
И многое-многое другое.
Мне давно хотелось попробовать, но что-то всё время мешало. Я разрабатывал много систем, связанных с обработкой изображений: тематика близка. Навыки более лежат в практической части и классических Computer Vision (CV) алгоритмах, чем в современных Machine Learning техниках, так что было интересно оценить свои знания на мировом уровне плюс подтянуть понимание свёрточных сетей.
И вот внезапно всё сложилось. Выпало пару недель не очень напряжённого графика. На kaggle проходил интересный конкурс по близкой тематике.Я обновил себе комп. А самое главное — подбил vasyutka и Nikkolo на то, чтобы составить компанию.
Сразу скажу, что феерических результатов мы не достигли. Но 18 место из 1.5 тысяч участников я считаю неплохим. А учитывая, что это наш первый опыт участия в kaggle, что из 3х месяц конкурса мы участвовали лишь 2.5 недели, что все результаты получены на одной единственной видеокарте — мне кажется, что мы хорошо выступили.
О чём будет эта статья? Во-первых, про саму задачу и наш метод её решения. Во-вторых, про процесс решения CV задач. Я писал достаточно много статей на хабре о машинном зрении(1,2,3), но писанину и теорию всегда лучше подкреплять примером. А писать статьи по какой-то коммерческой задаче по очевидным причинам нельзя. Теперь наконец расскажу про процесс. Тем более что тут он самый обычный, хорошо иллюстрирующий как задачи решаются. В-третьих, статья про то, что идёт после решения идеализированной задаче в вакууме: что будет когда задача столкнётся с реальностью.

Анализ задачи
Задача, которую мы начали делать звучала следующим образом: «Определить принадлежность водителя на фотографии к одной из десяти групп: аккуратное вождение, телефон в правой руке, телефон у правого уха, телефон в левой руке, телефон у левого уха, настройка музыки, пьёт жидкость, тянется назад, поправление причёски (красит губы, чешет затылок), разговор с соседом». Но, как мне кажется, лучше один раз посмотреть на примеры:
0
 1
1 2
2
3
 4
4 5
5
6
 7
7 8
8
9

- c0: safe driving
- c1: texting — right
- c2: talking on the phone — right
- c3: texting — left
- c4: talking on telephone — left
- c5: operating the radio
- c6: drinking
- c7: reaching behind
- c8: hair and makeup
- c9: talking to passenger
*******************************************
Всё кажется понятным и очевидным. Но это не совсем так. Какому классу принадлежат вот эти два примера?


Первый пример — 9 класс, разговор. Второй пример — нулевой класс, безопасное вождение.
По нашей оценке точность человека при распознавании класса по базе составляет где-то 94%. При этом наибольшую сумятицу вносит именно первый и десятый классы. На момент начала нашего участия первые места имели точность примерно на уровне 97% правильных распознаваний. Да-да! Роботы уже лучше людей!
Несколько подробностей:
- Размер базы для обучения 22 тысячи изображений.
- Примерно по 2 тысячи на класс.
- Всего в обучающей базе 27 водителей.
- Тестовая база — 79 тысяч изображений.
Сегодня основным средством для решения задач такого плана являются свёрточные нейронные сети. Они производят анализ изображения на многих уровнях, самостоятельно выделяя ключевые особенности и их отношения. Прочитать про свёрточные сети можно тут, тут и тут. У свёрточных сетей есть ряд минусов:
- Нужно много разнообразных данных для обучения. Две тысячи на класс это более менее достаточно, хотя и мало. Но то, что водителей всего 27 — очень ограничивает.
- Свёрточные сети склонны к «оверфиту». При обучении могут зацепиться за какой-то малозначимый признак, свойственный нескольким изображениям, но который не несёт существенного веса. У нас таким признаком стало открытие солнцезащитного козырька. Все фотографии с ним автоматом шли в 8 класс. Да и вообще: при оверфите сетка просто напросто может запомнить все 22 тысячи входных изображений. Вот хороший пример оверфита.
- Свёрточные сети неоднозначны из-за того что сложны. Приблизительно одно и то же решение на разных фреймворках может давать принципиально разные результаты. Несколько чуть-чуть изменённых параметров сети принципиально изменяют результат. Многие называют настройку сетей чем-то сродни искусству.
Альтернативой свёрточных сетей может являться ручной менеджмент низкоуровневых признаков. Выделить руки. Положение лица. Выражение лица. Открытый/закрытый козырёк у машины.
Свёрточных сетей очень много разных. Классический подход — использовать наиболее распространённые сети из «Зоопарка» (caffe theano keras). Это в первую очередь VGG16, VGG19, GoogleNet, ResNet. Для этих сетей есть много вариаций плюс можно использовать техники ускоряющие обучение. Конечно, данный подход используют все участники. Но базовый неплохой результат можно получить только на нём.
Наш сетап
Все вычисления в нашей работе проходили на одной единственной GTX1080. Это последняя игровая карта у NVIDIA. Не самый лучший вариант из того, что есть на рынке, но достаточно неплохой.
Мы хотели использовать кластер с тремя Tesla на одной из работ, но из-за ряда технических сложностей это не получилось. Так же обдумывали использование какой-то старой видеокарты из ноута на 4Gb, но в результате решили не идти по этому пути, там было сильно меньше скорости.
Используемый фреймворк — Caffe. Можно было бы использовать и Keras с Theano, что, безусловно повысило бы наш результат из-за несколько другой имплементации обучения. Но у нас не было на это времени, так что использовали по максимуму именно Caffe.
Оперативка — 16Gb, максимум при обучении использовалось 10Gb. Процессор — i5 последний.

