
Однажды, мне стало интересно: насколько статьи на Хабре связаны между собой? Поэтому сегодня мы займемся исследованием связности статей, и конечно не только посчитаем численные метрики, но и увидим картину целиком.
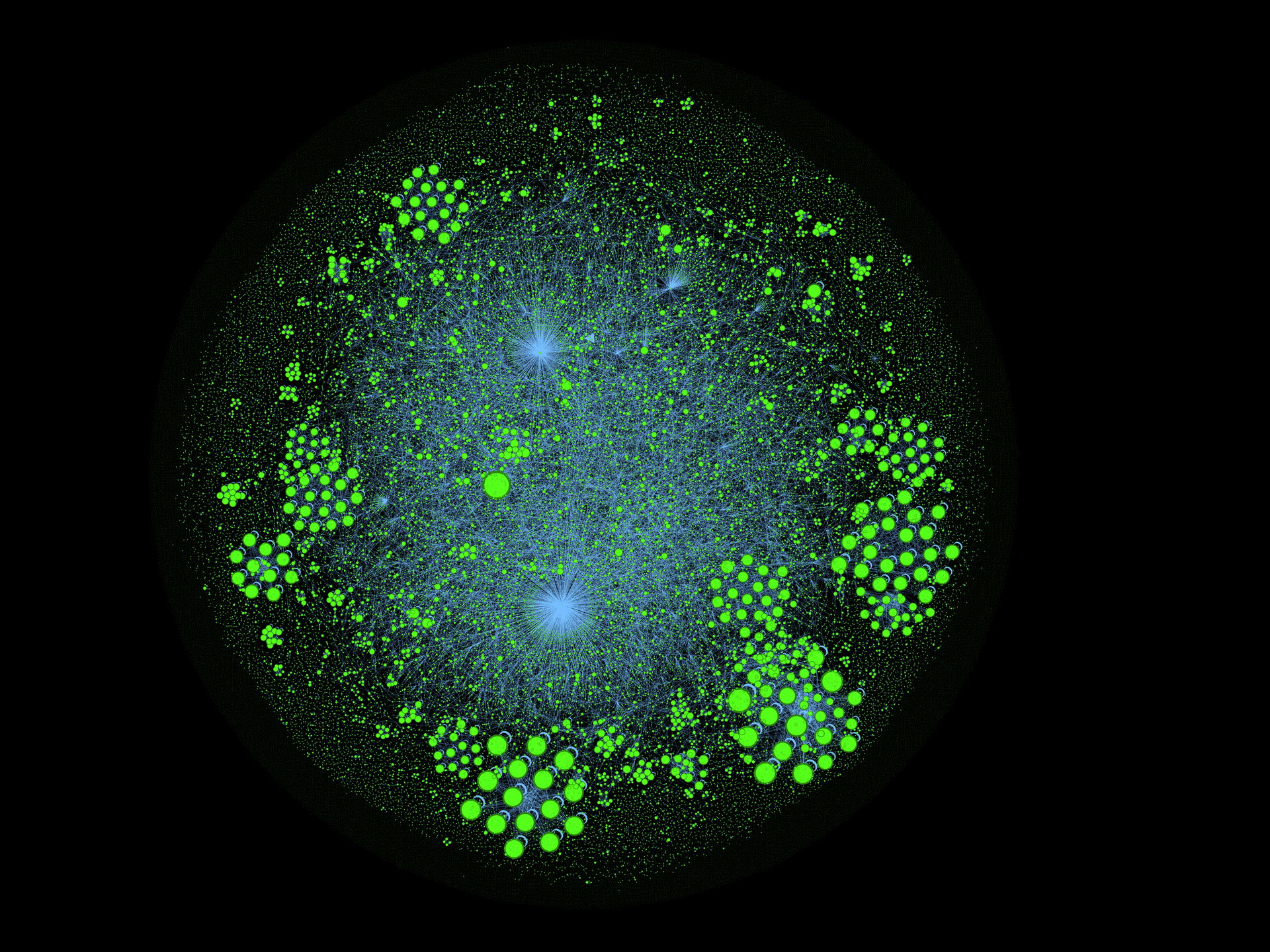
(это не просто картинка для привлечения внимания, а граф цитирования статей внутри Хабрахабра, где размер вершин определяется числом входящих рёбер, i.e., "количеством цитат внутри Хабра")
Началось всё с того, что в комментариях к статье про Хабра-граф и карму Tiberius и Loriowar озвучили идею, фактически витающую в воздухе: а почему бы не взглянуть на граф цитирования статьёй внутри самого Хабра?
Вы спрашивали? Мы отвечаем. Для того чтобы рассказ не был размахиванием рук, конкретизируем разбираемые вопросы:
Q1: Как выглядит граф цитирования Хабрахабра и какие в нём хабы (hubs and authorities)?
