
Всем привет!
Как можно было догадаться из заголовка речь пойдет о парсинге HTML (далее хтмл).
Преамбула
Как-то появилась у меня идея «Х», но для её реализации нужен посчитанный DOM со всеми стилями и плюшками. Гугление и яндексение ничего хорошего не показало. Есть всякие обвёртки для WebKit, но они работают не на всех платформах, да и сильно обрезанные. Существуют проекты где WebKit завёрнут в некий фронтэнд с которым ты работаешь через JavaScript. Что-то было испробовано, но результат был плачевным. Потребление ресурсов чего только стоило.
Хотелки
А хотелось, как тогда казалось, не так много:
- Отрисовщик (Render) хтмл без диких зависимостей. Только отрисовщик, сеть ложилась бы на пользователя. Иначе говоря, полный расчёт хтмл до момента рисования в окошке.
- Возможность приладить обвёртку для JavaScript движка
- Возможность легко сделать обвёртку для других языков программирования
И я вступил в неравный бой!
Изучал существующие хтмл и CSS (далее цэсс) парсеры.
Будучи бэкэнд разработчиком меня всегда не устраивали существующие хтмл парсеры. Все они делились условно на три категории:
- Парсят как душе угодно, имея исключительно своё представление об токенизации хтмл
- Парсят как-то следуя спецификации
- Парсят чётко следуя спецификации
Казалось бы, есть же третий пункт, наверное тему можно и закрыть?! Но нет, и вот почему: все существующие парсеры устроены по принципу «Парсим и Умираем». Это когда ты отдаешь программе целый хтмл, программа возвращает результат и любые последующие манипуляции невозможны, только чтение. Этот факт сильно ограничивает область применения парсеров. Стоит сделать ремарку, есть те кто работу с DOM перекладывает на уровень выше. Смысл такой: парсим сишным парсером, а потом через обвёртку пытаемся работать с DOM на, к примеру, Python, что немного абсурдно.
Далее, никто не позволял вклиниться в поток (имеется ввиду хтмл) в момент парсинга. Это крайне важно для прилаживания JavaScript движка. Не буду долго объяснять, а лучше покажу почему:
Фрагмент хтмл документа:
<script>document.write("<div cl");</script>ass="future"></div>
Итог любого браузера с JS:
...
<div class="future"></div>
То есть, в итоге будет создан полноценный DIV элемент. К слову, токенизация тега SCRIPT то ещё дело. Мне пришлось рисовать
схему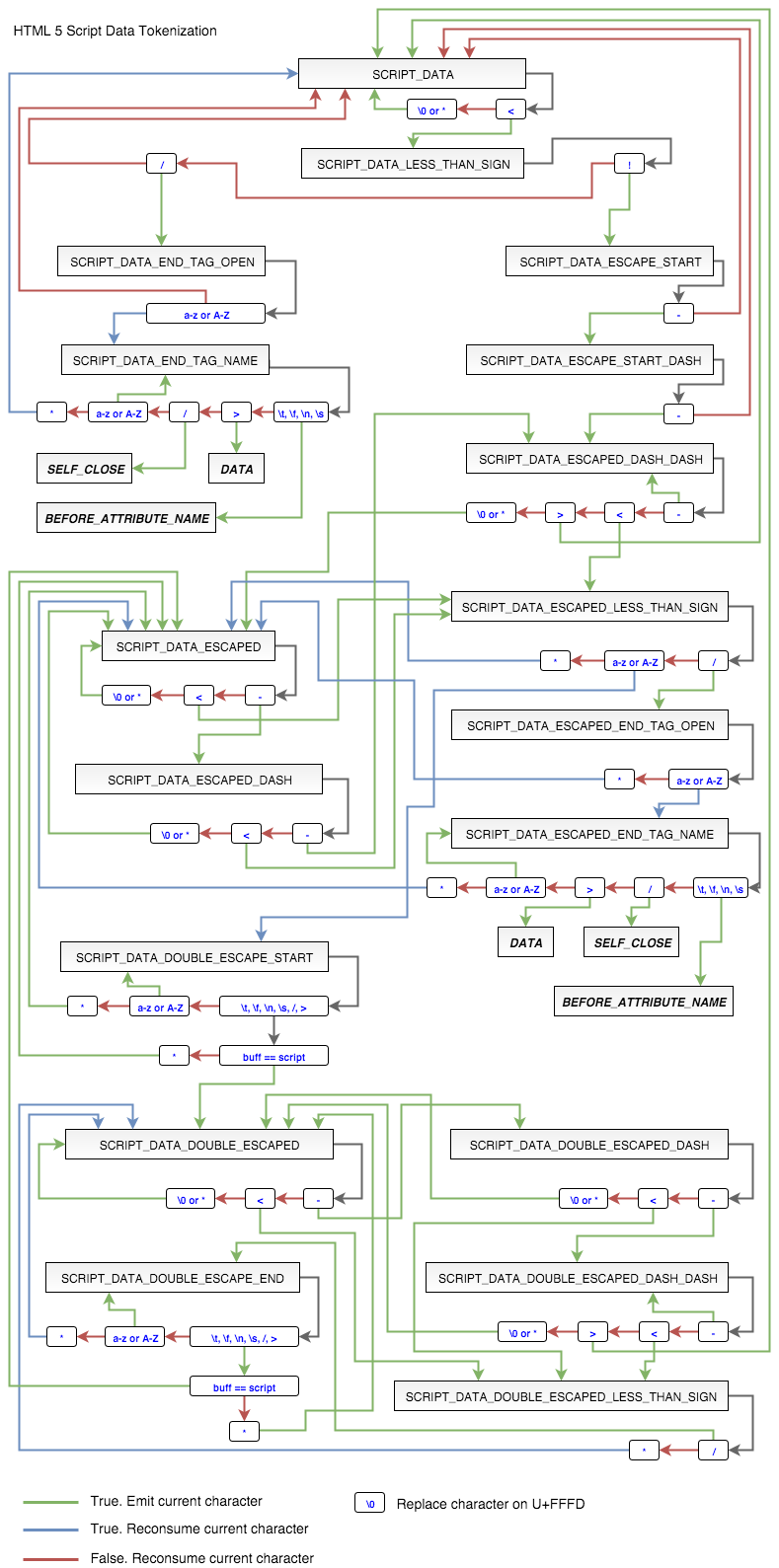
После всего увиденного было принято решение писать всё с нуля на Си. Тут же возникли требования к коду:
- Поддержка C99
- Возможность отделить хтмл парсер от отрисовщика чтобы использовать отдельно
