
Гегель считал, что общество становится современным, когда новости заменяют религию.
The News: A User's Manual, Alain de Botton
Читать все новости стало разительно невозможно. И дело не только в том, что пишет их Стивен Бушеми в перерывах между боулингом с Лебовски, а скорее в том, что их стало слишком много. Тут нам на помощь приходят агрегаторы новостей и естественным образом встаёт вопрос: а кого и как они агрегируют?
Заметив пару интересных статей на Хабре про API и сбор данных популярного новостного сайта Meduza, решил расчехлить щит Персея и продолжить славное дело. Meduza мониторит множество различных новостных сайтов, и сегодня разберемся какие источники в ней преобладают, можно ли их осмысленно сгруппировать и есть ли здесь ядро, составляющее костяк новостной ленты.
Краткое определение того, что такое Meduza:
«Помните, как неумные люди все время называли «Ленту»? Говорили, что «Лента» — агрегатор. А давайте мы и в самом деле сделаем агрегатор» (интервью Forbes)
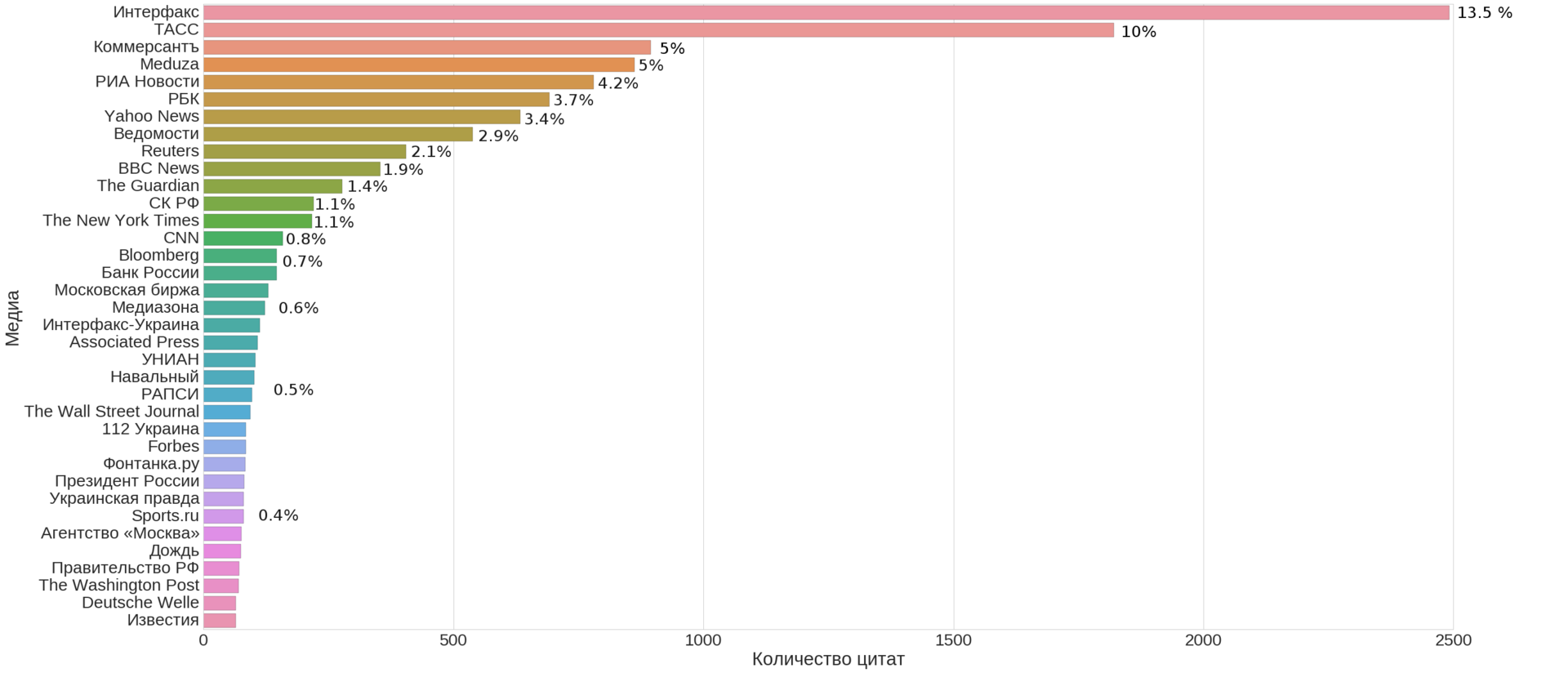
(это не просто КДПВ, а топ-35 медиа по числу новостей указанных в качестве источника на сайте Meduza, включая её саму)
Конкретизируем и формализуем вопросы:
- Q1: Из каких ключевых источников состоит лента новостей?
Иначе говоря, можем ли мы выбрать небольшое число источников достаточно покрывающих всю ленту новостей?
- Q2: Есть ли на них какая-то простая и интерпретируемая структура?
Проще говоря, можем ли мы кластеризовать источники в осмысленные группы?
- Q3: Можно ли по этой структуре определить общие параметры агрегатора?
Под общими параметрами здесь понимаются такие величины, как количество новостей во времени
Что такое источник?
