
При решении задач комбинаторики часто возникает необходимость в расчете биномиальные коэффициентов. Бином Ньютона, т.е. разложение 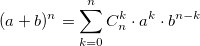 также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы:
также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы: 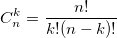 или использовать рекуррентную формулу:
или использовать рекуррентную формулу: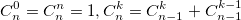 Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.
Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.
Прежде чем перейти к написанию процедур расчета, рассмотрим так называемый треугольник Паскаля.
или он же, но немного в другом виде. В левой колонке строки значение n, дальше в строке значения для k=0..n
для k=0..n
В полном соответствии с рекуррентной формулой значения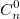 равны 1 и любое число равно сумме числа, стоящего над ним и числа «над ним+шаг влево». Например, в 7й строке число 21, а в 6й строке числа 15 и 6: 21=15+6. Видно также, что значения в строке симметричны относительно середины строки, т.е.
равны 1 и любое число равно сумме числа, стоящего над ним и числа «над ним+шаг влево». Например, в 7й строке число 21, а в 6й строке числа 15 и 6: 21=15+6. Видно также, что значения в строке симметричны относительно середины строки, т.е.  . Это свойство симметричности бинома Ньютона относительно a и b и оно видно в факториальной формуле.
. Это свойство симметричности бинома Ньютона относительно a и b и оно видно в факториальной формуле.
Ниже для биномиальных коэффициентов я буду также использовать представление C(n,k) (его проще набирать, да и формулу-картинку не везде можно вставить.
поскольку биномиальные коэффициенты неотрицательные, будем использовать в расчетах беззнаковый тип.
Вызовем функцию bci(10,4) — она вернет 210 и это правильное значение коэффициента C(10,4). Значит, задача расчета решена? Да, решена. Но не совсем. Мы не ответили на вопрос: при каких максимальных значениях n,k функция bci будет работать правильно? Прежде чем начать искать ответ, условимся, что используемый нами тип unsigned int 4-х байтный и максимальное значение равно 232-1=4'294'967'295. При каких n,k C(n,k) превысит его? Обратимся к треугольнику Паскаля. Видно, что максимальные значения достигаются в середине строки, т.е. при k=n/2. Если n четно, то имеется одно максимальное значение, а если n нечетно, то их два. Точное значение C(34,17) равно 2333606220, а точное значение C(35,17) равно 4537567650, т.е. уже больше максимального unsigned int.
Напишем тестовую процедуру
Значение в очередной строке должно быть примерно в 2 раза больше, чем в предыдущей. Поэтому последний правильно вычисленный коэффициент (см треугольник выше) — это C(12,6) Хотя unsigned int вмещает 4млрд, правильно вычисляются значения меньше 1000. Вот те раз, почему так? Все дело в нашей процедуре bci, точнее в строке, которая сначала вычисляет большое число в числителе, а потом делит его на большое число в знаменателе. Для вычисления C(13,6) сначала вычисляется 13!, а это число > 6млрд и оно не влезает в unsigned int.
Как оптимизировать расчет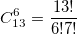 ? Очень просто: раскроем 13! и сократим числитель и знаменатель на 7! В результате получится
? Очень просто: раскроем 13! и сократим числитель и знаменатель на 7! В результате получится 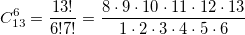 . Запрограммируем расчет по этой формуле
. Запрограммируем расчет по этой формуле
:
Явно лучше, ошибка возникла при расчете C(31,15). Причина понятна — все то же переполнение. Сначала умножаем на 31 (оп-па — переполнение, потом делим на 15). А что, если использовать рекурсивную формулу? Там только сложение, переполнения быть не должно.
Что ж, пробуем:
Все, что влезло в unsigned int, посчиталось правильно. Вот только строчка с n=34 считалась около минуты. При расчете C(n,n/2) делается два рекурсивных вызова, поэтому время расчета экспоненциально зависит от n. Что же делать — получается либо неточно, либо медленно. Выход — в использовании 64 битных переменных.
Замечание по результатам обсуждений: в конце статьи добавлен раздел, где приведен простой и быстрый вариант «bcr с запоминанием» одного из участников обсуждения.
Заменим в функции bci unsigned int на unsigned long long и протестируем в диапазоне n=34..68. n=34 — это максимальное значение, которое правильно считается bci, а C(68,34) ~2.8*1019 уже не влезает в unsigned long long ~1.84*1019
Видим, что ошибка возникает при n=63 по той же причине, что и в bci. Сначала умножение на 63 (и переполнение), затем деление на 31.
Ошибка возникла при n=63, а при n=68 результат уже не влезает в unsigned64. Поэтому можно сказать «до n<=62 функция bcl считает правильно, дальнейшее увеличение точности требует либо int128 либо длинной арифметики». А если очень высокая точность не нужна, но хочется считать биномиальные коэффициенты при n=100...1000? Снова берем процедуру bci и меняем в ней типы unsigned int на double:
Даже для n=1000 удалось посчитать! Переполнение double произойдет при n=1030.
Расхождение расчета bcd с точным значением начинается с n=57. Он небольшое — всего 8. При n=67 отклонение 896.
