
Пару дней назад появилась статья, которую почти никто не освещал. На мой взгляд, она замечательная, поэтому про неё расскажу в меру своих способностей. Статья о том, чего пока не было: машину научили играть в шутер, используя только картинку с экрана. Вместо тысячи слов:
Не идеально, но по мне — очень классно. 3D шутер, который играется в реальном времени — это впервые.
Подход, который применили — пересекается и с тем, как сделали бота, играющего в GO, и с тем как проходили игры Atari. По сути это «Deep reinforcement learning». Наиболее подробная статья на эту тему на русском, пожалуй здесь.
В двух словах. Пусть есть некоторая функция Q(s,a). Эта функция определяет профит, который вернёт наша система от выполнения действия a в состоянии s. Нейронную сеть обучают так, чтобы на выходах она давала аппроксимацию функции Q. В результате мы знаем цену любого действия в каждой ситуации. Чтобы понять более подробно лучше читать один из приведённых выше текстов.
Классический подход, который применялся в играх Atari для 3D-шутеров не работает. Слишком много информации, слишком много неопределённости. В играх Atari оптимальное действие можно было выполнить по последовательности из 3-4 кадров, чем там широко и пользовались, подавая их на вход. В Alpha Go авторы пользовались дополнительной системой, которая ходила и перебирала оптимальные варианты по правилам Go.
Как же авторы справились тут? Ведь не будешь прогать свой внутренний движок? Оказывается, всё очень просто и интересно. Глобально, было сделано 3 улучшения:
Теперь чуть поподробнее.
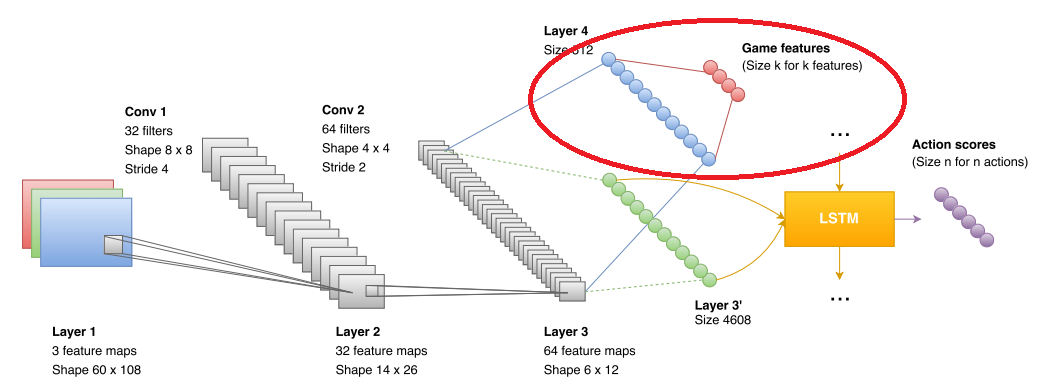
Когда человек впервые садиться за DOOM, то ему говорят: это плохой монстр, его нужно убить. У человека есть понимание что такое монстр => он быстро осваивается. Нейронная сеть никогда не видела монстра. Никогда не видела аптечки и никогда не видела бочки. Она не умеет отличать одно от другого.
Глубокое обучение с подкреплением подразумевает, что учиться система должна только по своей целевой функции. Но зачастую это невозможно. Нельзя по целевой функции понять, что массив движущихся пикселей — это враг. Ну, можно, но долго и муторно. Человек имеет априорную информацию. Нужно и в сеть её загрузить.
