
Высококачественные данные — это «топливо» для современных моделей глубокого обучения. Большая часть данных, размеченных под конкретные задачи, создается живыми людьми — аннотаторами, которые занимаются классификацией или проводят RLHF-разметку для LLM alignment. Многие из представленных в этой публикации методов машинного обучения могут помочь улучшить качество данных, но главным остается внимание к деталям и скрупулёзность.
Сообщество разработчиков машинного обучения осознает ценность высококачественных данных, но почему-то складывается впечатление, что «все хотят работать над моделями, а не над данными» (Sambasivan et al. 2021).
Рисунок 1. Два направления обеспечения высокого качества данных.
Эксперты-классификаторы ↔ качество данных
В процессе ручного сбора данных выполняется определенная последовательность этапов, каждый из которых вносит вклад в качество датасета:
- Разработка задачи: проектировать процесс работы над задачей нужно так, чтобы она стала яснее и проще. Подробные инструкции полезны, но если они слишком длинные и сложные, потребуется больше времени на подготовку к их выполнению.
- Подбор и обучение группы классификаторов: необходимо выбирать аннотаторов, имеющих нужные навыки и подходящий уровень единообразия меток. Необходимы тренинги. После онбординга также требуются регулярные сессии обратной связи и калибровки.
- Сбор и агрегирование данных. На этом этапе применяются дополнительные ML-методы для очистки, фильтрации и умной агрегации данных, чтобы выявить достоверные метки.

Рисунок 2. Контроль качества — это набор действий, позволяющих повысить качество, работая с атрибутами, указанными в модели качества.
Мудрость толпы
В 1907 году в журнале Nature была опубликована короткая статья с названием Vox populi (изначально «Vox populi, vox Dei») — латинская фраза, означающая «голос народа». В публикации рассказывалось о конкурсе на ежегодной выставке: организаторы предлагали людям угадать вес большого быка. За достаточно близкую догадку можно было выиграть приз. Среднее значение ответов расценивалось как «vox populi» и в конечном итоге оказалось очень близко к настоящему весу животного. Автор статьи сделал такой вывод: «Мне кажется, такой результат говорит о большей надежности демократического мнения, чем можно было ожидать». Наверное, это стало самым ранним упоминанием того, как работает краудсорсинг («мудрость толпы»).
Почти сто лет спустя Крис Кэллисон-Берч (Chris Callison-Burch) провел исследование (2009) по использованию Amazon Mechanical Turk (AMT) для оценки задач машинного перевода (Machine Translation, MT) неспециалистами и по созданию новых «золотых стандартов» перевода с их помощью. Схема оценки была проста: каждому аннотатору показывали исходное предложение, эталонный перевод и пять переводов пяти систем MT. Участников просили ранжировать пять переводов от лучшего к худшему. Каждую задачу выполняло пять аннотаторов.
Разумеется, существуют спамеры, создающие низкокачественные аннотации, чтобы оптимизировать объем (выполненных задач прим. переводчика), а значит, и свой заработок. Поэтому при измерении договоренностей между специалистами и неспециалистами необходимо применять различные схемы взвешивания, чтобы снизить вклад спамеров: (1) «взвешенные по специалистам»: использовать коэффициент консенсуса со специалистами на золотом наборе из 10 примеров; (2) «взвешенные по неспециалистам»: использовать коэффициент консенсуса с остальными аннотаторами для всего датасета.
В более сложной задаче аннотаторов-неспециалистов попросили создать новые «золотые» эталонные переводы. Кэллисон-Берч спроектировал задачу в два этапа: на первом этапе создавались новые переводы с учетом результатов работы МТ, а на втором фильтровались переводы, которые могли показаться сгенерированными системой MT. Корреляция между переводами специалистов и приглашенных аннотаторов оказалась выше, чем между переводами специалистов и систем MT.

