

Как-то раз я рассказывал о новой Байесовской модели человеку, который не особенно разбирался в предмете, но очень хотел всё понять. Он-то и спросил меня о том, чего я обычно не касаюсь. «Томас, — сказал он, — а как, на самом деле, выполняется вероятностный вывод? Как получаются эти таинственные сэмплы из апостериорной вероятности?».
Тут я мог бы сказать: «Всё очень просто. MCMC генерирует сэмплы из апостериорного распределения вероятностей, создавая обратимую цепь Маркова, равновесное распределение которой – это целевое апостериорное распределение. Вопросы?».
Объяснение это верное, но много ли от него пользы для непосвящённого? Меня больше всего раздражает в том, как учат математике и статистике, то, что никто никогда не говорит об интуитивно понятных идеях, лежащих в основе всяческих понятий. А эти идеи обычно довольно просты. С таких занятий можно вынести трёхэтажные математические формулы, но не понимание того, как всё устроено. Меня учили именно так, а я хотел понять. Я бессчётные часы бился головой о математические стены, прежде чем наступал момент очередного прозрения, прежде чем очередная «Эврика!» срывалась с моих губ. После того, как мне удавалось разобраться, то, что раньше виделось сложным, оказывалось на удивление простым. То, что раньше пугало нагромождением математических знаков, становилось полезным инструментом.
Этот материал – попытка интуитивно понятного объяснения MCMC-сэмплинга (в частности, алгоритма Метрополиса). Мы будем использовать примеры кода вместо формул или математических выкладок. В конечном итоге, без формул не обойтись, но лично я считаю, что лучше всего начинать с примеров и достичь интуитивного понимания вопроса, прежде чем переходить к языку математики.
Проблема и её неинтуитивное решение
Взглянем на формулу Байеса:
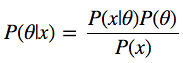
У нас есть P(?|x) – то, что нас интересует, а именно – апостериорная вероятность, или распределение вероятностей параметров модели ?, вычисленная после того, как приняты во внимание данные x, взятые из наблюдений. Для того, чтобы получить то, что нам нужно, надо перемножить априорную вероятность P(?), то есть – то, что мы думаем о ? до проведения экспериментов, до получения данных, и функцию правдоподобия P(x|?), то есть – то, что мы думаем о том, как распределены данные. Числитель дроби найти очень легко.
Теперь присмотримся к знаменателю P(x), который ещё называют свидетельством, то есть – свидетельством того, что данные х, были сгенерированы этой моделью. Вычислить его можно, проинтегрировав все возможные значения параметров:
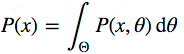
Вот в этом – основная сложность формулы Байеса. Сама она выглядит вполне невинно, но даже для слегка нетривиальной модели апостериорную вероятность не вычислить за конечное число шагов.
Тут можно сказать: «Хорошо, если напрямую это не решается, можем ли мы пойти по пути аппроксимации? Например, если бы мы могли бы как-нибудь получить образцы данных из этой самой апостериорной вероятности, их можно было бы аппроксимировать методом Монте-Карло.» К несчастью, для того, чтобы взять сэмплы из распределения, надо не только найти решение формулы Байеса, но ещё и инвертировать её, поэтому такой подход даже сложнее.
Продолжая размышления, можно заявить: «Ладно, тогда давайте сконструируем цепь Маркова, равновесное распределение которой совпадает с нашим апостериорным распределением». Я, конечно, шучу. Большинство людей так не выразится, очень уж безумно это звучит. Если вычислить напрямую нельзя, взять сэмплы из распределения тоже нельзя, то построить цепь Маркова с вышеозначенными свойствами – задача и вовсе неподъёмная.
И вот здесь нас ждёт удивительное открытие. Сделать это, на самом деле, очень легко. Существует целый класс алгоритмов для решения таких задач: методы Монте-Карло в Марковских цепях (Markov Chain Monte Carlo, MCMC). Сущность этих алгоритмов – создание цепи Маркова для выполнения аппроксимации методом Монте-Карло.
Постановка задачи
Для начала импортируем необходимые модули. Блоки кода, отмеченные как «Листинг», можно вставить в Jupyter Notebook и, по мере чтения материала, опробовать в деле. Полный исходник смотрите здесь.
?Листинг 1
%matplotlib inline
import numpy as np
import scipy as sp
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm
sns.set_style('white')
sns.set_context('talk')
np.random.seed(123)Теперь сгенерируем данные. Это будут 100 точек, нормально распределённых вокруг нуля. Наша цель заключается в том, чтобы оценить апостериорное распределение средней mu (предполагается, что мы знаем, что среднеквадратическое отклонение равно 1).
?Листинг 2
data = np.random.randn(20)Теперь построим гистограмму.
?Листинг 3
ax = plt.subplot()
sns.distplot(data, kde=False, ax=ax)
_ = ax.set(title='Histogram of observed data', xlabel='x', ylabel='# observations');
Гистограмма наблюдаемых данных
Теперь нужно описать модель. Мы рассматриваем простой случай, поэтому предполагаем, что данные распределены нормально, то есть, функция правдоподобия модели так же распределена нормально. Как вы, должно быть, знаете, у нормального распределения есть два параметра – это математическое ожидание (среднее значение) ? и среднеквадратическое отклонение ?. Для простоты, будем считать, что мы знаем, что ?=1. Мы хотим вывести апостериорную вероятность для ?. Для каждого искомого параметра нужно выбрать априорное распределение вероятностей. Для простоты, допустим, что нормальное распределение будет априорным распределением для ?. Таким образом, на языке статистики, модель будет выглядеть так:
??Normal(0,1)
x|??Normal(x;?,1)Что особенно удобно – для этой модели, на самом деле, можно вычислить апостериорное распределение вероятностей аналитически. Дело в том, что для нормальной функции правдоподобия с известным среднеквадратическим отклонением, нормальное априорное распределение вероятностей для mu является сопряжённым априорным распределением. То есть, наше апостериорное распределение будет следовать тому же распределению, что и априорное. В итоге, мы знаем, что апостериорное распределение для ? так же является нормальным. В Википедии несложно найти методику расчёта параметров для апостериорного распределения. Математическое описание этого можно найти здесь.
