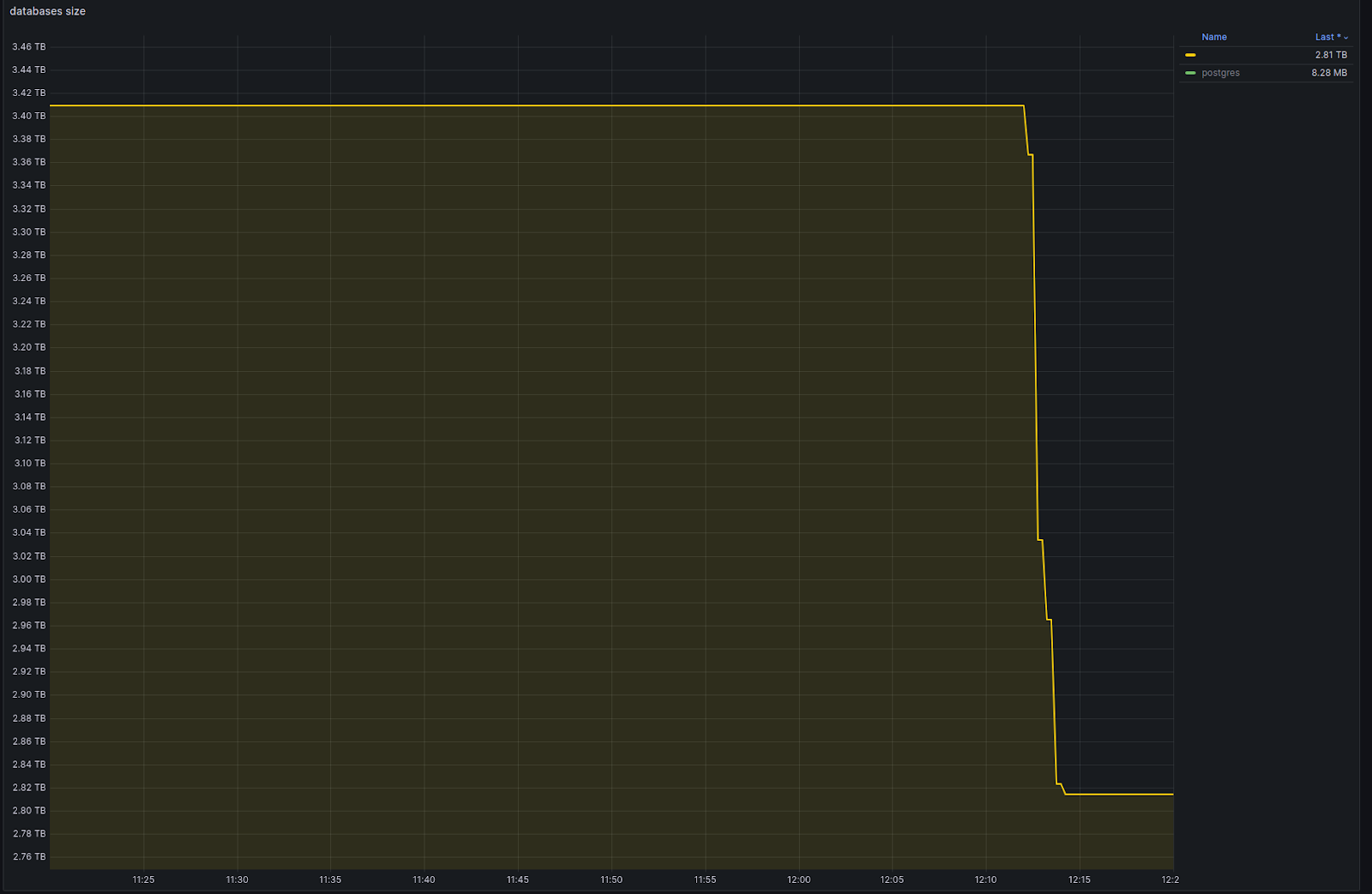
Однако уже в 12:20 начали массово поступать жалобы от клиентов. Я посмотрел в мониторинг сервиса и понял, что прод упал.
Мониторинг HTTP-ответов от сервиса показывает резкий скачок — 500 ошибок. Забились коннекты к БД, судя по загрузке CPU и RAM, что-то идет не так.
Обычная практика в подобных случаях — hotfix или откат деплоя (rollback). Второе проще, но в данной ситуации быстро вернуть все как было не получится — откатывать нечего. Мы удалили старые индексы вручную, и чтобы их вернуть, нужно вручную запустить SQL-команду и ждать 5 часов — это явно не выход.
Откатить нельзя, фиксить (запятая поставлена правильно)
К счастью, в инцидент оперативно вмешался Саша — мой тимлид. Он быстро и трезво оценил, что новые индексы есть, но они не работают. Как такое может быть?



Старых индексов уже нет. Новые partial индексы есть, но код на сервере старый → старый код не использует новые индексы при поисковых запросах → SQL-запросы выполняются очень долго. Коннекты БД и очередь запросов забились → сервис упал под нагрузкой.
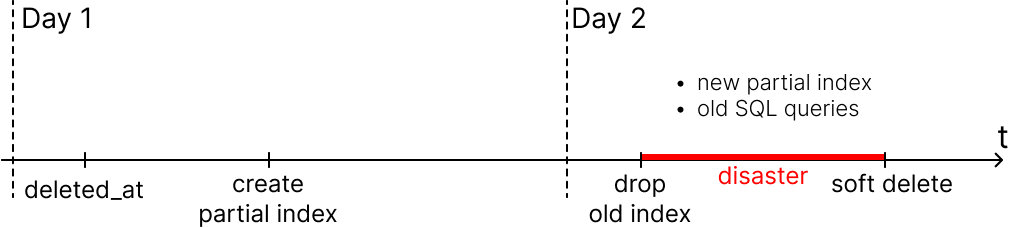
Изначально я не учел ключевую деталь: partial index работает, только когда SQL-запрос в коде содержит предикат, аналогичный предикату partial индекса (предикат тут — это то, что идет после WHERE).
Проще говоря:
Такой запрос не использует partial index:
SELECT * FROM exercise WHERE user_id = <user_id> AND resource_id = <resource_id>
Правильный запрос, чтобы использовался partial index:
SELECT * FROM exercise WHERE user_id = <user_id> AND resource_id = <resource_id> AND deleted_at IS NULL
Ясно, что в конечной точке деплоя все стало в порядке. Но в окне между 3-м и 4-м пунктами мы получили дизастер.
К сожалению, завершить деплой получилось лишь в 13:30. В GitLab-воркерах скопилась очередь билдов, и мой деплой ждал, пока не освободится воркер. Плюс дал свою задержку канареечный деплой.
В данном случае можно было катить с выключенной канарейкой. Когда деплой завершился, потребовалось еще рестартнуть memcached — после этого ситуация стала приходить в норму.
Инцидент завершился в 13:52.
План, исключающий падение прода
Добавить колонку в таблицу
deleted_atсdefault NULL(деплой миграции).Создать новый уникальный partial index руками. Закладываем 5 часов.
Включить soft delete в коде: установить Doctrine расширения, включить soft delete в конфигах, зафиксировать новую структуру БД через миграции.
Удалить старый уникальный индекс.