Рисунок 3. (Слева) Коэффициент консенсуса, измеренный сравнением каждой пары переводимых предложений («A > B», «A=B», «A < B»), то есть случайный коэффициент консенсуса равен 1/3. Верхняя граница установлена по коэффициенту консенсуса между специалистами. (Справа) Сравнение оценки BLEU между переводами из различных источников. Переводы специалистов предоставлены переводчиками LCD (Linguistic Data Consortium)
Консенсус оценщиков
Мы часто воспринимаем аннотирование как стремление к единственной непреложной истине и пытаемся оценить качество по одному золотому ответу и постоянным стандартам. Общепринятой практикой для поиска является сбор множества меток от ряда оценщиков. Учитывая, что каждый специалист работает с разным уровнем качества, можно использовать средневзвешенное значение аннотаций, но взвешивать его нужно по уровню (баллу) квалификации. Эта оценка квалификации часто аппроксимируется по тому, насколько часто один оценщик соглашается с другими.
Мажоритарное голосование: это самый простой способ агрегирования, эквивалентный взятию моды множества меток. В этом случае каждый аннотатор вносит равный вклад.
«Сырой» консенсус (Tratz & Hovy, 2010): при «сыром» консенсусе подсчитывается процент всех остальных людей, согласных с аннотатором. Он косвенно связан с мажоритарным голосованием: ожидается, что все члены класса большинства получат более высокий коэффициент консенсуса между аннотаторами.
Каппа-статистика Коэна (Landis & Koch, 1977): каппа-статистика Коэна измеряет консенсус между аннотаторами в виде
Графовое вероятностное моделирование: существует много работ, в которых графовое вероятностное моделирование используется для моделирования различных факторов при принятии решений при аннотировании, например, сложности задачи, латентных темы задачи, предвзятости аннотаторов и их надежности. Они используются для прогнозирования истинных меток. Zheng et al. (2017) сравнили 17 алгоритмов инференса истины при краудсорсинге, и большинство из них представляют собой графовые вероятностные модели.
-
MACE (Multi-Annotator Competence Estimation; Hovy et al. 2013) — это один из первых примеров использования графового моделирования, С его помощью оценивают вероятность того, что аннотатор расставляет случайные метки и действует как «спамер». Если система вознаграждений выстроена неправильно, то некоторые аннотаторы могут вести себя как «спамеры». Так они хотят оптимизировать количество выполненных задач и побольше заработать. Задача MACE — выявление спамеров. Пусть есть задача
, аннотатор
, истинная разметка
, присвоенная разметка
и
— моделирующая вероятность того, что аннотатор
занимается спамом. Тогда генеративный процесс можно представить показанным ниже способом. Параметр
определяет надёжность аннотатора
(вероятность того, что он не спамит), а параметр
определяет, как ведёт себя аннотатор, когда он спамит.
Затем мы можем для максимизации наблюдаемых данных получить
Для максимизации приведённой выше вероятности предельных величин можно применить или EM (Expectation–maximization), или VB (Variational Bayes). В процессе оптимизации EM на этапе M к частично учитываемым потерям перед нормализацией прибавляется фиксированное значение
Разногласия аннотаторов и две парадигмы
Описанный выше процесс агрегирования опирается на допущение, что существует единственный «золотой» ответ, поэтому мы соответствующим образом можем оценивать показатели аннотаторов. Однако во многих темах, особенно в сферах безопасности, социальных взаимодействий или культуры, люди могут обоснованно не соглашаться друг с другом. Тогда вопрос сводится к тому, насколько мы хотим применять строгие правила вместо принятия разнообразия мнений.
Aroyo & Welty (2015) рассматривали различные выводы, сложившиеся в практике сбора аннотаций, сделанных людьми, и выяснили, что все они неточны вплоть до того, что становятся «мифами». Основные заключения:
- Для некоторых выборок часто бывает более одной правильной интерпретации. Нужно использовать различные точки зрения, а качество аннотаций должны оценивать несколько человек.
- Расхождения в оценках — это не всегда плохо. Нужно снижать количество расхождений, вызванных ошибками или плохо спроектированным процессом, но прочие расхождения могут дать нам богатую информацию.
- Если причина в плохой формулировке задачи, то нужно улучшить инструкции. Однако более подробная инструкция не устранит присущее людям разнообразие мнений.