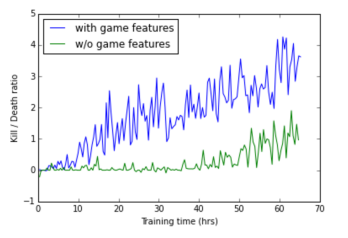
Поэтому авторы ввели дополнительный блок, который используется при обучении. В блок они подают что видит сеть (на рисунке отмечен красным эллипсом). Формат данных — boolean в стиле «вижу монстра», «вижу аптечку», «вижу амуницию». В результате свёрточная сеть явно тренируется распознавать врагов, аптечки и амуницию. В фазе игры этот блок никак не используется. Точнее используется, но об этом чуть ниже. А вот на сколько фичи повышают точность сети:
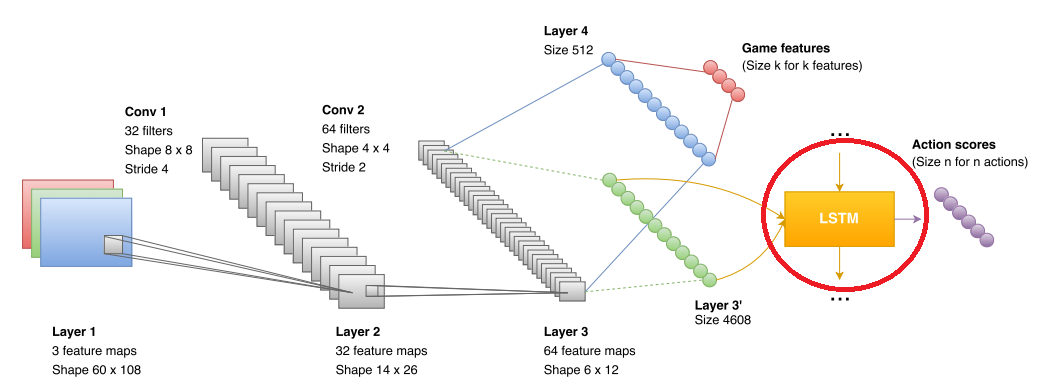
LSTM — это такая рекуррентная сеть, которая неплохо может объединять данные, которые получает свёрточная сеть. В оригинальных статьях по Atari и по Alpha GO, таких сетей не было, но их уже использовали в других DQR проектах (например, с теми же играми Atari). Так что ничего особо нового тут не было.
И опять, авторы упёрлись в неприятный момент. Рекуррентная сеть обеспечивала анализ данных и прогноз где-то на протяжении нескольких секунд (в работе обучают последовательностями длинной примерно 10 кадров, где кадр берётся несколько раз в секунду (1/5 fps, fps не указаны)). Более глобальные прогнозы для неё были неточны. Кроме того, сеть сложно обучить понятию «у нас скоро кончатся патроны, хорошо бы начинать что-то искать». В результате авторы извернулись и сделали две независимых сети. Одна сеть умела искать аптечки и патроны. Вторая делать фраги.
Переключение осуществляется за счёт того самого «выделения монстров», которая сеть генерит из-за особенностей обучения. Если монстров не видно, то используются решения «исследовательской сети», после появления монстра решения «боевой». Эффект от введения исследовательской сети:
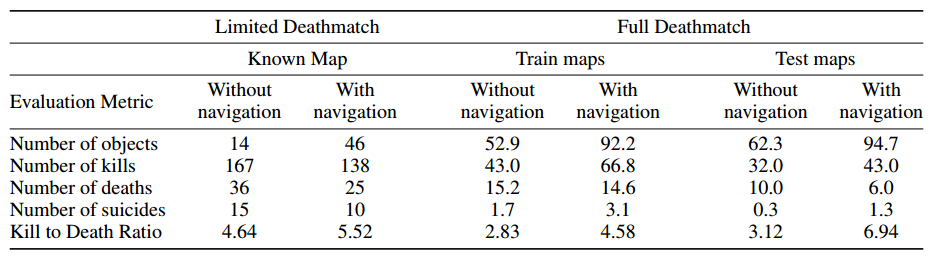
Кстати, исследовательская сеть убивает у бота «кемперское поведение», которое свойственно «боевой».
Исследовательской сети при обучении выписывали плюсы за пройденное расстояние.
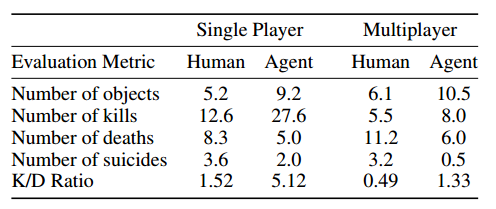
Человека сеть побеждает с неплохим отрывом. По-моему это главное.
По DQN я не специалист, возможно что-то не идеально рассказал. Было бы интересно послушать мнение специалистов. Но подборка методов, а в особенности результат меня очень впечатлили.
P.S. Ещё несколько примеров кровавого обучения:
*СР УВЧ!
Не идеально, но по мне — очень классно. 3D шутер, который играется в реальном времени — это впервые.