Такой вариант релиза предотвратит падение прода, но есть один интересный момент.
Дело в том, что до завершения релиза (пункт 4) в БД живет старый уникальный индекс. Поэтому в окне между 3-м и 4-м пунктами нас потенциально ждут ошибки 5xx, если кто-то сделает удаление при помощи soft delete, а потом попробует добавить новую запись с теми же данными. Старый уникальный индекс не даст этого сделать, пока не будет удален. При RPS близком к 1000 даже за минуту вы поймаете несколько ошибок.
Но есть более правильный вариант, к которому мы пришли вместе с разработчиком из соседней команды — она тоже недавно прокололась на таком кейсе.
План бесшовного релиза
Когда новый код с soft delete на проде, старый уникальный индекс нужно удалить. Иначе он не даст добавить новые записи, аналогичные удаленным с помощью soft delete. C другой стороны, нельзя удалять старый уникальный индекс, пока работает старый код.
Нам пришла идея: вместе с новым partial индексом создать временный поисковый индекс — аналогичный старому, но без ограничения уникальности.
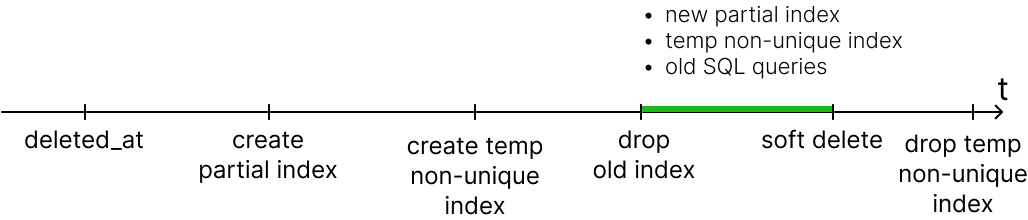
Добавить колонку в таблицу
deleted_atсdefault NULL— деплой миграции.Создать новый уникальный partial index руками, закладываем на это 5 часов.
Создать временный индекс, идентичный старому, но без ограничения уникальности. Тоже выполняем руками, закладываем 5 часов.
Удалить старый уникальный индекс.
Включить soft delete в коде: установить Doctrine-расширение, включить soft delete в конфигах, зафиксировать новую структуру БД через миграции.
Удалить временный неуникальный индекс.
В этом случае в любой момент релиза поисковые запросы будут работать быстро, и мы не получим проблем со вставкой новых записей.
Минусы такого варианта:
Удваивается время релиза из-за создания дополнительного временного неуникального индекса.
Временно удваивается размер хранилища БД.
Итоги
Плохо, что такой кейс случился. Хорошо, что мы установили причины, все исправили и смогли поделиться результатами. Это поможет предотвратить подобные инциденты не только в Skyeng, но и, надеюсь, у всех, кто дочитал статью до конца!
Кстати, коллеги с пониманием отнеслись к произошедшему. Ведь практически у каждого разработчика есть в запасе подобная история. Поспрашивайте другу друга в перерыве!
Ну и, конечно, не корите себя за ошибки. Как говорят мудрецы:

Спасибо за внимание. Жду ваших вопросов в комментариях, хорошего дня!
Комментарии (162)

vyachin
26.03.2024 08:41+5Я однажды уронил прод, поднял через 15 минут и ... уволился) Не выдержал упреков со стороны бывших коллег

DMGarikk
26.03.2024 08:41+8упреков? прод обычно роняет не один человек (ну разве что это тимлид в одно лицо чтото накатить решил), это обычно фейл в процессах.
Я за свою карьеру несколько раз прод ронял, последний раз это было года два назад, оч крупный сервис, как раз наверное размером со skyeng, лежали гдето полчаса
Главный факап был в том что решили упростить сложный процесс деплоя выкинув препрод тесты... и после мерджа внезапно соседние мерджи стали несовместимы с моим...из-за чего после срабатывания алертов в прод вылилось еще пара других релизов...которые нельзя откатывать...
формально виноват типа был я, потому что именно на моём MR-е упал прод
но вы понимаете что это не тоже самое? кто делал ревью? кто запускал тесты? где интеграционные тесты?

Lev3250
26.03.2024 08:41+10Может он его физически уронил
DMGarikk
26.03.2024 08:41+30у меня было похожее ;)) я зашел в серверную, услышал за стойками треск (сгорела розетка, физически)..и погасла коммуникационная стойка, потом на меня начальник пристально смотрел - не я ли чё дернул или задел...;) я тогда второй месяц чтоли работал... и видеонаблюдение у нас тогда барахлило и записей с камер не было ;)) было стрёмно ;))
p.s. Роман, я знаю что ты в комментах бываешь на хабре, это честно был не я ;) оно реально само, больше 10 лет прошло, я до сих пор это помню

alan008
26.03.2024 08:41+16- Коллеги, мы развернули 3 сервера!
- А они что, раньше не той стороной стояли?

13werwolf13
26.03.2024 08:41+46первый раз в жизни уложив прод (всего на пару минут, зато целиком и полностью все сервисы) я ожидал сурового нагоняя от начальства и криков "позор" от коллег. но начальник улыбаясь сказал что-то вроде "с почином, больше так не делай" а коллеги стали вспоминать кто и когда ложил прод и как это было. я расслабился, порадовался что работаю в хорошем коллективе и... начал корёжить себя изнутри. совесть заедала меня ещё пару дней.

MountainGoat
26.03.2024 08:41Я в таких случаях заедаю совесть.

serge-sb
26.03.2024 08:41Из ещё возможных вариантов - запивать и засыпать - я предпочитаю теперь последнее.

Glembus
26.03.2024 08:41Ложил прод. Совесть не мучает :). Автору, а зачем докидывать новую запись, если можно апдейт сделпть. Судя из описания вашего это флоу который у вас был: удалил, добавил с новым значением. Это тоже самое что обновил. Или вашей обезличенной статистике нужгэна история. Так сожно логер мусорку использовать и проблема решена.

zorn-v100500
26.03.2024 08:41Потому что soft delete только вводят, а фунцикляр нужен был еще до этого. И он был.

xirustam
26.03.2024 08:41Потому-что на старую запись могуть быть ссылки из других таблиц. Чтобы ваше предложение работало, надо ещё позаботиться о том, чтобы, во-первых, был каскадный soft delete, во-вторых, чистились все ссылки на удалённую запись. А ещё могут где-то во внешних системах остаться ссылки на удалённую запись... Т.е. проблем с таким подходом потом можно столько огрести...


Fragster
26.03.2024 08:41+9Нам пришла идея: вместе с новым partial индексом создать временный поисковый индекс — аналогичный старому, но без ограничения уникальности.
и получить еще + 300 гб и несколько часов создания нидекса.
Не лучше ли было после создания partial индекса, но до удаления основного индекса:
выкатить релиз с руками добавленными
...and deleted_at is nullпотом удалить основной индекс
а потом выкатить релиз с включением soft delete и удалением ручного условия?
Кажется, по времени и по месту это будет быстрее. Конечно, релиза два, но это может не быть такой уж проблемой.

vp_arth
26.03.2024 08:41В этом случае (в статье это, кстати, описано), будет период, когда старый уникальный индекс не позволяет заново создать ранее удалённые сущности. Это можно починить восстановлением удалённых записей (как предлагают в соседнем комментарии), но не всегда применимо (например, нужно сохранить историю).
Впрочем, если подумать, такая «багуля» лучше, чем полтора часа даунтайма)Fragster
26.03.2024 08:41+1Не будет. Soft delete выключен, одновременно существует два индекса. Промежуточный релиз заставляет использовать новый. Потом старый индекс удаляется и только потом включается soft delete.
vp_arth
26.03.2024 08:41Непонятно, чем ручной фильтр отличается от фильтра из DoctrineExtensions.
В период, когда старый индекс жив и ограничивает уникальность без учёта deleted_at, будет невозможно создать новую запись с тем же ключом, что и у уже существующей удалённой.
Или я не до конца понял идею.Fragster
26.03.2024 08:41+3Он ничем не отличается, просто с этим условием будет использоваться новый индекс, а не старый. При этом записи будут удаляться как и раньше, через delete, а не update, не нарушая уникальность первого индекса при создании в последствии записи с теми же значениями.
vp_arth
26.03.2024 08:41Всё, понял, спасибо. Да, рабочий вариант. Но много лишней ручной работы.
Fragster
26.03.2024 08:41+1Ну тут основной профит в отсутствии создания еще одного (неуникального) индекса, что дорого и по времени и по месту. И который все равно придется удалять.
При этом можно код подготовить заранее и сделать два pr, например из разных веток и применить их по очереди, при этом удаление индекса можно вообще в миграцию положить (оно быстрое).

