

Лет пять назад я уже писал на Хабре серию статей про биометрию и то как она устроена (1, 2, 3). Как ни странно, за эти годы достаточно мало что изменилось, хотя изменения и произошли. В этой статье я попробую как можно более популярно рассказать про сегодняшние технологии, про то какой прогресс идёт и почему к словам Грефа о том, что к словам «карта, основная задача которой состоит в идентификации, уходит в прошлое» стоит относится с скептицизмом.
Самое главное
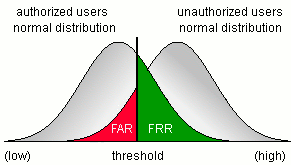
В биометрии есть одна главная характеристика, которая определяет качество любой системы. Точнее их две, но они неразрывны:
• Вероятность ложного сопоставления с объектом в базе (вероятность ложного допуска, FAR- false access rate)
• Вероятность отказа распознавания объекта находящегося в базе (FRR — false reject rate)
Написать программу с 100% точностью подтверждающей личность человека может каждый из вас за минуту. Нужно просто всегда выводить «да, это искомый человек». Только вот ложное сопоставление у такой программы тоже будет 100%. Сможет пройти любой человек.
Теперь вы знаете, что когда Греф говорит про 99.9% точности — то вам что-то недоговаривают.
Пару слов о точности
Точность это вообще такая штука, про которую сложно говорить в контексте больших цифр. 99.9% это много или мало? А вероятность 90%, может это достаточно?
Возьмём FAR равным 0.1% (хвалёные 99.9%). Предположим, что сам с собой человек совпадает всегда (FRR=0, хотя это будет далеко не так).
Предположим, в вашей компании работает 100 человек и вы хотите сделать учёт рабочего времени. При FAR=0.1% человек будет принят за кого-то другого примерно в 100*0.1=10% случаев. То есть из 100 сотрудников 10 человек будут проходить как другие люди каждый день.

