
Недавно мы рассказывали о последнем релизе СУБД InterSystems Cache 2015.1, в котором существенно улучшена производительность, реализована поддержка второй версии языка преобразования XML-документов XSL Transformations (XSLT) Version 2.0 и использование семафоров для синхронизации процессов в Cache и организации их взаимодействия между собой. Кроме того, в новом релизе Cache расширены возможности использования сценариев высокой доступности и поддерживается применение внешнего web-сервера NGINX для сервера приложений Cache. В этой статье мы поговорим о первом из перечисленных усовершенствований нашей СУБД, а именно о том, насколько после выхода нового релиза улучшается производительность Cache при работе на многопроцессорных серверах, оборудованных процессорами Intel Xeon E7 v2 (кодовое название Ivy Bridge-EX).
Эти процессоры, являющиеся самыми мощными в линейке Intel Xeon и рассчитанные на четырёх- и более процессорные системы, вышли около года назад. По сравнению с первым поколением Xeon E7 у них вдвое улучшена производительность, на 25% увеличен объём встроенного кэша, втрое максимальный объём поддерживаемой оперативной памяти и в четыре раза пропускная способность каналов ввода/вывода. Кроме того, благодаря использованию технологий защиты от сбоев, разработанных для процессоров Intel Itanium, серверы на базе Xeon E7 v2 обеспечивают доступность на уровне пяти девяток (99,999%). Процессор Xeon E7 содержит до 15 процессорных ядер, которые поддерживают по два потока команд и используют общую кэш-память третьего уровня (L3) объёмом до 37,5 Мбайт и до трёх линков QuickPath Interconnect (QPI). Четырехпроцессорные серверы, оборудованные этим процессором, масштабируются до 6 Тбайт оперативной памяти, а восьмипроцессорные – до 12 Тбайт оперативной памяти.
Для того чтобы оценить масштабируемость Cache 2015.1 при использовании процессоров Xeon E7 v2, компания InterSystems провела тестирование базы данных при обслуживании системы управления медицинскими записями (Electronic Medical Records, EMR) фирмы EPIC, которая используется в ряде крупнейших американских медицинских учреждений. Тесты показали, что Cache 2015.1 в сочетании с технологией Enterprise Cache Protocol (ECP) на серверах на базе Xeon E7 v2 способна обслуживать в секунду более 21 млн. запросов конечных пользователей к базе данных (мы называем этот показатель производительности Global References per Second или GREF). При этом более чем в три раза был улучшен результат, которого удалось добиться на Cache 2013.1 в сочетании с Xeon E5. Выбор для тестирования системы EMR объясняется тем, что медицинские учреждения наряду с финансовыми институтами, розничной торговлей и государственным сектором являются основными заказчиками InterSystems.
Трёхкратный рост производительности был получен благодаря следующим усовершенствованиям масштабируемости Cache 2015.1:
Тесты проводились с помощью копии реальной многотерабайтной базы данных, которую использует система EPIC EMR, обслуживающая сеть больниц Sanford Health. Sanford Health – одна из крупнейших медицинских организаций в США, которой принадлежит 43 госпиталя с 1400 врачами, и обеспечивающая лечение более 26 тысяч пациентов.
Эксперты по производительности Intersystems и Epic выполнили на многотерабайтной копии базы Sanford Health серию тестов для определения измеряемой в GREF производительности Cache 2015.1, а также протестировали работу той же базы данных с предыдущим релизом Cache 2013.1. Для генерации нагрузки, создаваемой запросами к базе данных от конечных пользователей, применялись специальные инструменты моделирования, разработанные Epic. При этом постепенно увеличивалось число конечных пользователей, обращающихся к базе данных. В тестах замерялись как показатели производительности GREF, так и величина задержки, т.е. насколько быстро база данных может обрабатывать серию сложных запросов.
 Для тестирования Cache 2015.1 использовался четырехпроцессорный сервер с процессорами Intel Xeon E7-4890 v2 с тактовой частотой 2,8 ГГц, а Cache 2013.1 работал на двухсокетном сервере с Intel Xeon E5-2680 2,7 ГГц. На обоих серверах работали Red Hat Enterprise Linux и VMware vSphere; они обладали необходимыми ресурсами вычислительной мощности, оперативной памяти и дисков, чтобы эти показатели не ограничивали масштабируемость систем или не замедляли реагирование базы данных на запросы. В качестве системы хранения использовался твердотельный массив.