У каждой новости на сайте есть указанный источник, в качестве примера помеченный ниже красным.
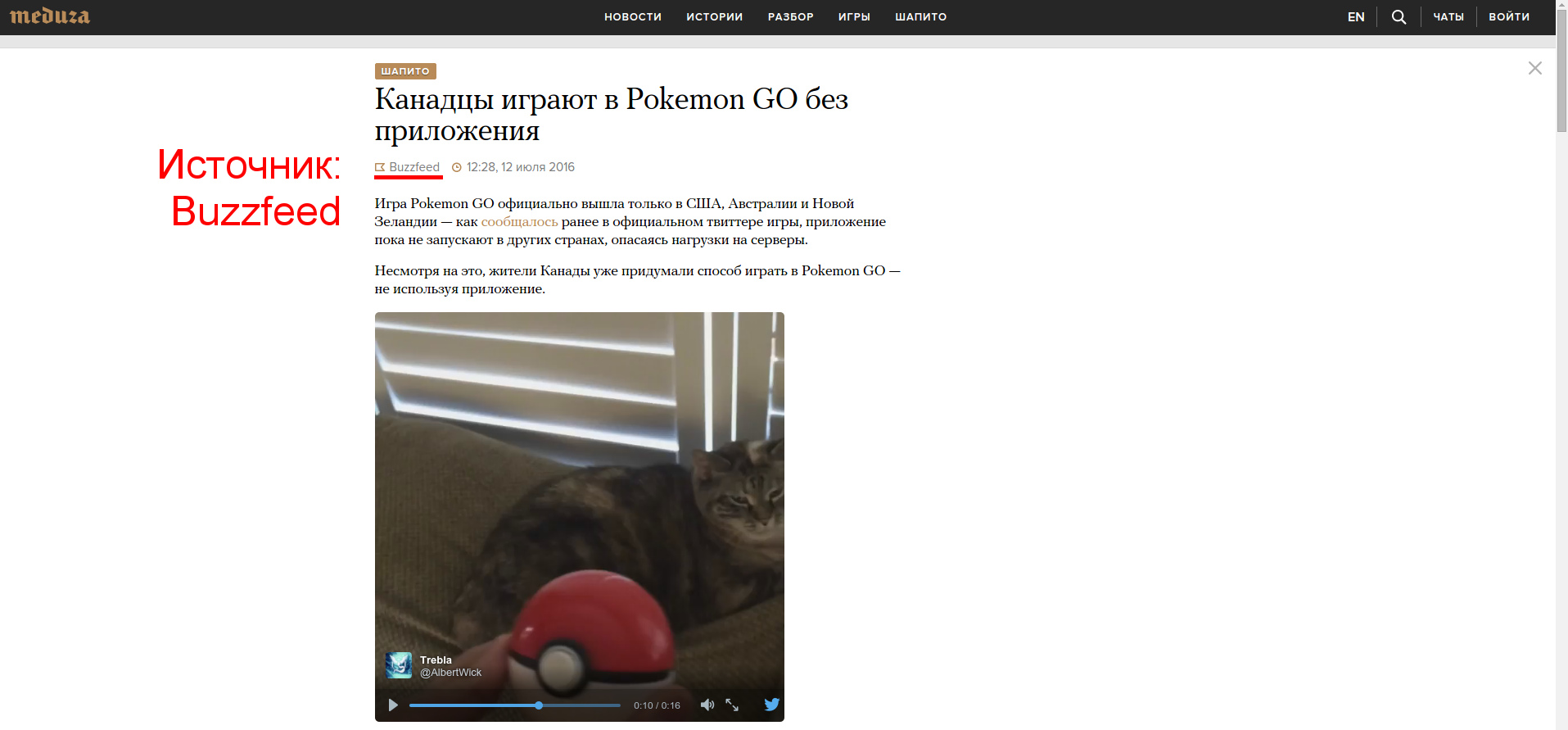
Именно этот параметр нас сегодня и будет особенно интересовать. Для анализа нам нужно собрать мета-данные по всем новостям. Для этого у Meduza имеется внутренний API, который можно использовать для своих нужд — запрос ниже вернет 10 последних русскоязычных новостей:
https://meduza.io/api/v3/search?chrono=news&page=0&per_page=10&locale=ru
На основе вот этой Хабра-статьи с кратким описание API и подобных запросов, мы получаем код для скачивания данных
import requests
import json
import time
from tqdm import tqdm
stream = 'https://meduza.io/api/v3/search?chrono=news&page={page}&per_page=30&locale=ru'
social = 'https://meduza.io/api/v3/social'
user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.3411.123 YaBrowser/16.2.0.2314 Safari/537.36'
headers = {'User-Agent' : user_agent }
def get_page_data(page):
# Достаём страницы
ans = requests.get(stream.format(page = page), headers=headers).json()
# отдельно достаёт все социальные
ans_social = requests.get(social, params = {'links' : json.dumps(ans['collection'])}, headers=headers).json()
documents = ans['documents']
for url, data in documents.items():
try:
data['social'] = ans_social[url]['stats']
except KeyError:
continue
with open('dump/page{pagenum:03d}_{timestamp}.json'.format(pagenum = page, timestamp = int(time.time())), 'w', encoding='utf-8') as f:
json.dump(documents, f, indent=2)
for i in tqdm(range(25000)):
get_page_data(i)Пример того, как выглядят данные для изучения:
affiliate NaN
authors []
bg_image NaN
chapters_count NaN
chat NaN
document_type news
document_urls NaN
full False
full_width False
fun_type NaN
hide_header NaN
image NaN
keywords NaN
layout_url NaN
live_on NaN
locale ru
modified_at NaN
one_picture NaN
prefs NaN
pub_date 2015-10-23 00:00:00
published_at 1445601270
pushed False
second_title NaN
share_message NaN
social {'tw': 0, 'vk': 148, 'reactions': 0, 'fb': 4}
source Интерфакс
sponsored NaN
sponsored_card NaN
table_of_contents NaN
tag {'name': 'новости', 'path': ''}
thesis NaN
title Роструд объявил о прекращении роста безработицы
topic NaN
updated_at NaN
url news/2015/10/23/rostrud-ob-yavil-o-prekraschen...