Q2: Насколько связным является сообщество (граф цитирования) и какие в нём кластеры?
- Q3: Как изменится граф, если из него убрать самоцитирование?
Под катом трафик. Все картинки кликабельны.
Краткие пояснения по терминологии:
Хаб — это вершина с большим количеством исходящих ссылок, а "авторитетный источник" (authority) — вершина с большим количеством входящих ссылок. Под связностью мы будем понимать среднее число рёбер приходящихся на вершину (входящую или выходящую). Самоцитирование — это ребро, у которого обе вершины с одинаковым автором.
Граф цитируемости статей (внутри Хабра)
Возьмем граф из начала статьи и внимательно посмотрим на каждый из кластеров и крупные вершины. Мне удалось выделить и пометить несколько интересных "сообществ" статей.
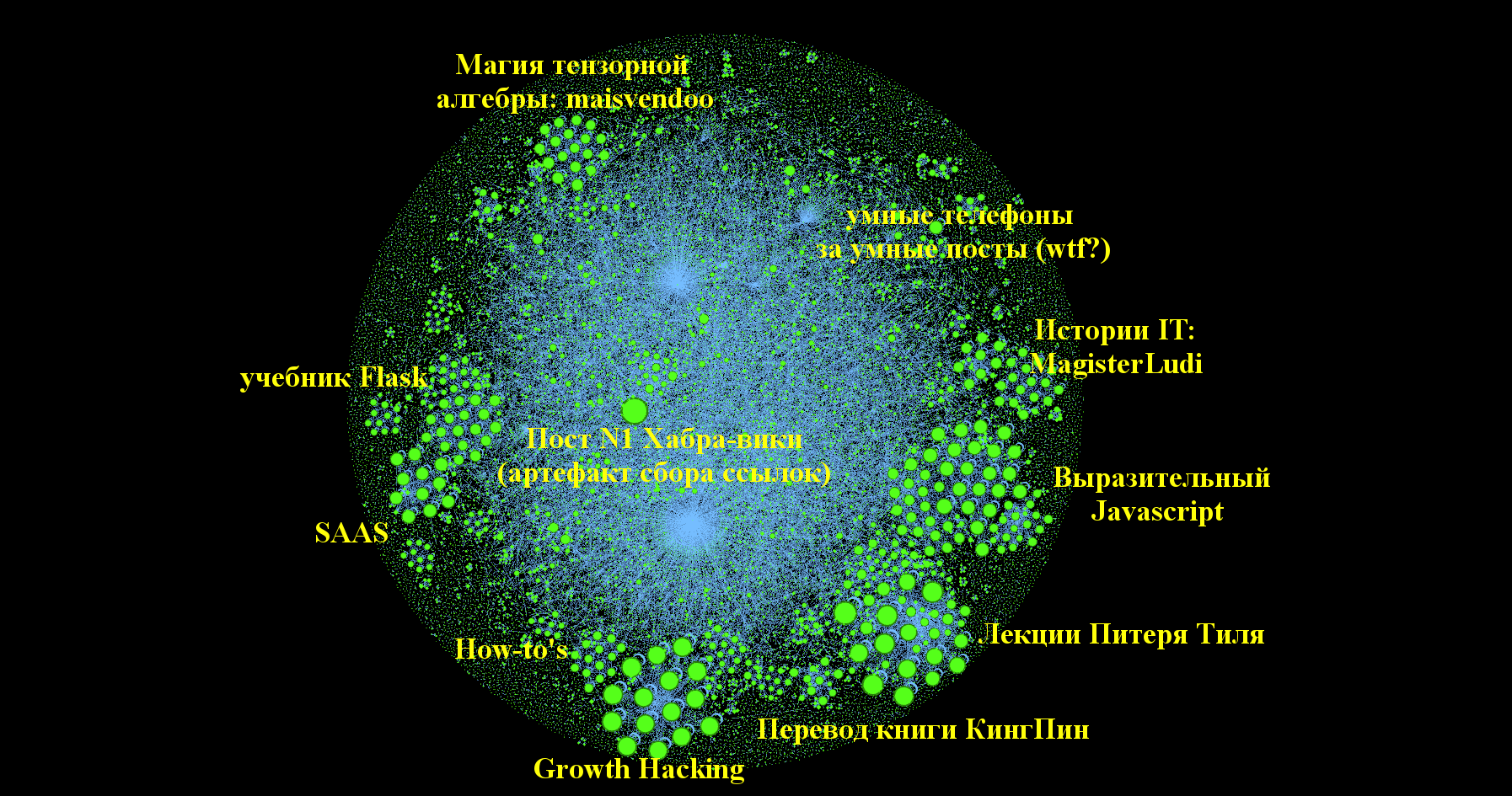
К сожалению, пост номер один: habrahabr.ru/post/1 получил много входящих по чисто техническим причинам (несовершенство парсера), на самом деле на него никто не ссылался.
