
Мне нравится открывать для себя новые способы мышления. Особенно нравится наблюдать, как смутная идея трансформируется в конкретную концепцию. Ярким примером этого является теория информации.
Теория информации дает нам точный язык для описания многих вещей. Какова степень неопределённости? Как ответить на вопрос B, зная ответ на вопрос A? Чем похож один набор убеждений на другой?
Когда я был ребенком, у меня имелись некоторые нестандартные мысли по этому поводу, но именно теория информации сформировала их в конкретные, мощные идеи, которые имеют множество сфер применения: от сжатия данных до квантовой физики и машинного обучения.
Теория информации выглядит пугающей, но я думаю, что это не так. На самом деле, многие основные идеи можно наглядно объяснить.
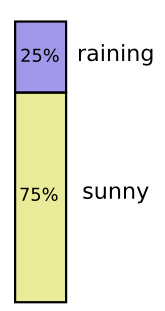
Большую часть времени я ношу футболку, но иногда надеваю пальто. Предположим, что я ношу пальто 38% времени.
Изображаем это на диаграмме:
Теперь я хочу объединить обе диаграммы. Это легко, если они никак не взаимодействуют друг с другом, то есть являются независимыми. Например, надену я сегодня футболку или пальто, на самом деле, не зависит от погоды на следующей неделе.
Отметим первую переменную по оси X, а вторую – по оси Y:

Обратите внимание на прямые линии: вертикальную и горизонтальную. Так выглядит независимость событий. Вероятность того, что я надел пальто, не влияет на факт выпадения осадков на этой неделе. Другими словами, вероятность того, что я надену пальто, и на следующей неделе пройдет дождь, есть произведение вероятностей того, что я надену пальто, и что будет дождь. Эти вероятности не влияют друг на друга.
При взаимодействии переменных, для одних пар вероятность увеличивается, а для других уменьшается. Вероятность того, что я надену пальто, когда идет дождь, гораздо выше, потому что переменные коррелируют. Вероятность того, что я надену пальто в дождливый день выше, чем вероятность того, что я надену пальто в солнечный день.
Визуально это выглядит так: одни области увеличиваются за счет дополнительной вероятности, а другие уменьшаются, потому что эта пара событий маловероятна.
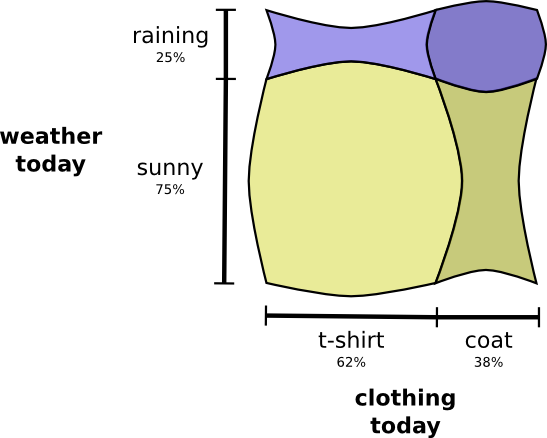
Впечатляет, правда? Но такая схема не очень удобна для понимания.
Давайте сосредоточимся на одной переменной – погоде. Мы знаем вероятность того, каким будет день: солнечным или дождливым. В обоих случаях можно рассмотреть условные вероятности. Какова вероятность того, что я надену футболку, если на улице солнечно? Какова вероятность того, что надену пальто, если идет дождь?

Вероятность того, что пойдет дождь, составляет 25%; что я надену пальто в дождливую погоду – 75%. Таким образом, вероятность того, что идет дождь, и я в пальто – это 25%, умноженные на 75%, что составляет примерно 19%. Вероятность того, что идет дождь, и я в пальто, равна вероятности того, что идет дождь, умноженной на вероятность того, что я надену пальто в дождливую погоду.
Это один из возможных случаев фундаментального тождества теории вероятностей.
Мы раскладываем функцию на произведение двух множителей. Сначала рассматриваем вероятность того, что одна переменная (погода) примет определенное значение. Затем рассматриваем вероятность того, что другая переменная (одежда) примет определенное значение, в зависимости от первой переменной.
Для начала произвольно выбираем переменную. Начнем с одежды, а затем рассмотрим погоду, обусловленную одеждой.
Это звучит немного странно, поскольку мы понимаем, что, с точки зрения причинно-следственной связи, именно погода влияет на то, что я ношу, а не наоборот… но сейчас это не принципиально.
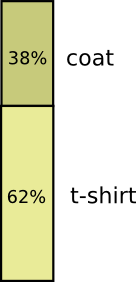
Рассмотрим пример. Если мы рассматриваем случайный день, то вероятность того, что я надену пальто, равняется 38%. Какова вероятность того, что пойдет дождь, если я надел пальто?
