
Здравствуйте, уважаемые читатели!
Несмотря на продолжающиеся праздники, мы не перестаем изучать зарубежную техническую мысль и время от времени сверяться с Радаром О'Рейли. В частности, нас заинтересовала опубликованная 4 мая статья Динеша Субхравети, повествующая о перспективах и проблемах виртуализации. В ней затронуты проблемы адекватного использования виртуализации, производительности распределенных систем, правильной работы с большими данными. Автор пытается исследовать вопрос о том, так ли незаменимы виртуальные машины, и найдется ли им место в завтрашнем дне. Поскольку на рынке существуют очень высокорейтинговые книги, так или иначе связанные с этой колоссальной темой, надеемся, что и предлагаемая статья покажется вам информативной и интересной. Если у вас появятся предложения об издании подобных книг — с удовольствием их выслушаем.

В настоящее время самыми высококлассными среди распределенных систем являются операционные системы для датацентров. Так, Hadoop развивается из фреймворка MapReduce в YARN – универсальную платформу для горизонтального масштабирования приложений.
Чтобы на таких платформах могла работать насыщенная экосистема, в которой нормально сосуществуют разнообразные программы, совершенно необходимо как следует изолировать эти приложения друг от друга. Механизм изоляции должен обеспечивать соблюдение лимита потребляемых ресурсов, устранять лишние программные зависимости между приложениями и хостом, гарантировать безопасность и приватность, локализовывать отказы и т.д. Данная проблема легко и красиво решается при помощи контейнеров. Однако нередко возникает вопрос: почему бы не задействовать виртуальную машину (VM)? В конце концов, все эти системы сталкиваются с одним и тем же набором проблем, которые решаются путем виртуализации традиционных корпоративных приложений.
Почему бы не использовать виртуальные машины?
Хотя YARN и подобные ей системы сталкиваются примерно с такими же проблемами, которые традиционно решаются на практике при помощи виртуальных машин, VM плохо подходят для горизонтального масштабирования по целому ряду причин.
Издержки
Ресурсы, потребляемые уровнем виртуализации, легко могут превратиться в существенный фактор, влияющий на общие издержки системы. Подобные накладные расходы могут и не играть существенной роли в традиционных приложениях, но когда мы имеем дело с большими распределенными приложениями, процент ресурсных накладных расходов быстро накапливается. Доли хост-памяти, теряемые на каждом узле в горизонтально масштабированном кластере, приводят к колоссальным растратам мощности. Более того, активное использование ресурсов виртуальными машинами препятствует плотным конфигурациям. Как правило, на одной физической машине могут работать лишь пара-тройка виртуальных машин.
Высокая стартовая задержка является основным источником издержек при применении виртуальных машин. В отличие от обычных приложений, которые запускаются, после чего просто продолжают работать, в новых экосистемах часто выполняются очень краткосрочные задачи. Если типичная задача в рамках крупного сильно распараллеленного задания выполняется в течение пары минут, то недопустимо тратить серьезный процент этого времени только на запуск виртуальной машины.
Несмотря на обширные оптимизации, предпринимаемые по всему стеку от железа и вплоть до прикладного уровня, издержки времени исполнения, возникающие из-за виртуальных машин, по-прежнему остаются проблемой. Хотя аппаратные возможности позволяют справиться с издержками виртуализации процессоров, проблема издержек остается острой при рабочих нагрузках, связанных, в первую очередь, с вводом/выводом. Так, в случае Hadoop виртуализованный стек ввода/вывода состоит из HDFS, гостевой файловой системы, гостевого драйвера, виртуального устройства, интерпретатора формата образов, файловой системы хоста, драйвера хоста и, наконец, физического устройства. Накапливающиеся издержки оказываются довольно существенными по сравнению с нативным исполнением.
Интересно, что результаты экспериментов по измерению производительности заданий, выполняемых на виртуализованном распределенном фреймворке типа Hadoop, могут наводить на неверные выводы. Если задание поставлено неграмотно, то кажется, что в виртуальной инфраструктуре оно порой выполняется даже быстрее, чем на нативном оборудовании. Однако это объясняется всего лишь более полной общей утилизацией ресурсов в пересчете на задание, а не каким-либо ускорением отдельных задач, обусловленным виртуализацией как таковой. Ведь правильно отрегулированные задачи в конечном итоге ограничены объемом ресурсов, предоставляемых базовым оборудованием.