Для тестирования Cache 2015.1 использовался четырехпроцессорный сервер с процессорами Intel Xeon E7-4890 v2 с тактовой частотой 2,8 ГГц, а Cache 2013.1 работал на двухсокетном сервере с Intel Xeon E5-2680 2,7 ГГц. На обоих серверах работали Red Hat Enterprise Linux и VMware vSphere; они обладали необходимыми ресурсами вычислительной мощности, оперативной памяти и дисков, чтобы эти показатели не ограничивали масштабируемость систем или не замедляли реагирование базы данных на запросы. В качестве системы хранения использовался твердотельный массив.
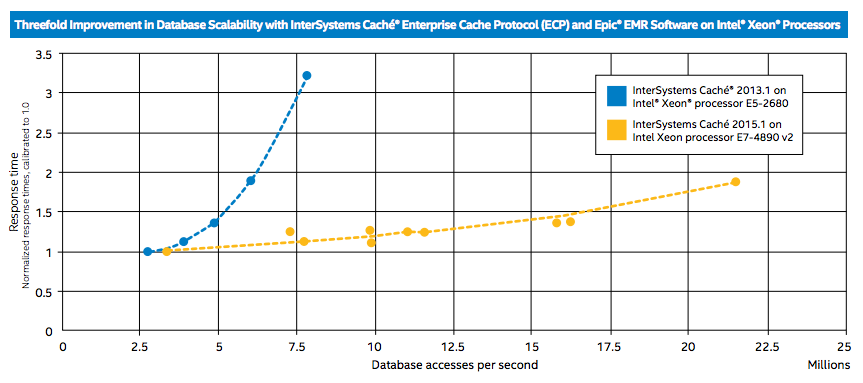
Как видно из графика, Cache 2015.1 на сервере с Intel Xeon E7-4890 v2 в тестах показала в три раза более высокую производительность, чем Cache 2013.1 на сервере с Intel Xeon E5-2680. Также график наглядно демонстрирует, что при росте числа запросов к базе данных задержки при использовании нового релиза Cache растут намного медленнее. Стоит отметить, что тестирование при более 22 млн. GREF не проводилось из-за ограничений аппаратной конфигурации сервера, а не достижения потолка производительности самой Cache 2015.1.
Тестирование продемонстрировало существенно улучшенную масштабируемость нового релиза Cache, обеспеченную как усовершенствованиями механизма распараллеливания самой базы данных, так и использованием преимуществ новой многоядерной архитектуры процессоров Intel Xeon E7 v2.
Спасибо за внимание, готовы ответить на ваши вопросы.

Эти процессоры, являющиеся самыми мощными в линейке Intel Xeon и рассчитанные на четырёх- и более процессорные системы, вышли около года назад. По сравнению с первым поколением Xeon E7 у них вдвое улучшена производительность, на 25% увеличен объём встроенного кэша, втрое максимальный объём поддерживаемой оперативной памяти и в четыре раза пропускная способность каналов ввода/вывода. Кроме того, благодаря использованию технологий защиты от сбоев, разработанных для процессоров Intel Itanium, серверы на базе Xeon E7 v2 обеспечивают доступность на уровне пяти девяток (99,999%). Процессор Xeon E7 содержит до 15 процессорных ядер, которые поддерживают по два потока команд и используют общую кэш-память третьего уровня (L3) объёмом до 37,5 Мбайт и до трёх линков QuickPath Interconnect (QPI). Четырехпроцессорные серверы, оборудованные этим процессором, масштабируются до 6 Тбайт оперативной памяти, а восьмипроцессорные – до 12 Тбайт оперативной памяти.
Для того чтобы оценить масштабируемость Cache 2015.1 при использовании процессоров Xeon E7 v2, компания InterSystems провела тестирование базы данных при обслуживании системы управления медицинскими записями (Electronic Medical Records, EMR) фирмы EPIC, которая используется в ряде крупнейших американских медицинских учреждений. Тесты показали, что Cache 2015.1 в сочетании с технологией Enterprise Cache Protocol (ECP) на серверах на базе Xeon E7 v2 способна обслуживать в секунду более 21 млн. запросов конечных пользователей к базе данных (мы называем этот показатель производительности Global References per Second или GREF). При этом более чем в три раза был улучшен результат, которого удалось добиться на Cache 2013.1 в сочетании с Xeon E5. Выбор для тестирования системы EMR объясняется тем, что медицинские учреждения наряду с финансовыми институтами, розничной торговлей и государственным сектором являются основными заказчиками InterSystems.