Скорее всего, я надену пальто в дождь, чем в солнечную погоду, но дождь – редкое явление в Калифорнии (поэтому предположим, что вероятность выпадения осадков равна 50%). Итак, вероятность того, что идет дождь, и я в пальто, равна произведению вероятностей того, что я надену пальто (38%), и что будет дождь, если я в пальто (50%). Это приблизительно 19%.
Это второй способ визуализировать то же распределение вероятностей.
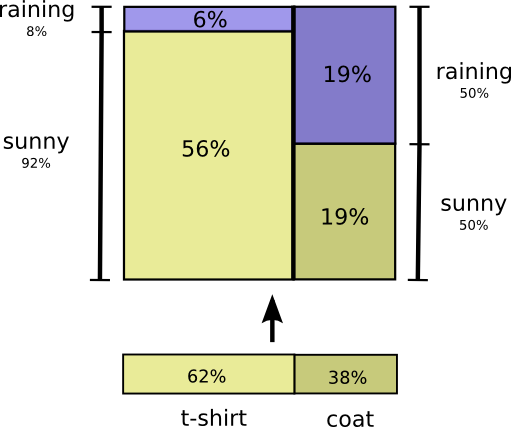
Обратите внимание, что обозначения имеют несколько иной смысл, чем на предыдущей схеме: теперь футболка и пальто – это безусловные вероятности (вероятность носить определенную одежду без учета погодных условий). Также мы видим, что появились два обозначения вероятностей солнечной и дождливой погоды, в зависимости от того, надел я футболку или пальто.
Возможно, вы слышали о теореме Байеса. Можно использовать её для перехода от одного из этих способов отображения распределения вероятностей к другому.
Отступление: парадокс Симпсона
Полезны ли эти приемы для визуализации распределения вероятностей? Я думаю, да. Через некоторое время мы применим их в теории информации, а пока я бы хотел немного отклониться от темы и исследовать парадокс Симпсона. Парадокс Симпсона – чрезвычайно сложное статистическое явление, которое сложно понять на интуитивном уровне.
Майкл Нильсен (Michael Nielsen) написал прекрасную статью «Reinventing Explanation» («Переосмысление объяснений»), в которой рассмотрел различные способы объяснения этого парадокса. Я попытаюсь проанализировать статью, используя приемы, проработанные нами в предыдущем разделе.
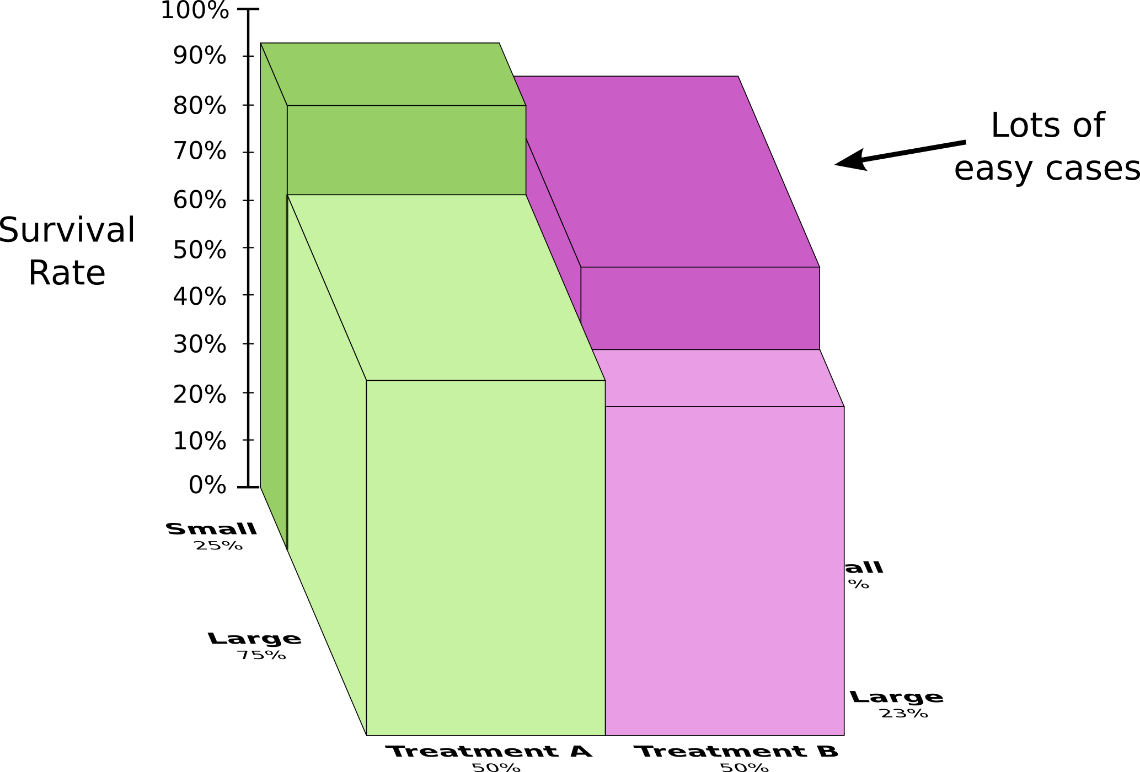
Тестируются два способа лечения камней в почках. Половине пациентов назначено лечение А, а другой половине назначено лечение В. У пациентов, которым было назначено лечение B, шансы выжить были выше, чем у тех, кому назначили лечение А.

