
Это первая часть, вот вторая.
За всеми архитектурами нейронных сетей, которые то и дело возникают последнее время, уследить непросто. Даже понимание всех аббревиатур, которыми бросаются профессионалы, поначалу может показаться невыполнимой задачей.
Поэтому я решил составить шпаргалку по таким архитектурам. Большинство из них — нейронные сети, но некоторые — звери иной породы. Хотя все эти архитектуры подаются как новейшие и уникальные, когда я изобразил их структуру, внутренние связи стали намного понятнее.

У изображения нейросетей в виде графов есть один недостаток: граф не покажет, как сеть работает. Например, вариационный автоэнкодер (variational autoencoders, VAE) выглядит в точности как простой автоэнкодер (AE), в то время как процесс обучения у этих нейросетей совершенно разный. Сценарии использования различаются еще сильнее: в VAE на вход подается шум, из которого они получают новый вектор, в то время как AE просто находят для входных данных ближайший соответствующий вектор из тех, что они “помнят”. Добавлю еще, что этот обзор не имеет цели объяснить работу каждой из топологий изнутри (но это будет темой одной из следующих статей).
Следует отметить, что не все (хотя и большинство) из используемых здесь сокращений общеприняты. Под RNN иногда понимают рекурсивные нейронные сети (recursive neural networks), но обычно эта аббревиатура означает рекуррентную нейронную сеть (recurrent neural network). Но и это еще не все: во многих источниках вы встретите RNN как обозначение для любой рекуррентной архитектуры, включая LSTM, GRU и даже двунапраленные варианты. Иногда похожая путаница происходит с AE: VAE, DAE и им подобные могут называть просто AE. Многие сокращения содержат разное количество N в конце: можно сказать “сверточная нейронная сеть” — CNN (Convolutional Neural Network), а можно и просто “сверточная сеть” — CN.
Составить полный список топологий практически невозможно, так как новые появляются постоянно. Даже если специально искать публикации, найти их может быть сложно, а некоторые можно просто упустить из виду. Поэтому, хотя этот список поможет вам создать представление о мире искусственного интеллекта, пожалуйста, не считайте его исчерпывающим, особенно, если читаете статью спустя долгое время после ее появления.
Для каждой из архитектур, изображенной на схеме, я привел очень короткое описание. Некоторые из них будут полезны, если вы хорошо знакомы с несколькими архитектурами, но не знакомы конкретно с этой.

Сети прямого распространения (Feed forward neural networks, FF or FFNN) и перцептроны (perceptrons, P) очень просты — они передают информацию от входа к выходу. Считается, что у нейронных сетей есть слои, каждый из которых состоит из входных, скрытых или выходных нейронов. Нейроны одного слоя между собой не связаны, при этом каждый нейрон этого слоя связан с каждым нейроном соседнего слоя. Простейшая мало-мальски рабочая сеть состоит из двух входных и одного выходного нейрона и может моделировать логический вентиль — базовый элемент цифровой схемы, выполняющий элементарную логическую операцию. FFNN обычно обучают методом обратного распространения ошибки, подавая модели на вход пары входных и ожидаемых выходных данных. Под ошибкой обычно понимаются различные степени отклонения выходных данных от исходных (например, среднеквадратичное отклонение или сумма модулей разностей). При условии, что сеть обладает достаточным количеством скрытых нейронов, теоретически она всегда сможет установить связь между входными и выходными данными. На практике использование сетей прямого распространения ограничено, и чаще они используются совместно с другими сетями.
Rosenblatt, Frank. “The perceptron: a probabilistic model for information storage and organization in the brain.” Psychological review 65.6 (1958): 386.
» Original Paper PDF

Сети радиально-базисных функций (radial basis function, RBF) — это FFNN с радиально-базисной функцией в качестве функции активации. Больше здесь нечего добавить. Мы не хотим сказать, что она не используется, но большинство FFNN с другими функциями активации обычно не выделяют в отдельные группы.
Broomhead, David S., and David Lowe. Radial basis functions, multi-variable functional interpolation and adaptive networks. No. RSRE-MEMO-4148. ROYAL SIGNALS AND RADAR ESTABLISHMENT MALVERN (UNITED KINGDOM), 1988.
» Original Paper PDF

