

Всем привет!
После публикации предыдущей статьи на почту прилетело не мало писем с просьбой показать и доказать, чем же одно решение лучше другого.
Я, воодушевленно принялся сравнивать, но всё, как обычно, немного сложнее, чем кажется с первого взгляда.
Да, в этой статье я предлагаю выложить все парсеры на стол и измерить!
Приступим!
Прежде чем что-то сравнивать, нам нужно понять: что же мы собственно хотим сравнить?! А сравнить мы хотим хтмл парсеры, но вот что такое хтмл парсер?
Хтмл парсер это:
- Токенизатор (Tokenizer) — разбивка текста на токены
- Построение дерева (Tree Builder) — размещение токенов «в нужные позиции» в дереве
- Последующая работа с деревом
Человек «с мороза» может сказать: — «Не обязательно строить дерево для парсинга хтмл, ведь достаточно получить токены». И к сожалению, будет не прав.
Дело в том, что для правильной токенизации хтмл нам необходимо иметь дерево под рукой. Пункт 1 и 2 неразделимы.
Приведу два примера:
Первый:
<svg><desc><math><style><a>
Результат правильной обработки:
<html>
<head>
<body>
<svg:svg>
<desc:svg>
<math:math>
<style:math>
<a:math>
Второй:
<svg><desc><style><a>
Результат правильной обработки:
<html>
<head>
<body>
<svg:svg>
<desc:svg>
<style>
<-text>: <a>
После ":" идет namespace, если не указано то хтмл.
Из двух примеров видно, что элемент STYLE ведет себя по разному в зависимости от того, где находится. В первом варианте есть элемент A, а во-втором — это уже текстовый элемент.
Здесь же можно привести пример с frameset, script, title… и их разным поведением, но думаю, общий смысл ясен.
Теперь, мы точно можем сделать вывод о том, что разбивка на токены не может быть верно осуществлена без построения хтмл дерева. А следовательно и парсинг хтмл не может быть осуществлён без, как минимум, двух стадий: токенизация и построение дерева.
Что касается терминов: «строгий», «не соответствует спецификации», «light», «html 4» и тому подобные… Я уверен, что все эти термины можно смело заменить на один: «обрабатывает не правильно». Всё это абсурд.
Как и что будем сравнивать?
А вот тут самое интересное. Носить гордое звание хтмл парсера могут далеко не все, более того даже те кто именует себя токенизаторами хтмл, по сути, не являются таковыми.
Выложив все парсеры на стол у меня сразу же возник вопрос, — кого с кем сравнить?
А сравнивать будем правильные парсеры: myhtml, html5lib, html5ever, gumbo.
Именно они соответствуют последней спецификации, и их результат будет совпадать с тем что мы может увидеть в современных браузерах.
Неправильные парсеры (не соответствуют спецификации) могут сильно отличаться по скорости/памяти, но толку от этого более чем никакого, они просто неправильно обрабатывают документ.
Никакие отговорки, вроде «парсер для html 4», приниматься во внимание не будут. Мир постоянно меняется, и за ним надо успевать.
Стоит отметить, что html5ever не совсем правильный парсер. Авторы пишут, что он не проходит все тесты html5lin-test-tree-builder, то есть тесты на правильность построения дерева. В правильные парсеры он попал за старания быть правильным.
Так же, на момент написания статьи html5lib не верно строит дерево для некоторого формата хтмл. Но это всё баги, которые я надеюсь, авторы исправят.
Будем мерить время/память для 466 хтмл файлов — TOP500 alexa. 466, а не 500 потому, что не все сайты работают и не все отдают свой контент.
Для каждой страницы будет создан fork со стадиями:
- Полная инициализация парсера
- Парсинг одной страницы
- Освобождение ресурсов
Тек же будет тест «из жизни» — прогнать все страницы, по возможности, одним объектом. Происходить всё это будет последовательно.
К тестам!
До тестов у нас дошли: myhtml, html5ever, gumbo.