Тем не менее, пациенты с маленькими камнями в почках имеют больше шансов выжить, если им назначить лечение А. Пациенты с большими камнями в почках имеют больше шансов выжить, если им назначить… лечение А! Как такое возможно?
Суть проблемы в том, что исследование не было должным образом рандомизировано. Скорее всего, пациенты, получившие лечение А, имели большие камни в почках, в то время как у пациентов, получавших лечение B, были небольшие камни в почках.
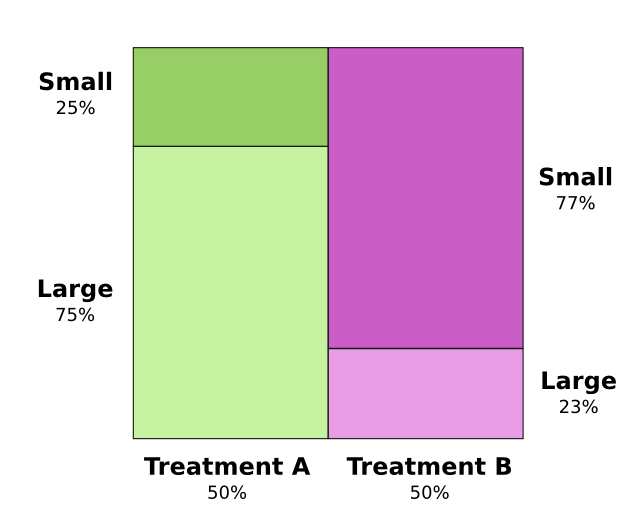
Как выяснилось, у пациентов с небольшими камнями в почках намного больше шансов выжить.
Чтобы лучше это понять, давайте объединим две предыдущие диаграммы. В результате мы получаем трехмерную схему вероятности выживания, которая разбита на области по размеру камней в почках.
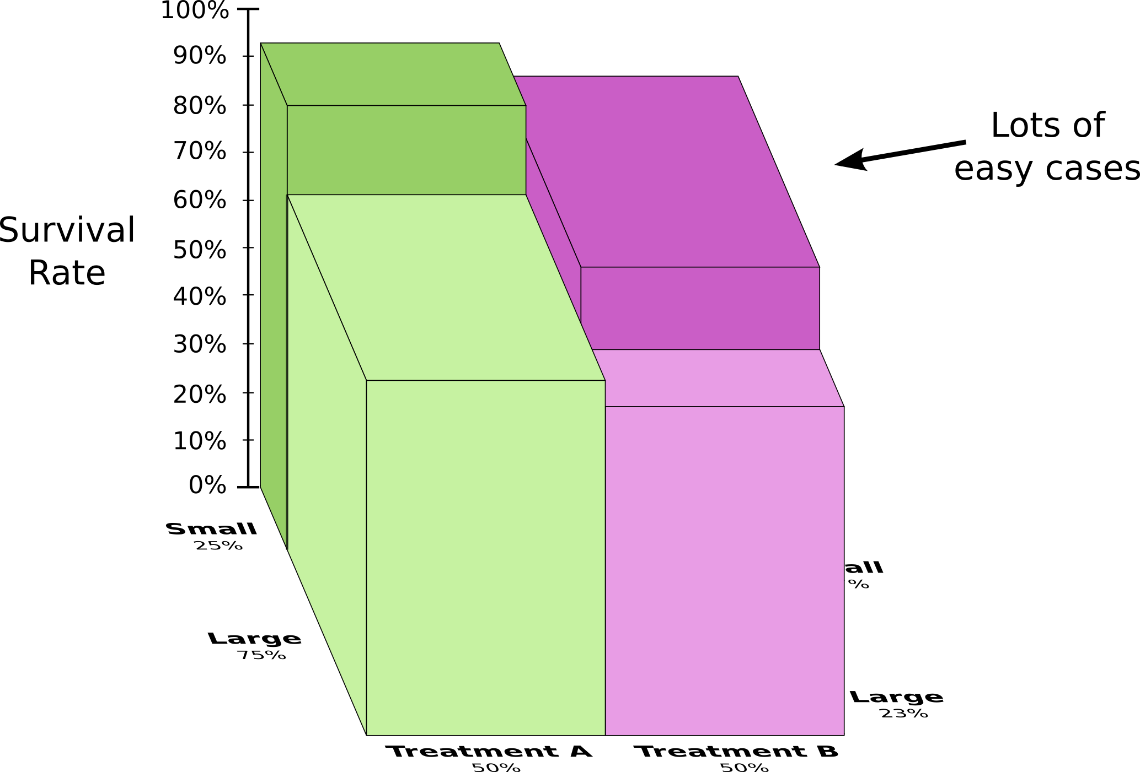
Теперь видно, что лечение А работает лучше, чем лечение B, в случаях как с большими камнями в почках, так и с маленькими. Лечение B казалось лучше только потому, что его назначили больным, у которых вероятность выжить была выше.