С другой стороны, данных характеристик хватает в тех случаях, когда у человека есть карта доступа. Чтобы проникнуть на ваше предприятие ему понадобиться воспользоваться картой примерно 1000 раз, чтобы сойти за её владельца. При минимальной охране это невозможно
Точности 0.1% FAR вполне достаточны так же для обеспечения верификации пользователя CALL-центра (после того как он представился, или после определения его номера телефона), но не для идентификации.
Пока что рассмотрим другой пример. Вероятность по глазу (один из самых точных методов распознавания) принять одного человека за другого (FAR) — 0.00001%. Кажется, что это очень хорошо? Но если в нашем банке миллион клиентов, а мы не используем карточки? А значит это, что у каждого пользователя с вероятностью 10% у нас выпадает джекпот — доступ к чужому счёту.
Конечно, можно распознавать по двум глазам, всё будет значительно лучше, вероятность ложного доступа будет всего 0.0001%. Но если за день банкоматами пользуются хотя бы 100 тысяч человек, то каждый день с вероятностью 10% мы будем иметь один ложный доступ к чужому счёту.
Хитрости в процентах
В реальности вас обманывают. Как я говорит, всё написанное выше без учёта FRR. Ошибочный отказ доступа тоже неприятен. Как его считают разработчики:
• Самые честные делают так: берём открытую базу с биометрическими характеристиками, считаем что получается.
• Жуликоватые производители выкидывают из базы одного-двух человек, которые портят всю статистику. Такие люди всегда есть.
А теперь секрет. Первый пункт это тоже обман. Хотя и законспирированный. Открытые базы — это зачастую идеальные картинки/данные, которые набирали в лаборатории при правильном освещении/уровне шумов. Все нерезкое/двусмысленное из таких баз убирают вручную.
В реальности всё не так хорошо. Предположим я хочу пройти по радужке глаза или по лицу или по венам рук (и там и там сканеры очень похожи). С чем я могу столкнуться?
1. Сканер не заметит, что у него кто-то появился в поле зрения
2. Сканер неправильно выставит фокус
3. Сканер засвечен солнцем
4. Сканер захватит не то что нужно
5. Параметры моей биометрической характеристики находятся вне пределах работы алгоритма: огромная/маленькая рука, ожог лица, изменённая геометрия радужки
6. Базы на которых работает алгоритм распознавания голоса обычно набирают не в метро и не на самых плохих телефонах.
Всё это не учитывается при подсчёте FRR.
В результате алгоритм, который даёт 0.1% отказов при распознавании человека по базе зачастую даёт 20-30% в реальных условиях. И это не проблема базового алгоритма, зачастую это проблема используемой техники или условий в которых она используется.
Эти 20-30% пользователей пробуют повторить распознавание во второй, третий, четвёртый раз. Статистика FAR растёт.
Ошибки
А есть люди, которые вообще не работают. Например по отпечаткам пальцев. Нам рассказывали, что на химзаводе 20% персонала не имело отпечатков, которые мог бы захватить сканер. Есть люди с заболеванием глаз/рук/голоса/лица, которые НИКОГДА не распознаются. В принципе.
Для каждого алгоритма есть определённый процент таких людей. Производители зачастую его умалчивают или сами не знают, если не имели опыта большого внедрения.
Люди
Люди не любят пользоваться чем-то новым. В особенности если оно их контролирует. Не хотят учиться. Я видел людей, которые принципиально не могли отсканировать свою руку. Всегда прикладывали с ошибкой и не слушали советов. Видел людей которые панически боялись сканирования глаза (это даже какая-то распространённая фобия). А уж сколько людей пытаются поломать ненавистные им сканеры по учёту рабочего времени, завесив тряпкой/замазав или испачкав камеру.
Да, установив сканер компании могут забыт такую тривиальную вещь, как периодически протирать его тряпочкой. Статистика падает.
Системы
Но, давайте отвлечёмся и поговорим конкретно про существующие системы. Что произошло в последние годы и куда идёт прогресс. Всё-таки вчера Сбербанк заявлял о принципиально новых решениях.
Пара общих слов. Прогресс не стоит на месте, но экспоненциального роста нет. Например новомодный Deep Learning, который в последнее время всё рвёт и мечет, затронул лишь несколько областей биометрии. Зато происходит безумный прогресс в электронике. Вычислительная мощь появляется в каждой плате. Raspberry Pi, Jetson, и.т.д.
Большая часть написанного нами 5 лет назад по прежнему актуальна. Основные изменения я попробую отразить.
Серьезная биометрия
Серьезная биометрия — это такая биометрия, которую можно применять где угодно вне зависимости от контекста. Она имеет наилучшие характеристики. Зачастую её можно ставить в режим идентификации по базе (когда мы имеем дело с небольшой компанией).
Глаза
Моя любимая тема — распознавание по радужке глаза. статистически это самая мощная и быстрая технология. У неё всегда было два больших минуса. Цена аппаратуры и удобство использования. Сейчас идёт планомерное развитие именно в этих направлениях. Есть существенные ограничения накладываемые оптикой, которая более-менее дошла до своего предела. Скорее всего в ближайшие годы произойдёт некоторое продвижение технологии за счёт новой базы по электронике. Пока что используется достаточно редко.
Пальцы
Пять лет назад мне казалось, что распознавание по папиллярному узору достигло всего чего только могло. Как я ошибался. За последние годы было выдвинуто много принципиально новых идей:
• Распознавание по 3d образу пальца. Есть несколько конкурирующих алгоритмов, но найти смог только эту ссылку. Разница — в используемом 3д сканере

• Распознавание по сосудам видным в ИК. Опять же, как я видел на выставках, сейчас есть несколько конкурирующих идей

• Принципиально другая математика, не завязанная на стандартные дактилоскопические признаки. Применение адекватных моделей пальца и корреляционных алгоритмов.
Если честно, то я даже не знаю характеристик большей части всех этих новых систем. Они лучше, чем обычная биометрия по пальцам. Говорят, что сильно меньше процент неработающих людей. Точно более высокая цена, чем у стандартных сканеров пальцев.
Пока нет баз на которых можно было бы независимо опробовать и подтвердить проценты. Каждый производитель создаёт свой специфичный сканер — в этом его новизна и уникальность.
Пальцы — наиболее часто используемая технология, но редко кто использует новомодные улучшения. Обычно используется самая слабая версия.
Вены рук
Очень хорошая характеристика. Проигрывает по точностям радужке глаза, но превосходит по удобству. Люди куда проще обучаются, более стабильна к внешним условиям. Дешевле, чем радужка глаза.

