
Введение
Предсказуемая, но такая долгожданная мной смена времен года происходит прямо сейчас. Многие из знакомых предвкушают начало дачного сезона и активно обновляют свой инвентарь. Список очень нужных вещей, которые необходимо купить превышает все мыслимые бюджеты на десять лет вперед(ведь еще надо предусмотреть аренду товарного поезда для доставки всего необходимого) и на помощь приходят онлайн доски размещения объявлений. В надежде сэкономить, вы определяете список вещей, которые вам уже не пригодятся, размещаете их на продажу, и в предвкушении выгодной сделки начинаете ждать звонков и… Их нет. В чем дело? Оказывается, разборчивого покупателя интересует не только тот факт, что «газонокосилка находится в отличном состоянии», но и мощность двигателя, направление выброса травы, положение вала, время наработки и т.д. Не являясь спецом в садовом оборудовании, как вы могли все это предусмотреть? И вот вы начинаете просматривать другие объявления на схожую тему, а время идет и ваш человек по дачной логистике уже заказал для перевозок баржу и два грузовых самолета. На примере одной из рубрик доски объявлений мы рассмотрим построение прогнозной модели, которая помогла бы выяснить, что именно хотели бы узнать люди из описания вашего предложения, а так же дать очень примерную оценку числа переходов на ваше объявление.
Здесь я старался описать всю картину целиком, big picture, детали же доступны по ссылкам на код и данные в конце поста. В статье делаются следующие предположения:
- Число переходов обратно пропорционально времени продажи товара
- Для других городов(в статье только про столицу) и рубрик, анализ можно сделать по аналогии
Описание набора данных
С помощью python библиотеки urllib было получено 3879 записей с одного популярного сайта. Рубрика — собаки, город Москва. При отборе объявлений я старался оставить только некоммерческие предложения о передаче в добрые руки, поэтому порода конкретно не указывалась. Описание полей выборки:
- description — полный текст объявления
- identificator — номер объявления на сайте
- num_counts — число посещений объявления с начала его размещения
- price — цена, за которую предлагается купить животное. обычно, волонтеры ставят 100р. или вовсе не указывают цену
- start_date — дата, когда объявление было размещено
- title — название объявления, как оно выглядит на первой странице
Первые 5 записей:
Цель исследования
Разработать модель для прогнозирования зависимости числа просмотров в сутки от описания объявления и определить наиболее значимые слова для данной рубрики.
Предобработка данных
Поле num_counts содержит число кликов с начала публикации start_date . Поскольку у каждой записи разное время публикации, необходимо число посещений разделить на число дней, прошедших с момента публикации до момента получения данных, таким образом получим грубую оценку числа посещений в сутки, ее и будем прогнозировать. Для анализа текста используется модель bag of words. Итак, план:
- Стемминг, что бы исключить использование одного и того же слова, находящегося в разных формах как разных признаков
- Поле «date» содержит дату в форме строки, поэтому ее нужно перевести в правильный с точки зрения анализа формат
- В качестве признака берется поле description, поэтому текст необходимо перевести в представление bag of words и применить tf-idf. При этом из текста убираются stopwords: предлоги, вспомогательные частицы и т.д.
- После нескольких неудачных попыток восстановить регрессию между document-term matrix и средним числом посетителей, было принято решение разбить целевую переменную на интервалы(квартили) и рассматривать задачу классификации (отсюда и tf-idf). Т.е. на выходе модель будет прогнозировать интервал, где содержится средняя посещаемость для данного объявления. Преобразование в квартили производилось только на обучающей выборке, поэтому необходимо написать функцию, которая преобразовывает и тестовую выборку тоже. Преобразовывать всю выборку целиком нельзя, поскольку тогда тестовые данные будут косвенно участвовать в обучении
- Поле 'price' представляет собой цену за животное. Большие цены являются индикатором продажи породистого животного, нас же интересует некоммерческая деятельность, поэтому оставляем только те записи, для которых price < 500р. или не указан
- Разбиение на train\test. Причем на train будет проводится обучение и подбор параметров по сетке на кросс-валидации, а на test будет проверяться финальное качество. Основная метрика — accuracy
После всех преобразований на выходе получится document-term matrix и целевая переменная mean_count, разбитая на квартили(я выбрал число квартилей равным 5).