В принципе, для практических задач точности функции bcd достаточно, но в олимпиадных задачах часто даются тесты «на грани». Т.е. теоретически может встретится задача, где точности double недостаточно и C(n,k) влезает в unsigned long long еле-еле. Как избежать переполнения для таких крайних случаев? Можно использовать рекурсивный алгоритм. Но если он для n=34 считал минуту, то для n=67 будет считать лет 100. Можно запоминать рассчтанные значения (см Дополнение после публиукации).Также можно использовать рекурсию не для всех n и k, а только для «достаточно больших». Вот процедура расчета, которая считает правильно для n<=67. Иногда и для n>67 при малых k (к примеру, считает C(82,21)=1.83*1019).
В какой-то из олимпиадных задач мне потребовалось вычислять много C(n,k) для n >70, т.е. они заведомо не влезали в unsigned long long. Естественно, пришлось использовать «длинную арифметику» (свою). Для этой задачи я написал «рекурсию с памятью»: вычисленные коэффициенты запоминались в массиве и экспоненциального роста времени расчета не было.
При обсуждении часто упоминаются варианты с запоминанием рассчитанных значений. У меня есть код с динамическим выделением памяти, но я его не привел. На даный момент вот самый простой и эффективный из комментария chersanya: http://habrahabr.ru/post/274689/#comment_8730359http://habrahabr.ru/post/274689/#comment_8730359
Если в программе надо использовать [почти] все коэффициенты треугольника Паскаля (до какого-то уровня), то приведенный рекурсивный алгоритм с запоминанием — самый быстрый способ. Аналогичный код годится и для unsigned long long и даже для длинной арифметики (хотя там, наверное, лучше динамически вычислять и выделять требуемый объем памяти). Конкретные значения N_MAX могут быть такими:
35 — посчитает все коэффициенты C(n,k), n< 35 для unsigned int (32 бита)
68 — посчитает все коэффициенты C(n,k), n< 68 для unsigned long long (64 бита)
200 — посчитает коэффициенты C(n,k), n< 200 и некоторых k для unsigned long long (64 бита). Например, для С(82,21)=~1.83*1019
K_MAX — это может быть N_MAX/2+1, но не больше 35, поскольку C(68,34) за границей unsigned long long.
Для простоты можно всегда брать K_MAX=35 и не думать «войдет — не войдет» (до тех пор, пока не перейдем к числами с разрядностью >64 бита).
также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы: или использовать рекуррентную формулу: Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.Прежде чем перейти к написанию процедур расчета, рассмотрим так называемый треугольник Паскаля.
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
или он же, но немного в другом виде. В левой колонке строки значение n, дальше в строке значения
для k=0..n n биномиальные коэффициенты
0 1
1 1 1
2 1 2 1
3 1 3 3 1
4 1 4 6 4 1
5 1 5 10 10 5 1
6 1 6 15 20 15 6 1
7 1 7 21 35 35 21 7 1
8 1 8 28 56 70 56 28 8 1
9 1 9 36 84 126 126 84 36 9 1
10 1 10 45 120 210 252 210 120 45 10 1
11 1 11 55 165 330 462 462 330 165 55 11 1
12 1 12 66 220 495 792 924 792 495 220 66 12 1
13 1 13 78 286 715 1287 1716 1716 1287 715 286 78 13 1
14 1 14 91 364 1001 2002 3003 3432 3003 2002 1001 364 91 14 1
15 1 15 105 455 1365 3003 5005 6435 6435 5005 3003 1365 455 105 15 1
16 1 16 120 560 1820 4368 8008 11440 12870 11440 8008 4368 1820 560 120 16 1
В полном соответствии с рекуррентной формулой значения
равны 1 и любое число равно сумме числа, стоящего над ним и числа «над ним+шаг влево». Например, в 7й строке число 21, а в 6й строке числа 15 и 6: 21=15+6. Видно также, что значения в строке симметричны относительно середины строки, т.е. . Это свойство симметричности бинома Ньютона относительно a и b и оно видно в факториальной формуле.Ниже для биномиальных коэффициентов
я буду также использовать представление C(n,k) (его проще набирать, да и формулу-картинку не везде можно вставить.Расчет биномиальных коэффициентов через факториальную формулу
поскольку биномиальные коэффициенты неотрицательные, будем использовать в расчетах беззнаковый тип.
// расчет факториала n
unsigned fakt(int n)
{
unsigned r;
for (r=1;n>0;--n)
r*=n;
return r;
}
// расчет C(n,k)
unsinged bci(int n,int k)
{
return fakt(n)/(fakt(k)*fakt(n-k));
}
Вызовем функцию bci(10,4) — она вернет 210 и это правильное значение коэффициента C(10,4). Значит, задача расчета решена? Да, решена. Но не совсем. Мы не ответили на вопрос: при каких максимальных значениях n,k функция bci будет работать правильно? Прежде чем начать искать ответ, условимся, что используемый нами тип unsigned int 4-х байтный и максимальное значение равно 232-1=4'294'967'295. При каких n,k C(n,k) превысит его? Обратимся к треугольнику Паскаля. Видно, что максимальные значения достигаются в середине строки, т.е. при k=n/2. Если n четно, то имеется одно максимальное значение, а если n нечетно, то их два. Точное значение C(34,17) равно 2333606220, а точное значение C(35,17) равно 4537567650, т.е. уже больше максимального unsigned int.