Остальные кластеры довольно интересны, например есть целая группа историй IT в духе: Грэйс «бабуля COBOL» Хоппер или целый ряд статей по Тензорной Алгебре. Всего у нас 95 тысяч вершин и порядка 50 тысяч рёбер. Связность очень низкая: на одну вершину в среднем приходится порядка одного ребра и примерно 60% всех точек не связаны ни с одной другой статьёй на Хабре — см. большое плотное облако вокруг графа на самой последней картинке внизу.
Граф без самоцитирования
Как мы видим картинка существенно поменялась и ряд кластеров пропал. В целом это отражает классический сценарий, когда серия статей одного автора имеет высокую связность за счет ссылок на всю серию в каждой статье.

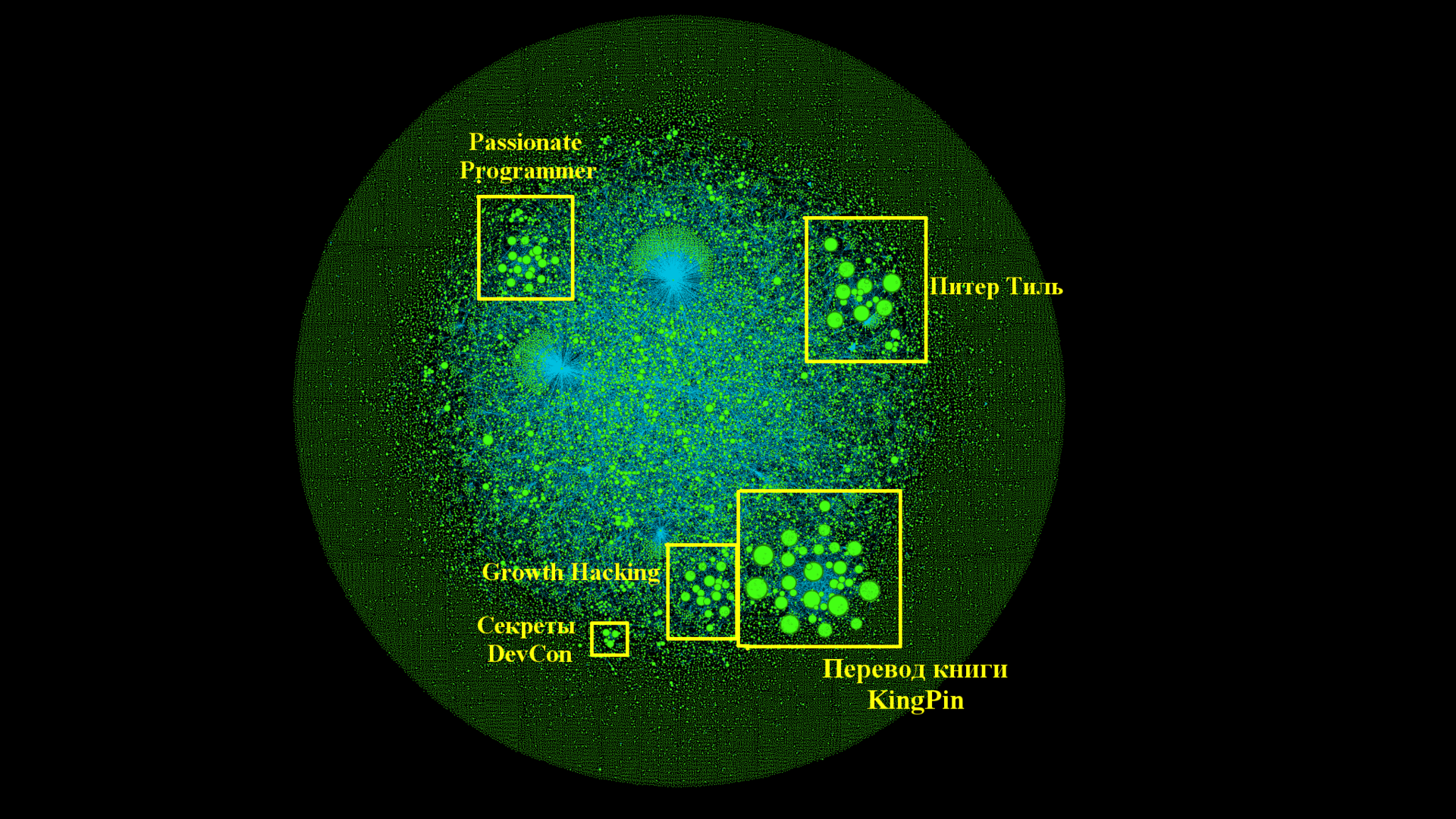
Однако, ряд кластеров всё-таки выжил. Посмотрим на них повнимательнее.
