
Как вам известно, вчера завершился очередной чемпионат ACM ICPC. Поздравляем студентов МФТИ, ИТМО, УрФУ и ННГУ с отличным выступлением, ребят из СПбГУ — с 1-м местом. Теперь мы приглашаем всех желающих принять участие в Яндекс.Алгоритме 2016. В этом году финал чемпионата пройдет в Минске.

В этом году впервые помимо традиционных призов победители получат возможность попасть на стажировку в Яндекс. 22 мая регистрация закроется и останется только следить за другими участниками в отборочных раундах. Квалификационный раунд продлится в этом году двое суток — с 21 по 22 мая. Раунды вновь будут оцениваться по системе TCM/Time. Для тех, кому интересно, какой сложности задачи их ждут, мы разобрали тур прошлогодней квалификации. Также у вас есть возможность потренироваться на нем.
UPDATE: Уже начался квалификационный раунд Яндекс.Алгоритма 2016, приходите порешать задачи, которые мы обязательно разберем в будущем. На наш взгляд, задачки не хуже, чем в прошлом году.
Михаил — обычный пользователь интернета. Когда Михаил ищет что-либо в интернете с помощью Яндекса, случается, что он допускает опечатки в поисковом запросе. Конечно же, в большинстве случаев Яндекс может угадать, что имел в виду Михаил и исправить запрос. Например, если Михаил опечатается и напишет «дезоксирибонукленовая» (что неудивительно), Яндекс исправит запрос на «дезоксирибонуклеиновая».
Возможно, вы подумали, что в этой задаче вам нужно написать программу, исправляющую опечатки в запросе пользователя. Это не так: кроме этой задачи вам предложено ещё 5 увлекательнейших задач, а времени до конца соревнования осталось не так уж много. Просто проверьте, содержит ли очередной запрос Михаила опечатки.
Входные данные
В первой строке входного файла находится запрос Михаила: от 1 до 5 слов, состоящих из строчных латинских букв и разделённых одиночными пробелами. Вторая строка содержит целое число N (1???N???100): количество слов, содержащихся в словаре Яндекса (не волнуйтесь, в реальности количество слов, содержащихся в словарях Яндекса, гораздо больше ста). Третья строка содержит слова из словаря. Каждое слово представляет собой строку, состоящую из строчных латинских букв. Слова разделены одиночными пробелами. Гарантируется, что и слова из запроса, и слова из словаря содержат не более 20 букв.
Выходные данные
В единственной строке выходного файла выведите «Correct» (без кавычек), если все слова из запроса Михаила содержатся в имеющемся словаре, и «Misspell» (без кавычек), если хотя бы одного слова в словаре нет.
Решение задачи
В задаче требовалось определить, входят ли все слова из первого множества во второе множество.
С ограничениями в этой задаче хватило бы простого решения тривиального за O(N·M), где N и M — размеры первого и второго множества, соответственно. Для его реализации нужно непосредственно проверить, что каждое слово из первого множества находится во втором.
Достаточно простая реализация получается на языке python:
Анна — обычный пользователь интернета. Анна очень любит слушать музыку и пользоваться сервисом Яндекс.Музыка. Однажды, слушая песни на Яндекс.Музыке в режиме случайного перемешивания, Анна была очень расстроена тем, что после её любимой группы «Эпидемия» внезапно заиграл Григорий Лепс. Пылающая от негодования Анна написала гневное письмо в техническую поддержку сервиса, после чего команда разработчиков Яндекс.Музыки решила улучшить выбор следующей песни для проигрывания.
Всего на сервисе находится N песен, каждую из которых Анна хочет послушать хотя бы один раз. При этом Анна не возражает против повторного прослушивания песен, однако очень возражает против резкой смены жанров. В базе данных Яндекс.Музыки помимо самой музыки содержится информация о том, насколько некоторые песни похожи по жанру друг на друга. Каждая запись имеет вид (a,?b,?U) и означает, что если включить песню с номером b сразу после песни с номером a, пользователь испытает U единиц недовольства.
Известно, что все пользователи, и Анна в том числе, обращают внимание на самые неудачные переключения песен, поэтому недовольством от прослушивания некоторого плейлиста назовём максимум по всем недовольствам от переключения подряд идущих песен.