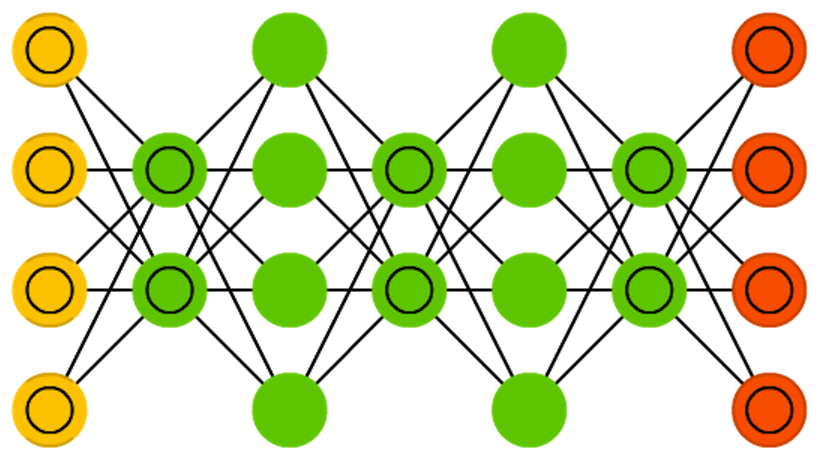
Нейронная сеть Хопфилда — полносвязная сеть (каждый нейрон соединен с каждым), где каждый нейрон выступает во всех трех ипостасях. Каждый нейрон служит входным до обучения, скрытым во время него и выходным после. Матрица весов подбирается таким образом, чтобы все «запомненные» вектора являлись бы для нее собственными. Однажды обученная одному или нескольким образам система будет сходиться к одному из известных ей образов, потому что только одно из этих состояний является стационарным. Отметим, что это не обязательно соответствует желаемому состоянию (к сожалению, у нас не волшебный черный ящик). Система стабилизируется только частично из-за того, что общая “энергия” или “температура” сети во время обучения постепенно понижается. Каждый нейрон обладает порогом активации, соизмеримым с этой температурой, и если сумма входных данных превысит этот порог, нейрон может переходить в одно из двух состояний (обычно -1 или 1, иногда 0 или 1). Узлы сети могут обновляться параллельно, но чаще всего это происходит последовательно. В последнем случае генерируется случайная последовательность, которая определяет порядок, в котором нейроны будут обновлять свое состояние. Когда каждый из нейронов обновился и их состояние больше не изменяется, сеть приходит в стационарное состояние. Такие сети часто называют ассоциативной памятью, так как они сходятся с состоянию, наиболее близкому к заданному: как человек, видя половину картинки, может дорисовать недостающую половину, так и нейронная сеть, получая на входе наполовину зашумленную картинку, достраивает ее до целой.
Hopfield, John J. “Neural networks and physical systems with emergent collective computational abilities.” Proceedings of the national academy of sciences 79.8 (1982): 2554-2558.
» Original Paper PDF

Цепи Маркова (Markov Chains, MC или discrete time Markov Chain, DTMC) — своего рода предшественники машин Больцмана (BM) и сетей Хопфилда (HN). В цепях Маркова мы задаем вероятности перехода из текущего состояния в соседние. Кроме того, это цепи не имеют памяти: последующее состояние зависит только от текущего и не зависит от всех прошлых состояний. Хотя цепь Маркова нельзя назвать нейронной сетью, она близка к ним и формирует теоретическую основу для BM и HN. Цепи Маркова также не всегда являются полносвязными.
Hayes, Brian. “First links in the Markov chain.” American Scientist 101.2 (2013): 252.
» Original Paper PDF