NikitaYakuntsev
26.03.2024 08:41Новый будет использоваться для поиска, но при этом старый уникальный индекс не позволит совершать вставки.

dyadyaSerezha
26.03.2024 08:41+2На эту тему как раз
Старый уникальный индекс не даст этого сделать, пока не будет удален. При RPS близком к 1000 даже за минуту вы поймаете несколько ошибок.
RPS тут ни при чем, а при чем только частота удаления/повторного создания записей.
В идеале, логику на удаление которое не удаление, нужно было добавить в последнюю очередь. Тогда бы все заработало.

hogstaberg
26.03.2024 08:41+1+300Гб индекса временно. И на фоне размера базы >3Тб это выглядит уже не так уж и страшно. Пара часов выполнения фоновой задачи тоже не то чтобы выглядело прямо очень критично. Подозреваю что дописать везде в коде условие руками и выкатить новую версию было бы дольше, причем уже активной работы. И с большим шансом где-то что-то пропустить в процессе.
Fragster
26.03.2024 08:41+300Гб индекса временно. И на фоне размера базы >3Тб
Если +1 индекс это +10% базы и два часа, то +2 индекса - это +20% базы и 4 часа. Не знаю, как у вас, но у нас накатывание/сборка собственно кода занимает минуты.
hogstaberg
26.03.2024 08:41Накатить быстро. Править исходники руками потенциально долго и больше шансов что-то упустить.
Насчёт +20% - ну я сомневаюсь что там места впритык прям, чисто из здравого смысла стоит всегда запас хотя бы в 50% от размера базы иметь.
Fragster
26.03.2024 08:41Про "править руками" - ниже я написал про скоупы ларавеля и, скорее всего, в джанге это все аналогично. Иначе расширением бы софтделит не сделать. Поэтому править надо только в одном месте.

OlehR
26.03.2024 08:41В оракле можно так: alter index indexname unusable; Но ведь оракл стоит слишком дорого :)vp_arth
26.03.2024 08:41+1Подешевле есть Firebird. Там тоже можно индексы отключать. Да и в Postgres, если постараться, можно какой-нибудь indisvalid выставить, или точечно констрейнты снести.

Ivan22
26.03.2024 08:41+3так это точно также не даст запросам использовать этот индекс, и в итоге прод упадет

Suher
26.03.2024 08:41+4вероятно, можно будет вернуть индекс назад меньше, чем за пять часов
Ivan22
26.03.2024 08:41+5неа, если у тебя unusable index, его включение обратно будет rebuild. Что займет времени как создание с нуля

plFlok
26.03.2024 08:41+4а какой тогда паттерн использования этой оракловой фичи? она ведь существует для решения какой-то задачи?

onyxmaster
26.03.2024 08:41+9Чтобы эксперты по Ораклу знали что они не зря потратили жизнь на изучение Оракла =)
Ivan22
26.03.2024 08:41+3Ну это как ты когда жалко удалять когда-то любимый, а теперь ненужный кусок кода - заботливо просто комментируешь его, в надежде вдруг еще пригодится.
hogstaberg
26.03.2024 08:41Главная проблема оракла не в том, что слишком долго, а в том, что слишком закрыто и слишком проприетарно. Да и те фичи, за которые стоит отдать денег, в реальности нужны далеко не каждому.

SystemOutPrintln
26.03.2024 08:41+2Из платности/цены какого-то продукта не следует автоматически, что он идеален/лучше более дешёвых вариантов.
Небось айфоном пользуетесь?

Igelko
26.03.2024 08:41+8Создать индекс
Не проверить, что он используется.
Классика, или почему всегда руками дёргаю explain analyze для всех запросов ещё на этапе разработки.
Ivan22
26.03.2024 08:41+6а где вы берете ВСЕ запросы ?

damakin
26.03.2024 08:41+3Для Laravel есть пакет lanin/laravel-api-debugger, который добавляет к ответу API список SQL-запросов и обращений к кэшу. Помогает выявить долгие запросы (которые затем будут исследованы EXPLAIN ANALYZE), циклы, проблему N+1 и потенциальных кандидатов на кэширование.

onegreyonewhite
26.03.2024 08:41+1Для постгреса есть расширение, которое если немного допилить, то можно собирать даже автоматически запросы и даже explain по ним всем сделать и записать в готовую табличку. Даже эффективнее порой, чем методом пристального взгляда собирать статистику по данным и запросам. Я просто запускал в docker-compose окружение, прогонял тестовые сценарии, потом смотрел табличку с сортировкой по проблемным запросам (время выполнения и наличие seq scan).
vp_arth
26.03.2024 08:41+1Если оно ещё и чанки всякие(`where id in(?, ?, ...,?)`) группировать умеет, цены ему нет. Что за расширение? И что значит немного допилить? Это про конфигурацию или код писать надо?

magarif
26.03.2024 08:41+1ChatGPT говорит, что это pg_stat_statements =)
onegreyonewhite
26.03.2024 08:41Именно так. Только надо допилить ручками некоторые вещи, чтобы работало как надо. В интернете полно мануалов. Я хотел статью написать, но руки не доходят. Там очень много нюансов надо объяснять.
Это про конфигурацию или код писать надо?
Да. Там нужно для больших запросов кое-что подправить в конфиге и для автоматического анализа пару-тройку функций написать.
Igelko
26.03.2024 08:41+2Ниже комментаторы уже накидали хороших вариантов автоматизации, а я обычно чаще всего писал запросы руками и потому прогрепать исходники на предмет нужной таблички было достаточно просто.
Тем более, что большая таблица в коде часто довольно хорошо локализована, в отличие от небольших справочников и запросы известны в лицо.
Когда использовал SQLAlchemy, то включал дебаг и вытаскивал запросы из консоли. В этом случае просто прогонял только небольшую ветку тестов, касающихся этой таблицы, чтоб не утонуть.
С ORM вообще смотреть в дебаг-консоль полезно, чтобы сразу увидеть, что генерируется плохой запрос.


kozlov_de
26.03.2024 08:41деструктивная операция удаления индекса и отсутствие внятного плана отката конечно никого не насторожили
и на препроде никто конечно не проверял
прод упал? ДИХСН
я бы вас депремировал и провел инструктаж всему отделу разработки
или в наказание заставил бы вас проводить инструктаж всему отделу

janson
26.03.2024 08:41+22Последнее однозначно нужно, разбор инцидента и выводы. И как я вижу, они пошли дальше - инструктаж провели на весь хабр ))

DarkHost
26.03.2024 08:41+1Ну да, куда же бюрократии. Ребята уже "хапнули" проблем, уже поняли в чем была их ошибка, сделали выводы и поняли как в следующий раз этого избежать. Нужно просто в рабочую вики записать информацию "для будущих поколений", и всё. Но нет, давайте обязательно сделаем совещание, да не одно, на котором это все будем несколько часов обсуждать и клевать всем мозги вопросами: "А вы уверены, что в следующий раз подобной проблемы не произойдет. А вы можете дать гарантии?"

gustav21
26.03.2024 08:41+1вместе с разработчиком из соседней команды — она тоже недавно прокололась на таком кейсе.
Непонятно только, почему эти выводы не были сделаны ещё в первый раз ) Надеюсь, об инциденте остальные команды узнают не через эту статью )
zorn-v100500
26.03.2024 08:41+5У вас ник сам за себя говорит.
А кто работать будет после этого ? )
Ну и из классики - "теперь ты стоишь миллион долларов".
Тот кто уронил прод, хорошо научился "как делать не нужно". Это вам не бумажные "не делай так" читать и дискутировать.

speshuric
26.03.2024 08:41+10я бы вас депремировал и провел инструктаж всему отделу разработки
Так есть шанс депремировать каждый квартал новую команду.