version 2
vk_share_image /image/share_images/16851_vk.png?1445601291
webview_url NaN
with_banners True
fb 4
reactions 0
tw 0
vk 148
trust 3
Name: news/2015/10/23/rostrud-ob-yavil-o-prekraschenii-rosta-bezrabotitsy, dtype: objectДанные для статьи были собраны в середине июля 2016 и доступны здесь {git}.
Типы документов и надежность источника
Начнем со следующего простого вопроса: какова доля новостей среди всех имеющихся документов и какой вид имеет распределение типов документов?
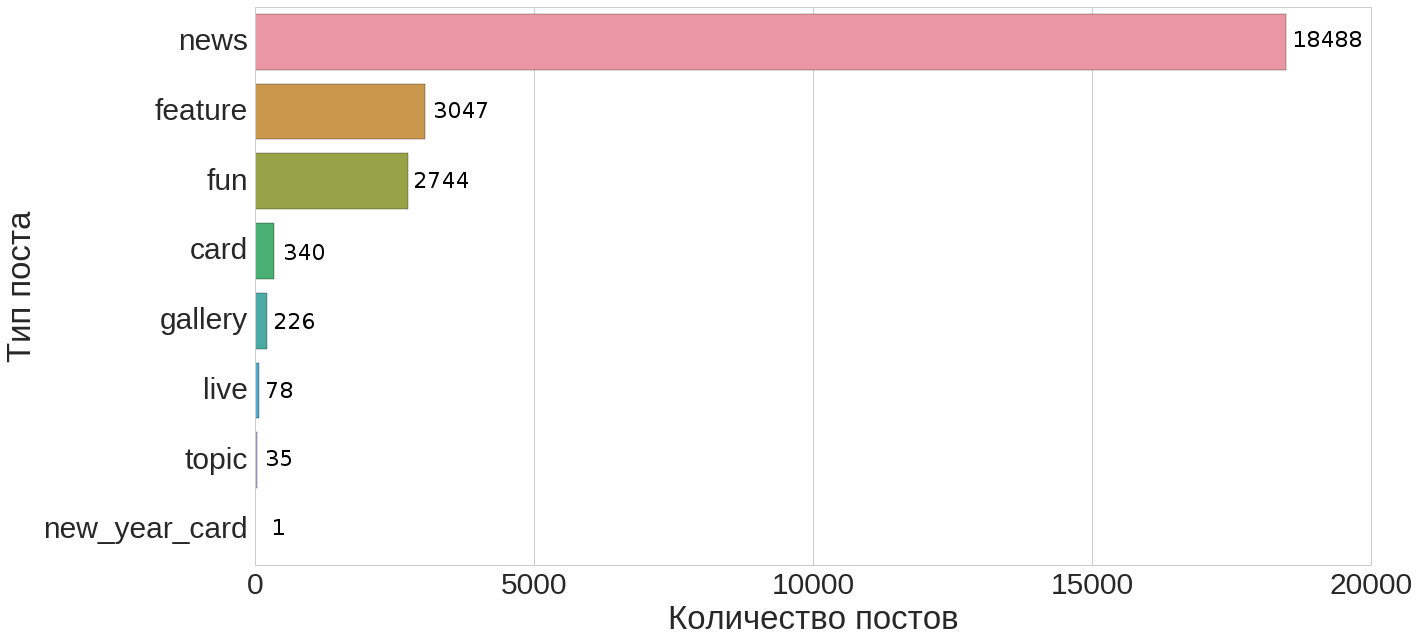
Из этого распределение видно (для удобства здесь же табличное представление этого распределения ниже), что новости составляют порядка 74% всех документов.
Далее мы сфокусируемся на новостях и в качестве иллюстрации рассмотрим параметр "надежность источника", применимый только к новостям:
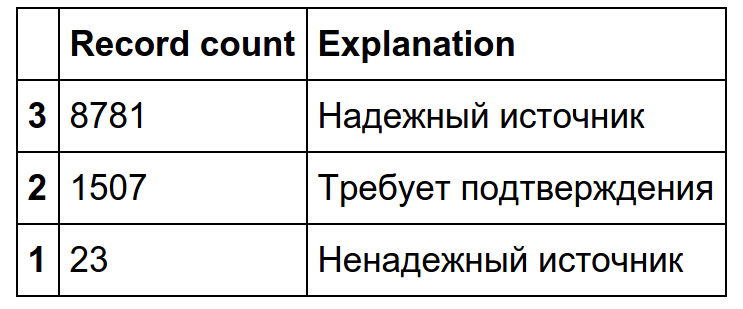
Как мы видим фактически все новости попадают в категории "надежный источник" или "требует подтверждения".