Напишем тестовую процедуру
void test()
{
for (n=10;n<=35;++n)
printf("%u %u",n,bci(n,n/2);
// для C++ можно использовать cout<<n<<" "<<bci(n,n/2)<<endl;
}
Запустим ее и увидим
10 252
11 462
12 924
13 532
14 50
15 9
16 1
17 2
18 1
19 0
20 0
21 1
22 0
23 4
24 1
25 0
26 1
27 0
28 1
29 0
30 0
31 0
32 2
33 2
34 0
35 0
Значение в очередной строке должно быть примерно в 2 раза больше, чем в предыдущей. Поэтому последний правильно вычисленный коэффициент (см треугольник выше) — это C(12,6) Хотя unsigned int вмещает 4млрд, правильно вычисляются значения меньше 1000. Вот те раз, почему так? Все дело в нашей процедуре bci, точнее в строке, которая сначала вычисляет большое число в числителе, а потом делит его на большое число в знаменателе. Для вычисления C(13,6) сначала вычисляется 13!, а это число > 6млрд и оно не влезает в unsigned int.
Как оптимизировать расчет
? Очень просто: раскроем 13! и сократим числитель и знаменатель на 7! В результате получится . Запрограммируем расчет по этой формулеunsigned bci(int n,int k)
{
if (k>n/2) k=n-k; // возьмем минимальное из k, n-k.. В силу симметричность C(n,k)=C(n,n-k)
if (k==1) return n;
if (k==0) return 1;
unsigned r=1;
for (int i=1; i<=k;++i) {
r*=n-k+i;
r/=i;
}
return r;
}
:
и снова протестируем
10 252
11 462
12 924
13 1716
14 3432
15 6435
16 12870
17 24310
18 48620
19 92378
20 184756
21 352716
22 705432
23 1352078
24 2704156
25 5200300
26 10400600
27 20058300
28 40116600
29 77558760
30 155117520
31 14209041
32 28418082
33 39374192
34 78748384
35 79433695
Явно лучше, ошибка возникла при расчете C(31,15). Причина понятна — все то же переполнение. Сначала умножаем на 31 (оп-па — переполнение, потом делим на 15). А что, если использовать рекурсивную формулу? Там только сложение, переполнения быть не должно.
Что ж, пробуем:
unsigned bcr(int n,int k)
{
if (k>n/2) k=n-k;
if (k==1) return n;
if (k==0) return 1;
return bcr(n-1,k)+bcr(n-1,k-1);
}
void test()
{
for (n=10;n<=35;++n)
printf("%u %u",n,bcr(n,n/2);
// для C++ можно использовать cout<<n<<" "<<bcr(n,n/2)<<endl;
}
Результат теста
10 252
11 462
12 924
13 1716
14 3432
15 6435
16 12870
17 24310
18 48620
19 92378
20 184756
21 352716
22 705432
23 1352078
24 2704156
25 5200300
26 10400600
27 20058300
28 40116600
29 77558760
30 155117520
31 300540195
32 601080390
33 1166803110
34 2333606220
35 242600354
Все, что влезло в unsigned int, посчиталось правильно. Вот только строчка с n=34 считалась около минуты. При расчете C(n,n/2) делается два рекурсивных вызова, поэтому время расчета экспоненциально зависит от n. Что же делать — получается либо неточно, либо медленно. Выход — в использовании 64 битных переменных.
Замечание по результатам обсуждений: в конце статьи добавлен раздел, где приведен простой и быстрый вариант «bcr с запоминанием» одного из участников обсуждения.
Использование 64 битных типов для расчета C(n,k)
Заменим в функции bci unsigned int на unsigned long long и протестируем в диапазоне n=34..68. n=34 — это максимальное значение, которое правильно считается bci, а C(68,34) ~2.8*1019 уже не влезает в unsigned long long ~1.84*1019
unsigned long long bcl(int n,int k)
{
if (k>n/2) k=n-k;
if (k==1) return n;
if (k==0) return 1;
unsigned long long r=1;
for (int i=1; i<=k;++i) {
r*=n-k+i;
r/=i;
}
return r;
}
void test()
{
for (n=34;n<=68;++n)
printf("%llu %llu",n,bcl(n,n/2));
// для C++ можно использовать cout<<n<<" "<<bcl(n,n/2)<<endl;
}
Результат теста
34 2333606220
35 4537567650
36 9075135300
37 17672631900
38 35345263800
39 68923264410
40 137846528820
41 269128937220
42 538257874440
43 1052049481860
44 2104098963720
45 4116715363800
46 8233430727600
47 16123801841550
48 32247603683100
49 63205303218876
50 126410606437752
51 247959266474052
52 495918532948104
53 973469712824056
54 1946939425648112
55 3824345300380220
56 7648690600760440
57 15033633249770520
58 30067266499541040
59 59132290782430712
60 118264581564861424
61 232714176627630544
62 465428353255261088
63 321255810029051666
64 66050867754679844
65 454676336121653775
66 350360427585442349
67 23341572944240599
68 46683145888481198
Видим, что ошибка возникает при n=63 по той же причине, что и в bci. Сначала умножение на 63 (и переполнение), затем деление на 31.