TimsTims
26.03.2024 08:41+9Зато там премию получают те, кто ничего не делают)
Hidden text
Не ошибается тот, кто ничего не делает. Ничего не делаем = прод не падал = премии не лишили. Сидим дальше.

vvbob
26.03.2024 08:41+4Смех-смехом, а часто так и бывает. Кто больше всех делает, тот и косячит больше, это неминуемо. Каким бы продвинутым спецом человек не был, при интенсивной работе все равно нет-нет да накосячит. От усталости, невнимательности, да и просто оттого что все знать невозможно, и знания часто появляются в результате ликвидации последствий своих-же ошибок.
Вот и получается в некоторых командах, что один пашет и постоянно огребает за косяки, а другой разгребает лайтовые некритичные баги и с начальством в курилке общается. Первый кругом неправ, а второй премии получает (реально из жизни пример, я был в качестве первого и мне не понравилось, уволился после выдачи халявщику очередной премии за успехи в работе, с которой меня прокинули).

Vitimbo
26.03.2024 08:41+1Можно получить премию и только после нее релизиться. К следующей премии начальство остынет и можно будет опять что-то уронить без урона для кошелька.

ef_end_y
26.03.2024 08:41А потом в таких коллективах вводят оценку производительности за количество строк написанного кода. Если бы меня хоть раз депремировали за ошибку, я гарантированно уволился


alexhott
26.03.2024 08:41+4А вариант: создать вместо старого новый уникальный индекс в user_id, resurce_id, deleted_at ?
а то потом среди удаленных надо будет чего-нибудь найти
Imbashket
26.03.2024 08:41+1И сколько таких записей будет? 100? 1000? Дешевле достать эту 1000 записей и отфильтровать, чем делать доп колонку в индексе на поллярда записей. Скорей всего, при таком количестве строк, индекс может даже скипнуться и сработать фул скан.
Ivan22
26.03.2024 08:41+20для аналитики такой паттерн - фактически антипаттерн. Всю базу переколбасить и индексы и запросы еще переделать. Для аналитики достаточно удаления оставить как и были просто логгировать в отдельную таблицу (ну или много таблиц) вида - [имя_таблицы] , [pk] , [дата удаления]. Ну и на стороне аналитического солюшена доработать ETL для обработли этого лога делитов. В итоге прод. база не меняется, все работает, все довольны.
p.s. А еще лучше иметь CDC солюшен который сам аптоматически трекает все измениния включая делиты, и из него сорсится аналитическая база

barloc
26.03.2024 08:41Кажется, что ребята экономят и на дата инженерах, и на аналитической инфре. Строить агрегаты в таком постгресе - представляю удовольствие. А потом ещё появляются шарды...

bondeg
26.03.2024 08:41+9Ещё лучше, не трекать абсолютно все изменения в принципе, а завести условный clickhouse, в который отправлять необходимые аналитикам данные в фоне.
Аналитика в принципе не должна работать с боевыми данными никогда.

ptr128
26.03.2024 08:41+7deleted_at = NULL
Это выражение всегда ложно.




zubrbonasus
26.03.2024 08:41Мне кажется вы уже давно пережили день, в который нужно было обзаводится микросервисами и развивать событийную архитектуру, и конечно же шардировать таблицы. Это позволило бы выбрать некоторый объем данных дабы не было ожидания в 5 часов.
Чем богаты тем и рады.

LeVoN_CCCP
26.03.2024 08:41Вот поэтому когда я вижу в резюме C#, дотнет, или там джаваскрипт, ксс и подобные вещи при этом в каждом стоит "знаю SQL" всегда бессознательно появляется улыбка.
Самое главное, о чём умолчала история - а где КуА-окружение? там где банально в пару кликов тестов (благодаря аналитике "частых кнопок") это всплыло просто в первый десяток минут прогона.
DMGarikk
26.03.2024 08:41+7я не автор, но прям с негодованием просится моя собственная боль
"Мы пишем код достаточно стабильный чтобы его еще и тестировать"
"тесты замедляют выход в фичей в прод"
;)) вангую что у автора чтото из этого

rinace
26.03.2024 08:41+2Мы не можем проводить нагрузочное тестирование , у нас сроки горят .

zavbaz
26.03.2024 08:41+1Если не тестировать то потом может подгореть что-то помимо срОков.
rinace
26.03.2024 08:41+1Я лично знаю не одну информационную систему которые регулярно падают, и в промышленной эксплуатацию без нагрузочного тестирования. Так, что насчет подгорания это страшилки для джунов. В реальном мире все несколько иначе.
DMGarikk
26.03.2024 08:41от сроков подгорит быстрее чем от падений и нестабильной работы...это реалии
LeVoN_CCCP
26.03.2024 08:41+1У меня один вопрос - если вы написали какой-то код, вы в тот же день его кидаете в прод?
Вспоминая все места где приходилось работать - стабильно раз в день ночью весь мастер просто гоняется функциями (в параллели несколько потоков есс-но), которые основные. И приходящий человек с утра когда видит, что обычные 2 часа может гарантировать всё ок. А если бы увидел 2.5-3 часа, уже встали бы вопросы.
Я говорил не про тесты новых фич - может они будут бесполезны (простите все кому наступил на больное) и их уберут, что вообще не надо тестировать. Но если ты вносишь изменения в основное, то основными тестами (которые опять же будут если написанное выше "обмазаны аналитикой" нужно именно "для понимания что делает пользователь" а не для красивых картинок руководству) его прогнать за пару дней. Тем более бывает что сделал что-то на коленке, просто чтоб текущий зазор закрыть а потом надо с мыслью "переспать" чтоб сделать по-другому и это лучше делать явно не тогда когда оно ушло в прод и начало обрастать костылями от коллеги.
onyxmaster
26.03.2024 08:41Каждый день пишу код и кидаю его в прод. И товарищи по работе тоже так делают. Несколько раз в день.

Akhristenko
26.03.2024 08:41+3Так проблема возникала не из-за того, что код не работает. А из-за того, что не используются индексы и он работает медленнее чем должно. И на одном пользователе это может быть незаметно, но вылезает потом в проде. А нагрузочное тестирование на каждый апдейт обычно не проводят.
vvbob
26.03.2024 08:41+2Удаление индекса - это не "каждый апдейт", ИМХО. Как раз тот случай когда надо проводить нагрузочное.