Анализ и кластеризация источников
На самом первом графике (в начале статьи) мы видим, что существенный вклад вносят несколько топовых источников. Возьмем источники, на которые приходится порядка ~100 ссылок и попробуем найти на них структуру.
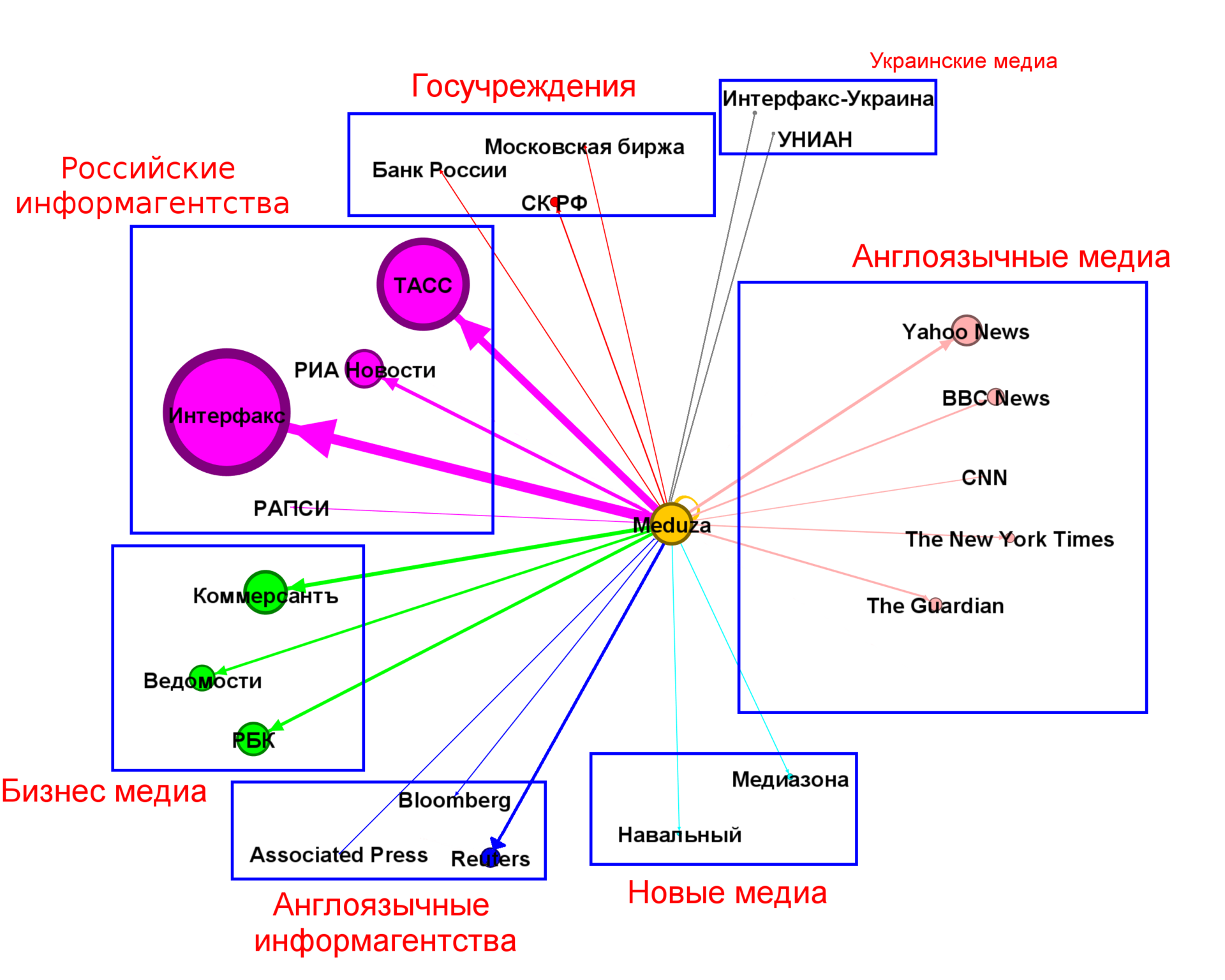
(размеры вершины и дуг пропорциональны количеству ссылок)
Безусловно количество кластеров и само разбиение может быть иным и во многом здесь субъективно.
Из графика выше мы видим, что самый большой вклад вносят российские информагентства ~30% всех новостей, за ним следуют бизнес-медиа с ~11.5%, далее переводы англоязычных медиа ~8.5% и мировые информагентства ~3.5%. Совокупно эти четыре кластера покрывают бо?льшую часть новостей (50%+). У остальных кластеров <3%. Авторский материал (источник: сама Meduza) составляет порядка 5%.