Разведочный анализ
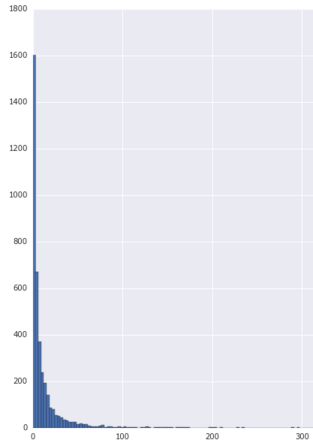
Число просмотров в сутки имеет степенное распределение, возможно эта рубрика в принципе не популярна:
Интересно посмотреть на диаграмму рассеяния между числом слов и числом просмотров:
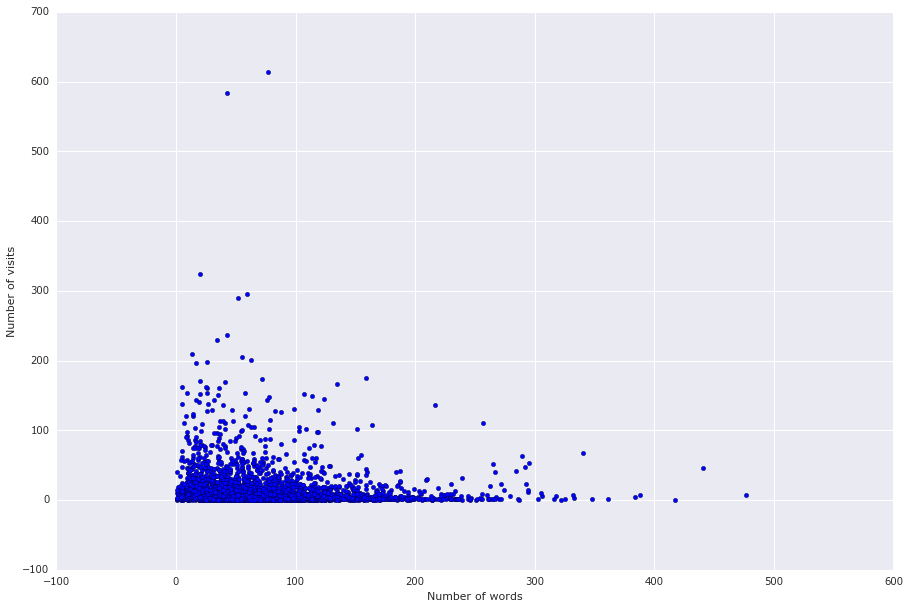
Видно, что более короткие объявления имеют большее число посещений. Здесь я бы предложил такое объяснение — в длинных объявлениях потенциальному хозяину часто описывается модель общения между ним и питомцем, например:
Если Вы любите домашний покой, то Ромуш тихо ляжет у Ваших ног и с удовольствием посмотрит с Вами фильм, который Вы потом непременно вместе обсудите за чашкой горячего шоколада с ватрушками. И с ним Вам будет очень уютно и тепло холодными вечерами. Если у Вас дети и Ваш дом похож на «детский дримлэнд», то Ромуш будет впереди всех бежать с криком «Банзай», тем самым забавляя детвору, которая будет просто пищать от восторга от их нового друга!
Поскольку все люди разные, такое объявление сразу может отсеять людей, представляющих свою коммуникацию по-другому. Не уверен, что это хорошо, поскольку модель общения это крайне субъективный взгляд волонтера и человек теряет интерес к объявлению не потому ему не подходит собака, а по необъективным причинам — примерил себе не ту модель. Вторая возможная причина — описание тяжелой жизни в приюте. Нет никаких сомнений, что жизнь там не сахар, но средний человек, прочитав такой текст может пережить сильный стресс и несознательно постарается забыть об этом, как о травмирующем воспоминании(это моя субъективная гипотеза).
Baseline для модели
Целевая переменная была разбита на 5 интервалов(читай — классов):
(13.599, 324] 454
[0.0888, 1.184] 454
(5.334, 13.599] 453
(2.436, 5.334] 453
(1.184, 2.436] 453
Т.е. есть 454 записей, где целевая переменная принимает значения из интервала (13.599, 324] и т.д. Если все время предсказывать каким-нибудь конкретным интервалом, то число правильных ответов будет примерно 0.2, выберем это значение как базовый уровень, качество которого мы хотели бы улучшить.