?Листинг 4
def calc_posterior_analytical(data, x, mu_0, sigma_0):
sigma = 1.
n = len(data)
mu_post = (mu_0 / sigma_0**2 + data.sum() / sigma**2) / (1. / sigma_0**2 + n / sigma**2)
sigma_post = (1. / sigma_0**2 + n / sigma**2)**-1
return norm(mu_post, np.sqrt(sigma_post)).pdf(x)
ax = plt.subplot()
x = np.linspace(-1, 1, 500)
posterior_analytical = calc_posterior_analytical(data, x, 0., 1.)
ax.plot(x, posterior_analytical)
ax.set(xlabel='mu', ylabel='belief', title='Analytical posterior');
sns.despine()
Апостериорное распределение, найденное аналитически
Здесь изображено то, что нас интересует, то есть, распределение вероятностей для значений ? после учёта имеющихся данных, принимая во внимание априорную информацию. Предположим, однако, что априорное распределение не является сопряжённым и мы не можем решить задачу, так сказать, вручную. На практике обычно бывает именно так.
Код, как путь к пониманию сущности MCMC-сэмплинга
Теперь поговорим о сэмплировании. Во-первых, нужно найти начальную позицию параметра (её можно выбрать случайным образом). Давайте зададим её произвольно следующим образом:
mu_current = 1.Затем предлагается переместиться, «прыгнуть» из этой позиции в какое-то другое место (это уже относится к цепям Маркова). Эту новую позицию можно выбрать и «методом тыка», и руководствуясь какими-то глубокими соображениями. Сэмплер в алгоритме Метрополиса прост, как пять копеек: он выбирает образец из нормального распределения с центром в текущем значении mu (переменная mu_current) с неким среднеквадратическим отклонением (proposal_width), которое определяет ширину диапазона, из которого выбираются предлагаемые значения. Здесь мы используем scipy.stats.norm. Надо сказать, что вышеупомянутое нормальное распределение не имеет ничего общего с тем, что используется в модели.
proposal = norm(mu_current, proposal_width).rvs()Следующий шаг – оценка того, подходящее ли место выбрано для перехода. Если полученное нормальное распределение с предложенным mu объясняет данные лучше, чем при предыдущем mu, то в выбранном направлении, безусловно, стоит двигаться. Но что значит «лучше объясняет данные»? Мы определяем это понятие, вычисляя вероятность данных, учитывая функцию правдоподобия (нормальную) с предложенными значениями параметров (предложенное mu и sigma, значение которого зафиксировано и равно 1). Расчёты тут простые. Достаточно вычислить вероятность для каждой точки данных с помощью команды scipy.stats.normal(mu, sigma).pdf(data) и затем перемножить индивидуальные вероятности, то есть – найти значение функции правдоподобия. Обычно в таком случае пользуются логарифмическим распределением вероятностей, но здесь мы это опускаем.
likelihood_current = norm(mu_current, 1).pdf(data).prod()
likelihood_proposal = norm(mu_proposal, 1).pdf(data).prod()
# Вычисление априорного распределения вероятности для текущего и предложенного mu
prior_current = norm(mu_prior_mu, mu_prior_sd).pdf(mu_current)
prior_proposal = norm(mu_prior_mu, mu_prior_sd).pdf(mu_proposal)
# Числитель формулы Байеса
p_current = likelihood_current * prior_current
p_proposal = likelihood_proposal * prior_proposalДо этого момента мы, на самом деле, пользовались алгоритмом восхождения к вершине, который лишь предлагает перемещения в случайных направлениях и принимает новое положение только если mu_proposal имеет более высокий уровень правдоподобия, нежели mu_current. В конечном итоге мы дойдём до варианта mu = 0 (или к значению, близкому к этому), откуда двигаться будет уже некуда. Однако, мы хотим получить апостериорное распределение, поэтому должны иногда соглашаться на перемещения в другом направлении. Главный секрет здесь заключается в том, что разделив p_proposal на p_current, мы получим вероятность принятия предложения.
p_accept = p_proposal / p_currentМожно заметить, что если p_proposal больше, чем p_current, полученная вероятность будет больше 1, и такое предложение мы, определённо, примем. Однако, если p_current больше чем p_proposal, скажем, в два раза, шанс перехода будет составлять уже 50%:
accept = np.random.rand() < p_accept
if accept:
# Обновляем позицию
cur_pos = proposalЭта простая процедура даёт нам сэмплы из апостериорного распределения.
Зачем это всё?
Оглянемся назад и отметим, что введение в систему вероятности принятия предлагаемой позиции перехода – это причина, по которой всё это работает и позволяет нам избежать интегрирования. Это хорошо видно, если вычислять уровень принятия предложения для нормализованного апостериорного распределения и наблюдать за тем, как он соотносится с уровнем принятия предложения для ненормализованного апостериорного распределения (скажем, ?0 – это текущая позиция, а ? это предлагаемая новая позиция):

Если это объяснить, то, деля ту апостериорную вероятность, которая получилась для предлагаемого параметра, на ту, что вычислена для текущего параметра, мы избавляемся от уже надоевшего P(x), которое посчитать не в состоянии. Можно интуитивно понять, что мы делим полное апостериорное распределение вероятностей в одной позиции на то же самое в другой позиции (вполне обычная операция). Таким образом мы посещаем области с более высоким уровнем апостериорного распределения вероятностей сравнительно более часто, чем области с низким уровнем.