Анализ общего числа публикаций
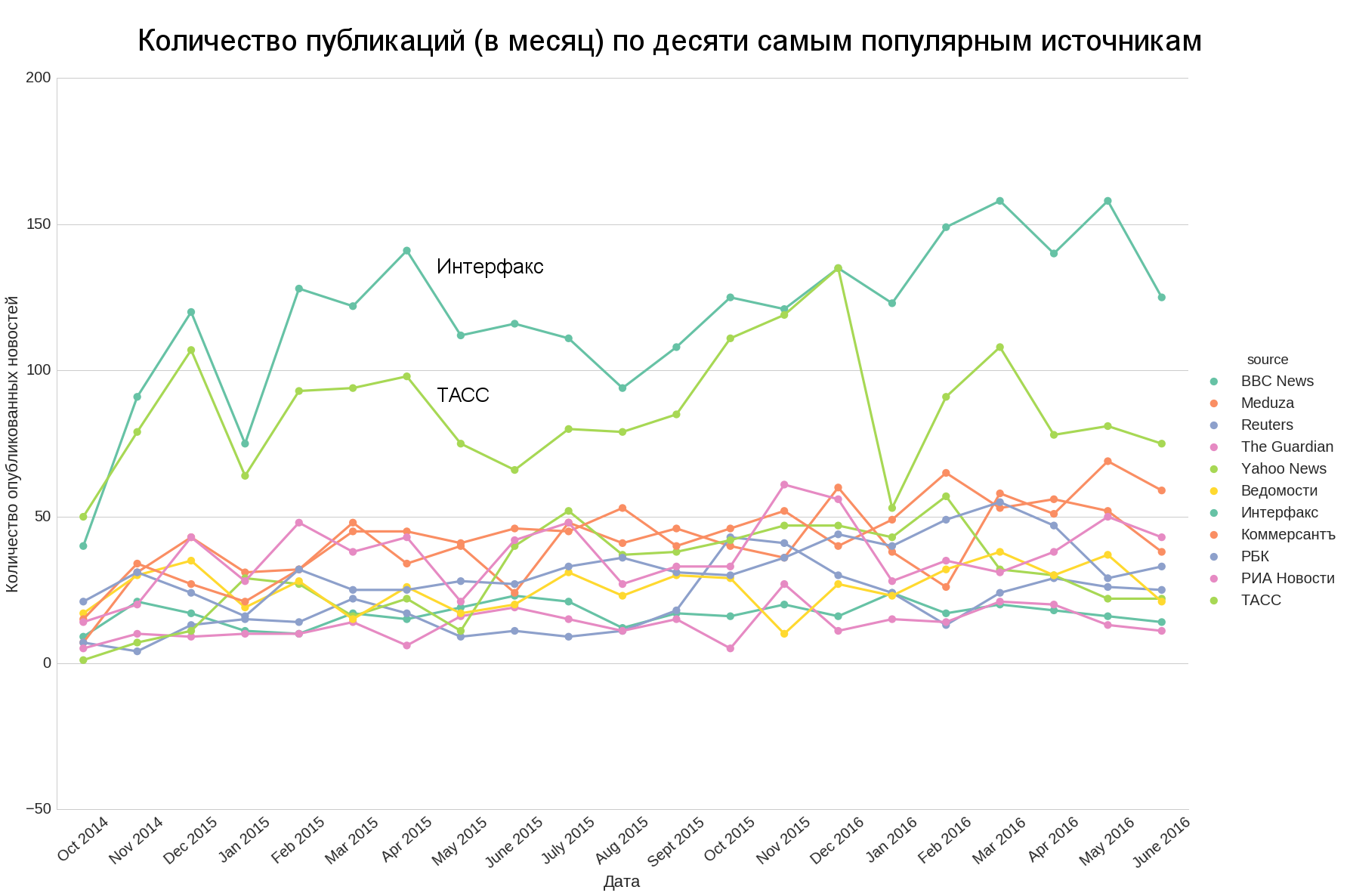
Также интересно: насколько количество новостей из различных источников сопоставимо во времени и можем ли мы взять топ (например, топ-10) и оценить по нему общий тренд на всё количество новостей.
Мы видим, что только ТАСС и Интерфакс количественно существенно отличаются от остального топа, остальные источники количественно довольно близки к друг другу.
