
Вступление
Cегодня мы вместе с анализом графов, data mining, subgroup discovery и всеми веселыми штуками взглянем на Хабр. Весь код и данные прилагаются — каждый может взглянуть на них самостоятельно, легко повторить рассчеты из статьи и найти что-то интересное самостоятельно.

(это не просто картинка для привлечения внимания, а — граф связей ~45000 пользователей Хабра по тому, кто на кого подписан; размер вершины пропорционален числу подписчиков; все картинки кликабельны; подробности далее)
Обсуждаемые проблемы возникли, конечно же, далеко не вчера, но некоторые их аспекты кажутся мне достаточно новыми и поэтому достойными дискуссии, основанной на непредвзятых и репрезентативных данных. Например в комментариях этой статьи, увидел интересное утверждение:
Тут проблема в том, что на всем хабре за сегодня не насчитать больше 50-80 человек, которые вообще могут голосовать. У 90% пользователей карма просто ниже 5. Как итог оценивают комментарии и статьи только избранные. Это как жюри выходит такое.
И решил, что стоить его сформулировать в виде гипотезы и проверить:
Q1: Правда ли, что Хабр превратился в жюри-based сообщество, где два с половиной человека голосуют за статьи?
Вот в этой статье к нам вернулись "железные" Хабы и стало интересно, а как вообще представлены разные сообщества внутри Хабра? Формулируем в виде гипотезы:
Q2: Как сегментировано сообщество, или проще говоря сколько у нас здесь групп по интересам и соотвествуют ли они имеющимся хабам?
Последнее, но не менее интересное наблюдение, что активность на Хабре упала (по данным Хабра-пульса и моим субъективным наблюдениям), что даже решили ввести аккаунты "read & comment". Поэтому решил оценить активность сообщества и продумать, как информация о структуре сообщества может нам помочь:
Q3: Насколько активно сообщество и как нам может помочь структура внутренних групп?
За подробностями добро пожаловать под кат.
Структура статьи
- Методология сбора данных
- Распределения кармы, постов, комментариев...
- Сообщества Хабра
- Связность Хабов
- Активность и выводы
Методология сбора данных
Как известно, на Хабра-API пишут новую версию Duke Nukem Forever, поэтому приходится собирать все интересные данные самостоятельно (ну ок, на самом деле он не предоставляет всех интересных данных). Какие данные нам нужно собрать?
- База пользователей: пройдемся по всем постам (переберем все id от 2*10^5 до 2.76*10^5)
- Их персональные данные: карма, рейтинг, посты, etc
- Связи между пользователями (для анализа сообщества): отметим последователей для каждого пользователя и хабы каждой статьи.
Так как у Хабра стоит лимит на число подключений лучше всего использовать распределенную архитектуру парса, например разбить все статьи на N групп и || в 4 потока на каждой машине парсить. Все данные собираются в github HabraData (если вы пишите магистерскую или еще какой диплом по анализу данных, особенно если вдруг на русском, то там можно найти много всего интересного).
Общая схема сбора:
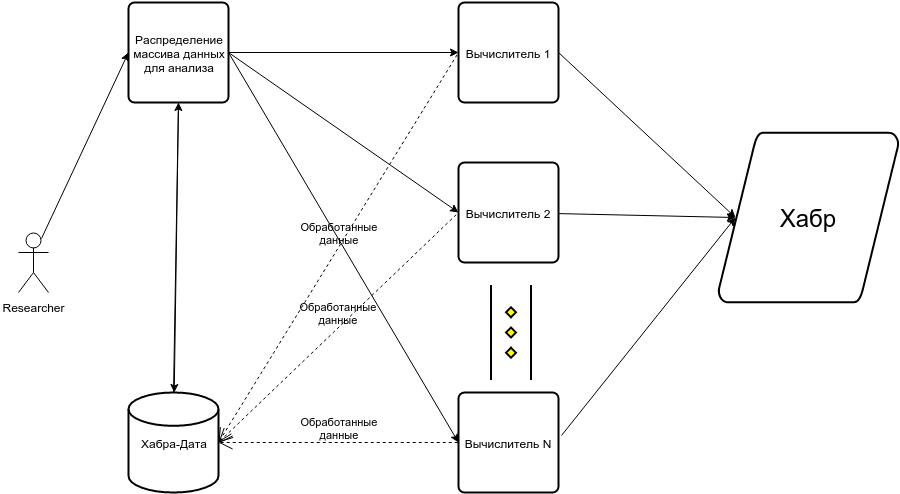
Собирались все пользователи, кто за последние ~2 года оставил комментрий и\или написал статью. Потом фильтровались те, кого забанили, ушел в минус, etc. Параллельно собирались данные по статьям, а именно к каким хабам они относятся. Данные использованные в каждом эксперименте поясняются по ходу рассказа.
Неотфильтрованные список пользователей ~ 25к доступен здесь, а здесь отфильтровнный датасет с ключевыми показателями пользователей в виде:
user,karma,rating,publications,comments,favourites,followers
....
var_bin,3.0,0.0,1,18,6,1
varagian,187.0,26.0,20,151,86,44
varanio,55.0,0.0,3,51,24,6
varerysan,16.0,0.0,9,26,0,3
....Вопрос первый: анализ распределений кармы, комментариев, постов, etc
Распределение кармы ака Карма-неравенство
Первый интересный инсайт бо?льшая часть ~61% сконцентрирована у 10% пользователей, на второй десяток (топ 20% за вычетом, тех кто в топ 10%) приходится уже меньше 20%.
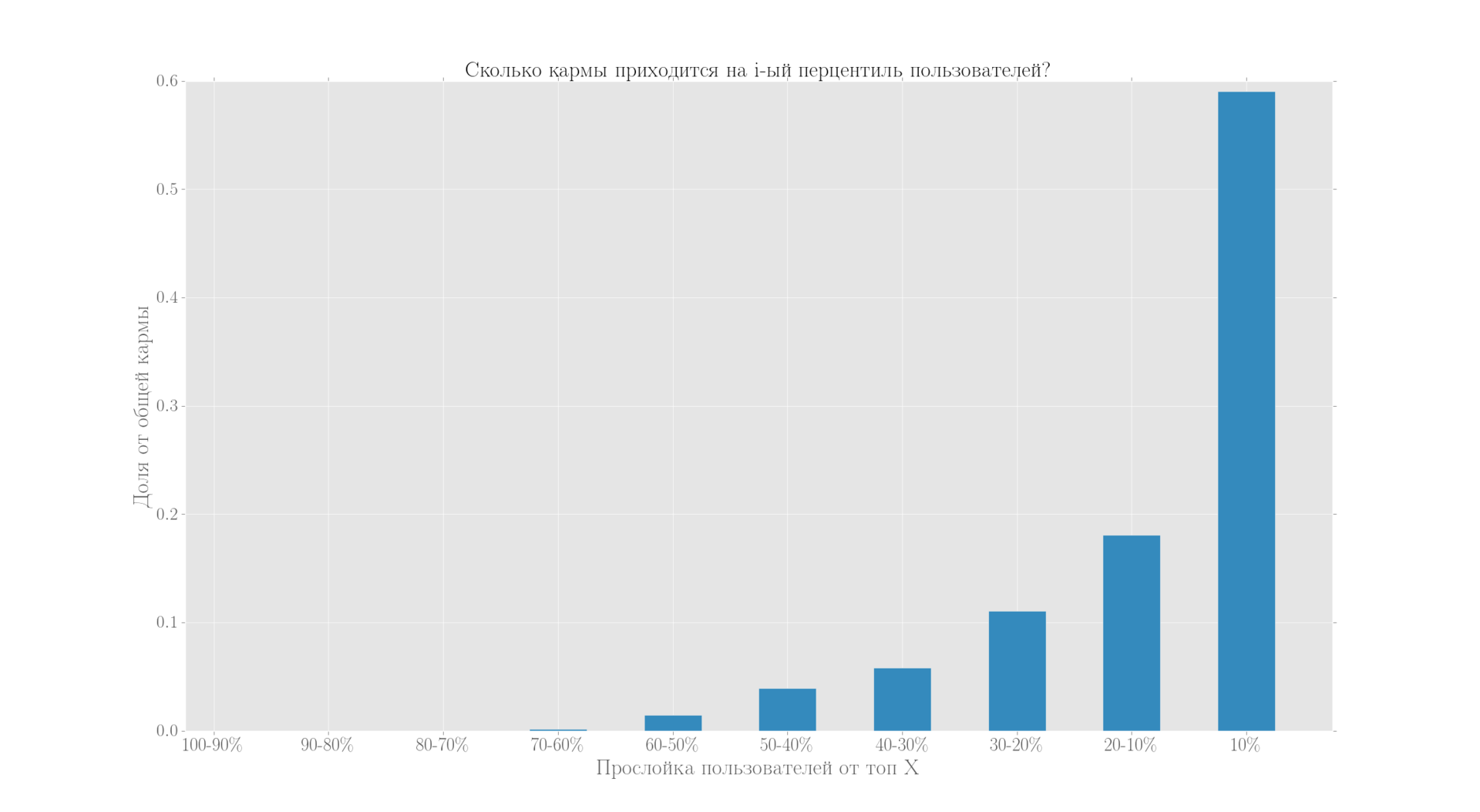
Отвечаем на комментарий в начале статьи: порядка 50% активных пользователей имеют карму 5 и более, то есть порядка 7500 человек.
