
 Клонирование объектов в JavaScript довольно частая операция. К сожалению, JS не предоставляет быстрых нативных методов для решения этой задачи.
Клонирование объектов в JavaScript довольно частая операция. К сожалению, JS не предоставляет быстрых нативных методов для решения этой задачи.К примеру, популярная Node.JS ORM Sequelize, которую мы используем на backend-е нашего проекта, значительно теряет в производительности на предвыборке большого (1000+) количества строк, только на одном клонировании. Если вместе с этим, к примеру, в бизнес-логике использовать метод
clone известной библиотеки lodash — производительность падает в десятки раз.Но, как оказалось, не всё так плохо и современные JS-движки, такие как, например, V8 JavaScript Engine, могут успешно справляться с этой задачей, если правильно использовать их архитектурные решения. Желающим узнать как клонировать 1 млн. объектов за 30 мс — добро пожаловать под кат, все остальные могут сразу посмотреть реализацию.
Сразу хочется оговориться, что на эту тему уже немного писали. Коллега с Хабра даже делал нативное расширение node-v8-clone, но оно не собирается под свежие версии ноды, сфера его применения ограничена только бэкэндом, да и скорость его ниже предлагаемого решения.
Давайте разберемся на что тратится процессорное время во время клонирования — это две основных операции выделение памяти и запись. В целом, их реализации для многих JS-движков схожи, но далее пойдет речь о V8, как основного для Node.js. Прежде всего, чтобы понять на что уходит время, нужно разобраться в том, что из себя представляют JavaScript объекты.
Представление JavaScript объектов
JS очень гибкий язык программирования и свойства его объектам могут добавляться на лету, большинство JS-движков используют хэш-таблицы для их представления — это дает необходимую гибкость, но замедляет доступ к его свойствам, т.к. требует динамического поиска хэша в словаре. Поэтому оптимизационный компилятор V8, в погоне за скоростью, может на лету переключаться между двумя видами представления объекта — словарями (hash tables) и скрытыми классами (fast, in-object properties).
V8 везде, где это возможно, старается использовать скрытые классы для быстрого доступа к свойствам объекта, в то время как хэш-таблицы используются для представления «сложных» объектов. Скрытый класс в V8 — это ничто иное, как структура в памяти, которая содержит таблицу дескрипторов свойств объекта, его размер и ссылки на конструктор и прототип. Для примера, рассмотрим классическое представление JS-объекта:
function Point(x, y) {
this.x = x;
this.y = y;
}
Если выполнить
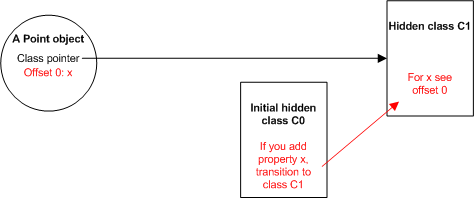
new Point(x, y) — создастся новый объект Point. Когда V8 делает это впервые, он создает базовый скрытый класс для Point, назовем его C0 для примера. Т.к. для объекта пока ещё не определено ни одного свойства, скрытый класс C0 пуст.
Выполнение первого выражения в
Point (this.x = x;) создает новое свойство x в объекте Point. При этом, V8:- создает новый скрытый класс
C1, на базеC0, и добавляет вC1информацию о том что у объекта есть одно свойствоx, значение которого хранится в0(нулевом) офсете объектаPoint. - обновляет C0 записью о переходе (a class transition), информирующей о том, что если свойство
xдобавлено в объект описанныйC0тогда скрытый классC1должен использоваться вместоC0. Скрытый класс объектаPointустанавливается вC1.
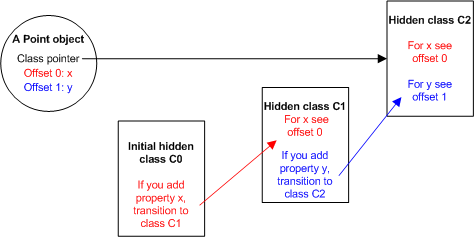
Выполнение второго выражения в
Point (this.y = y;) создает новое свойство y в объекте Point. При этом, V8:- создает новый скрытый класс
C2, на базеC1, и добавляет вC2информацию о том что у объекта также есть свойствоy, значение которого хранится в1(первом) офсете объектаPoint. - обновляет C1 записью о переходе, информирующей о том, что если свойство
yдобавлено в объект описанныйC1тогда скрытый классC2должен использоваться вместоC1. Скрытый класс объектаPointустанавливается вC2.