"Народные" кластеры
Три самых больших и интересных кластера, которые выжили — это перевод книги Passionate Programmer, KingPin и лекции Питера Тиля. Отличная командная работа, в том числе и по документированию серии! Это очень интересный и позитивный результат, он говорит о том, что сообщество может скоординировано проводить достаточно большую и сложную работу, а так же поддерживать ссылочную целостность — найдя одну статью, всегда можно извлечь и найти всю серию.
Карта хабов ака граф исходящих рёбер
Мы уже посмотрели на "авторитетные источники", где вес вершины определялся входящими ребрами, теперь мы можем взглянуть на вершины с большим числом исходящих рёбер. И определить — какие же в сети присутствуют хабы.

Рассмотрим степень влияния каждого из хабов, подсветив их рёбра.

Теперь внимательно посмотрим, что же это за хабы?
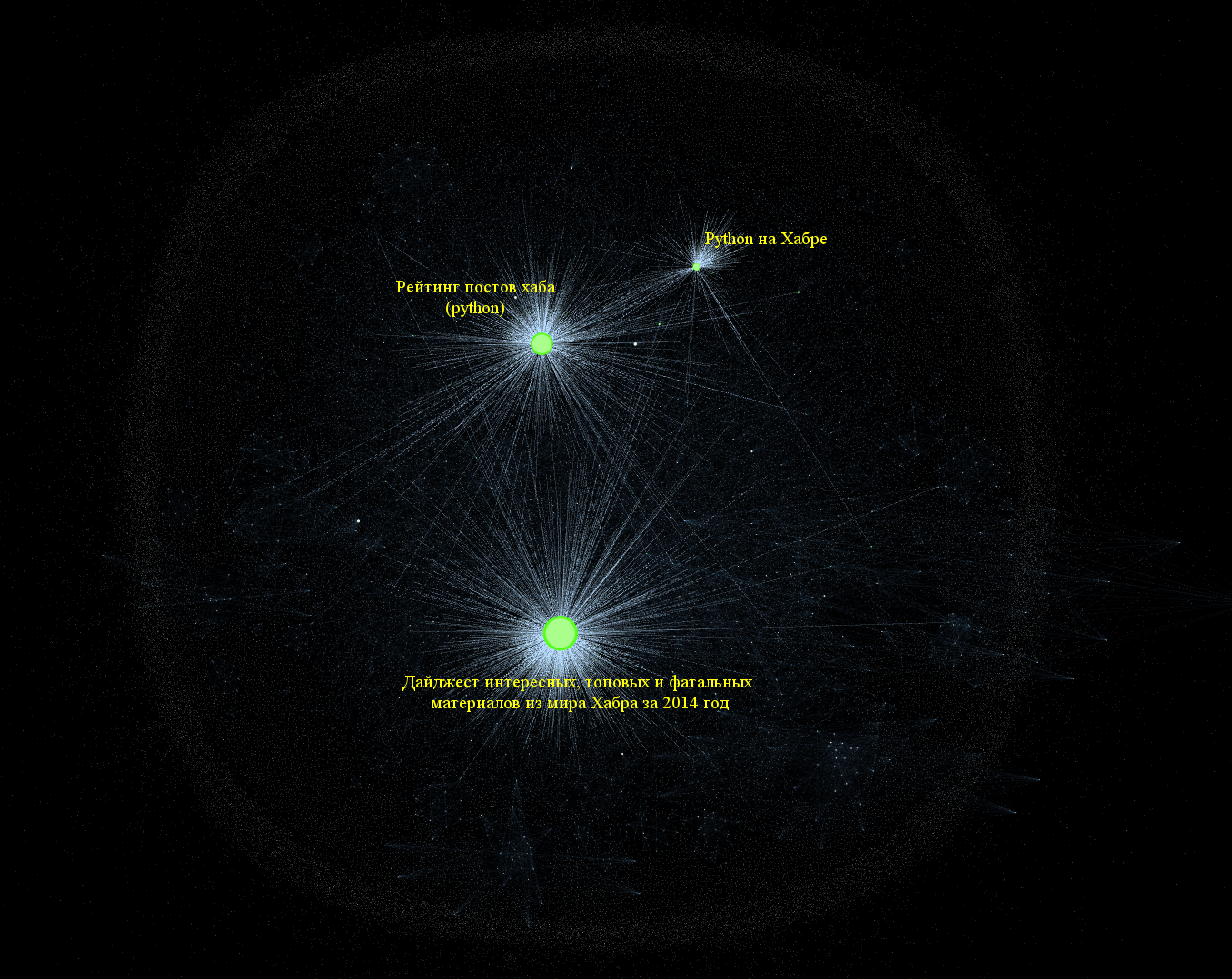
Как мы видим речь в основном идёт о постах с подборками интересных материалов на самом Хабре. Например, топом самого интересного или материалами по питону. Что безусловно логично — самым большим числом внешних ссылок обладают каталоги, хранящие исходящие ссылки (где же этот мета-обзор всех обзоров статей Хабра?).