Трёхкратный рост производительности был получен благодаря следующим усовершенствованиям масштабируемости Cache 2015.1:
- Новый алгоритм распараллеливания для определённых приложений, благодаря которому при увеличении нагрузки и числа пользователей время реакции приложений остаётся на прежнем уровне;
- Cache 2015.1 использует специальные команды, минимизирующие задержки при работе приложений на многоядерных системах, связанные с неравномерным доступом к данным (NUMA, non-uniform memory access), поэтому при увеличении числа установленных в серверы процессоров время реакции приложений не увеличивается.
Как проводились тесты
Тесты проводились с помощью копии реальной многотерабайтной базы данных, которую использует система EPIC EMR, обслуживающая сеть больниц Sanford Health. Sanford Health – одна из крупнейших медицинских организаций в США, которой принадлежит 43 госпиталя с 1400 врачами, и обеспечивающая лечение более 26 тысяч пациентов.
Эксперты по производительности Intersystems и Epic выполнили на многотерабайтной копии базы Sanford Health серию тестов для определения измеряемой в GREF производительности Cache 2015.1, а также протестировали работу той же базы данных с предыдущим релизом Cache 2013.1. Для генерации нагрузки, создаваемой запросами к базе данных от конечных пользователей, применялись специальные инструменты моделирования, разработанные Epic. При этом постепенно увеличивалось число конечных пользователей, обращающихся к базе данных. В тестах замерялись как показатели производительности GREF, так и величина задержки, т.е. насколько быстро база данных может обрабатывать серию сложных запросов.
 Для тестирования Cache 2015.1 использовался четырехпроцессорный сервер с процессорами Intel Xeon E7-4890 v2 с тактовой частотой 2,8 ГГц, а Cache 2013.1 работал на двухсокетном сервере с Intel Xeon E5-2680 2,7 ГГц. На обоих серверах работали Red Hat Enterprise Linux и VMware vSphere; они обладали необходимыми ресурсами вычислительной мощности, оперативной памяти и дисков, чтобы эти показатели не ограничивали масштабируемость систем или не замедляли реагирование базы данных на запросы. В качестве системы хранения использовался твердотельный массив.
Для тестирования Cache 2015.1 использовался четырехпроцессорный сервер с процессорами Intel Xeon E7-4890 v2 с тактовой частотой 2,8 ГГц, а Cache 2013.1 работал на двухсокетном сервере с Intel Xeon E5-2680 2,7 ГГц. На обоих серверах работали Red Hat Enterprise Linux и VMware vSphere; они обладали необходимыми ресурсами вычислительной мощности, оперативной памяти и дисков, чтобы эти показатели не ограничивали масштабируемость систем или не замедляли реагирование базы данных на запросы. В качестве системы хранения использовался твердотельный массив.Результаты
Как видно из графика, Cache 2015.1 на сервере с Intel Xeon E7-4890 v2 в тестах показала в три раза более высокую производительность, чем Cache 2013.1 на сервере с Intel Xeon E5-2680. Также график наглядно демонстрирует, что при росте числа запросов к базе данных задержки при использовании нового релиза Cache растут намного медленнее. Стоит отметить, что тестирование при более 22 млн. GREF не проводилось из-за ограничений аппаратной конфигурации сервера, а не достижения потолка производительности самой Cache 2015.1.
Выводы
Тестирование продемонстрировало существенно улучшенную масштабируемость нового релиза Cache, обеспеченную как усовершенствованиями механизма распараллеливания самой базы данных, так и использованием преимуществ новой многоядерной архитектуры процессоров Intel Xeon E7 v2.
Спасибо за внимание, готовы ответить на ваши вопросы.
Комментарии (11)
ToSHiC
07.05.2015 20:20+4Стоит отметить, что тестирование при более 22 млн. GREF не проводилось из-за ограничений аппаратной конфигурации сервера, а не достижения потолка производительности самой Cache 2015.1.
