
Прошу под кат.
Начальные знания:
Представление графов в форме матрицы смежности, знание основных понятий о графах. Знание C++ для практической части.
Теория
Це?пь Ма?ркова — последовательность случайных событий с конечным или счётным числом исходов, характеризующаяся тем свойством, что, говоря нестрого, при фиксированном настоящем будущее независимо от прошлого. Названа в честь А. А. Маркова (старшего).
Если говорить простыми словами, то Цепь Маркова — это взвешенный граф. В его вершинах находятся события, а в качестве веса ребра, соединяющего вершины A и B — вероятность того, что после события A последует событие B.
О применении цепей Маркова написано довольно много статей, мы же продолжим разработку класса.
Приведу пример цепи Маркова:
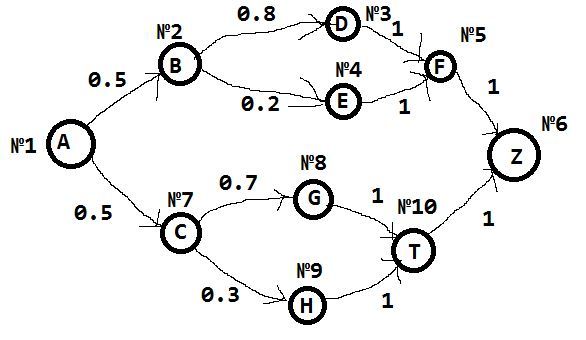
В дальнейшем мы будем рассматривать в качестве примера эту схему.
Очевидно, что если из вершины A есть только одно исходящее ребро, то его вес будет равен 1.
Обозначения
В вершинах у нас находятся события (от A, B, C, D, E...). На ребрах вероятность того, что после i-го события будет событие j > i. Для условности и удобства я пронумеровал вершины (№1, №2 и т.д ).
Матрицей будем называть матрицу смежности ориентированного взвешенного графа, которым изображаем цепь Маркова. ( об этом далее ). В данном частном случае эта матрица называется также матрицей переходных вероятностей или просто матрицей перехода.
Матричное представление цепи Маркова
Представлять цепи Маркова мы будем при помощи матрицы, именно той матрицы смежности, которой представляем графы.
Напомню:
Матрица смежности графа G с конечным числом вершин n (пронумерованных числами от 1 до n) — это квадратная матрица A размера n, в которой значение элемента aij равно числу рёбер из i-й вершины графа в j-ю вершину.
Подробнее о матрицах смежности — в курс дискретной математики.
В нашем случае матрица будет иметь размер 10x10, напишем ее:
0 50 0 0 0 0 50 0 0 0
0 0 80 20 0 0 0 0 0 0
0 0 0 0 100 0 0 0 0 0
0 0 0 0 100 0 0 0 0 0
0 0 0 0 0 100 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 70 30 0
0 0 0 0 0 0 0 0 0 100
0 0 0 0 0 0 0 0 0 100
0 0 0 0 0 100 0 0 0 0
Идея
Посмотрите внимательнее на нашу матрицу. В каждой строке у нас есть ненулевые значения в тех столбцах, чей номер совпадает с последующим событием, а само ненулевое значение — вероятность, что это событие наступит.
Таким образом, мы имеем значения вероятности наступления события с номером, равным номеру столбца после события с номером, равным строки.
Те кто знают теорию вероятностей могли догадаться, что каждая строка — это функция распределения вероятностей.
Алгоритм обхода цепи Маркова
1) инициализируем начальную позицию k нулевой вершиной.
2) Если вершина не конечная, то генерируем число m от 0...n-1 на основе распределения вероятности в строке k матрицы, где n — число вершин, а m — номер следующего события (!). Иначе выходим
3) Номер текующей позиции k приравниваем к номеру сгенерированной вершине
4) На шаг 2
Замечание: вершина конечная если распределение вероятностей нулевое (см. 6-ю строку в матрице).
Довольно изящный алгоритм, так ведь?