Также этот граф подсказывает нам о большой любви сообщества к Python (и, надо сказать, небезосновательно).
Лидеры по числу входящих\исходящих цитат
Рассмотрим остальные посты (25+ ссылок) без учёта входящих и исходящих (т.е. считаем граф неориентированным).
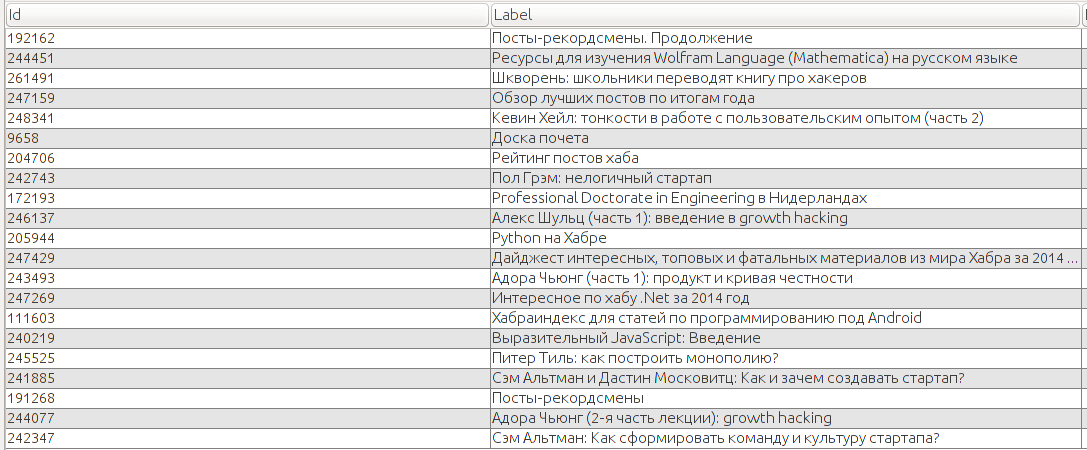
Все статьи в списке можно условно разделить на каталоги (интересные и полезные ссылки по теме Х) и части серии. Если внимательно приглядеться, то первые — это в точности наши хабы, а вторые — authorities.
То есть статей, которые бы просто все активно цитировали на Хабре нет (по крайней мере цитируют их тут реже, чем статьи серий).
Рейтинг цитирования авторов
Также интересно собрать число цитат в статьях, приходящихся на автора. При подсчете и составлении рейтинга не учитывалось самоцитирование (по этой теме будет отдельный рейтинг).
Первое место оказалось довольно предсказуемым — причём с бооольшим отрывом.
1 alizar,743
2 marks,261
3 ilya42,202
4 MagisterLudi,202
5 lapyk,167
6 XaocCPS,144
7 SLY_G,131
8 frii_fond,127
9 grokru,124
10 dmitrykabanov,118
11 kichik,115
12 saul,101
13 itinvest,99
14 jeston,97
15 ValdikSS,95
16 Mithgol,83
17 andorro,76
18 UiDesignGroup,72
19 IT_invest,71
20 amarao,70
21 p-y-t-h-o-n,69
22 esetnod32,66
23 aleksandrit,66
24 azproduction,64
25 nokiaman,64
26 wiygn,63
27 NCNecros,62
28 FSBook,61
29 Boomburum,61
Рейтинг самоцитирования
Данный рейтинг интересен прежде всего тем, что позволяет понять насколько сравнимо число цитат остальных авторов с собственным. В среднем мы видим, что число цитирований своих статей превосходит число обычных цитат. Также это говорит о существенном вкладе в связность графа цитирования личных статей.
Можно считать это личным вкладом в связность статей Хабра (автор данной статьи даже занял в этом рейтинге 26-ое (!) место).
1 itinvest,541
2 SLY_G,526
3 MagisterLudi,469
4 1cloud,424
5 esetnod32,415
6 ptsecurity,410
7 maisvendoo,373
8 zag2art,365
9 ilya42,337
10 EvseyFaydo,302
11 lol_wat,270
12 frii_fond,264
13 1eqinfinity,258
14 alexzfort,229
15 XaocCPS,226
16 andorro,226
17 alizar,222
18 khizmax,218
19 Boomburum,196
20 Mithgol,188
21 Milfgard,174
22 eagleson,173
23 vedenin1980,168
24 OsipovRoman,161
25 CooperMaster,159
26 varagian,155
27 bbk,154
28 Irina_Ua,153
29 dmitrykabanov,133
30 Unrul,131
Воспроизводимость и открытые данные
Твёрдно уверен, что любой результат исследований должен быть воспроизводим, повторяем, а также доступен читателю. Поэтому все исходные данные прилагаются к статье.