Коды
Теперь, когда у нас есть способы визуализации вероятности, мы можем погрузиться в теорию информации.
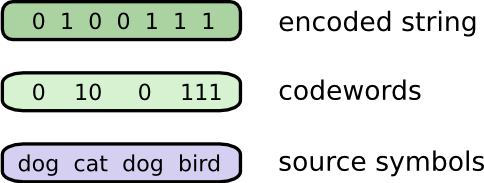
Я расскажу вам о моем воображаемом друге Бобе. Боб очень любит животных. Он постоянно говорит о животных. На самом деле, он говорит только четыре слова: собака, кошка, рыба и птица.
Несмотря на то, что Боб является плодом моего воображения, пару недель назад он переехал в Австралию. Кроме того, он решил, что хочет со мной общаться только с помощью бинарных кодов. Все (воображаемые) сообщения от Боба выглядят следующим образом:

Боб и я должны создать код для общения и способ преобразовывать слова в последовательность битов.

Чтобы отправить сообщение, Боб заменяет каждый символ (слово) соответствующей кодовой комбинацией, и затем объединяет их вместе, чтобы сформировать кодированную строку.
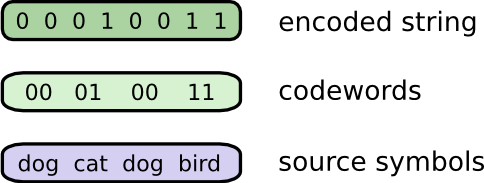
Неравномерный код
К сожалению, услуги связи в воображаемой Австралии очень дорогие. Я должен платить 5$ за каждый бит сообщения от Боба. Я упоминал, что он любит поболтать? Чтобы я не разорился, мы решили найти способ уменьшить среднюю длину сообщения.
Оказывается, Боб говорит все слова с разной частотой. Боб очень любит собак. Он говорит о собаках все время. Иногда он говорит о других животных (особенно о кошке, за которой его собака любит гоняться), но в основном он говорит о собаках.
Вот график частоты использования слов:
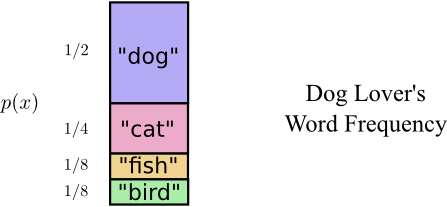
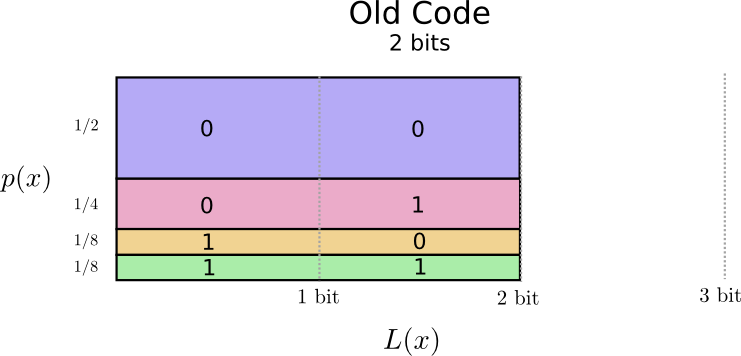
Выглядит многообещающе. Кодовые слова в нашем старом коде занимают 2 бита каждое, независимо от того, как часто они используются.
Существует отличный способ визуализировать это. На следующей диаграмме мы отложим по вертикальной оси p(x) – вероятности использования каждого слова, а по горизонтальной оси L(х) – длины соответствующей кодовой комбинации. Обратите внимание, что диаграмма занимает область, равную средней длине посылаемого нами кодового слова, то есть 2 бита.