Создание скрытого класса, каждый раз когда добавляется новое свойство может быть не эффективным, но т.к. для новых экземпляров этого же объекта скрытые классы буду переиспользованны — V8 страется использовать их вместо словарей. Механизм скрытых классов помогает избежать поиска по словарю при доступе к свойствам, а также позволяет использовать различные оптимизации основанные на классах, в т.ч. inline caching.
В связи с этим, идеальным объектом для компилятора будет объект — с конструктором в котором четко определен набор его свойств, не изменяющийся в процессе выполнения. Поэтому самой важной оптимизацией для ускорения доступа к свойствам объектов при клонировании является правильное описание его конструктора. Второй важной частью является непосредственно оптимизация самого процесса чтения-записи, о чем и пойдет речь дальше.
Динамическая генерация кода
V8 компилирует JavaScript код напрямую в машинный во время первого исполнения, без промежуточного кода или интерпретатора. Доступ к свойствам объектов при этом оптимизируется inline cache-м, машинные инструкции которого V8 может изменять прямо во время выполнения.
Рассмотрим чтение свойства объекта, в течении первоначального выполнения кода, V8 определяет его текущий скрытый класс и оптимизирует будущие обращения к нему, предсказывая что в этой секции кода объекты будут с тем же скрытым классом. Если V8 удалось предсказать корректно, то значение свойства присваивает (или получается) одной операцией. Если же предсказать верно не удалось, V8 изменяет код и удаляет оптимизацию.
Для примера, возьмем JavaScript код получающий свойство
x объекта Point:point.x
V8 генерирует следующий машинный код для чтения
x:# ebx = the point object
cmp [ebx,<hidden class offset>],<cached hidden class>
jne <inline cache miss>
mov eax,[ebx, <cached x offset>]
Если скрытый класс объекта не соответствует закешированному, выполнение переходит к коду V8 который обрабатывает отсутствие inline cache-а и изменяет его. Если же классы соответствуют, что происходит в большинстве случаев, значение свойства
x просто получается в одну операцию.При обработке множества объектов с одинаковым скрытым классом достигаются те же преимущества что и у большинства статических языков. Комбинация использования скрытых классов для доступа к свойствам объектов и использования кэша значительно увеличивает производительность JavaScript-кода. Именно этими оптимизациями мы и воспользуемся для ускорения процесса клонирования.
Клонирование
Как мы выяснили из теории выше, клонирование будет наиболее быстрым если выполняется два условия:
- все поля объекта описаны в конструкторе — используются скрытые классы, вместо режима словаря (хэш-таблицы)
- явно перечислены все поля для клонирования — присваивание проходит в одну операцию благодаря использованию inline cache-а
Другими словами, для быстрого клонирования объекта
Point нам нужно создать конструктор, который принимает объект этого типа и создает на его основе новый:function Clone(point) {
this.x = point.x;
this.y = point.y;
}
var clonedPoint = new Clone(point);
В принципе и всё, если бы ни одно но — писать такие конструкторы для всех видов объектов в системе достаточно накладно, так же, объекты могут иметь сложную вложенную структуру. Для того чтобы упростить работу с этими оптимизациями мною была написана библиотека создающая конструкторы клонирования для переданного объекта любой вложенности.
Принцип работы библиотеки очень прост — она получает на вход объект, генерирует по его структуре конструктор клонирования, который в дальнейшем можно использовать для клонирования объектов этого типа.
var Clone = FastClone.factory(point);
var clonedPoint = new Clone(point);
Функция генерируется через eval и операция это не дешевая, поэтому преимущество в производительности достигаются в основном при необходимости повторного клонирования объектов с одинаковой структурой. Результаты сравнительного теста производительности для браузера Chromium 50.0.2661.102 Ubuntu 14.04 (64-bit) при помощи benchmark.js:
| библиотека | операций/сек. |
|---|---|
| FastClone | 16 927 673 |
| Object.assign | 535 911 |
| lodash | 66 313 |
| JQuery | 62 164 |
В целом, мы получаем такие же результаты на реальной системе, клонирование ускоряется в 100 — 200 раз на объектах с повторяющейся структурой.