Как гипервизор приложений играет в прятки
Как правило, приложения и операционные системы разрабатываются с расчетом на взаимодействие друг с другом. В контексте виртуализованного приложения гипервизор играет роль обычной операционной системы, управляющей физическим оборудованием. При этом разрушается симбиоз приложений и ОС, так как между ними возникает непрозрачный уровень виртуализации. Фактически же и хост, и гостевая система, и гипервизор выполняют лишь некоторое подмножество функций обычной операционной системы. Не столь важно, идет ли речь о гипервизоре типа А или типа B. Например, в случае Xen ядро Xen является гипервизором, Dom0 — хост-системой, а на DomUs работают гостевые системы. В Linux сама ОС Linux — это хост, Qemu/KVM — гипервизор, который, в свою очередь, обеспечивает работу гостевых ядер. Многоуровневая система программ, выполняющих низкоуровневые системные функции, неявным образом разрушает существующие интерфейсы приложений.
В приложениях, работающих на виртуальной машине, невозможно рассмотреть топологию и конфигурацию базовых физических ресурсов. Определенный компонент может «показаться» приложению непосредственно подключенным блочным устройством, а окажется файлом, расположенным на каком-то далеком NFS-сервере. Обфускация компьютерных и сетевых топологий осложняет планирование ресурсов на прикладном уровне. В случае Hadoop диспетчер ресурсов будет принимать неоптимальные планировочные решения, так как станет исходить из неверных представлений о физических ресурсах. Данные и сведения о локальности задач могут быть потеряны, но это еще полбеды; основные и дублирующие блоки могут оказаться в одном и том же отказавшем домене, из-за чего потеря данных будет безвозвратной.
Аналогично, гипервизор не позволяет «заглянуть» в приложение. Грубое представление о ресурсах при отсутствии информации об их семантике на прикладном уровне не позволяет выполнять многие варианты оптимизации. Например, считывание конкретного значения config из файла представляет собой операцию считывания, выполняемую блочным устройством на уровне виртуального оборудования. Без семантического контекста такие оптимизации, как предварительная выборка или кэширование, будут неэффективны. Другой пример: гипервизор резервирует большие области физической памяти, даже если она не используется гостевым приложением – дело в том, что гипервизор просто не может выявить неиспользуемые страницы памяти в гостевой системе.
Техническая поддержка
Большое количество виртуальных машин и работающих на их базе гостевых операционных систем – это обременительная техподдержка. Своевременное применение патчей безопасности к каждой отдельной виртуальной машине на просторах крайне динамичной инфраструктуры, где виртуальные машины создаются и удаляются буквально на лету, на большом предприятии может оказаться неподъемной задачей. Чрезмерное распространение виртуальных машин — еще одна проблема. Более того, фактическая стоимость лицензирования гостевых операционных систем может оказаться баснословной, особенно если речь идет о горизонтальном масштабировании.
Плохое сопряжение между приложением и операционной системой
Принято считать, что виртуализация помогает «отвязать» приложения от аппаратного обеспечения. Однако виртуализация приводит к образованию новых тесных связей между приложениями и их гостевыми операционными системами. Приложения запускаются как придатки виртуальной машины, что, в свою очередь, впутывает гостевую операционную систему в «черный ящик» виртуализованного образа. Можно выполнить миграцию всей виртуальной машины целиком – например, для ремонта оборудования — но невозможно обновить операционную систему, не нарушая функционирования работающего в ней приложения.
Поскольку приложение всегда привязано к гостевой операционной системе, те ресурсы, которые выделяются приложению, нельзя масштабировать по требованию. Сначала ресурсы добавляются в гостевую операционную систему, а она, в свою очередь, предоставляет их приложению. Однако, обычно гостевые операционные системы требуют перезагрузки для того, чтобы они могли распознать дополнительную память или новые ядра.
Виртуальные машины: неверная абстракция приложений
В конечном итоге, заказчика интересует исправно работающее приложение — а не операционные системы или виртуальные машины. Именно приложение требуется виртуализовать. Однако виртуальная машина не может непосредственно виртуализовывать приложения; чтобы восполнить этот недостаток, ей требуется дополнительная гостевая операционная система.

Для виртуализации приложения виртуальным машинам нужен дополнительный уровень с гостевой ОС
Иллюстрация автора.