За последние годы несколько подешевела аппаратная база, но в целом — технология сейчас достаточно стабильна.
3д лицо
Алгоритм по 3д лицу напрямую привязаны к существующим 3д сканерам и их цене. Этим обусловлено их развитие. Сама по себе характеристика неплохая, сравнимая с венами рук. Но значительно удобнее и чем вены и чем радужка. Достаточно просто посмотреть на сканер и вас пропустило.
Так как 3д сканеров сейчас существует десяток, то на каждый из них может быть своя система. Точность системы обычно обусловлена качеством сканера. Например можно распознавать лица и через RealScense, но высокой точности не будет.
Для большинства систем, данное направление — одно из самых дорогих по цене сканера. Многие фирмы не озвучивают ценник.
Биометрия для специальных целей
Вся биометрия которую я отметил выше была ещё 5 лет назад. Пусть чуть-чуть в другом формате. Но два направления потерпели за эти годы принципиальное развитие. Они не стали «серьезными методами», но они стали работоспособными. Это верификация по голосу и по 2д лицу. Лет пять назад их было практически невозможно использовать. Сейчас они достаточно неплохо закрепились в задачах верификации (подтверждения личности человека) и в задачах прореживания базы. И там и там метод должен использоваться в качестве «подсказки» для оператора. Например:
• В колл-центрах для подтверждения личности говорящего (голос)
• В магазинах для того чтобы продавец сразу видел что купил покупатель в прошлые разы + обращаться по имени-отчеству (лицо)
• Find Face (лицо)
• Банки перед выдачей кредита (лицо, голос)
Данные методы не дают однозначный результат, но могут быть привлекательны для бизнеса. Именно тут применим нашумевший Deep Learning и тут идёт основной прогресс.
Предсказать, что произойдёт с этими методами в ближайшие годы — невозможно.
Биометрия Just for lulz
Я не знаю как по другому назвать эту биометрию. Конечно, она даёт какую-то вероятность правильно распознать человека и откинуть злоумышленника. Наверное шкафчик в гардеробе запереть можно. Или телефон запаролить, если там ничего важного нет. Но на большее я бы не рассчитывал.
• Биометрия по электрокардиограмме
• Биометрия по почерку
• Биометрия по походке
Где-то раз в пару месяцев на Хабре обязательно бывает статья про что-то очередное из этой серии. Идентификация по тому, как человек держит телефон. Или по тому, как стучит по клавиатуре. Это очень плохие методы, которые при желании всегда можно обойти, которые генерят больше проблем, чем решений.
Умершие методы
Ещё есть пара методов, про которые давно ничего не слышно. Неудобство использования, сложность оборудования, плохая точность:
• Биометрия по сетчатке глаза
• Биометрия по геометрии рук
Что не так с проектом Сбербанка.
Теоретически всю страну можно загнать в биометрическую базу и распознавать по ней. Наверное даже правильно собранный сканер радужки, работающий по двум глазам и 3D лицу — справится с задачей. Но цена такого сканера будет высока. Плюс — его нет на рынке, нужно разрабатывать с нуля.
Проблемы будут те же — мы получим 5-10% пользователей кто не сможет им пользоваться. В масштабах страны это очень много.
Под проектом может не скрываться ничего нового. Возможно имеется ввиду телефонный банкинг + выдача кредитов. Там биометрия давно используется в других банках.
В теме биометрии я периодически кручусь с 2008 года. В основном как разработчик, иногда как консультант. И ещё в 2009 многие банки интересовались этой технологией. Встраивали биометрию в тестовые банкоматы, например. Но ничего тогда не пошло. Принципиально новых технологий с тех пор нет (за исключением Deep Learning лиц и голоса, которые уже используются банками). Меня удивляет вновь оживший интерес к теме.
Так же мне непонятно как реализовать «отказ от карточек» при расплате в магазинах. Сейчас цены хороших и надежных биометрических сканеров начинаются где-то от 600 долларов. Скорее это в районе 1000, особенно с учётом интеграции. И цена во многом оправданна чисто на уровне железа. Ладно, положим, что при миллионных тиражах можно достигнуть 400. По сравнению с мобильными терминалами — это существенная цена.
Если же делать свой сканер глаза+лицо — это несколько тысяч долларов.
Если же работать в режиме «верификация» с дешевыми сканерами пальцев — карточка нужна по прежнему.
Комментарии (26)

LeonidZ
30.05.2016 04:26Поясните, пожалуйста, возможно я просто не понимаю:
> Предположим, в вашей компании работает 100 человек и вы хотите сделать учёт рабочего времени. При FAR=0.1% человек будет принят за кого-то другого примерно в 100*0.1=10% случаев. То есть из 100 сотрудников 10 человек будут проходить как другие люди каждый день.
При FAR = 0.1% человек будет принят за кого-то другого в 0.1% случаев. А если вы умножаете на количество сотрудников (100), то получаете вероятность (10%) того, что хотя бы 1 из 100 сотрудников за этот день будет распознан некорректно. Отсюда можно предполагать, что в среднем за 1 рабочий месяц (20 рабочих дней примерно) в такой компании будет 2 случая некорректного распознавания.
ZlodeiBaal
30.05.2016 04:44Это при сравнении с базой 10%. Сравнение одного человека с базой — 100 сравнений. FAR считается для двух человек.
А ещё учитывайте что у вас 100 человек должно в день пройти.
nmk2002
30.05.2016 11:13Что будет с вашими расчетами, если взять не 100, а 1000 человек?
ZlodeiBaal
30.05.2016 12:21Данный подход более-менее работает для итогового числа 0-50%. Им сложно оценить полностью нерабочую ситуацию. Конечно, там будет не 100% фэйлов при распознавании, будут люди которые даже распознаются и будут работать более менее.
nmk2002
30.05.2016 12:27+1Если я правильно помню тервер, то формула расчета вероятности для такой ситуации такая:
1-(1-0,001)^100 = 0,095 = 9,5%
То есть ваши выводы вроде правильные.