Возможно, мы смогли бы создать код переменной длины, где кодовые комбинации для часто используемых слов были бы короткими. Проблема в том, что когда мы делаем одни слова короче, другие становятся длиннее. В идеале, нам нужно свести к минимуму длину всех кодовых слов сообщения (хотя бы часто используемых).
Таким образом, часто используемые слова (например, «собака») имеют короткие кодовые комбинации, а слова, которые употребляются реже – длинные кодовые комбинации.

Изобразим полученные коды на схеме. Обратите внимание, что часто используемое кодовое слово стало короче, в то время как другие стали длиннее. На графике размер минимальной области уменьшился до 1 бита, и теперь средняя длина кодового слова равна 1,75 бит.
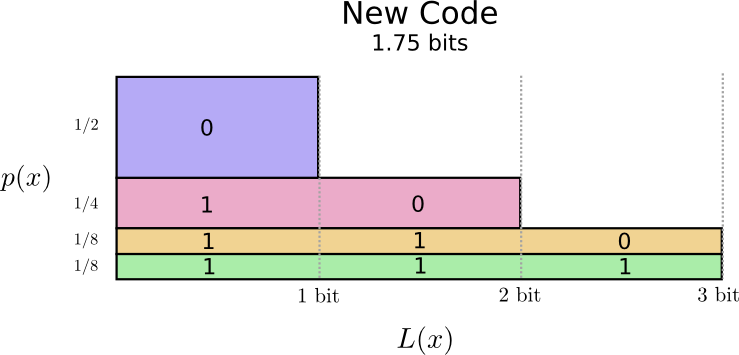
Вы можете задаться вопросом: почему бы не использовать единицу как кодовое слово? К сожалению, это привело бы к неопределенности при декодировании. Мы поговорим об этом в ближайшее время.
Этот код является самым лучшим, поскольку при заданных вероятностях невозможно получить среднюю длину кода меньше 1,75 бит.
Это фундаментальное ограничение. Не имеет значения, какое слово было отправлено, и какой код был выбран – средняя длина сообщения всегда будет равна 1,75 бит.
Независимо от того, насколько хорошо продуман наш код, невозможно сделать среднюю длину сообщений короче. Это предел энтропии распределения, мы обсудим этот вопрос подробнее в ближайшее время.

Чтобы понять суть этого предела, необходимо разобраться в оптимальном соотношении коротких и длинных слов. Когда мы это поймем, то сможем определить наилучший код.
Пространство кодовых слов
Существуют два кода длиной 1 бит: 0 и 1, и четыре кода длиной 2 бита: 00, 01, 10 и 11. Каждый новый бит удваивает количество возможных кодов.
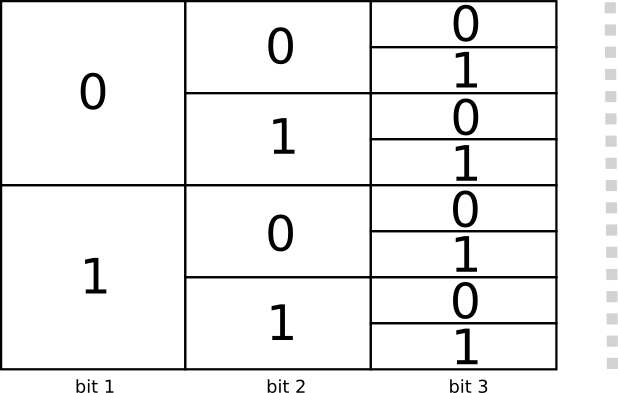
Нас интересует код переменной длины, в котором одни кодовые слова длиннее других. В самом простом случае у нас будет восемь кодовых слов длиной 3 бита каждое. Также можно составить более сложные комбинации кодовых слов из двух слов длиной 2 бита и четырех слов длиной 3 бита. Как определить, сколько кодовых слов разной длины мы должны взять?
Напомню, что Боб переводит свои сообщения в кодированные строки, последовательно заменяя каждое слово кодовым словом.
При создании кода переменной длины нужно быть предельно внимательным. Как разбить закодированную строку обратно на кодовые слова? Когда все слова имеют одинаковую длину, можно просто делить строку через каждую пару шагов, но если длина кодовых слов отличается, мы должны обратить внимание на её содержание.
Мы хотим, чтобы наш код был декодируемым, и притом только одним способом. Нам не нужна неопределенность при декодировании строки. Было бы проще, если бы мы имели специальный символ «конец кодового слова». (Но ужасно неэффективно! Если у нас есть дополнительный символ в коде, который стоит в конце кодовых слов, то это чудовищная трата ресурсов).
Но мы используем только 0 и 1. Мы должны иметь возможность сказать, где заканчивается каждое кодовое слово.