Реализация
В эту статью я хочу отдельно вынести код реализации описанного обхода. Инициализация и заполнение цепи Маркова не несут особого интереса (полный код см. в конце).
template <class Element> Element *Markov<Element>::Next(int StartElement = -1)
{
if (Markov<Element>::Initiated) // если матрица смежности создана
{
if (StartElement == -1) // если стартовый элемент по умолчанию
StartElement = Markov<Element>::Current; // то продолжаем ( в конструкторе Current = 0 )
std::random_device rd;
std::mt19937 gen(rd());
std::discrete_distribution<> dicr_distr(Markov<Element>::AdjacencyMatrix.at(Current).begin(),
Markov<Element>::AdjacencyMatrix.at(Current).end()); // инициализируем контейнер для генерации числа на основе распределения вероятности
int next = dicr_distr(gen); // генерируем следующую вершину
if (next == Markov<Element>::size()) // тонкости работы генератора, если распределение вероятностей нулевое, то он возвращает количество элементов
return NULL;
Markov<Element>::Current = next; // меняем текущую вершину
return &(Markov<Element>::elems.at(next)); // возвращаем значение в вершине
}
return NULL;
}
Данный алгоритм выглядит особенно просто благодаря особенностям контейнера discrete_distribution. На словах описать, как работает этот контейнер довольно сложно, поэтому возьмем в пример 0-ю строку нашей матрицы:
0 50 0 0 0 0 50 0 0 0
В результате работы генератора он вернет либо 1, либо 6 с вероятностями в 0.5 для каждой. То есть возвращает номер столбца ( что эквивалентно номеру вершины в цепи ) куда следует продолжить движение дальше.
Пример программы, которая использует класс:
#include <iostream>
#include "Markov.h"
#include <string>
#include <fstream>
using namespace std;
int main()
{
Markov<string> chain;
ofstream outs;
outs.open("out.txt");
ifstream ins;
ins.open("matrix.txt");
int num;
double Prob = 0;
(ins >> num).get(); // количество вершин
string str;
for (int i = 0; i < num; i++)
{
getline(ins, str);
chain.AddElement(str); // добавляем вершину
}
if (chain.InitAdjacency()) // инициализируем матрицу нулями
{
for (int i = 0; i < chain.size(); i++)
{
for (int j = 0; j < chain.size(); j++)
{
(ins >> Prob).get();
if (!chain.PushAdjacency(i, j, Prob)) // вводим матрицу
{
cerr << "Adjacency matrix write error" << endl;
}
}
}
outs << chain.At(0) << " "; // выводим 0-ю вершину
for (int i = 0; i < 20 * chain.size() - 1; i++) // генерируем 20 цепочек
{
string *str = chain.Next();
if (str != NULL) // если предыдущая не конечная
outs << (*str).c_str() << " "; // выводим значение вершины
else
{
outs << std::endl; // если конечная, то начинаем с начала
chain.Current = 0;
outs << chain.At(0) << " ";
}
}
chain.UninitAdjacency(); // понятно
}
else
cerr << "Can not initialize Adjacency matrix" << endl;;
ins.close();
outs.close();
cin.get();
return 0;
}
Пример вывода, который генерирует программа:
A B D F Z
A C G T Z
A C G T Z
A B D F Z
A C H T Z
A B D F Z
A C G T Z
A C G T Z
A C G T Z
A B D F Z
A B D F Z
A C G T Z
A B D F Z
A B D F Z
A C H T Z
A C G T Z
A C H T Z
A C H T Z
A B E F Z
A C H T Z
A B E F Z
A C G T Z
A C G T Z
A C H T Z
A B D F Z
A B D F Z
A C H T Z
A B D F Z
A C G T Z
A B D F Z
A B D F Z
A B D F Z
A B D F Z
A C G T Z
A B D F Z
A C H T Z
A C H T Z
A B D F Z
A C G T Z
A B D F Z
Мы видим, что алгоритм работает вполне сносно. В качестве значений можем указывать что угодно.
Из иллюстрации цепи Маркова видно, что A B D F Z наиболее вероятная последовательность событий. Она же чаще всего и проявляется. Событие E встречается реже всего
Конфигурационный файл, использовавшийся в примере:
10
A
B
D
E
F
Z
C
G
H
T
0 50.0 0 0 0 0 50 0 0 0
0 0 80.0 20.0 0 0 0 0 0 0
0 0 0 0 100.0 0 0 0 0 0
0 0 0 0 100.0 0 0 0 0 0
0 0 0 0 0 100.0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 70.0 30.0 0
0 0 0 0 0 0 0 0 0 100.0
0 0 0 0 0 0 0 0 0 100
0 0 0 0 0 100.0 0 0 0 0
Заключение
Таким образом мы видим, что к цепям Маркова применимы алгоритмы на графах и выглядят эти алгоритмы довольно красиво. Если кто-то знает более лучшую реализацию, то прошу отписываться в комментариях.
Полный код и readme на гитхабе: код
Всем спасибо за внимание.
Комментарии (17)


daiver19
01.06.2016 18:23+1А теперь давайте с помощью этой замечательной реализации попробуем генерировать тексты. В реальности мало когда приходится иметь дело с dense (плотными?) графами, так что представлять граф в виде матрицы неоптимально.