Складываем полную картину
Соберём вышесказанное воедино.
?Листинг 5
def sampler(data, samples=4, mu_init=.5, proposal_width=.5, plot=False, mu_prior_mu=0, mu_prior_sd=1.):
mu_current = mu_init
posterior = [mu_current]
for i in range(samples):
# предлагаем новую позицию
mu_proposal = norm(mu_current, proposal_width).rvs()
# Вычисляем правдоподобие, перемножая вероятности для каждой точки данных
likelihood_current = norm(mu_current, 1).pdf(data).prod()
likelihood_proposal = norm(mu_proposal, 1).pdf(data).prod()
# Вычисляем априорное распределение вероятностей для текущего и предлагаемого mu
prior_current = norm(mu_prior_mu, mu_prior_sd).pdf(mu_current)
prior_proposal = norm(mu_prior_mu, mu_prior_sd).pdf(mu_proposal)
p_current = likelihood_current * prior_current
p_proposal = likelihood_proposal * prior_proposal
# Принять предложенную точку?
p_accept = p_proposal / p_current
# Обычно сюда было бы включено априорное распределение вероятностей, здесь это опущено для простоты
accept = np.random.rand() < p_accept
if plot:
plot_proposal(mu_current, mu_proposal, mu_prior_mu, mu_prior_sd, data, accept, posterior, i)
if accept:
# Обновляем позицию
mu_current = mu_proposal
posterior.append(mu_current)
return posterior
# Функция визуализации
def plot_proposal(mu_current, mu_proposal, mu_prior_mu, mu_prior_sd, data, accepted, trace, i):
from copy import copy
trace = copy(trace)
fig, (ax1, ax2, ax3, ax4) = plt.subplots(ncols=4, figsize=(16, 4))
fig.suptitle('Iteration %i' % (i + 1))
x = np.linspace(-3, 3, 5000)
color = 'g' if accepted else 'r'
# Визуализация априорного распределения вероятностей
prior_current = norm(mu_prior_mu, mu_prior_sd).pdf(mu_current)
prior_proposal = norm(mu_prior_mu, mu_prior_sd).pdf(mu_proposal)
prior = norm(mu_prior_mu, mu_prior_sd).pdf(x)
ax1.plot(x, prior)
ax1.plot([mu_current] * 2, [0, prior_current], marker='o', color='b')
ax1.plot([mu_proposal] * 2, [0, prior_proposal], marker='o', color=color)
ax1.annotate("", xy=(mu_proposal, 0.2), xytext=(mu_current, 0.2),
arrowprops=dict(arrowstyle="->", lw=2.))
ax1.set(ylabel='Probability Density', title='current: prior(mu=%.2f) = %.2f\nproposal: prior(mu=%.2f) = %.2f' % (mu_current, prior_current, mu_proposal, prior_proposal))
# Правдоподобие
likelihood_current = norm(mu_current, 1).pdf(data).prod()
likelihood_proposal = norm(mu_proposal, 1).pdf(data).prod()
y = norm(loc=mu_proposal, scale=1).pdf(x)
sns.distplot(data, kde=False, norm_hist=True, ax=ax2)
ax2.plot(x, y, color=color)
ax2.axvline(mu_current, color='b', linestyle='--', label='mu_current')
ax2.axvline(mu_proposal, color=color, linestyle='--', label='mu_proposal')
#ax2.title('Proposal {}'.format('accepted' if accepted else 'rejected'))
ax2.annotate("", xy=(mu_proposal, 0.2), xytext=(mu_current, 0.2),
arrowprops=dict(arrowstyle="->", lw=2.))
ax2.set(title='likelihood(mu=%.2f) = %.2f\nlikelihood(mu=%.2f) = %.2f' % (mu_current, 1e14*likelihood_current, mu_proposal, 1e14*likelihood_proposal))
# Апостериорное распределение вероятностей
posterior_analytical = calc_posterior_analytical(data, x, mu_prior_mu, mu_prior_sd)
ax3.plot(x, posterior_analytical)
posterior_current = calc_posterior_analytical(data, mu_current, mu_prior_mu, mu_prior_sd)
posterior_proposal = calc_posterior_analytical(data, mu_proposal, mu_prior_mu, mu_prior_sd)
ax3.plot([mu_current] * 2, [0, posterior_current], marker='o', color='b')
ax3.plot([mu_proposal] * 2, [0, posterior_proposal], marker='o', color=color)
ax3.annotate("", xy=(mu_proposal, 0.2), xytext=(mu_current, 0.2),
arrowprops=dict(arrowstyle="->", lw=2.))
#x3.set(title=r'prior x likelihood $\propto$ posterior')
ax3.set(title='posterior(mu=%.2f) = %.5f\nposterior(mu=%.2f) = %.5f' % (mu_current, posterior_current, mu_proposal, posterior_proposal))
if accepted:
trace.append(mu_proposal)
else:
trace.append(mu_current)
ax4.plot(trace)
ax4.set(xlabel='iteration', ylabel='mu', title='trace')
plt.tight_layout()
#plt.legend()Визуализация MCMC
Для того, чтобы визуализировать процесс сэмплирования, мы рисуем графики некоторых вычисляемых величин. Каждый ряд изображений представляет собой один проход Метрополис-сэмплера.