Машины Больцмана (Boltzmann machines, BM) во многом похожи на сети Хопфилда, но в них некоторые нейроны помечены как входные, а некоторые остаются скрытыми. Входные нейроны становятся выходными, когда все нейроны в сети обновляют свои состояния. Сначала весовые коэффициенты присваиваются случайным образом, затем происходит обучение методом обратного распространения, или в последнее время все чаще с помощью алгоритма contrastive divergence (когда градиент вычисляется при помощи марковской цепи). BM — стохастическая нейронная сеть, так как в обучении задействована цепь Маркова. Процесс обучения и работы здесь почти такой же, как в сети Хопфилда: нейронам присваивают определенные начальные состояния, а затем цепь начинает свободно функционировать. В процессе работы нейроны могут принимать любое состояние, и мы постоянно перемещаемся между входными и скрытыми нейронами. Активация регулируется значением общей температуры, при понижении которой сокращается и энергия нейронов. Сокращение энергии вызывает стабилизацию нейронов. Таким образом, если температура задана верно, система достигает равновесия.
Hinton, Geoffrey E., and Terrence J. Sejnowski. “Learning and releaming in Boltzmann machines.” Parallel distributed processing: Explorations in the microstructure of cognition 1 (1986): 282-317.
» Original Paper PDF

Ограниченная машина Больцмана (Restricted Boltzmann machine, RBM), как ни удивительно, очень похожа на обычную машину Больцмана. Основное отличие RBM от BM в том, что они ограничены, и следовательно, более удобны в использовании. В них каждый нейрон не связан с каждым, а только каждая группа нейронов соединена с другими группами. Входные нейроны не связаны между собой, нет соединений и между скрытыми нейронами. RBM можно обучать так же, как и FFPN, за небольшим отличием: вместо передачи данных вперед и последующего обратного распространения ошибки, данные передаются вперед и назад (к первому слою), а затем применяется прямое и обратное распространение (forward-and-back propagation).
Smolensky, Paul. Information processing in dynamical systems: Foundations of harmony theory. No. CU-CS-321-86. COLORADO UNIV AT BOULDER DEPT OF COMPUTER SCIENCE, 1986.
» Original Paper PDF

Автоэнкодеры (Autoencoders, AE) — нечто подобное FFNN, это скорее другой способ использования FFNN, чем принципиально новая архитектура. Основная идея автоэнкодеров — автоматическое кодирование (как при сжатии, а не при шифровании) информации, отсюда и название. Сеть напоминает по форме песочные часы, так как скрытый слой меньше, чем входной и выходной; к тому же она симметрична относительно средних слоев (одного или двух, в зависимости от четности/нечетности общего количества слоев). Самый маленьких слой почти всегда средний, в нем информация максимально сжата. Все, что расположено до середины — кодирующая часть, выше середины — декодирующая, а в середине (вы не поверите) — код. AE обучают методом обратного распространения ошибки, подавая входные данные и задавая ошибку равной разницу между входом и выходом. AE можно построить симметричными и с точки зрения весов, выставляя кодирующие веса равными декодирующим.
Bourlard, Herve, and Yves Kamp. “Auto-association by multilayer perceptrons and singular value decomposition.” Biological cybernetics 59.4-5 (1988): 291-294.
» Original Paper PDF
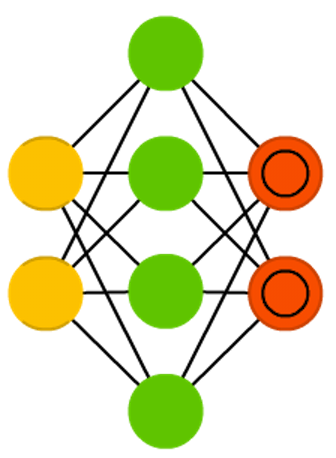
Разреженный автоэнкодер (Sparse autoencoder, AE) — в некоторой степени антипод AE. Вместо того чтобы обучать сеть представлять блоки информации на меньшем “пространстве”, мы кодируем информацию так, чтобы она занимала больше места. И вместо того чтобы заставлять систему сходиться в центре, а затем обратно расширяться до исходного размера, мы, наоборот, увеличиваем средние слои. Сети этого типа могут применяться для извлечения множества маленьких деталей из набора данных. Если бы мы стали обучать SAE тем же методом, что и AE, мы получили бы в большинстве случаев абсолютно бесполезную сеть, где на выходе получается ровно то же, что и на входе. Чтобы этого избежать, мы вместо входных данных выдаем на выходе входные данные плюс штраф за количество активированных нейронов в скрытом слое. Это в какой-то мере напоминает биологическую нейронную сеть (spiking neural network), в которой не все нейроны постоянно находятся в возбужденном состоянии.
Marc’Aurelio Ranzato, Christopher Poultney, Sumit Chopra, and Yann LeCun. “Efficient learning of sparse representations with an energy-based model.” Proceedings of NIPS. 2007.
» Original Paper PDF