Подход, который применили — пересекается и с тем, как сделали бота, играющего в GO, и с тем как проходили игры Atari. По сути это «Deep reinforcement learning». Наиболее подробная статья на эту тему на русском, пожалуй здесь.
В двух словах. Пусть есть некоторая функция Q(s,a). Эта функция определяет профит, который вернёт наша система от выполнения действия a в состоянии s. Нейронную сеть обучают так, чтобы на выходах она давала аппроксимацию функции Q. В результате мы знаем цену любого действия в каждой ситуации. Чтобы понять более подробно лучше читать один из приведённых выше текстов.
Классический подход, который применялся в играх Atari для 3D-шутеров не работает. Слишком много информации, слишком много неопределённости. В играх Atari оптимальное действие можно было выполнить по последовательности из 3-4 кадров, чем там широко и пользовались, подавая их на вход. В Alpha Go авторы пользовались дополнительной системой, которая ходила и перебирала оптимальные варианты по правилам Go.
Как же авторы справились тут? Ведь не будешь прогать свой внутренний движок? Оказывается, всё очень просто и интересно. Глобально, было сделано 3 улучшения:
- При обучении использовалась некоторая дополнительная информация от движка
- Использовалась LSTM на выходе CNN
- Обучалось две сети: «Исследовательская» и «Боевая»
Теперь чуть поподробнее.
Информация от движка
Когда человек впервые садиться за DOOM, то ему говорят: это плохой монстр, его нужно убить. У человека есть понимание что такое монстр => он быстро осваивается. Нейронная сеть никогда не видела монстра. Никогда не видела аптечки и никогда не видела бочки. Она не умеет отличать одно от другого.
Глубокое обучение с подкреплением подразумевает, что учиться система должна только по своей целевой функции. Но зачастую это невозможно. Нельзя по целевой функции понять, что массив движущихся пикселей — это враг. Ну, можно, но долго и муторно. Человек имеет априорную информацию. Нужно и в сеть её загрузить.
Поэтому авторы ввели дополнительный блок, который используется при обучении. В блок они подают что видит сеть (на рисунке отмечен красным эллипсом). Формат данных — boolean в стиле «вижу монстра», «вижу аптечку», «вижу амуницию». В результате свёрточная сеть явно тренируется распознавать врагов, аптечки и амуницию. В фазе игры этот блок никак не используется. Точнее используется, но об этом чуть ниже. А вот на сколько фичи повышают точность сети:
LSTM
LSTM — это такая рекуррентная сеть, которая неплохо может объединять данные, которые получает свёрточная сеть. В оригинальных статьях по Atari и по Alpha GO, таких сетей не было, но их уже использовали в других DQR проектах (например, с теми же играми Atari). Так что ничего особо нового тут не было.
Две сети
И опять, авторы упёрлись в неприятный момент. Рекуррентная сеть обеспечивала анализ данных и прогноз где-то на протяжении нескольких секунд (в работе обучают последовательностями длинной примерно 10 кадров, где кадр берётся несколько раз в секунду (1/5 fps, fps не указаны)). Более глобальные прогнозы для неё были неточны. Кроме того, сеть сложно обучить понятию «у нас скоро кончатся патроны, хорошо бы начинать что-то искать». В результате авторы извернулись и сделали две независимых сети. Одна сеть умела искать аптечки и патроны. Вторая делать фраги.
Переключение осуществляется за счёт того самого «выделения монстров», которая сеть генерит из-за особенностей обучения. Если монстров не видно, то используются решения «исследовательской сети», после появления монстра решения «боевой». Эффект от введения исследовательской сети:
Кстати, исследовательская сеть убивает у бота «кемперское поведение», которое свойственно «боевой».
Исследовательской сети при обучении выписывали плюсы за пройденное расстояние.
Что в итоге вышло
Человека сеть побеждает с неплохим отрывом. По-моему это главное.
По DQN я не специалист, возможно что-то не идеально рассказал. Было бы интересно послушать мнение специалистов. Но подборка методов, а в особенности результат меня очень впечатлили.
P.S. Ещё несколько примеров кровавого обучения:
*СР УВЧ!
Поделиться с друзьями
fishca
patr
ага, а потом
fishca
Все будет хорошо!
playermet
Новый уровень жанра programming game с ботами.