Само распределение показывает, что действительно существенная группа сконцентрирована в районе нуля, что будет понятным из дальнейшего анализа.
Распределение кармы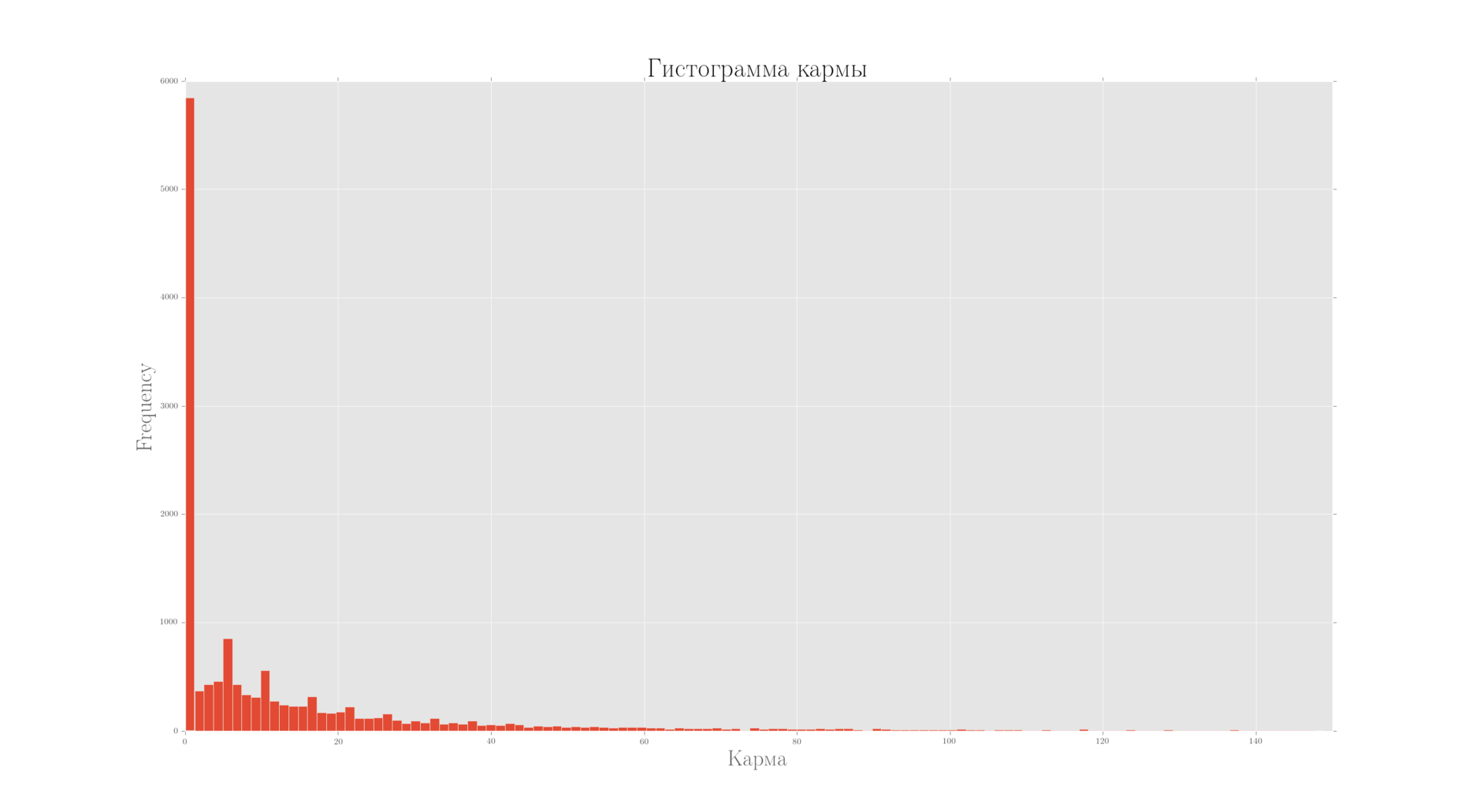
(c количеством столбиков произошло что-то странное на 20 пунктов их 16, отсюда некоторая негладкость распределения)
(c количеством столбиков произошло что-то странное на 20 пунктов их 16, отсюда некоторая негладкость распределения)
(У графиков ниже почему-то неправильно отобразилась метка на оси y, она должна читаться как «доля».)
Следующий интересный график — распределение публикаций, из него мы видим, что бо?льшую часть статей написала небольшая часть пользователей (также здесь мог сказаться и факт разделения Хабра, хотя с этого момента прошло достаточно времени.)
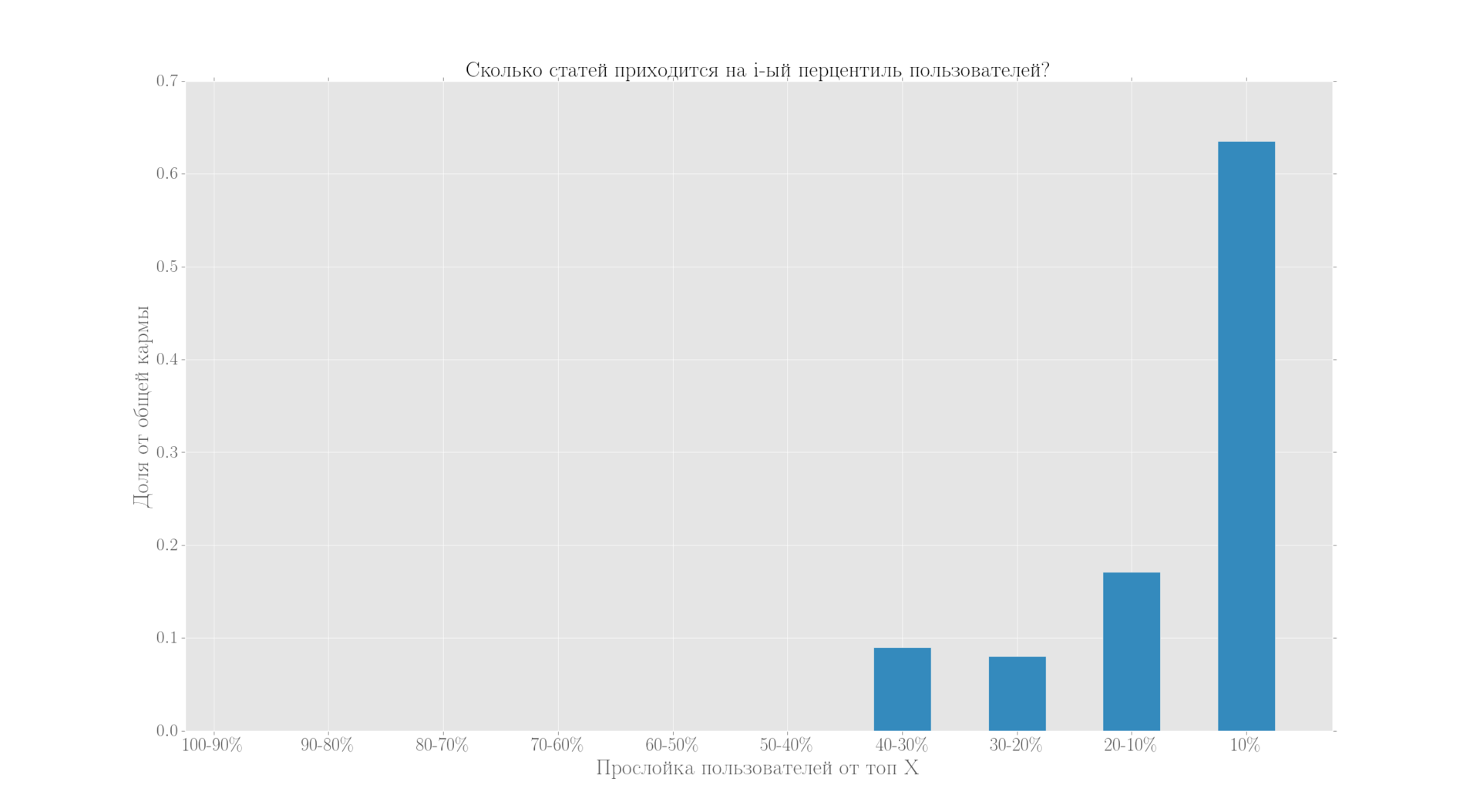
(так как распределение обрывается, то вылез неприятный эффект и левый столбец вышел чуть выше правого в хвосте, они должны быть примерно одинаковыми)
Не менее интересно проверить сохранится ли такое же распределение и для комментариев? На самом деле оно является более сбалансированным, но общий паттерн сохраняется и отражает ситуацию с кармой.