В ходе многолетней работы промышленные и исследовательские комитеты посвятили немало совместных усилий решению проблем, связанных с виртуальными машинами. Предлагались многочисленные инновации. Некоторые из них даже развились в самостоятельные технологии. Однако при внимательном рассмотрении оказывается, что многие из этих инноваций не дают прогресса и перехода на качественно новый уровень по сравнению с контейнерами. Такие технологии в первую очередь направлены на устранение проблем, вызываемых самими виртуальными машинами. В принципе, огромный сегмент промышленных разработок ориентирован в неверном направлении: мы оптимизируем виртуальные машины, а не приложения. Такая фундаментально ошибочная модель позволяет добиться лишь относительной оптимизации. На следующих примерах рассмотрены лишь некоторые широко распространенные приемы, изобретенные для преодоления нестыковок между приложениями и виртуальными машинами.
Паравиртуализация
Паравиртуализация — один из наиболее всепроникающих способов оптимизации производительности виртуальных машин. Поскольку гипервизор не может напрямую просматривать гостевую операционную систему и ее приложения, а также влиять на нее или на них. Вместо этого он опирается на гостевую операционную систему, которая получает от него подсказки и выполняет предписанные им операции. Интерфейс между гостевой системой и гипервизором называется «API паравиртуализации» или «интерфейс гипервызовов». Разумеется, такая техника не будет работать со стандартными немодифицированными операционными системами. Осуществить такие изменения непросто, равно как и поддерживать их, адаптируя к изменяющимся версиям ядра.
Динамическое перераспределение памяти
Операционные системы очень рачительно распоряжаются физической памятью. Благодаря целому комплексу приемов (ленивое выделение, копирование при записи и др.) запросы о выделении памяти отклоняются во всех случаях кроме крайней необходимости. Для того, чтобы справиться с неспособностью гипервизора обращаться к внутренним компонентам операционной системы, применяется техника, именуемая «динамическое перераспределение памяти», она же – «раздувание» (ballooning). На гостевой системе задействуется специальный драйвер, позволяющий обнаруживать неиспользуемые области памяти и передающий эту информацию гипервизору. Неиспользуемые страницы памяти выжимаются из гостевой операционной системы и предоставляются хост-системе. К сожалению, в результате возникает неприятный побочный эффект: приложения периодически испытывают искусственный дефицит памяти. Данная техника допускает слабое решение, но все равно значительно уступает нативным механизмам ядра, централизованно распределяющим память.
Дедупликация
Применение нескольких экземпляров одной и той же гостевой операционной системы и ее стандартных сервисов в закрытой области адресного пространства каждой виртуальной машины приводит к тому, что некоторые образцы контента хранятся на нескольких страницах памяти. Для снижения подобных издержек была разработана техника онлайновой дедупликации страниц, называемая «совмещение общих страниц в памяти» (KSM). Однако, она чревата серьезными издержками производительности, особенно на тех хостах, где не предусмотрены ограничения памяти и используются конфигурации c NUMA (неравномерным доступом к памяти).
Раскрываем черный ящик
Виртуальные машины расценивают данные файловой системы как монолитные блобы образов, которые должна интерпретировать гостевая файловая система. Была выполнена определенная работа, призванная прояснить непрозрачную структуру образов виртуальных машин для индексирования, дедупликации, оффлайнового конкурентного пропатчивания базовых образов и т.д. Однако оказалось, что учесть все характерные особенности форматов образов, сегментов выделенных в них устройств, файловых систем и изменяющихся дисковых структур очень непросто.
Контейнеры: Экономная виртуализация для горизонтально масштабируемых приложений
Контейнеры — это очень своеобразный механизм виртуализации, направленный на непосредственную виртуализацию самих приложений, а не операционной системы. В то время как виртуальная машина предоставляет виртуальный аппаратный интерфейс, на котором может работать операционная система, контейнер предоставляет интерфейс виртуальной операционной системы, на котором могут работать приложения. Он отделяет приложение от его экосистемы посредством согласованного интерфейса виртуальной операционной системы, виртуализуя качественно определенный и семантически насыщенный интерфейс между приложением и операционной системой, а не между операционной системой и аппаратным обеспечением.
Контейнер состоит из множества пространств имен, каждое из которых проецирует подмножество ресурсов хоста на приложение по их виртуальным именам. Вычислительные ресурсы виртуализуются пространством имен процессов, сетевые ресурсы виртуализуются сетевым пространством имен, представление виртуальной файловой системы обеспечивается благодаря пространству имен монтирования и т.д. Поскольку контейнеризованные процессы нативно работают на хосте под управлением уровня виртуализации, те подсистемы, к которым применяется контейнерная виртуализация, могут быть адаптированы для использования в конкретном практическом контексте. Та степень, в которой хост и его ресурсы предоставляются в использование контейнеризованным процессом, может контролироваться с филигранной точностью. Например, контейнеризованное приложение может быть ограничено собственным приватным представлением о файловой системе, однако ему может быть разрешен доступ к сети хоста.