Дальнейшее повышение точности и расчет при n>67
Ошибка возникла при n=63, а при n=68 результат уже не влезает в unsigned64. Поэтому можно сказать «до n<=62 функция bcl считает правильно, дальнейшее увеличение точности требует либо int128 либо длинной арифметики». А если очень высокая точность не нужна, но хочется считать биномиальные коэффициенты при n=100...1000? Снова берем процедуру bci и меняем в ней типы unsigned int на double:
double bcd(int n,int k)
{
if (k>n/2) k=n-k; // возьмем минимальное из k, n-k.. В силу симметричности C(n,k)=C(n,n-k)
if (k==1) return n;
if (k==0) return 1;
double r=1;
for (int i=1; i<=k;++i) {
r*=n-k+i;
r/=i;
}
return ceil(r-0.2); // округлим до ближайшего целого, отбросив дробную часть
// комментарий изменен после обсуждений: такой способ использован, чтобы расхождение с точным значением
// было как можно позже. Где-то оно превышало 0.5 и простой round не годился
}
void testd()
{
for (n=50;n<=1000;n+=50)
printf("%d %.16e\n",n,bcd(n,n/2));
// для C++ можно использовать cout<<n<<" "<<bcd(n,n/2)<<endl;
}
Результат теста
50 1.2641060643775200e+014
100 1.0089134454556417e+029
150 9.2826069736708704e+043
200 9.0548514656103225e+058
250 9.1208366928185793e+073
300 9.3759702772827310e+088
350 9.7744946171567713e+103
400 1.0295250013541435e+119
450 1.0929255500575370e+134
500 1.1674431578827770e+149
550 1.2533112137626624e+164
600 1.3510794199619429e+179
650 1.4615494992533863e+194
700 1.5857433585316801e+209
750 1.7248900341772600e+224
800 1.8804244186835327e+239
850 2.0539940413411323e+254
900 2.2474718820660189e+269
950 2.4629741379276902e+284
1000 2.7028824094543663e+299
100 1.0089134454556417e+029
150 9.2826069736708704e+043
200 9.0548514656103225e+058
250 9.1208366928185793e+073
300 9.3759702772827310e+088
350 9.7744946171567713e+103
400 1.0295250013541435e+119
450 1.0929255500575370e+134
500 1.1674431578827770e+149
550 1.2533112137626624e+164
600 1.3510794199619429e+179
650 1.4615494992533863e+194
700 1.5857433585316801e+209
750 1.7248900341772600e+224
800 1.8804244186835327e+239
850 2.0539940413411323e+254
900 2.2474718820660189e+269
950 2.4629741379276902e+284
1000 2.7028824094543663e+299
Даже для n=1000 удалось посчитать! Переполнение double произойдет при n=1030.
Расхождение расчета bcd с точным значением начинается с n=57. Он небольшое — всего 8. При n=67 отклонение 896.
Для экстремалов и «олимпийцев»
В принципе, для практических задач точности функции bcd достаточно, но в олимпиадных задачах часто даются тесты «на грани». Т.е. теоретически может встретится задача, где точности double недостаточно и C(n,k) влезает в unsigned long long еле-еле. Как избежать переполнения для таких крайних случаев? Можно использовать рекурсивный алгоритм. Но если он для n=34 считал минуту, то для n=67 будет считать лет 100. Можно запоминать рассчтанные значения (см Дополнение после публиукации).Также можно использовать рекурсию не для всех n и k, а только для «достаточно больших». Вот процедура расчета, которая считает правильно для n<=67. Иногда и для n>67 при малых k (к примеру, считает C(82,21)=1.83*1019).
unsigned long long bcl(int n,int k)
{
if (k>n/2) k=n-k;
if (k==1) return n;
if (k==0) return 1;
unsigned long long r;
if (n+k>=90) {
// разрядности может не хватить, используем рекурсию
r=bcl(n-1,k);
r+=+bcl(n-1,k-1);
}
else {
r=1;
for (int i=1; i<=k;++i) {
r*=n-k+i;
r/=i;
}
}
return r;
}
В какой-то из олимпиадных задач мне потребовалось вычислять много C(n,k) для n >70, т.е. они заведомо не влезали в unsigned long long. Естественно, пришлось использовать «длинную арифметику» (свою). Для этой задачи я написал «рекурсию с памятью»: вычисленные коэффициенты запоминались в массиве и экспоненциального роста времени расчета не было.