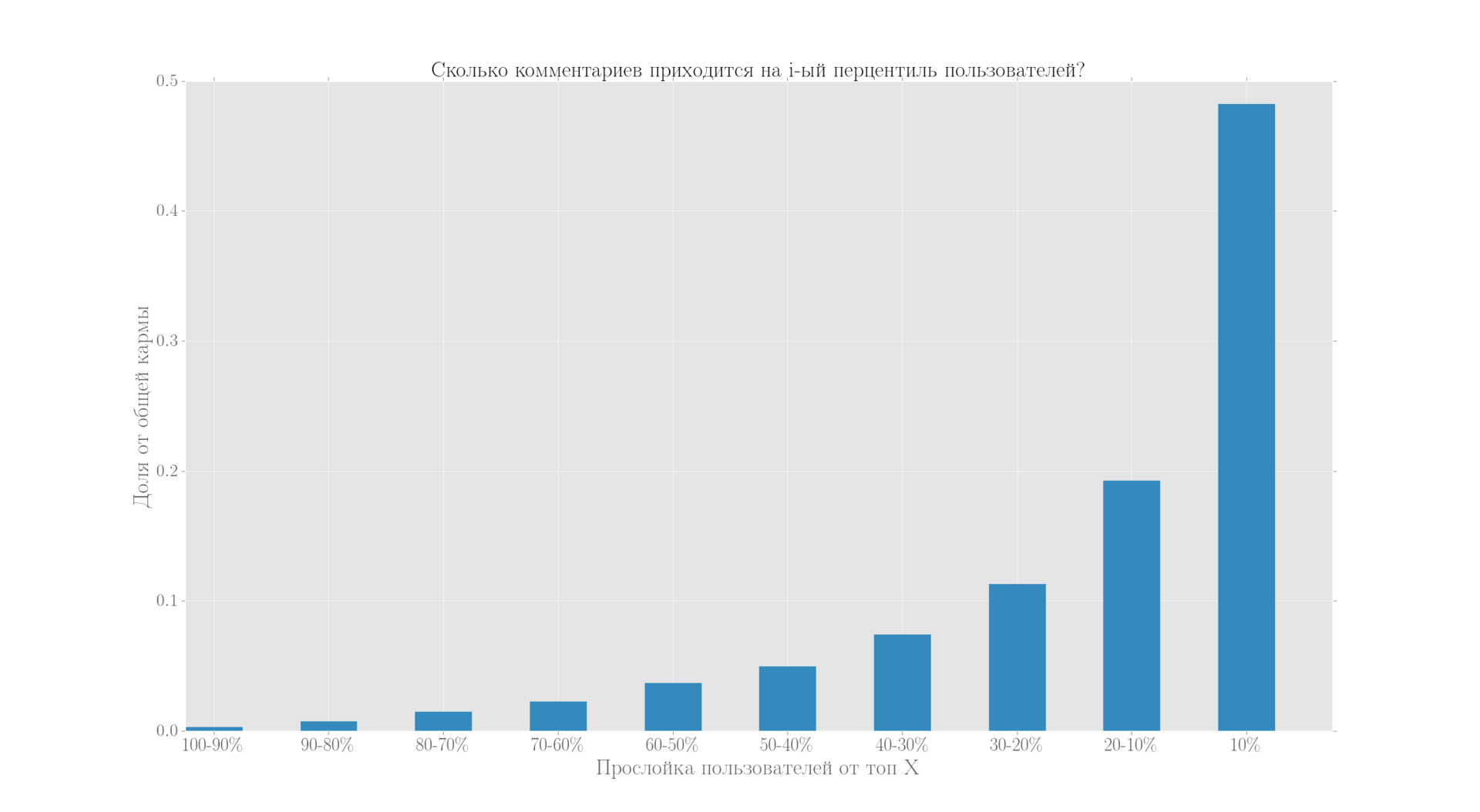
Мы видим, что структура сохраняется и для других показателей:
Распределение числа последователей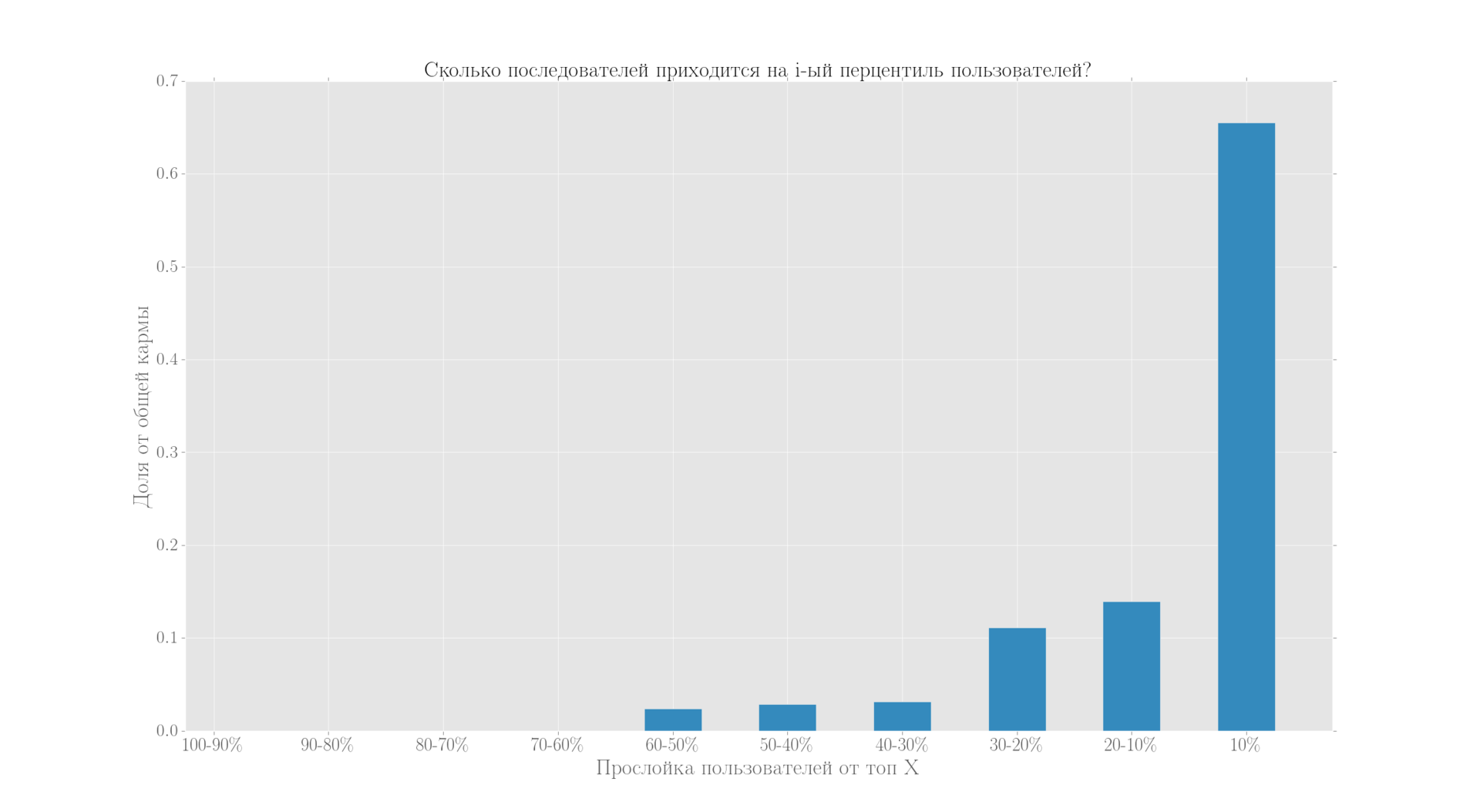
Распределение числа записей в избранном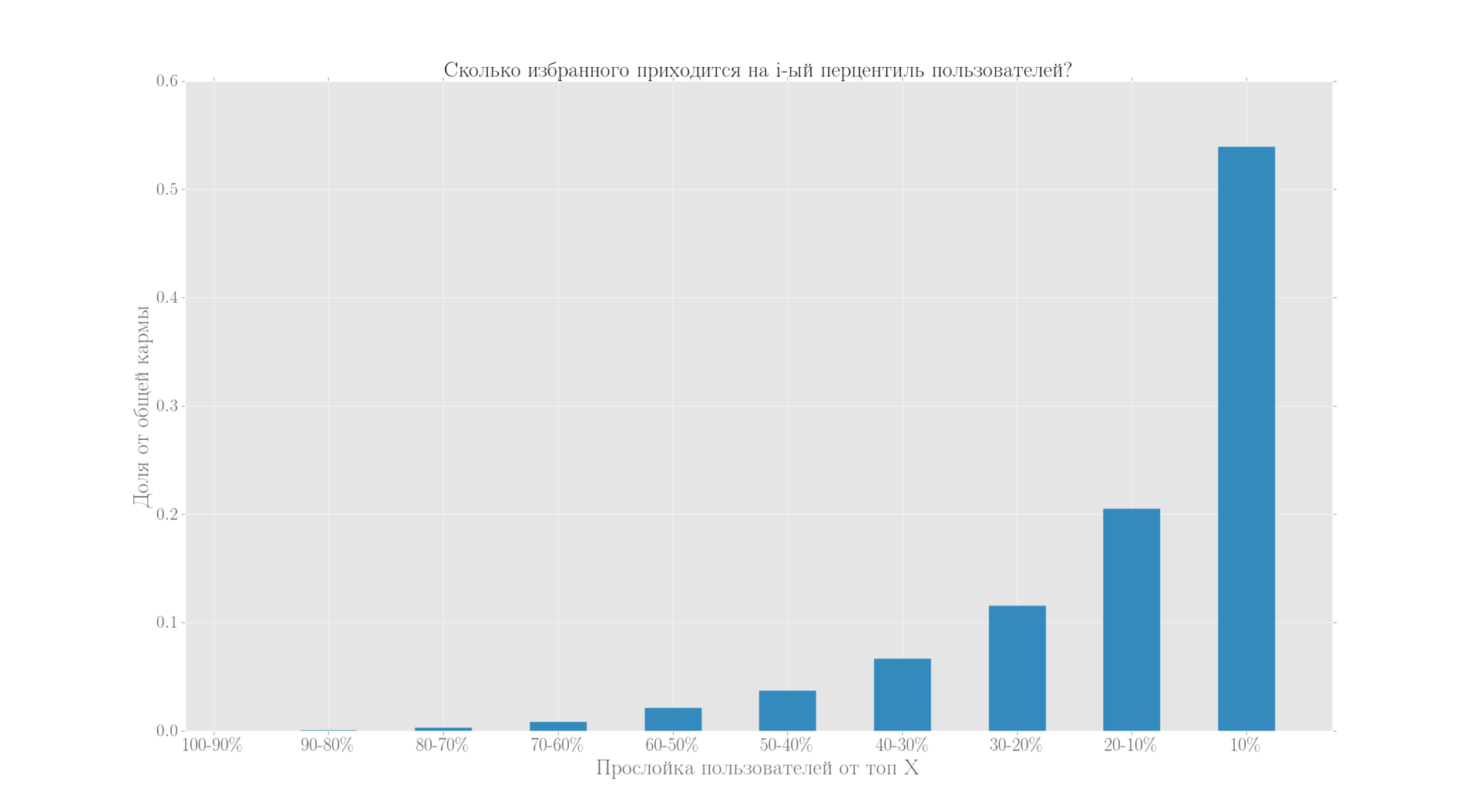
Распределение рейтинга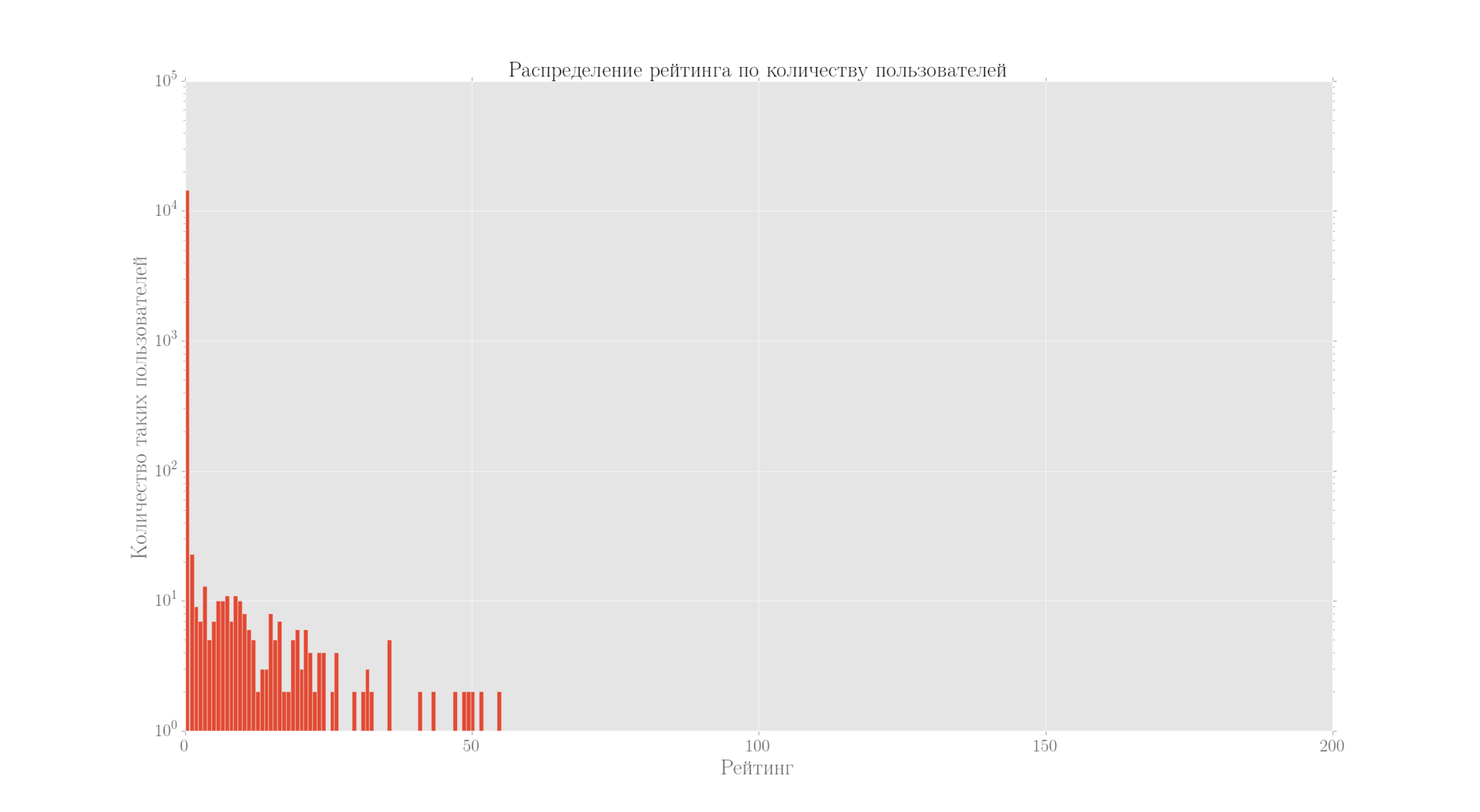
Положительная корреляция присутствует:
Зависимость между кармой и числом подписчиков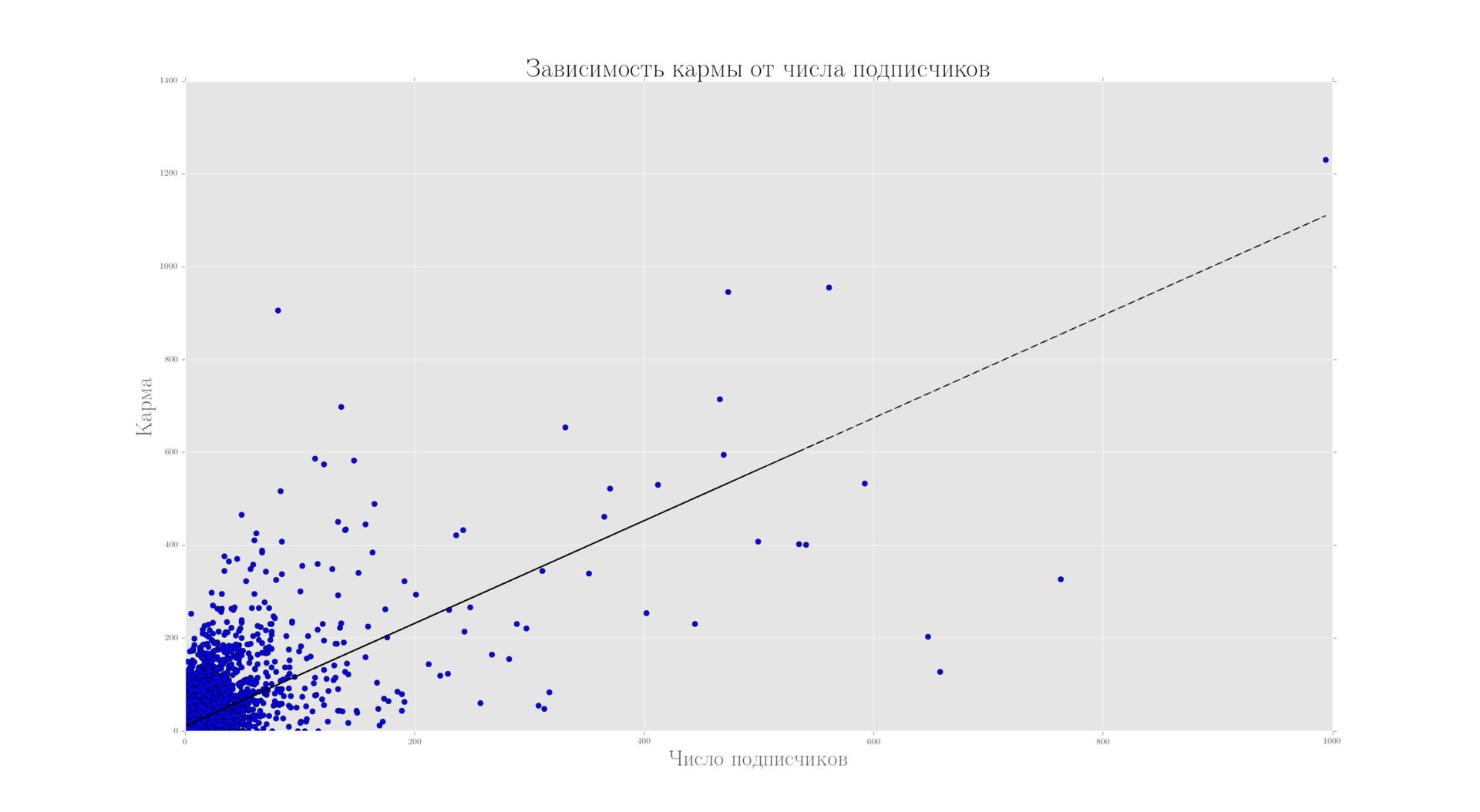
Интересный момент, что рейтинг больше не зависит от кармы
Зависимость между кармой и рейтингом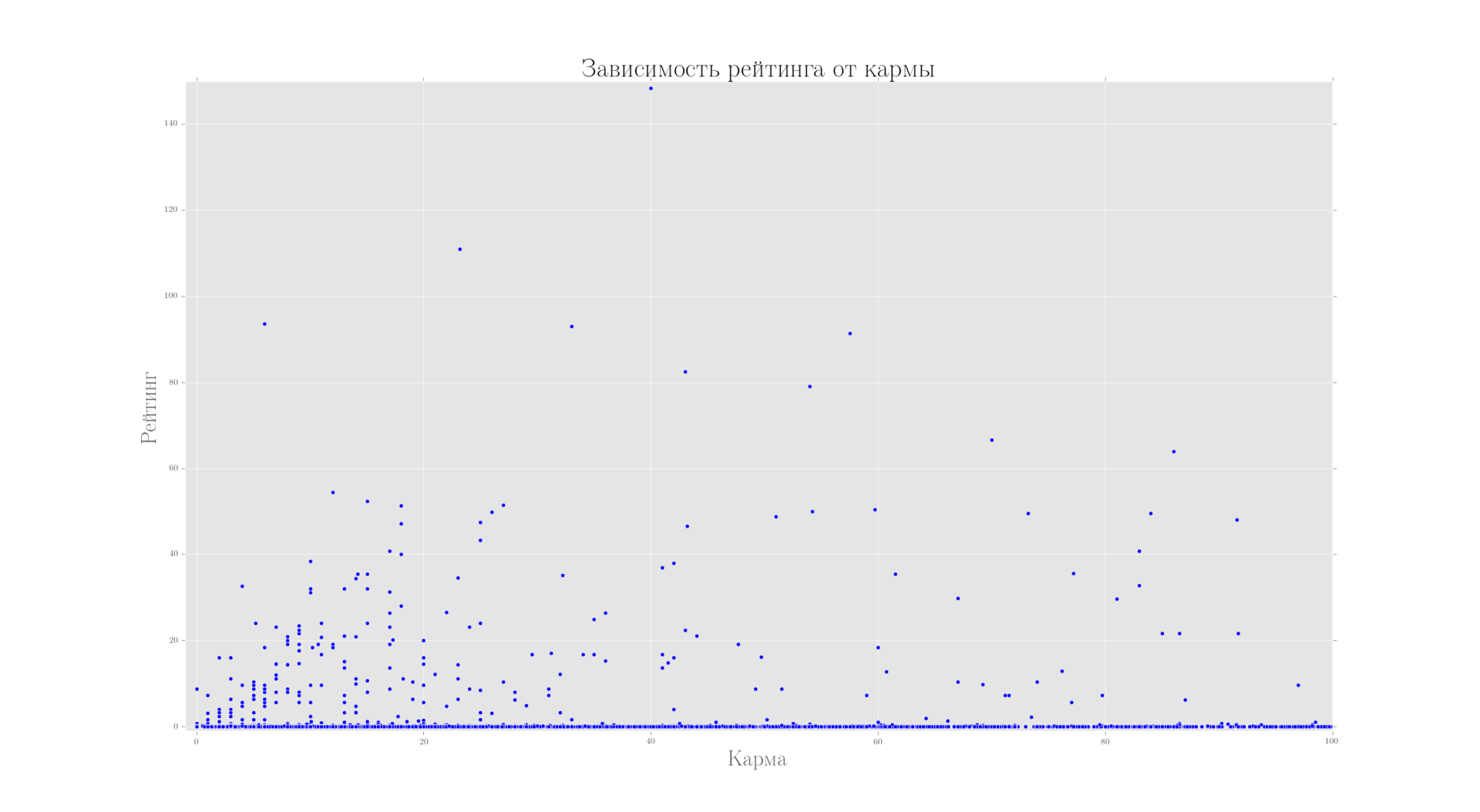
Так же на людей пишущих много комментариев подписываются не чаще, чем на любых других