Спасибо за внимание!
Библиотека — github.com/ivolovikov/fastest-clone
Материалы по теме:
jayconrod.com/posts/52/a-tour-of-v8-object-representation
developers.google.com/v8/design
Комментарии (55)

ChALkeRx
03.06.2016 11:29+1Идея неплохая, да.
Функция генерируется через eval
Не надо так пугать =). Через
new Functionже.
Посмотрел код — конкатенировать много мелких строк через
+=не очень хорошо, но вы результат не храните, как я понял — так что это несущественно.
Но это далеко не самая злая оптимизация, что я видел. Ещё вот такие штуки бывают:
https://github.com/petkaantonov/bluebird/blob/ee247f1a04b5ab7cc8a283bedd13d2e83d28f936/src/util.js#L201-L213
volovikov
03.06.2016 11:40Оптимизация интересная — Вы правы. О том что она делает можно прочитать в статье которую я привел — http://jayconrod.com/posts/52/a-tour-of-v8-object-representation в секции In-object slack tracking. Если в кратце, то она обычно используется чтобы вернуть объект к представлению в виде класса из хэш-таблицы, в которую v8 переводит его, например, после удаления какого-нибудь свойства.

faiwer
03.06.2016 12:37Подскажите: а как правильно поступать когда нужна конкатенация множества мелких строк?
[].join? И как когда есть конкатенация множества больших строк (порядка 20-100 MiB на каждую)?Zenitchik
03.06.2016 12:48Мы так и поступили для клиентской шаблонизации. В ejs, если не ошибаюсь, то же самое сделано.
ChALkeRx
03.06.2016 12:55+2Если конкатенация множества мелких строк — да,
[].join.
Строки в JS, как и во многих других языках, immutable и pooled.
+=создаёт новую строку и добавляет её в пул. Причём строки ссылаются на старые, которые уже были в пуле — поэтому если мы строим посимвольно огромную строку — это худшее, что можно придумать — все её компоненты будут в пуле (пока мы её не нормализуем руками или не освободим, конечно).
Про множество больших строк — не скажу точно, надо проверять для вашего конкретного юзкейса, это зависит от того, каким образом вы их собираете и что вы с ними делаете потом. Например, если у вас есть строка A в 20 MiB, строка B в 20 MiB, и вы сохраняете две строки C = A + B и D = B + A + B + A + B, у вас всё равно в сумме получается занято 40 MiB — тут лучше складывать. Такое поведение оптимально для большинства частых случаев, кроме тех, когда складывается именно очень большое количество мелких строк — тогда накладные расходы становятся очень большими.
См. https://github.com/pieroxy/lz-string/issues/46#issuecomment-80531018, например — это пример посимвольной сборки был.

VitaZheltyakov
03.06.2016 12:40-2Открою Вам великую тайну:
new Function работает так же как и evalChALkeRx
03.06.2016 13:10+13Вы ошибаетесь.
evalнаследует текущую область видимости, а уnew Functionона своя и в неё не попадает всё окружение, как вeval.VitaZheltyakov
04.06.2016 02:22-1Вот поэтому Хабр мертв… 9 плюсов абсурдному комментарию…
new Function отличается от eval только тем, что он не может использовать переменные из области видимости, в которой он был вызван. Все остальное (область видимости, контекст, остальные переменные) точно такие же как у eval. Механизм действия данных подходов одинаков.
То что вы написали, это вообще какая-то околесица.
— Когда это eval стал наследовать текущую область видимости? Он использует глобальную область.
— new Function использует так же глобальную область. Возможно, вы имели в виду, что new Function создает область видимости данной функции. Но и eval может сделать точно также, если ему передать соответствующую конструкцию.
ChALkeRx
04.06.2016 10:30+5Когда это eval стал наследовать текущую область видимости? Он использует глобальную область.
> var x; (function() { var x; eval('x=10'); console.log(x)})(); console.log(x); 10 undefined
xв какой области поменялся? В текущей (той, из которой был вызван). А вы сказали — в глобальной.