Пару слов о правилах
Я думаю, что большая часть читателей никогда не участвовала в kaggle, так что проведу небольшой экскурс в то, какие правила у соревнования:
- Участникам представляется два набора данных. Тренировочный — на котором подписаны целевые результаты. Тестовый — по которому нужно произвести распознавание.
- Участник должен распознать все изображения из тестового сета и отправить их на сайт в csv-формате (текстовый файл вида «номер изображения» — вероятность первого класса, вероятность второго класса, ....).
- Всего в день можно сделать 5 попыток отправки.
- После каждой отправки пользователю говорят текущий процент по тестовой базе. Но, нужно учесть один интересный момент. Пользователю говорят результат не по всей базе, а только по небольшой её части. В нашей задаче это было 39%.
- Итоговый результат соревнования считается по оставшемуся куску базы (61%) после закрытия конкурса. Это может привести к серьёзным перестановкам участников.
- Первые три места — призовые. Если участник попадает в них, он должен опубликовать своё решение и организатор проверит его.
- Решение не должно:
- Содержать проприетарные данные
- Использовать размеченную пользователем тестовую выборку при обучении. При этом доразмечать обучающую выборку разрешается.
Пару слов о метрике
Предположим, что мы придумали некоторый механизм распознавания и распознали все изображения. Как они будут дальше проверяться? В данной задаче использовался подход вычисления мультиклассовых логарифмических потерь. Вкратце его можно записать как:

y — матрица решений. Единица если объект принадлежит классу.
p — матрица ответов которые прислал пользователь. Лучше всего записывать вероятность принадлежности классу.
M-число классов
N- число объектов
В окрестности нуля значение заменяется константой.
Мы прикинули, что вероятности «95%» соответствует значение logloss примерно «0.2», значение «0.1» соответствует вероятности «97.5%». Но это грубые оценки.
Мы ещё вернёмся к этой функции, но несколько ниже.
Первые шаги
Теория хороша. Но с чего начинать? Начнём с самого простого: возьмём сетку CaffeNet, которая приложена к Caffe и для которой есть пример.
После того, как я сделал аналогичное действие — сразу получил результат «0.7786», который был где-то на 500 месте. Забавно, но у многих результат был значительно хуже. При этом, стоит отметить, что 0.77 приблизительно соответствует 80-85% правильных распознаваний.
Не будем останавливаться на этой сетке, уже достаточно устаревшей. Возьмём что-нибудь стандартное современное. К стандартным можно причислить:
- Семейство VGG:
- VGG-16
- VGG-19
- Семейство ResNet:
- ResNet-50
- ResNet-101
- ResNet-152
- Семейство Inception
Про нестандартные методы можно прочитать чуть ниже в части «Идеи, которые не прокатили».
Так как мы начинали где-то через два с половиной месяца после начала соревнования имело смысл исследовать форум. На форуме советовали VGG-16. Автор поста уверял, что получил решение с потерями «0.23» на базе данной сети.
Рассмотрим решение автора:
- Он использовал предобученную сеть VGG. Это значительно повышает скорость обучения.
- Он обучил не одну, а 8 сеток. При обучении каждой сетки на вход подавалось лишь 1/8 входной базы данных (22/8 тысячи изображений).
- Полученное решение давало уровень в 0.3-0.27
- Итоговый результат он получил сложением результата этих 8 сеток.
Решение повторить у нас не удалось. Впрочем, много у кого не получилось сделать это. Хотя автор выкладывал обучающий скрипт на Keras’е. Судя по всему на Keras’е его можно было достичь, но не на caffe. Победитель, занявший третье место тоже считал VGG на Keras, а все остальные сетки на Caffe и Theano.
Нам же чистый VGG давал 0.4, что, конечно, улучшало наш результат на тот момент, но лишь места до 300ого.
В результате от VGG мы решили отказаться и опробовали обучение предобученного ResNet-50 (вот тут можно интересно почитать что это такое). Что немедленно дало нам 0.3-0.29.
Маленькая ремарка: мы так и не использовали технику «разбить базу на 8 частей». Хотя, скорее всего, она бы принесла нам небольшую дополнительную точность. Но такое обучение бы заняло несколько дней, что было нам неприемлемо.
Зачем нужно разбиение базы на 8 частей и обучение независимых сеток? Предположим, первая из сеток всегда ошибается в пользу ситуации А, при выборе из А и В. Вторая сетка наоборот — выносит решение В. При этом обе сетки часто ошибаются относительно реального решения. Но сумма сеток будет более корректно оценивать риск А/В. По сути она в большинстве спорных ситуаций поставит 50% — А, 50% — В. Такой подход минимизирует наши потери. Мы же достигали его по-другому.
Чтобы повысить точность с 0.3, мы сделали следующий ряд действий:
- Обучили несколько сеток ResNet-50 с различными гиперпараметрами. Все они давали где-то 0.3-0.28, но сумма их была больше.
- Обучили сетку ResNet-101, которая сама по себе дала где-то 0.25
- Обучили сетку ResNet-50 с изменениями изображения, что дало где-то 0.26
Изменения изображения следующие: при обучении вместо исходной обучающей картинки подаётся повёрнутая картинка, картинка подрезанная, картинка, зашумлённая помехами. Это повышает стабильность работы и повышает точность.
Итоговый результат сложения всех перечисленных сеток был на уровне «0.23-0.22».
К новым вершинам
Результат 0.22 был где-то в районе 100 места. Это уже неплохой результат. По сути тот максимум, который даёт корректно настроенная сеть. Но чтобы идти дальше нужно остановиться, подумать и осмыслить сделанное.
Самый простой способ сделать это — посмотреть «Confusion Matrix». По сути за этим понятием скрывается бюджет ошибок. Как и когда мы ошибаемся. Вот матрица, которая у нас вышла:
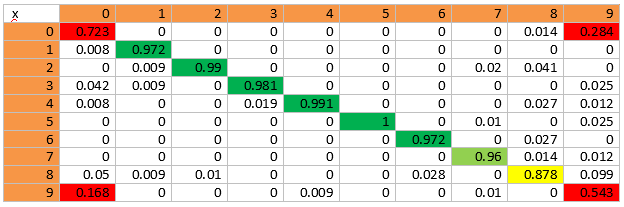
В этой матрице по оси x — это объекты исходного класса. По оси y — куда они были отнесены. Например, из 100% объектов нулевого класса 72% было успешно отнесено в него самого, 0.8%- в первый класс, 16.8% — в девятый.
Из матрицы можно сделать следующие выводы:
- Наибольшее число ошибок — нулевой и девятый класс. Это логично. Я зачастую сам не могу понять, говорит человек, или нет. Выше по тексту был пример.
- Второй по числу ошибок — восьмой класс. Любой класс где рука бывает рядом с головой может быть отнесён в восьмой класс, если информации недостаточно. Это разговоры по телефону. Это разговоры с соседом, с активной жестикуляцией. В некоторых ситуациях, когда человек пьёт жидкость — он тоже может быть похож.
Следовательно, нужно разработать алгоритм, который более корректно может различить эти три класса.
Для того, чтобы это сделать мы воспользовались следующими идеями:
- На взгляд человека 90% информации, позволяющей различить 0 и 9 класс содержится на лице. При этом в большинстве случаев, когда ошибалось отнесение в 8 класс — тоже итоговое решение принимается по области вокруг лица.
- Все сетки, приведённые выше были заточены на разрешение 224*224. При этом качество лица сильно просаживается.
Значит, нам нужно сохранить разрешение около лица и использовать его для уточнения 0-8-9 классов. Всего у нас было три идеи как это сделать. Про две из них будет написано ниже в разделе «Идеи, которые не прокатили». Прокатила следующая идея:
Обучаем простой классификатор Хаара на выделение лица. В принципе, лицо можно даже неплохо по цвету выделить. Учитывая что мы неплохо знаем, где лицо должно оказаться.
Правила соревнований не запрещали ручную разметку тренировочной базы. Поэтому мы отметили где-то на 400 изображениях лицо. И получили весьма неплохую подборку кадров распознанную в автоматическом режиме (лица найдены корректно на 98-99% кадров):