Ссылки: граф цитирования Хабрахабра и граф без самоцитирования (Gephi), а также дапм всех статей Хабрахабра доступен здесь (собрано в 20-х числах мая 2016-го), как и большое число других вкусных и интересных данных по Хабру, специально собранных и очищенных для использования (может неплохо подойти, если пишите диплом или нужны реальные текстовые или (полу-)структурированные данные).
Выводы
- Q1: Хабы — подборки интересностей на Хабре, авторитетные источники — серии статей, граф похож на облачко с несколькими сообществами и огромным поясом статей вокруг без единой ссылки (порядка 60% всех вершин)
- Q2: Граф сильно разреженный — порядка одного ребра на вершину, встречаются достаточно связные кластеры — например "Магия тензорной алгебры", поддерживающие связность за счет того, что каждая статья хранит каталог всех ссылок серии
- Q3: Без самоцитирования практически все кластеры пропадают, но остаётся небольшой ряд "народных" кластеров, например перевод книги KingPin, показывающий настоящую командную работу сообщества.
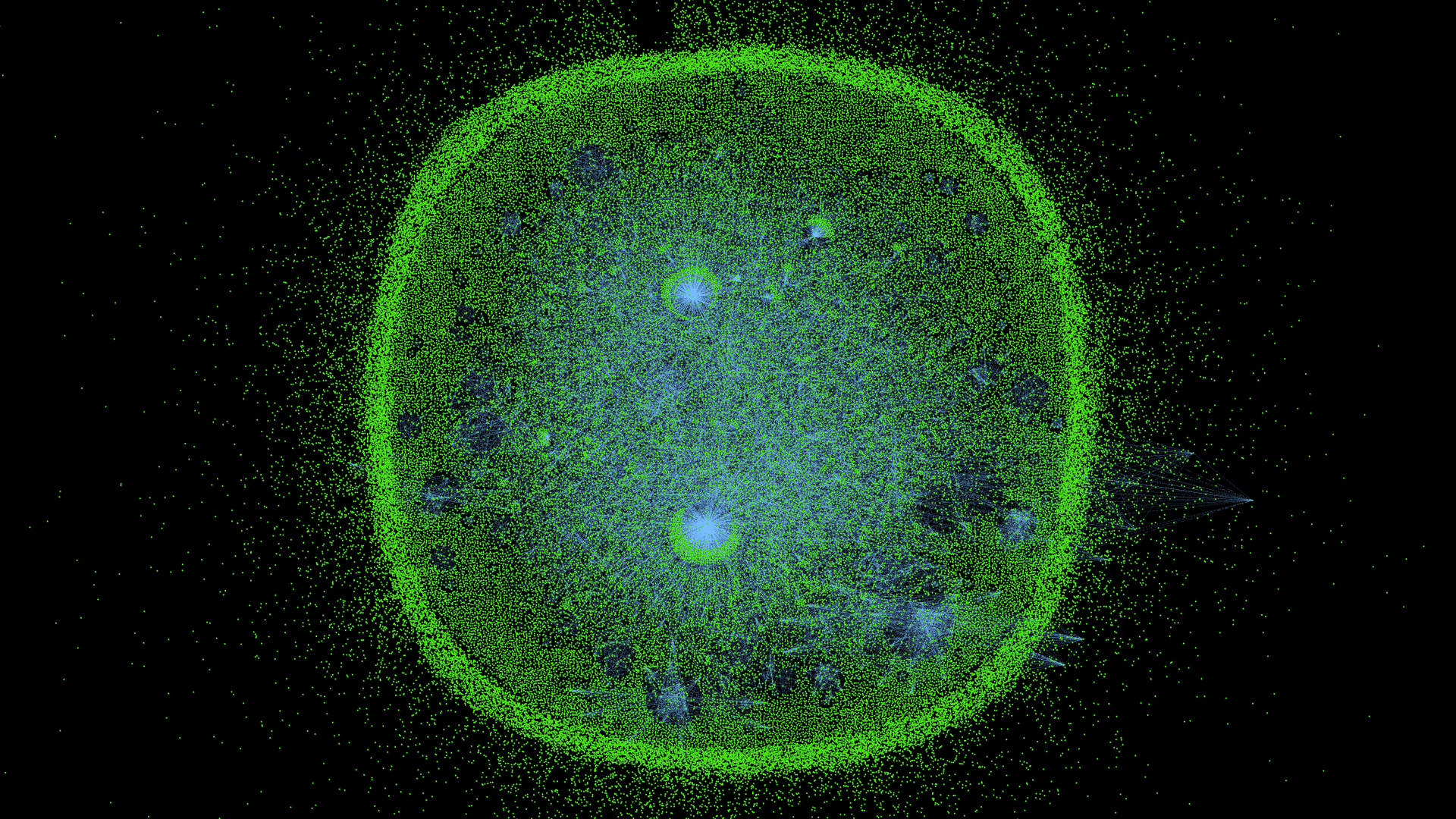
Вместо заключения
Из любви к искусству: граф цитирования без учета рёбер в качестве веса вершин
Комментарии (42)

Loriowar
13.06.2016 11:10+3Замечательно, спасибо. Не думал что предложение так быстро материализуется.