> (function() { eval('var y=10;'); console.log(y)})(); console.log(y); 10 ReferenceError: y is not defined
yобъявился в какой области видимости? В текущей (той, из которой был вызван). А вы сказали — в глобальной. И это явно не просто использование переменной, на которое вы ссылаетесь тут:
new Function отличается от eval только тем, что он не может использовать переменные из области видимости, в которой он был вызван.
И да, то, что через eval можно сэмулировать поведение
new Function— верно: засунув тудаnew Function, например. Но я не вижу никаких разумных причин вызыватьevalвместоnew Function— используяnew Function, вы можете быть уверены, что у вас не захватится текущая область видимости, без дополнительных костылей.
Плюс не забывайте про оптимизации —
evalвсегда вызывает деоптимизацию функции, которая его содержит (угадайте, почему).
И да, см. http://www.ecma-international.org/ecma-262/6.0/#sec-eval-x и http://www.ecma-international.org/ecma-262/6.0/#sec-function-constructor.
VitaZheltyakov
04.06.2016 11:47-8Вы даже не представляете, каково мне вести дискуссию с Вами… Это как учить 2-х летнего ребенка читать.
Во-первых, вы путаете понятия «выполнить» и «присвоить».
var y; (function() { var x; eval('y=10'); console.log(x)})(); console.log(y); undefined 10
Во-вторых, думаете, что я не проверю ваш код:
(function() { eval('var y=10;'); console.log(y)})(); console.log(y); 10 10
В-третьих, в JavaScript есть только один механизм выполнения произвольного кода, который работает не как eval. И вы его, как я вижу не знаете. Все остальные способы: начиная с new Function заканчиваяChALkeRx
04.06.2016 12:02+1Во-вторых, думаете, что я не проверю ваш код:
В чём выполняете, если не секрет? Я не могу воспроизвести такого поведения, как у вас, независимо от браузера или режима. Вы точно очистили окружение после предыдущей команды (в которой вы задали глобальный
yв10)?
Поведение
evalдействительно зависит от режима, и в strict mode он ведёт себя несколько не так — объявленные в нём переменные не добавляются в окружающий контекст. Но и совсем не так, как вы показали. И это не решает всех его проблем.
Зависимость поведения
evalот strict mode — ещё один повод не использоватьeval, кстати говоря.
Zenitchik
04.06.2016 12:09+1var y; (function() { var x; eval('y=10'); console.log(x)})(); console.log(y);
undefined
10
А какого поведения Вы ожидали? Вы подтвердили, что код, переданный в eval, выполняется в том контексте, в котором вызван eval.
(function() { eval('var y=10;'); console.log(y)})(); console.log(y);
10
Uncaught ReferenceError: y is not defined(…)
var y='main'; (function(){var y='func'; (new Function('','console.log(y)'))(); console.log(y)})(); console.log(y); main func main
var y='main'; (function(){var y='func'; eval('console.log(y)'); console.log(y)})(); console.log(y); func func main
Легко видеть, что Function работает в глобальном окружении. Это штатный способ создать функцию, не замкнув ничего лишнего.
ChALkeRx
04.06.2016 12:12+1Вот вам ещё один пример, с режимами, кстати:
'use strict'; eval('console.log((function() { return !this; })())'); (new Function('console.log((function() { return !this; })())'))();
выдаёт
true false
Как видно из примера,
evalнаследует текущий режим strict mode, аnew Function— нет.
Ещё раз —
evalиnew Functionне одинаковые, они имеют разное влияние на окружение, они выполняются в разных режимах, они наследуют разные области видимости.
VitaZheltyakov
04.06.2016 12:47-3ChALkeRx и Zenitchik
Вы оба продолжаете путать абстрактные понятия «выполнил» и «присвоил».
Рассмотрим пример:
var x = new Function(тыры-пыры);
Как это работает? Сначала выполняется код функции (тыры-пыры) в глобальной области. Поэтому этот код имеет доступ к глобальным переменным, но не имеет доступа к локальным переменным.
Затем выполняется присвоение, которое ограничивает область видимости данной функции.
Вот так. Все легко и просто. Главное представлять все на уровне абстракций.