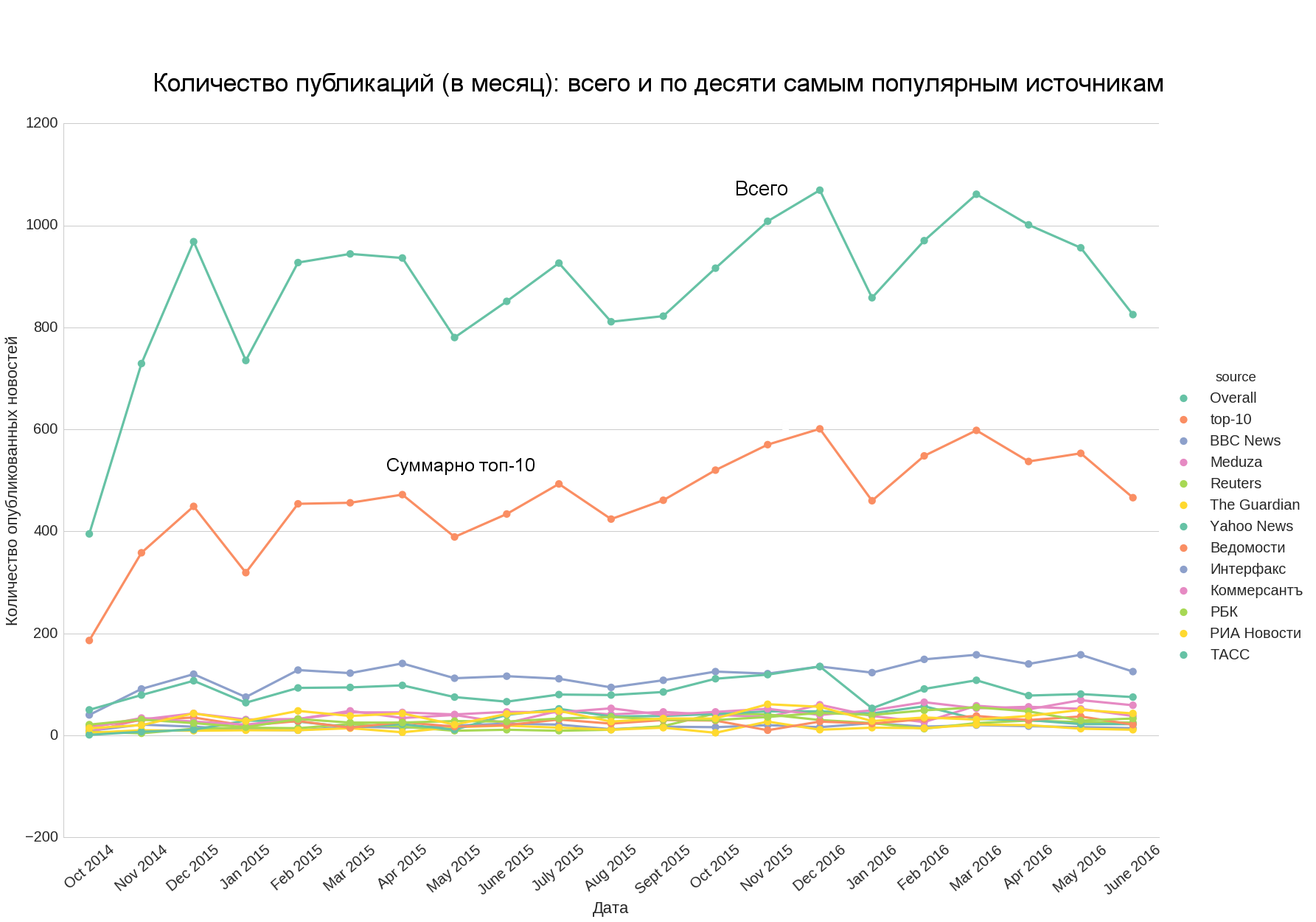
Если мы добавим топ-10 и общее число новостей, то заметим, что первое хорошо апроксимирует второе, то есть количество новостей в топ-10 даёт хорошее представление об общем количестве новостей.
Сравнение с медиалогией
Данные и графики в этой части взяты отсюда.
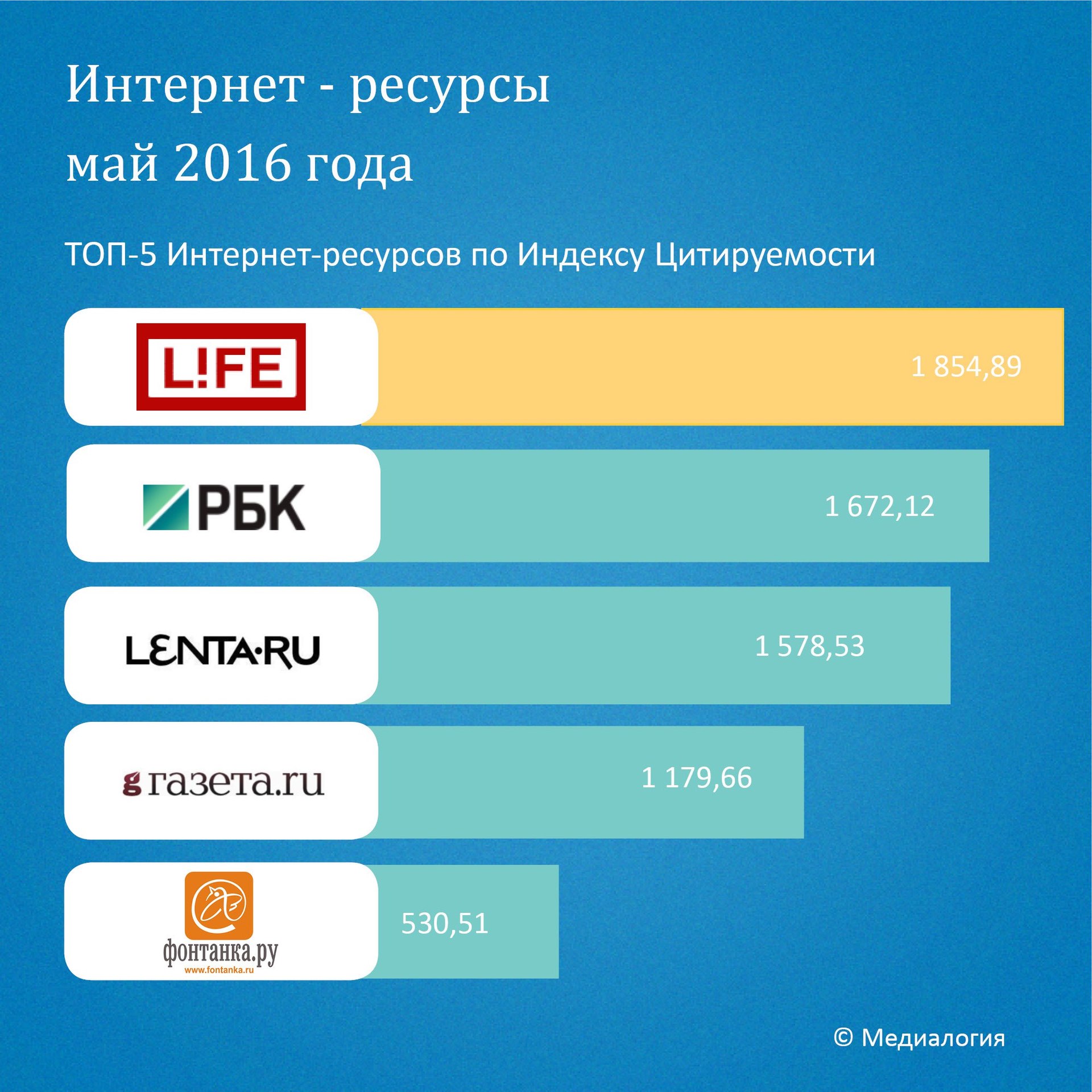
Интересно взглянуть насколько такая выборка соотносится с общими рейтингами цитируемости новостей в сети. Рассмотрим имеющиеся данные медиалогии за май 2016-го:
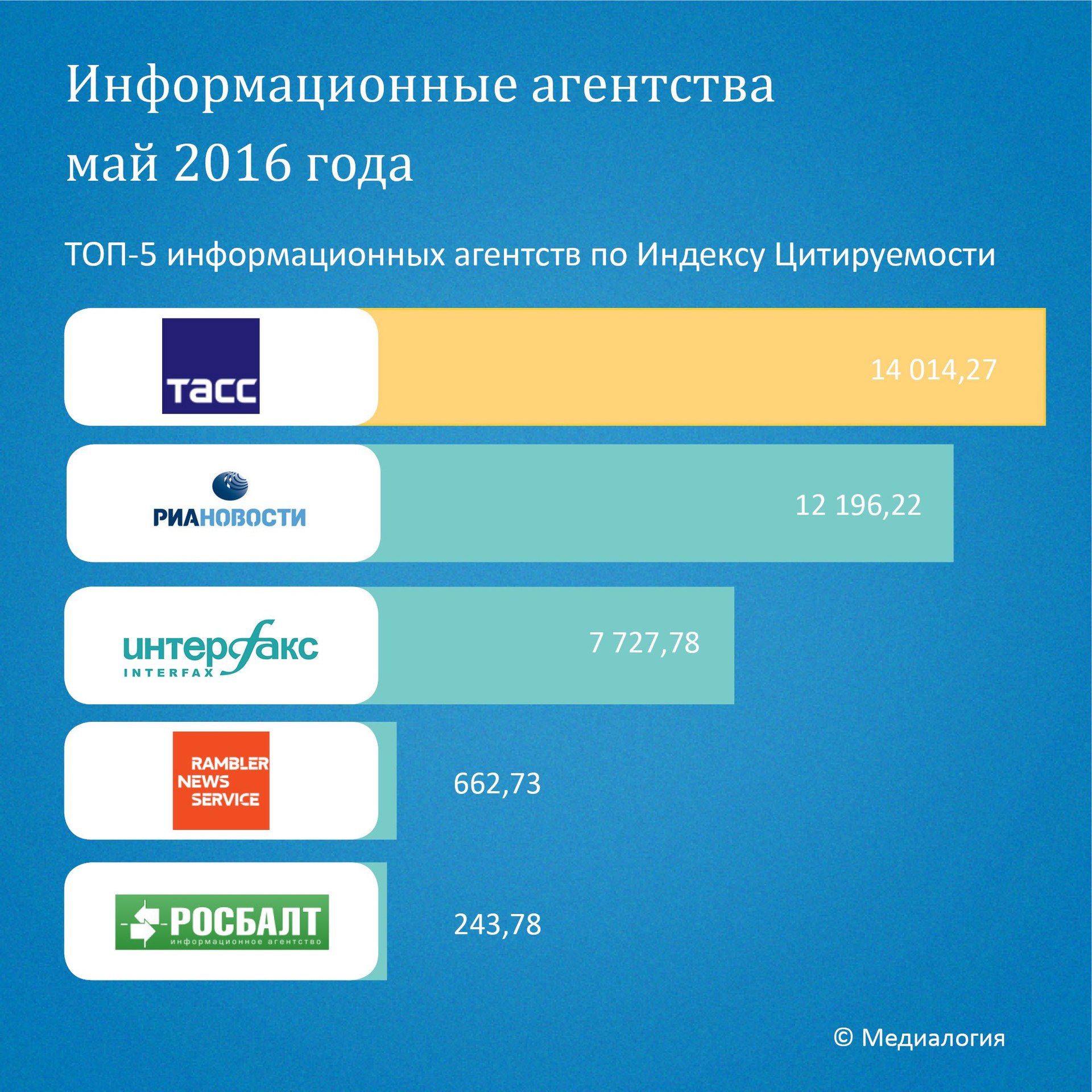
В целом мы видим, что тройка точно также представлена в топе, хотя и в другом порядке (что довольно естественно, агрегатор не обязательно может поставить к себе высоко-цитируемую новость, например, в силу того, что может посчитать её виральной и недостойной существенного внимания, или приходящейся на слишком ненадежный источник — что согласуется с распределением надежности новостей).