В первом столбце показано априорное распределение вероятностей, то есть – наши предположения о ? до ознакомления с данными. Как можно видеть, это распределение не меняется, мы лишь показываем здесь предложения нового значения ?. Вертикальные синие линии – это текущее ?. А предлагаемое ? отображается либо зелёным, либо красным цветом (это, соответственно, принятые и отвергнутые предложения).
Во втором столбце – функция правдоподобия и то, что мы используем для того, чтобы оценить, насколько хорошо модель объясняет данные. Здесь можно заметить, что график меняется в соответствии с предлагаемым ?. Там же отображается и синяя гистограмма – сами данные. Сплошная линия выводится либо зелёным, либо красным цветом – это график функции правдоподобия при mu, предложенном на текущем шаге. Чисто интуитивно понятно, что чем сильнее функция правдоподобия перекрывается с графическим отображением данных – тем лучше модель объясняет данные и тем выше будет результирующая вероятность. Точечная линия того же цвета – это предложенное mu, точечная синяя линия – это текущее mu.
В третьей колонке – апостериорное распределение вероятностей. Здесь показано нормализованное апостериорное распределение, но, как мы выяснили выше, можно просто умножить предыдущее значение для текущего и предложенного ? на значение функции правдоподобия для двух ? для того, чтобы получить ненормализованные значения апостериорного распределения (что мы и используем для реальных вычислений), и разделить одно на другое для того, чтобы получить вероятность принятия предложенного значения.
В четвёртой колонке представлен след выборки, то есть – значения ?, сэмплы, полученные на основе модели. Здесь мы показываем каждый сэмпл, вне зависимости от того, был ли он принят или отвергнут (в таком случае линия не меняется).
Обратите внимание на то, что мы всегда двигаемся к сравнительно более правдоподобным значениям ? (в плане плотности их апостериорного распределения вероятности) и лишь иногда – к сравнительно менее правдоподобным значениям ?. Например, как в итерации №1 (номера итераций можно видеть в верхней части каждого ряда изображений по центру.
?Листинг 6
np.random.seed(123)
sampler(data, samples=8, mu_init=-1., plot=True);






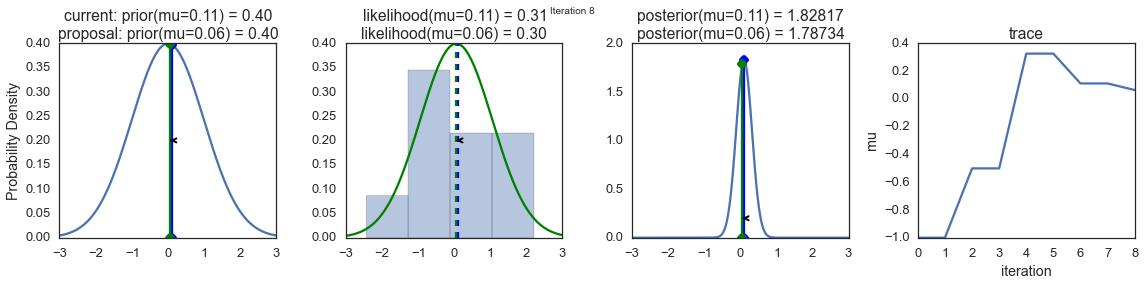
Визуализация MCMC
Замечательное свойство MCMC заключается в том, что для получения нужного результата вышеописанный процесс просто нужно достаточно долго повторять. Сэмплы, генерируемые таким образом, берутся из апостериорного распределения вероятностей исследуемой модели. Есть строгое математическое доказательство, которое гарантирует, что это именно так и будет, но здесь я не хочу вдаваться в такие подробности.
Для того, чтобы получить представление о том, какие именно данные производит система, давайте сгенерируем большое количество сэмплов и представим их графически.
?Листинг 7
posterior = sampler(data, samples=15000, mu_init=1.)
fig, ax = plt.subplots()
ax.plot(posterior)
_ = ax.set(xlabel='sample', ylabel='mu');
Визуализация 15000 сэмплов
Это обычно называют следом выборки. Теперь, для того, чтобы получить приближённое значение апостериорного распределения вероятностей (собственно говоря, это нам и нужно), достаточно построить гистограмму этих данных. Важно помнить, что, хотя полученные данные похожи на те, сэмплированием которых мы занимались для подгонки модели, это два разных набора данных.
Нижеприведённый график отражает наше представление о том, каким должно быть mu. В данном случае так получилось, что он тоже демонстрирует нормальное распределение, но для другой модели он мог бы иметь совершенно иную форму, нежели график функции правдоподобия или априорного распределения вероятностей.
?Листинг 8
ax = plt.subplot()
sns.distplot(posterior[500:], ax=ax, label='estimated posterior')
x = np.linspace(-.5, .5, 500)
post = calc_posterior_analytical(data, x, 0, 1)
ax.plot(x, post, 'g', label='analytic posterior')
_ = ax.set(xlabel='mu', ylabel='belief');
ax.legend();
Аналитическое и оценочное апостериорные распределения вероятностей
Как можно заметить, следуя вышеописанному методу, мы получили сэмплы из того же распределения вероятностей, что было получено аналитическим путём.
Ширина диапазона для выборки предлагаемых значений
Выше мы задали интервал, из которого выбираются предлагаемые значения, равным 0,5. Именно это значение оказалось очень удачным. В общем случае, ширина диапазона не должна быть слишком маленькой, иначе сэмплинг будет неэффективным, так как для исследования пространства параметров понадобится слишком много времени и модель будет демонстрировать типичное для случайного блуждания поведение.
Вот, например, что мы получили, установив параметр proposal_width в значение 0,01.