Kolyuchkin
30.05.2016 08:44+1Ознакомьтесь, пожалуйста, с отечественной концепцией применения биометрии — госты из серии ГОСТ Р 52633.
Vasyutka
30.05.2016 11:57вот всегда безумно радовали подобные госты. Вот этот, например, 2007 года. С 2007 года изменилось в биометрии ОЧЕНЬ многое. Да и госты про защиту информации — ну не меняют их под каждую уязвимость. Я уж не говорю про то, что на практике такое творчество — это попытка прописать ограничения для рынка такие, чтобы одна конкретная компания заняла большую долю на рынке (и это не только РФ касается, просто так делают, если это выгодно).

Beowulfenator
30.05.2016 11:39Обычно для сравнения разных биометрических методов используют EER (equal error rate). Это такое значение порога, при котором FAR=FRR. Было бы очень интересно увидеть, какие EER достигаются с помощью рассмотренных в статье методов.
Vasyutka
30.05.2016 11:52так сравнивать можно, но сравнение уж очень кривое. Например, есть вероятность кривого захвата биометрической информации, или у фиксироанного процента людей что-то не так с этим признаком. Скажем, в 2% случаях. Если не делать специальных оговорок, то EER тогда ниже 2% никак не может быть. Но этот же метод дает отличный FAR, например 10^-7, но FRR все также чуть больше 2%. Плохо, что каждый 50ый не может воспользоваться системой, но все зависит от сценария использования. Ему можно оставить пластиковую карту. А другой метод будет крайне низкую надежность, нельзя применить уже для 30 человек, но EER 1%.
ZlodeiBaal
30.05.2016 12:14+1Проблема EER — он не определяет качество системы. Услышав EER нельзя предсказать то, как она будет работать. Это просто непонятная точка в пересечении двух кривых. Рабочие точки могут лежать в других местах. Более того, предположим EER=5%. Это значит, что может быть точка FAR=0.01%, FRR=6%, что даст рабочую систему. А может оказаться что точка с FAR 0.01% будет давать 40% FRR — система нерабочая.
EER хорош, когда сравнивается два очень похожих алгоритма. Он хорош, когда что-то разрабатываешь. Видя как он изменился — понимаешь, что происходит. Но при разговоре о биометрических системах EER странная вещь.

