
Сервис databoom – это облачный backend для Web и мобильных приложений. Он сокращает время и снижает стоимость прототипирования и разработки приложений за счет упрощения доступа к данным. На следующих видео показано, как легко с помощью databoom строится прототип Web приложения.
Microsoft Azure позволяет удивительно легко создавать надежные масштабируемые приложения. Если еще пару лет назад Azure означал Windows, то сегодня Microsoft Azure является прекрасной средой и для Linux разработчиков.
Серверная часть databoom работает под управлением Linux, использует Node.js и native модули, написанные на C++. Простота развертывания виртуальных машин, балансировщиков и других сервисов под Azure позволила нам достаточно легко развернуть облачное решение.
Начав с прототипов, многие наши клиенты продолжают работать с нами, создавая все более сложные приложения, для которых критически важными являются вопросы надежности, защищенности и масштабируемости. Поэтому мы выбрали Microsoft Azure.
Наиболее важными для нас достоинствами Azure явились следующие:
Для разворачивания решения databoom на Azure мы выбрали простую схему (рисунок 1).
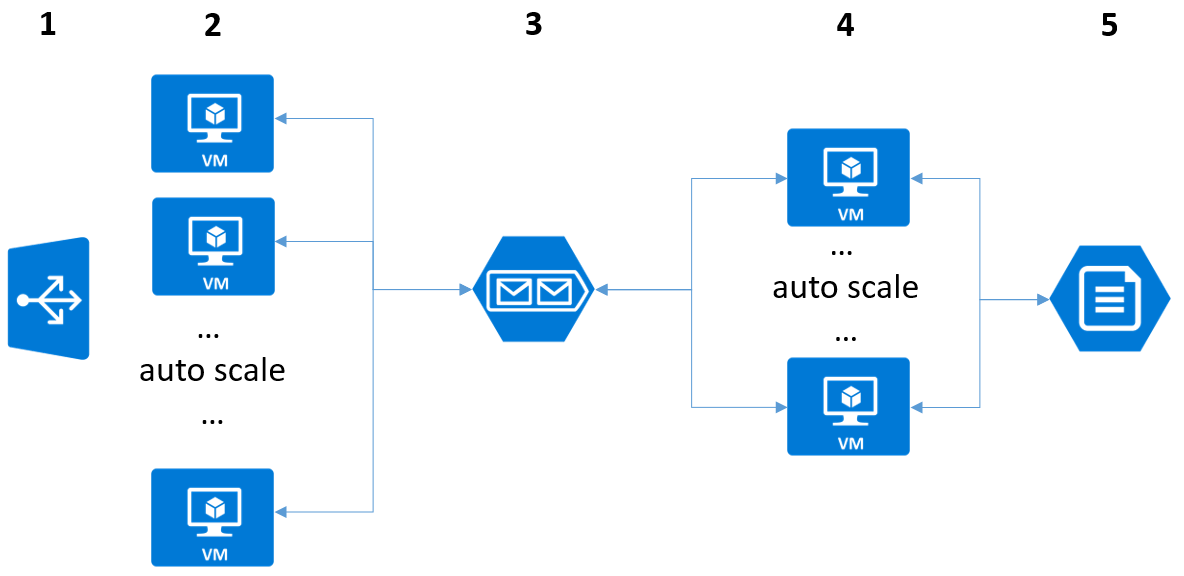
Рис. 1. – Схема архитектуры облачной инфраструктуры Databoom
Здесь цифрами обозначены различные уровни системы:
Балансировщик нагрузки распределяет нагрузку между виртуальными машинами и в случае увеличения нагрузки запускает новые виртуальные машины, обеспечивая автоматическое масштабирование.
Для обработки HTTP запросов используются одноядерные виртуальные машины с Node.js приложением. Node.js по умолчанию использует одно ядро. Можно было бы использовать многоядерные компьютеры с несколькими экземплярами Node.js на каждом, но в этом случае нам бы пришлось подключить модуль Cluster на каждой машине. При этом функции модуля Cluster дублируются функциями балансировщика, что означает еще один лишний слой в процессе прохождения запроса. С другой стороны, скажем, четыре одноядерные машины работают не хуже, чем одна четырехъядерная (на наших тестах получилось, что по количеству запросов в секунду, даже лучше).
Для взаимодействия множества Node.js приложений с базой данных была реализована специализированная очередь для больших потоков сообщений. Каждый компьютер имеет несколько постоянных TCP соединений и асинхронно шлет и принимает потоки сообщений. Каждое TCP соединение на каждом из компьютеров способно передавать сотни тысяч запросов в секунду. Это позволяет масштабировать решение до любого требуемого количества запросов в секунду.
Для управления базами данных используются многоядерные компьютеры и специализированный балансировщик нагрузки. В случае увеличения нагрузки поднимаются дополнительные компьютеры. В случае сбоя одного из компьютеров, база данных тут же поднимается на любом наименее нагруженном или вновь поднятом компьютере.
Балансировка нагрузки, возможность поднятия компьютеров на лету, многократное дублирование данных в хранилище, возможность обнаружения сбоев и перенос нагрузки на другие компьютеры и многие другие возможности MS Azure позволили нам создать надежное масштабируемое решение.