Имея такие данные, Яндекс.Музыка должна составить оптимальный для пользователя плейлист, удовлетворяющий следующим условиям:
Сможете ли вы составить плейлист, удовлетворяющий указанным условиям?
Входные данные
В первой строке входного файла содержатся два целых числа N и M (1???N???100 000,?1???M???200 000), разделённые пробелами: количество песен, которые хочет прослушать Анна и количество записей о переходах между этими песнями, соответственно. Следующие M строк содержат по три целых числа ai,?bi,?Ui (1???ai,?bi???N,?ai???bi,?1???Ui???1 000 000 000), разделённых пробелами, которые говорят о том, что если включить песню с номером bi сразу после песни с номером ai, пользователь испытает Ui единиц недовольства. Гарантируется, что никакой переход от одной песни к другой не встречается в записях дважды.
Выходные данные
Выведите единственное число: максимальное недовольство, которое испытает Анна в процессе прослушивания оптимально составленного плейлиста, или -1, если плейлист составить невозможно.
Решение задачи
Научимся решать задачу без дополнительного параметра Ui.
Дан ориентированный граф с N вершинами и M дугами, требуется определить, можно ли построить такую последовательность вершин графа, что любые две соседние вершины соединены дугой, и все N различных вершин графа входят в эту последовательность.
Заметим, что сильно связную компоненту этого графа можно заменить на одну вершину. Это можно сделать, т.к. для любого сильно связного графа можно построить последовательность вершин, в которой все вершины графа будут встречаться не менее одного раза. Докажем это утверждение. Предположим у нас есть какая-то последовательность с K различными вершинами, заканчивающаяся вершиной x. Выберем любую из еще не представленных в ней вершин y, т.к. граф сильно связный, то существует цепочка дуг ведущая из x в y, добавим вершины, через которые проходит эта цепочка в последовательность. В новой полученной последовательности не менее K?+?1 различной вершины.
После того, как мы сжали сильно связные компоненты графа в новые вершины, останется ориентированный граф без циклов. Несложно видеть, что для того, чтобы можно было построить исходную последовательность вершин, у этого графа должен быть единственный способ упорядочить вершины топологически, причем между любыми двумя соседними вершинами в топологическом подрядке должна быть дуга.
Дополнительно заметим, что если для какого-то графа можно построить требуемую последовательность вершин, то и после добавление дополнительных дуг в него, это свойство сохранится.
Ответ на задачу будем искать двоичным поиском по максимальному недовольству, которое испытает Анна в процессе прослушивания оптимально составленного плейлиста.
Итак, получаем следующий алгоритм решения задачи:
Двоичным поиском выберем значение U, для которого оставим только дуги с Ui???U в графе.
Стянем сильно связные компоненты полученного графа в отдельные вершины.
В полученном графе найдем топологический порядок вершин, проверим, что между всеми парами соседних вершин есть дуга.
В зависимости от того удалось или нет найти требуемую последовательность для заданного значения U, определяем в какую сторону двигаться двоичному поиску.
Полезные ссылки:
en.wikipedia.org/wiki/Strongly_connected_component
en.wikipedia.org/wiki/Topological_sorting
Иван — обычный пользователь интернета. Одна из любимых игр Ивана — «Шляпа», в которой нужно быстро объяснять загаданное слово. Для того, чтобы играть было интересно, он ищет необычные слова в интернете, задавая различные поисковые запросы.
Ивана всегда интересовало, почему один документ оказывается выше другого в поисковой выдаче. Задав запрос об этом в поиске Яндекса, Иван выяснил, что документы упорядочиваются автоматически по убыванию релевантности документов. А релевантность, в свою очередь, вычисляется по формуле, подобранной специальным алгоритмом.
В этой задаче мы будем использовать упрощенную версию формулы релевантности — линейную комбинацию параметров документа. Формула ранжирования задается N параметрами (a1,?a2,?...,?aN), а каждый документ описывается N числовыми параметрами (f1,?f2,?...,?fN).
Релевантность же определяется по формуле:
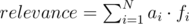
Интернет очень быстро изменяется, и некоторые документы могут меняться несколько раз в минуту. Конечно, после этого необходимо изменить и некоторые параметры этого документа.
Можете ли вы в условиях изменяющихся параметров документов находить самые релевантные?
Входные данные
В первой строке входных данных записано одно целое число N (1???N???100) — количество параметров в формуле ранжирования. Вторая строка содержит N целых чисел ai (0???ai???100 000 000).