Обучив ResNet-100 по изображениям мы получили точность где-то на уровне 80%. Но добавление результатов обучения в сумму используемых сетей дало дополнительные 0.02 по тестовой выборке переместив нас в район тридцатых мест.
Идеи, которые не прокатили
Разорвём стройную канву повествования и сделаем небольшой шаг в сторону. Без этого шага всё хорошо, а с этим шагом становиться понятно, что происходило в голове на тот момент.
Идей, которые не дают результата в любой исследовательской задаче сильно больше, чем идей, которые дают результат. А иногда случается, что идеи по тем или иным причинам нельзя использовать. Тут небольшой список идей, которые мы уже успели опробовать на момент выхода на тридцатые места.
Первая идея была простой как бревно. Мы уже писали на Хабре (1, 2) про сети, которые могут раскрашивать изображения по классовой принадлежности объектов. Нам показалось, что это очень хороший подход. Можно научить сеть детектировать именно то, что нужно: телефоны, руки, открытый козырёк у машины. Мы даже потратили два дня на разметку, настройку и обучения SegNet. И вдруг мы поняли, что SegNet имеет закрытую не OpenSource лицензию. А следовательно мы не можем честно его использовать. Пришлось отказаться. А результаты автоматической разметки были перспективными (здесь показано сразу несколько подходов).
Первый:

Второй:


А вот так выглядит процесс разметки:


Вторая идея касалась того, что разрешения 224*224 нам не хватает для принятия решения 0 класс или 9. Наибольшие проблемы доставляет потеря разрешения на лицах. Но нам было известно, что лицо практически всегда находиться в левой верхней части изображения. Поэтому мы перетянули картинки, получив таких милых головастиков с максимальным разрешением в интересных нам местах:


Не прокатило. Результат был примерно как от обычного обучения + сильно коррелированный с тем, что у нас было.
Следующая идея была достаточно большой и объемлющей. Посты на форуме конкурса натолкнули нас на размышления: а что же сеть видит в реальности? Что её интересует?
Есть целый подбор статей на эту тему: 1, 2, 3
На форуме Kaggle приводились такие классные картинки:

Мы, естественно, решили изобрести свой велосипед, для данной задачи. Тем более пишется он очень просто.
Берём исходное изображение и начинаем двигать по нему чёрный квадрат. При этом смотрим, как изменяется отклик системы.

Результат же отрисуем в качестве тепловой карты.
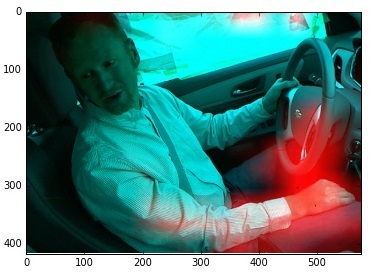
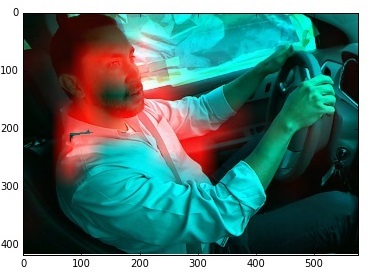
На изображении тут показан пример неправильной классификации изображения класса 9 (разговор с соседом). Изображение классифицировано как «тянется к контролю музыкой». И действительно, похоже. Ведь сеть сама по себе не видит 3d. Она видит руку, которая лежит в направлении к переключателю приборной панели. Ну и что что рука лежит на ноге.
Посмотрев ещё с несколько десятков ошибок мы поняли, что опять всё упирается туда же: сетка не смотрит на то, что происходит на лице.
Поэтому мы придумали другой способ обучения. На вход сети подавался набор, где половина картинок шло напрямую из обучающей базы, а половина была с затёртым всем кроме лица:

И о чудо, сетка стала на порядки лучше работать! Например по ошибочно классифицированному мужику:

Или вот, по другому (как было — как стало):
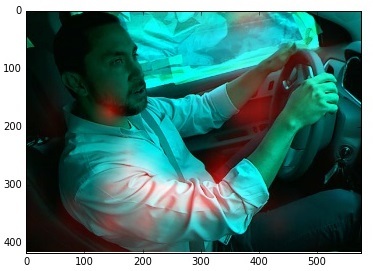
При этом сеть неплохо работала и по остальным классам (отмечала корректные зоны инереса).
Мы уже хотели праздновать победу. Загрузили сеть на проверку — хуже. Объединили с нашей лучшей — итоговый результат не улучшился. Даже не помню, стали ли мы её добавлять в наш лучший ответ. Долго думали, что у нас какая-то ошибка, но ничего не нашли.
Вроде как с одной стороны — сеть стала правильнее смотреть и много какие ошибки исправлять. С другой стороны где-то начала новые делать. Но при этом значимой статистической разницы не давала.
Идей которые не прокатили было сильно больше. Был Dropout, который нам почти ничего не дал. Были дополнительные различнае шумы: тоже не помогло. Но про это ничего красивого и не напишешь.
Вернёмся к нашим баранам
Мы остановились где-то в районе 30х мест. Осталось немного. Множество идей уже провалилось, на компе накопилось штук 25 тестовых проектов. Улучшений не было. Наши знания о нейронных сетях плавно начали исчерпываться. Поэтому пошли гуглить форум текущего конкурса и старые форумы kaggle. И решение нашлось. Оно называлось «pseudo labeling» и «Semi-supervised learning». И ведёт оно на тёмную сторону. Вернее серую. Но было объявлено админами конкурса как легальное.
Вкратце: мы используем тестовую выборку для обучения разметив её алгоритмом обученным по тренировочной выборке. Звучит странно и сумбурно. Но если подумать, то оно забавно. Загоняя в сеть объекты, которые ей же размечены мы ничего не улучшаем в локальной перспективе. Но. Во-первых, мы учимся выделять те признаки, которые дают такой же результат, но проще. По-сути мы обучаем свёрточные уровни таким образом, чтобы они научились выделять новые признаки. Может на каком-то следующем изображении они выделяться и лучше помогут. Во-вторых, мы защищаем сеть от переобучения и оверфита, внося псевдо-произвольные данные, которые заведомо не ухудшат сеть.
Почему этот путь ведёт на серую сторону? Потому что формально использовать тестовую выборку для обучения запрещено. Но ведь мы тут её не используем для обучения. Только для стабилизации. Тем более админы разрешили.
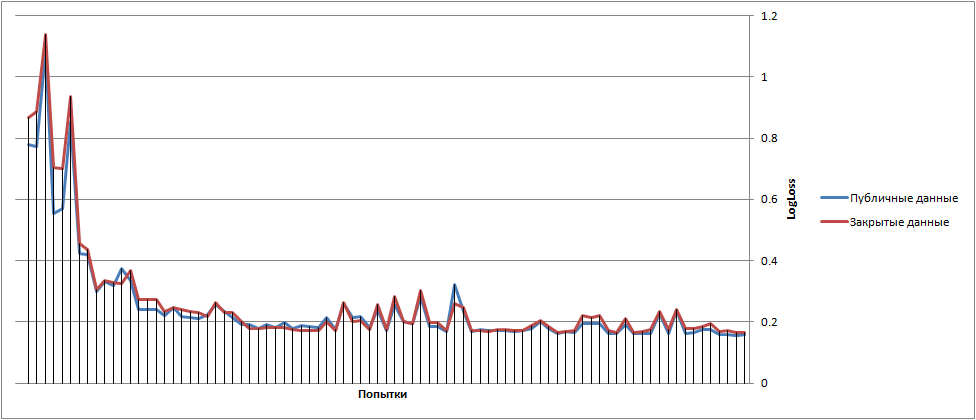
Результат: + 10 позиций. Попадаем в двадцатку.
Итоговый график блуждания результатов выглядел примерно следующим образом(в начале мы не расходовали все попытки в день):
И ещё раз про LogLoss
Где-то в начале статьи я упомянул про то, что к LogLoss я ещё вернусь. С ним всё не так просто. Можно заметить, что log(0) это минус бесконечность => если вдруг поставить 0 в классе где ответ единица, то мы получим минус бесконечность.
Неприятно. Но организаторы защитили нас от этого. Они говорят, что они заменяют величину стоящую под log на max(a,10^(-15)). А значит мы получаем добавку -15/N к результату. Что равно -0.000625 к результату за каждое ошибочное изображение для публичной проверки и -0.0003125 для закрытой. Десять изображений влияют на ошибку в третьем знаке. А это уже позиции.
Но ошибку можно уменьшить. Предположим, вместо 10^(-15) мы поставим 10^(-4). Тогда если мы ошибёмся мы получим -4/N. Но если мы угадаем правильно, то у нас тоже будут потери. Вместо log(1)=0 мы возьмём log(0.9999), что равно -4*10^(-5). Если мы ошибаемся раз в 10 попыток, то нам безусловно это выгоднее, чем потери 10^(-15).
А дальше начинается магия. Нам нужно объединить 6-7 результатов, чтобы оптимизировать метрику LogLoss.
Всего мы делали 80 отправок результата. Из них где-то 20-30 было посвящено именно оптимизации потерь.
Я думаю, что 5-6 мест у нас отыграно за этот счёт. Хотя, как мне кажется, все этим занимаются.
Всю эту магию делал Vasyutka. Я даже не знаю, как последний вариант выглядел. Лишь его описание, которое мы себе сохранили, достигало двух абзацев.
Что мы не сделали
На момент окончания конкурса у нас остался небольшой стэк идей. Наверное, если бы мы всё успели, то это стоило бы нам ещё пяток позиций. Но мы понимали, что это явно не выход в топ-3, поэтому не бросали на борьбу все оставшиеся силы.
- Мы так и не исследовали разбиение базы на небольшие кусочки и независимое их обучение. В теории это добавляет стабильности. Мы использовали похожий подход при Semi-supervised learning, но тоже не целиком исследовав всё поле возможностей.
- Был ещё один серый механизм, который мы всё же не решили использовать, но долго думал. Хотя от администрации не было явного на него запрета. Механизм: найти на тестовой выборке фотографии которые соответствуют разным машинам, построить их модель и вычесть из фотографий фон. Работы тут где-то на 2-3 дня. Но не хотелось: не верили ни в то, что выведет в десятку, ни в то, что идею не запретят.
- Мы не исследовали формирование батча (небольшого массива по которому происходит шаг обучения). Только общий принцип, чтобы статистически он был правильный. Можно было создавать батчи из разных водителей, из одинаковых, и.т.д. Народ на форуме этим развлекался. В принципе идея здравая. Но решили не делать по соображениям времени.
- За пару дней до конца я вспомнил о существовании такого метода. Этот метод позволяет заставить сеть обучаться на общих признаках классов, а не на одинаковых. По сути, исключить фоновые помехи, личность водителя и тип машины. Исходников на этот метод нет, пришлось бы делать сеть с нуля. Так же не ясен вопрос с открытостью/закрытостью. Так как времени оставалось 2 дня — отказались.
Анализ решений других участников
После конца конкурса многие участники публикуют свои решения. Вот тут ведётся статистика по лучшим 20 из них. Сейчас где-то половина из топ-20 опубликовала решения.
Начнём с лучшего из опубликованных. Третье место.


