
Со временем все чаще и чаще появлялась проблема выбора материала. Ведь довольно большую роль играет чтец, жанр книги. Часто возникает ситуация, когда кто-то советует книгу (или в той же статье на хабре в читальном зале), а аудио-версии банально нет еще. Все эти проблемы я попытался решить отдельным сайтом. Сейчас есть парочка довольно больших и раскрученных по аудиокнигам, где вы можете прямо онлайн слушать их. Такие сайты обладают достаточно слабым фильтром по книгам. И, по сути, являются чисто каталогом.

Источник информации
За все время я заметил, что рутрекер является одним из самых масштабных хранилищ аудиокниг. Если книга существует в таком формате, то почти наверняка она есть в раздачах. Многие чтецы даже вручную делают релизы торрентов. Первым заданием было полной синхронизацией всех доступных аудиокниг с рутрекера.
Выбор книги
Следующей целью было создание широкого фильтра для подбора книги. Удобные фильтры помогут сменить подход к выбору книги. Если раньше вы просто находили себе вариант, а потом искали его аудиокнигу (которой могло не оказаться), то теперь вы исключаете первый пункт и ищете в базе максимально всех существующих книг. Конкретно сейчас у меня получилось сделать следующий набор фильтров:
- Семантический глобальный поиск по всей базе по всем текстовым полям
- Сортировка (asc/desc) по дате создания торрента, количеству просмотров (на сайте), рейтингу (из внешних источников), количество загрузок (по данным рутрекера), ну и наугад
- Фильтр по автору произведения, автору озвучки, жанрам, и возможность исключить книги, которые вы отметили как «прочитанное»
- Возможность подписки на авторов книг или озвучки. Да-да! Вы можете выбрать понравившегося исполнителя и подписаться на все его обновления. Я, например, мониторю все книги Игоря Князева
База рутрекера
Итак, первый пункт это анализ публикаций рутрекера и формирование базы. Для хранилища выбрал MongoDB. Во-первых, идеально для кучи не особо связанных данных, во-вторых, идеально показала себя в плане производительности. Да и вообще разрабатывать сайт с простым «пробрасыванием» json с UI на базу очень просто и занимает минимальное время. Кстати, в MongoDB 3.2 добавили left outer join.
Основной сложностью было унифицирование информации. Рутрекер хоть и заставляет оформлять раздачи (за что им спасибо), но все равно за 10 лет (именно столько времени прошло с момента публикации первой аудиокниги) оформление отличается. Пришлось открывать наугад разные разделы и собирать возможные варианты.
Скрипт парсера написан на питоне, для эмуляции браузера библиотека mechanize, для работы с DOM — BeautifulSoup.
Метод, который возвращает объект максимально эмулирующий поведение обычного браузера. Второй метод получает объект браузера, авторизируется на рутрекере и возвращает этот самый объект, внутри которого уже хранятся cookies авторизации.
def getBrowser():
br = mechanize.Browser()
cj = cookielib.LWPCookieJar()
br.set_cookiejar(cj)
br.set_handle_equiv(True)
br.set_handle_gzip(True)
br.set_handle_redirect(True)
br.set_handle_referer(True)
br.set_handle_robots(False)
br.set_handle_refresh(mechanize._http.HTTPRefreshProcessor(), max_time=1)
br.addheaders = [
('User-agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2327.5 Safari/537.36'),
('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'),
('Accept-Encoding', 'gzip, deflate, sdch'),
('Accept-Language', 'ru,en;q=0.8'),
]
return br
def rutrackerAuth():
params = {u'login_username': '...', u'login_password': '...', u'login' : ''}
data = urllib.urlencode(params)
url = 'http://rutracker.org/forum/login.php'
browser = getBrowser()
browser.open(url, data)
return browser
Сам по себе сбор данных выглядит как набор регулярных выражений в разных вариациях:
yearRegex = r'Год .*(\d{4}?)'
result['year'] = int(re.search(yearRegex, descContent, re.IGNORECASE).group(1))
# Пример разбора даты создания торрента, где дата указана в русской локали
timeData = soupHandle.find('div', {'id' : 'tor-reged'}).find('span').encode_contents()
import locale
locale.setlocale(locale.LC_ALL, 'ru_RU.UTF-8')
result['creationTime'] = datetime.datetime.strptime(timeData, u'[ %d-%b-%y %H:%M ]')
Очень важно использовать BULK-запросы в mongo, чтобы парсер не нагружал единичными вставками базу. К счастью, все это делается очень просто:
BULK = tableHandle.initialize_unordered_bulk_op()
# Цикл...
BULK.find({'_id' : book['_id']}).upsert().update({'$set' : result})
BULK.execute()
Поле slug генерируется пакетом slugify (pip install slugify).
Вот список всех полей для каждой из книг, которые я в итоге собрал:
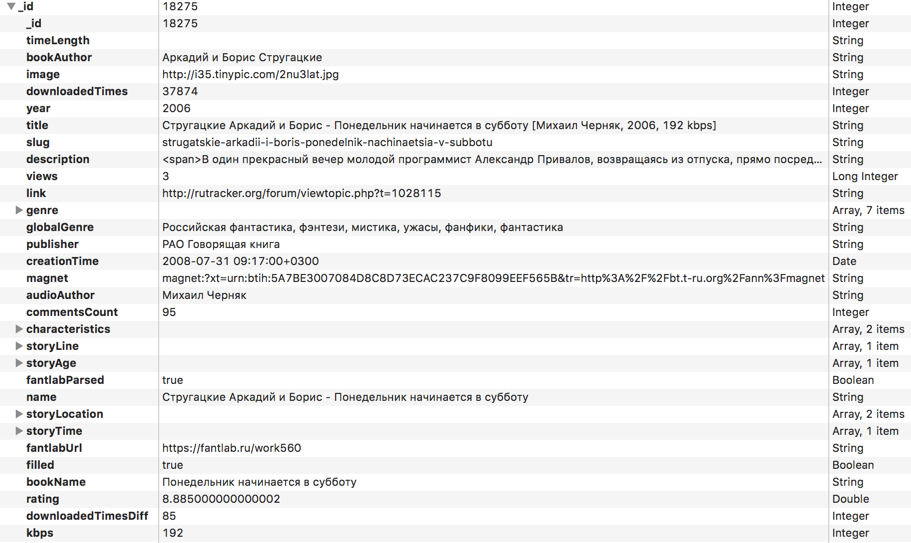
Сразу же не забываем создать индекс для всех полей, по которым будет идти сортировка или фильтрация:

Это замедлит время вставки, но очень ускорит выборку. Синхронизация базы происходит раз в день, поэтому второй вариант для сайта предпочтительней.
Загрузка данных происходит по всем подфорумам аудиокниг:
forums = [
{'id' : '1036'}, {'id' : '400'}, {'id' : '574'},
{'id' : '2387'}, {'id' : '2388'}, {'id' : '695'},
{'id' : '399'}, {'id' : '402'}, {'id' : '490'},
{'id' : '499'}, {'id' : '2325'}, {'id' : '2342'},
{'id' : '530'}, {'id' : '2152'}, {'id' : '403'},
{'id' : '716'}, {'id' : '2165'}
]
for i in xrange(pagesCount):
url = 'http://rutracker.org/forum/viewforum.php?f='+forum['id']+'&start=' + str(i*50) + '&sort=2&order=1'
Нормализация базы
Данные мы скачали, но есть проблема: нет точности в указанных данных. Кто-то напишет «В. Герасимов», кто-то «Вячеслав Герасимов». В одном месте укажут полное или альтернативное название произведение. Также появился вопрос в получении независимой оценки произведения. Погуглил пару заголовков книг и посмотрел на выдачу первых сайтов. Одним из них оказался fantlab.ru, который строит оценку по голосам пользователей, имеет довольно внушительную базу книг, содержит полное описание жанра и поджанров книг, точное имя автора и произведения.
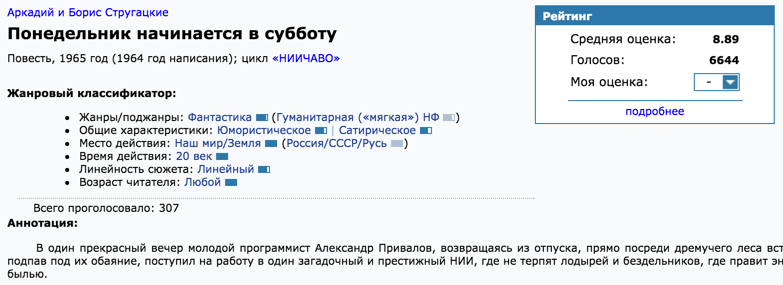
Имя автора, название книги
Абсолютно вся информация из скриншота парсится и вносится в базу. Все поля вручную проверяются членами сообщества fantlab. Все идеально, но есть одна проблема: как связать раздачу с рутрекера и определенную запись с fantlab? В раздачах не указывают отдельно названия произведения. Иногда даже автора неверно пишут (или не указывают). По сути, полным источником информации есть заголовок. Всю боль можно увидеть в следующем скриншоте раздач:

Стоит ли говорить, что даже исключив весь текст в угловых скобках встроенный поиск на fantlab не справляется и не находит ничего. Выход я нашел, хоть и не совсем изящный: phantomjs(selenium) + google.
У меня довольно много проектов используют эту связку, поэтому настроенный headless-браузер и базовые скрипты для selenium готовы были для использования. По сути, я брал заголовок с рутрекера, добавлял к нему приставку " fantlab" и гуглил. Первый результат, который по шаблону подходил по адресу произведения парсился. Оставлю пару замечаний по поводу phantomjs: очень сильно течет память. Я давно уже сделал для себя пару «костылей», которые позволяют процессу жить месяцами на сервере и не падать по причине нехватки памяти:
def resourceRequestedLogic(self):
driver.execute('executePhantomScript', {'script': '''
var page = this;
page.onResourceRequested = function(request, networkRequest) {
if (/\.(jpg|jpeg|png|gif|tif|tiff|mov|css)/i.test(request.url))
{
//console.log('Final with css! Suppressing image: ' + request.url);
networkRequest.abort();
return;
}
}
''', 'args': []})
Эта функция выполняется в момент запроса какого-то ресурса и проверяет его по маске медиа-файлов. Все картинки и видео исключаются. Т.е. они даже не загружаются в память. Вторая функция принудительно сбрасывает кеш. Вызывать нужно по таймеру раз в ~час:
def clearDriverCache(self):
driver.execute('executePhantomScript', {'script': '''
var page = this;
page.clearMemoryCache();
''', 'args': []})
Открываем гугл и вбиваем ему в поле поиска любой текст, чтобы сменить UI (получить результат выдачи). Все дальнейшие запросы будут происходить на этой же странице.
driver.get('http://google.ru')
driver.find_element_by_css_selector('input[type="text"]').send_keys(u"Имя книги fantlab")
driver.find_element_by_css_selector('button').click()
Так как запросы все аяксовые, нам нужно вручную проверять факт загрузки. В selenium для этого есть некоторые методы, которые ожидают пока определенный элемент не появится на странице.
count = 0
while True:
count += 1
time.sleep(0.25)
if count >= 3:
break
try:
link = driver.find_element_by_css_selector('a[href*="fantlab.ru/work"]')
if link:
return link.get_attribute('href')
except:
continue
Жанры
Следующий шаг: приведение к одному виду всех имен авторов и всех жанров. В некоторых раздачах писали «ужас», в других «ужасы». Здесь на помощь пришла библиотека pymorphy2: позволяет получить начальную форму слова.
# Убираем все спец символы из строки жанров
fullGenre = fullGenre.replace('/', ',').replace(';', ',').replace('--', '-').replace(u'ё', u'е')
fullGenre = re.sub(r'[\.|"«»]', '',fullGenre)
fullGenre = re.sub(r'\[.*?\]', '',fullGenre)
# Разбиваем жанры по запятой, убираем пустые поля и начальные/конечные пробелы
allGenres = filter(None, fullGenre.split(','))
allGenres = [item.strip() for item in allGenres]
# Делаем список уникальным (убираем дубликаты)
allGenres = list(set(allGenres))
insertGenresList = []
for genre in allGenres:
# Проходим по каждому жанру, получаем его начальную форму
morphology = morph.parse(genre)[0]
genre = morphology.normal_form
insertGenresList.append(genre)
Имена авторов
С авторами можно было бы тоже что-то придумать с библиотекой pymorphy2: разбивать на слова, проверять вхождения слов и их совпадение. Но тут я вспомнил пункт про глобальный поиск всего по всем полям. Это и будет решением. Для полнотекстового поиска взял sphinx. Он напрямую не дружит с mongodb, поэтому нужно написать скрипт, который будет выбрасывать xml с данными по указанной схеме.
docset = ET.Element("sphinx:docset")
schema = ET.SubElement(docset, "sphinx:schema")