- Специалисты проявляют способности не всегда лучше неспециалистов, но между ними будет большой разрыв в понимании того, что важно.
- Эталонные аннотации могут меняться со временем, особенно если они связаны с недавними событиями или новостями.
Позже Rottger et al. (2021) сформулировали эту разницу в две противоположные парадигмы аннотирования данных для субъективных задач NLP.
| Дескриптивная | Прескриптивная | |
|---|---|---|
| Определение | Поддерживать субъективность аннотатора, стремясь смоделировать множество точек зрения. | Ограничивать субъективность аннотатора, стремясь всегда придерживаться одной точки зрения. |
| Плюсы | — Может помочь понять, какие элементы более субъективны; — Стимулирует к разнообразию |
— Более соответствует стандартной схеме NLP. — Проще выполнять контроль качества, измеряя степень расхождения или выполняя агрегацию разметки. |
| Минусы | — Для измерения качества данных или показателей аннотатора нельзя использовать метрики наподобие расхождения; — Нельзя использовать для обучения моделей, оптимизированных под генерацию одного заранее заданного поведения. |
— Разработка высококачественных инструкций по аннотированию — дорогостоящая и сложная задача, инструкции на практике никогда не будут идеальны; — Может быть сложно обучить аннотаторов правильному применению инструкций; — Нельзя передать интерпретируемое разнообразие мнений или согласованно кодировать одно конкретное мнение. |
Дескриптивная парадигма позволяет нам понять множество важных эффектов, а также учесть различные точки зрения. Например, было обнаружено, что самоидентификация аннотатора является статистически существенным фактором в том, что он размечает контент как токсичный (Goyal et al. 2022).
Тематика может быть еще одной существенной причиной расхождения мнений между аннотаторами. Wang et al. (2023) изучили процесс оценки людьми безопасности разговорной ИИ-системы и сравнили результаты между разметкой, созданной профессионалами в сфере Trust & Safety (T&S), и аннотаторами-краудсорсерами. Они собирали подробные метаданные по аннотаторам-краудсорсерам, например, демографическую или поведенческую информацию. Сравнивая разметку специалистов по T&S и аннотаторов-краудсорсеров, они обнаружили, что консенсус сильно варьируется по семантическим темам и уровню серьезности:
- Коэффициент консенсуса сильно варьируется в различных темах; от 0.96 в темах насилия/кровопролития до 0.25 по личным темам.
- Коэффициенты консенсуса выше в «экстремальных» и «доброжелательных» беседах при наличии четырёх вариантов, размечающих беседы как «доброжелательные», «спорные», «умеренные» и «экстремальные».

Рисунок 4. Корреляции между аннотациями специалистов и неспециалистов сильно варьируются.
Zhang et al. (2023) предложили таксономию для анализа первопричин расхождения мнения аннотаторов. Среди перечисленных причин есть необходимость избегать расхождения вследствие стохастических погрешностей или несогласованности на индивидуальном уровне. Если аннотатору несколько раз дают одно и то же задание, но его оценка меняется, то можно говорить об ошибке из-за человеческого фактора. Основанная на этом представлении методика обратного преобразования свертки расхождений (Gordon et al. 2021) позволяет отделять стабильные мнения от ошибок, привязав мнение каждого человека к его собственной первичной разметке. Это приводит к внутренней согласованности в ответах аннотатора.

Рисунок 5. Таксономия причин расхождений аннотаторов
Обратное преобразование свёртки расхождений зависит от графового вероятностного моделирования:
- Вычисляем, насколько часто аннотатор возвращает неосновные метки,
- Для каждой выборки получаем выравненное распределение меток
основных меток на основании
- Создаём выборку
в качестве нового тестового множества.
- Замеряем метрики показателей аннотатора по новому тестовому множеству.
В случае классификации
Имея истинные
Новое тестовое множество, сэмплированное из
Для выявления систематического расхождения между аннотаторами при обучении прогнозированию меток Davani et al. (2021) экспериментировали с моделью множественных аннотаторов. В ней прогнозирование разметки каждого аннотатора обрабатывалось как одна подзадача.