Скажу сразу. Решение мне не нравится и кажется нарушением правил конкурса.
Авторы решения отметили, что все примеры снимались последовательно. Для этого они проанализировали тестовую выборку в автоматическом режиме и нашли соседние кадры. Соседние кадры — это изображения с минимальным изменением => они принадлежат одному классу => по всем близким решениям можно вынести единый ответ.
И да, это ужасно помогает. Если вы разговариваете по телефону держа его в левой руке — есть кадры где не видно телефона и непонятно, говорите вы или чешите голову. Но посмотрев на соседний кадр можно всё прояснить.
Я бы не возражал, если бы таким образом накапливалась статистика и вычиталась фоновая машина. Но реверсинженерить видео — это по мне за гранью добра и зла. Почему-объясню ниже. Но, конечно, решение за организаторами.
Мне очень нравится пятое решение. Оно такое классное и настолько тривиальное. Мысль приходила мне в голову раз десять по ходу конкурса. Но каждый раз я отметал её. «Зачем?!». «Почему это вообще будет работать?!». «Лень тратить время на эту бесперспективщину».
Я даже не обсудил её с товарищами. Как оказалось — зря. Идея вот:

Взять две картинки одного класса. Разбить пополам и склеить. Подать в обучение. Всё.
Я не очень понимаю почему это работает (кроме того, что это стабилизирует выборку: 5 миллионов сэмплов это круто, это не 22 тыщи). А ещё у ребят было 10 карточек TitanX. Может это сыграло важную роль.
Шестое решение плохо описано, я его не понял. Девятое очень похоже на наше. Да и точность отличается не сильно. Судя по всему ребята смогли натренировать сети лучше и качественнее. Подробно они не описали за счёт чего небольшой прирост.
Десятое решение реализовало часть наших идей но чуть чуть по-другому:
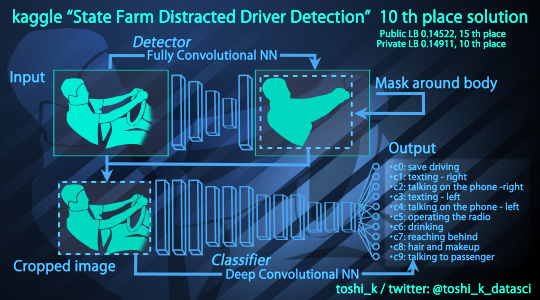
Вырезать область с человеком, чтобы увеличить разрешение -> подать на обучение. Решаются те же проблемы которые мы решали вырезанием лица. Но, судя по всему, лучше.
15 решение — всё как у нас. Даже лиц так же вырезали (плюс область руля от чего мы отказались).
Но… Они натренировали 150 моделей и складывали их. 150!!!
19, 20 решение — всё как у нас но только без лиц. И 25 натренированных моделей.
От игрушек к делу
Предположим вы страховая фирма, которая хочет внедрить систему определения того что делает водитель. Вы собрали базу, несколько команд предложили алгоритмы. Что имеем:
- Алгоритм, который использует данные о соседних кадрах. Это странно. Если бы вы хотели, чтобы ваш алгоритм так работал — вы бы предложили анализировать не фотографии, а видео. Более того. Такой алгоритм почти невозможно завязать с видео как таковым. Если у вас есть алгоритмы, которые распознают отдельный кадр — его очень легко можно надстроить до алгоритма работающего с видео. Алгоритм, который использует «5 ближайших кадров» — очень сложно.
- Алгоритмы, которые используют по 150 нейронных сетей. Это огромные вычислительные мощности. Такой продукт не получиться делать массовым. 2-3 сети это по хорошему максимум. Ок, пусть 10 — предел. Одно дело, если бы ваша задача была детектировать рак. Там такие затраты допустимы. Там нужно бороться за каждый процент. Но ваша цель — массовый продукт.
Но, ещё получили несколько неплохих и интересных моделей.
Давайте пойдём дальше. И поймём насколько работают эти модели. К сожалению, их у меня нет, так что тестировать буду на нашей, которая дала 18й результат, что в принципе не так уж и плохо.
Из всех статей, которые я написал на Хабр моя любимая про то как надо собирать базу. Вот с этой стороны и подойдём к анализу. Что мы знаем о собранной базе?
- При наборе базы водители машину не водили. Машина ехала на грузовике, водителям давались задания что делать.
- Вся база набиралась в дневные часы. Судя по всему в рабочие. Нет низкого солнца. Нет вечерних кадров.
- Все ситуации перфекционизированны. Люди не держат телефон левой рукой у правого уха. Телефоны у всех плюс-минус одинаковые.
- База набиралась в Америке. Вы спросите как я понял? Нет ни одной машины с ручной коробкой…
На первый раз хватит четырёх ситуаций. Но их значительно больше. Все ситуации нельзя предвидеть никогда. Именно поэтому базу нужно набирать настоящую а не моделировать.
Поехали. Кадры ниже делал сам.
Как повлияло то, что при наборе базы водители не водили. Вождение, это достаточно сложный процесс. Нужно крутить головой градусов на 120, смотреть на светофоры, круто поворачивать на перекрёстках. Всего этого в базе нет. А следовательно, такие ситуации определяются как «разговор с соседом». Вот пример:



Дневные часы. Это очень большая проблема. Конечно, можно сделать систему, которая будет ночью смотреть на водителя включая ИК подсветку. Но в ИК подсветке человек выглядит совсем по другому. Нужно будет целиком переделывать алгоритм. Скорее всего тренировать один на день и один на ночь. Но есть не только проблема ночи. Вечер — когда ещё светло но уже темно для камеры и есть шумы. Сетка начинается путаться. Веса на нейронах гуляют. Первая из картинок распознана как разговор с соседом. Вторая картинка — прыгает между «тянется назад», «мэйкап» (что в рамках сети логично, ведь я тянусь к козырьку), «разговор с соседом», «безопасное вождение». Солнце на лице — очень неприятный фактор, знаете ли…


Про перфекционизм. Вот более-менее реальная ситуация:

И веса на нейронах: 0.04497785 0.00250986 0.23483475 0.05593431 0.40234038 0.01281587 0.00142132 0.00118973 0.19188504 0.0520909
Максимум на том, что телефон у левого уха. Но сеть немножко сошла сума.
Про Россию вообще молчу. Почти все кадры с рукой на ручке передач распознаны как «тянется назад»:


Видно, что проблем достаточно много.Я не стал тут добавлять снимки где я пробовал обмануть сеть (включением фонаря на телефоне, странными шапками, и.т.д.). Это реально и это обманывает сеть.
Паника. Почему всё так плохо? Вы же обещали 97%!!
А проблема в том, что НИКАКАЯ система компьютерного зрения не делается с первой итерации. Всегда должен быть процесс запуска. Начиная с простого тестового образца. С набора статистики. С исправлением появляющихся проблем. А они будут всегда. При этом 90% нужно исправлять не программно, а административно. Попался на том, что пробовал обмануть систему — получи пирожок. Кто-то не так крепит камеру? Будь добр, крепи по человечески. А не то сам дурак.
Делая разработку нужно быть готовым, что прежде чем получиться идеальный результат нужно будет всё 2-3 раза переделать.
И мне кажется, что для данной задачи всё не плохо, а наоборот, хорошо. Показанные 95-97% работоспособности по тесту хороши и означают, что система перспективна. Это значит, что итоговую систему можно будет довести до плюс-минус такой же точности. Просто нужно вложить в разработку ещё в 2-3 раза больше сил.
Кстати. Про крепление камеры. судя по всему, то как крепили камеру набирая статистику мешает пассажиру. То, как крепил камеру я — даёт немножко другую картинку, по которой падает статистика. Зато не мешает пассажиру. Думаю, что решение с камерой мешающей пассажиру будет непригодно, скорее всего будут пересобирать базу. Или сильно дособирать.
Так же не понятно где планируются обрабатываться изображения. В модуле, который будет снимать? Тогда нужно там иметь прилично вычислительной мощи. Отправлять на сервер? Тогда это явно единичные кадры. Сохранять на карте и раз в неделю передавать с домашнего компа? Неудобный форм-фактор.
Сколько же время уходит на задачу такого плана с нуля
Дохрена. Я ни разу не видел задачу доведённую до релиза быстрее чем за пол года. Наверное, приложения вида Prism, конечно, можно и за месяц развернуть, а то и быстрее, если инфраструктура есть. Но любая задача где важен результат и которая не является арт-проектом — это долго.
Конкретно по этой задаче. В наборе базы было задействовано минимум человек 70. Из которых человек 5 минимум — обслуживающий персонал, который водил грузовик, сидел с блокнотиком. А человек 65-100 — люди которые вошли в базу (не знаю, сколько их всего). Организовать такую движуху, все набрать-проверить вышло у организаторов вряд ли меньше, чем 1-2 месяца. Сам конкурс шёл 3 месяца, но сделать неплохое решение по набранной базе можно и за 2-3 недели (что мы и сделали). А вот довести это решение до рабочего образца может выйти уже в 1-3 месяца. Нужно оптимизировать решение под железо, выстраивать алгоритмы передачи, дорабатывать решение чтобы оно в холостую при отсутствии водителя ничего не гоняло. И прочее-прочее-прочее. Такие вещи всегда зависят от постановки задачи и от того где и как решение должно использоваться.
А потом начинается второй этап: опытная эксплуатация. Нужно поставить систему людям 40-50 в машину на пару дней каждому и посмотреть как оно работает. Сделать выводы когда оно не работает, обобщить и переработать систему. И тут начнётся болото, где оценить сроки реализации априори до начала работ практически невозможно. Нужно будет принимать правильные решения: в каких ситуациях система дорабатывается, в каких ставиться заглушка, а в каких мы будем бороться административно. Это самое сложное, это мало кто умеет.

Выводы
Выводы будут на тему kaggle. Мне понравилось. Я порадовался нашему уровню. Периодически мне казалось, что мы отстали от времени, выбираем не оптимальные методы в нашей работе. А походу всё норм. Со стороны оценки себя в окружающем мире kaggle очень хорош.
Со стороны решения задач kaggle интересный инструмент. Наверное это один из правильных и всеобъемлющих методов, который позволяет провести неплохой НИР. Нужно только понимать, что готовым продуктом тут не пахнет. Но понять и оценить сложность и пути решения задачи — нормально.
Будем ли мы участвовать ещё — не знаю. Сил чтобы бороться за первые места нужно потратить массу. Но, если будет интересная задачка — почему бы и нет.
Комментарии (32)

gogolgrind
07.08.2016 23:41Сталкивался с похожей в какой-то мере проблемой, когда реализовывал одну статью с конференции. У авторов все было идеально. У меня на валидации было % 99 accuracy. Когда дело дошло до реальных фотографий начался лютый треш. Это немного расстраивает. Я не очень понимаю как в таких случаях добиваться по-настоящему рабочего состояния. ;(