Как нужно понимать эту фразу? Звучит как «кончился сервер, а не БД, работающая на нём», что слишком похоже на «mongodb работает быстро, если оперативной памяти в сервере больше, чем данных».
laphroaig
08.05.2015 00:00Лет десять назад работал с десктопным кластером — это примерно как если бы несколько десятков Raspberry Pi 2 засунули в стандартный десктоп-корпус, объединили 10Гб ethernet, а наружу вывели только 1Гб. В рамках проекта очень быстро научились обрабатывать входящий гигабитный трафик 2-3 процессорами, а остальные невозможно было задействовать. Видимо нечто подобное здесь имеется ввиду.
laphroaig
Мне одному кажется, что меня хотят
нае..обмануть?tsafin
Тут конечно есть некоторая методическая нечистота, и не получилось сравнения «яблок с яблоками». Думаю, данные сравнивались с теми что были в наличии с предыдущего тестирования годом а может и больше раньше (это пока спекуляции — спрошу внутри). Надо учитывать, что Epic постоянно занимается тестированием на новом интеловском и не интеловском железе (и в облаке), и они могут представить полный ряд референсных данных своего приложения на любом процессоре, любого предыдущего поколения.
Заранее оговорюсь, что в момент «предыдущего тестирования» (больше чем год назад) я работал на другой стороне и посему дальше комментарии про процессоры, а не базы данных.
Xeon E5-2680 является серверным 8-и ядерным процессором семейства SandyBridge-EP (2 процессора на мамке). Техпроцесс 32 нанометра.
Xeon E7-4890 является серверным 15-ядерным процессором семейства IvyBridge-EX (4 процессора на мамке), со следующим техпроцессом — 22нанометра.
IvyBridge является «компактизацией» SandyBridge, т.е. дизайн ядра процессора почти не менялся, вместо этого просто перешли на новый техпроцесс. И при всех прочих обстоятельствах, переход на новый техпроцесс считается успешным если удается при той же частоте дать 10-15% ускорения (ну или уменьшения потребления электричества при той же производительности).
Таким образом при почти одинаковой частоте, ядро-к-ядру, чисто за счет улучшения техпроцесса, могут давать ускорение 15-20%. Т.е. если при похожем увеличении параллелизма на разных, но близких процессорах, мы видим кривую роста на новой версии СУБД не повторяющую рост на предыдущей версии (пусть и с некоторым сдвигом), а более крутой рост (больше чем ожидаемые 15%), то прирост получен через алгоритмические оптимизации а не через улучшения в железе.
Попрошу показать мне не такой транспонированный график — прокомментирую больше.
laphroaig
Вы издеваетесь? Даже если сравнивать яблоки с яблоками, даже если эти яблоки одного «сорта», у любого технического специалиста должна возникнуть масса вопросов к методике тестирования и полученным результатам. На практике результаты любых бенчмарков, в реальных проектах, если и достижимы (что редкость), то только путем вложения колоссальных средств в адаптацию и оптимизацию существующих решений. Поэтому абсолютные результаты никому не интересны, кроме маркетологов, и результаты приведенные здесь вызывают соответствующую реакцию.
Я, возможно, чего-то недопонял, и 15% не бог весть какой прирост, но 16 ядер против 60… В реальных проектах 21 млн. persec можно смело уменьшать на порядок ( и даже в этом случае производительность впечатляет ). Вот если бы сравнивали с Cache 2013.1 на том же железе, и показали, что новая версия выжимает из железа все соки — это было бы интересно, а так все результаты в мусорку.
tsafin
Вы надеюсь понимаете, что речь идет о СУБД а не чисто счетной задаче из какого-нибудь набора SPECint? И количество и процессоров не самый определяющий фактор, и часто задачи, которые мы тут решаем скорее disk-bound, а не cpu-bound?
Самый большой вызов при проектировании алгоритмов на СУБД и/или сервере приложений (а Cache является одновременно и сервером базы данных и сервером приложений) получить хоть какой выигрыш от дополнительных ядер. В большинстве движков баз данных от добавления ядер вообще ничего не меняется, или меняется на единицы процентов, а с определенного предела даже может стать немного хуже.
На данном графике к порогу еще не приблизились.
Для более детальных комментариев, не руководствуясь догадками, мне нужно больше информации по природе алгоритма Epic EMR, надеюсь получить её вскоре и дать уже обоснованный ответ.
laphroaig
Я не пытаюсь доказать, что Cache 2015.1 по сравнению Cache 2013.1 не так хороша, как здесь представлено. Более того, хоть и работал с Cache последний раз более 5 лет назад, общая концепция мне очень нравится и некоторые идеи использую в своих проектах. Основная претензия в том, что представленные здесь результаты скорее дискредитируют в общем-то неплохой продукт.