Дополнение после публикации
При обсуждении часто упоминаются варианты с запоминанием рассчитанных значений. У меня есть код с динамическим выделением памяти, но я его не привел. На даный момент вот самый простой и эффективный из комментария chersanya: http://habrahabr.ru/post/274689/#comment_8730359http://habrahabr.ru/post/274689/#comment_8730359
unsigned bcr_cache[N_MAX][K_MAX] = {0};
unsigned bcr(int n,int k)
{
if (k>n/2) k=n-k;
if (k==1) return n;
if (k==0) return 1;
if (bcr_cache[n][k] == 0)
bcr_cache[n][k] = bcr(n-1,k)+bcr(n-1,k-1);
return bcr_cache[n][k];
}
Если в программе надо использовать [почти] все коэффициенты треугольника Паскаля (до какого-то уровня), то приведенный рекурсивный алгоритм с запоминанием — самый быстрый способ. Аналогичный код годится и для unsigned long long и даже для длинной арифметики (хотя там, наверное, лучше динамически вычислять и выделять требуемый объем памяти). Конкретные значения N_MAX могут быть такими:
35 — посчитает все коэффициенты C(n,k), n< 35 для unsigned int (32 бита)
68 — посчитает все коэффициенты C(n,k), n< 68 для unsigned long long (64 бита)
200 — посчитает коэффициенты C(n,k), n< 200 и некоторых k для unsigned long long (64 бита). Например, для С(82,21)=~1.83*1019
K_MAX — это может быть N_MAX/2+1, но не больше 35, поскольку C(68,34) за границей unsigned long long.
Для простоты можно всегда брать K_MAX=35 и не думать «войдет — не войдет» (до тех пор, пока не перейдем к числами с разрядностью >64 бита).
stack_trace
Извините, но C++ тут совсем непричём.
Teivaz
Здесь этот тэг можно применить по аналогии со Stack Overflow, которые пишут:
stack_trace
Да я ничего против не имею, просто здесь не только тег, но и хаб и даже в заголовок вынесено. Впрочем, ничего плохого в этом не вижу, статья по большей части алгоритмическая и не про языки.
zelserg
Я все примеры компилировал на С++. Заголовком я хотел сказать «можно брать функции расчета, вставлять их в программы на языках С, С++ и все будет работать». На Бейсике или Паскале это не получится. Что Вас не устраивает?
stack_trace
Я же написал, что ничего против не имею, почему вы у меня спрашиваете, что меня не устраивает?
zelserg
А хочу понять логику высказывания «С++ непричем». Первый отзыв и сразу «непричем»… Если мне нужно найти некий алгоримХ на языке С++, я пишу в поисковике «алгоритмХ С++» и если поисковик возвращает мне алгоритмХ на PHP, то вот этот РНР — «непричем». А если он возвращает алгоритм на С++ или С, то это то, что надо. Я его беру и использую.
stack_trace
Да потому что широко распространено заблуждение, что если вы можете что-то написать на C то код на C++ будет выглядеть также. Это заблуждение и это чаще всего неверно. То, что код для С компилируется плюсовым компилятором почти всегда и так всем известно, это не делает его кодом на С++. Этот же код, например, отлично скомпилировался бы и Objective C компилятором, может и этот хаб/тег добавите?
zelserg
«То, что код для С компилируется плюсовым компилятором почти всегда и так всем известно». В том то и дело, что раз «почти», то есть исключения. Вот я и написал в заголовке С++ в скобках, показывающее, что примеры в статье к исключениям не относятся.
В заголовке указано: на Си (С++), Objective C не подходит ни под одну из категорий?
Если вы трактуете простой и понятный текст своебразным образом, то причем тут я, заголовок, С и С++?
stack_trace
Послушайте, я никак не трактую ваш текст, я просто сделал замечание, с которым, я думаю, согласится любой, для кого C++ — основной язык разработки. Код на С != код на С++, равно как С != С++. Заходя в хаб С++ я ожидаю увидеть код на С++, а заходя в хаб С — код на С. При этом я прекрасно отдаю себе отчёт в том, что почти любой код из хаба С скомпилируется как С++.
Конечно же, нет.Обычно, указывают что код на C++ когда он явно на C++ и ничем больше не скомпилируется. Так можно ещё поставить теги C++11, C++14, C++17. А что? Компиляторами, поддерживающими эти стандарты он тоже скомпилируется.
Вообще, не стоит воспринимать моё замечание так в штыки. Вы просили пояснений — я их дал, я не собирался с вами спорить.
zelserg
Насчет заблуждений. Я занимаюсь программированием не один десяток лет и давно избавился от заблуждения, которое в грубой формулировке звучит примерно так: «если при написании кода можно выпендриться, то нужно выпендриться».
stack_trace
Да причём тут «выпендриться»? Вы о чём вообще?
zelserg
Похоже, у нас разный менталитет и мы не понимаем друг друга. Вы в тегах С++ ищете то, что будет работать только на С++, а я в тегах С++ ищу то, что будет работать на С++.
stack_trace
Ну, хабр это же не pastbin, тут люди обычно не код ищут а статьи на конкретную тему, узнать что-то новое про конкретную область. Так вот, к теме С++ данная статья имеет крайне слабое отношение, и ничего нового про С++ из этой статьи узнать не получиться, равно как и про Objective C. Про С — возможно, про алгоритмы — наверняка. ИМХО, правильными хабами для этой статьи были бы C и Алгоритмы, но никак не C++.