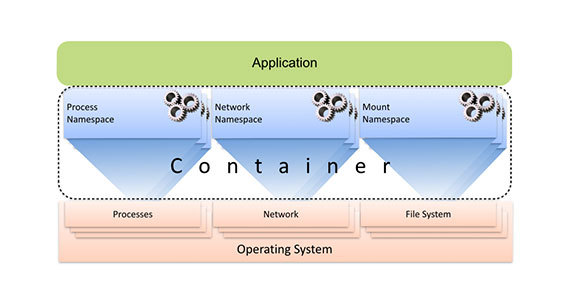
Контейнеры проецируют подмножество ресурсов хоста на приложение при помощи нескольких пространств имен. Иллюстрация автора
В отличие от работы с виртуальными машинами, при работе с контейнерами отсутствует уровень гостевой операционной системы, благодаря чему контейнеры получаются легковесными, дублирования функциональности не происходит, а издержки, связанные с промежуточными уровнями, исчезают практически полностью. При этом задержка при запуске также становится пренебрежимой, возможности масштабирования возрастают на порядок, а также упрощается управление системой.
Уже существуют первые варианты датацентров, использующих такие технологии, как YARN, Mesos и Kubernetes. Для обеспечения адекватной изоляции в этих датацентрах в качестве основного субстрата используются контейнеры. Это открывает путь к инновациям нового поколения, то есть, к истинному прогрессу.
Несмотря на продолжающиеся праздники, мы не перестаем изучать зарубежную техническую мысль и время от времени сверяться с Радаром О'Рейли. В частности, нас заинтересовала опубликованная 4 мая статья Динеша Субхравети, повествующая о перспективах и проблемах виртуализации. В ней затронуты проблемы адекватного использования виртуализации, производительности распределенных систем, правильной работы с большими данными. Автор пытается исследовать вопрос о том, так ли незаменимы виртуальные машины, и найдется ли им место в завтрашнем дне. Поскольку на рынке существуют очень высокорейтинговые книги, так или иначе связанные с этой колоссальной темой, надеемся, что и предлагаемая статья покажется вам информативной и интересной. Если у вас появятся предложения об издании подобных книг — с удовольствием их выслушаем.

В настоящее время самыми высококлассными среди распределенных систем являются операционные системы для датацентров. Так, Hadoop развивается из фреймворка MapReduce в YARN – универсальную платформу для горизонтального масштабирования приложений.
Чтобы на таких платформах могла работать насыщенная экосистема, в которой нормально сосуществуют разнообразные программы, совершенно необходимо как следует изолировать эти приложения друг от друга. Механизм изоляции должен обеспечивать соблюдение лимита потребляемых ресурсов, устранять лишние программные зависимости между приложениями и хостом, гарантировать безопасность и приватность, локализовывать отказы и т.д. Данная проблема легко и красиво решается при помощи контейнеров. Однако нередко возникает вопрос: почему бы не задействовать виртуальную машину (VM)? В конце концов, все эти системы сталкиваются с одним и тем же набором проблем, которые решаются путем виртуализации традиционных корпоративных приложений.
«Любые проблемы в информатике решаются добавлением еще одного уровня косвенности – кроме, разумеется, проблемы переизбытка уровней косвенности» — Дэвид Уилер.
Почему бы не использовать виртуальные машины?
Хотя YARN и подобные ей системы сталкиваются примерно с такими же проблемами, которые традиционно решаются на практике при помощи виртуальных машин, VM плохо подходят для горизонтального масштабирования по целому ряду причин.
Издержки
Ресурсы, потребляемые уровнем виртуализации, легко могут превратиться в существенный фактор, влияющий на общие издержки системы. Подобные накладные расходы могут и не играть существенной роли в традиционных приложениях, но когда мы имеем дело с большими распределенными приложениями, процент ресурсных накладных расходов быстро накапливается. Доли хост-памяти, теряемые на каждом узле в горизонтально масштабированном кластере, приводят к колоссальным растратам мощности. Более того, активное использование ресурсов виртуальными машинами препятствует плотным конфигурациям. Как правило, на одной физической машине могут работать лишь пара-тройка виртуальных машин.
Высокая стартовая задержка является основным источником издержек при применении виртуальных машин. В отличие от обычных приложений, которые запускаются, после чего просто продолжают работать, в новых экосистемах часто выполняются очень краткосрочные задачи. Если типичная задача в рамках крупного сильно распараллеленного задания выполняется в течение пары минут, то недопустимо тратить серьезный процент этого времени только на запуск виртуальной машины.