Модель
После нескольких экспериментов я выбрал в качестве классификатора случайный лес. Различные параметры настраивались через grid search на кросс-валидации с числом фолдов равным пяти. Обучение занимает приблизительно 15-20 минут на intel i7. Среднее качество на кросс-валидации по метрике accuracy составило 0.386, что почти в два раза больше предсказания константным значением. На отложенной выборке, которая ранее нигде не участвовала accuracy = 0.384 В таблицах ниже видно, что классификатор лучше различает крайние значения(интервалы [0.0888, 1.184] и (13.599, 324] ) и хуже смежные:

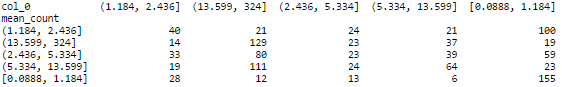
Возможно, качество модели может быть улучшено, если к тексту добавить фотографии. Для извлечения признаков из фото можно попробовать использовать сверточные нейронные сети, например, AlexNet.
Значимость слов
Посмотрим топ-50 слов, которые оказываются важными при классификации:

График не противоречит интуиции: людей интересует сколько животному лет и какой пол, ходит ли собака на поводке, подходит ли больше для семьи или одиноких людей, как ладит с другими питомцами. Можно заключить, что это тот минимум информации, который должен быть включен в объявление.
Исходники
Набор данных и ipython ноутбук
Заключение
Мы уже видели, что число просмотров для рубрики «животные в дар» не высоко, причем для приютов еще меньше, чем для частных лиц. Возможно это связанно с недостаточным информированием людей и различными предрассудками. Приведу некоторые факты:
- Объявления размещают волонтеры, чей интерес состоит в том, чтобы обеспечить как можно более лучшие условия для своего подопечного. Им не платят денег за то, как много животных удастся пристроить. Если у вас возникают проблемы, вы можете вернуть животное обратно. Поэтому у волонтера нет желания во чтобы то не стало впарить больного питомца. Если животное требует специальный уход, то такие вещи всегда оговариваются заранее, причем вы можете рассчитывать на всяческую(разумную) поддержку со стороны волонтера
- В приютах следят за эпидемиологической ситуацией, в противном случае, в условиях стресса и кормов среднего качества все животные давно бы умерли
- В приюте очень много животных, которые были домашними, но потерялись, сбежали от хозяев во время автомобильной аварии или какого-либо инцидента, или просто стали ненужными и неудобными. Т.е. это не дикие волки
- С каждым животным, которого вы видите на объявлении минимум раз в неделю, а то и больше, волонтеры проводят дрессировку — гуляют на поводке, учат командам, таким образом идет постоянный контакт с человеком
- Вы тоже можете принять в этом участие
- В приютах есть и кошки тоже
- В приютах есть собаки маленьких и средних размеров
Если когда-нибудь вы захотите завести себе животное, то обязательно проверьте, вдруг кто-то смотрит на вас с фотографии здесь:
Благодарности
Данный анализ проводился в рамках финального проекта курса «Машинное обучение и майнинг данных» ДПО ВШЭ, поэтому огромное спасибо нашим преподавателям за их терпение и труд, а так же моему научному руководителю.
P.S. Обо всех неточностях и опечатках пишите в личку!
UPD. Пользователь andraszsom в рамках соревнования на kaggle выложил анализ зависимости между различными исходами жизни в приюте(эвтаназия, или животное отдано на адаптацию в семью и т.п.) от породы, возраста и других признаков, линк.
Комментарии (4)


ProX_Alex
03.04.2016 17:42+1В заключении в Вас вселился волонтер и превратил статью про машинное обучение в призыв спасти животных.
Assistant_Branch_Manager
9851754
В моей задаче я разбил целевую переменную на пять интервалов, таким образом получил 5 классов документов — очень высокая посещаемость, очень низкая посещаемость и все, что посередине. Я рассуждал так: TFIDF считает насколько данное слово характерно для данного класса документов. Если я не буду разбивать целевую переменную на интервалы, то придется рассматривать задачу регрессии, но тогда с точки зрения tfidf я получу столько классов, сколько принимает уникальных значений мой y. Тогда, множитель TF останется без изменений, а IDF скорее всего будет просто константой, поскольку IDF = log (число документов в классе / (число документов в классе, в которых данное слово встречается + 1) ). Число документов в классе будет почти всегда единицей, из-за того, что в целевой переменной для регрессии почти все значения уникальны, так же и знаменатель (число документов в классе, в которых данное слово встречается + 1) = 2 почти всегда, поэтому IDF ~ log(0.5) и пользы от него никакой.
Я следовал рекомендациям sklearn. Допустим я хочу провести кросс-валидацию по 5 разбиениям: на 4/5 частях от всей выборки я обучаюсь, на 1/5 проверяю качество модели, и так 5 раз. tf-idf настраивается только на обучающей выборке (та, которая 4/5), а на тестовой выборке (та, которая 1/5) только применяет преобразование, т.е. тест не участвует в обучении.