
NVIDIA подняла волну пиара по поводу разработанной и имплиментированной в DIGITS сетки DetectNet. Сетка позиционируется как решение для поиска одинаковых/похожих объектов на изображении.

Что это такое
В начале года я несколько раз упоминал про забавную сетку Yolo. В целом, весь народ, с которым я общался, отнеслись к ней скорее негативно, со словами, что Faster-RCNN куда быстрее и проще. Но, инженеры NVIDIA ею вдохновились и собрали свою сетку на Caffe, назвав её DetectNet.
Принцип сетки такой же как и в Yolo. Выходом сети для изображения (N*a*N*a) является массив N*N*5, в котором для каждого региона исходного изображения размером a*a вводиться 5 параметров: наличие объекта и его размер:

Плюс сетки:
- Быстро считает. У меня получалось по 10-20ms на кадр. В то время, когда Faster-RCNN тратил по 100-150.
- Просто обучается и настраивается. С Faster-RCNN нужно было долго возиться.
Минус один: есть решения с более качественным детектированием.
Общие слова, перед тем как начну рассказ
В отличие от распознавания категорий, про которое я писал вчера, детектирование объектов сделано плохо. Не user friendly. Большая часть статьи будет на тему того, как всё же это чудо запустить. К сожалению, такой подход убивает изначальную идею DIGITS, что можно сделать что-то не разбираясь в логике системы и её математике.
Но если всё же запустили — пользоваться удобно.
Что будем распознавать
Пару лет назад у нас была совсем безумная затея с автомобильными номерами. Которая вылилась в целую серию статей по ней. В том числе была порядочная база фотографий, которую мы выложили.
Я решил воспользоваться частью наработок и подетектировать номера через DIGITS. Так что их-то и будем использовать.
База размеченная нужным образом у меня была совсем маленькая, под другие цели. Но обучить хватило.
Поехали
Выбрав в главном меню «New Dataset->Images->Object Detection» мы попадаем в меню создания датасета. Здесь нужно обязательно указать:
- Training image folder — папку с изображениями
- Training label folder — папку с текстовичками-подписями к изображениям
- Validation image folder — папку с изображениями для проверки
- Validation label folder — папку с текстовичками-подписями к ним
- Pad image — Если изображение меньше указанного тут, то оно будет дополнено чёрным фоном. Если больше — создание базы упадёт ? \ _ (?) _ / ?
- Resize image — к какому размеру ресайзнуть изображение
- Minimum box size — лучше всего установить это значение. Это минимальный размер объекта при валидации
Тут есть сложность. Как делать текстовик-подпись к изображению с его описанием? Пример на ГитХабе от NVIDIA в официальном репозитории DIGITS скромно об этом умалчивает, упоминая лишь, что он такой же, как в датасете kitti. Меня несколько удивил такой подход к пользователям готового из коробки фреймворка. Но ок. Пошёл, скачал базу и доки к ней, прочитал. Формат файла:
Car 0.00 0 1.95 96.59 181.90 405.06 371.40 1.52 1.61 3.59 -3.49 1.62 7.68 1.53
Car 0.00 0 1.24 730.55 186.66 1028.77 371.36 1.51 1.65 4.28 2.61 1.69 8.27 1.53
Car 0.00 0 1.77 401.35 177.13 508.22 249.68 1.48 1.64 3.95 -3.52 1.59 16.82 1.57
Описание файла:
#Values Name Description
----------------------------------------------------------------------------
1 type Describes the type of object: 'Car', 'Van', 'Truck',
'Pedestrian', 'Person_sitting', 'Cyclist', 'Tram',
'Misc' or 'DontCare'
1 truncated Float from 0 (non-truncated) to 1 (truncated), where
truncated refers to the object leaving image boundaries
1 occluded Integer (0,1,2,3) indicating occlusion state:
0 = fully visible, 1 = partly occluded
2 = largely occluded, 3 = unknown
1 alpha Observation angle of object, ranging [-pi..pi]
4 bbox 2D bounding box of object in the image (0-based index):
contains left, top, right, bottom pixel coordinates
3 dimensions 3D object dimensions: height, width, length (in meters)
3 location 3D object location x,y,z in camera coordinates (in meters)
1 rotation_y Rotation ry around Y-axis in camera coordinates [-pi..pi]
1 score Only for results: Float, indicating confidence in
detection, needed for p/r curves, higher is better.