В третей строке входных данных записано одно целое числа D (10???D???100?000, N·D???100?000) — количество документов для ранжирования. Далее в D строках записано по N целых чисел fij(0???fij???100 000 000) — числовые параметры i-го документа.
Следующая строка содержит одно целое число Q (1???Q???100?000) — количество запросов к системе ранжирования. Следующие Q строк описывают запросы. Запрос на выдачу самых релевантных документов задается парой 1 K (1???K???10). Запрос на изменение параметра документа задается четверкой 2 d j v (1???d???D, 1???j???N, 0???v???100 000 000) и означает, что j-ый параметр у d-го документа становится равным v.
Выходные данные
После каждого запроса первого типа выведите в одну строку порядковые номера K самых релевантных документов в порядке убывания релевантности (числа следует разделять одиночными пробелами). Гарантируется, что все документы в любой момент времени имеют различные значения релевантности.
Решение задачи
Начнем с анализа запросов второго типа. Заметим, что при выполнении таких запросов релевантность изменяется только у одного документа, и более того, новую релевантность можно вычислить за O(1).
Для выполнения запросов первого типа нужно находить K максимальных элементов в списке релевантности. Для этого можно использовать сбалансированное дерево поиска.
При реализации на языке C++ можно использовать стандартный контейнер std::map, а при использовании Java -TreeMap. При использовании этих контейнеров можно удалять старые значения релевантности документов по ключу, и после этого добавлять документ уже с новым значением, а максимальные искать частичным проходом итератора от максимального ключа.
Операции второго типа будут обрабатываться за) (удаление и добавление по ключу), а операции нахождения K максимальных за
(удаление и добавление по ключу), а операции нахождения K максимальных за ) (как минимум для C++).
(как минимум для C++).
Роман — обычный пользователь интернета. Как и многие другие обычные пользователи, Роман очень нетерпелив. Например, сейчас Роман ждёт обновления новостей на главной странице Яндекса и постоянно жмёт «Обновить» в браузере. Для того, чтобы не перегрузить Яндекс огромным количеством запросов (Роман очень нетерпелив!), все запросы Романа складываются в очередь, откуда отправляются на сервис новостей таким образом, чтобы запросы шли не чаще, чем некоторая заданная в конфигурации частота.
Ограничение на частоту может быть задано двумя способами: не более X запросов в секунду либо 1 запрос не чаще, чем в Y секунд. Каждый запрос Романа будет обработан в тот момент времени, в который его обработка не приведёт к нарушению ограничения на частоту, но, естественно, не раньше того момента, как запрос был отправлен. Для более подробного пояснения смотрите примеры.
Сможете ли вы написать программу, которая моделирует работу сервиса по ограничению частоты запросов и сообщает, в какой момент обработан каждый запрос?
Входные данные
В первой строке записано ограничение частоты в формате X / Y, где X и Y — два целых числа (1???X,?Y???10 000), хотя бы одно из которых равно 1. Если Y?=?1, то сервис не должен обрабатывать более X запросов в секунду. Если X?=?1, то сервис не должен обрабатывать более, чем один запрос в Y секунд.
Во второй строке содержится число N (1???N???100 000) — количество запросов обновления страницы, которые Роман отослал на сервер, нажимая кнопку «Обновить» в браузере.
Следующая строка содержит N целых чисел ti (1???ti???1 000 000 000 000 000 000), разделённых пробелами — времена отсылки запросов, заданные в наносекундах (в одной секунде 1 000 000 000 наносекунд). Гарантируется, что числа ti расположены по неубыванию.
Выходные данные
Выведите N чисел, разделённых пробелами — время обработки каждого запроса. Смотрите примеры для пояснения.
Решение задачи
Для решения задачи достаточно считывать по очереди времена всех запросов и записывать в массив времена, когда они были обработаны. Для того, чтобы получить время обработки i-го запроса, достаточно взять минимум из времени его поступления и времени обработки (i?-?X)-го запроса, увеличенного на Y·1 000 000 000 (в случае, если i???X, запрос будет обработан сразу же при поступлении).
Алексей — обычный пользователь интернета. Однажды, пользуясь сервисом Яндекс.Карты, Алексей задумался: ведь наверняка итоговое изображение на экране формируется из нескольких прямоугольных изображений меньшего размера, получаемых с сервера. Алексею стало интересно: сколько существует возможных размеров изображений таких, что из них можно составить картинку, видимую на экране.