Несмотря на обширные оптимизации, предпринимаемые по всему стеку от железа и вплоть до прикладного уровня, издержки времени исполнения, возникающие из-за виртуальных машин, по-прежнему остаются проблемой. Хотя аппаратные возможности позволяют справиться с издержками виртуализации процессоров, проблема издержек остается острой при рабочих нагрузках, связанных, в первую очередь, с вводом/выводом. Так, в случае Hadoop виртуализованный стек ввода/вывода состоит из HDFS, гостевой файловой системы, гостевого драйвера, виртуального устройства, интерпретатора формата образов, файловой системы хоста, драйвера хоста и, наконец, физического устройства. Накапливающиеся издержки оказываются довольно существенными по сравнению с нативным исполнением.
Интересно, что результаты экспериментов по измерению производительности заданий, выполняемых на виртуализованном распределенном фреймворке типа Hadoop, могут наводить на неверные выводы. Если задание поставлено неграмотно, то кажется, что в виртуальной инфраструктуре оно порой выполняется даже быстрее, чем на нативном оборудовании. Однако это объясняется всего лишь более полной общей утилизацией ресурсов в пересчете на задание, а не каким-либо ускорением отдельных задач, обусловленным виртуализацией как таковой. Ведь правильно отрегулированные задачи в конечном итоге ограничены объемом ресурсов, предоставляемых базовым оборудованием.
Как гипервизор приложений играет в прятки
Как правило, приложения и операционные системы разрабатываются с расчетом на взаимодействие друг с другом. В контексте виртуализованного приложения гипервизор играет роль обычной операционной системы, управляющей физическим оборудованием. При этом разрушается симбиоз приложений и ОС, так как между ними возникает непрозрачный уровень виртуализации. Фактически же и хост, и гостевая система, и гипервизор выполняют лишь некоторое подмножество функций обычной операционной системы. Не столь важно, идет ли речь о гипервизоре типа А или типа B. Например, в случае Xen ядро Xen является гипервизором, Dom0 — хост-системой, а на DomUs работают гостевые системы. В Linux сама ОС Linux — это хост, Qemu/KVM — гипервизор, который, в свою очередь, обеспечивает работу гостевых ядер. Многоуровневая система программ, выполняющих низкоуровневые системные функции, неявным образом разрушает существующие интерфейсы приложений.
В приложениях, работающих на виртуальной машине, невозможно рассмотреть топологию и конфигурацию базовых физических ресурсов. Определенный компонент может «показаться» приложению непосредственно подключенным блочным устройством, а окажется файлом, расположенным на каком-то далеком NFS-сервере. Обфускация компьютерных и сетевых топологий осложняет планирование ресурсов на прикладном уровне. В случае Hadoop диспетчер ресурсов будет принимать неоптимальные планировочные решения, так как станет исходить из неверных представлений о физических ресурсах. Данные и сведения о локальности задач могут быть потеряны, но это еще полбеды; основные и дублирующие блоки могут оказаться в одном и том же отказавшем домене, из-за чего потеря данных будет безвозвратной.
Аналогично, гипервизор не позволяет «заглянуть» в приложение. Грубое представление о ресурсах при отсутствии информации об их семантике на прикладном уровне не позволяет выполнять многие варианты оптимизации. Например, считывание конкретного значения config из файла представляет собой операцию считывания, выполняемую блочным устройством на уровне виртуального оборудования. Без семантического контекста такие оптимизации, как предварительная выборка или кэширование, будут неэффективны. Другой пример: гипервизор резервирует большие области физической памяти, даже если она не используется гостевым приложением – дело в том, что гипервизор просто не может выявить неиспользуемые страницы памяти в гостевой системе.
Техническая поддержка
Большое количество виртуальных машин и работающих на их базе гостевых операционных систем – это обременительная техподдержка. Своевременное применение патчей безопасности к каждой отдельной виртуальной машине на просторах крайне динамичной инфраструктуры, где виртуальные машины создаются и удаляются буквально на лету, на большом предприятии может оказаться неподъемной задачей. Чрезмерное распространение виртуальных машин — еще одна проблема. Более того, фактическая стоимость лицензирования гостевых операционных систем может оказаться баснословной, особенно если речь идет о горизонтальном масштабировании.