Допустим, задача классификации определена для аннотированного датасета
- Исходная: прямое прогнозирование мажоритарного голосования
без использования полной матрицы аннотаций
.
- Единая: обучение по одной модели на каждого аннотатора по отдельности, чтобы спрогнозировать
; затем результаты агрегируются по мажоритарному голосованию.
- Множественная разметка: обучение прогнозированию
метки для описания меток всех аннотаторов для выборки
с общим слоем MLP и последующей агрегацией результатов.
- Многозадачная: аналогична множественной разметке, но голова прогнозирования каждого аннотатора обучается из отдельного слоя MLP так, что мы выделяем дополнительные вычислительные ресурсы на обучение разнице между аннотаторами.
Эксперимент привёл к созданию датасета GHC (Gab Hate Corpus). Он показал, что многозадачная модель достигает лучшей оценки F1, а также способна естественным образом обеспечивать оценку неопределённости прогнозов, коррелирующую с расхождением аннотаций.

Рисунок 6. Иллюстрация различных архитектур для моделирования разметки множества аннотаторов
Jury Learning (Gordon et al. 2022) имитирует процесс с участием присяжных, моделируя поведение при разметке различных аннотаторов, обусловленное их характеристиками. Мы начинаем обучение модели с датасета с метками и демографическими характеристиками каждого разметчика. Модель должна научиться прогнозировать метки, созданные отдельными аннотаторами, каждый из которых действует как потенциальный присяжный. В момент принятия решения исследователи могут указать состав группы присяжных, чтобы определить стратегию сэмплирования. Окончательное решение принимается агрегированием меток присяжных после нескольких процессов.

Рисунок 7. Иллюстрация того, как работает обучение присяжных
Модель обучения присяжных — это DCN (Deep & Cross network), часто применяемая в случае работы с рекомендациями. Она совместно обучается для изучения эмбеддинга комментариев, эмбеддинга аннотаторов и эмбеддинга групп (характеристик аннотатора). Текстовое содержимое обрабатывается предварительно обученным BERT. Он также подвергается совместной тонкой настройке, но в течение более короткого периода, чтобы избежать переобучения.

Рисунок 8. Архитектура модели DCN для обучения присяжных
Эксперимент проводился с датасетом токсичного контента. Он сравнивает обучение присяжных с исходной моделью (BERT с тонкой настройкой для прогнозирования меток индивидуальных аннотаторов без применения метаданных). Показатели измеряются в MAE (mean absolute error, средней абсолютной погрешности). Обучение присяжных стабильно обгоняет по показателям исходную модель без учёта аннотаторов при полном тестовом множестве, а также для каждого сегмента группы.

Рисунок 9. Результаты эксперимента по сравнению исходной моделью с обучением присяжных
Качество данных ↔ обучение модели
После создания датасета можно использовать различные методики для идентификации ошибочных меток согласно динамике обучения. Мы будем рассматривать только те методики, которые находят и исключают примеры данных с потенциально неверными метками, а не те, которые позволяют обучать модель на шумных данных.
Функции влияния
Функции влияния — это классическая методика из робастной статистики (Hampel, 1974) для измерения влияния примеров обучающих данных. В методике используются описания того, как меняются параметры модели при увеличении веса примера обучающих данных на бесконечно малую величину. Koh и Liang (2017) предложили применять эту концепцию к глубоким нейросетям.
При
где
Удаление примера данных
Влияние повышения веса
При помощи функции влияния мы можем измерить влияние одного примера данных на параметры модели и функцию потерь в замкнутой форме. Это может помочь в аппроксимации обучения при исключении по одному без действительного выполнения повторного обучения. Чтобы выявить неправильно размеченные данные, можно измерить

Рисунок 10. Значения функций влияния, соответствующие результатам обучения при исключении по одному для 10-class MNIST
Учитывая замкнутость формы, функции влияния всё равно сложно масштабировать из-за трудоёмкости вычисления произведения векторов Гессе. Grosse et al. (2023) вместо этого экспериментировали с аппроксимацией EK-FAC (Eigenvalue-corrected Kronecker-Factored Approximate Curvature; George et al., 2018).