Естественно, большая часть параметров тут не нужна. Реально можно оставить только параметр «bbox», остальное всё равно не будет использоваться.
Как выяснилось позже, для DIGITS был ещё второй тьюториал, где формат файла всё же подписывался. Но был он не в репозитории DIGITS ? \ _ (?) _ / ?
Там подтверждено, что мои догадки о том, что нужно использовать были верны:

Начинаем обучать
Класс. База сделана, Начинаем обучать. Для обучения нужно выставить такие же настройки, как указанные в примере:
- Subtract Mean в None
- base learning rate в 0.0001
- ADAM solver
- Выбрать вашу базу
- Выбрать вкладку «Custom Network». Скопировать в неё текст из файла "/caffe-caffe-0.15/examples/kitti/detectnet_network.prototxt" (это в форке caffe от nvidia, понятно).
- Так же, рекомендуется скачать предварительно натренированную модель GoogleNet вот тут. Указать её в «Pretrained model(s)»
Так же, я сделал следующее. Для скопированной сетки «detectnet_network.prototxt» все значения размера изображения «1248, 352» я заменил на размеры изображений из своей базы. Без этого обучение падало. Ну, естественно, ни в одном тьюторивале этого нет… ? \ _ (?) _ / ?
График Loss падает, обучение пошло. Но… График точности стоит на нуле. Что такое?!
Ни один из двух тьюториалов которые я нашел не отвечал на этот вопрос. Пошёл копаться в описание сетки. Где копаться, было понятно сразу. Раз падают loss — обучение идёт. Ошибка в validation пайплайне. И действительно. В конфигурации сети есть блок:
layer {
name: "cluster"
type: "Python"
bottom: "coverage"
bottom: "bboxes"
top: "bbox-list"
python_param {
module: "caffe.layers.detectnet.clustering"
layer: "ClusterDetections"
param_str: "1024, 640, 16, 0.05, 1, 0.02, 5, 1"
}
}
Выглядит подозрительно. Открыв описание слоя clustering можно найти комментарий:
# parameters - img_size_x, img_size_y, stride,
# gridbox_cvg_threshold,gridbox_rect_threshold,gridbox_rect_eps,min_height,num_classes
Становится понятно, что это пороги. Зарандомил там 3 числа не вникая в суть. Обучение пошло + начал расти validation. Часов за 5 достиг каких-то разумных порогов.

Но вот облом. При успешном обучении 100% картинок не распонзавалось. Пришлось копаться и разбираться, что этот слой значит.
Слой реализует сбор полученных гипотез в единое решение. Как основной инструмент тут применяется OpenCV модуль «cv.groupRectangles». Это функция, которая ассоциирует группы прямоугольников в один прямоугольник. Как вы помните, у сети такая структура, что в окрестности объекта — должно быть много срабатываний. Их нужно собрать в единое решение. У алгоритма сбора есть куча параметров.
- gridbox_cvg_threshold (0.05) — порог детектирования объекта. По сути достоверность того, что мы нашли номер. Чем меньше — тем больше детекций.
- gridbox_rect_threshold (1) — сколько детекторов должно сработать, чтобы было принято решение «есть номер»
- gridbox_rect_eps (0.02) — во сколько раз могут отличаться размеры прямоугольников, чтобы объединить их в одну гипотезу
- min_height — минимальная высота объекта
Теперь их достаточно просто подобрать, чтобы всё заработало. А теперь юмор. Таки был ещё и третий тьюториал, где часть всего этого дела описана.
Но не вся ? \ _ (?) _ / ?