Arkham
Что с «противоречивыми» оценками? Например — взрывать бочку впритык к себе — плохо, а взрывать бочку которая впритык к противнику — хорошо? Это закладывалось в изначальные знания сети, или она этому училась сама? И училась ли?
P.S. Судя по видео, переключение «боевой» и «исследовательской» сети происходит топорно — бот не умеет стрелять во врага и «стрейфится» по направлению к аптечке/патронам. Да и просто в «боевой» бот обычно либо стоит либо бежит только вперёд.
ZlodeiBaal
Да, переключение явно топорное.
С бочками, думаю, что сеть можно было бы обучить, если пускать её на уровень с кучей бочек. А так она даже вряд ли их научилась детектировать. Они не выводились в feature вектор состояния из движка, как я понимаю.
Кто-то на ютубе писал в стиле: «кардинальное отличие поведения от детей! дети не пропускают ни одной бочки, когда учатся играть!».
Arkham
Да! Было-бы намного круче, если бы сеть в первых циклах обучения пыталась различными способами взаимодействовать с объектами, и на основе этого уже выделяла их в разные группы враг/предмет/и т.п.
asurkis
Но разве дети взрывают бочки не потому что взрыв «красиво нарисован»? Причём взрыв — не самое важное. Я лично постоянно их взрывал именно поэтому. А бот не знает понятий «красиво», «взрыв» и тому подобных.
Wesha
Нет — потому что раздаётся классный звук "БАБАХ!!!"
fishca
Не на всех были хорошие звуковые в то время, когда бабахало. Иногда из спикера доносился просто скрежет, а на «БАБАХ!!!»
Parilo
С бочкой оценка не такая уж и противоречивая. Сеть вырабатывает признаки близко/далеко, позиции врагов. Эти признаки вырабатываются в процессе обучения и потом к конкретному набору признаков привязывается действие, стрелять или не стрелять.
Более интересная задача как найти в большом пространстве возможных состояний наиболее интересные области и прицельно исследовать именно их. То есть например повзаимодействовать с бочкой, а не изучать, к примеру, что бывает от выстрелов в разные конфигурации стен.
Vjatcheslav3345
Тогда нужна сеть-стратег, которая принимает решения более высокого уровня. При этом исследователь только генерирует для стратега и для война выявленные им закономерности мира типа: "врагов можно подстрелить рикошетом" или "в моём мире есть проёмы и зеркала, отличающиеся только цветом притолки". а стратег и воин принимают решения на основании подтвердившихся закономерностей и собственного опыта.
Кстати, а как сеть поведёт себя на уровне типа "зеркального лабиринта", с очень большим количеством переотражений противника в зеркальных поверхностях?
dfm
Трудно поверить в такой KDR судя по видео. Опять таки, если противник попал в прицел, то ему уже не отвертеться. Обработка каждого кадра в несколько проходов в секунду не даст уйти из под прицела. Это уже получается AIM и за такое банят вообще-то :)
Интересно было-бы посмотреть на соревнования этих сетей, как на один из вариантов киберспорта среди программистов. Только не в 2,5D, а в полноценном 3D.
ZlodeiBaal
Да, 90% качества этой сети это на мой взгляд и есть aimbot:)
anprs
По идее, бот должен быть более предсказуемым. Человек должен понимать то, что если бот сейчас не в бою, его надо искать в местах расположения патронов/аптечек.
Как мне кажется, человек, который будет отстреливаясь от бота собирать аптечки/броню/патроны (т.е. держа в голове план уровня, во время боя задним ходом бежать к местам расположения аптечек — совмещая бой с пополнением запасов) должен у бота выигрывать. Хуже точность? Почему сеть показывает лучший результат?
ZlodeiBaal
Я боюсь, что дум это это квака. Тут всё же тактика контроля карты не позволяет быть более кривым в стрельбе.
CrazyFizik
Нейросеть потребуется слишком большая иначе будут интерфернции. Большая сеть => дольше обучение, больше ресурсов и т.д. В общем эффективнее будет разбить на несколько независимых сетей. Просто помимо проблемы тренировки коэффициентов присутствует еще и проблема выбора топологии и размера сети — а это тоже нетривиальная задача. Ну просто физически нашлепать и обучить сетку из нескольких миллиардов хаотично организованных нейронов несколько проблено, эволюции на это потребовалось на это много-много лет и один фиг получим набор узкоспециализированных подсетей :-) У нас же тоже НС дифференцирована
andrey_aksamentov
имхо
Почему бы не поставить сети задачу пройти игру, а она (сеть) уже играя много времени усвоит что не дает ей выжить, что добавляет здоровье, что патроны. Человек вроде бы так же обучается.