mayorovp
26.03.2024 08:41+1Не так-то просто провести нагрузочное тестирование переходного состояния, когда схема у БД по сути от одной версии ПО, а само ПО другой версии.
Особенно когда переходов много (и все автоматически не потестируешь), а разработчик не видит конкретно этот переход опасным.
vvbob
26.03.2024 08:41Понятно что непросто. Но потом чинить прод с горящей жопой и стоящим за спиной крайне недовольным тобой руководством, это куда как сложнее и неприятнее.
Понимаю, конечно, почему такое случается, сам так иногда так встревал. Кажется что исправление ерундовое, никакие проблемы не должно вызвать, а тестить все очень тщательно лень, да и хочется фикс побыстрее накатить.. А потом вдруг выясняется что этот ерундовый фикс ломает что-то очень важное..
mayorovp
26.03.2024 08:41+1Даже этот, в общем-то, простейший переход состоит из 4х шагов. Которых на самом деле больше (то же развёртывание нового кода включает в себя кучу промежуточных шагов).
Сколько ручных нагрузочных тестирований вы собираетесь проводить при каждом релизе?
vvbob
26.03.2024 08:41+3Еще раз - удаление индекса на нагруженной базе это не "каждый релиз", странно что приходится это повторять. Вы реально не видите разницы между фиксом какой-либо формочки и удалением индекса на таблице? Это изменение которое напрямую влияет на производительность, и делать такое наживую, не проверив на тестовой базе, это прямой путь к таким вот инцидентам, о чем собственно автор и написал.
И выводы были сделаны какие-то странные: "плохо что это случилось, хорошо что мы все починили".. КМК вывод тут главный должен быть такой - Теперь мы все подобные фиксы сначала проверяем на специальной тестовой БД, имитирующей нагрузку прода, и только потом выкатываемся на прод.
LeVoN_CCCP
26.03.2024 08:41Я не говорил про нерабочий код и не говорил про медленнее, мной было написана мысль "работает не так как ожидается" (для меня это равносильно не работает, код вроде бы есть и он работает, но не так как задумывалось) и вот это проверяется именно что авто-тестированием в КуА (или как его кто называет).
На одном пользователе, то есть КуА контур гоняет авто-тесты в один поток? Ну ладно, ваше дело. Я выше написал комментарий другому человеку, посмотрите, там есть ещё пара смежных мыслей.
ptr128
26.03.2024 08:41+6Я бы решал эту задачу проще.
Для каждой таблицы добавил бы её аналог с дополнительным полем времени удаления в первичном ключе: deleted timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP.
На каждой таблице создал бы AFTER DELETED триггер FOR EACH STATEMENT с функцией, вставляющей все удаленные записи в таблицу из п.1
И для клиентов абсолютно прозрачно, и индексы вообще трогать не надо.

sirmax123
26.03.2024 08:41+2Это хорошо но поддерживать сложно потом
ptr128
26.03.2024 08:41+4Можете более развернуто объяснить суть этих сложностей?
Как по мне, поддерживать обязательное наличие в выражениях WHERE и ON на клиентах условие частичного индекса и не забывать там же выполнять UPDATE вместо DELETE - куда сложней для поддержки.
sirmax123
26.03.2024 08:41+5Я работал с биллингом провайдера, где логика была размазана между кодом приложения и хранимкам/триггерами в базе, лично мне (возможно от недостатка квалификации) это было сложно поддерживать и модифицировать. Да, никакого стейджинга у нас конечно не было, по финансовым соображениям.
Меня смущает размазывание логики по разным местам, ничего более
ptr128
26.03.2024 08:41+1Вообще исключить логику из реляционной БД невозможно и даже вредно. Первичные и уникальные ключи, внешние ключи, различные ограничения (CONSTRAINT), секционирование, репликация и т.п. - это тоже логика. Обычно все же избегают реализации в БД только бизнес-логики, да и то не всегда это удается без существенного ущерба производительности.
В предложенном моем сценарии бизнес-логика не затрагивается, а логика в БД прозрачна для приложения.
sirmax123
26.03.2024 08:41+2Во-первых я с вами совершенно согласен в вопросе того, что логику вынести из базы нельзя
Во-вторых я согласен с утверждением что часто более производительные решения - это использовании возможностей базы
Но я не cогласен что триггер это не бизнес-логика, с точки зрения приложения данные перемещаются какой-то магией.
Вот представьте что пришел новый разработчик и условно решил "погрепать" код что бы найти место, где заполняется табличка с удаленными записями? И что он найдет? Догадается в базе посмотреть или нет? Где код этих функций/триггеров храните, вместе с кодом приложения или отдельно в другом репозитории? Если вместе/отдельно по почему так? А если отдеьная группа разработчиков их пишет, и эта группа хочет использовать свой флоу какой-то, да и сидят они в другом городе/стране (тут я уже конечно перегибаю, но бывает всякое)
А потом в базе случилась неконсистентность, допустим из-за бага, и нужно руками выполнить запрос(ы) - не забудете триггер отключить?
В общем, кроме очевидных приимуществ использование триггеров может нести еще и некоторые неудобства, о которых я собственно и говорю.ptr128
26.03.2024 08:41Но я не cогласен что триггер это не бизнес-логика, с точки зрения приложения данные перемещаются какой-то магией.
Вы, конечно, вправе иметь свое мнение и давать свою семантику термину "бизнес-логика". Но тогда "какая-то магия" - это так же ошибки дублировании ключей, внешних ключей, заполнение значениями по умолчанию, вычисляемые поля, секционирование и многое другое.
Вот представьте что пришел новый разработчик и условно решил "погрепать" код что бы найти место, где заполняется табличка с удаленными записями?
Если разработчик не в состоянии запустить поиск по регулярному выражению в локальной копии репозитория проекта, то, боюсь - это не разработчик.
Где код этих функций/триггеров храните, вместе с кодом приложения или отдельно в другом репозитории? Если вместе/отдельно по почему так?
Обычно, проект в одном репозитории, так как метаданные, переносимые данные, миграции и т.п. непосредственно связаны с кодом приложения и являются его неотъемлемой частью. Исключения рассмотрены ниже и требуют контрактов.
А если отдеьная группа разработчиков их пишет
Если при этом почему-то всё равно требуется прямой доступ к БД, то они будут работать с витринами данных и подробности внутренней организации последних для разработчиков будут скрыты. Будет контракт подразумевать, что конкретное приложение видит только не удаленные записи - вторая таблица им будет недоступна. Будет контракт подразумевать видимость в одной таблице и тех и других записей - это будет предоставлено через секционирование или представление.
На практике же, такой подход считается устаревшим и отдельная группа разработчиков не будет иметь доступа к БД, ограниченная контрактами только на сервисы или топики.
vvbob
26.03.2024 08:41А в чем тут сложность? Один раз создал таблицу и триггер, и больше поддерживать там нечего, просто записи сыпятся в эту "корзину". Причем создать все это можно в миграции, т.е. в репозитории кода эта операция будет присутствовать и будет понятно откуда что появилось.
ЗЫ ну разве что, вижу доп. сложность в том, что при изменении исходной таблицы надо будет делать такие-же изменения в "корзине" что-бы данные соответствовали. Тут да, некоторая сложность появляется.
vvbob
26.03.2024 08:41+1Еще плюс, при вашем варианте основные таблицы не будут распухать, если записи часто удаляют, будут пухнуть таблицы с удаленными записями, но они для аналитики и наверняка не так активно юзаются.
rinace
26.03.2024 08:41+1Хорошо, когда точно известна причина падения .
В жизни как правило, чуть другой сценарий - рабочий день начался , пришли пользователи - прод упал.
И начинается самое интересное - "Кто виноват? Что делать?"