# Храним ID записи в базе, чтобы потом вытаскивать информацию
idAttribute = ET.SubElement(schema, "sphinx:attr")
idAttribute.set("name", "mongoid")
idAttribute.set("type", "int")
# Дальше перечисляем все поля, которые должны индексироваться
text = ET.SubElement(schema, "sphinx:field")
text.set("name", "audioauthor")
text = ET.SubElement(schema, "sphinx:field")
text.set("name", "bookauthor")
text = ET.SubElement(schema, "sphinx:field")
text.set("name", "title")
text = ET.SubElement(schema, "sphinx:field")
text.set("name", "publisher")
text = ET.SubElement(schema, "sphinx:field")
text.set("name", "description")
# Мы должны вручную генерировать индекс для каждой записи книги и это обязательно должен быть атрибут с имением id
globalIterator = 0
all = bookTable.find()
# Убираем то, что может сломать xml разметку
def safeText(data):
data = re.sub('<[^<]+?>', ' ', data)
data = "".join([c for c in data if c.isalpha() or c.isdigit() or c==' ']).rstrip()
return data
for card in all:
document = ET.SubElement(docset, "sphinx:document")
globalIterator += 1
# Этот самый обязательный id
document.set("id", str(globalIterator))
mongoid = ET.SubElement(document, "mongoid")
mongoid.text = str(card["_id"])
title = ET.SubElement(document, "audioauthor")
title.text = safeText(card["audioAuthor"])
# И далее все то же для всех полей...
Параметры в sphinx.conf:
source src_bookaudio
{
type = xmlpipe2
xmlpipe_command = python /path/to/sphinx.py
sql_attr_uint = mongoid
}
index bookaudio
{
morphology = stem_enru
charset_type = utf-8
source = src_bookaudio
path = /var/lib/sphinxsearch/data/bookaudio.main
}
И команда: indexer bookaudio --rotate
Как же использовать поиск для унификации полей? Берем список всех авторов книг, и складываем одинаковые вхождения. Получится что-то типа:
Вячеслав Герасимов — 1324
Игорь Князев — 432
...
authors = {}
for book in allBooks:
author = book['audioAuthor']
if author in authors:
authors[author] += 1
else:
authors[author] = 1
То, что используется максимально часто наверняка есть наиболее правильной формой. Берем топовые вхождения и делаем глобальный поиск по всем авторам.
import sphinxapi
client = sphinxapi.SphinxClient()
client.SetServer('localhost', 9312)
client.SetMatchMode(sphinxapi.SPH_MATCH_ALL)
client.SetLimits(0, 10000, 10000)
import operator
sorted_x = reversed(sorted(authors.items(), key=operator.itemgetter(1)))
counter = 0
for i in sorted_x:
print i[0].encode('utf-8'),
print ' - ' + str(i[1])
searchData = client.Query(i[0], 'bookaudio')
for match in searchData['matches']:
mongoId = int(match['attrs']['mongoid'])
BULK.find({'_id' : mongoId}).upsert().update({'$set' : {'audioAuthor' : i[0]}})
Все похожие вхождения (в том числе «В. Герасимов», например) будут заменены на наиболее используемые формы.
Интерфейс
Написание веб-интерфейса для всего этого не несет никакой технической сложности. По сути, это надстройка для доступа к базе. Вот что у меня получилось. Список самых скачиваемых аудиокниг за всю историю трекера:
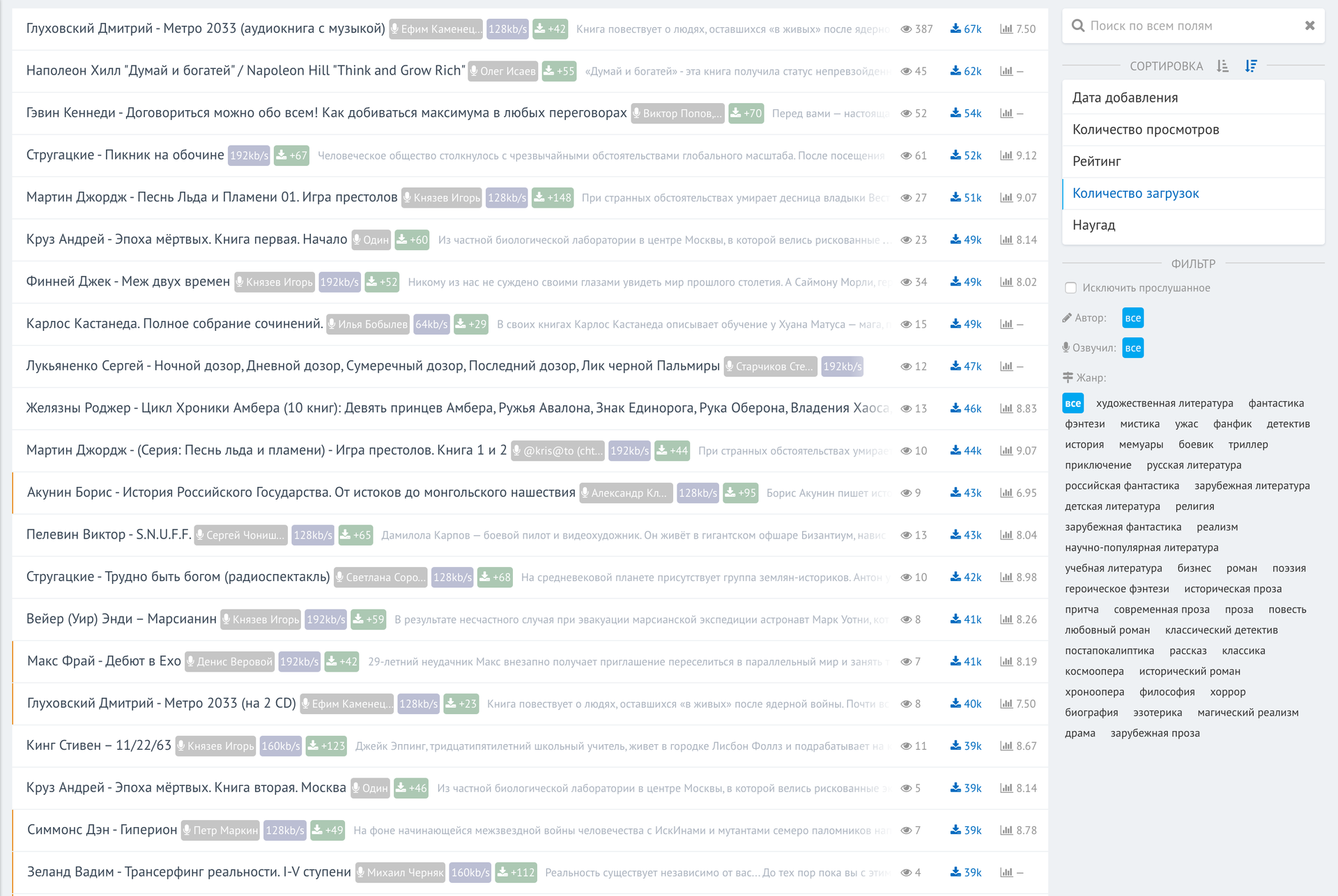
И работа с фильтрами:
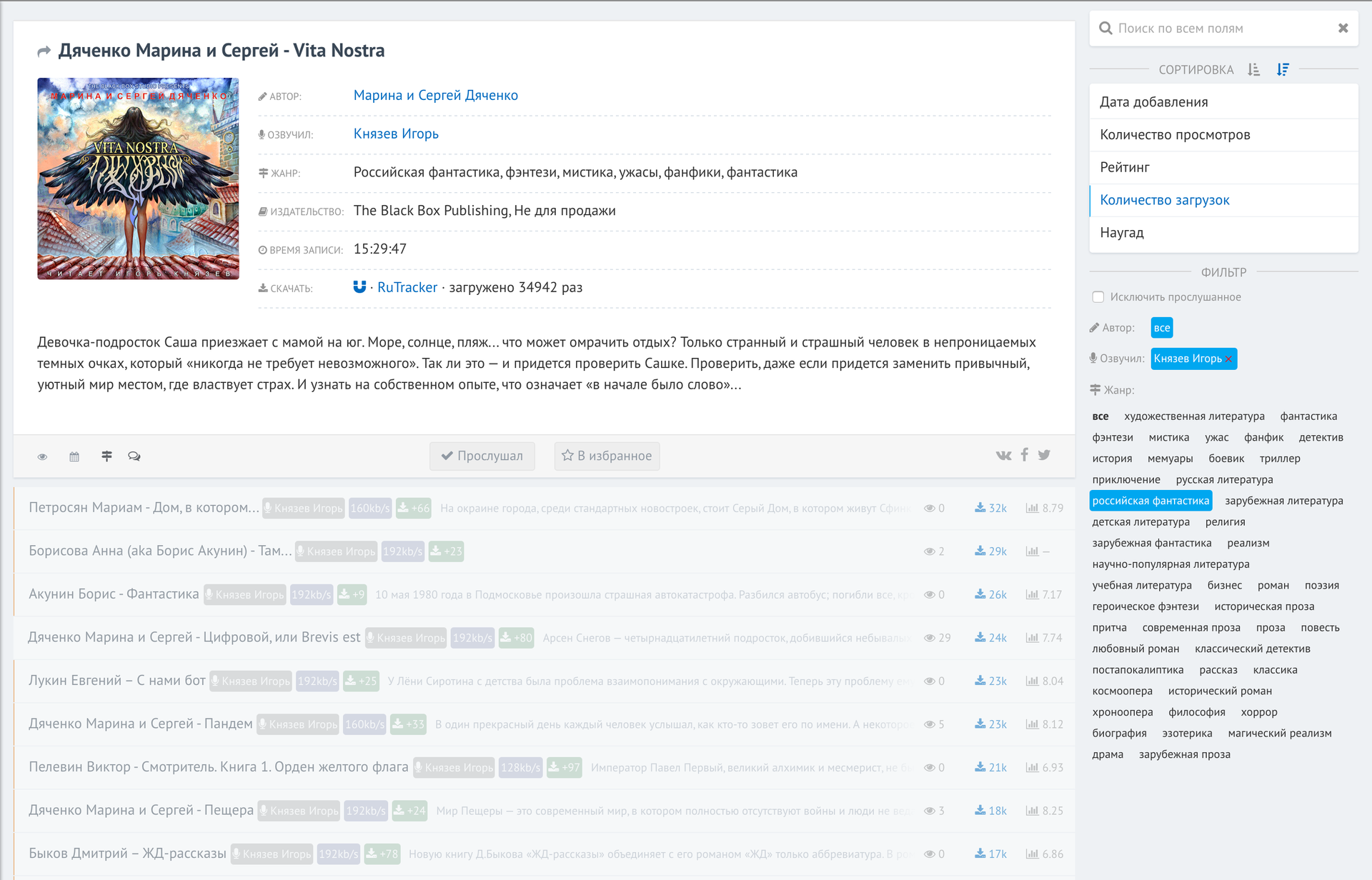
Как видите, я захотел посмотреть все книги, озвученные Игорем Князевым по жанру «российская фантастика», отсортированные по количеству загрузок на рутрекере (вверху самые скачиваемые).
Пробелом или нажатием на карточки внизу раскрывается информация о книге. Благодаря mongodb все фильтры отрабатывают мгновенно по базе в 30к книг.
Завершение
Не все идеально: база не везде точная, интерфейс можно улучшить. Фильтр по жанрам нужно перевести в древовидную структуру. Все это работа за 3 дня и для личного пользования и выбора книг мне хватает. Вы бы пользовались таким сервисом?
Комментарии (104)