Плохое сопряжение между приложением и операционной системой
Принято считать, что виртуализация помогает «отвязать» приложения от аппаратного обеспечения. Однако виртуализация приводит к образованию новых тесных связей между приложениями и их гостевыми операционными системами. Приложения запускаются как придатки виртуальной машины, что, в свою очередь, впутывает гостевую операционную систему в «черный ящик» виртуализованного образа. Можно выполнить миграцию всей виртуальной машины целиком – например, для ремонта оборудования — но невозможно обновить операционную систему, не нарушая функционирования работающего в ней приложения.
Поскольку приложение всегда привязано к гостевой операционной системе, те ресурсы, которые выделяются приложению, нельзя масштабировать по требованию. Сначала ресурсы добавляются в гостевую операционную систему, а она, в свою очередь, предоставляет их приложению. Однако, обычно гостевые операционные системы требуют перезагрузки для того, чтобы они могли распознать дополнительную память или новые ядра.
Виртуальные машины: неверная абстракция приложений
В конечном итоге, заказчика интересует исправно работающее приложение — а не операционные системы или виртуальные машины. Именно приложение требуется виртуализовать. Однако виртуальная машина не может непосредственно виртуализовывать приложения; чтобы восполнить этот недостаток, ей требуется дополнительная гостевая операционная система.

Для виртуализации приложения виртуальным машинам нужен дополнительный уровень с гостевой ОС
Иллюстрация автора.
В ходе многолетней работы промышленные и исследовательские комитеты посвятили немало совместных усилий решению проблем, связанных с виртуальными машинами. Предлагались многочисленные инновации. Некоторые из них даже развились в самостоятельные технологии. Однако при внимательном рассмотрении оказывается, что многие из этих инноваций не дают прогресса и перехода на качественно новый уровень по сравнению с контейнерами. Такие технологии в первую очередь направлены на устранение проблем, вызываемых самими виртуальными машинами. В принципе, огромный сегмент промышленных разработок ориентирован в неверном направлении: мы оптимизируем виртуальные машины, а не приложения. Такая фундаментально ошибочная модель позволяет добиться лишь относительной оптимизации. На следующих примерах рассмотрены лишь некоторые широко распространенные приемы, изобретенные для преодоления нестыковок между приложениями и виртуальными машинами.
Паравиртуализация
Паравиртуализация — один из наиболее всепроникающих способов оптимизации производительности виртуальных машин. Поскольку гипервизор не может напрямую просматривать гостевую операционную систему и ее приложения, а также влиять на нее или на них. Вместо этого он опирается на гостевую операционную систему, которая получает от него подсказки и выполняет предписанные им операции. Интерфейс между гостевой системой и гипервизором называется «API паравиртуализации» или «интерфейс гипервызовов». Разумеется, такая техника не будет работать со стандартными немодифицированными операционными системами. Осуществить такие изменения непросто, равно как и поддерживать их, адаптируя к изменяющимся версиям ядра.
Динамическое перераспределение памяти
Операционные системы очень рачительно распоряжаются физической памятью. Благодаря целому комплексу приемов (ленивое выделение, копирование при записи и др.) запросы о выделении памяти отклоняются во всех случаях кроме крайней необходимости. Для того, чтобы справиться с неспособностью гипервизора обращаться к внутренним компонентам операционной системы, применяется техника, именуемая «динамическое перераспределение памяти», она же – «раздувание» (ballooning). На гостевой системе задействуется специальный драйвер, позволяющий обнаруживать неиспользуемые области памяти и передающий эту информацию гипервизору. Неиспользуемые страницы памяти выжимаются из гостевой операционной системы и предоставляются хост-системе. К сожалению, в результате возникает неприятный побочный эффект: приложения периодически испытывают искусственный дефицит памяти. Данная техника допускает слабое решение, но все равно значительно уступает нативным механизмам ядра, централизованно распределяющим память.
Дедупликация
Применение нескольких экземпляров одной и той же гостевой операционной системы и ее стандартных сервисов в закрытой области адресного пространства каждой виртуальной машины приводит к тому, что некоторые образцы контента хранятся на нескольких страницах памяти. Для снижения подобных издержек была разработана техника онлайновой дедупликации страниц, называемая «совмещение общих страниц в памяти» (KSM). Однако, она чревата серьезными издержками производительности, особенно на тех хостах, где не предусмотрены ограничения памяти и используются конфигурации c NUMA (неравномерным доступом к памяти).
Раскрываем черный ящик
Виртуальные машины расценивают данные файловой системы как монолитные блобы образов, которые должна интерпретировать гостевая файловая система. Была выполнена определенная работа, призванная прояснить непрозрачную структуру образов виртуальных машин для индексирования, дедупликации, оффлайнового конкурентного пропатчивания базовых образов и т.д. Однако оказалось, что учесть все характерные особенности форматов образов, сегментов выделенных в них устройств, файловых систем и изменяющихся дисковых структур очень непросто.