CombatSTUN
30.05.2016 15:04Полностью согласен с автором статьи. Греф делает очень громкие заявления.
В 2009 работал со сканером L-1 Identity Solutions / Bioscrypt V-Flex 4G, переводили склад на учёт рабочего времени по отпечатку. Склад 200-300 человек, в основном простые рабочие из ближней Азии. Специфика их работы предполагает ручной труд при котором велика вероятность повреждения или износа кожи в области пальцев. Был случай когда сканер не смог распознать все 10 пальцев, при условии что был выбран самый щадящий режим сканирования. Либо очень тяжело сканировались участки, после которых повторная идентификация не удавалась.
На мой взгляд идентификация по биометрическим показателям очень сложная вещь, которая предполагает бережное хранение своих биометрических ключей, и использовать её можно только для дополнительной безопасности.
По распознаванию голосом тоже есть множество вопросов, а именно копирование его. Все же знают, что существуют пародисты, которые в некоторых случаях неплохо копируют голоса популярных артистов. Да и сгенерировать голос не является особой проблемой.
Kremnik
30.05.2016 23:40Про голос не соглашусь. Не работаю в системах биометрии, но работаю в системах распознавания звуков и, в частности, голоса. Так вот в человеческом голосе существует не менее 42-х параметров, которые однозначно его (голос) определяют. С точки зрения физики голос это звуковая волна, и она определяется всего тремя параметрами (амплитудой, частотой и начальной фазой), которые входят в гармоническую функцию (синус). Но голос состоит из множества наложений таких синусов.
Так вот человеческое ухо и, далее, наш мозг сигнал усредняет, сглаживает. Но электроника прекрасно записывает, а методы цифровой обработки сигналов прекрасно распознают все эти незаметные колебания в голосе и смогут запросто различить два даже очень похожих голоса. Поэтому люди-звукоподражатели человека обмануть смогут, но электронику вряд ли.
Откуда 42 параметра? Считается, что при производстве звука, когда человек использует свой голосовой аппарат (лёгкие, выдыхаемый воздух, гортань, язык, глотка, полость рта, зубы и т. д.) меняется не менее 42 показателей, которые и определяют звучание голоса.Optik
31.05.2016 07:1842 параметра не так много как кажется. Есть у вас результаты экспериментов на достаточно большой выборке, где подтверждается однозначность значений этих параметров? Из того, что известно мне, точность распознования голоса находится в районе 95-96% (FP, FN не знаю). Это конечно клёво, но не 99,9%. Хотя кто Грефа знает, мож он захочет клиентов заставить и лицом перед камерой вертеть и песни при этом петь.
Vasyutka
31.05.2016 11:20Вопрос их распределения, однозначности обратного восстановления (звучит одинаковый голос, но решение о восстановлении этих параметров не однозначно из-за малейших шумов). Мы не замечая варьируем тон, тембр, темп и все на свете в зависимости от настроения, и эта вариативность нужна, чтобы общаться. опять же помехи! Входил в метро сейчас — стоял банкомат сбербанка, выходил — еще один. шумно.
CombatSTUN
31.05.2016 12:15Спасибо за подробное объяснение. Но получается, что устройства распознавания могут в точности скопировать все параметры голоса и сгенерировать такой же?
Моё суждения в плане безопасности, сводятся к тому, что на данный момент биометрия не настолько надёжна. И её нельзя применять как основной способ идентификации, т.к. любой из биометрических ключей являются открытыми.(Наверно из области фантастики, но руку человека можно отрезать, голос скопировать(если применять с паролем, можно подслушать), насчёт глаз не знаю, но мне кажется когда появятся искусственные глаза, то и этот фактор будет преодолим в безопасности)
Самое неизученное место на теле человека это мозг. И хранение информации в нём, является самым надёжным местом.(Который конечно может подвести самого носителя).
Vasyutka
31.05.2016 14:17одна из проблем речевой идентификации: если использовать одну и туже (уникальную для каждого) фразу, то идентификация становится очень даже не плоха по статистике. Слов в языке много, действительно все по-разному говорят — супер. Проблема в том, что диктофона достаточно (скрытность жучка-микрофона фантастическая), чтобы ходить потом за этого человека. Т.е. признак ОЧЕНЬ открытый. вены — более скрытый. а разные фразу (по запросу с экрана) — очень плохая идентификация. Т.к. хоть и можно заставить человека наговорить всякого, но точно предсказать как он скажет N+1 первую фразу не выйдет (мозг, да). А значит и идентификация не очень
robert_ayrapetyan
Про пальцы — редко где встретишь скан одного пальца, обычно сканируют минимум два (на разных руках), а в случае с некоторыми визами — вообще все 10.
ZlodeiBaal
На проходных часто один. Если не проходит — просят второй приложить. Проходные оптимизируются под скорость. Сложно 10 пальцев быстро отсканировать.
DrZlodberg
Вопрос бюджета. Делается 5 сканеров соответствующе расположенных прямо на дверной ручке. берёшься за ручку — сканирует всю руку. Скорость современных сканеров, вроде, позволяет делать это достаточно не напряжно по времени. Правда тут будут проблемы с сильно большими или маленькими руками, но, думаю, большая часть вполне пройдёт. Можно заточить под маленькие, тогда проблемы будут только у обладателей реально огромных рук (ручку не обязательно обхватывать целиком если у двери нет мощной пружины).
Vasyutka
Можно, но не видели таких продуктов.
с такой контактной системой все-таки есть еще проблема, если это не индивидуальный предмет (как телефон, например), то все-таки жир и грязь налипают.
DrZlodberg
И даже вряд-ли кто будет делать такое. Очень специфичная штука. Однако потенциальная возможность есть, или по индивидуальному заказу сделать не проблема как мне кажется.
С жиром немного сложнее, но тоже решаемо (гулять — так гулять!)
Просто подвижные стёклышки (прикинул по руке — возможно даже одного на все датчики хватит), которые прикрывают датчик после каждого измерения двигать вверх или вниз через щетки, которые будут всё стирать. Раз в сутки их потребуется промыть, однако и обычные датчики тоже надо промывать, как я понимаю.
Однако сейчас довольно много существует качественных олиефобных покрытий, которые эту проблему решают. А без жира туда и грязь налипать не будет.
Как-то так.