Существует вероятность создать код, который не является однозначно декодируемым. Допустим, что 0 и 01 – это два кодовых слова. Тогда было бы непонятно, какое первое слово закодировано в строке 0100111. Существует правило, которое гласит, что одно кодовое слово не должно быть расширенной версией другого кодового слова. Еще одно правило: кодовое слово не должно быть префиксом другого кодового слова. Это называется свойством префикса, а код, который подчиняется этому свойству, называется префиксным кодом.
Необходимо понимать, что из-за одного слова приходится жертвовать некоторыми другими комбинациями из пространства кодовых слов. Если мы возьмем кодовое слово 01, то потеряем возможность использовать любые кодовые слова с этим префиксом. Мы не можем больше использовать комбинации 010 или 011010110 из-за неопределенности – они потеряны для нас.

Мы теряем четверть всех возможных кодовых слов, так как эта четверть начинается с 01. Это цена, которую мы платим, чтобы получить одно кодовое слово длиной в 2 бита. В свою очередь, это означает, что все остальные кодовые слова должны быть немного длиннее.
Всегда стоит выбор между длиной и разнообразием кодовых слов. Выбирая короткое кодовое слово, мы теряем большое количество других, потому нам приходится кодировать оставшиеся слова более длинными кодами. Мы должны найти оптимальное соотношение длины и разнообразия слов.
Оптимальное кодирование
Чтобы получить короткое кодовое слово, нам нужно заплатить, однако наши средства ограничены. Мы платим за одно кодовое слово долей других возможных кодовых слов.
Стоимость покупки кодового слова длиной 0 равняется 1 (все возможные кодовые слова), то есть, если вы хотите иметь кодовое слово длиной 0, то у вас не будет других кодовых слов. Стоимость кодового слова длиной 1 (например, 0) равняется 1/2, потому что половина возможных кодовых слов начинается с 0. Стоимость кодового слова длиной 2 (например, 01) равняется 1/4, потому что четверть всех возможных кодовых слов начинается с 01. В общем и целом, стоимость кодовых слов экспоненциально убывает с увеличением длины кодового слова.
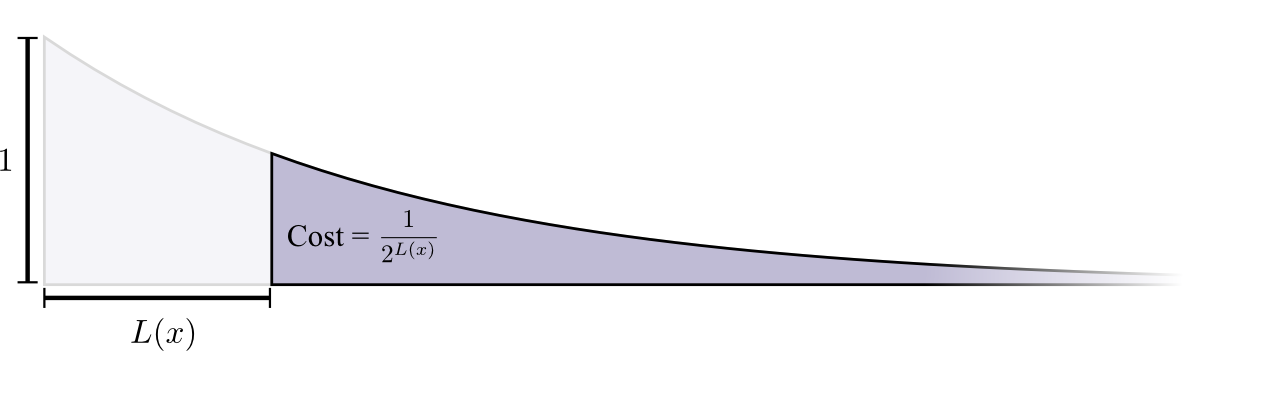
Отметим, что если стоимость снижается по экспоненте (с основанием e), то она является как высотой, так и площадью [фигуры на графике].
(Здесь я немного схитрил. Я использовал экспоненту с основанием 2 (но это неправильно, нужно перейти к экспоненте по основанию e). Это просто экономит нам время при расчете log(2) в нашем доказательстве и делает его визуально более понятным).
Нам нужны короткие кодовые слова, потому что мы хотим уменьшить среднюю длину сообщений. Каждое кодовое слово увеличивает среднюю длину сообщения, поскольку мы должны умножить его вероятность на длину кодового слова.
Например, если мы отправляем кодовое слово длиной 4 бита в 50% случаев, то средняя длина сообщения вырастет на 2 бита. Это можно представить в виде прямоугольника.

Эти две величины связаны длиной кодового слова. Длину кодового слова определяет количество пожертвованных слов. Увеличение средней длины сообщения зависит от длины добавленного кодового слова.