Контейнеры: Экономная виртуализация для горизонтально масштабируемых приложений
Контейнеры — это очень своеобразный механизм виртуализации, направленный на непосредственную виртуализацию самих приложений, а не операционной системы. В то время как виртуальная машина предоставляет виртуальный аппаратный интерфейс, на котором может работать операционная система, контейнер предоставляет интерфейс виртуальной операционной системы, на котором могут работать приложения. Он отделяет приложение от его экосистемы посредством согласованного интерфейса виртуальной операционной системы, виртуализуя качественно определенный и семантически насыщенный интерфейс между приложением и операционной системой, а не между операционной системой и аппаратным обеспечением.
Контейнер состоит из множества пространств имен, каждое из которых проецирует подмножество ресурсов хоста на приложение по их виртуальным именам. Вычислительные ресурсы виртуализуются пространством имен процессов, сетевые ресурсы виртуализуются сетевым пространством имен, представление виртуальной файловой системы обеспечивается благодаря пространству имен монтирования и т.д. Поскольку контейнеризованные процессы нативно работают на хосте под управлением уровня виртуализации, те подсистемы, к которым применяется контейнерная виртуализация, могут быть адаптированы для использования в конкретном практическом контексте. Та степень, в которой хост и его ресурсы предоставляются в использование контейнеризованным процессом, может контролироваться с филигранной точностью. Например, контейнеризованное приложение может быть ограничено собственным приватным представлением о файловой системе, однако ему может быть разрешен доступ к сети хоста.

Контейнеры проецируют подмножество ресурсов хоста на приложение при помощи нескольких пространств имен. Иллюстрация автора
В отличие от работы с виртуальными машинами, при работе с контейнерами отсутствует уровень гостевой операционной системы, благодаря чему контейнеры получаются легковесными, дублирования функциональности не происходит, а издержки, связанные с промежуточными уровнями, исчезают практически полностью. При этом задержка при запуске также становится пренебрежимой, возможности масштабирования возрастают на порядок, а также упрощается управление системой.
Уже существуют первые варианты датацентров, использующих такие технологии, как YARN, Mesos и Kubernetes. Для обеспечения адекватной изоляции в этих датацентрах в качестве основного субстрата используются контейнеры. Это открывает путь к инновациям нового поколения, то есть, к истинному прогрессу.
kekekeks
И в чём вывод? Используйте Docker и будет счастье?
de1m
По наблюдениям довольно мало людей знают, что такое докер. Я недавно был на собеседовании и они там чуть ли не кипятком… когда узнали, что знаю, что такое докер и даже могу создавать образы. Да и знакомые администраторы тоже не очень в теме, может из-за того, что они больше с виндой работают.
Мне вот интересно, это только я так докер воспринимаю, что это революция (или очень близко) в виртуализации (я понимаю, что это не виртуализация) или я это как-то не так воспринимаю? Скоро сюда ещё и Microsoft подключится со своим нано сервером.
Botkin
Я склонен считать, что таки эволюция
navion
Простите моё невежество, но в чем именно революция?
Контейнерами уже лет 10 пользуются через OpenVZ и любой админ из хостинга умеет с ним работать.
vaniaPooh
LXC как технология существует с 2008 года.
equand
FreeBSD jail в 4.0 версии появилось. 2000 год.
icoz
Таки это эволюция от jail'ов freebsd до ванильного ядра в linux. Ну и плюс несколько приятностией докера — хаб с готовыми образами, скриптовый язык создания контейнера, «слоеность» фс контейнера…
equand
В то время как jail бсдшные намного более стабильная система с куда более тонкой настройкой и отлаженной системой.
armab
Имхо такие вещи как Docker, Vagrant, CoreOS — однозначно революция.
Просто потому что они сделали уже существующие сложные вещи очень простыми для использования и автоматизации.
reji
Скорее уж docker registry. Именно благодаря репозиторию мы обязаны всей этой шумихи вокруг контейнеров. Примерно такое же произошло с появлением github.
armab
На момент появления публичного Docker Hub все уже неплохо вертелось: blog.docker.com/2014/06/announcing-docker-hub-and-official-repositories В любом случае, Hub/Registry это важная часть Docker платформы и экосистемы.
Сыграло все:
Особенно важно выделить огромную работу на публику: Конференции, DockerCon, доклады. Отсюда и куча людей, которые начали его пробовать и нести свой вклад в проект через GitHub (1К contributors!)