Зависимость между количество подписчиков и написанных комментариев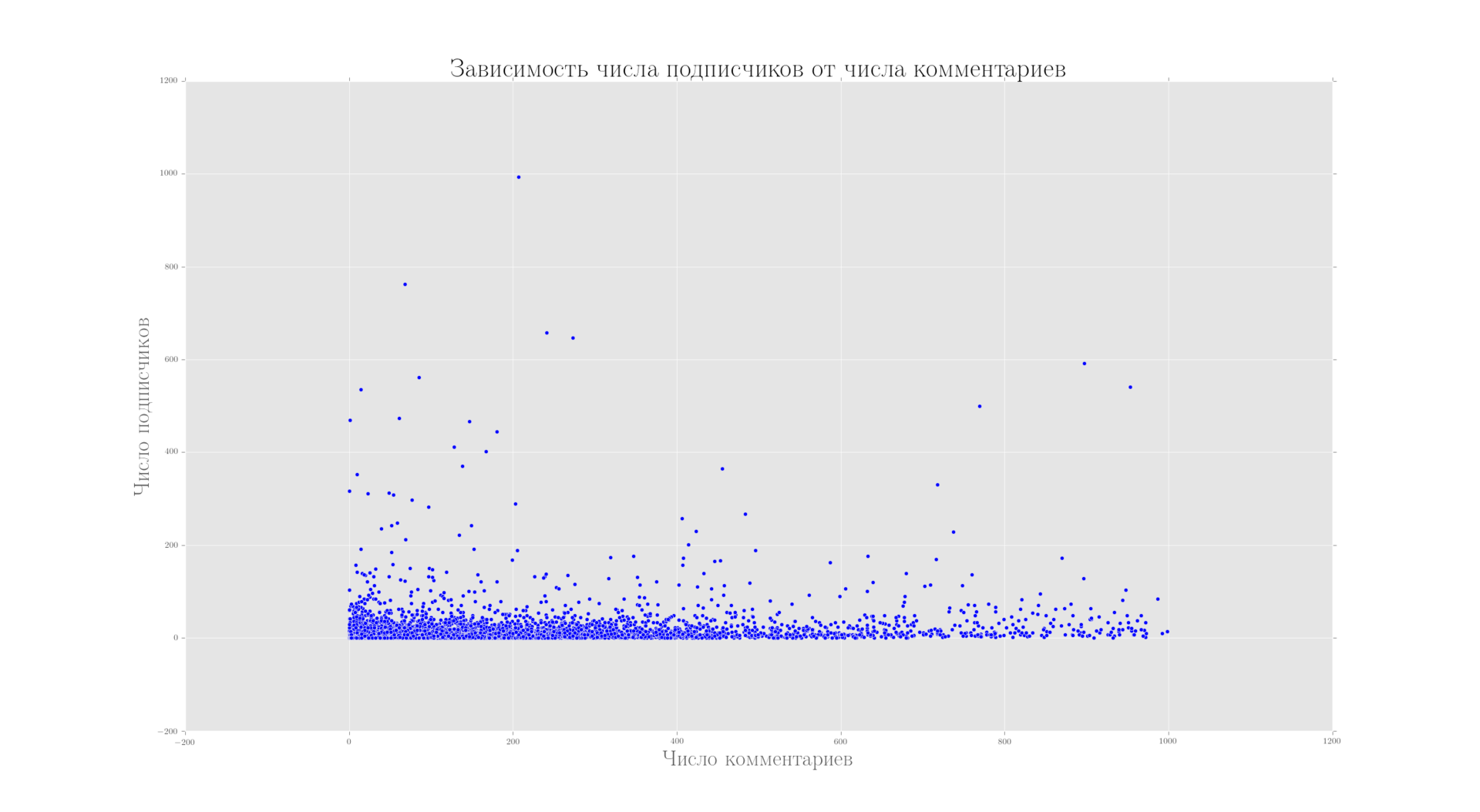
Предварительные выводы по первому вопросу
Во-первых, данные отвергают гипотезу о том, что подавляющее число (активных) пользователей не может голосовать. Во-вторых, показывает общую корреляцию между написанными статьями, кармой и числом подписчиков, что в целом можно охарактеризовать положительно. Однако существенный дисбаланс заметен невооруженным взглядом и нам предстоит проанализировать его влияние при ответе на вопрос Q3 о падении уровня активности.
Сообщества Хабра
Здесь мы попытаемся понять, какие группы существуют внутри Хабрахабра. В основе анализа лежат два следующих предположения:
- Подписываются на людей, которые пишут на тематику интересующую читателя