Этим и объясняется такое поведение приведенного вами примера:
'use strict'; eval('console.log((function() { return !this; })())'); (new Function('console.log((function() { return !this; })())'))();ChALkeRx
04.06.2016 13:10+2Во-первых, вы не ответили на вопрос, в чём вы выполняете код, что он даёт такие результаты, как у вас выше. Или вы в этом всё-таки ошиблись?
Во-вторых, в вашем примере
var x = new Function(тыры-пыры);вообще не выполняет код внутри функции, как несложно увидеть. Пока мы её не вызовем, конечно. Не верите — напишите тамconsole.log, что ли. Не верите вconsole.log— напишите там долгий цикл.
Во-третьих, я советую вам разобрать именно по шагам все приведённые примеры, и понять, что вы ожидаете в них получить следуя вашей логике. Как минимум в одном случае вы уже явно удивились результату — когда сказали «думаете, что я не проверю ваш код».
VitaZheltyakov
04.06.2016 18:04-6По порядку:
— Код я проверяю в Firefox dev.
— Я привел пример, который показывает ошибку ваших представлений о понятиях «выполнил» и «присвоил».
— Я не зря привел пример с 2-х летним ребенком, которого учат читать. Научить двух летнего ребенка читать не возможно, т.к. восприятие его недостаточно сформировано.
Точно так же и с вами — вы не понимаете абстрактных понятий. И я с этим ничего не могу сделать. Я не могу дать вам пример кода, после понимания которого вы вдруг «прозреете» и начнете понимать работу js на уровне абстракций.
— Последующий ваш комментарий я не понял. Что вы хотели мне показать? Он работает предсказуемо. Если он вас ставит в недоумение или удивляет, то это потому что вы не понимаете абстракций.ChALkeRx
04.06.2016 18:37+1Так. Давайте заново. Я утверждаю, что этот код в условии чистого окружения (в котором не было заранее объявлено переменной
y):
(function() { eval('var y=10;'); console.log(y)})(); console.log(y);
вне strict mode бросит исключение на втором
console.log, а в strict mode — на первом.
Вы мне написали, что он выводит два раза
10, и сказали что я пытаюсь вас ввести в заблуждение:
Во-вторых, думаете, что я не проверю ваш код
Очевидно, вы не ожидаете увидеть там исключения. На самом деле — оно там есть, проверьте ещё раз.
Скорее всего, вы неправильно что-то сделали, когда проверяли первый раз (например, заранее объявили глобальныйyравный 10) — отсюда и неверные выводы. Попробуйте назвать переменнуюyyy, например.
Я сказал, что поведение вас удивляет ровно потому, что вы не согласились с копипастой из командрой строки, решили, что я вас ввожу в заблуждение, и показали мне свой результат неправильной проверки с заверениями, что так и должно быть. Так как поведение вас удивляет — у вас неверное понимание того, как это работает.

vitvad
05.06.2016 07:27+5VitaZheltyakov Firefox dev 48.0a2
(function() { eval('var y=10;'); console.log(y)})(); console.log(y); 10 ReferenceError: y is not defined
это встроеным dev tools. firebug завести не удалось, он говорит что теперь будет dev tools использоваться по умолчанию.
Так вот, в старых версиях хрома ~ v10 — v15 хромовский dev tools а так же firebug в консоли все делали через eval если мне не изменяет память.
Года 4 назад я наткнулся на это и с тех пор проверял либо запуская код из файла либо в nodejs REPL
и еще вопрос, вы со всеми так по хамски общаетесь или просто день не удался?
ChALkeRx
04.06.2016 16:38+1Вот вам ещё пример с
eval, для размышлений:
var z = 20; function x() { z = 10; eval('var z'); console.log(z); } x(); console.log(z);
Угадаете, что будет?
Это, кстати, пример того, почему eval нельзя считать полностью равноценным вставке кода в тело функции — вызов
evalизменил привязку (примечание для всех: пожалуйста, не делайте так в реальном коде).
S-ed
05.06.2016 23:16Хороший пример. Не знал что Eval изменяет scope для всех последующих строк в данной области видимости. Довольно странный эффект. На сайте мозиллы написано что Eval вызывает интерпретатор, тогда как большая часть конструкций JS оптимизирована современными движками (отчасти то, о чём шла речь в данной статье, не знаю, можно ли назвать это компиляцией).