Тогда почему подробно описаны процессоры, но практически ничего не сказано о дисках? Ок, твердотельные накопители, но сколько их? Возможно Вам очевидно, что наборы дисков на серверах идентичны, а мне нет. А сколько оперативной памяти? По максимуму 6 и 12 ТБ? А много терабайтная база это сколько? 2, 6, 12 или 100 ТБ? А «влезает» ли вся база или набор запрашиваемых данных данных в ОЗУ? А «сложные запросы» — это что? и т.д. и т.п.На все вопросы ответить невозможно, но я считаю, что лучше представить реальные данные, а не маркетинговую шелуху. Чем меньше возникает вопросов, тем больше вызывают доверие результаты, пусть даже они не такие крутые, как вам хотелось бы.
morisson
BTW, приходите на нашу конференцию на ритфест 21-22 мая. Можно будет задать вопросы лично инженерам и разработчикам InterSystems (кроме России будут инженеры из Австралии и Бельгии). Также, что, наверняка, не менее интересно, можно будет пообщаться с инженерами партнеров InterSystems в России, тех кто используют наши технологии для разработки информационных систем и делают на этом бизнес.
tsafin
И, laphroaig, также присоединяюсь к высказанному выше приглашению на фестиваль РИТ++ в рамках которого у нас будет проходить конференция CacheConf. Я вам, как бывшему пользователю Cache, даже могу дать скидочный код на весь фестиваль, про который мы писали здесь. На следующей неделе мы увеличим цены на билеты, т.ч. торопитесь — забронируйте билет по текущей цене! Обращайтесь!
tsafin
При внутреннем тестировании приложения, когда в игру вовлечены несколько вендоров (в данном случае 4: Epic Systems, InterSystems, Intel, Vmware) публикация таких подробных деталей конфигураций часто невозможна. Даже если пара вендоров даст добро на публикацию, любой другой легко может наложить вето. И в итоге получается такая, максимально обтекаемая форма, и график без цифр. Извините, в данной ситуации более подробных данных мы опубликовать не можем.
Если бы речь была о публичном бенчмарке, типа SPECint, HPC-H, и т.п. то вендор обязан был бы публиковать все подробности конфигураций и скриптов. Но в данном случае это внутренний бенчмарк, созданный Epic в 2002 году и применяемый им все это время для определения потолка производительности системы. Детали раскрывать не могу (да и не знаю многого), но высокоуровневое описание почитал на страницах проекта.
Epic использует ECP для горизонтального масштабирования системы. [Вы, как бывший пользователь Cache, знаете что это такое, для других поясню — это Enterprise Caching Protocol, протокол для передачи данных на удаленные монтировки, со встроенной синхронизацией и когерентностью]
На тестовой системе Epic трафик внешних «пользователей» (в рамках тестирования, конечно, генерируемый) распределяется по «более чем 50» (на начало 2014 года) серверам приложений. Сразу заметим, что максимальное количество ядер на 1 сервере приложений дела не играет, всегда можно рядом поставить еще десяток. В итоге мы имеем, скажем, 3000 тысячи ядер, так или иначе распределенных на машины.
На момент начала проекта Epic заметил, что чтобы они ни делали, сколько бы серверов приложений не ставили, они получают потолок в 7миллионов GloRef в секунду на 2013.1. В лучшем случае получалось увеличение responce time до неприемлемых значений. В рамках работ по оптимизации в 2015.1 было сделано несколько улучшений, больших и малых, но пару стоит упомянуть:
улучшен алгоритм синхронизации на Linux/x64 системах (как собственно для примитивов синхронизации, так и, например, для write daemon); и собственно ускорена работа всех элементов, вовлеченных в ECP взаимодействие, что позволило снять видимые ограничения в 7миллионов GloRef, и достичь 3-хкратного увеличения
В теории могли достичь и больших значений верхнего предела, но:
— этого значения более чем хватает на их прогнозируемые нагрузки на самых больших инсталляциях ; — и у них закончились возможности тестовой лаборатории :)
Т.е. конечно же, эта история больше про все агрегатные улучшения в движке Cache 2015.1 (на всех поддерживаемых аппаратных платформах, а не только x64), чем про специфичные x64 оптимизации. Но и про оптимизации тоже.
numberfive
плюсую. сравнение разных версий ПО на разном железе не говорит ничего ни о железе, ни о ПО.