К сожалению, html5lib вылетел из тестирования. Предварительный прогон показал, что он заметно медленнее остальных. Сравнивать его нет смысла, он написан на python и он медленный, очень медленный.
MyHTML и Gumbo написаны на C. html5ever — это Rust. В расте я не силён, пока не силён, и поэтому попросил Алексея Вознюка помочь мне. Алексей согласился (респект и уважуха) и сделал сишную обёртку для тестирования парсера.
Общий результат тестов времени выполнения:

Общий результат тестов занимаемых ресурсов:

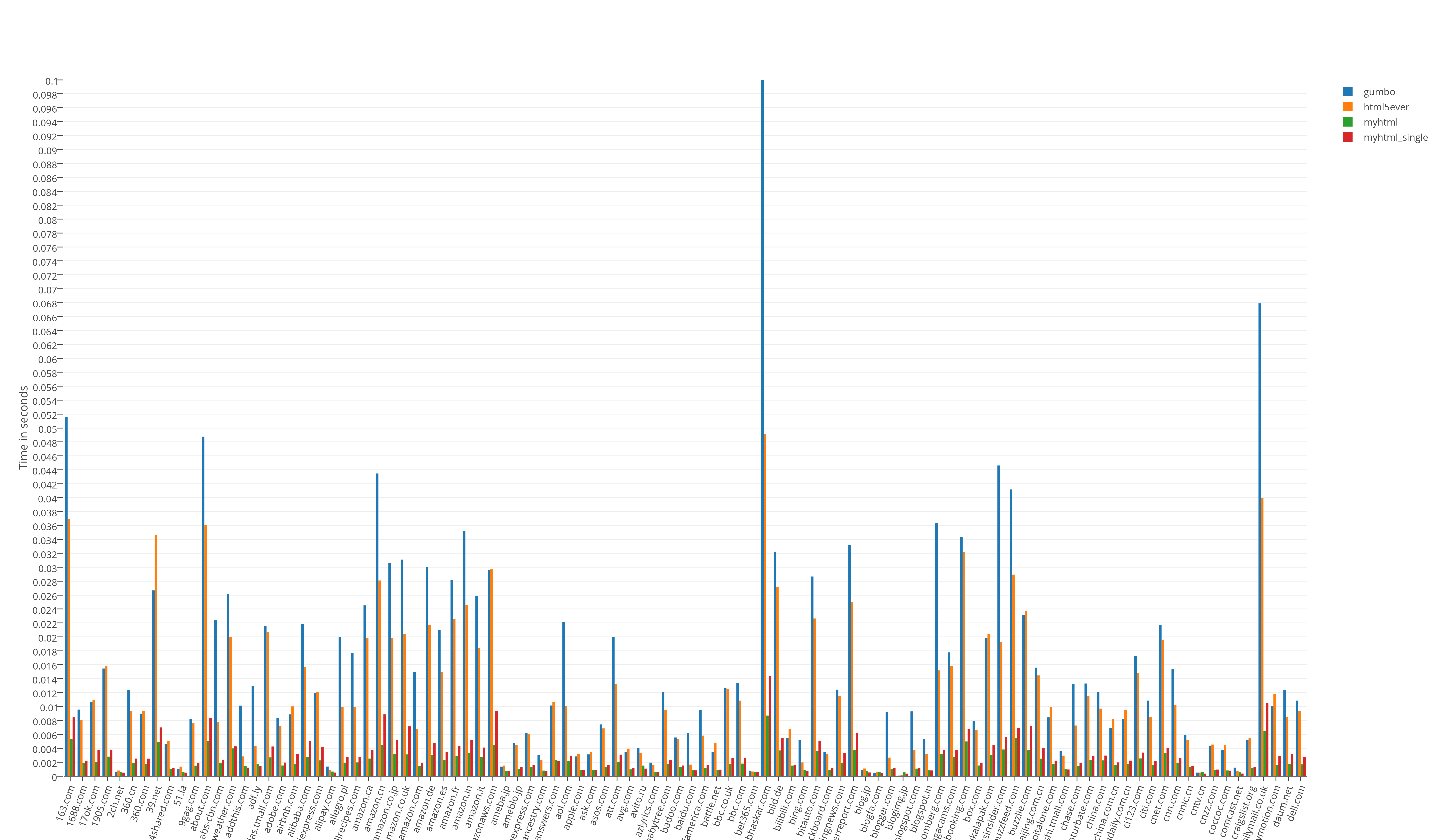
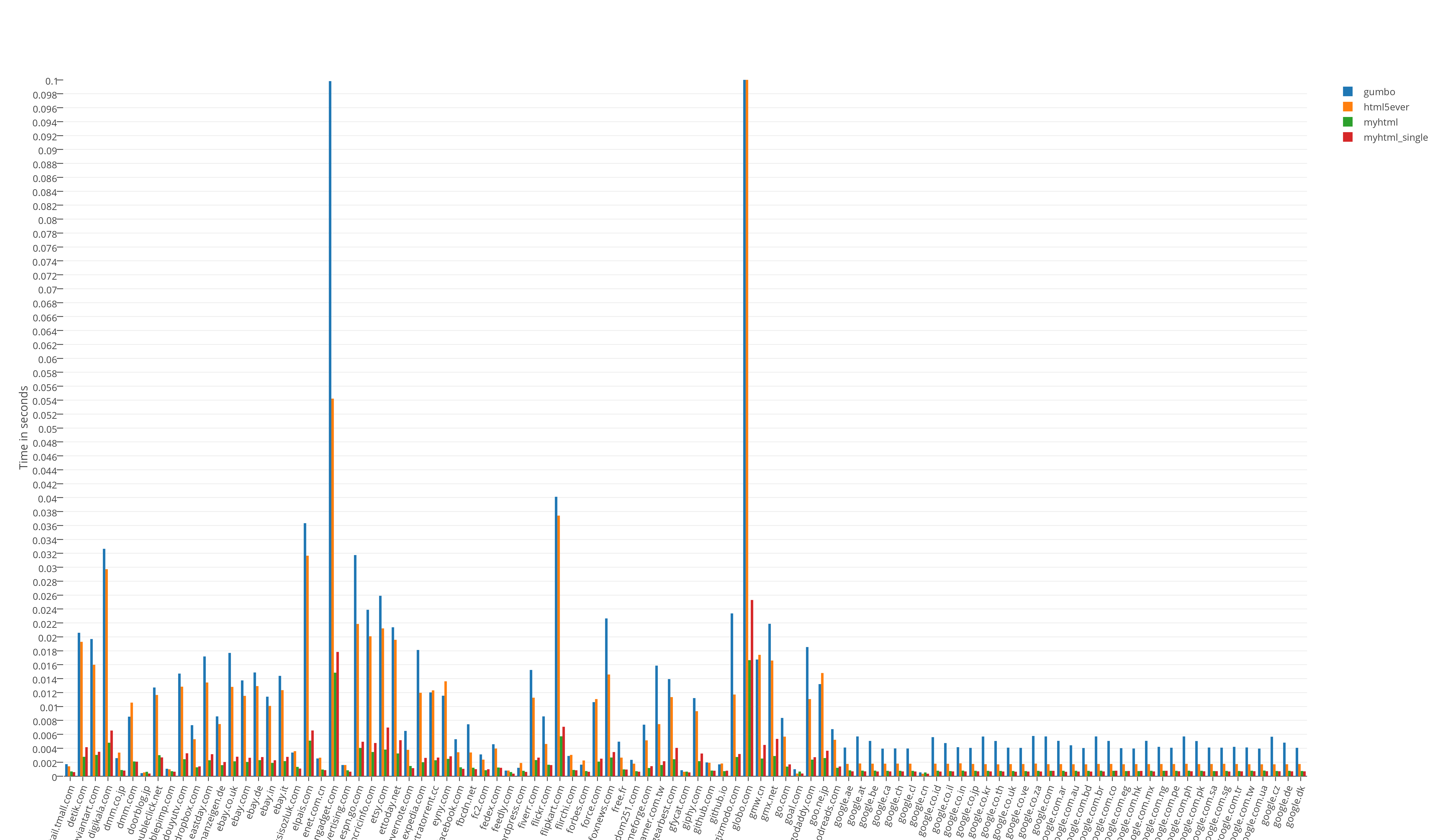

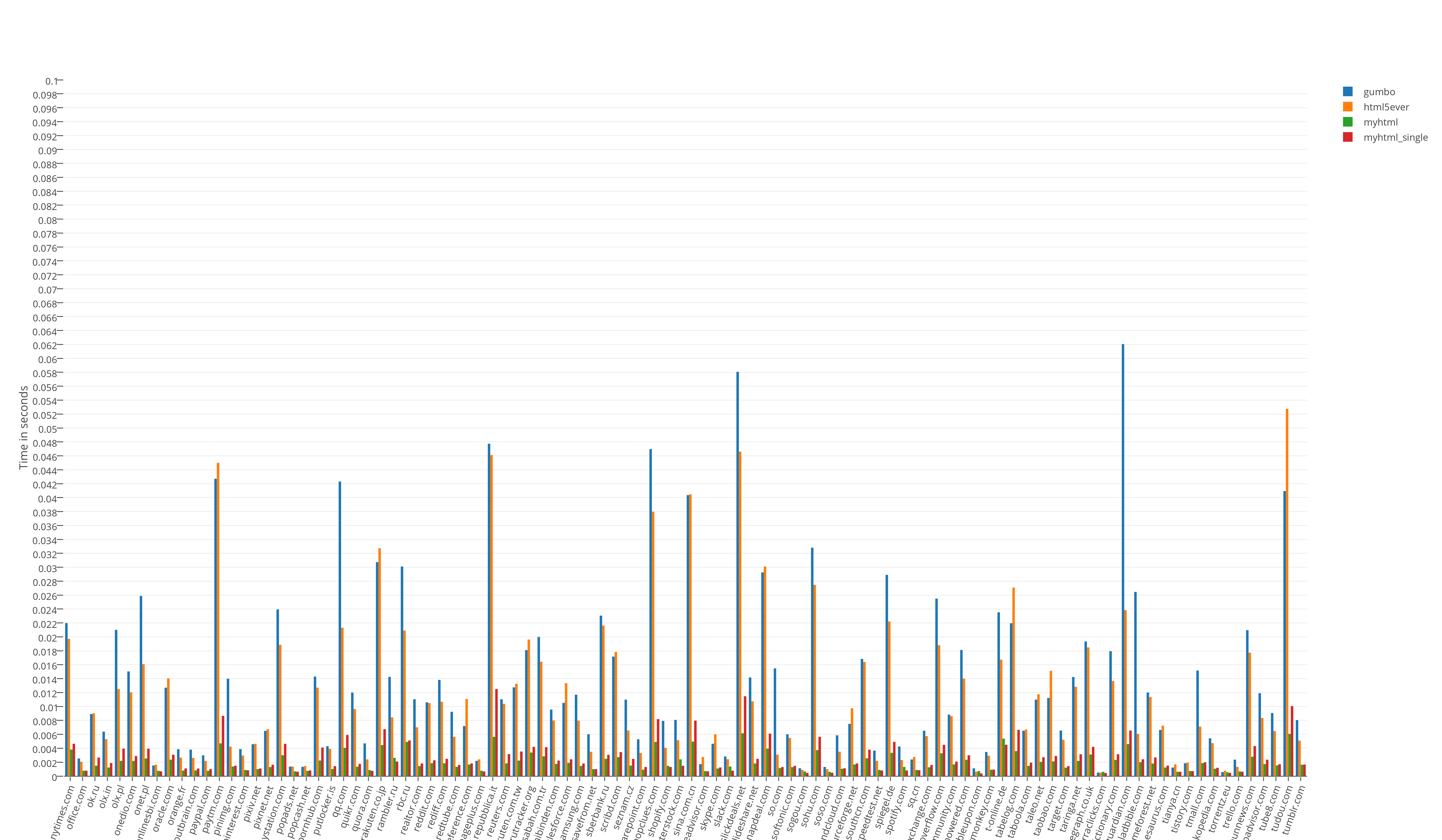

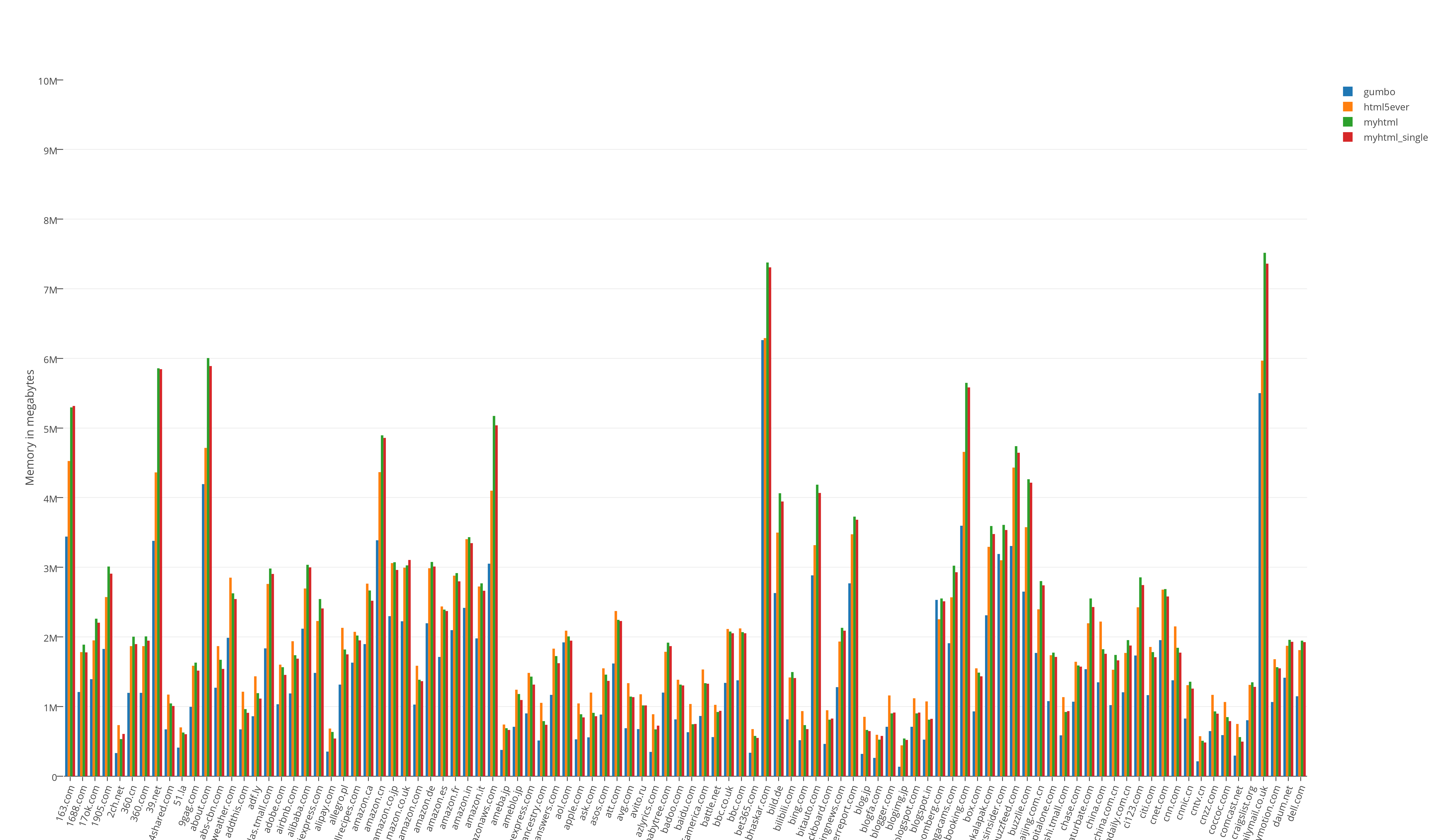