Архитектура вариационных автоэнкодеров (VAE) такая же, как и у обычных, но обучают их другому — приблизительному вероятностному распределению входных образцов. Это в какой-то степени возвращение к истокам, так как VAE немножко ближе к машинам Больцмана. Тем не менее, они опираются на Байесовскую математику касательно вероятностных суждений и независимости, которые интуитивно понятны, но требуют сложных вычислений. Базовый принцип можно сформулировать так: принимать в расчет степень влияния одного события на другое. Если в одном месте происходит определенное событие, а другое событие случается где-то еще, то эти события вовсе не обязательно связаны. Если они не связаны, то распространение ошибки должно это учитывать. Это полезный подход, так как нейронные сети — своего рода огромные графы, и иногда бывает полезно исключить влияние одних нейронов на другие, проваливаясь в нижние слои.
Kingma, Diederik P., and Max Welling. “Auto-encoding variational bayes.” arXiv preprint arXiv:1312.6114 (2013).
» Original Paper PDF

Шумоподавляющие (помехоустойчивые) автоэнкодеры (Denoising autoencoders, DAE) — это такое AE, которым на подаем на вход не просто данные, а данные с шумом (например, делая картинку более зернистой). Тем не менее, ошибку мы вычисляем прежним методом, сравнивая выходной образец с оригиналом без шума. Таким образом, сеть запоминает не мелкие детали, а крупные черты, так как запоминание небольших деталей, постоянно меняющихся из-за шума, часто не приводит никуда.
Vincent, Pascal, et al. “Extracting and composing robust features with denoising autoencoders.” Proceedings of the 25th international conference on Machine learning. ACM, 2008.
» Original Paper PDF

Глубокие сети доверия (Deep belief networks, DBN) — сети, представляющие собой композицию нескольких RBM или VAE. Такие сети показали себя эффективно обучаемыми одна за другой, когда каждая сеть должна научиться кодировать предыдущую. Этот метод также называют “жадное обучение”, он заключается в принятии оптимального на данный момент решение, чтобы получить подходящий, но, возможно, не оптимальный результат. DBN могут обучаться методами contrastive divergence или обратным распространением ошибки и учатся представлять данные в виде вероятностной модели, в точности как RBM или VAE. Однажды обученную и приведенную к стационарному состоянию модель можно использовать для генерации новых данных.
Bengio, Yoshua, et al. “Greedy layer-wise training of deep networks.” Advances in neural information processing systems 19 (2007): 153.
» Original Paper PDF
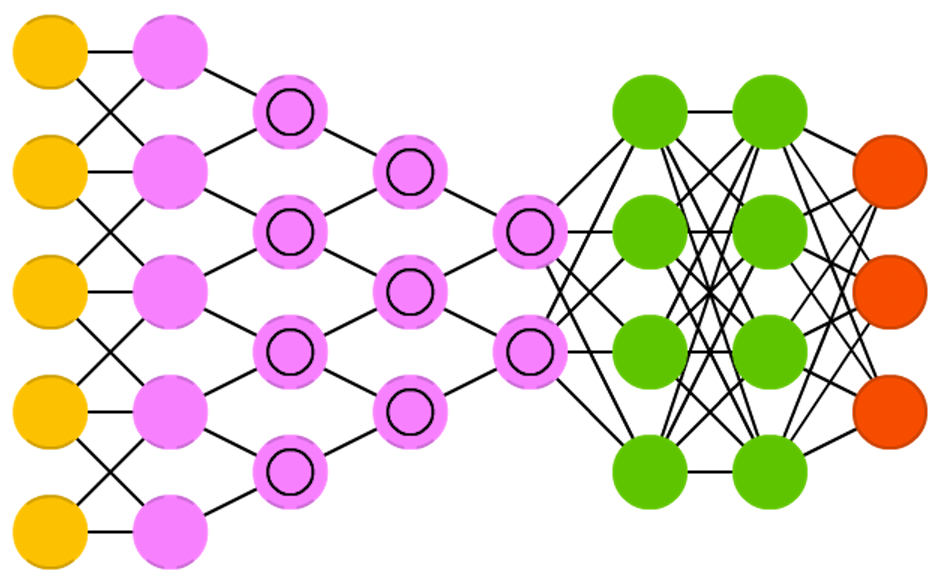
Свёрточные нейронные сети (convolutional neural networks, CNN) и глубокие свёрточные нейронные сети (deep convolutional neural networks, DCNN) кардинально отличаются от других сетей. Они используются в основном для обработки изображений, иногда для аудио и других видов входных данных. Типичным способом применения CNN является классификация изображений: если на вход подается изображение кошки, сеть выдаст «кошка», если картинка собаки — «собака». Такие сети обычно используют «сканер», не обрабатывающий все данные за один раз. Например, если у вас есть изображение 200х200, вы захотите строить слой сети из 40 тысяч узлов. Вместо это сеть считает квадрат размера 20х20 (обычно из левого верхнего угла), затем сдвинется на 1 пиксель и считает новый квадрат, и т.д. Заметьте, что мы не разбиваем изображение на квадраты, а скорее ползем по нему. Эти входные данные затем передаются через свёрточные слои, в которых не все узлы соединены между собой. Вместо этого каждый узел соединен только со своими ближайшими соседями. Эти слои имеют свойство сжиматься с глубиной, причём обычно они уменьшаются на какой-нибудь из делителей количества входных данных (например, 20 узлов в следующем слое превратятся в 10, в следующем — в 5), часто используются степени двойки. Кроме сверточных слоев есть также так называемые слои объединения (pooling layers). Объединение — это способ уменьшить размерность получаемых данных, например, из квадрата 2х2 выбирается и передается наиболее красный пиксель. На практике к концу CNN прикрепляют FFNN для дальнейшей обработки данных. Такие сети называются глубокими (DCNN), но названия их обычно взаимозаменяемы.
LeCun, Yann, et al. “Gradient-based learning applied to document recognition.” Proceedings of the IEEE 86.11 (1998): 2278-2324.
» Original Paper PDF