Только не обижайтесь, ради бога. Никак не хотел вас задеть своим замечанием.
zelserg
А разве не вы мне тут минусов наставили? Или какой-то идиот c чувством неполноценности влез в чужое обсуждение?
zelserg
Мне даже жалко этого идиота. То, что ему вернется, явно будет несопоставимо с какими-то «минусами». Хотя он, скорее всего, не свяжет свои мелкие гадости с этим возвратом. Что тут скажешь — сам делал, никто не принуждал…
stack_trace
Я не ставлю минусы тем, с кем общаюсь, за исключением редких случаев, типа оскорбления. Я вообще нечасто их ставлю. Не переживайте из-за них, это просто выражение согласия или несогласия людей с тем, что вы написали, а не оценка вам.
semenyakinVS
Вот-вот. Вот если бы "<название статьи> на этапе компиляции" — тогда другое дело
zelserg
Т.е «Расчет биномиальных коэффициентов на Си (С++) на этапе компиляции»? Мне это кажется странным, мягко говоря.
Eivind
Нет ничего проще:
semenyakinVS
… и вот как-то так были устранены претензии к названию статьи
Eivind
encyclopedist
Вот такая функция считает в 32 битных числах правильно до 33 включительно (проверяем, делится ли, и если да то сначала делим а потом умножаем):
zelserg
Интересное замечание, но хочу заметить:
1. Возможно, при каких-то k и n<=33 все же возникнет переполнение
2. Граница отодвинулась, но для n=34 все же осталось переполнение.
3. Переход на 64 бита кардинально отодвигает эту границу
Можно, конечно, в числителе и знаменмтеле поискать общие множители и посокращать их, но я не стал двигаиться в этом напралении.
encyclopedist
encyclopedist
И ещё лучший выриант (Live):
С unsigned int работает до 33, с unsigned long работает до 66.encyclopedist
Обновление. Теперь точно все множители сокращает:
Работает до 34 и 67 соответственно.zelserg
«Простая задача часто имеет простое и понятное решение. Увы, неправильное...» Как увидеть эту неправильность и довести до ума — вот в чем вопрос. Способы могут быть разными. У меня работает и при n=67 и не тратит время на вычисление НОДов.
encyclopedist
Все зависит от требований. У меня без доп памяти. С доп памятью надо ещё посмотреть что лучше (на вскидку и моё решение и динамическое программирование работают за O(n^2)).
encyclopedist
Моё даже лучше: gcd считается за логарифмическое время, поэтому O(n log n).
encyclopedist
Вот без НОДов (трюк r*a/b = (r/b)*a + (r%b)*a/b из этого комментария Mrrl ). Считает без переполнения пока это теоретически возможно. (на Coliru)
zelserg
Спасибо за трюк и за ссылку. Надо же — перед написанием статьи искал на хабре «биномиальные», а надо было «мультиномиальные»
a_batyr
zelserg
Напишите, как. Кроме приведенной в статье рекурсии, естественно.
a_batyr
Расчёт БК без умножения, динамически.
Храним массив БК для элементов C(i,0), C(i,1), ..., C(i,i). Инициализируем для i=0 как {1}. Каждую следующую итерацию вычисляем через предыдущие значения C(i,k) = C(i-1,k)+C(i-1,k-1) вплоть до заданного C(n,k).
Вы написали что-то похожее, только рекурсивно, что слишком прожорливо. Вам не нужно повторно вычислять промежуточные значения, а в случае рекурсии вы это делаете. Храня уже известные значения вы на порядок улучшите производительность.
zelserg
Я сделал добавление в статье — рекурсивная функция bcr с запоминанием.
Она, конечно, самая быстрая, но значимого выигрыша в скорости для int и long long не дает. Значимого — т.е. чтобы bci/bcl, были узким местом в какой-то задаче, а новая bcr расшивала это узкое место.
chersanya
Странное у вас понимание «значимости» ускорения :) Если функция работает например в несколько раз быстрее — это уже значимое ускорение, хотя при правильном решении на олимпиаде это обычно не повлияет, т.к. таймлимит обычно ставится значительно больше необходимого. Измерили бы скорости всех вариантов да указали в статье, было бы интересно сравнить.
zelserg
«Во-первых стоило сразу привести в статье длинную арифметику. Это грустно, когда оперируют с double при расчёте целочисленных значений»
Сначала о грусти. Для практических расчетов биномиальных коэффициентов (БК) double — самое простое и эффективное решение. Если вы моделируете случайные процессы, то точности в 16 знаков «за глаза» хватает и выборки из 1000 элементов, скорее всего, тоже хватит. Кроме того, БК в реальных расчетах живут не сами по себе, а умножаются на вероятности, которые сами по себе double. Грустно городить длинную арифметику для расчета БК, а потом умножать их на double.
Длинная арифметика нужна при расчете БК только в одном случае — при решении олимпиадных задач и это тема для отдельной статьи (не моей). Я считаю, что каждый потенциальный олимпиец должен написать свою длинную арифметику, не такая уж она и сложная. А коль не может — значит олимпиады не для него.
a_batyr
Использование double это костыль, который может быть оправдан лишь в некоторых случаях. Тогда вам стоило написать длинную арифметику и лишь вскольз упомянуть про double (типа если вам не нужна точность, используйте double). Но я хотел сказать, что не приведя решение с длинной арифметикой и динамикой вы не до конца раскрыли тему статьи. Вы приводите заголовок и совершенно не раскрываете тему статьи для олимпийцев. И уберите кавычки с этого слова ради бога, олимпийцы это живые люди!