?Листинг 9
posterior_small = sampler(data, samples=5000, mu_init=1., proposal_width=.01)
fig, ax = plt.subplots()
ax.plot(posterior_small);
_ = ax.set(xlabel='sample', ylabel='mu');
Результат использования слишком маленького диапазона
Слишком большой интервал тоже не подойдёт – предлагаемые для перехода значения будут постоянно отвергаться. Вот, что будет, если установить proposal_width в значение 3.
?Листинг 10
posterior_large = sampler(data, samples=5000, mu_init=1., proposal_width=3.)
fig, ax = plt.subplots()
ax.plot(posterior_large); plt.xlabel('sample'); plt.ylabel('mu');
_ = ax.set(xlabel='sample', ylabel='mu');
Результат использования слишком большого диапазона
Однако, обратите внимание на то, что мы здесь продолжаем брать сэмплы из целевого апостериорного распределения, как гарантирует математическое доказательство. Но такой подход менее эффективен.
?Листинг 11
sns.distplot(posterior_small[1000:], label='Small step size')
sns.distplot(posterior_large[1000:], label='Large step size');
_ = plt.legend();
Маленький и большой размер шага
С использованием большого количества итераций, то, что у нас получится, в конечном счёте, будет выглядеть как настоящее апостериорное распределение. Главное то, что нам нужно, чтобы сэмплы были независимы друг от друга. В данном случае это, очевидно, не так. Для того, чтобы оценить эффективность нашего сэмплера, можно воспользоваться показателем автокорреляции. То есть – узнать, как образец i коррелирует с образцом i-1, i-2, и так далее.
?Листинг 12
from pymc3.stats import autocorr
lags = np.arange(1, 100)
fig, ax = plt.subplots()
ax.plot(lags, [autocorr(posterior_large, l) for l in lags], label='large step size')
ax.plot(lags, [autocorr(posterior_small, l) for l in lags], label='small step size')
ax.plot(lags, [autocorr(posterior, l) for l in lags], label='medium step size')
ax.legend(loc=0)
_ = ax.set(xlabel='lag', ylabel='autocorrelation', ylim=(-.1, 1))
Автокорреляция для маленького, среднего и большого размера шага
Очевидно то, что хотелось бы иметь интеллектуальный способ автоматического определения подходящего размера шага. Один из обычно используемых методов заключается в такой подстройке интервала, из которого выбирают значения, чтобы примерно 50% предложений отбрасывалось. Что интересно, другие алгоритмы MCMC, вроде Гибридного метода Монте-Карло (Hamiltonian Monte Carlo) очень похожи на тот, о котором мы говорили. Главная их особенность заключается в том, что они ведут себя «умнее», когда выдвигают предложения для следующего «прыжка».
Переходим к более сложным моделям
Теперь легко представить, что мы могли бы добавить параметр sigma для среднеквадратического отклонения и следовать той же процедуре для второго параметра. В таком случае генерировались бы предложения для mu и sigma, но логика алгоритма практически не изменилась бы. Или мы могли бы брать данные из очень разных распределений вероятностей, вроде биномиального, и, продолжая пользоваться тем же алгоритмом, получали бы правильное апостериорное распределение вероятностей. Это просто здорово, это – одно из огромных преимуществ вероятностного программирования: достаточно определить желаемую модель и позволить MCMC заниматься байесовским выводом.
Вот, например, нижеприведённую модель можно очень легко описать средствами PyMC3. Так же, в этом примере мы пользуемся Метрополис-сэмплером (с автоматически настраиваемой шириной диапазона, из которого берутся предлагаемые значения) и видим, что результаты практически идентичны. Можете с этим поэкспериментировать, поменять распределение, например. В документации по PyMC3 можно найти более сложные примеры и сведения о том, как всё это работает.
?Листинг 13
import pymc3 as pm
with pm.Model():
mu = pm.Normal('mu', 0, 1)
sigma = 1.
returns = pm.Normal('returns', mu=mu, sd=sigma, observed=data)
step = pm.Metropolis()
trace = pm.sample(15000, step)
sns.distplot(trace[2000:]['mu'], label='PyMC3 sampler');
sns.distplot(posterior[500:], label='Hand-written sampler');
plt.legend();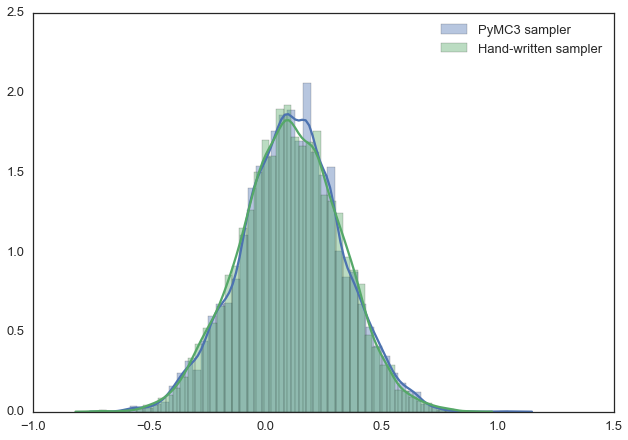
Результаты работы различных сэмплеров
Подведём итоги
Надеемся, мы смогли донести до вас сущность MCMC, Метрополис-сэмплера, вероятностного вывода, и теперь у вас появилось интуитивное понимание всего этого. А значит – вы готовы к чтению материалов по данному вопросу, насыщенных математическими формулами. Там вы сможете найти все те детали, которые мы обошли здесь стороной для того, чтобы не скрыть за ними самого главного.