- Без внешних зависимостей
Зачем же так сразу жёстко — на Си?! Решение должно быть встраиваемым, чтобы без особого труда можно было сделать обвязку для стороннего языка программирования.
С переменным успехом удалось реализовать в черновом варианте:
- Парсер хтмл
- Парсер цэсс
- Селекторы (Selectors)
- Отрисовщик inline, inline-block, block, table...
Про отрисовщик можно писать долго, за короткой фразой «Отрисовщик inline элементов» прячется не мало: работа со шрифтами по спецификации, расчёт размера текста, расчет vertical-align, построение вспомогательного дерева для отрисовки текста и ещё куча всего.
В итоге, после двух-трёх лет неспешной разработки я начинаю переделывать черновой вариант в рабочий. Первым, что логично, стал хтмл парсер.
Сейчас хтмл парсер обладает следующими возможностями:
- Асинхронно парсить HTML, обрабатывать токены, строить дерево
- Полная поддержка HTML 5 по спецификации html.spec.whatwg.org/multipage
- Имеем два API: «Высокого» уровня и «низкого». Первое-это публичное апи, которое имеет описание и вообще, всё как у людей, но не позволяет видеть структуры. Второе-это использование исходников напрямую.
- Возможность манипулировать элементами: добавлять, удалять, изменять .
- Возможность манипуляции с атрибутами элементов: добавлять, удалять, изменять
- Поддерживает 34 кодировки на вход. На выход только UTF-8, и вся работа внутри только в UTF-8
- Может определять кодировку текста. Сейчас доступны unicode: UTF-8, UTF-16LE, UTF-16BE (+ определение по BOM) и русские: windows-1251, koi8-r, iso-8859-5, x-mac-cyrillic, ibm866
- Может работать в Single Mode — без тредов
- Парсить фрагменты HTML
- Парсить кусками (chunks). Можно отдавать резанные куски HTML (разорванные в произвольном месте) и он будет их парсить, без предварительного накопления буфера.
- Не имеет внешних зависимостей
- Поддерживает C99
- Работа с памятью. Память кешируется, выделяется кусками и под объекты. К примеру, удаление десяти элементов, а потом добавление десяти других не съест память под новые
+ еще куча всяких мелких, но нужных штук о которых можно писать долго.
На очереди CSS парсер и Render. Делаю всё один, «бензина» должно хватить.
Любая помощь крайне приветствуется!
Спасибо за внимание! Надеюсь вам будет это полезно!
Собственно сам парсер
P.S.: Если сообщество проявит к этой теме интерес то могу писать узконаправленные статьи о том как работает расчёт отрисовки и с какими сложностями сталкивался/сталкиваюсь.