Что в итоге
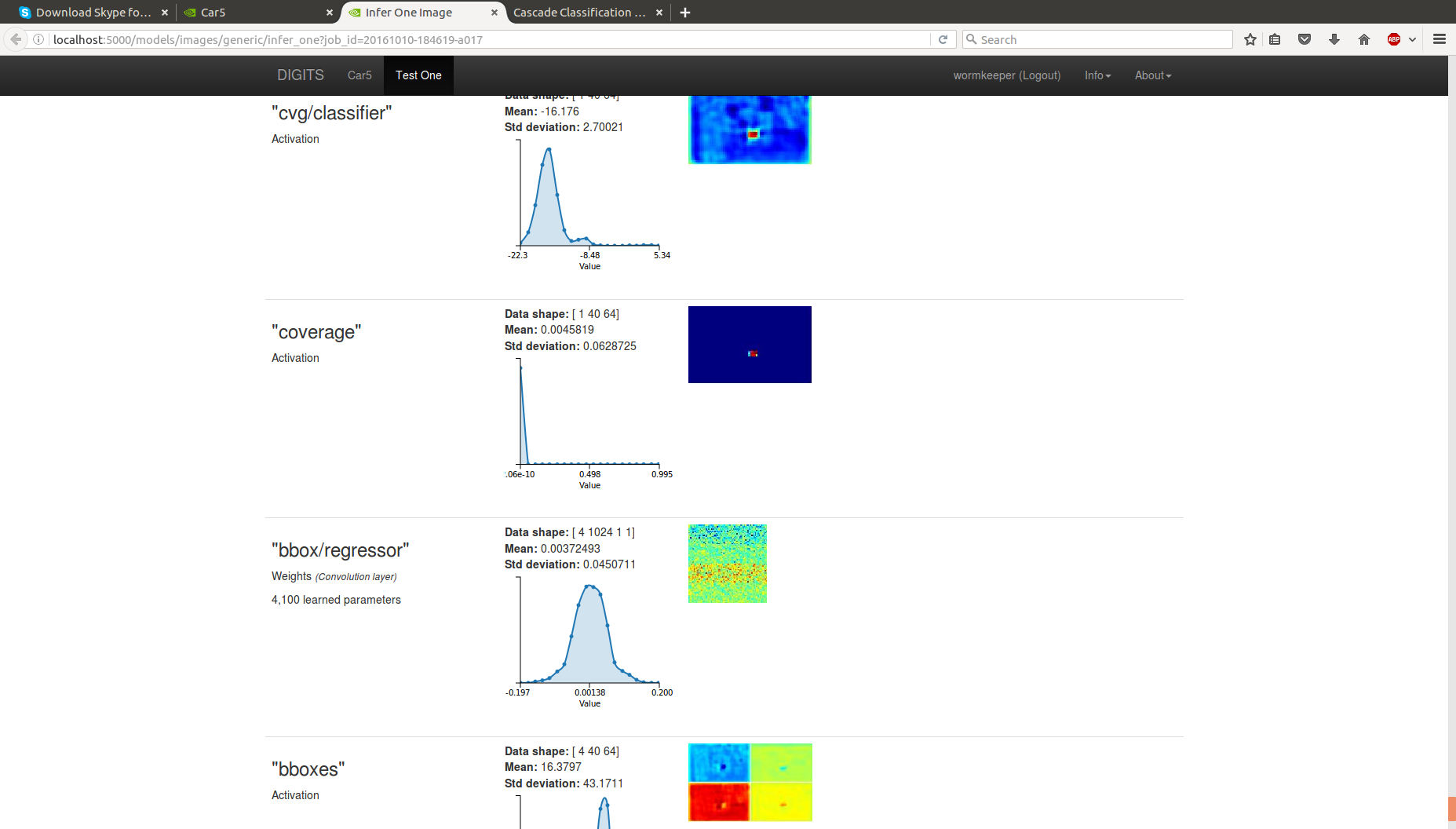
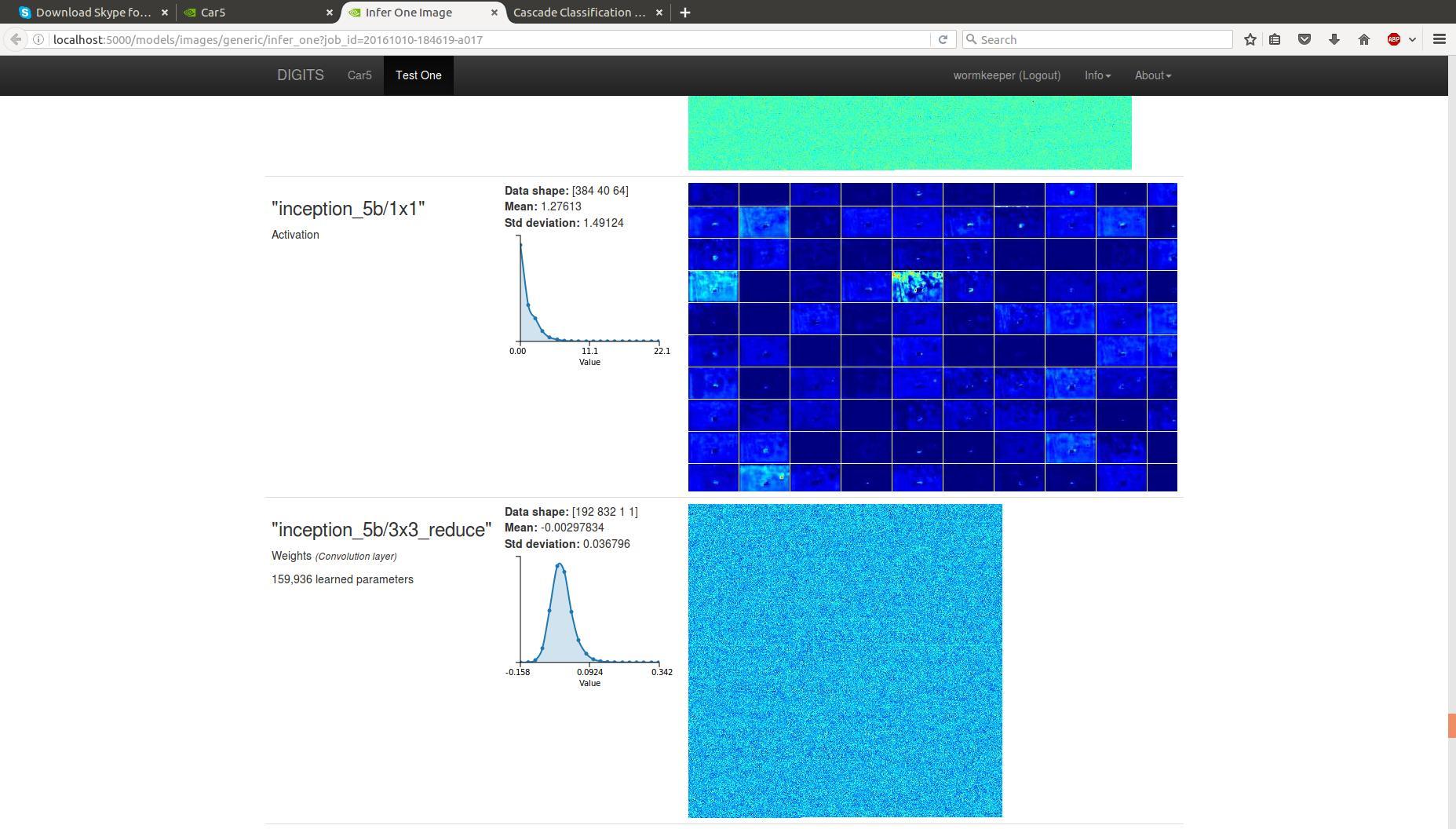
В итоге можно посмотреть что сетка выделила:

Работает неплохо. На первый взгляд лучше, чем Хаар, который мы использовали. Но сразу стало понятно, что маленькая обучающая база (~1500 кадров) — даёт о себе знать. В базе не учли грязные номера => они не детектируются. В базе не учли сильную перспективу номера => они не детектируются. Не учли слишком крупные/слишком мелкие. Ну, вы поняли. Короче нужно не полениться и разметить тысяч 5 номеров нормально.
При распознавании можно посмотреть прикольные картинки с картами активации (1,2,3). Видно, что на каждом следующем уровне номер виден всё чётче и чётче.