Андрей Портнов, Виктор Чернов, Владислав Головков
Выпускники ведущих московских технических ВУЗ-ов (МФТИ и МИФИ).
Проблемами обработки данных занимаемся с начала 90х годов XX века, когда все трое были сотрудниками вычислительного центра института атомной энергии им. И.В.Курчатова (филиал в г. Троицке). Разработали свою технологию обработки данных NitrosBase, получившую несколько призов всероссийских и международных выставок и форумов. На основе этой технологии были разработаны СУБД класса InMemory "NitrosBase InMemory DB" и графовая СУБД "NitrosBase RDF Storage". На основе NitrosBase RDF Storage мы построили сервис databoom — BaaS решение, значительно облегчающее разработку Web и мобильных приложений.
Microsoft Azure позволяет удивительно легко создавать надежные масштабируемые приложения. Если еще пару лет назад Azure означал Windows, то сегодня Microsoft Azure является прекрасной средой и для Linux разработчиков.
Серверная часть databoom работает под управлением Linux, использует Node.js и native модули, написанные на C++. Простота развертывания виртуальных машин, балансировщиков и других сервисов под Azure позволила нам достаточно легко развернуть облачное решение.
Начав с прототипов, многие наши клиенты продолжают работать с нами, создавая все более сложные приложения, для которых критически важными являются вопросы надежности, защищенности и масштабируемости. Поэтому мы выбрали Microsoft Azure.
Наиболее важными для нас достоинствами Azure явились следующие:
- Возможность автоматического увеличения количества виртуальных машин при росте нагрузки, и, соответственно, их уменьшения при падении нагрузки. При этом плата берется только за реально работающие машины.
- Возможность быстрого автоматического переноса нагрузки на другие машины в случае выхода из строя одной из машин.
- Надежность хранения данных. Каждая запись на виртуальный диск в Azure копируется в 3 разных места в разных стойках в разных концах датацентра.
Для разворачивания решения databoom на Azure мы выбрали простую схему (рисунок 1).
Рис. 1. – Схема архитектуры облачной инфраструктуры Databoom
Здесь цифрами обозначены различные уровни системы:
- Балансировщик нагрузки с возможностью масштабирования;
- Одноядерные виртуальные машины с Node.js приложением, которое принимает HTTP запросы, ведет обработку буферов приема ответа, ведет простые логи, ведет частичную обработку JSON данных, ведет разбор OData запросов, и т.д;
- Специализированная очередь для больших потоков сообщений.
- Машины, управляющие базами данных.
- Надежное дисковое хранилище.
Балансировщик нагрузки распределяет нагрузку между виртуальными машинами и в случае увеличения нагрузки запускает новые виртуальные машины, обеспечивая автоматическое масштабирование.
Для обработки HTTP запросов используются одноядерные виртуальные машины с Node.js приложением. Node.js по умолчанию использует одно ядро. Можно было бы использовать многоядерные компьютеры с несколькими экземплярами Node.js на каждом, но в этом случае нам бы пришлось подключить модуль Cluster на каждой машине. При этом функции модуля Cluster дублируются функциями балансировщика, что означает еще один лишний слой в процессе прохождения запроса. С другой стороны, скажем, четыре одноядерные машины работают не хуже, чем одна четырехъядерная (на наших тестах получилось, что по количеству запросов в секунду, даже лучше).
Для взаимодействия множества Node.js приложений с базой данных была реализована специализированная очередь для больших потоков сообщений. Каждый компьютер имеет несколько постоянных TCP соединений и асинхронно шлет и принимает потоки сообщений. Каждое TCP соединение на каждом из компьютеров способно передавать сотни тысяч запросов в секунду. Это позволяет масштабировать решение до любого требуемого количества запросов в секунду.
Для управления базами данных используются многоядерные компьютеры и специализированный балансировщик нагрузки. В случае увеличения нагрузки поднимаются дополнительные компьютеры. В случае сбоя одного из компьютеров, база данных тут же поднимается на любом наименее нагруженном или вновь поднятом компьютере.
Балансировка нагрузки, возможность поднятия компьютеров на лету, многократное дублирование данных в хранилище, возможность обнаружения сбоев и перенос нагрузки на другие компьютеры и многие другие возможности MS Azure позволили нам создать надежное масштабируемое решение.
Об авторах
Андрей Портнов, Виктор Чернов, Владислав Головков
Выпускники ведущих московских технических ВУЗ-ов (МФТИ и МИФИ).
Проблемами обработки данных занимаемся с начала 90х годов XX века, когда все трое были сотрудниками вычислительного центра института атомной энергии им. И.В.Курчатова (филиал в г. Троицке). Разработали свою технологию обработки данных NitrosBase, получившую несколько призов всероссийских и международных выставок и форумов. На основе этой технологии были разработаны СУБД класса InMemory "NitrosBase InMemory DB" и графовая СУБД "NitrosBase RDF Storage". На основе NitrosBase RDF Storage мы построили сервис databoom — BaaS решение, значительно облегчающее разработку Web и мобильных приложений.