Видимая область карты занимает N???M пикселей на экране Алексея. Его интересует количество пар (A,?B) (1???A???N,?1???B???M) таких, что прямоугольниками A???B можно выложить прямоугольник N???M, размещая их вплотную друг с другом, без накладываний и поворотов. При этом Алексей уверен, что посылать большие картинки с сервера очень накладно, и поэтому его не интересуют пары (A,?B), для которых A·B?>?R. Также Алексей понимает, что посылать большое количество маленьких картинок тоже невыгодно, поэтому его не интересуют пары (A,?B), для которых A·B?<?L.
Помогите Алексею ответить на интересующий его вопрос.
Входные данные
Единственная строка входного файла содержит четыре целых числа N, M, L, R (1???N,?M???1 000 000 000,?1???L???R???N·M), разделённых пробелами.
Выходные данные
Выведите единственное число: количество возможных пар, удовлетворяющих требованиям Алексея.
Решение задачи
Из условия, что прямоугольниками A???B можно выложить прямоугольник N???M следует, что N делится на A, а M делится на B. Сформируем список Dn, состоящий из делителей N, и список Dm из делителей M. Как известно, найти все делители какого-либо числа X можно за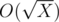 . Имея два таких списка, можно двумя вложенными циклами перебрать всех пары-кандидаты (A,?B) и проверить выполнение условия L???A·B???R. Если условие выполняется, ответ нужно увеличить на 1.
. Имея два таких списка, можно двумя вложенными циклами перебрать всех пары-кандидаты (A,?B) и проверить выполнение условия L???A·B???R. Если условие выполняется, ответ нужно увеличить на 1.

Бонус: наибольшее количество делителей у числа до 1 000 000 000 — 1344.
Юра — обычный пользователь интернета. Он очень любит читать историю городов мира, а еще больше он любит путешествовать и во время этих путешествий рассказывать друзьям о том, что происходило в том или ином месте в X или XVI столетии. Когда Юра приезжает в новый город, у него уже готов список достопримечательностей этой местности, и остается только правильно проложить маршрут к этим местам.
Для того, чтобы проложить хороший маршрут, Юра пользуется сервисом Яндекс.Карты. Однажды он обратил внимание на кнопку со светофором и нажал на нее. Дороги на карте раскрасились в различные цвета. Юра заинтересовался, как Яндекс определяет загруженность дорог, и решил поискать информацию в интернете.
В этой задаче мы используем упрощенную версию определения загруженности дорог. Все дороги в сервисе карт пронумерованы целыми числами от 1 до M. Про каждую дорогу известны два числа Li и Ri. Если в текущий момент времени на дороге находится менее Li автомобилей, то дорога считается свободной, и на карте она рисуется зеленым цветом. Если же в текущий момент времени на дороге находится более Ri автомобилей, то дорога считается загруженной, и на карте она рисуется красным цветом. Если дорога не является ни свободной, ни загруженной, то она рисуется на сервисе оранжевым цветом.
Вам дано описание дорог с сервиса карт и информация о том, где расположены N автомобилей. Можете ли вы определить, каким цветом должны быть нарисованы эти дороги на карте?
Входные данные
В первой строке входных данных записано целое число M (1???M???1 000) — количество дорог. Далее следуют M строк по два целых числа Li и Ri (1???Li???Ri???10) в каждой — параметры i-й дороги. В следующей строке записано одно целое число N (1???N???1 000) — количество автомобилей, находящихся на дорогах в данный момент. Следующая строка содержит N целых чисел rj (1???rj???M) — номера дорог, где расположены автомобили.
Выходные данные
Выведите M строк, по одной для каждой дороги из входных данных. Если i-ая дорога должна быть нарисована красным, то в i-ой строке выведите «Red», если оранжевым — «Orange», иначе выведите «Green».
Решение задачи
Для начала в задаче нужно для каждой дороги подсчитать количество автомобилей, находящихся на ней. А затем для каждой дороги по ее параметрам легко определить степень ее загруженности.