Вместе это выглядит так:
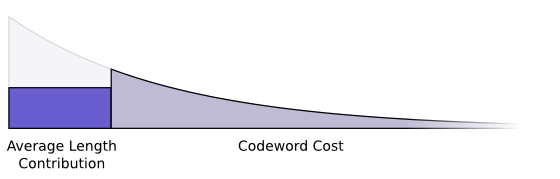
Короткие кодовые слова уменьшают среднюю длину сообщения, но дороги. Длинные кодовые слова увеличивают среднюю длину сообщения, но обходятся дешевле.

Как же лучше использовать наш ограниченный бюджет? Сколько мы должны тратить на кодовые слова для каждого события?
Кто-то больше инвестирует в инструменты, которые регулярно использует, мы же будем инвестировать в часто используемые кодовые слова.
Существует логичный способ сделать это: распределить наш бюджет согласно частоте событий. Таким образом, если событие происходит в 50% случаев, мы тратим 50% нашего бюджета на приобретение короткого кодового слова для него. Если событие происходит только в 1% случаев, мы потратим 1% нашего бюджета, потому что это в этом случае неважно, какой длины будет слово.
Это вполне логичный способ, но вот оптимальный ли? Да, и я докажу это.
Следующее доказательство наглядно и должно быть доступно, но является самой трудной для понимания частью статьи. Вы как читатели можете принять его на веру и перейти к следующему разделу.
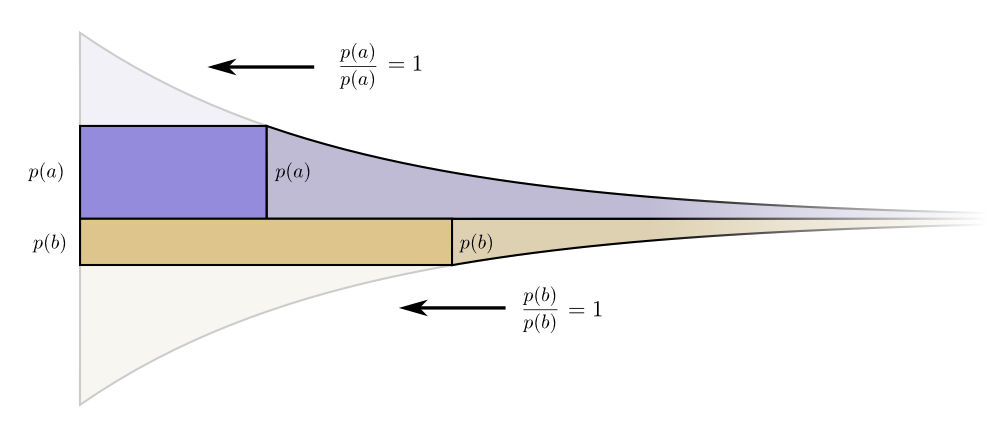
Изобразим конкретный пример, где нам нужно понять, какое из двух вероятностных событий произошло. Событие a происходит в p(a) случаев, событие b происходит в p(b) случаев. Мы распределяем наш бюджет естественным способом, описанным выше, затрачивая p(a) нашего бюджета на получение короткого кодового слова a, и p(b) на получение короткого кодового слова b.
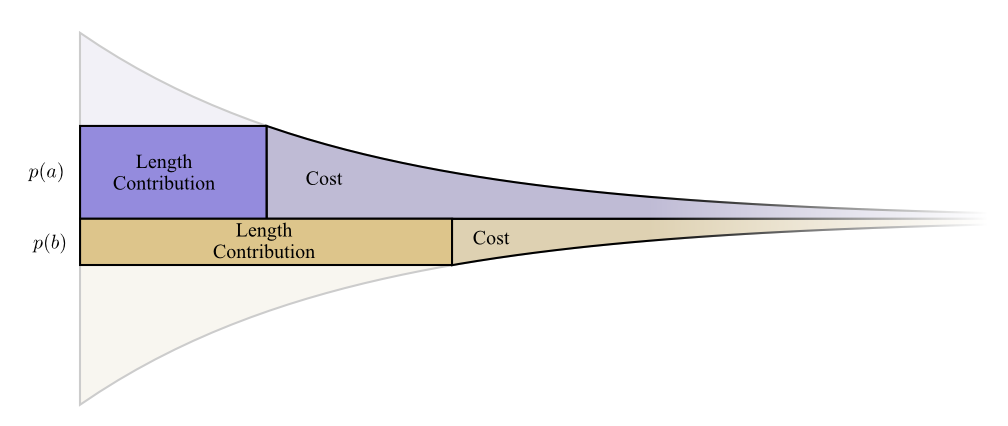
Границы стоимости и увеличения длины слова идеально совпали. Имеет ли это какой-нибудь смысл?