{kind=link}
{kind=link}
{kind=link}
Как запустить
Приятный момент — результат можно запустить кодом из ~20 строчек. И это будет готовый детектор номеров:
import numpy as np
import sys
caffe_root = '../' # путь в корень каффе
sys.path.insert(0, caffe_root + 'python')
import caffe
caffe.set_mode_cpu() # Если на проце. Иначе:
#caffe.set_device(0)
#caffe.set_mode_gpu()
model_def = caffe_root + 'models/DetectNet/deploy.prototxt' #описание сети
model_weights = caffe_root + 'models/DetectNet/DetectNet.caffemodel' #веса сети
net = caffe.Net(model_def, # defines the structure of the model
model_weights, # contains the trained weights
caffe.TEST) # use test mode (e.g., don't perform dropout)
#Как преобразовывать картинки перед отправкой в сеть
mean=np.array([128.0,128.0,128.0])
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1)) # move image channels to outermost dimension
transformer.set_mean('data', mean) # subtract the dataset-mean value in each channel
transformer.set_raw_scale('data', 255) # rescale from [0, 1] to [0, 255]
transformer.set_channel_swap('data', (2,1,0)) # swap channels from RGB to BGR
# Вход сети на всякий случай поставим корректный
net.blobs['data'].reshape(1, # batch size
3, # 3-channel (BGR) images
640, 1024) # image size is 227x227
image = caffe.io.load_image('/media/anton/Bazes/ReInspect/CARS/test/0.jpg')# тестовое изображение загружаем
transformed_image = transformer.preprocess('data', image)# подготовим дял укладывания в сеть
output = net.forward() # распознаем
output_prob = output['bbox-list'][0] # массив результатов в формате нужном нам
print output_prob[0]
Вот тут вот я выложил деплой файл для сетки и веса обученой сети, если кому надо.
Комментарии (32)

Zifix
18.10.2016 20:36Спасибо за статью.
Быстро считает. У меня получалось по 10-20ms на кадр. В то время, когда Faster-RCNN тратил по 100-150.
А что за видеокарта?
ZlodeiBaal
18.10.2016 20:39+11080, так что да, это не очень репредентативно для простых устройств
Zifix
18.10.2016 20:53Понятно, а более быстрые сети в природе существуют? Насколько реально получить такие скорости на видеокарте среднего уровня типа 950?
ZlodeiBaal
18.10.2016 21:56+1Я думаю, что на 950 максимум раза в 2 упадёт. А так должна работать.
Zifix
18.10.2016 22:06Ну работать это само собой, просто интересно, насколько подобные сети сегодня шагнули вперед по скорости.
Кстати, какая зависимость размера кадра и скорости? Уменьшения кадра и падения качества распознавания? Точных цифр не надо, достаточно одним словом охарактеризовать.
BelBES
18.10.2016 22:14+1Ну работать это само собой, просто интересно, насколько подобные сети сегодня шагнули вперед по скорости.
Вообще ни на сколько не шагнули :-)
Есть некоторые методы сжатия сетей, но драматичного прироста производительности они не дают.
ZlodeiBaal
18.10.2016 22:21+1В DetectNet вычислений на верхнем уровне практически нет, как я понимаю. А для свёрточной сети объём вычислений будет прямо пропорционален площади. Ускорения тут скорее от железа будут зависить. Вроде NVIDIA сделало нативную поддержку ядер 3*3. Но каких-то тестов не от NVIDIA не видел.
Nikobraz
18.10.2016 22:08+2Не могу не заметить, что в новый Titan X и Теслы подвезли INT8 инструкции оптимизированные для машинного обучения. Также хочу услышать комментарий автора, относительно них.
ZlodeiBaal
19.10.2016 00:29+1На новых не работал. Видел тесты NVIDIA, что они просто разрывают всех по производительности. Но реально не читал про опыт использования. И сам не тестировал.
Nikobraz
19.10.2016 00:53Тесл еще в продаже нет, только Титан(в P100 поддержки INT8 нет). Еще нагуглил, что Intel Xeon Phi уже поддерживают часть инструкций, запихивая по 8 штук за раз в AVX-512. Видимо будет отчаянная грызня до последней капли крови за нейросети.
ZlodeiBaal
19.10.2016 00:58То что я видел у интела до сих пор — было на редкость убого. Но по крайней мере они стали это направление направленно развивать — что, конечно, очень хорошо.

masha_kupina
18.10.2016 20:55А ATI какие нибудь интересные решения для своих железок не предлагает? И у кого из этих производителей больше взаимопонимания с юзерами и разработчиками под GPU?
ZlodeiBaal
18.10.2016 20:59+3У NVIDIA. Считайте что они захватили рынок. Нет, какая-то поддержка ATI есть. Но обычно кривая и бажная. В Theano вроде есть, в TensorFlow. Но ATI реагирует на желания пользователей лишь после того как на них прореагирует NVIDIA. Или даже позже.