n1kkk1ros
15.05.2016 00:28+3Крутая идея. Хотелось бы попользоваться. Даже Князев не всегда хорош, и поэтому было бы отлично покрутить данный ресурс

Ockonal
15.05.2016 00:47Если за определенное время наберется относительно позитивный фидбек, вложу больше сил и даже посмотрю в сторону скачивания всех аудиокниг и возможность слушать их прямо с сайта.

xxxTy3uKxxx
15.05.2016 00:31+1Отличная идея! Может стоит глянуть в сторону бота для телеграмма?
Ockonal
15.05.2016 00:40+4Спасибо. Если честно, я сам не люблю этой истерии по поводу телеграм-ботов. Не считаю это удобным. Если вы хотите выбрать себе книгу, то можете уделить время, зайти на сайт и воспользоваться полным и широким набором фильтров :) Ведь именно для этого все затевалось ;)
Да и сейчас на сайте нет возможности слушать онлайн. Для этого нужны ресурсы, если сервис зайдет — сделаю. Возможно тогда можно будет сделать бота, который будет интерпретировать фразы вида: «получить книгу с озвучкой игоря князева по жанру российская фантастика»
serf
15.05.2016 02:19+2У меня нет vk аккаунта, как залогиниться по другому?
Ockonal
15.05.2016 02:20Попробуйте завтра, я добавлю facebook и twitter
serf
15.05.2016 02:30+3Этих тоже у меня нет :) Можно гугла или просто логин/пароль?
Да вот здесь book-audio.com/performers не нашел например таких декламаторов (которые представлены на rutracker):
Андрей Кравец
Александр Сталеваров
Дмитрий Бобров
Дмитрий Хазанович
Петр Маркин
Светлана НикифороваOckonal
15.05.2016 02:31Этот раздел сейчас чисто для галочки и для демонстрации возможности подписки на автора (которая сейчас тоже не работает, потому что кручу код).
Этой публикацией я хотел проверить реакцию людей, потому что все это занимает довольно много времени и усилий :) Если все будет хорошо, то сделаю много чего еще.
Сделаю гугл логинserf
15.05.2016 02:51+1Я бы пользовался сервисом. Особенно были бы полезны уведомления о новых книгах (или новых релизах от других декламаторов) по декламаторам и авторам.
Несколько моментов:
— дата выхода книги нигде не фигурирует, соответственно нет сортировки по этой дате (не должно быть проблемой взять с fantlab тк рейтинг уже оттуда получается)
— в карточке книги не указан рейтинг
— в карточке книги жанры не кликабельны
— было бы удобно в карточке книги иметь ссылку на соответствующую fantlab страницу (откуда берется рейтинг). Там можно понять в каком порядке стоит слушать книги (полагаю структуру серий автоматически составить было бы проблемно), комментарии и тд.Ockonal
15.05.2016 02:53Спасибо за отзыв, все это будет. Попытаюсь как-то и группировать серию книг. Думаю, для самых популярных произведений это вполне реально.

tapin13
15.05.2016 10:32+3поддерживаю self, хотелось бы «просто логин/пароль». Лично не люблю привязок к соц сетям.
Вообще идея отличная. Главное если будите рости, не перегружайте сайт, как это в свое время сделал имхонет, и пришлось уйти.
С удовольствием пользовался!

webmasterx
15.05.2016 05:20Я бы скорее всего сервисом не пользовался бы сейчас, но раньше он мне бы пригодился. Так как загружать все торренты зарубежной фантастики оказалось немного утомительным. автоматизацию не делал, так как одновременно еще и слушал скаченные книги и база «что не надо качать» постепенно росла и умещалась в памяти. Еще обычно скачивал серию книг в отдельную папку
Ockonal
15.05.2016 11:27Понимаю вас, тоже затрудняет, но на данном этапе было бы сложно еще и поддерживать прослушивание онлайн. Может как-нибудь в будущем.
webmasterx
15.05.2016 12:45Я неправильно высказался. прослушивание онлайн не надо. Просто намекаю что «старослушателям» такое не надо. ибо почти все книги прослушаны, а за новыми следят «вручную». Мне даже кажется что лучше всего добавить (если нет) — возможность скачать все торренты (или по автору/исполнителю)
WarmongeR
15.05.2016 06:40Исходники в OpenSource выпустите?
Ockonal
15.05.2016 11:28Я уже писал ниже, что вообще все получилось очень универсальным. Сайт по сути является UI прослойкой для MongoDB, можно подсовывать данные любого формата с минимальными изменениями. Я уже подумывал о чем-то похожем для фильмов. +Какой-то интерактивный просмотр фильма, когда ты не читаешь описания этого самого фильма. Просто жанрами подбираешь по настроению и включаешь фильм на весь экран. Не зная ни его названия, ни описания. :)
tapin13
15.05.2016 10:25Очень не удобно, когда каждая новая ссылка с сайта (на себя же) открывается в новом табе. (FF 28)
tapin13
15.05.2016 10:27Читаю сейчас серию книг, скачал с руторрет, попытался поискать по названию или имени автора и ничего не найдено. (если что книга Артём Мичурин «Еда и патроны»)
Ockonal
15.05.2016 11:41Проверил, в базе есть. Сайт сейчас в очень тестовой форме. Отклик получился хороший, буду активно дорабатывать и проверять. Спасибо.


FTM
15.05.2016 10:40+2Отличная идея. С удовольствием пользовался бы вашим сервисом.
Кстати, решал подобную задачу на рутрекере, но только с музыкальными произведениями. Группировал по жанрам, исполнителям, годам и т.п. Все описанные вами проблемы для аудиокниг в плане оформления раздач присутствуют и там.Ockonal
15.05.2016 11:13Мне очень помог мой старый движок другого проекта, который тоже работал с MongoDB. По сути, это универсальный UI для почти любой подобной информации. Скрипт парсинга тоже довольно универсальный. Возможно, позже подумаю о том, что бы открыть исходники.
Спасибо.


f0rmat1k
15.05.2016 13:21+2Пользуясь случаем хочу рассказать кратко о моем поделии. Тоже задумывался, что хочу слушать аудиокниги по категориям и длительности. В итоге запилил эти фишки для передачи «Модель для сборки»: http://mds-online.ru
volanddd
15.05.2016 14:26+2А где ссылка?