Развёртывающие нейронные сети (deconvolutional networks, DN), также называемые обратными графическими сетями, — это свёрточные нейронные сети наоборот. Представьте, что вы передаёте сети слово “кошка” и обучаете ее генерировать картинки кошек путем сравнения получаемых картинок с реальными изображениями кошек. DNN тоже можно объединять с FFNN. Стоит заметить, что в большинстве случаев сети передаётся не строка, а бинарный классифицирующий вектор: например, <0, 1> — это кошка, <1, 0> — собака, а <1, 1> — и кошка, и собака. Вместо слоев объединения, которые часто встречаются в CNN, здесь присутствуют аналогичные обратные операции, обычно интерполяцию или экстраполяцию.
Zeiler, Matthew D., et al. “Deconvolutional networks.” Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on. IEEE, 2010.
» Original Paper PDF
Читать продолжение.
О, а приходите к нам работать? :)wunderfund.io — молодой фонд, который занимается высокочастотной алготорговлей. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Присоединяйтесь к нашей команде: wunderfund.io
Комментарии (14)


HabraBabra
26.10.2016 21:43Пишите, «О, а приходите к нам работать? :)» причем в вакансиях ничего не написано)
xopxe
26.10.2016 21:44Как же не написано?)
Вот же две)HabraBabra
26.10.2016 21:47Смотрел исключительно на сайте хабра в профиле компании, а там ровно ноль. Почему то показалось, там принято размещать актуальную информацию. Пардон, ошибся.

Regis
27.10.2016 01:00+1А можете хотя бы где-то на сайте указать город? А то «Приятный офис в центре» без указания города звучит как издёвка :) Дэфолт-сити?




artem_guy
31.10.2016 15:43Довольно познавательно. Правда, практическое применение некоторых из архитектур, всё-таки, сомнительное :)

kryvichh
31.10.2016 15:43Спасибо большое!
Но вот как сейчас, глядя на это многообразие, выбирать сеть наиболее оптимальную для конкретной задачи?
Например, мы хотим сделать спелл-чекер русских слов на основе нейронной сети. Скормить ей словарь русских слов, чтобы она затем по последовательности букв на входе выдавала вероятность того, что это — нормальное слово. А еще лучше — предлагало вариант слова с исправлением ошибки. Какая тут сеть лучше подойдет?
samodum
Ооо, отлично! Спасибо огромное!