ZlodeiBaal
07.08.2016 23:50+7Методично, плавно вылавливая каждую ошибку и делая для неё затычку. Где программно, где новым алгоритмом, где дообучая, где постулируя административно.К сожалению это единственный путь.
Если честно, то 80% статей — дикий шлак. Результаты нельзя ни повторить, ни довести. Либо получаются куда слабее и проще. Я даже как-то на Хабре писал пример одной такой попытки. А вообще у меня таких примеров относящихся к работе с десятки есть. Даже если выложен код — он часто на примерах авторов даёт другой результат.

ternaus
07.08.2016 23:53А вот ещё такой вопрос: «Сколько времени на итерацию при тренировке различных сетей уходит на GTX 1080 с caffe?»
Интересует порядок величины, чтобы я знал, пора ли мне апгрейд делать.ZlodeiBaal
07.08.2016 23:57ResNet-101 с батчем в 11-12 картинок где-то чуть меньше секунды на прогон сети. Но все изображения в оперативку перед стартом грузил. Сколько времени чистая тренировка, сколько передача данных — не знаю.
VGG-16 и 19 подольше, там батч плохо помню, где-то в районе 30. Думаю секунды по 2 на шаг.
За ночь где-то 40к итераций по ResNet-101 у меня пролетало.Я периодически даже делал чтобы несколько независимых тренировок проходило. Сетей обученных более чем на 30к итераций мы вроде в итоговый ответ не включали.

BelBES
07.08.2016 23:58+1А я что-то собиралась-собирался поучавствовать в этом конкурсе, да так и забыл про него(
И вдруг мы поняли, что SegNet имеет закрытую не OpenSource лицензию.
Хм, а чего там такого инновационного? Энкодер + Декодер? Можно было тогда попробовать FCN тренировать, с ним вроде бы нет проблем в плане лицензии.
ZlodeiBaal
08.08.2016 00:01Ну. Когда времени немного — страшно пробовать что-то новое настроить. На то чтобы SegNet запустить и протестировать у нас в своё время дня два ушло. Так что решили обойтись без этого подхода. Так да, я встречал похожие, но не видел никакого сравнения по качеству/точности/количеству примеров для тренировки.
kxx
08.08.2016 00:14Сейчас на kaggle лидируют либо сверточные сети (для изображений), либо xgb (для всего остального). Другие алгоритмы, похоже, за последние 3 года канули в Лету.
ZlodeiBaal
08.08.2016 00:25Я с kaggle достаточно плохо знаком в этом плане. Даже про xgboost лишь краем уха слышал. А задач на рекуррентные сети там не бывает?
ternaus
08.08.2016 00:29+3Бывают, но редко:
https://www.kaggle.com/c/grasp-and-lift-eeg-detection
https://www.kaggle.com/c/how-much-did-it-rain-ii
И это очень печально.

sim0nsays
08.08.2016 05:08+2Огромное спасибо за рассказ, особенно за разбор других опубликованных решений! Больше нейросетей!

TrojaNFlash
08.08.2016 09:13-2Точность можно повысить сильно, обработав сначало автомобиль, белая заниженная приора, тонированные фонари или тонер по кругу, громкость выхлопа итд

rzykov
08.08.2016 11:28+1Автору респект за интересный пост!
Интересно, а как вы отнесетесь к идее того, чтобы использовать нейронную сеть для извлечения фич, а не как классификатор.
Я имею ввиду следующие, делаем на нейронной сети классификатор, берем выход препоследнего слоя и работаем с ним как с обычными фичами. Здесь уже появляется большое поля для манерва, можно использовать другие методы, например, SVM.
Что думаете?BelBES
08.08.2016 11:43Я имею ввиду следующие, делаем на нейронной сети классификатор, берем выход препоследнего слоя и работаем с ним как с обычными фичами. Здесь уже появляется большое поля для манерва, можно использовать другие методы, например, SVM.
Что думаете?
Ну сетки примерно это и делают: сначала сверточные слои отрабатывают для feature extraction и генерируют на выходе набор карт, поверх которых уже запускается классификатор, реализованный в виде либо полносвязнных слоев, либо в виде GAP, ну а SVM — это частный случай полносвязных нейронных сетей, разве что тренируется немного по другому.
SKolotienko
08.08.2016 14:37Спасибо! Очень интересный, цельный и законченный пост со справделивыми выводами. И поздравляю с хорошим результатом!