Также достаточно простая реализация получается на языке python:
В этом году впервые помимо традиционных призов победители получат возможность попасть на стажировку в Яндекс. 22 мая регистрация закроется и останется только следить за другими участниками в отборочных раундах. Квалификационный раунд продлится в этом году двое суток — с 21 по 22 мая. Раунды вновь будут оцениваться по системе TCM/Time. Для тех, кому интересно, какой сложности задачи их ждут, мы разобрали тур прошлогодней квалификации. Также у вас есть возможность потренироваться на нем.
UPDATE: Уже начался квалификационный раунд Яндекс.Алгоритма 2016, приходите порешать задачи, которые мы обязательно разберем в будущем. На наш взгляд, задачки не хуже, чем в прошлом году.
A. Опечатки
Михаил — обычный пользователь интернета. Когда Михаил ищет что-либо в интернете с помощью Яндекса, случается, что он допускает опечатки в поисковом запросе. Конечно же, в большинстве случаев Яндекс может угадать, что имел в виду Михаил и исправить запрос. Например, если Михаил опечатается и напишет «дезоксирибонукленовая» (что неудивительно), Яндекс исправит запрос на «дезоксирибонуклеиновая».
Возможно, вы подумали, что в этой задаче вам нужно написать программу, исправляющую опечатки в запросе пользователя. Это не так: кроме этой задачи вам предложено ещё 5 увлекательнейших задач, а времени до конца соревнования осталось не так уж много. Просто проверьте, содержит ли очередной запрос Михаила опечатки.
Входные данные
В первой строке входного файла находится запрос Михаила: от 1 до 5 слов, состоящих из строчных латинских букв и разделённых одиночными пробелами. Вторая строка содержит целое число N (1???N???100): количество слов, содержащихся в словаре Яндекса (не волнуйтесь, в реальности количество слов, содержащихся в словарях Яндекса, гораздо больше ста). Третья строка содержит слова из словаря. Каждое слово представляет собой строку, состоящую из строчных латинских букв. Слова разделены одиночными пробелами. Гарантируется, что и слова из запроса, и слова из словаря содержат не более 20 букв.
Выходные данные
В единственной строке выходного файла выведите «Correct» (без кавычек), если все слова из запроса Михаила содержатся в имеющемся словаре, и «Misspell» (без кавычек), если хотя бы одного слова в словаре нет.
Решение задачи
В задаче требовалось определить, входят ли все слова из первого множества во второе множество.
С ограничениями в этой задаче хватило бы простого решения тривиального за O(N·M), где N и M — размеры первого и второго множества, соответственно. Для его реализации нужно непосредственно проверить, что каждое слово из первого множества находится во втором.
Достаточно простая реализация получается на языке python:
import sys
words = sys.stdin.readline().split()
_ = sys.stdin.readline()
d = sys.stdin.readline().split()
print "Correct" if all(word in d for word in words) else "Misspell"
B. Оптимальный плейлист
Анна — обычный пользователь интернета. Анна очень любит слушать музыку и пользоваться сервисом Яндекс.Музыка. Однажды, слушая песни на Яндекс.Музыке в режиме случайного перемешивания, Анна была очень расстроена тем, что после её любимой группы «Эпидемия» внезапно заиграл Григорий Лепс. Пылающая от негодования Анна написала гневное письмо в техническую поддержку сервиса, после чего команда разработчиков Яндекс.Музыки решила улучшить выбор следующей песни для проигрывания.
Всего на сервисе находится N песен, каждую из которых Анна хочет послушать хотя бы один раз. При этом Анна не возражает против повторного прослушивания песен, однако очень возражает против резкой смены жанров. В базе данных Яндекс.Музыки помимо самой музыки содержится информация о том, насколько некоторые песни похожи по жанру друг на друга. Каждая запись имеет вид (a,?b,?U) и означает, что если включить песню с номером b сразу после песни с номером a, пользователь испытает U единиц недовольства.
Известно, что все пользователи, и Анна в том числе, обращают внимание на самые неудачные переключения песен, поэтому недовольством от прослушивания некоторого плейлиста назовём максимум по всем недовольствам от переключения подряд идущих песен.
Имея такие данные, Яндекс.Музыка должна составить оптимальный для пользователя плейлист, удовлетворяющий следующим условиям:
- Каждая песня содержится в нём хотя бы один раз;
- Для каждой пары соседних песен имеется соответствующая запись в базе данных (лучше не переключать песни, не зная, чем это может обернуться);
- Недовольство от прослушивания плейлиста должно быть как можно меньше.
Сможете ли вы составить плейлист, удовлетворяющий указанным условиям?