Botkin
Панацеи, все-таки, нет и нужно под каждую конкретную задачу искать оптимальное решение.
К тому же, многие из проблем, поднимаемых автором, уже решены. Не покидает ощущение, что писалось лет 5-7 назад.
reji
Как раз насчет кластера на контейнерах и пишу статьи. На этих выходных, если успею, вторую из цикла допишу. Ссылка, если интересно.
ph_piter Автор
Спасибо, почитаю обе
lexore
Автор статьи использует hadoop yarn (ПО, требовательное к I/O) на виртуалках?
Может просто не использовать виртуалки?
Если выделять под hadoop отдельный железный сервер, отпадет необходимость «быстро развернуть кучу виртуалок под hadoop».
Такое ощущение, что у автора на работе много серверов виртуализации общего назначения.
И он осознал, что разворачивать в них кучу виртуалок для hadoop — неоптимально.
Ему бы прийти к CIO и сказать «нам нужно выделить часть серверов только под hadoop».
Или может я чего-то непонимаю?
xhumanoid
да даже не знаю как описать, то что автор набросал:
1) hadoop (главная идея) — если данным долго идти к processing unit, то давайте вычислительные юниты придут к данным — объединяем data & compute nodes на одних машинках
2) YARN — изоляция ВЫЧИСЛИТЕЛЬНЫХ ресурсов (память/cpu/io), но в любом случае доступ к hdfs проходит зачастую по direct без использования сетевых сокетов. пытаться разворачивать свои приложения в ярне просто потому, что это модно или он якобы даёт хорошую изоляцию ресурсов глупо, уж лучше mesos смотреть в этом случае. Ярн использует cgroups, но namespaces не использует и не собирается, так как у него совсем другие задачи.
3) KSM — не, я конечно понимаю что openvz её не поддерживает (могу ошибаться, давно пинал), но lxc её умеет. её разрабатывали как раз для повышения плотности приложений и не только виртуалок.
4) www.projectserengeti.org — гипервизор предоставляет планировщику хадупа структуру кластера с учетом физической топологии (виртмашина-физмашина-стойка). неужели вы думаете, что vmware так просто отдаст этот рынок?
5) «Так, в случае Hadoop виртуализованный стек ввода/вывода состоит из HDFS, гостевой файловой системы, гостевого драйвера, виртуального устройства, интерпретатора формата образов, файловой системы хоста, драйвера хоста и, наконец, физического устройства» — raw девайсы отдавать уже не модно в виртуалки?
мне интересно другое:
для некоторых задач в которых применяются виртуалки приходится тюнить параметры ядра (зачастую сеть), есть задачи где требуются свои кастомные модули загружать в ядро, КАК в таких случаях себя поведут контейнеры?
в итоге статья сводится к КО: пихать везде виртуализацию глупо
но продолжается неправильно: давайте пихать везде контейнеры
а уж каким боком рассматривается yarn в качестве горизонтального масштабирования, учитывая до конца нерешенные проблемы с long running приложениями, я не понимаю, я бы еще понял если бы он в пример приводил mesos и mesosphere.com
Stas911
Вроде в любой книге по Hadoop Operations написано, что запускать его на виртуалках — нефига не хорошая идея дл прода.
lucky_brick
docker — го-гавно. все просто на нем зависли.
контейнеров — дохера.
виртуализация в продакшн… кто так делает -то?
lucky_brick
и я не думаю, что надо хвалиться тем, что ТП может развернуть контейнер (это как верстать в дримвивере и программировать в пазл-игре),
если нихера не понимаешь это не поможет.
например: мне, как человеку плохо врубающемуся в dns устраивает, что какой нить DO перет эти проблемы на себя давая мне простую формочку…
но это не проканает если надо настроить кластер машин… для боя…
но мыж тут не про сайт-васи-пупкина.рф говорим?
vanesku
Docker бомба! К сожалению еще не все осознали, но все двигается в сторону замены бесполезных громоздких виртуальных машин на контейнеры. У нас в компании успешно развернут кластер на Kubernetes, в котором ежедневно деплоится/ранятся/удаляется пару сотен контейнеров и сервисами и апликухами, для автоматизированного и ручного тестирования. Огромный плюс в том, что среда разработки идентична среде тестирования и продакшн. Просто скачивается готовый образ и за пару десятков секунд стартует необходимая среда с всеми компонентами. Как-нибудь напишу про это подробнее.
Stas911
Было б очень интересно прочитать!
Stas911
Если бы еще сравнить с другими системами (напр. Juju) — вообще было б здорово