- Человек, с достаточным числом подписчиков, достаточно пишет на тему интересующую читателей
Как мы видим из предыдущего вопроса: у нас будет некоторая группа людей-хабов (в смысле здесь хаб, от английского hub, т.е. людей с большим числом подписчиков) и эти хабы должны естественно группироваться по общим подписчикам.
Построим граф следующим образом, от пользователя v1 есть дуга к v2, если v1 подписан на v2. Размер вершины пользователя в графе пропорционален числу входящих дуг.
Здесь доступен датасет с подписчиками в виде:
user:follower1,folllower2,.... Здесь доступен исходный граф (формат Gephi) на основе датасета выше, а здесь версия с размеченными и сгруппированными сообществами (также Gephi). Всего в графе (датасете) 45 тысяч пользователей и 110 тысяч дуг "подписки".
Различные сообщества подсвечены на основе метода Louvain Сommunity Detection. Здесь же приводится граф, вершины которого подсвечены в соответствии с их сообществом, так же обозначены дуги подписки.

Для удобства чтения удалим дуги и сгруппируем сообщества, подсветим всех пользователей с достаточным числом подписчиков (что как мы знаем из Q1 скоррелировано с числом статей). Теперь можно разобраться с тем, какие же темы стоят за каждой группой.

Попробовал проанализировать группы и вывести возможные метки сообществ. Было бы интересно провести более глубокий анализ сообществ и услышать мнения самих авторов из разных групп.