DAiMor
15.05.2016 15:18Я так понимаю аудиокниги только на русском. Было бы интереснее, если бы еще на английском были.

grims
15.05.2016 15:21+5Автор молодец! Сервис действительно нужный заметил по себе уже давно, было бы неплохо если бы такой проект в один прекрасный день ожил на просторах рунета.
Автору успехов, и если сказал «А», то нужно говорить и «Б».
shooorf
15.05.2016 15:21У рутрекера есть API api.rutracker.org/v1/docs — через него можно получить информацию о раздачах, включая название (а в нем обычно есть почти все необходимое, в том числе жанр, год, автор и т.п.)

Verdoga
15.05.2016 15:44+2Уважаемый автор, уже отыскал ссылку на этот проект. Очень надеюсь, что дело не затухнет. Есть несколько пожеланий, я ресурсом ещё не пользовался, это, так сказать, по прочтении статьи.
— Очень бы хотелось видеть nnmclub и рутор. Там бывают более удобные сборники по сериям или авторам.
— Очень бы хотелось, прям до слёз, связки с abook-club. Причин этому несколько: во-первых, там хорошая картотека, правда жанрового классификатора нет; во-вторых, там есть ссылки на их форум, где написаны отзывы и рецензии читателей; и последняя — там есть демо дикторов.
— Не мешало бы сделать модерацию данных.
Кстати, на abook-club есть сортировка по сериям у авторов, не всегда верно, но может поможет.
Об опыте использования текущей версии сервиса отпишу позднее. А вообще очен рад тому, что такой сервис появился!Ockonal
15.05.2016 16:01Спасибо больше за развернутый отзыв. Много пунктов сам знаю и хотел интегрировать. Данная публикация была как проверка, нужно ли вообще тратить свои силы и время на развитие. Как показал отклик – нужно.
Буду собирать максимально большую и полную базу из всех источников, которые найду
firekod
15.05.2016 16:28+1Отличный сервис, спасибо! Теперь все в одном месте и сразу можно скачивать по magnet-ссылке (нет необходимости обходить блокировку рутрекера, широким массам это будет удобно).
Можете еще добавить в фильтр год издания книги и рейтинг.
Например, чтобы можно было сделать такую выборку: зарубежная фантастика, начиная с 2000 года, с рейтингом не меньше 7,5 – и все это отсортировано по дате добавления.Ockonal
15.05.2016 16:48Спасибо за хорошие слова. Обязательно прикручу возможность указывания рейтинга, дат в range-формате.
Desprit
15.05.2016 16:48+1Огромное человеческое спасибо за хак для PhantomJS, который позволяет игнорить загрузку сторонних ресурсов. Каждый день имею дело с web scraping и Scrapy, но иногда приходится прибегать к помощи фантома. Ваш фикс в среднем ускоряет процентов на 30-40 загрузку, а в некоторых примерах у меня прирост был даже 100%.
Как-то уже искал решения раньше, но для python'а особо ничего не было и я бросил.
Verdoga
15.05.2016 16:57Уважаемый Ockonal, возможно вы не согласитесь со мной, но всё же я позволю себе обрисовать личную точку зрения на подобные ресурсы. Возможно она слишком субъективна, но это о наболевшем. Таких ресурсов действительно в рунете не хватает. Собирать информацию о книге, авторе, серии бывает утомительно с разных сайтов, особенно если данные не совпадают. Сервис-каталог аудио книг должен включать в себя не только информацию о книгах, сериях, циклах, но и информацию о самом авторе. Мне очень нравится классификация литературы на сайте «Лаборатория фантастики», на рутрекере жанровые классификации очень часто непонятны. Например: «Русская литература» — тогда уже хотя бы «Русская проза». Такой каталог должен нести в себе максимум информации обо всём, что связано с конкретной книгой. То есть каталог должен включать в себя: раздел биографий, раздел жанров, раздел серий/циклов, раздел каталожных карточек с отдельными произведениями. И вся эта информация должна сливаться воедино с перекрёстными ссылками. Возможно я слишком много требую, всё это невозможно получить в автоматизированном режиме, но ведь такого рода проекты и не делаются за месяц и на автоматизированной обработке данных. Отсюда вытекает вопрос модерации, о котором я писал в предыдущем комментарии.
О модерации. Я думаю, что требуется хорошая обратная связь, чтобы человек, мог сообщить об ошибке в один или два клика, не уходя со страницы. Модераторы же должны проверять каталог вручную. Ник проверявшего информацию модератора должен быть на странице с книгой, чтобы человек мог связаться с ним. Думаю со временем наберётся небольшой клуб энтузиастов, такой же как и на abook, и со временем получим сервис, который будет в состоянии предоставить действительно качественную информацию обо всех аудио книгах рунета. Я сам бы с большим удовольствием принял бы участие в подобном проекте.
Ну и конечно социальная составляющая: рейтинги, отзывы и рецензии. Я считаю, что последние нужно разделять, поскольку к рецензии должны быть более строгие требования и оня должна проходить обязательную модерацию.
Вот и всё. В общих чертах я обрисовал вам сервис своей мечты, а мелких деталей очень много.Ockonal
15.05.2016 17:02Спасибо за развернутый ответ. Я вас абсолютно понимаю и считаю очень важным пунктом то, что я сам очень долго слушаю книги и понимаю, что такому же любителю может понадобится, какой интерфейс информация и т.д. Конечно же у меня в планах было и получение информации по авторам книг, и по актерам, которые озвучивают книги. Очень много смогу получить автоматизированно, дело только времени. Согласен, что без модерации никуда.
Конкретно сейчас основная цель: стабильная независимая площадка, которая в автоматическом режиме может добавлять новые аудиокниги и парсить базовую информацию для них. К счастью, много людей уже написали о сотрудничестве, в том числе и доработке сайта. Подписывайтесь на обновления (здесь комментарии, группа в вк или просто мониторьте сайт). Буду уделять всему этому время и прислушиваться ко всем советам.
СпасибоVerdoga
15.05.2016 17:08Да это наипервейшая задача. Но проверка нужна в ближайшее время, поскольку дальше будет сложнее разгребать завалы информации.
Где группа ВК? Что-то не вижу:)
alekssamos
15.05.2016 19:05А ещё можно слушать обычные текстовые книги при помощи синтезаторов речи (TTS). А через специальную программу, например «Балаболка» можно записать в .mp3 или .wav… И получится аудиокнига из книги в текстовом формате…
Ockonal
15.05.2016 19:05У меня была идея делать подобное для небольших рассказов, но использовать движок IVONA. Там довольно неплохой синтезатор.
Verdoga
15.05.2016 19:38Много же вы таким образом слушали?
Ockonal
15.05.2016 20:21Я брал только небольшие рассказы, которые хотелось прочитать. АПИ там ограничивает по длине куски тестовые. Я прогонял их циклом и склеивал фрагменты в один mp3-файл. Слушать вполне реально
Verdoga
15.05.2016 20:28Мы лёгких путей не ищем:) Некоторым ещё нравится локуэндовская Ольга. Меня она раздражает проглатыванием всего окончания.
А вообще сейчас уже довели до ума бесплатный синтезатор RHvoice, он весьма неплохо обрабатывает интонации в зависимости от пунктуации и словарь там уже не маленький. Единственный недостаток на предложениях длиннее пяти слов, коих в тексте большинство, ровно посередине он начинает читать монотонно как сомнамбула, чем портит всё впечатление.
Verdoga
15.05.2016 20:16Способ неплохой, особенно когда нет альтернативы. Только есть несколько проблем.
Первая — нельзя слушать много книг подряд начитанных машиной. Нужно прерываться на книги начитанные человеком, даже пускай не очень хорошим диктором. Причина такого ограничения кроется в искажении речи. Если долго слушать машинную речь, то неверные ударения, которые мы воспринимаем на слух, становятся для нас нормальными и мы сами незаметно начинаем неверно расставлять их уже в нашей речи. Я сам долго страдал подобной проблемой после синтезатора Алёна, вместо пробЕл, говорил прОбел.
Вторая — машина крайне плохо начитывает некоторые произведения и жанры. Например фентези очень плохо начитывается, поскольку придуманные имена, названия и слова. Ещё портят впечатления междометия и некоторые диалоги с не помеченными говорящими, не всегда есть возможность понять на слух кто что сказал. Фантастика тоже раз на раз неприходится. Ну и в других местах лучше не браться так читать. Вот и сейчас лежит фентезийный цикл, первая книга начитана Татьяной (Ivona), а боязно браться, поскольку боюсь испортить впечатление машинной начиткой, судя по началу книжка не удалась.
Вот демка Татьяны, если кому интересно послушать.