О, а приходите к нам работать? :)wunderfund.io — молодой фонд, который занимается высокочастотной алготорговлей. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Присоединяйтесь к нашей команде: wunderfund.io
Комментарии (22)

varagian
18.03.2016 22:17+1Отличный выбор статьи для перевода — было здорово в похожем ключе разобрать-описать задачку в духе: "А вот тут аналитического решения нет (потому что распределения не сопряженные итд), и нам ничего не остается, кроме как использовать MCMC и вот смотрите, как здорово получается"
В догонку: ELI5 (с веселым матаном и картинками) MCMC можно прочитать тут.

sim0nsays
20.03.2016 20:32+1Спасибо за пост, прочитал и кажется что-то понял про MCMC!
Небольшой вопрос — выглядит, что начальная точка может сбить сэмплинг posterior distribution, если она далека от его центра. В посте немного говорится о выборе proposal width, но ведь и начальную точку надо где-то выбирать. Или типа на практике где значение по умолчанию довольно очевидно?
sim0nsays
20.03.2016 20:57+3И вопрос немного в сторону — а как вообще не практике выбирают prior distribution для параметров, т.е. распределение до того как мы вообще хоть какие-то данные видели? В статье так весело сказали, что мол возьмем для мю нормальное с центром в нуле и с неким std, но разве это не означает уже некоторое откуда-то взявшееся предположение?
Какие распределения используют для prior на практике и почему?
DaylightIsBurning
21.03.2016 14:07Присоединяюсь, этот вопрос в статье совсем не раскрыт, неясно даже, откуда берутся
prior_currentprior_proposalи для чего нужны. Что если взять их равными 1.0?
ffriend
21.03.2016 18:04+3В статье так весело сказали, что мол возьмем для мю нормальное с центром в нуле и с неким std, но разве это не означает уже некоторое откуда-то взявшееся предположение?
Означает, в этом и смысл байесовской статистики. Например, мы хотим оценить результат президентских выборов, в которых участвует 2 кандидата — А и Б. А — политик с 20-летним стажем, никогда президентом не избирался, но всегда находился в "верхах", часто появляется на радио и ТВ. Б — тоже политик, но с гораздо меньшим стажем, практически неизвестный широкому кругу избирателей. Мы ещё ничего не знаем о текущих предпочтениях избирателей, но можем предположить, что кандидат А имеет примерно в 3 раза больше шансов победить, чем кандидат Б. Вот это предположение и будет нашей априорной вероятностью, т.е.
P(A wins) = theta = 0.75 P(B wins) = 1 - theta = 0.25
Здесь мы моделируем выборы через распределение Бернулли, т.е. простое бинарное распределение с единственным параметромtheta, показывающим вероятность победы кандидата А (вероятность победы кандидата Б, соответсвенно, равна1 - theta). Если бы кандидатов было больше 2, то нам пришлось бы использовать уже категориальное распределение.
А вот если мы после нашего предположения проведём ещё соцопрос, то его результаты и будут нашим evidence (всё-таки бьёт по ушам это "свидетельство"). И если прогнать априорное распределение и evidence через формулу Байеса, то как раз и получится апостериорное распределение.
Однако, если мы хотим быть тру байесовцами, то мы никак не можем считать theta константой, а обязательно должны сделать его случайной переменной! Это, в общем-то, вполне логично: наша оценка победы кандидата А на выборах вряд ли равна строго 0.75. Скорее, мы верим, что скорее всего его шансы равны 0.75, но готовы согласиться (хотя и с меньшей вероятность) и на 0.7 или 0.8, или даже, чем чёрт не шутит, на 0.5, хотя в это мы верим и меньше. Т.е. наша предварительная вера сама по себе является непрерывной случайной переменной.
Вопрос: какое распределение будет иметь параметр theta (теперь его уже корректней звать случайной переменной theta — ещё одна отличительная особенность в терминологии частотного и байесовского подходов)? Отбросим на секунду выборы и возьмём монетку, потому что её мы можем бросать сколько угодно, а вот кидать кандидатов в президенты, пожалуй, не стоит. Допустим, мы бросили монетку 10 раз, 7 из которых она упала орлом — записываем: theta[1] = 0.7. theta[1] — это наша первая оценка параметра theta. Повторим эксперимент ещё 9 раз — получим, скажем, такой набор измерений параметра: theta[1:10] = [.8, .6, .9, .8, .7, .5, .8, .8, .7, .9]. Если попробовать сгладить и нарисовать такое распределение, то получится как-то так:
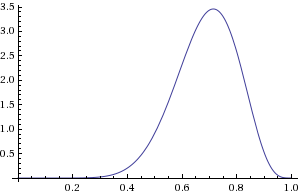
При этом такое распределение как раз и соответсвует нашей оценке для возможных параметров theta — наиболее вероятно, что theta лежит в окресности значения 0.75, с меньшей вероятность — больше или меньше этого значения. К нашему набору экспертиментов можно подойти формально через биномиальное распределение (которое является всего лишь распределением не одного, а нескольких бросков монетки) как это описано в Википедии, а можно сразу заметить, что функция плотности вероятности для theta уж очень напоминает Beta распределение. Тут важно понимать, что это не задача предполагает точно и однозначно Beta распределение, а это мы его выбрали, потому что удобно.
Возвращаясь к выборам и собирая всё вместе, получаем такую модель. Есть 2 переменные: theta — вероятность победы кандидата А, и x — количество голосов за каждого кандидата, которое мы узнаем после опроса. Есть 4 вероятности: P(theta) — предварительная вероятность победы кандидата А, т.е. наша вера до соцопроса; P(x|theta) — правдоподобие, вероятность получить такие данные при таком значении theta; P(x) — вероятность получить такие данные вообще и наша искомая P(theta|x) — вероятность победы кандидата A уже после соцопроса.