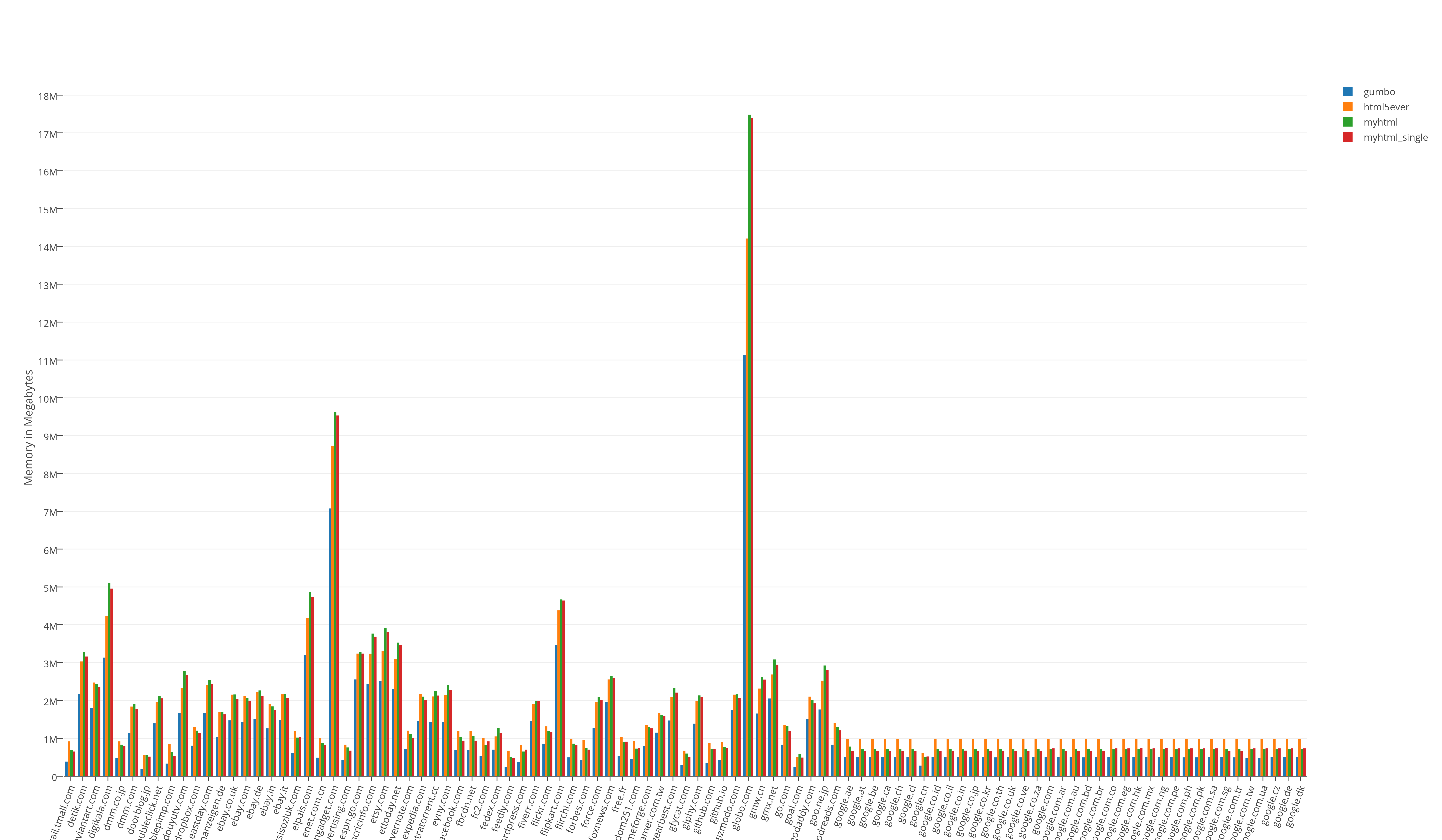

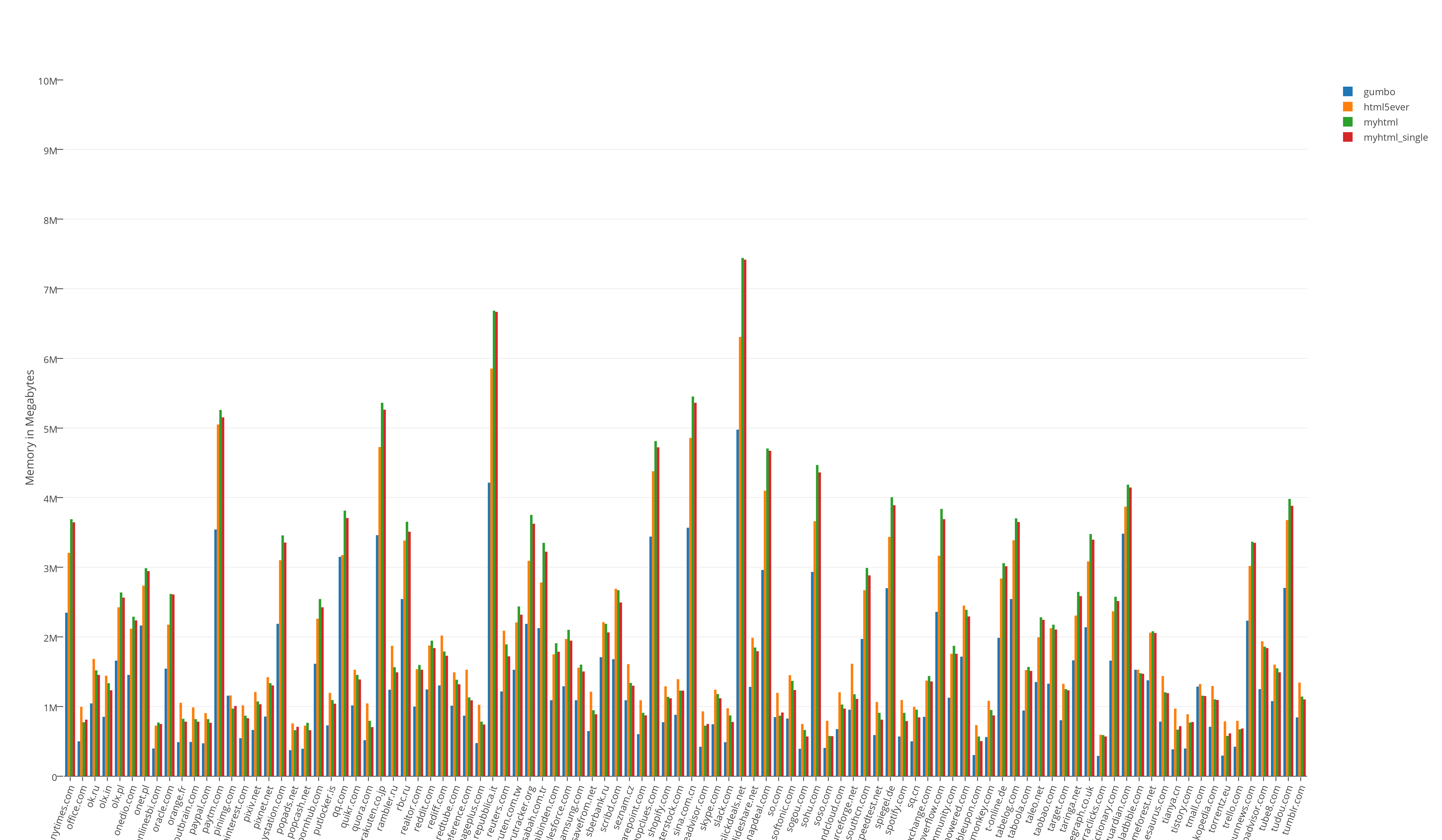

Результат тестов «из жизни». Прогон всех (466) страниц в одно процессе:
myhtml:
Общее время: 0.50890; Память на старте: 1052672; Память по окончании: 32120832
gumbo:
Общее время: 6.12951; Память на старте: 1052672; Память по окончании: 29319168
html5ever:
Общее время: 4.50536; Память на старте: 1052672; Память по окончании: 30715904
Итоги
Бесспорный лидер по скорости — myhtml. gumbo — лидер по памяти, что не удивительно. html5ever показал себя, мягко говоря, никак. Он не быстр и по памяти не особо проявил себя, и использовать его можно только из Rust.