Bagow
15.05.2016 20:19Было б круто указывать в описании наличие\отсутствие фоновой музыки. Не могу слушать с музыкой.
Ockonal
15.05.2016 20:20К сожалению, это невозможно :( Иногда не хватает даже самой нужной информации в раздаче, не говоря о таких подробностях.
Много людей выразили интерес в модерировании. Возможно, добавится интерфейс и хотя бы самые популярные книги можно будет дополнить информацией вида: фоновой музыки, качества чтения и т.д.Bagow
15.05.2016 20:47+1Я готов быть волонтером. Может анализируя дорожку на наличие пиков от нуля с помощью ffmpeg можно определить отсутствие музыкального фона.

HuntGuter
15.05.2016 21:08Отличный сервис, доступ к базе удобнее чем ICIJ сделали для своей базы офшоров =)
Будут ли исходники на ГитХабе?Ockonal
15.05.2016 21:10Я подумывал о том, чтобы заняться офшорами, спарсить их и как-то удобно выводить, но это слишком скучно и политика. :)
Веб-интерфейс, думаю, да. Уже сейчас не справляюсь со всеми проблемами верстки. Не моё это. Как и дизайн.
Кстати, если есть волонтер, кто может уделить 15-20 минут на пару вопросов по проблемах в верстке — напишите мне.

nrcpp
15.05.2016 22:06Сервис интересный. Добавлю только, что парсинг — не самое гибкое решение, если есть возможность, лучше использовать API, как писали выше.
Ockonal
15.05.2016 22:09Как показала практика, апи не всегда самое удобное средство. В том же примере выше, как я посмотрел, можно получать заголовок раздачи по одной штуке. Парсер же получает по 30-40 штук за раз (не помню сколько их там в одной выдаче).
У меня уже есть готовая база для парсеров с юнит-тестами, которые раз в N время валидируют результат парсинга и сообщают, если что-то идет не так, останавливая процесс.shooorf
16.05.2016 11:21Справедливости ради: в запрос на информацию о раздачах можно включить до сотни ID через запятую(%2C): http://api.rutracker.org/v1/get_tor_topic_data?by=topic_id&val=94316%2C146284%2C194249
Сами ID можно получить одним запросом вида http://api.rutracker.org/v1/static/pvc/f/1056
Что еще может быть полезно — api.rutracker.org не заблокирован в РФ.

Crystal_HMR
16.05.2016 12:14Всегда считал, что аудиокниги слушать не смогу. «Внутренний голос пугается, когда слышит, что читает не он»©
Но вот уже два года стараюсь ездить на работу велосипедом (чуть ли не единственный шанс без потери времени соблюдать хоть какую-то форму), и вот стал задумываться. С пятой попытки (менял чтецов, книги) — мне «пошел» Азимов. И тут Вы, и Ваш сервис! Это невероятно круто, спасибо!
PS. На главной внизу добавьте хоть 20px какого-то футера, а то я слегка в недоумении был, когда перестало листаться. И ни скролл-таба (не знаю как правильно называется то, что обычно появляется справа при листании дивов), ни информации о том, что это конец страницы — я не увидел. Это мелочь, и не критично, но всё же :)Ockonal
16.05.2016 12:15Спасибо ;) Сегодня я заменю разметку этих колонок по всему сайту, будет нормально работать.
Я тоже очень люблю на велосипеде книги слушать.
corsarr
17.05.2016 13:25Отличная идея!!! Главное не остановиться на половине, а продолжить и развивать до ~…
У отца появилась прогрессирующая проблема со зрением и он подсел на аудио книги. Приходится вручную лопатить просторы в поисках. Это я к тому, что было бы вовсе замечательно реализовать проект с учетом слабовидящих или вовсе не видящих пользователей + APP (Android, iOS)Ockonal
17.05.2016 13:25Спасибо. Пока разве что можно добавить стиль с повышенном контрастом и увеличенными шрифтами. Один не потяну еще приложение. Хотя некоторые люди отзывались о сотрудничестве в эту сторону.