Как видите, мы выбрали априорное распределение не "потому что", а "для того, чтобы". Если бы кандидатов у нас было больше, то вместо бета-распределения мы бы могли взять распределение Дирехле. Если бы моделировали отклонение от графика для автобуса, то могли бы предположить, что оно примерно нормальное. Или равномерное, или то же бета — тут уже зависит от того, что подсказывает интуиция (или прежний опыт или общие соображения) и с чем нам удобней работать.DaylightIsBurning
21.03.2016 18:20В контексте MCMC нужно все же отметить, что выбор a priori не влияет на полученное равновесное a posteriory распределение, а только лишь на скорость сходимости семлирования. Чем ближе наше a priory к a posteriory, тем меньше МСМС шагов нужно будет просчитать для получения результата с заданной точностью. На примере данной статьи, можно было вообще приравнять
prior_current = prior_proposal = 1и всё будет работать аналогично (часто так и делают). Выбор начального значения mu_current вообще значения не имеют, так как на практике первые N шагов выкидывают.
ffriend
21.03.2016 23:05Уф, честно говоря, я не особо понял ваш комментарий, поэтому давайте по частям.
выбор a priori не влияет на полученное равновесное a posteriory распределение
Сам MCMC имеет мало отношения к априорному и апостериорному распределению, как и вообще к байесовской статистике. Если брать конкретно алгоритм Метрополиса-Хастинга (кстати, кто знает, где ударение в имени "Метрополис"?), то ему для работы нужно только уметь получать плотность вероятности в каждой точке. Что это за вероятность — ему глубоко всё равно, но чаще всего это правдоподобие данных, т.е.P(x | theta), гдеtheta— это параметры, которые алгоритм варьирует. Соответсвенно, скорость сходимости зависит от того, насколько мы сходу угадали значения параметровtheta.
Априорная вероятность — это немного другое. Автор этой статьи изначально исходит из задачи статистического вывода в байесовских сетях, которые постоянно используют понятия априорного и апостериорного распределения. И вот в таких сетях априорное распределение очень даже влияет на апостериорное: во-первых, зачастую одно определяет форму другого, а во-вторых, если априорная "вера" высока, то она может очень сильно повлиять на параметры апостериорного распределния (если "вера" слаба, то апостериорное распределение в основном определяется данными, что совпадает с частотным подходом).
Т.е. теорема Байеса (вместе с априорным и апостериорным распределением) и MCMC — это ортогональные понятия, и даже на странице про алгоритм Метрополиса-Хастинга в Википедии нет ни одного упоминания про "prior distribution".
можно было вообще приравнять prior_current = prior_proposal = 1 и всё будет работать аналогично
Опять же, не понял, что вы хотели сказать.prior_currentиprior_proposal— это вычисляемые значения, приравнивать их чему-то как бы нет смысла. Возможно, вы имели ввидуmu_currentиmu_proposal, из которых они вычисляются. Но и их приравнивать чему-то нет смысла, разве что на шаге инициализации:mu_proposalвычисляется как случайное отклонение отmu_current, аmu_current, соотвественно, принимает или не принимает новое значениеmu_proposalна каждом новом шаге. Если вдруг мы в коде по ошибке сделаемmu_current == mu_proposal, то наш алгоритм вообще не будет двигаться и никогда не найдёт… эээ, назовём этоmu_optimal.
В общем, наверное я что-то не так понял, поэтому появните, пожалуйста.DaylightIsBurning
22.03.2016 01:19скорость сходимости зависит от того, насколько мы сходу угадали значения параметров theta.
При генерации Марковой Цепи с помощью Metropolis-Hastings форма a priori не влияет на форму a posteriori (при условии достаточного семплинга), поэтому часто выбирают a priori = 1 (см §1.4). Обычно Metropolis-Hastings используется для того, что бы получить p(theta | x), то есть плотность вероятности параметров, принимая во внимание данные. Скорость сходимости этой процедуры от начального значения параметра theta (`mu_init`) почти не зависит, а зависит от выбранного шага (`proposal_width`) и того, на сколько удачно выбрана форма a priori. В рассматриваемом примере форма a priori задана формой выбранного (нормального) распределения и его параметрами
` mu_proposal = norm(mu_current, proposal_width).rvs()… prior_current = norm(mu_prior_mu, mu_prior_sd).pdf(mu_current) prior_proposal = norm(mu_prior_mu, mu_prior_sd).pdf(mu_proposal) `. Тут важно обратить внимание, что mu_proposal выбрано не как-нибудь, а из нормального распределения! Для того, что бы "скомпенсировать" этот конкретный выбор, нужно посчитать `prior_current/prior_proposal`
Замена кода из статьи на
` mu_proposal = random.uniform(mu_current-proposal_width, mu_current+proposal_width)… prior_current = 1 prior_proposal = 1 `
, не повлияет на результат семплинга, кроме той части, что нужно будет сделать несколько больше шагов. Чем ближе a priori и a posteriori, тем меньше шагов понадобится (при прочих равных) для что бы получить a posteriori с необходимой точностью.ffriend
22.03.2016 02:38Ну вот, так гораздо понятней. Только, боюсь, вы не совсем поняли смысл статьи (ну или я его совсем-совсем не понял).
A priori, про который вы говорите, относится к изначальным знаниям, которые позволяют оптимизировать сам алгоритм случайного блуждания. Дословно из статьи:
The a priori information gleaned from this analytical work can then be used to propose exactly those (large) moves which are compatible with the system.
Если следовать нотации из Википедии, Metropolis-Hastings работает с двумя распределениями: целевымPи вспомогательнымQ, из которого делается сэмплирование для определения направления и длины шага. A priori, про который вы говорите, помогает выбрать более оптимальную длину и направление, при этом, конечно, при большом количестве шагов его значение уменьшается.