Meklon
13.06.2016 11:42+1Очень круто. А чем анализ делался? Библиотеки на Python есть для подобного?

varagian
13.06.2016 12:27+1Все трансформации шли посредством requests (запросы к Хабру) + BeautifulSoup4 (парсим HTML) + pandas (работаем с табличками и подсчет рейтингов). Графы анализировались и визуализировались в Gephi.
Meklon
13.06.2016 13:57+1Все-таки надо освоить Pandas. А то я какой-то ужас с гетерогенными массивами в городу, чтобы таблицы получить)
varagian
13.06.2016 17:07Еще в копилку numpy, scipy, matplotlib и бонусом маленький модуль tqdm
Meklon
13.06.2016 17:37+1Оооо… progress bar! Я счастлив. Приходилось извращаться) Как в этом проекте, например:
https://github.com/meklon/DAB_analyzer
Ermako
14.06.2016 11:54Советую вот этот пост почитать.
habrahabr.ru/post/276725Meklon
14.06.2016 14:51+1Спасибо, красиво, но у меня не блокнот, а более или менее полноценная программа консольная. Универсальность, да. Сейчас очень симпатично выглядит.

Meklon
13.06.2016 14:30+1Gephi — полный восторг. Просто кластерный анализ без графов тоже может, насколько я понимаю?

Stas911
13.06.2016 16:13+1Из pandas в gephi есть готовый экспорт?
varagian
13.06.2016 17:00Pandas всё же сделан для обработки неструктурированных данных (например, табличных с i.d.d.), а Gephi для визуализации структурированных (конкретнее для графов).
Для работы с графами в python есть NetworkX и в нём есть экспорт в Gephi — см. write_gefx.
Еще Gephi умееть работать с простыми графами в XML, поэтому иногда проще сгенерить такую XML-ку обычными print — например, если граф достаточно большой и не хочется его материализовать в памяти python-интерпретатора. Для примера, кусочек такой XML-ки ниже:
XML-представление графа в Gephi<?xml version='1.0' encoding='utf-8'?> <gexf version="1.1" xmlns="http://www.gexf.net/1.1draft" xmlns:viz="http://www.gexf.net/1.1draft/viz" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.w3.org/2001/XMLSchema-instance"> <graph defaultedgetype="undirected" mode="static"> <nodes> <node id="presentation" label="presentation" /> <node id="rust" label="rust" /> <node id="css" label="css" /> ... </nodes> <edges> <edge id="0" source="presentation" target="soft" weight="0.08333333333333333" /> <edge id="1" source="presentation" target="android" weight="0.01639344262295082" /> <edge id="2" source="rust" target="virus" weight="0.01694915254237288" /> .... </edges> </graph> </gexf>Stas911
13.06.2016 23:06Понятно, спасибо. А что вы имели ввиду, когда писали, что pandas для неструктурированных, если там все на DataFrames которые суть те же таблицы? Или я не понял что-то?
varagian
13.06.2016 23:21Неструктурированные данные — это каждая строка — точка, а каждая колонка — это переменная, причем на точках нет структуры т.е. про точки говорят, что они i.i.d. — независимы и одинаково распределены (вот переход тут немного упростил конечно).
В случае с графом между точками есть отношение — edge(X,Y), то есть точки уже не независимы, а связаны между собой.
DataFrames задают таблицы, в которых подразумевается, что каждая строка — это точка и когда мы строим, ну например, линейную регрессию Xw = y мы в явном виде подразумеваем, что точки из X в R^n независимы и у X в точности n колонок и каждая колонка — это переменная, а каждая строка — это точка в R^n.
Конечно, при желании можно таблицами в pandas задавать структурированные данные (как графы, например) и самому ввести все нужные операции, но встроенных методов работы со структурированными данными в духе add_edge там нет.