Stas911
17.05.2016 20:57А где ссылка-то? Хотелось бы на английском много-много аудиокниг
grims
17.05.2016 21:26+1Ну, мил-человек, что же Вы так невнимательно… изучите автора со всех сторон, профиль там и все такое…
neosapient
17.05.2016 22:45Шикарно!
Я в своё время предлагал администрации сайта Фантлаба прикрутить ссылки на торрент-раздачи аудиокниг, но администрация отказалась ((
А можете импортировать из fantlab.ru те книги, что я уже прочитал (поставил оценку)? и те книги, что ожидаю прочитать в первую очередь (соответствующая Книжная полка «Прочитать»)?
А затем дать возможность убирать из поисковой выдачи те книги, что я прочитал и в первую очередь показывать те книги, что я отложил на прочтение?
P.S.
Вижу у вас на сайте, что можно «исключить прослушанное». Но у меня несколько сотен книг помечены как Прослушанное и столько же ожидают Прочтения. Всё это руками переносить — лениво.Ockonal
17.05.2016 22:47«Если гора не идет к Магомету...» :)
Классная идея, даже не дмал о таком. Правда, доступен ли список прочитанного пользователя для остальных? Чтобы можно было без знания логина/пароля выкачать эти данные? Или может fantlab дает экспортнуть в какой-то формат. Я бы написал импортер.neosapient
18.05.2016 10:52>> доступен ли список прочитанного пользователем для остальных? Чтобы можно было без знания логина/пароля выкачать эти данные?
Сомневаюсь, что эти личные данные доступны просто так. Но я б рискнул бы предоставить вам мой логин и пароль от сайта fantlab.ru, чтобы вы импортировали данные с него.
>> может fantlab дает экспортнуть в какой-то формат?
Это вам придется договариваться с админами сайта fantlab.ru. Может они запилят какое-нибудь API к их сайту.neosapient
18.05.2016 11:05Был неправ! ))
Можно посмотреть мои личные данные без авторизации на сайте fantlab.ru
Вот список книг которые я прочитал и оценил
http://fantlab.ru/user116033/marks
А вот моя книжная полка тех книг, что ожидают прочтения
http://fantlab.ru/bookcase98627

snnwolf
19.05.2016 17:09Возможно уже кто-то писал, но когда только зарегался получил ошибку: http://take.ms/Mt9VC
И при авторизации, ничего не происходит. Дебаггер в хроме получает ответ от сервера:
{"result" : "ok", "data" : "2f5xxxxxx0c2eXXXXXXXX487xxxxxx0ae0b"}

Artcomplex
19.05.2016 19:19О! Я как раз мечтал о таком сервисе!
Единственно- немного на другом ресурсе http://staroeradio.ru/program -здесь терабайты советских радиопостановок, «театр у микрофона» и т.п.
Местами гораздо более качественный продукт, нежели простая начитка аудиокниг.
И ужасный поиск.
Но и рутрекер очень интересен, спасибо.Ockonal
19.05.2016 19:22Посмотрел, там слишком мало мета-информации и все с разным описанием. Я сойду с ума писать логику, которая бы обрабатывала все возможные случаи и вариации :) Да и жанров для всего этого не найдешь. Моему набору фильтров просто не хватит информации.
Скоро выкачу новое обновление, там не только рутрекер будет.Artcomplex
19.05.2016 19:52+1Согласен. По-любому, то что сделано- круто. Буду пользоваться, спасибо.
Да и визуально приятно выглядит (кроме юзерпика :) )
З.Ы. Заметил, что первая загрузка сайта долго идет, вторая побыстрее.
chomper
24.05.2016 10:41Жанры в фильтре не пролистываются, а на маленьких экранах и вовсе не видны.
https://i.gyazo.com/dd8e850b6a90acf7a8f54d5ff78bd76b.png
bNN
24.05.2016 11:28Спасибо за проделанную работу!
Подскажите, интерфейс сделан же на каком-то фреймворке? Подскажите название :)



stassss2011
Да, мне бы такой сервис пригодился. Очень интересная идея и неплохая реализация. Ссылку б, что-ли? Или может оформить в виде расширения для браузера.
Ockonal
На хабре нельзя давать ссылки в профильных хабах. Что скажу, версия сделана за пару дней, уже относительно хорошо функционирует и я выбрал себе следующую книгу для чтения. Эта статья как точка отсчета, чтобы понять, нужно ли кому еще подобное. Вряд ли подобная проблема возникает у людей, которые редко слушают книги.
Хотел послушать отзывы, допилить еще UI и написать уже, например, в я пиарюсь.
А вообще, если поискать, можно найти ссылку ;)
Survtur
Вам надо было просто назвать Ваш проект как нибудь искабельно, типа «Который Трехдневный Книгодер», вот легко бы гуглилось.
msin
Поддерживаю… Глаза уже не те, чтобы целый день пялиться в экран, а вечером для отдыха читать ебук. Пора переходить на аудиокниги… но малость как-то напрягает, всю жизнь читал сам… не уверен, что эффект будет такой же
Ockonal
Главное попробовать :) Вначале тоже было тяжело. Выбирайте хороших чтецов с наверняка интересными книгами. Постепенно очень привыкаешь к подобному.
Verdoga
Попробуйте перечитать уже знакомые книги, но которые давно не читали. Главное, чтобы там был хороший диктор, и тогда эти книги для вас зазвучат по новому.
Rastishka
ЛайфхакСовет: некоторые пользователи заполняют в своем профиле пункт "сайт".