Статья же концентрируется на распределениP. Более того, речь идёт о статистическом выводе в байесовских сетях. И вот в байесовских сетях есть своя a priori (в статье это априорное распределение значений параметра —P(theta)), которая никакого отношения к распределению Q (как и вообще к методам MCMC) не имеет (равно как и статья, на которую вы ссылаетесь, не имеет никакого отношения и ни разу не упоминает байесовские сети).
Весь алгоритм Метрополиса-Хастингса в рамках данной статьи сводится всего к паре шагов:
- Взять случайное значение mu, измерить, насколько он хорош.
- Передвинуться в случайном направлении (в данном конкретном случае — согласно нормальному распределению с центром в mu, но вообще на этом автор нигде не концентрируется).
- Если стало лучше, то остаться, если хуже, то с некоторой вероятностью вернуться назад.
- Повторить.
Соответсвенно,mu_currentиmu_proposalотносятся к значению параметра, который мы оптимизируем, и ну никак не могут быть равны.
sim0nsays
21.03.2016 19:33Спасибо за подробный ответ!
Хочу прояснить два момента
- В приведенных примерах есть какие-то данные до и после измерения (предшествующие рейтинги кандидатов, броски монетки итд). Но что делать, когда более ранних данных вообще нет? Вот только сейчас мы вообще получили нового кандидата, про которого ничего не знаем. Или начали сэмплировать новое распределение, которого раньше не видели (так что даже не знаем, в каком диапазоне может быть скажем среднее). Откуда берется интуиция в этом случае?
- Был сделан вывод, что в качестве prior для theta может подойти распределение, которое похоже на распределение случайного процесса с параметром theta. Вот здесь тонкий момент — то что есть некое распределение, у которого есть параметр, формально не дает права утверждать, что значение параметра распределено похожим образом. Или в этом и заключается стандартный баейсовский переход? Я не чтобы спорить, а чтобы понять.
DaylightIsBurning
21.03.2016 20:40начали сэмплировать новое распределение, которого раньше не видели
Любое предположение подойдёт, от него зависит только скорость сходимости. Можно попытаться проанализировать распределение и выбрать a priory и таким образом улучшить сходимость.
то что есть некое распределение, у которого есть параметр, формально не дает права утверждать, что значение параметра распределено похожим образом
А никто этого и не утверждает, в случае MCMC форма a priori не влияет на форму a posteriori.
ffriend
21.03.2016 23:56Но что делать, когда более ранних данных вообще нет?
Допустим, вы играете в русскую рулетку, но вам даже не сказали, сколько патронов в револьвере. Какова вероятность, что при первом нажатии курка револьвер выстрелит? А чёрт его знает, пятьдесят на пятьдесят! На практике, при отсутствии предварительных знаний, интуиции и общих соображений, равномерное распределение вероятности между всеми значениями работает довольно хорошо. Правда, в этом случае байесовская статистика полностью совпадает с частотной, которая опирается только на наблюдаемые данные (evidence).
Был сделан вывод, что в качестве prior для theta может подойти распределение, которое похоже на распределение случайного процесса с параметром theta.
Уф, нет, здесь что-то не так. Обычно при объяснении я сразу рисую графы, но рисовать на форуме довольно проблематично, поэтому попробую обойтись псевдографикой.
Для начала нужно понять отличительные черты нотации частотной и байесовской статистики. Частотники, когда описывают распределение случайной переменной Y, которая зависит от параметра theta, пишут:
")
в то время как байесовцы заменяют это на:
")
Эта незначательная, казалось бы, деталь раскрывает очень важное различие между двумя подходами: в отличие от частотников, байесовцы часто выносят параметры распределения в отдельную случайную переменную с собственным (возможно, тоже параметризованным) распределением. Т.е. в байесовском подходе мы уже работаем не с одной случайной переменнойY, а с двумя, связанными в граф:
Theta -> Y
Чтобы окончательно убрасть двоякость, заменимThetaнаX— по иксу сразу видно, что он — случайная переменная, а не просто константный параметр:
X -> Y
этот граф можно параметризовать двумя распределениями: посколькуXу нас ни от чего не зависит, то для него достаточно определитьP(X), а вотYзависит отX, так что для него понадобится условное распределение —P(Y | X). В общем случае, эти два распределения никак не связаны и представляют собой 2 абсолютно независимые функции. Однако, если мы ничего не знаем о системе, то и сделать с ней ничего не можем, поэтому обычно мы делаем несколько упрощений:
- считаем, что
P(X)иP(Y|X)принадлежат к какому-нибудь красивому и хорошо изученному распределению; - по возможности стараемся сделать
P(X)иP(Y|X)сопряжёнными.
Первое, обычно, не создаёт проблем, а вот если не получается применить второе упрощение, то и приходится использовать всякие приближённые методы вывода типа MCMC (или наоборот, использовать точный вывод в приближённых графах, чем и занимаются вариационные методы).
Я надеюсь, это отвечает на ваш вопрос?- считаем, что
- В приведенных примерах есть какие-то данные до и после измерения (предшествующие рейтинги кандидатов, броски монетки итд). Но что делать, когда более ранних данных вообще нет? Вот только сейчас мы вообще получили нового кандидата, про которого ничего не знаем. Или начали сэмплировать новое распределение, которого раньше не видели (так что даже не знаем, в каком диапазоне может быть скажем среднее). Откуда берется интуиция в этом случае?
ffriend
Таки первые 2 формулы должгы идти в обратном порядке — сначала формула Байеса, а потом — формула полной вероятности свидетельства ;)
eu-gen
Все верно, формулы 1 и 2 просто перепутаны. А я уже, было, подумал "Ах вот как она, формула Байеса, выглядит в n+1-мерном пространстве..."