k12th
03.06.2016 11:36Попробовал клонирование через
JSON.parse(JSON.stringify()). У этого способа есть существенный минус — даты и регулярки потребуют особой обработки, функции пропадут, а циклические структуры вовсе свалят код в эксепшен. Но иногда этого хватает. Скорость в ~2 раза выше чем у lodash и jQuery.ChALkeRx
03.06.2016 12:03+2Справедливости для,
JSON.parseиJSON.stringifyподдерживаютreplacer/reviver, которые как раз и нужны, чтобы сохранить дополнительные типы. Но тогда всё будет заметно медленнее работать, скорее всего.k12th
03.06.2016 12:08Блин, про
reviverя не знал, позор мне.
С другой стороны, часто ли нужно клонировать регулярки? В 99% случаев они часть кода, а не данных. Функции тоже нет смысла клонировать. Даты можно хранить как таймстемпы (правда, тоже не всегда).
Zenitchik
03.06.2016 12:51Проверял. Это зависит от количества свойств объекта. На небольшом количестве простое перекладывание в for in работает быстрее. Увы, забыл, со скольки свойств начинается выигрыш времени от JSON, но объекты, с которыми я обычно работаю, оказались недостаточно велики.
k12th
03.06.2016 12:54for..inв лоб даст только shallow-клон, для глубокого надо писать рекурсивную функцию — а зачем, если можно простоJSON.parse(JSON.stringify()).Zenitchik
03.06.2016 15:08Я имел в виду именно рекурсивную функцию. И как я уже писал — «за шкафом». Просто на тех объектах, с которыми я обычно работаю, перекладывание быстрее чем сериализация и последующий парсинг.
Когда я решал для себя этот вопрос, я предполагал, что в зависимости от количества свойств буду использовать разный способ копирования и написал две функции, но так случилось, что объектов, достойных JSON.parse(JSON.stringify()) — у меня так и не завелось.
ChALkeRx
03.06.2016 12:15+7Кстати, о птичках (то есть попугаях).
CloneFactory.prototype = Object.create(null);даёт ещё 10-15% прироста в скорости.
Правда, у вас при этом не будет наследуемых отObjectметодов, но в оптимизированном коде они не очень-то и нужны и без них можно обойтись.
Держите: https://jsfiddle.net/1sq3uhmo/.
ChALkeRx
03.06.2016 20:38+1Знаете, а я мог ошибиться с процентами — это стоит перепроверить на более адекватном бенчмарке.
Сейчас посмотрел ещё раз — разброс сам по себе очень большой, хоть он и говорит о том, что точность ±1-2%.
TargetSan
03.06.2016 12:45+1Мне кажется, что если вы упираетесь в такие вещи, как скорость клонирования (!) объектов, вам надо переходить с JS на что-то более cтатичное. А пытаться писать хайлоад на динамическом языке, ещё и таком, как JS — не лучшая идея.
ChALkeRx
03.06.2016 13:01+3Это не так. v8 очень хорошо оптимизирован, и не особо сложными телодвижениями там можно достичь очень больших скоростей (как, например, показано в этой статье). Вполне можно посмотреть машинный код того, что получится — и вряд ли вы сделаете заметно быстрее.
По поводу «статичности» и того, как работает оптимизатор внутри — см, например http://mrale.ph/blog/2015/01/11/whats-up-with-monomorphism.html.
TargetSan
03.06.2016 13:20+3Да, оптимизация V8 хорошая. Но статический компилятор сможет лучше. Просто из-за более полной информации.
Впрочем, я не хочу превращать эту ветку в холивар "статика против динамики". Мне действительно интересно, почему вы полагаетесь на такую сравнительно зыбкую штуку как JIT и не выделяете нагруженную часть в нативный аддон.
ChALkeRx
03.06.2016 13:34+4Выделение нагруженной части в нативный аддон автоматически выигрыша в скорости не приносит — его надо ещё тщательно оптимизировать, чтобы оказаться быстрее JITа. При этом ошибки в нативном аддоне могут обойтись дороже, из-за ручной работы с памятью.
На тестовых задачах с числодробилками — да, возможно. Но в реальной жизни такое случается не так часто, обычно время уходит не на алгоритмы, стоящие за логикой работы сервера.