Didntread
26.03.2024 08:41+1хорошо еще, что день начался, а не закончился
rinace
26.03.2024 08:41+3По житейскому опыту - когда день кончился и все упало - легче и проще.
Клиентов почти нет , нагрузки нет , топов нет , манагеров почти нет . Проблема как правило в железе или виртуализации.
А вот когда днём - совсем другие шаманские танцы начинаются . Основной мотив - мы упёрлись в СУБД, дайте нам серебряные пули и волшебный эликсир . И конечно стандартная игра в футбол , переходящая в волейбол - "у нас всё хорошо , проблема не в приложении".
Местами даже весело ...
Ivan22
26.03.2024 08:41а еще бывает, это у тебя в европе день уже закончился, а у клиентов в штатах только начался, и они давай тебе ошибки сыпать до полуночи

teror4uks
26.03.2024 08:41+1В целом из текста не понятна роль тим лида в команде, т.е. ситуация с добавлением индекса или колонки в бд не выглядит как что то экстраординарное, но всё же требует повышенного внимания, а здесь получается что никакого контроля от старших коллег по цеху не было, что настораживает, или он просто не разбирается как такое должно быть реализовано, (а это уже проблемы посерьёзнее). Подтверждение тому в словах автора что кто то из коллег уже ронял прод с похожим кеййсом и похоже никого это так и не насторожило.
TimsTims
26.03.2024 08:41+2никакого контроля от старших коллег по цеху не было
Вот тут автор в статье очень подробно расписал какую задачу он решал, какой план работ придумал. Читая этот план работ сразу на уме возникала только одна мысль: "ну вроде логично, проблем вроде не предвидится". Так что можно сказать "весь хабр проконтролировал". Но ошибся. Человеческой фактор. И мы с вами не знаем - был ли "контроль тимлида" или нет - факт остаётся фактом - прод падал.
Спихивать ответственность на тимлидов - плохая практика. Разработчики так разленятся думать и будут писать говнокод, который должен будет настырно контролировать лид. "Пропустил мой плохой код - сам виноват!".
Другими словами - неважно был ли там контроль, или нет - от инцидента бы это маловероятно что спасло.
Подтверждение тому в словах автора что кто то из коллег уже ронял прод с похожим кеййсом
Нет, не было у них похожих кейсов. Там же написано, что все роняли прод по такой то причине (другой).
teror4uks
26.03.2024 08:41ну вроде логично, проблем вроде не предвидится"
"на бумаге" всё логично вот как раз и должны быть люди которые под сомнения поставят эту логичность обычно у которых есть опыт такого, например лиды
Спихивать ответственность на тимлидов - плохая практика. Разработчики так разленятся думать и будут писать говнокод, который должен будет настырно контролировать лид.
конечно лид проглядел значит он виноват, это его команда уронила, а он не проконтролировал, не сказал протестить лучше, больше, и т.д. Ничего настырно контролировать не нужно, если человек не тянет, то возможно или задачи не по уровню отдаются, или наняли не того, всегда есть разные варианты решения
Нет, не было у них похожих кейсов. Там же написано, что все роняли прод по такой то причине (другой).
цитата автора из текста: "Но есть более правильный вариант, к которому мы пришли вместе с разработчиком из соседней команды — она тоже недавно прокололась на таком кейсе."

WarLikeLaux
26.03.2024 08:41+2А как же тестирование на stage с меньшим размером БД? Это же вроде как база должна быть для таких изменений, которые быстро не откатить, даже если кажется что всё ОК будет.

gleb_l
26.03.2024 08:41+9Ну вот нельзя так просто взять серебряную пулю из коробки, и убить ей зомби всех мастей. К каждой гадине нужно подбирать свою :).
У данных есть степень динамичности (текучка кадров), как и у плохих разработчиков, или плохих руководителей. Если ваш бизнес a priori отправляет в утиль 90% генерированных данных (не в обиду, а в силу особенностей бизнеса - чел закрыл онлайн-сессию обучения - ее, и весь ее контекст - в треш) - то это значит, что в рабочих таблицах 90% строк будут забиты ботвой, и лишь 10% - текуще-полезны.
А теперь вброс - R/W хранилище с поддержкой ACID - самый дорогой (во всех смыслах) и вычислительноемкий способ хранения данных (в том числе ботвы). Использование его механизмов (втч ссылочной целостности) на 90% для хранения отработки - сильное архитектурное расточительство.
Аналитике нужны R/O данные - поэтому правы те, кто советуют сносить удаленное в специальные таблицы и/или R/O базы для анализа. Кесарю-кесарево.
Далее, если вам комбинированная работа с данными "как-то не очень" - неважно, шардирование, часть логики в SP итд - то за это рано или поздно придется кому-то сильно заплатить - либо железом, либо переделкой архитектуры, либо троттлом бизнеса. Все конкуретноспособные системы уходят от средних или паттерновых подходов в пользу эджевых - ибо дьявол в деталях, и соревнуются уже далеко не на пределе возможностей коробочных решений, а либо на уровне своих кастомных IP, либо тех же коробок, обложенных по кругу своими же воркэраундами ;)
PS - а что вы будете делать со ссылочной целостностью, которая теперь не гарантируется на уровне RDBMS? Как трактовать ссылки FK на PK, который помечен, как удаленный?

mvv-rus
26.03.2024 08:41+2План бесшовного релиза
Когда новый код с soft delete на проде, старый уникальный индекс нужно удалить. Иначе он не даст добавить новые записи, аналогичные удаленным с помощью soft delete. C другой стороны, нельзя удалять старый уникальный индекс, пока работает старый код.
Нам пришла идея: вместе с новым partial индексом создать временный поисковый индекс — аналогичный старому, но без ограничения уникальности.
...
В этом случае в любой момент релиза поисковые запросы будут работать быстро, и мы не получим проблем со вставкой новых записей.
Вы не пробовали оценить вероятность появления в таблице по-настоящему дублирующих записей (с deleted_at is null)? А то ведь буде такая появится, то ваш замечательный частичный индекс просто не создастся.
PS Есть еще пара вопросов, чисто технических, но они не в тему IMHO. Потому что тема - она как уронить бой и выжить после этого.

Xambey97
26.03.2024 08:41+3Вообще ситуация с этим удручает, повсюду девопсов выгоняют с обслуживания проектов, скидывают в нагрузку эти задачи разработчикам + менеджеры часто не дают время на нормальное написание тестов, особенно интеграционных, и пайплайнов адекватных (а бывает еще что и инфраструктура швах, документации нет, дофига самописных инструментов, сиди настраивай), чтобы все это проверить автоматически перед выпусками часто или нет совсем, или минимум. А потом крупные системы ложатся вот так... И так в +- среднем по больнице даже в самых крупных IT компаниях на рынке рф, особенно на новых проектах, где фичи надо было выпустить еще позавчера, хотя и на моей памяти мертвых более чем на 5 минут продов практически не бывало, но вот выкатка в прод. не рабочего функционала или когда что-то отваливается в процессе, сколько угодно

not-allowed-here
26.03.2024 08:41а потом люди удивляются почему это у "девопса" в каморке стоит пара стареньких серваков на которых актуальны бекап системы в полном конфиге крутится.... +)))

zaiats_2k
26.03.2024 08:41+1А потом крупные системы ложатся вот так...
Возможно потому, что на самом деле "упущенная прибыль" от таких падений не так велика? Ну вот сколько на самом деле таких людей, которые именно в эти 1.5 часа хотели расстаться со своими деньгами, и в итоге отказались от этой идеи? Может быть большинство просто подумало, "ну, это интернет, тут бывает сайты лежат", и зашли на следующий день и всё оплатили.