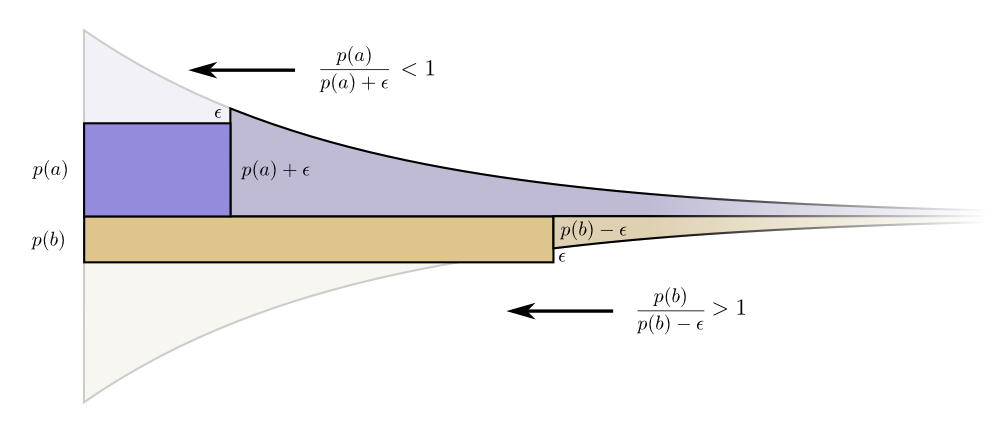
Рассмотрим, что произойдет со стоимостью и длиной, если мы немного изменим длину кодового слова. Если увеличить длину кодового слова, то длина сообщения начнет возрастать, в то время как стоимость будет уменьшаться.

Чтобы сделать кодовое слово a короче, нужно затратить p(a). С другой стороны, нам не столь важна длина каждого конкретного кодового слова сама по себе, мы рассматриваем ее с точки зрения того, как часто мы используем те или иные кодовые слова. В случае слова a частотой будет p(a). Наш выигрыш от уменьшения слова a составит p(a).
Интересно, что соприкасающиеся границы на графике равны. Это означает, что наш первоначальный бюджет имеет интересное свойство: если есть возможность, то инвестирование в уменьшение длины любого кодового слова даст положительный результат.
В конце концов, мы стремимся к оптимальному соотношению выгоды и затрат – оно определяет, во что мы должны больше инвестировать. В этом случае отношение равно единице и не зависит от величины p(a). Это справедливо и для других событий.
Есть смысл инвестировать в любое слово, так как соотношение выгоды и затрат всегда равно единице.
Менять бюджет можно бесконечно, потому нам нужно найти оптимальный. Чтобы сделать это, давайте вложим в одно кодовое слово средства другого. Если мы вложим в a на ? больше, за счет уменьшения b, то это делает кодовое слово a короче, а кодовое слово b длиннее.
Сейчас мы получили затраты на короткое кодовое слово для a и затраты для b. Теперь, если мы воспользуемся той же формулой, то получим как отношение выгоды и затрат для a, так и для b.
Затраты более не сбалансированы – b выгоднее a. Инвесторы кричат: «Купить b! Продать a!» Если мы сделаем это, то в итоге вернемся к нашему первоначальному плану – так можно улучшить все неоптимальные бюджеты.
Наш самый первый вариант распределения средств (инвестировать в каждое кодовое слово пропорционально частоте его использования) не только логичен, но и оптимален. Хотя это доказательство приведено только для двух кодовых слов, его легко применить к большему их количеству.
Внимательный читатель мог заметить, что для нашего оптимального бюджета можно рассмотреть коды, где кодовые слова имеют дробные длины. Это настораживает. Что это значит? На практике, отправляя одно кодовое слово, вам придется округлить его длину. Однако, как мы увидим позже, можно отправить дробные кодовые слова, если отсылать несколько за один раз.
Во второй части Теории визуализации информации в истории с Бобом появится еще один персонаж – Алиса, и на примере их «взаимодействия» с автором мы рассмотрим вопросы расчета энтропии, явление перекрестной энтропии и энтропии нескольких переменных.
OlegUV
«Что это, Бэримор?!»
Долго разглядывал заглавную картинку, пытаясь понять, что хотели этим хотели сказать мастера визуализации, но так и не понял, нажал на кнопку ката и получил то же самое, но в развёрнутом виде: 62% -футболки пересекают 25% дождь и далее в том же духе. Господа-товарищи, «визуализация» — это когда понятно даже тупому, ну или хотя бы красиво.
lol_wat
Это же картинка для привлечения внимания, врядли она одна должна целиком и полностью объяснять «теорию визуализации информации», а вот свою задачу решает — хочется кликнуть и почитать подробнее
OlegUV
Точку зрения копирайтера/seo-шника/копипастера — понимаю, но не разделяю.