Ermako
14.06.2016 11:58+1А не смотрели в сторону graph_tool? Там есть готовые алгоритмы кластеризации и много разной визуализации.
varagian
14.06.2016 12:40Неплохо, нужно будет попробовать в последующем анализе. Только с ссылкой какие-то проблемы — видимо без "d" на конце: https://graph-tool.skewed.de

Amareis
13.06.2016 12:37+5If it exists, there is
pornPython library of it. No exceptions.Meklon
13.06.2016 13:56+2Не так давно на Python подсел и именно это очень радует)
varagian
13.06.2016 17:01+1Однажды попробовав Python, уже не могу переключиться назад :-)
Meklon
13.06.2016 17:34+1Печалит только то, что у меня часто отдельная программа одноразовая. Чисто посчитать и вывести конкретные данные.
varagian
13.06.2016 17:46+1На самом деле скриптовые языки для этого и нужны — "склеить вот это вот всё". У меня тоже самое — нужно для какой-то статьи поставить эксперименты: качаем, форматируем, трансформируем, склеиваем, запускаем, меряем и тадаам — результаты и графики.
Хотя мы сейчас довольно интересное демо пилим, где основные вычисления идут на python, а react даёт пользователю возможность поиграть через браузер.
Meklon
13.06.2016 18:09+1У меня к этому еще добавляются датчики и железяки слепленные в одном экземпляре на жвачке и изоленте. Причём иногда как добавочный модуль к оборудованию за пару миллионов)

LoadRunner
14.06.2016 10:20+1Я так понимаю, учитывалось цитирование только в статьях?
Или комментарии тоже учитывались? Было бы интересно посмотреть на такой граф тоже.varagian
14.06.2016 10:41Только статьи.
Loriowar
14.06.2016 21:44+1Коли разок "выстрелило", то попробую ещё раз предложить идею анализа, поддержав и развив мысль LoadRunner: круто было бы сделать аналогичные исследования, но для комментов. Лично мне, в голову приходят следующее интересности:
- кто ни кого ссылается в комментариях, то бишь группы по интересам;
- зависимость количества комментариев пользователя от их качества (кто пишет "редко но метко", а кто берёт количеством);
- как часто в одной ветке встречаются одни и те же лица, то есть, например, гипотеза: " Milfgard и Meklon очень часто материализуются в одном треде";
- "магическая" корреляция (или её отсутствие) между размером комментария и рейтингом;
- какая-нибудь статистика про большие комментарии и их "качество": периодически встречаются достойнейшие высказывания, которые тянут на статью, но выражены в формате комментария;
- статистика о количество пользователей в одной ветке обсуждения: существуют ли длинные обсуждения с большим вовлечением народа или это удел нескольких пользователей, которые решили уйти подальше и поглубже в дебаты/споры/etc; есть ли связь глубины и полезности как в абсолютном отншении (суммы плюсов и минусов за комментарии в ней), так и в относительном (то есть чем длиннее ветка, тем более "полезным" получается каждый комментарий в ней в среднем) и тд;
- просто "общая температура по больнице" и топ глубоко обсуждаемых статей, то есть оценить статью не общим количеством комментариев, а количеством обсуждений и их глубины (например, ветка в 10-15 комментариев гораздо содержательнее чем последовательное количество из такого же количества несвязанных сообщений).
Ну и, как говорится: "Сила Habr'ы в комментариях" так что их обязательно нужно всесторонне изучить.
varagian
14.06.2016 22:01Ок, была такая магистерская работа в вышке, которая до Хабра не добралась, как я не старался пинать автора — человек собрал комменты и кластеризовал юзеров по типу комментирования — в духе "общительный" или там "молчун" и тд.
Мне все хочется повторить, собрать и выложить такие данные, но это будет нетривиально.
Loriowar
14.06.2016 22:37+1Пните ещё разок… авось получится: достанет пыльный диссер из закромов родины и навояет… статистика должна быть интересной.
Таки да работа нетривиальная, я как представляю сколько всего нужно сделать для такого анализа… но зато и результат шикарным обещает быть.
Meklon
15.06.2016 00:22+3Мы скорее часто устраиваем беспредел в комментариях, когда синхронно появляемся. Насчет корреляции — почти уверен, что я всегда появляюсь в тех тредах, где отписался Milfgard, но не наоборот. Можно еще проверить зависимость между упоминанием человека и его появлением в треде.

Milfgard
15.06.2016 02:26+1Вот яркий пример «наоборот» )
LoadRunner
15.06.2016 06:40+1А я в таких частых случаях вообще Вас обоих путаю — кто из вас кто и приходится пару секунд вспоминать. Я не сторонник теории заговоров, но всё это крайне подозрительно, потому что одновременное появление чаще как раз без упоминания.
Tiberius
Отличная статья! Огромное спасибо за проделанную работу!
Последнюю амёбу надо поставить себе на рабочий стол, выглядит, как делящаяся клетка;)))
asvishnyakov
И правда. А мне почему-то вакуольку напомнило