GTAlex
26.03.2024 08:41А где прогон всех этапов на дев/стейдж стенде с проверкой включения индексов после удаления основного?
И ещё, после добавления поля и новых индексов уже сразу можно код править на предмет корректировки WHERE чтобы partial index заработали до удаления основного?

msincster
26.03.2024 08:41как я понял, то эта фича в WHERE добавляется тем самым расширением, так что для такого сценария нужно было все запросы вручную править, а после включения расширения - убирать (как уже было предложено ранее в комментах)
rinace
26.03.2024 08:41Добавлю свои 5 копеек:
1) Уронил прод на Оракле запросом к недокументированному представлению
2) ошибся с pid для kill -9 и прибил системный процесс PostgreSQL
Сорри, но это всё.

not-allowed-here
26.03.2024 08:41+4не ну я конечно тот еще ретроград, но ИМХО - а для аналитики нужна Нагрузка на продуктивную базу? и у вас настолько критична Задержка Аналитики в пару суток?
почему нельзя - просто поставить старенький сервак с 6 SSD SOHO класса и выгружать на него БД раз в 2-3 дня для аналитики через бекапы? За одно еще и точку бекапов получите дополнительную и регулярный тест консистентности бекапов и Песочницу для условно нагрузочного тестирования....
vp_arth
26.03.2024 08:41А может там как раз для какой-нибудь инкрементальной выгружалки с реплики эти таймстемпы нужны.
not-allowed-here
26.03.2024 08:41хм, тогда опять же вопросы к Архитектуре БД и отсутствию конкретной роли DBA..... да и нагрузки получаются кошмарные - если в целом эта "выгружалка с реплики" оперирует существенными объемами... в целом всё равно получается пачка вопросов с Общим смыслом - "А нафига так-то?!"
vp_arth
26.03.2024 08:41Ничего не понимаю. В соседней ветке ты такую же выгружалку называешь «идеальной», а тут «нафига так-то?». В чём разница?
not-allowed-here
26.03.2024 08:41Варианты конечно возможны всякие - но там система описана другая и там аналитика сбоку от Frontend - который шлет туда весь поток событий именно нужных для бизнес-аналитики не касаясь БД Прода - вот такая система "идеальная" - она собирает Событийно полно и не грузит продуктивную БД и в любой момент может отвалится, сломаться и/или сдохнуть не повлияв на работу Прода.
а периодическая "выгружалка" дергающая данные из БД прода ради такой "логики" Ущербна концептуально - потому что по сути это тот же бекап, но куском....
vp_arth
26.03.2024 08:41Событийка с фронта и аналитика по данным в БД — это две разные системы, разные источники данных для аналитики. И зачастую, нужны обе. Не все бизнес-процессы инициирует конечный пользователь.
с отдельной БД, в которую из основной данные периодически подгружаются.
А это как раз про выгружалку, которая «по сути тот же бэкап»
not-allowed-here
26.03.2024 08:41Событийка с фронта и аналитика по данным в БД — это две разные системы, разные источники данных для аналитики.
именно - и поэтому неправильно сваливать всю аналитику в Прод - аналитика по данным БД делатеnся отдельно от прода по RO реплике(бессмысленно, но или если так уж Хочется потратить лишние деньги - то по Реплике для Бекапа) или по Бекапу - в реальности и в 99.9999% случаев - Аналитика легко может отставать на неделю от реального времени без потери эффективности. да и точность для аналитики в масштабе плюс минус 5% за глаза - всё равно "накопленная ошибка" с момента съема данных до формирования и тем более до начала влияния отчета "съест" точность....
А это как раз про выгружалку, которая «по сути тот же бэкап»
конкретно в предлагаемой реализации нет работы с БД прода - просто поток событий Фронта дублируется на систему аналитики.
И зачастую, нужны обе. Не все бизнес-процессы инициирует конечный пользователь.
туту опять же вопрос архитектуры - если возникает ситуация которую нужно крутить БИЗНЕС аналитикам не отражающуюся в фронте - это странно - нужно ли аналитикам её видеть? и как клиенты(тут в широком смысле - пользователи системы не только внешние но и внутренние) узнают о таком процессе?
или тут Бизнес аналитика увязана с техничкой? опять же а нафига? Техничка ни в коем случае не должна пересекаться с бизнесом и выходить за рамки контура безопасности прода - черепова-то, однако....
vvbob
26.03.2024 08:41+1Можно и чуть сложнее, зато более актуальная аналитика будет. У нас для аналитики крутится как отдельный сервис, с отдельной БД, в которую из основной данные периодически подгружаются. Т.о. любой факап на БД аналитики никаким образом не заденет прод. И если аналитика слишком уж начнет активно все анализировать, то на скорости работы прода это тоже никак не отразится.
not-allowed-here
26.03.2024 08:41ну судя по отсутствию нагрузочного тестирования и анализа работы БД после Глобальных реорганизаций мой вариант Ребятам будет Крайне не лишним - ваш вобще идеален - но тут вопрос реализации им счас для его внедрения надо завести 301-ю БД и поправить сбор аналитики во всем frontend

Homyakin
26.03.2024 08:41Наверное архитектурно лучше вынести данные для аналитики в отдельную БД и сервис (если ресурсы есть), чтобы изменения там не влияли на основной поток.

lyekka
26.03.2024 08:41Вместо создания неуникального индекса сработало бы временное создание RULE на выборку с предикатом deleted_at IS NULL?

Galahed
26.03.2024 08:41+1Паттерн soft delition предполагает окурки, а не полноценные записи. Которые числятся через определённое время. Так же и другие логированные действия сохраняются в отчеты за периоды с необходимвм бизнесу уровнем детализации и чистятся. Отчеты существуют в отдельной БД от сбора статистики и от основной прод бд тоже.
Основная бд тоже должна быть распилена, даже если там одна таблица ивообще ничо не придумать - распиливайте по датам, первым цифрам id аккаунтов и проч (пример тупой, обычно можно придумать как распилить так, чтобы снизить нагрузку и не потерять бизнес смысл).
Дальше - отчеты собираются и анализируются в отдельных СУБД. Для анализа хороши колоночные СУБД типа клик хаус, для сбора можно использовать даже не СУБД, а тупо писать на диск в соответствующие смысловой нагрузке файлы и пути байты (дозаписывать файлы). Потом собирать все это раз в сутки ночью. Ну или использовать более что-то распространённое под highload.

RoKon4eg
26.03.2024 08:41Не секрет, что современный софт обвешан аналитикой — каждое действие пользователя обезличивается и логируется.
Типичные события в журнале аналитиков: пользователь открыл страницу, пользователь кликнул по кнопке и так далее. Это помогает понять, на какие кнопки кликают чаще других, а какие пора выкинуть за ненадобностью. Бизнес, в свою очередь, может делать выводы, какие фичи в приложении нравятся пользователям, а какие «не взлетели»
Есть подозрение, что логирование не обезличенное. СкайЭнг и еще Тинькофф - два сайта куда боишься лишний раз мышкой кликнуть - т.к. потом будет шквал звонков от менеджеров и обращений во все мессенджеры...

gotomadness
26.03.2024 08:41План бесшовного релиза
угу, а за время c не уникальным индексом (после дропа old и до релиза) - наделать дублей в базу, сразу этого даже не заметить и делать задумчивое лицо на ломающемся очередном реиндексе/full vacuum/(упаси) наливки дампа)

olegsklyarov Автор
26.03.2024 08:41+2В окне после drop old index и до релиза soft delete, в БД уже живет новый уникальный partial index. Он не даст сделать дубликат.
Потому что все записи в БД с
deleted_at IS NULLи все эти записи уже под новым уникальным partial индексом.

chigiwar
26.03.2024 08:41Вывод: тестируйте миграции на препроде, запускайте нагрузочные тесты после изменений.

Yuriy_75
26.03.2024 08:41+1C "мягким удалением" необходимо понимать факт, что FK в таблице уже не обеспечивают целостности данных. Если одна строка уже "мягко" удалена, при этом есть строки в других таблицах, которые на нее ссылаются - эти строки валидны или нет?

gwathedhel
26.03.2024 08:41Эм, тестовый стенд? Погонять с нагрузкой, проверить как все заработает после деплоя? Не? Сразу хехрачим в прод, ну а чо?
А потом спрашивают, почему так относятся в прогерам...
mayorovp
26.03.2024 08:41+2Так после деплоя-то всё заработало, проблема случилась в процессе.
gwathedhel
26.03.2024 08:41Так для того и нужен стенд, чтобы проверить с нагрузкой как такие серьезные изменения с базой будут отрабатывать. По загрузке базы можно было бы предугадать насколько загрузится и прод. И увидеть заранее проблему с индексом.
vvbob
26.03.2024 08:41Проблем с индексами на тестовой БД и без нагрузки можно было бы увидеть, просто посмотрев план выполнения типичных запросов.