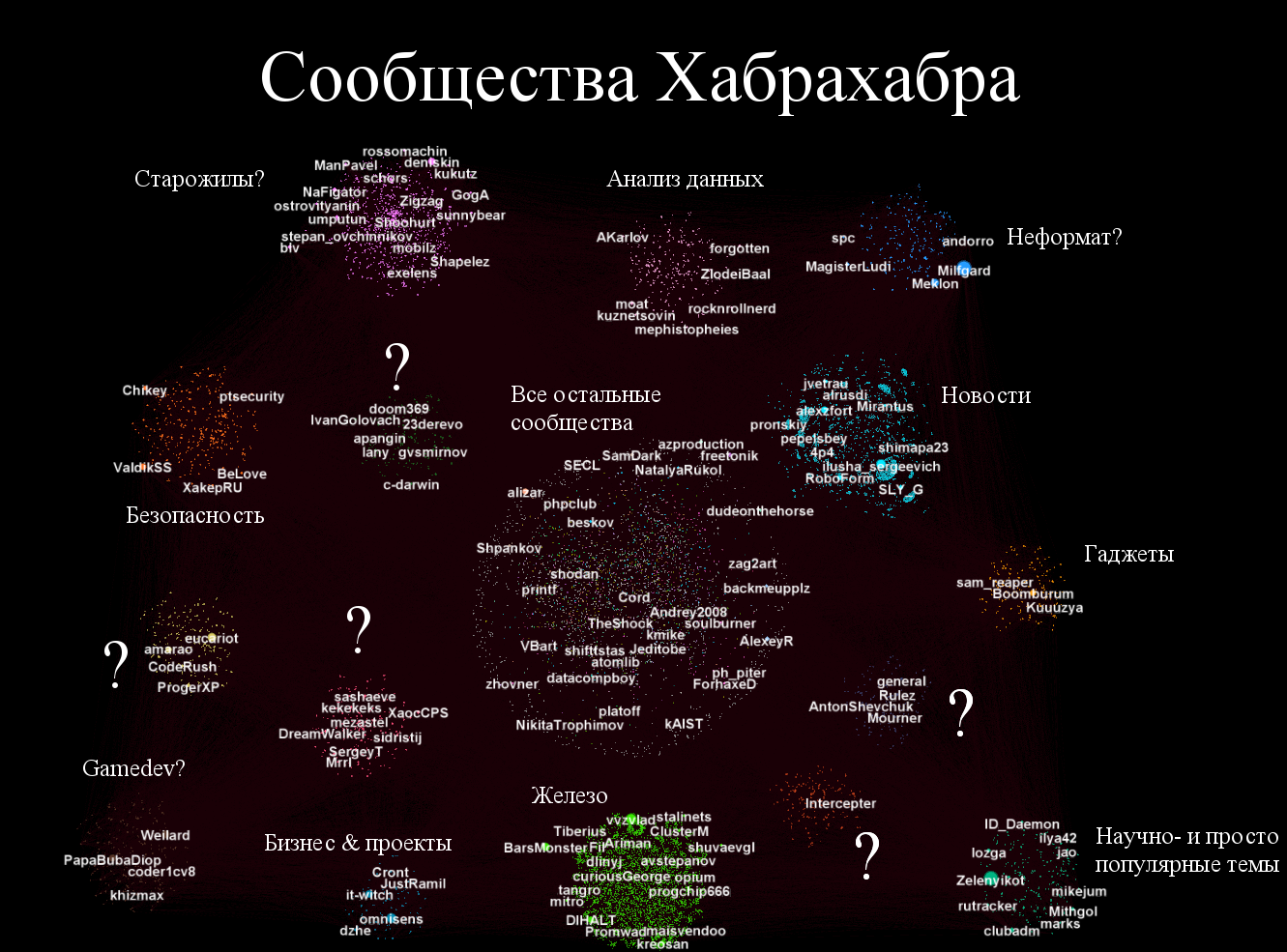
Предварительные выводы
Из анализа графа следует, что железо является самой большой группой среди подписчиков ~10% от общего числа. Именно поэтому убранные хабы о железе вызвали столь негативную реакцию, так как большая группа активных писателей и читателей (кто буквально подписан на обновления от "железячных" авторов) вдруг потеряла привычную площадку. Более того, как мы увидим, далее железные хабы переплетены с хабами программирования, что во многом создает единое окружение и для авторов и для читателей. (Надеюсь, что не открыл Америку с анализом сообществ и хабов тем, кто их иногда передвигает.)
Связность Хабов
Другой интересный метод измерения сегментации основан на следующем наблюдении, если статьи часто помещают в два хаба А и Б, значит А и Б объединены какой-то общей тематикой или вообще говоря схожи. Мы можем взять множество статей, которое поместили в хаб А и множество, которое поместили в Б и рассчитать степень их схожести с помощью коэффициента Жаккара
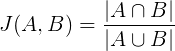
Таким образом мы можем получить граф, вершинами которого являются Хабы, а дуги — это степень схожести по Жаккару. Далее применим тот же метод, что и использовался ранее (Louvain Сommunity Detection).
Здесь доступны исходные данные, а здесь граф с сообществами
Граф вместе с дугами; вершины соответствует цветам сообществ, также мы видим отдельно стоящую группу "переехавших" хабов. Размер вершины — это общий вес входящих в неё ребер (граф ненаправленный)
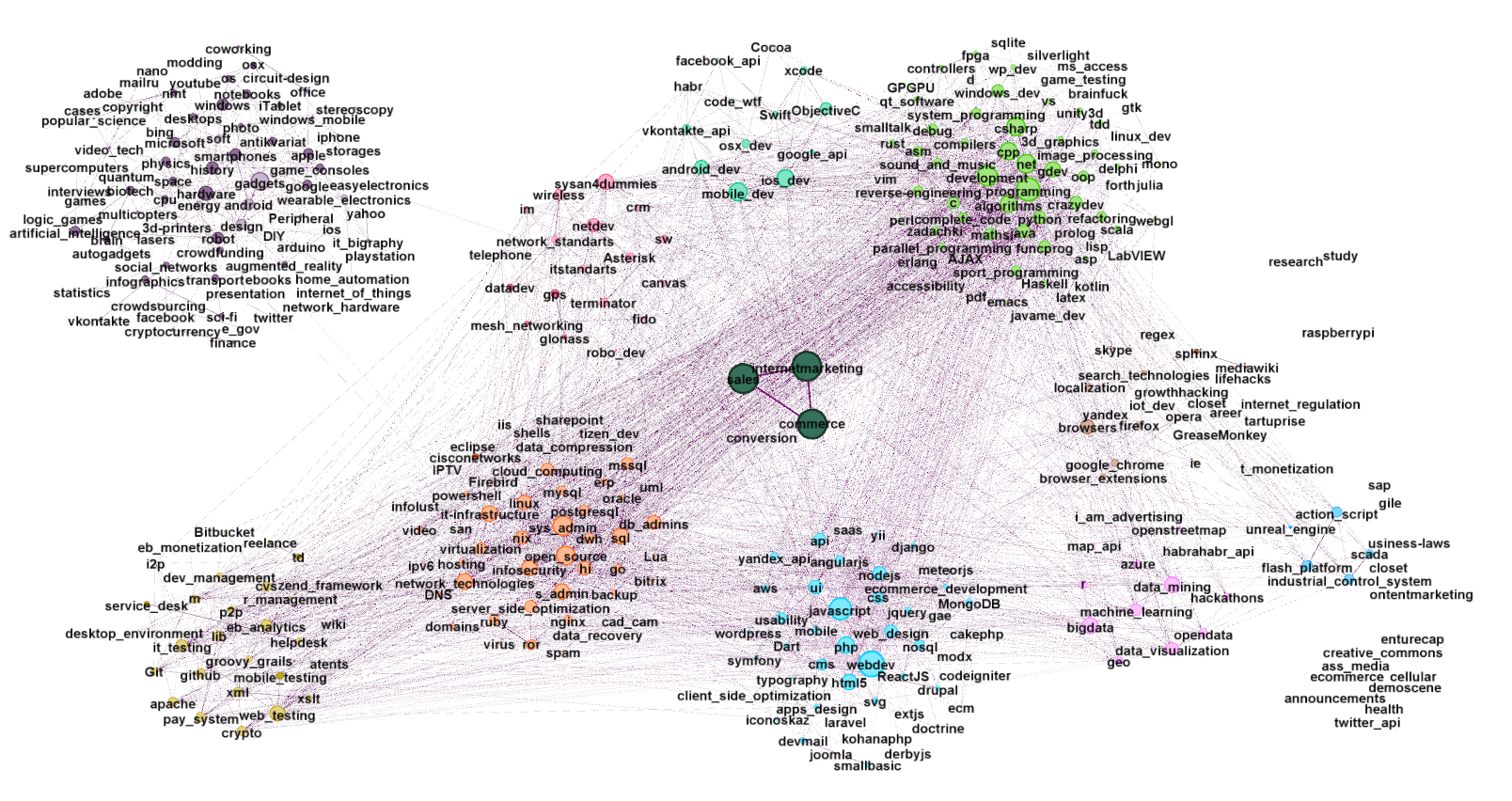
(Интесивность ребра — вес)
Более читаемая версия без рёбер. На ней мы видим порядка 10ти крупных сообществ Хабов, причем например железячный Хаб controllers (Программирование микроконтроллеров), плотно сидит в центре "группы программировния"