Входные данные
В первой строке входного файла содержатся два целых числа N и M (1???N???100 000,?1???M???200 000), разделённые пробелами: количество песен, которые хочет прослушать Анна и количество записей о переходах между этими песнями, соответственно. Следующие M строк содержат по три целых числа ai,?bi,?Ui (1???ai,?bi???N,?ai???bi,?1???Ui???1 000 000 000), разделённых пробелами, которые говорят о том, что если включить песню с номером bi сразу после песни с номером ai, пользователь испытает Ui единиц недовольства. Гарантируется, что никакой переход от одной песни к другой не встречается в записях дважды.
Выходные данные
Выведите единственное число: максимальное недовольство, которое испытает Анна в процессе прослушивания оптимально составленного плейлиста, или -1, если плейлист составить невозможно.
Решение задачи
Научимся решать задачу без дополнительного параметра Ui.
Дан ориентированный граф с N вершинами и M дугами, требуется определить, можно ли построить такую последовательность вершин графа, что любые две соседние вершины соединены дугой, и все N различных вершин графа входят в эту последовательность.
Заметим, что сильно связную компоненту этого графа можно заменить на одну вершину. Это можно сделать, т.к. для любого сильно связного графа можно построить последовательность вершин, в которой все вершины графа будут встречаться не менее одного раза. Докажем это утверждение. Предположим у нас есть какая-то последовательность с K различными вершинами, заканчивающаяся вершиной x. Выберем любую из еще не представленных в ней вершин y, т.к. граф сильно связный, то существует цепочка дуг ведущая из x в y, добавим вершины, через которые проходит эта цепочка в последовательность. В новой полученной последовательности не менее K?+?1 различной вершины.
После того, как мы сжали сильно связные компоненты графа в новые вершины, останется ориентированный граф без циклов. Несложно видеть, что для того, чтобы можно было построить исходную последовательность вершин, у этого графа должен быть единственный способ упорядочить вершины топологически, причем между любыми двумя соседними вершинами в топологическом подрядке должна быть дуга.
Дополнительно заметим, что если для какого-то графа можно построить требуемую последовательность вершин, то и после добавление дополнительных дуг в него, это свойство сохранится.
Ответ на задачу будем искать двоичным поиском по максимальному недовольству, которое испытает Анна в процессе прослушивания оптимально составленного плейлиста.
Итак, получаем следующий алгоритм решения задачи:
Двоичным поиском выберем значение U, для которого оставим только дуги с Ui???U в графе.
Стянем сильно связные компоненты полученного графа в отдельные вершины.
В полученном графе найдем топологический порядок вершин, проверим, что между всеми парами соседних вершин есть дуга.
В зависимости от того удалось или нет найти требуемую последовательность для заданного значения U, определяем в какую сторону двигаться двоичному поиску.
Полезные ссылки:
en.wikipedia.org/wiki/Strongly_connected_component
en.wikipedia.org/wiki/Topological_sorting
C. Ранжирование документов
Иван — обычный пользователь интернета. Одна из любимых игр Ивана — «Шляпа», в которой нужно быстро объяснять загаданное слово. Для того, чтобы играть было интересно, он ищет необычные слова в интернете, задавая различные поисковые запросы.
Ивана всегда интересовало, почему один документ оказывается выше другого в поисковой выдаче. Задав запрос об этом в поиске Яндекса, Иван выяснил, что документы упорядочиваются автоматически по убыванию релевантности документов. А релевантность, в свою очередь, вычисляется по формуле, подобранной специальным алгоритмом.
В этой задаче мы будем использовать упрощенную версию формулы релевантности — линейную комбинацию параметров документа. Формула ранжирования задается N параметрами (a1,?a2,?...,?aN), а каждый документ описывается N числовыми параметрами (f1,?f2,?...,?fN).
Релевантность же определяется по формуле:
Интернет очень быстро изменяется, и некоторые документы могут меняться несколько раз в минуту. Конечно, после этого необходимо изменить и некоторые параметры этого документа.
Можете ли вы в условиях изменяющихся параметров документов находить самые релевантные?
Входные данные
В первой строке входных данных записано одно целое число N (1???N???100) — количество параметров в формуле ранжирования. Вторая строка содержит N целых чисел ai (0???ai???100 000 000).