Что ж, некоторые вообще считают нормальным снимать вертикальное видео и я на это никак не могу повлиять :-(
zelserg
«И уберите кавычки с этого слова ради бога». Облимпийцы без кавычек — это Олимпийские боги (уж они то не одобрят убирание кавычек) в греческой мифологии и спортсмены-участники Олимпийских игр. К участникам прочих олимпиад слово олимпийцы не относится.
В моей статье я сделал 2 небольших замечания для желающих заниматься олимпиадным программированием.
1. Привел улучшенный вариант функции bcl, который правильно считает все БК, попадающие в unsigned long long
2. Для тех, кому потребуется точное вычисления очень больших биномиальных коэффициентов («длинная арифметика»), посоветовал использовать рекурсивный расчет с запоминанием. Это все, я хотел сказать и сказал. Кто не понял — я не виноват.
zelserg
12 человек добавили в избранное, но только 2 плюсанули. Итог — минус 2. Пожалуй, не стоит писать подобные статьи (это был пробный камень. так сказать).
samo-delkin
Ну, вот ты написал
это же можно в одну строку записать.
То есть не знаешь ни C, ни C++. Алгоритм тоже неоптимальный.
На олимпиады ссылаешься, а зачем они нужны? Пользы от них никакой нет.
a_batyr
Это тот случай когда в комментариях вопрос раскрыт намного лучше, чем в самой статье.
zelserg
Каждый видит и понимает «по способностям».
zelserg
В каждой статье есть шероховатости. Раздельный расчет нужен был для анализа, где переходить к рекурсивному расчету.
Критиковать гораздо легче, чем написать свою статью. На любую, самую замечательныую статью найдутся критики и недоброжелатели. Не навится — не читайте и не комментируйте. Значит она не для вас. Кто-то комментирует, чтобы статья стала лучше (и я вношу исправления по ходу обсуждения), а кто-то с целью нагадить и выпятить свое Я.
В данному моменту 26 человек поставили ее в избранное, значит посчитали ее интересной и/или полезной. Вот для таких она и написана. А любителям выискивать соринки в чужих глазах посоветую заняться своими.
«На олимпиады ссылаешься, а зачем они нужны? Пользы от них никакой нет.» Вопрос спорный. Не смог решить задачу, тебя не взяли в команду и обида гложет?
samo-delkin
Не, я просто решал такие задачи и не получил от этого ничего. Зря время только потратил.
Можно, конечно, сидеть и ждать, когда тебя в команду возьмут, а можно просто сидеть и делать программы, которые потом работают вместо тебя месяцами. (Хотя я пользуюсь уже несколько лет.)
KvanTTT
А еще есть: Методы вычисления мультиномиальных коэффициентов.
zelserg
Хорошая статья, добавил ее в избранное. Метод рекурсивного расчета с запоминанием я когда-то делал и для int и для long long. Он быстрый, ест не так уж много памяти. Но в результате остановился на приведенной к конце статьи bcl. Запоминание осталось только для длинной арифметики, когда надо было посчитать очень много очень больших коэффицентов (да и операция деления в длинной арифмиетике — то еще «удовольствие»).
Треугольник Паскаля интересная штука — очень быстрая, если запоминать промежуточные результаты и очень медленная, если не запоминать.
middle
А почему вы не считаете треугольник Паскаля? Простое быстрое итеративное решение.
zelserg
Что вы имеете в виду под «почему вы не считаете треугольник Паскаля»?
Я написал в статье функцию bcr, поторая считает по треугольнику паскаля. И написал, что элемент из 34 строки считался около минуты. Также в конце статьи написал, что при расчете коэффициентов с длинной арифметикой использовал рекурсию (т.е. треугольник паскаля) с запоминанием посчитанных коэффициентов.
middle
Я имел в виду, почему вы не используете итеративный алгоритм построения треугольника Паскаля, храня строку в массиве? 70 строк у меня на ноуте считаются за долю секунды.
Upd: и это при том, что я считаю каждый элемент отдельно — чтобы жизнь мёдом не казалась. А если печатать всю посчитанную строку целиком — будет вообще миллисекунды.
zelserg
Я писал процедуры расчета по треугольнику с запоминанием, но не стал приводить их в статье.
1. Для int и long long заметной глазу разницы в скорости нет (ну не замечает мой глаз миллисекунды).
2. Для олимпиадных задач, в которых надо было считать коэффициенты разницы тоже не было.
3. Код с запоминанием не такой простой и чуть более объемный (зачем искать/приводить путь в два шага, если есть путь в один шаг).
chersanya
Странно видеть рядом с упоминанием олимпиадных задач оценку скорости на глаз :)
А по-моему, он почти не отличается от кода без запоминания, если будем хранить весь треугольник. Заодно автоматически получается кеширование — если несколько раз попросим одно и то же значение, оно не будет пересчитываться.