Выводы и ссылка на данные
Тезисно, выводы по рассматриваемым вопросам:
Q1: Топ 10-15 новостных источников составляющих большинство новостей: российские информагентства и бизнес-медиа, а также переводы известных международных информагентств и медиа (более половины всех новостей) — см. первый график.
Q2: На топовых источниках выделено семь кластеров: причем четыре ключевых перечисленных выше (Q1) покрывают большинство топовых источников и большинство самих новостей — см. график в разделе "Анализ и кластеризация источников".
- Q3: Топ-10 источников позволяет оценить общий тренд на количество новостей агрегатора во времени — см график в разделе "Анализ общего числа публикаций".
Данные (актуальность — середина июля 2016) доступны в git репозитории.
Комментарии (23)
Laney1
11.08.2016 12:40+1Интересно, есть ли спонсированные новости (поле sponsored)
про сайт не скажу, но в мобильном приложении у них часто встречаются статьи с пометками «партнерский материал», т.е. реклама. Интересно, как к этому относится гугл
devian
11.08.2016 13:41+6На сайте тоже есть партнерские материалы. Но какие варианты отношения гугла к этому вы можете здесь рассматривать? Это уникальный контент (а зачастую еще и очень интересный, особенно если учесть, что это реклама). В чем тут конфликт может быть?

Akr0n
11.08.2016 16:28+2Медуза зарабатывает на нативной рекламе и делает это очень круто. Что плохого в этом должен видеть Google?

ikashnitsky
11.08.2016 12:45+1Еще интересно было бы взвесить данные на количество просмотров, расшариваний и (тут не знаю как точно обозначить термин) длительность экспозиции материала. Например, материал из раздела "карточки" будет значительно дольше представлен читателям, нежели рядовая новость.

Alex_Great
11.08.2016 16:39-3В чем ценность и смысл выводов? Что и кому это дает?
Столько букв ради того, чтобы показать то, что и так всем известно.
DenimTornado
11.08.2016 16:50В чём ценность и смысл вашего коммента?




dimm_ddr
12.08.2016 10:57+1Вообще просто распределение источников мало о чем говорит само по себе. Вот соотношение тем которые берутся из этих источников ко всем темам на этом источнике — это было бы гораздо информативнее. Впрочем я понимаю, что это гораздо более сложная задача.

varagian
12.08.2016 10:58Можно поподробнее, какие темы имеются ввиду?
TotalAMD
12.08.2016 12:26+1Видимо, предлагается провести анализ, какие из опубликованных за отчётный период материалов данного СМИ были взяты Медузой к себе.
dimm_ddr
12.08.2016 13:36+1Для примера, без привязки к реальным агрегаторам, пусть есть два агенства. У обоих по методике из данной статьи наибольшая часть новостей из Интерфакса и из газеты ру. Но первое берет из обоих самые читаемые или самые популярные(оставим в стороне вопрос как они это меряют, допустим у них на самом деле это получается), а второе берет из Интерфакса только мелкие незначащие или просто развлекательные новости, а из газеты ру — исключительно политические и скандальные. То есть источники и даже их соотношение примерно одинаковые, но набор новостей совершенно разный.
varagian
12.08.2016 17:15В такой постановке не получится решить: нужно знать какие-то внутренние показатели в духе "читаемые" и "популярные", а вот разбить все новости на темы и посмотреть по источникам — теоретически выполнимо.
elingur
12.08.2016 11:14+1как они агрегируют?
Вопросы по поводу как: для агрегации используется классификация или кластеризация? На основе источников или по тексту? Можно ли что-то почитать по методам кластеризации/классификации на медузе?varagian
12.08.2016 11:43В смысле, как происходит кластеризация в статье? Взят топ и источники разбиты по категориям СМИ. В самой Медузе наверняка сидят люди, которые изучают источники, такие как информагентства и принимают решения стоит ли публиковать новость и в каком разделе.
Т.е. кластеризация здесь не автоматическая, а для классификации нужны размеченные данные и в общем-то, нужно понять что классифицировать — источник по тексту новости? То есть саму задачу нужно будет еще поставить.


onthefly
21.08.2016 16:15В схеме распределения источников Московская биржа отнесена к государственным организациям. В действительности биржа является публичной коммерческой организацией, более половины акций которой находится в свободном обращении.
Zverik
Хороший анализ, но дополнить бы.