А так, даже Intel прикрутил для своей IntelPHI какой-то форк Caffe. Но вот стоит ли этим пользоваться? Не думаю.masha_kupina
18.10.2016 22:05Спасибо за развернутый ответ. Стало быть, хоть жефорсовые флопсы и дороже радеоновских, зато это какие надо флопсы)

enclis
18.10.2016 21:11В Torch есть поддержка OpenCL, но оно работает заментно медленее чем CUDA/cuDNN.
Nikobraz
18.10.2016 22:17AMD что-то не видно и не слышно. Топовое решение у них S9300 x2, судя по ттх FP32 считает как боженька, а FP64 плохо. Да и ориентируются, судя по сайту на облачные игры. Поддерживает только C++AMP и OpenCL.
BelBES
18.10.2016 22:21+1У AMD долгов столько, что некогда им заниматься венчурными вложениями в Deep Learning :(
BelBES
18.10.2016 21:13+2Быстро считает. У меня получалось по 10-20ms на кадр. В то время, когда Faster-RCNN тратил по 100-150.
Чет мне кажется, что Faster тоже полетит, если у него в качестве feature extractor будет использоваться GoogLeNet вместо VGG-16...
ZlodeiBaal
18.10.2016 21:55+1Кстати, тут есть любопытный вопрос. Если YOLO заапдейтить верхушку вот таким образом (назвается SSD). То у него качество распознавания раза в 1.2 вырастает. Но этот апдейт, по сути, просто напросто Residual Connection.
Возникает логичный вопрос: где сетки для детектирования на базе полноценного ResNet??? Они должны хорошо работать. Почему никто на базе ResNet не пересобрал Faster-RCNN? Или всё это уже давно сделано в недрах крупных компаний, просто не публикуются результаты?
Чет мне кажется, что Faster тоже полетит, если у него в качестве feature extractor будет использоваться GoogLeNet вместо VGG-16...
Как я понял YOLO на VGG16 всё же даёт ~50 fps. По крайней мере вот эти ребята недавно эксперементировали вроде. А. Вы чуть выше это тоже упомянули. Но 100fps я не видел сам:)
так что не думаю, что Faster прямо таки в 10 раз ускориться. Но раза в 2 может.

sim0nsays
18.10.2016 22:11+1Топовый результат в object detection на ImageNet как раз продемонстрирован ResNet, воткнутым в Faster-RCNN
ZlodeiBaal
18.10.2016 22:28+1А там опубликована статья? Ссылочкой не поделитесь? Я переодически табличку по VOC2012 отслеживаю — http://host.robots.ox.ac.uk:8080/leaderboard/displaylb.php?cls=mean&challengeid=11&compid=6&submid=8822#KEY_RRR-ResNet152-COCO-MultiScale
Но там по тем сеткам, где архитектура открыта она какая-то мутная. То марковские модели впилят, то какие-то карты фич полу-вручную разгребают.BelBES
19.10.2016 01:24+1А чего там публиковать то? Ну воткнули и воткнули, в faster'е же feature extraction впиливается достаточно прямолинейно. А вообще вот, например, статейка про то, как чего-нибудь сильно кастомное приделать к faster'у: https://arxiv.org/pdf/1608.08021.pdf
sim0nsays
21.10.2016 20:44В изначальной статье про ResNets это обсуждается в Appendix: https://arxiv.org/abs/1512.03385
BelBES
18.10.2016 22:20+1Как я понял YOLO на VGG16 всё же даёт ~50 fps. По крайней мере вот эти ребята недавно эксперементировали вроде. А. Вы чуть выше это тоже упомянули. Но 100fps я не видел сам:)
С VGG-16 у меня получалось ~90мс на кадр (на 980Ti), а вот при использовании упрощенных фич 100fps он действительно выдает, но детектирует совсем плохо.

nazargulov
22.10.2016 04:02А зачем вы удалили приложение по распознаванию номеров из App Store? Где его можно скачать?
mrgloom
23.10.2016 15:18То что там GoogLeNet используется несет какой то смысл или можно любую воткнуть?
ZlodeiBaal
23.10.2016 23:49Можно любую. Более того, DIGITS можно поверх любой более-менее адекватной современной версии caffe зацепить. Просто перед стартом указать переменную в папку где Caffe.
Конечно, после этого DetectNet и прочие свистелки-перделки перестают работать, но графички потерь и всё такое он кажет.
A-Stahl
Передайте центру личностного и духовного развития, что силой мысли можно не только ложки гнуть, но и мягкие знаки правильно расставлять.