Для сравнения — ваш код из статьи:
И простейший вариант с запоминанием (не компилировал, но должно работать):
Кстати, в вашей строчке
неправильный либо код, либо комментарий.
zelserg
1. Я не сравниваю «на глаз» с олимпиадным программированианием. «На глаз» относится к замечанию «на моем ноутбуке», про миллисекунды — типа юмор. Про олимпиадное — то что тесты проходят и оптимизации скорости расчета БК не требуется.
2. При запоминании фиксированные размеры мне как-то не очень… Но вариант вполне простой и рабочий.
return ceil(r-0.2); // округлим до ближайшего целого, отбросив дробную часть
неправильный либо код, либо комментарий.
Комментарий мог быть таким: я сравнивал double с точными расчетами и «экспериментально» нашел, что это значение подходит (чтобы расхождение наступило как можно позже). Наверно, можно заменить на 0.4 или другую константу, но лучше не будет.
Кстати, в статье есть еще одно «экспериментально найденная» константа: if(n+k)>90 для перехода к рекурсивной ветке.
chersanya
Ну фиксированные размеры я поставил только для простоты, и чтобы код оставался кодом на Си (у вас как я понял старательно не используется ничего из С++). Можно сделать вектором и добавлять туда по надобности, хотя раз N всё равно < 70, то можно независимо от задачи делать размер 70х70.
С точки зрения производительности это будет намного быстрее, когда на нужно посчитать большое количество коэффициентов: они будут просто браться из таблицы. Это может пройти тесты и в какой-нибудь задаче, где ваше решение не проходит. Если вам такая не попалась, не значит что её не может быть.
Комментарий в таком случае вводит в заблуждение — видя округление к ближайшему целому читатель ожидает ceil(r — 0.5) или floor(r + 0.5), или лучше всего round. И кстати не понятно, зачем это вообще — если N такие, что переполнения нет, то можно считать с int64. Если же N большие и мы используем double, то значит точность до единицы не нужна — она всё равно не будет получена при больших N.
Кстати, если так убрать ваш ceil и возвращать просто r, то функцию можно сразу сделать шаблонной — чтобы не было такого, что «заменим unsigned на double», а одна функция работала и для int32, и для int64, и для double и для длинной арифметики.
zelserg
Если просто возращать r, то у биномиальных коэффициентов появляются дробные хвосты и мне это не понравилось (все же БК — по определению целые).
zelserg
Изменил комментарий в статье.
chersanya
И ещё, для как вы называете «олимпийцев» вычисление биномиальных коэффициентов неплохо написано на e-maxx.ru/algo/binomial_coeff, причём в разных вариантах.
zelserg
Интересная стстья. При «длинных» расчетах запоминать последние две строки приходилсь, а вот запоминать факториалы — никогда. Как-то выкручивался или мне просто не попалась задача, где это необходимо
zelserg
Интересно, кто и за что заминусовал этот комментарий. Похоже, кто-то просто наставил минусов из желания нагадить. Ладно, они ему так или иначе вернутся.
middle
Ну хоть упомяньте их в статье, а то складывается впечатление, что либо быстро, но с переполнением, либо медленно, но без него. Разбирать задачу и даже не упомянуть характеристики столь важного варианта — как-то удивительно.
Про int и long long я ничего не говорил :)
middle
Собственно, о сложности столь простого куска кода и рассуждать-то странно:
zelserg
Написал добавление в статье
cybrid
Достаточно странная статья. Рассмотрены только «кривые» решения, а рекурсивное решение с запоминанием и прямое решение с подсчетом простых множителей не приведены.
zelserg
Привел рекурсивное с запоминанием, а подсчет множителей я не считаю «прямым».
dprotopopov
Мой ответ на Вашу публикацию habrahabr.ru/post/274729 — Расчет биномиальных коэффициентов с использованием Фурье-преобразований
zelserg
Давайте сравним скорость расчета C(67,33). Можете кинуть проект, который считает этот коэффицент и который можно открыть в VS2010?
zelserg
Или сами сравните. Полагаю, перевести bcr с запоминанием на c# несложно.
dprotopopov
взятое возвращаю кармой.
Можете сравнить и описать на Хабре эксперимент для разных типов данных, для C++ и C# — многих заинтересует.
Ryder95
мне кажется, первый код работать не будет, так как переменная r в цикле инициализируется, то после цикла её нет, поэтому вернуть r невозможно
zelserg
Спасибо, поправил. Намудрил, когда переводил переделал факториал из рекурсии в цикл.
ShashkovS
Вообще говоря, совсем несложно сделать реализацию на основе разложения числа n! на простые множители (по известной формуле из википедии).
Если известны ограничения на n, то простые числа можно захардкодить, иначе добыварь решетом Эратосфена.
После этого останется только вычесть показатели степеней и перемножить. При этом гарантируется, что самое большое число, которое встретится в вычислениях — это ответ.
Заодно такая техника позволит вычислять очень большие Cnk
Вот код на Python:
То есть C5000010000 вычисляется за 0.02 секунды, а там ещё есть, что ускорять.
sci_nov
www.artlebedev.ru/kovodstvo/sections/136
Абзацы 07 и 08.