R0bur
26.03.2024 08:41Нам пришла идея: вместе с новым partial индексом создать временный поисковый индекс — аналогичный старому, но без ограничения уникальности.
Как я понял, установка обновления программ с поддержкой Soft Delete занимает заметное время. И пока старые программы работают со временным неуникальным индексом, в БД могут появиться записи, от которых раньше защищало требование уникальности. Поэтому, наверное, этот метод тоже нельзя считать идеальным?

jobgemws
26.03.2024 08:41Вопрос в лоб: т е не делалась проверка гипотезы, что с новым индексом будет лучше и что вообще новый индекс будет использоваться?
Здесь проблема значительно шире, а именно что не делается проверка гипотезы в том числе даже если написано так в документации. Нет! Всё нужно перепроверять с учётом специфики системы.

datacompboy
26.03.2024 08:41Нам пришла идея: вместе с новым partial индексом создать временный поисковый индекс — аналогичный старому, но без ограничения уникальности.
а как быть с тем, что код при этом в случае дубликатов будет получать двойные строки -- где одна старая, а одна новая? То есть вместо 5хх для ситуаций, которые код не умеет обрабатывать, получаем гораздо менее заметные и более подлюччие ошибки.
Лучше окно с 5хх пока код мигрируется.
Еще лучше -- делать миграцию кода в несколько шагов:
Добавяем deleted_at default null. Если что пошло не так -- дропнуть поле быстро.
Пушим код, в котором запросы с "and deleted_at is null". Если что не так -- всегда можно откатить флаг включающий его.
Добавляем новый индекс. Если внезапно пошло не так -- можем быстро дропнуть.
Удаляем уникальный индекс. Кочка невозврата (если что-то пошло не так -- откат это 5 часов).
Флипаем флаг на soft delete. Если что не так -- флаг можем флипнуть взад, и/или ручками "delete where deleted_at is not null".
Yuriy_75
26.03.2024 08:41Еще не забыть про каскадное проставление признака deleted_at в связанных записях.
datacompboy
26.03.2024 08:41Каскады в highload? Но зачем? Это ж верный путь в tail latency hell
Yuriy_75
26.03.2024 08:41Так что же, если highload - пускай будут в данных несоответствия?
Это конечно тоже можно скрыть, если во всех селектах джойнить и все таблицы на которые идут ссылки в FK. И в них уже deleted_at проверять.
datacompboy
26.03.2024 08:41Если хайлоад, то eventual consistency как правило приемлемо, либо полагаемся на денормализацию, либо на offline чистку (вне потока обработки). Так же как банк показывает последний известный баланс и норм провести транзакции ночью :)

Kuzzzzmin
26.03.2024 08:41Когда ты сам роняешь прод - это опыт, но часто его оплачивает компания по дорогому прайсу, обидно когда тебе роняют прод внешним влиянием и кроме боли никто ничего не получает при тех же затратах.

nikhotmsk
26.03.2024 08:41Вот я смотрю на всё это, и у меня вопрос: может ли бизнес исключить использование SQL в принципе и перейти на самописную базу данных, хотя бы на новых проектах? Плюсы очевидны же, сам написал индекс - сам знаешь как оно работает.
vp_arth
26.03.2024 08:41+2Бизнесу в подавляющем большинстве случаев по барабану на то, что у тебя там на серверах крутится. Сможешь обеспечить не худшие циферки стоимости, производительности и надёжности — убеди и вперёд. Хоть по файлику итерируйся.
Ещё один вопрос со стороны бизнеса будет, конечно, «А где мы найдём спецов по этому велосипеду, когда ты уйдёшь?»Yuriy_75
26.03.2024 08:41Насчет производительности и надежности можно будет утверждать, только погоняв базу с числом записей, которое отвечает самым радужным ожиданиям на развитие бизнеса в ближайшие годы.
Иначе имеем случай, когда на 10 тыс клиентов все летало, а на 1 млн вдруг затормозило.

Dominux
26.03.2024 08:41+2~0,5 млрд записей в одной таблице БД
Как такая большая платформа ещё не упала? Про шардинг и репликации не слышали?
Не секрет, что современный софт обвешан аналитикой — каждое действие пользователя обезличивается и логируется
Для аналитики логично использовать OLAP, все же специально для этого созданы как никак. Смысл в том, что данные для аналитики почти никогда не нужны в реальном времени, они требуются для ее дальнейшего отложенного анализа. Общепринятый вариант - писать аналитику в отдельный сервис, чтобы если тот упадет или нагрузится, то это не мешало работать основным критически-важным риалтайм сервисам.
P.s.: с одной стороны мы имеем мидлов, которым на собесах задают вопросы по видам и тонкостям шардинга, а с другой - топовые платформы, на которых ребята никогда не слышали даже об OLAP или о выделении некоторой логики в отдельные сервисы

Northerner19
26.03.2024 08:41Был у меня подобный опыт вставки новых индексов и прод шакалило несколько часов пока все записи не проиндексировались. После такого все запросы тупо встали и была не просто задержка а все по таймауту улетало с клиента. Но это был не самый серъезный мой фейл.
Полностью ронять прод получалось только на несколько минут но по мне более опасная ситуация когда все вроде работает но есть "нюанс") Этим нюансом было состояние заказа. В какой-то момент клиент пожаловался что он оплатил одну и туже покупку 5 раз. Просто тыкал на кнопку и ждал результата. Все оказалось до банальности тупо - отсутствовала проверка состояния заказа а фронт не подстраховал, потом конечно кнопку оплаты после нажатия дизейбили но факт проблемы вскрылся. Менеджер мне ничего не сказал, типа херня случается. Клиенту потом конечно деньги вернули) Но масштаб проблемы мог быть спокойно в разы больше. Были и другие косяки примерно такого же уровня но у кого они не было по опыту? Автора с посвящением )

asumin
26.03.2024 08:41Не душноты ради, просто интересно. Имеем исходные данные: high load и аналитические запросы и стек под это : PHP 8.1, Symfony 5, orm Doctrine, PostgreSQL, почему ни click house + golang, например?
ptr128
26.03.2024 08:41click house
Например, потому что нужен ACID. Причем не только в пределах одного INSERT в одну не распределенную таблицу.

lexore
26.03.2024 08:41+1добавить поле deleted_at
добавить в запросы "and deleted_at = null"
А дальше можно следовать плану автора.
Ну и повторю умные мысли из комментариев:
Нет отката = двойная проверка на стейджинге. Особенно про БД.
Брать аналитику с прод БД чревато падениями этой БД. Даже с реплики не стоит брать.

JumpinCarrot
26.03.2024 08:41+1Логика нашего приложения допускает повторную вставку записи после ее
удаления. Но после внедрения soft delete мы больше не сможем вставить в
БД запись с такой же парой (user_idиresource_id) из-за нарушения уникальности — БД выдаст ошибку.А можете мне объяснить, как непрофессионалу в БД, почему мы хотим вставлять новую запись с таким же идентификатором? Разве нельзя использовать новый?
mayorovp
26.03.2024 08:41Потому что это внешние ключи, т.е. идентификаторы других записей. Как можно "использовать новый идентификатор", когда нам нужен именно этот?

Chipazawra
26.03.2024 08:41+1Шарить продуктовую базу с другими командами большая ошибка темболее с аналитиками. Как минимум можно им дать async реплику для этого.
mgis
Последняя картинка позабавила)
Я когда пару раз прод ломал, безумно нервничал и корил себя.