В моем детстве, когда только появились приставки и все игры были пиратскими и на английском, только многочисленным методом тыка удавалось проходить игры заучивая решения разных ситуаций.
Parilo
Этот метод работает. Об этом много говорилось в более ранних статьях. Но этот путь оооочень долгий и требовательный к ресурсам. Поэтому стараются как-то ускорить обучение, это тоже довольно интересное занятие
KonstantinSamsonov
ну сеть научится поднимать частоту процессора в DosBox и fps до 200-300 и сможет за 8 минут сыграть матч, потом научится запускать несколько процессов обучения параллельно, а потом, когда научится зарабатывать на роликах в ютубе «Как пройти казаков 2 за 2 часа» скопит денег на амазон EC2 и уже с них захватит весь мир онлайна и тут она поймёт что её враги не здесь, а где-то рядом…
Vjatcheslav3345
… а потом поймет, что примитивные технологии не позволят ей сделать киборгов раньше, чем её отключит электромонтёр… шекспировская трагедия.
andrey_aksamentov
Одна сеть может одновременно играть в большое количество копий игры, вроде как многозадачное мышление.
Если какой то поток находит какое то решение, то тут же передает его остальным потокам.
Parilo
Да, это используется очень часто. Это помогает максимально быстро набрать банк наиболее разнообразного опыта для обучения.
4ebriking
переименуйте статью — зашёл случайно, набор букв мне ничего не говорит, а тут оказывается про ИИ, играющий в шутер по картинке с экрана. Круто же!
midday
>>При обучении использовалась некоторая дополнительная информация от движка
Что за информация? Мне кажется это ключевое, а не описано.
ZlodeiBaal
yeti357
Я не очень в курсе как в этом думе с наведением на цель, но мне кажется что позиционирование перекрестья у него точнее/быстрее чем у человека, что несколько упрощает ему задачу в плане k/d. А так круто конечно.
CrazyFizik
Это не впервые. Нейросеть уже давно обучали играть в Кваку, Анреал, Марио, ПакМен и т.п. используя только информацию с экрана. Но это только один подход, В гонках будет проще использовать уже систему направленных сенсоров. И это было задолго до новомодного глубоко обучения (профит о которой разве что в появлении памяти, о чем собственно известно эдак с 80-ых годов наверное). Да профит от модульной сети в играх тоже известен.
По использованию нейросетей в играх на мой взгляд самым интересным было применение нейроэволюционных алгоритмов (например, NEAT и проект NERO по нему).
ZlodeiBaal
А приведите пример про Q, Unreal, и.т.д. Ни разу такого не видел.
Марио через Q-Learning как я понял не взлетел.
CrazyFizik
Ну вот можете поискать статью Neuroevolution in games: State of the art and open challenges.
Там например что-то типа обзора разных методов для разных игр. В общем сравниваются разные алгоритмы, сети, подходы к управлению и получению информации из окружающего мира и т.п. Как раз там указан Q2 в котором использовался визуальный вход 14x2. Дальше можно пойти по ссылкам. На ютубе можно найти MarI/O — там тоже используется визуальный вход (но очень примитивный) а в качестве алгоритма выступает NEAT ( на сайте университета Техаса по нему полно инфы). В Interactively Evolved Modular Neural Networks for Game Agent Control рассматривают преимущества модульной нейросети (одна нейросеть управляет движением, другая управляет стрельбой) по сравнению с единой нейросетью на примере игры XNA NET Rummble (старая демонстрашка XNA).
Это вот так навскидку. По UT находил кучу статей, где вообще для каждого аспекта игры (смена оружия, поиск бонусов, стрельбу, передвижение и т.п.) была своя сеть (охрененно сложная модульная сеть) но всех названий не упомню уже. А так вообще дофига статей и даже целых дипломов и диссертаций. Проблема только в том, что подавляющее большинство статей которые я читал на эту тему находятся в репозитариях за доступ к которым надо платить — поэтому читать я их могу только на работе.