Изменения прогнозов во время обучения
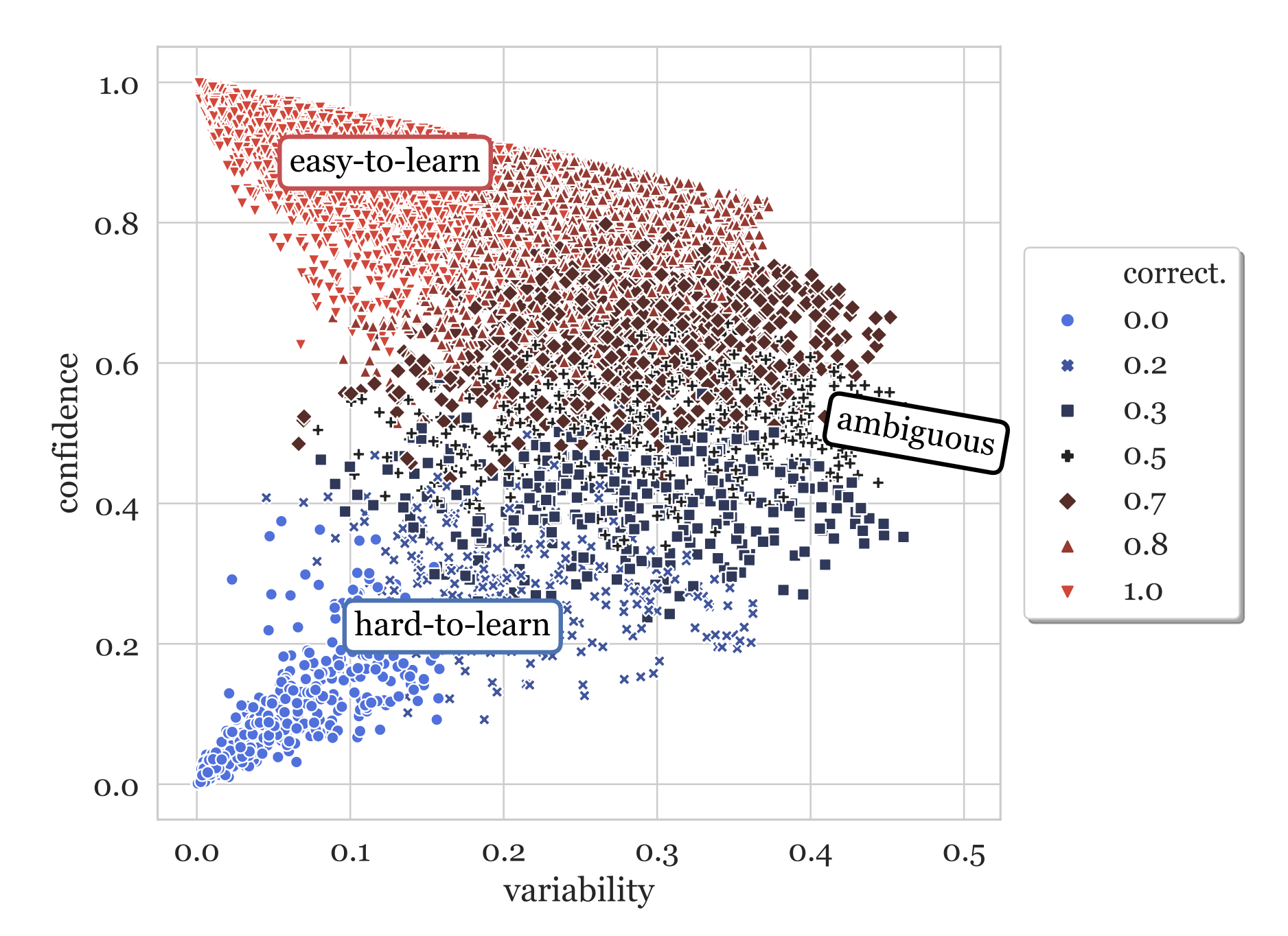
Ещё одна ветвь методик отслеживает изменения в прогнозах модели при обучении. Она выявляет случаи, которым сложно обучиться. Data Maps (Swayamdipta et al., 2020) для анализа качества датасета отслеживает два атрибута динамики поведения модели во время обучения:
- Достоверность: достоверность модели в настоящей метке, определяемая как средняя вероятность модели настоящей метки между эпохами. Также здесь используется грубая метрика «корректность», определяемая как доля таких случаев, когда модель прогнозирует между эпохами правильную метку.