AlexAntonov
08.08.2016 15:27На тренировочной и тестовой выборках у вас получались схожие результаты, когда уже оказались в первой сотне? Касательно слова «оверфит» в названии статьи и склеивания полукартинок… В этом плане синтетически увеличить тренировочный набор — очень интересная идея. Можно понять, есть ли склонность алгоритма к оверфиту. И если всё хорошо, то дообучить. Интересно было бы посмотреть, что даст склеивание четвертинок и далее
ZlodeiBaal
08.08.2016 15:29Вот тут наша динамика и по Public и по Private
В целом оно идентично идёт и в первой сотне и выше.SKolotienko
08.08.2016 17:13А есть такой же график, но ещё с качеством по кросс-валидации на обучающей выборке? И как, кстати, делали кросс-валидацию?
ZlodeiBaal
08.08.2016 17:20Неа, нету.
Сначала пробовали выделить кусок из тренировочной выборки. Но она аццки коррелированна бы тогда была. Чтобы корректно её проверять нужно было несколько водителей целиком выкидывать, а это ухудшало точность. Поэтому для тестирования взяли 1.5к из тестовой выборки и разметили руками.
Но тут есть проблема. Руками разметить можно с меньшей точностью, чем результат обучения. Так что такая разметка особо для проверки и не годилась. Как только мы дошли до точностей 0.21 она любой смысл потеряла. Дальше тестировались только по тому что отправляли на KaggleSKolotienko
08.08.2016 17:27Я примерно ожидал, что вы сделали кросс-валидацию «честную», т.е. с выкидыванием водителей, а не просто случайную. Не совсем понимаю, почему ты говоришь, что это ухудшало точность. Вроде в обучающей выборке было 27 водителей и можно было устроить например Leave One Driver Out кросс-валидацию :) В добавок, в статье ведь написано, что если обучить несколько моделей на разных подвыборках, а потом усреднить — качество может улучшиться.
А как тогда происходил подбор гиперпараметров? По размеченной вручную части тестовой выборки? Или только по Public LB? В данной задаче повезло, конечно, что вы не разошлись в результатах между Public и Private, но так опасно делать…ZlodeiBaal
08.08.2016 17:37+11) Один водитель — нерепрезентативен. Нужно выкидывать сразу 5-10. Там есть старушка в обучающей выборке, которая в 30% не то делает. Обычно смотрит на пассажира.
2) Время обучения. У нас было всего 2.5 недели. Полноценную модельку обучить — ночь времени. Время бы увеличилось пропорционально числу фолдов.
3) «если обучить несколько моделей на разных подвыборках» мы ту же точность получили, склеив 3 сетки обученные с разными гиперпараметрами
4) Мы всё же по нашей выборе могли понять, выше у нас или ниже, чем 0.21. Плюс смотрели насколько результаты друг с другом скоррелированны получились. Пробовали стабилизировать различными сложениями результатов с максимальной корреляцией.
5) Подбор гиперпараметров это всё же подбор learnng rate, подбор точки остановки. Мы этими инструментами точность не настраивали. Мы старались получить точность добавлением dropout|приращений и прочей глобальной фигни, которая должна увеличивать вариативность выборки.
6) А чем подборка гиперпараметров по 3-4 водителям будет лучше, чем подборка по LB? По мне точность одинаковы должна быть.SKolotienko
08.08.2016 18:52Понял, времени на подсчёт 27 фолдов просто не было. Но если бы было возможно — то тогда возможно схема с Leave One driver Out (27 фолдов обучить на 26 водителях и тестировать на 1 «выкинутом» водителе) могла дать довольно хорошую почти несмещённую оценку того, как ваш алгоритм ведёт себя на ранее не виданных водителях. Вероятно такая оценка может быть точнее, чем вручную размеченная часть тестовой выборки, и чем Public LB.
Во всяком случае, мне было бы страшно настраиваться на Public LB из-за переобучения. Но, похоже, в данном случае, этого не произошло, поэтому можно считать ваш метод подходящим.


anprs
09.08.2016 13:46Был ещё один серый механизм, который мы всё же не решили использовать, но долго думал. Хотя от администрации не было явного на него запрета. Механизм: найти на тестовой выборке фотографии которые соответствуют разным машинам, построить их модель и вычесть из фотографий фон. Работы тут где-то на 2-3 дня. Но не хотелось: не верили ни в то, что выведет в десятку, ни в то, что идею не запретят.
Почему?
Причины описанные в разделе «От игрушек к делу» (потому что странно? не спортивно?) мне кажутся для данного случая неподходящими. Для реализации в модуле, который будет снимать это вариант идеальный — можно при установке модуля сделать калибровку, снять изображение салона без водителяZlodeiBaal
09.08.2016 13:52Причины по которым мы не использовали на конкурсе:
1) Времени было мало
2) Не было явного разрешения от админов на манипуляцию с тестовой выборкой.
В полноценной реализации да, возможно и получиться использовать. Но нужно сперва смотреть ряд факторов:
1) это одиночные кадры или видеопоток? Механизмы будут разными. Для одиночных кадров вычитание куда менее эффективно. Машина которая проехала по тоннелю и которая выехала на солнышко — плохо вычитается. Другие яркости другие градиенты.
2) За рулём всегда один водитель или разные?
Снять изображение салон без водителя — малорабочий вариант. Это неудобный кейс для массового пользователя. Мне кажется что когда есть конечная постановка задачи — набор алгоритмов нужно выбирать исходя из неё. В такой набор мог бы попасть алгоритм который вычитает фон, а мог бы и не попасть.anprs
13.08.2016 17:56Не было явного разрешения от админов на манипуляцию с тестовой выборкой.
А там по правилам нельзя делать то на что нет явного разрешения или можно то на что нет явного запрета?
ternaus
Вопрос: Вы не могли бы выложить код вашего решенния?
Комментарий: Усреднение 26 fine-tuned VGG16 с аугментацией, где подвыборки выделялись по водителям => 0.19 Public Leaderboard, 0.22 Private LeaderBoard
Это соревнование очень интересное в том смысле, что влоб cross validation не работает. Но при желании можно найти подход. Мне оно тоже очень понравилось, хотя я изрядно оверфитил и меня в результате кинуло на 56 мест.
ZlodeiBaal
Решение собиралось из кучи отдельных кусков, всего порядка 25 проектов сейчас лежит. При этом часть на питоне в убунте писались, всякие обработчики базы в винде на шарпе, там же с лицами и их выделением кусок. Мне, честно говоря лень это всё собирать в единый код, нужно 2-3 дня потратить чтобы всё проверить и запустить:)
Если какие-то отдельные куски нужны, могу выложить. Но ничего нового и особенного нет.
Нас чуть-чуть вперёд кинуло, позиций на 10 после private. Я думаю тут ещё не последнюю роль сыграло, что мы сами ручками разметили 1.5 тысячи и прежде чем отсылать проверяли по ним, стабильно ли решение. Точность эти 1.5к не показывали, но понятно было стало ли лучше решение или нет.
ternaus
Мне вполне хватит куска про python с убунтой с кратким описанием того, что данный файл/функция делает.
ZlodeiBaal
Вы похоже масштаба проблемы не понимаете;)
https://yadi.sk/d/DQY8g0Dptzqke — вот все питоновские исходники.
Подписывать что какая функция делает и структурировать это всё я не буду — это и есть два дня работы;)
pycaffe — питоновские слои для загрузки данных каффе.
*.ipynb — проекты для обучения и тестирования
pascal_multilabel_with_datalayer — используемые описания сетей
ternaus
Спасибо.