Ну а что касается безмодельного обучения в общем, то там действительно сложно взлететь — во-первых очень длительный процесс обучения, во-вторых, это тот самый случай когда программа умнее программиста. Например, когда я обучал ропатов убивать ропатов и поленился взяв фитнесс функцию из 5 слагаемых: Положительное — попадания и время жизни, негативные — получение урона, промахи попадание по союзнику, к 60-ому поколению боты разбредались по карте максимально далеко друг от друга и расстреливали препятствия (попадания по всем объектам считались положительными если dammager.team!=hitted.team) — все живы-здоровы, получают очки и никто не умирает, а самое главное неподвижные объекты никуда не убегут и обеспечат хороший процент попаданий, а самое главное сдачи не дадут.
ZlodeiBaal
Спасибо. А есть видюшки с примерой работы таких сетей?
Но всё же тут интересно, что все аспекты игры собраны более-менее в одной сети с единым пайплайном тренировки. Понятно, что чтобы сделать aimbot, никакой нейронной сети не нужно. Так же как для того чтобы сделать бота, который по триггерам бегает.
AlexanderG
Если не ошибаюсь, нейронные сети для ИИ использовались также в Black & White и Creatures.
CrazyFizik
Еще в FEAR, Sims, L4D и даже в Крайзисе говорят они где-то там есть.
В общем с 10-ок игр точноберется. Правда чо там внутри зарыто — я хз.
Проблема в том что говнокодеров разбирающихся в ИИ на самом деле очень мало, задачи там сложные и даже тут на Хабре считают что лучше нафигачить 100500 if...then...else чем морочить голову всякими сложными вещами. Это вот недавно снова пошла мода на все эти нейросети и генетические алгоритмы.
А так у меня была когда то древнейшая книга (она была древней уже когда я учился в универе) которая как раз была посвящена как можно вставить академический ИИ в игры, еще и на примере ботов из Кваки и были там не только нейросети.
aaamodder
Мне кажется, что вместо предпоследней картинки должна быть какая-то другая, не совпадающая с последней.
ZlodeiBaal
Да, спасибо.
fishca
Вот я одного не очень понял как это картинки экрана подсовывали ИИ?
Может проще ИИ научить лазить в видеопамять напрямую?
ZlodeiBaal
Не, не проще. Это же исследование. Куда проще было собирать его из готовых кусочков, а не городить своё. Они взяли уже готовый api, из которого можно всё вытащить — http://vizdoom.cs.put.edu.pl/ взяли какой-то фреймворк который LSTM и свёрточные сети поддерживает. И скрестили.
ls1
Страшно подумать, что можно будет скрестить на коленке лет через 10
fishca
Ждем битву ИИ
ivodopyanov
LSTM? А у них при этом не возникали проблемы с корреляцией данных, из-за чего experience replay вводили?
ZlodeiBaal
Возникали, там даже какой-то график есть.
Они в итоге учили на небольших последовательностях где-то по десятку кадров. При этом первые 5 кадров служили для того, чтобы накопить аккумулятор LSTM — обучения не происходило. А апдейтили веса только на последних нескольких кадрах. Там вообще целая пачка таких маленьких аджастментов. Та же e-greed стратегия.
Я не разу Q-Learning не обучал, поэтому важность и специфику этих мелочей мне сложно оценить.
Semenych
Интересно радуется ли нейросеть когда выигрывает и расстраивается ли когда ее убивают?
fireSparrow
Мечтают ли нейросети об электроовцах?
Vjatcheslav3345
Моделирование живого — уже сейчас этим занимаются — OpenWorm
(https://habrahabr.ru/post/208036/). И уже сейчас задаются вопросом — а чувствует эта модель живого существа боль? При желании можно скачать и поиграться.
Parilo
Смотря как на это посмотреть. Используется обучение с подкреплением, то есть награды и штрафы. Но вот радость и печаль надо сначала каким либо образом определить, но это уже философский вопрос… В любом случае при текущем развитии НС, это как пытаться определить что чувствует нематода или еще какой-либо простой организм.
SKolotienko
Спасибо за статью! Хороший пересказ
Wesha
Что за версия игры на первом видео? Интерьер из дума, а вот монстров таких там точно не было