- Дисперсия: колебательность достоверности, определяемая как квадратическое отклонение вероятности модели настоящей метки между эпохами.
Рисунок. 11. Data map для обучающего датасета SNLI, основанная на классификаторе RoBERTa
Сложные для обучения сэмплы (низкая достоверность, низкая дисперсия) получают ошибочные метки с большей вероятностью. Исследователи провели эксперимент с датасетом WinoGrande, где был изменён 1% данных разметки. После повторного обучения изменённые экземпляры перешли в области с более низкой достоверностью и чуть более высокой дисперсией.
Это указывает на то, что сложные для обучения области содержат сэмплы с ошибочными метками. С этим знанием мы можем обучить классификатор на равном количестве изменённых меток и очистить сэмплы при помощи одной только оценки достоверности (непонятно, почему в статье не использовали в качестве признаков и достоверность, и дисперсию). Этот простой классификатор шума можно затем применить к исходному датасету, чтобы выявить потенциально ошибочно размеченные экземпляры.

Рисунок 12. Примеры данных с высокой достоверностью и низкой дисперсией после изменения меток переместились в область с низкой достоверностью и чуть более высокой дисперсией
Однако мы не должны считать все сложные для обучения сэмплы некорректными. На самом деле в статье приводится гипотеза, что неоднозначные (с высокой дисперсией) и сложные для обучения (с низкой достоверностью и дисперсией) сэмплы более информативны для обучения. Эксперименты показали, что они хороши для обобщения OOD за счет более качественные результаты при оценке OOD по сравнению со 100% обучающего датасета.
Чтобы изучить, имеют ли нейросети тенденцию к забыванию ранее изученной информации, Mariya Toneva et al. (2019) провели эксперимент. Ученые отслеживали прогнозы модели для каждого сэмпла в процессе обучения и подсчитали переходы каждого сэмпла от правильной к неправильной классификации и наоборот. Затем сэмплы были разбиты на категории:
- Забываемых (избыточных) сэмплов: если метка класса меняется между эпохами обучения.
- Незабываемых сэмплов: если метка класса не меняется между эпохами обучения. Такие сэмплы после изучения никогда не забываются.
Исследователи обнаружили, что существует большое количество незабываемых примеров. Примеры с шумными метками или изображения с «необычными» признаками (которые сложно классифицировать визуально) оказываются самыми забываемыми примерами. Эксперименты опытным путём подтвердили, что незабываемые примеры можно спокойно удалить, не скомпрометировав при этом точность модели.
В реализации эксперимента событие забывания считается только тогда, когда сэмпл включается в текущую группу обучения. Исследователи вычисляют забывание среди описаний одного примера в последующих минигруппах. Количество событий забывания на сэмпл достаточно стабильно для разных порождающих значений, а забываемые примеры имеют небольшую тенденцию быть впервые изученными позже в процессе обучения. Также оказалось, что события забывания переносимы на протяжении периода обучения и между архитектурами.
Pleiss, et al. (2020) разработали методику AUM (Area under the Margin) для выявления ошибочных меток на основании этого допущения: допустим, изображение с птицей (BIRD) ошибочно размечено как «собака» (DOG). Обновление градиента будет стимулировать обобщение от других изображений BIRD к этому изображению BIRD, в то время как метка DOG создаёт некорректный сигнал, стимулируя обновление выполняться в другом направлении. Поэтому в сигналах обновления градиента возникает напряжение между обобщением и (ошибочным) прогнозом.