В третей строке входных данных записано одно целое числа D (10???D???100?000, N·D???100?000) — количество документов для ранжирования. Далее в D строках записано по N целых чисел fij(0???fij???100 000 000) — числовые параметры i-го документа.
Следующая строка содержит одно целое число Q (1???Q???100?000) — количество запросов к системе ранжирования. Следующие Q строк описывают запросы. Запрос на выдачу самых релевантных документов задается парой 1 K (1???K???10). Запрос на изменение параметра документа задается четверкой 2 d j v (1???d???D, 1???j???N, 0???v???100 000 000) и означает, что j-ый параметр у d-го документа становится равным v.
Выходные данные
После каждого запроса первого типа выведите в одну строку порядковые номера K самых релевантных документов в порядке убывания релевантности (числа следует разделять одиночными пробелами). Гарантируется, что все документы в любой момент времени имеют различные значения релевантности.
Решение задачи
Начнем с анализа запросов второго типа. Заметим, что при выполнении таких запросов релевантность изменяется только у одного документа, и более того, новую релевантность можно вычислить за O(1).
Для выполнения запросов первого типа нужно находить K максимальных элементов в списке релевантности. Для этого можно использовать сбалансированное дерево поиска.
При реализации на языке C++ можно использовать стандартный контейнер std::map, а при использовании Java -TreeMap. При использовании этих контейнеров можно удалять старые значения релевантности документов по ключу, и после этого добавлять документ уже с новым значением, а максимальные искать частичным проходом итератора от максимального ключа.
Операции второго типа будут обрабатываться за
D. Ограничитель частоты
Роман — обычный пользователь интернета. Как и многие другие обычные пользователи, Роман очень нетерпелив. Например, сейчас Роман ждёт обновления новостей на главной странице Яндекса и постоянно жмёт «Обновить» в браузере. Для того, чтобы не перегрузить Яндекс огромным количеством запросов (Роман очень нетерпелив!), все запросы Романа складываются в очередь, откуда отправляются на сервис новостей таким образом, чтобы запросы шли не чаще, чем некоторая заданная в конфигурации частота.
Ограничение на частоту может быть задано двумя способами: не более X запросов в секунду либо 1 запрос не чаще, чем в Y секунд. Каждый запрос Романа будет обработан в тот момент времени, в который его обработка не приведёт к нарушению ограничения на частоту, но, естественно, не раньше того момента, как запрос был отправлен. Для более подробного пояснения смотрите примеры.
Сможете ли вы написать программу, которая моделирует работу сервиса по ограничению частоты запросов и сообщает, в какой момент обработан каждый запрос?
Входные данные
В первой строке записано ограничение частоты в формате X / Y, где X и Y — два целых числа (1???X,?Y???10 000), хотя бы одно из которых равно 1. Если Y?=?1, то сервис не должен обрабатывать более X запросов в секунду. Если X?=?1, то сервис не должен обрабатывать более, чем один запрос в Y секунд.
Во второй строке содержится число N (1???N???100 000) — количество запросов обновления страницы, которые Роман отослал на сервер, нажимая кнопку «Обновить» в браузере.
Следующая строка содержит N целых чисел ti (1???ti???1 000 000 000 000 000 000), разделённых пробелами — времена отсылки запросов, заданные в наносекундах (в одной секунде 1 000 000 000 наносекунд). Гарантируется, что числа ti расположены по неубыванию.
Выходные данные
Выведите N чисел, разделённых пробелами — время обработки каждого запроса. Смотрите примеры для пояснения.
Решение задачи
Для решения задачи достаточно считывать по очереди времена всех запросов и записывать в массив времена, когда они были обработаны. Для того, чтобы получить время обработки i-го запроса, достаточно взять минимум из времени его поступления и времени обработки (i?-?X)-го запроса, увеличенного на Y·1 000 000 000 (в случае, если i???X, запрос будет обработан сразу же при поступлении).
E. Размер карт
Алексей — обычный пользователь интернета. Однажды, пользуясь сервисом Яндекс.Карты, Алексей задумался: ведь наверняка итоговое изображение на экране формируется из нескольких прямоугольных изображений меньшего размера, получаемых с сервера. Алексею стало интересно: сколько существует возможных размеров изображений таких, что из них можно составить картинку, видимую на экране.