Тест «из жизни» показал, что отличия в памяти не значительные, а вот по скорости, я бы не постеснялся сказать, колоссальные.
Что использовалось
Оборудование:
Intel® Core(TM) i7-3615QM CPU @ 2.30GHz
8 ГБ 1600 МГц DDR3
Программное обеспечение:
Darwin MBP-Alexander 15.3.0 Darwin Kernel Version 15.3.0: Thu Dec 10 18:40:58 PST 2015; root:xnu-3248.30.4~1/RELEASE_X86_64 x86_64
Apple LLVM version 7.0.2 (clang-700.1.81)
Target: x86_64-apple-darwin15.3.0
Thread model: posix
Ссылки
Код Бенчмарка
Картинки и CSV
myhtml, gumbo, html5ever
Обвязка для html5event от Алексея
Спасибо за внимание!
P.S. от автора myhtml
Являясь автором myhtml мне морально сложно было делать подобное тестирование. Но я постарался крайне ответственно подойти к этому делу, и с каждым парсером работать как со своим.
Комментарии (11)

alekseev_ap
17.03.2016 22:40Извиняюсь за глупый вопрос, но всё же интересно. А Ваш парсер может парсить HTML странички с JavaScript так, чтобы в результате получить дерево с учётом их работы? Т.е. если в HTML есть ссылка на JavaScript файл, который генерит код вставки картинки и прочего контента, то будет ли в дереве тег этого изображение вместе с остальными атрибутами (src, width, height, alt, title, ...) или будет только тег скрипта?

lastmac
17.03.2016 22:56Привет!
Вполне нормальный вопрос. Нет, это только парсер с заделом на будущее. То есть он делался с мыслью о связке с JavaScript движком. Этот функционал ожидается в будущем.alekseev_ap
18.03.2016 09:05А есть ли такие уже сейчас? Желательно на C/C++
lastmac
18.03.2016 09:25WebKit.
Собственно ради этого и был начат проект myhtml. Расчет (быстрый расчёт) DOM на C без зависимостей (Render Tree). У меня не хватит времени и сил сделать JS engine, он будет опционально подключаем.

RPG18
18.03.2016 10:46Из простого для быстрого старта можно использовать классы Qt WebKit(до 5.6) или Qt WebEngine. Из них можно получить конечный html код, который можно распарсить myhtml/gumb.
RPG18
Для теста "из жизни" сколько времени заняло скачивание этих страниц?
lastmac
Привет!
Страницы были скачены заранее. Каждая страница загружается в память и потом отдается парсерам.
Если конкретно ответить на вопрос — не могу сказать, замеры не делались.
RPG18
Интересно посмотреть на порядок цифр. Предположим что в среднем загрузка страницы происходит за 0,5 сек. Загрузка всех страниц займет 233 сек.
В целом получилось наглядная иллюстрация подхода: если где-то хотим ускорить, то где-то придется потратить память.
lastmac
UPDATE:
Простите, торопился и неверно прочитал коммент. Не совсем так, по памяти я гуляю и оптимизаций не делал. Там есть куда ужиматься и ускориться. Пока просто нет на это времени.