Допустим, у нас есть датасет классификации
Отрицательный допуск обозначает ошибочный прогноз, а большой положительный допуск предполагает высокую достоверность правильного прогноза. Гипотеза заключается в том, что ошибочно размеченные сэмплы будут иметь меньший допуск, чем корректные сэмплы из-за напряжения между обобщением при помощи стохастического градиентного спуска из-за других сэмплов.
Чтобы определить пороговое значение, исследователи подставили ложные данные, названные «пороговыми сэмплами»:
- Создаём подмножество пороговых сэмплов
. Если существует
обучающих сэмплов для
классов, мы случайным образом выбираем
сэмплов и меняем все их метки на фальшивый новый класс
.
- Объединяем пороговые сэмплы в исходный датасет:
;
- Обучаем модель на
и замеряем AUM всех данных;
- Вычисляем пороговую
как 99-й перцентиль AUM пороговых сэмплов;
- Выявляем ошибочно размеченные данные, используя как пороговое значение
:

Рисунок 13. Как AUM пороговых сэмплов помогает отделить ошибочно размеченные сэмплы

Рисунок 14. Погрешность тестирования на CIFAR 10/100 со случайно ошибочно размеченными сэмплами; сравнение разных методик фильтрации данных или обучения на шумных данных
Шумная кросс-валидация
Методика NCV (Noisy Cross-Validation) (Chen et al., 2019) случайным образом делит датасет пополам, а затем идентифицирует сэмплы данных как «чистые», если их метки соответствуют метке, спрогнозированной моделью, обученной только на другой половине датасета. Ожидается, что чистые сэмплы более надёжны. INCV (Iterative Noisy Cross-Validation) итеративно выполняет NCV, добавляя больше чистых сэмплов к надёжному множеству кандидатов

Рисунок 15. Алгоритм INCV (итеративной шумной кросс-валидации)
Источники
[1] Francis Galton “Vox populi” Nature 75, 450-451 (1907).
[2] Sambasivan et al. “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI" CHI 2021
[3] Chris Callison-Burch. “Fast, Cheap, and Creative: Evaluating Translation Quality Using Amazon’s Mechanical Turk” EMNLP 2009
[4] Rottger et al. “Two Contrasting Data Annotation Paradigms for Subjective NLP Tasks” NAACL 2022.
[5] Aroyo & Welty “Truth Is a Lie: Crowd Truth and the Seven Myths of Human Annotation” AI Magazine 36.1: 15-24 (2015).
[6] Hovy et al. “Learning Whom to Trust with MACE” NAACL-HLT 2013.
[7] Wang et al. “All that Agrees Is Not Gold: Evaluating Ground Truth Labels and Dialogue Content for Safety” 2023.
[8] Zhang et al. “A Taxonomy of Rater Disagreements: Surveying Challenges & Opportunities from the Perspective of Annotating Online Toxicity” arXiv preprint arXiv:2311.04345 (2023).
[9] Davani et al. “Dealing with disagreements: Looking beyond the majority vote in subjective annotations” ACL 2022.
[10] Gordon et al. “Jury Learning: Integrating Dissenting Voices into Machine Learning Models” CHI 2022.
[11] Gordon et al. “The Disagreement Deconvolution: Bringing Machine Learning Performance Metrics In Line With Reality” CHI 2021
[12] Daniel et al. 2018 “Quality Control in Crowdsourcing: A Survey of Quality Attributes, Assessment Techniques, and Assurance Actions” ACM Computing Surveys (CSUR), 51(1), 1-40 (2018).
[13] Koh & Liang. “Understanding Black-box Predictions via Influence Functions” ICML 2017.
[14] Grosse et al. “Studying Large Language Model Generalization with Influence Functions” arXiv preprint arXiv:2308.03296 (2023).
[15] Swayamdipta et al. “Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics” EMNLP 2020.
[16] Toneva, et al. “An Empirical Study of Example Forgetting during Deep Neural Network Learning” ICLR 2019.