Видимая область карты занимает N???M пикселей на экране Алексея. Его интересует количество пар (A,?B) (1???A???N,?1???B???M) таких, что прямоугольниками A???B можно выложить прямоугольник N???M, размещая их вплотную друг с другом, без накладываний и поворотов. При этом Алексей уверен, что посылать большие картинки с сервера очень накладно, и поэтому его не интересуют пары (A,?B), для которых A·B?>?R. Также Алексей понимает, что посылать большое количество маленьких картинок тоже невыгодно, поэтому его не интересуют пары (A,?B), для которых A·B?<?L.
Помогите Алексею ответить на интересующий его вопрос.
Входные данные
Единственная строка входного файла содержит четыре целых числа N, M, L, R (1???N,?M???1 000 000 000,?1???L???R???N·M), разделённых пробелами.
Выходные данные
Выведите единственное число: количество возможных пар, удовлетворяющих требованиям Алексея.
Решение задачи
Из условия, что прямоугольниками A???B можно выложить прямоугольник N???M следует, что N делится на A, а M делится на B. Сформируем список Dn, состоящий из делителей N, и список Dm из делителей M. Как известно, найти все делители какого-либо числа X можно за
. Имея два таких списка, можно двумя вложенными циклами перебрать всех пары-кандидаты (A,?B) и проверить выполнение условия L???A·B???R. Если условие выполняется, ответ нужно увеличить на 1.Бонус: наибольшее количество делителей у числа до 1 000 000 000 — 1344.
F. Загруженность дорог
Юра — обычный пользователь интернета. Он очень любит читать историю городов мира, а еще больше он любит путешествовать и во время этих путешествий рассказывать друзьям о том, что происходило в том или ином месте в X или XVI столетии. Когда Юра приезжает в новый город, у него уже готов список достопримечательностей этой местности, и остается только правильно проложить маршрут к этим местам.
Для того, чтобы проложить хороший маршрут, Юра пользуется сервисом Яндекс.Карты. Однажды он обратил внимание на кнопку со светофором и нажал на нее. Дороги на карте раскрасились в различные цвета. Юра заинтересовался, как Яндекс определяет загруженность дорог, и решил поискать информацию в интернете.
В этой задаче мы используем упрощенную версию определения загруженности дорог. Все дороги в сервисе карт пронумерованы целыми числами от 1 до M. Про каждую дорогу известны два числа Li и Ri. Если в текущий момент времени на дороге находится менее Li автомобилей, то дорога считается свободной, и на карте она рисуется зеленым цветом. Если же в текущий момент времени на дороге находится более Ri автомобилей, то дорога считается загруженной, и на карте она рисуется красным цветом. Если дорога не является ни свободной, ни загруженной, то она рисуется на сервисе оранжевым цветом.
Вам дано описание дорог с сервиса карт и информация о том, где расположены N автомобилей. Можете ли вы определить, каким цветом должны быть нарисованы эти дороги на карте?
Входные данные
В первой строке входных данных записано целое число M (1???M???1 000) — количество дорог. Далее следуют M строк по два целых числа Li и Ri (1???Li???Ri???10) в каждой — параметры i-й дороги. В следующей строке записано одно целое число N (1???N???1 000) — количество автомобилей, находящихся на дорогах в данный момент. Следующая строка содержит N целых чисел rj (1???rj???M) — номера дорог, где расположены автомобили.
Выходные данные
Выведите M строк, по одной для каждой дороги из входных данных. Если i-ая дорога должна быть нарисована красным, то в i-ой строке выведите «Red», если оранжевым — «Orange», иначе выведите «Green».
Решение задачи
Для начала в задаче нужно для каждой дороги подсчитать количество автомобилей, находящихся на ней. А затем для каждой дороги по ее параметрам легко определить степень ее загруженности.
Также достаточно простая реализация получается на языке python:
import sys
M = int(sys.stdin.readline())
LR = []
C = [0] * M
for i in xrange(M):
LR.append(map(int, sys.stdin.readline().split()))
N = int(sys.stdin.readline())
for r in map(int, sys.stdin.readline().split()):
C[r - 1] += 1
for i in xrange(M):
print "Green" if C[i] < LR[i][0] else ("Red" if C[i] > LR[i][1] else "Orange")
Поделиться с друзьями
DarkGenius
Спасибо за подробный разбор и интересные задачи!
altolstikov
Ждем всех на квалификационном раунде Яндекс.Алгоритма 2016, который уже начался.