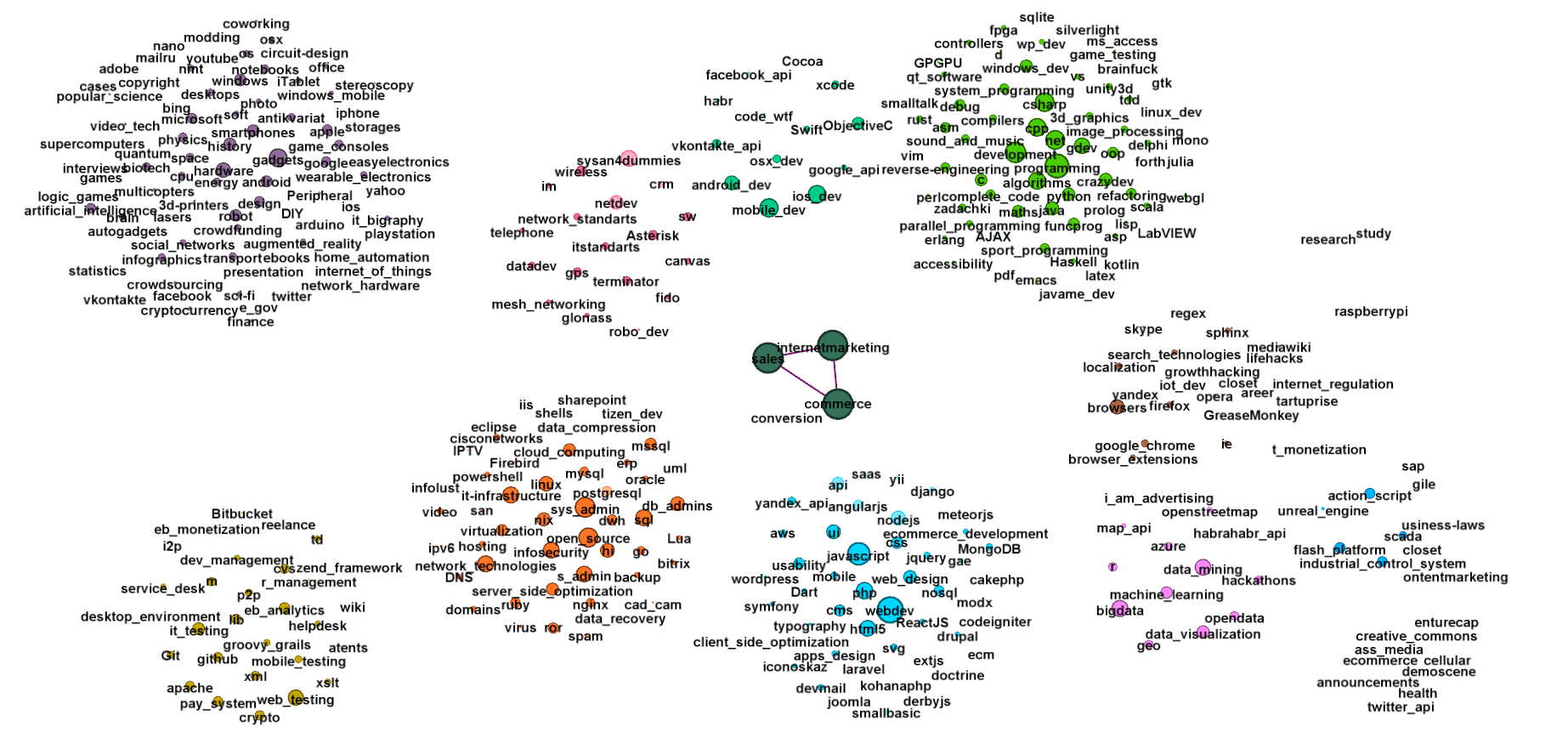
Из графа выше видно, что если мы двинем железные хабы, то заденем и связанные хабы программирования, заодно зацепив самую большую группу активных читателей. Также из обоих графов выше мы видим порядка 15 крупных сообществ читателей по отношению "подписан" и большую кучу различных микро-сообществ, а также порядка 10 больших групп тесно связанных хабов.
Активность и Выводы
Общие статистика читателей и писателей
* Active -- кто оставил хотя бы один комментарий или написал одну статью за последние два года ~25к
* С неотрицательной кармой\рейтингом и не переведен в режим read only ~ 14к
* Общее количество подписчиков у активных пользователей 44k
* Общее число подписок: 104k
* Пользователи с хотя бы одним подписчиком: 11.5k
* Диаметр графа: 4.7
* Плотность ~0
* Количество микросообществ: 528То есть мы видим, что действительно существенная часть аудитории не участвует в обсуждении по каким-то причинам.
По различным данным (сравните июль 2014 и сентябрь 2015 на графиках ниже) просели не только просмотры и голоса, но и статьи перестали находить отклик. Как будто бы дискуссия и обсуждение пропали. Возможно это связано с а) дисбалансом, как мы видим из Q1, б) с нарушением существовавшей экосистемы, как мы видим из Q2.
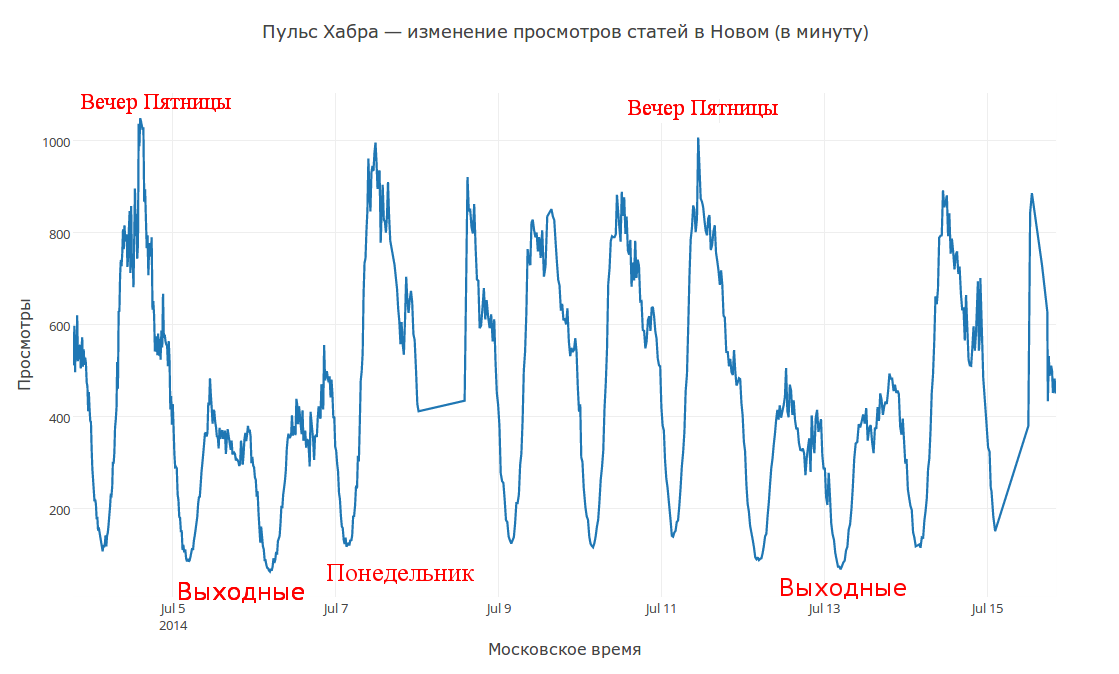
Возродить дискуссию, запустив новый тип аккаунтов, задумка безусловно интересная, но возможно стоит обратить внимание на структуру разделения сайтов с учетом внутренних групп и специфики ресурса. Чтобы не быть голословным, обратите внимание на формат статей Мосигры, они безусловно вписываются в формат Хабра, однако практически все хабы, связанные с их статьями, были перемещены.