[17] Pleiss, et al. “Identifying Mislabeled Data using the Area Under the Margin Ranking” NeuriPS 2020.
[18] Chen et al. “Understanding and utilizing deep neural networks trained with noisy labels” ICML 2019.
IamSVP
Оч. сложная, но оч крутая статья!
Работе с данными действительно должно быть посвящено больше времени, чем с моделями, хотя именно на втором часто сосредотачиваются во время разработки.
Тут рассматриваются работа над исправлением ошибок во время разметки, но как быть например в случае ambiguous данных? Например в разметке есть классы "каска" и "голова" и много картинок, где они встречаются вместе. Вот как объяснить как и на что реагировать?! (Примеров может быть множество, ["окно", "человек"] ["перила", "человек"] ["рука", "телефон"], ...) Есть ли какие методы хотя бы фильтрации таких данных, чтобы понимать, что вот такие картинки лучше не добавлять в датасет, так как они "запутывают" модель
Rubcov Автор
Интересно, что бы ответил на это сам Lilian Weng, но если опираться на опыт нашей команды, то все зависит от постановки бизнес-задачи. Если важнее понимать, что человек без каски, так как это нарушает ТБ, то максимизируем предсказание этого класса. Как я понял из вопроса, мы говорим о задаче детекции. Нам ничего не мешает предсказывать и каску, и голову. Каждый из классов имеет достаточно признаков, чтобы модель не путалась.
В идеале нужно серьезно подойти к аннотации данных. Чтобы нейронка не путалась, нужно однозначно определять объект. Один класс — один объект.
Также объем данных должен быть как можно больше и разнообразнее. Так нейронка сможет выучить те признаки, которые помогут ей различать очень близкие классы.
Что делать в случае распознавания очень близких к друг другу объектов. Если мы говорим о двух видов касок, которые различаются немного и то только спереди, то ничего сделать нельзя: нейронка будет время от времени путать. Тут можно пытаться сделать распознавание по другим критериям: например, люди в определенной спецодежде носят тот или иной вид касок. Эту информацию мы тоже можем учитывать. Еще можно агрегировать данные по времени. Например, у нас есть детекция видео: в этом случае мы можем собирать предсказания за 10 кадров и определять класс голосованием или каким-нибудь более умным способом.
Еще есть мемы где нейронка путает собаку породы корги и буханку хлеба. В этом случаи они действительно похожи. В этом случае можно добавить больше изображений корги или добавить в негативные семплы фото буханок хлеба)
Есть ли фильтрация данных, чтобы понимать, что такие картинки лучше не добавлять?
Можно использовать методы deep metric learning. Там как раз пытаются решать задачу разделения векторов очень похожих классов.
По ссылке ниже можно ознакомиться:
https://www.youtube.com/watch?v=e2iEriMkg8k&t=398s
для данных примеров:
["окно", "человек"] ["перила", "человек"] ["рука", "телефон"]
Можно учить сегментацию, а не детекцию, но и детекция должна справиться отлично.
Универсальный ответ: больше чистых данных, в идеале с продакшена, и использовать их в конкретной узкой задаче.
А вот что говорит мой коллега, у которого нет аккаунта:
Вообще, можно просто NMS настроить так, чтобы он при пересечении таких классов не пытался фильтровать один из них, но применял алгоритм раздельно. Это если с точки зрения исключительно постобработки подойти.
А так, мне кажется, это просто вопрос того, как разметка выглядит. Если допустить, что для класса голова и для класса каска абсолютно одинаковые bbox'ы, то с точки зрения модели эти классы в целом идентичны, конечно, как ни называй. Но обычно все же те же разные ракурсы и прочее позволяют отделить именно bbox'ы головы/руки от каски/телефона. Даже если один бокс частично пересекается или находится в другом, то они все же не идентичны. Никто же не видит проблемы, когда обучают модель, чтобы, например, детектить машину и людей в ней отдельно. Не говоря уже о том, что все же не всякая голова в датасете обычно в каске, и не во всякой руке держат телефон etc.
Ну и про сегментацию поинт хороший, да