Ну и вообще неясно, в чем суть, вроде же очевидный алгоритм вытекающий из определения цепей Маркова, нет?
SolidMinus
01.06.2016 18:27Спасибо за критику.
Генерировать текст на основе этой реализации можно, вполне. Простые подсчеты говорят, что в тексте из 1000 уникальных (!) слов матрица будет размером 1000x1000, что с точки зрения памяти не такой и большой размер, учитывая, что средний размер слова где-то 7 букв ( байт), то занимаемая память будет 7000 байт ( размер памяти под элементы ) + 1000000 * sizeof(double) байт ( размер под матрицу ), что для современных компьютеров приемлемо. Ведь текст из 1000 неповторяющихся слов — это довольно большой текст, так ведь? Ну а дальше можно накатать алгоритм, который будет составлять матрицу перехода.
А как вы предлагаете представлять граф? Какие у Вас есть предложения?daiver19
01.06.2016 18:45+1Текст марковскими цепями генерируют обычно учитывая предыдущие 2-4 слова. При этом граф получается очень разреженным, а у вас N^2 памяти. Естественно, граф надо представлять списком смежности (в случае текста это хэш-таблица строка->пары строка+вес)
mwambanatanga
02.06.2016 13:32> Текст марковскими цепями генерируют обычно учитывая предыдущие 2-4 слова.
Я ничего не понимаю в марковских цепях, но по определению из текста, это система без «памяти». То есть для генерации следующего слова зависит только от текущего, но не от предыдущих.SolidMinus
02.06.2016 13:32Цепи, которые учитывают предыдущие состояния называются цепями Маркова 1-го порядка, 2-го порядка ну и т.д

Mendel
03.06.2016 10:02Из определения следует, что не учитывается прошлое, а только ТЕКУЩЕЕ СОСТОЯНИЕ. Состояние может быть не одномерным (из последнего слова), а многомерным — из нескольких слов, да еще и не просто учитывать само слово, но и его морфемы. Вообще такая цепочка будет полезна не только для генерации, но и например для разрешения морфологической омонимии.
mwambanatanga
09.06.2016 09:09Тогда почему «текущее состояние» это несколько слов, а «будущее» (генерируемое) — это одно слово?
Mendel
09.06.2016 14:21Почему одно то? точно так-же несколько.
Маршрут перехода такой:
1 Тогда почему текущее
2 почему текущее состояние
3 текущее состояние это
4 состояние это несколько
5 это несколько слов
Тут веселее с сайдэффектами, к примеру в начале у нас пустой узел, потом однословные и т.п… Или сразу сказать на трехсловное выводя сразу все три слова. Знаки препинания тоже вопросы вызывают.
Но всё это детали реализации. Суть не меняется.

Mendel
01.06.2016 19:32+1Такое расточительство по памяти возможно лишь в учебном примере.
Одномерное состояние с малой выборкой вариантов будет на пределе памяти.
А если взять скажем простой вариант текста — три слова, у каждого собственно слово + две морфемы. На практике варианты конечно доступны не все, но скажем миллион узлов будет точно.

paimei
07.06.2016 10:43В каждой строке у нас есть ненулевые значения в тех столбцах, чей номер совпадает с последующим событием, а само ненулевое значение — вероятность, что это событие наступит
Вы вероятность в процентах, что ли, измеряете?SolidMinus
07.06.2016 11:37В данном случае — да. Программно удобнее генерировать целые числа, нежели дробные.
paimei
07.06.2016 11:44Я не буду упоминать про классическое определение вероятности — полагаю, оно всем известно.
Но даже из чисто практических соображений матрица смежности должна содержать значения вероятностей от 0 до 1. Потому что, например, вероятность перехода за N шагов — это матрица смежности в N-ной степени, стационарные вероятности — это результат решения САУ на основе матрицы смежности и т.д.
Вы ведь не просто так марковскую цепь моделируете — вы, наверное, хотите эту модель затем как-то исследовать. Для этого, я полагаю, лучше придерживаться классики.
Идея о том, что целые числа генерировать удобнее — вообще непонятна.Mendel
07.06.2016 14:32Ну на общем фоне это не самое худшее решение.
1 — экономим память. В этом решении очень существенно.
2 — проще решается проблема округления, чтобы общая сумма таки была 1.
3 — ну какие могут быть серьезные анализы с такой моделью? Даже на нормальный дорген не поятнет. Так, поиграться…
Kolyuchkin
Уберите код в спойлер… все равно укажут на это.