Другое дело — может быть полезной выделение какой-то части в асинхронную нить, но этого можно добиться и не выходя из JS.
И да, стоимость переписывания на нативный код и поддержки нативного аддона в человеко-часах в большинстве случаев будет больше, чем стоимость сэкономленных ресурсов. Кроме случаев очень больших компаний со множеством серверов (Facebook, вон, предпочёл форкнуть PHP). Если можно добавить в код волшебный костыль для ускорения работы какого-то нагруженного места на порядок и забыть про это — почему бы и нет. Переписывать всё на нативном — зачем?
В целом — в большей части случаев не стоит связываться, а когда стоит — вы в этом уже точно будете уверены и перепробуете все остальные способы.
TargetSan
03.06.2016 13:58+1По поводу "тщательной оптимизации" — вы ею уже занимаетесь, только при этом полагаетесь на такие неочевидные штуки как поведение JIT. Вы и так уже вставили "волшебный костыль".
По поводу "ручной работы с памятью" — я нигде не упоминал С. В С++ есть масса средств для полу-автоматического управления памятью. Кроме него, есть Golang — статика со сборкой мусора. Рекламировать крутизну некоего языка на R тут не буду.
По поводу "тестовых задач и числодробилок" — вот как раз на них JIT себя и показывает хорошо, из-за однообразного кода.
Но правда и в том, что вашего конкретно случая я не знаю. Может, у вас эти кучи объектов потом перетасовываются так, что в нативе это действительно заморочно сделать.
Ну а "не стоит связываться" — да, не стоит. Потому что нативный V8 API местами проектировали в горячечном бреду, не иначе. Один только C++ only чего стоит.

dom1n1k
03.06.2016 13:25Можно упираться в баузере, где нет выбора. Ну не то чтобы упираться именно в эту одну вещь, но чувствовать ее влияние.

mediaton
03.06.2016 12:50вот еще появится Object.getOwnPropertyDescriptors Proposal
const shallowClone = (object) => Object.create( Object.getPrototypeOf(object), Object.getOwnPropertyDescriptors(object) );ChALkeRx
03.06.2016 13:58+1Его приняли уже. И он есть в вебките (что в следующем сафари) из коробки и в v8 за флагом.

Meredian
03.06.2016 17:22Хорошая новость, т.к. Купертох
node-v8-cloneзабросил. Но бенчмарки и тесты вы оттуда притащили бы все-таки, они очень наглядные, плюс там очень хорошее разбираение того, что можно так скоприровать, и что нельзя.

RZK333
03.06.2016 20:03Почему сразу не дадите вашу версию Sequelize c fast-clone поглядеть? :) вопрос чисто из лени.
вскоре могу наткнуться на такую же проблему, есть бэкенд на Sequelize в который заезжает 42МБ статистических данных из внешнего сервиса, часть из них доезжает в базу и делаются выборки.volovikov
04.06.2016 11:10+1Решение у нас не самое элегантное) Мы просто переопределяем метод прототипа
AbstractQuery.prototype.handleSelectQueryи для raw queries используем fast-clone. Ещё, к стати, если говорить о Sequelize, мы используем адаптер для БД mysql2 вместо стандартного mysql, т.к. он более быстро разбирает протокол.

koresar
07.06.2016 10:38Сравнение с lodash здесь лишнее. Там проверяются циклические ссылки. И поддерживается великое множество типов из ES6. Еще, lodash по разному работает в разных браузерах, версиях v8 и пр.
ChALkeRx
07.06.2016 10:44+2Сравнение с lodash здесь не к тому, что эта супер-библиотека лучше lodash и должна быть использована всегда, а к тому, чтобы показать, какой выигрыш от использования библиотеки (и этого подхода в целом) можно получить на частном случае, когда структура объектов одинакова (и циклических ссылок нет).
webmasterx
а как насчет Object.assign()? Или это что-то другое и им нельзя скопировоать объект?
webmasterx
Понял почему нет упоминаний. Он не рекурсивен. А вам важно рекурсивное копирование.
volovikov
Добавил в тест Object.assign, он не попал туда именно из-за отсутствия поддержки рекурсии, но скорость его также, к сожалению, значительно ниже.