
Представьте, что мы хотим написать на обычном SQL запрос не в базу данных, а к логам. В работе может возникнуть задача анализа логов, для которой потребуется делать запросы на SQL к неструктурированному набору данных, который даже не находится в СУБД. В этой заметке я расскажу о примере использования Spark SQL для выявления правил (логики) выбора необходимых документов из большого хранилища.
По сути, эта заметка является продолжением предыдущего рассказа про Spark. Его модуль, который называется Spark SQL предназначен для структурированной обработки данных. Одним из вариантов использования Spark SQL является исполнение запросов, написанных с использованием базового синтаксиса SQL. В отличие от реляционных баз данных все операции мы исполняем не с таблицами, а с так называемыми DataFrame, которые являются распределённом набором данных. Получить DataFrame можно из обычного RDD или даже из файла формата JSON.
Одним из важных преимуществ подобной распределённой обработки данных является компактность кода и возможность интерактивной работы. Это особенно важно на тех этапах, когда мы предварительно анализируем данные и отлаживаем запросы. При этом, процесс работы можно наблюдать через удобный интерфейс: http://127.0.0.1:4040/jobs/.
Так как речь в заметке идёт именно об анализе логов с помощью запросов на SQL, то рассмотрим следующий пример:
case class Doc(alias: String, classId: Int, typeId: Int)
val data = sc.textFile(bigFile).map(_.split("\\|"))
val docs = data.map(p => Doc(p(0).trim, p(1).trim.toInt, p(2).trim.toInt))
val df = docs.toDF()
df.show
df.printSchema
df.groupBy("classId").count.show
df.registerTempTable("docs")
sqlContext.sql("SELECT COUNT(alias) FROM docs WHERE typeId = 99999").showИз примера видно, что метод «toDF» преобразует обычный RDD в DataFrame. Теперь мы можем исполнять запросы с помощью конструктора (API) и с помощью стандартного синтаксиса SQL. Рассмотрим ещё один пример. Пусть существует лог достаточно большого размера. Необходимо в распределённом режиме обработать информацию. Прежде всего, создадим объект хранения данных:
case class Log(docId: Int, typeId: Int)Теперь загрузка и преобразование в DataFrame:
val df = sc.textFile(logFile).map(_.split(",")).map(p => Log(p(0).trim.toInt, p(1).trim.toInt)).toDF()Вот и всё. Теперь можно начинать работу с данными. Прежде всего, попробуем проверить работоспособность на небольшом объёме данных. Исполним указанный код для вывода первых двадцати записей:
df.showДанные уже структурированы как таблица базы данных. У них тоже есть схема, которую мы можем посмотреть с помощью команды:
df.printSchemaПредположим, что по условиям задачи мы ожидаем, что все идентификаторы документов будут уникальными. Посмотрим общее количество идентификаторов документа, а также количество уникальных идентификаторов документа:
df.select("docId").count
df.select("docId").distinct.countЗамечательно. Теперь мне интересно сгруппировать по идентификатору типа все записи. Посмотрю на количество:
df.groupBy("typeId").count.showХотелось бы взглянуть на некоторые документы заданного типа:
df.filter(df("typeId").equalTo(1)).showВывод данных может быть прямо в консоль, наподобие любого другого консольного клиента для SQL. Для наглядности отображения привожу следующий пример (получаю данные из обычного файла формата JSON):
val log = sqlContext.read.json(jsonFile)
log.printSchema()
log.registerTempTable("log")
val sqlQueryList = List(
"SELECT * FROM log",
"SELECT MAX(id) max FROM log",
"SELECT id AS `Max ID` FROM log ORDER BY id DESC LIMIT 1",
"SELECT l1.id AS `Max ID` FROM log l1 LEFT JOIN log l2 ON l1.id < l2.id WHERE l2.id IS NULL",
"SELECT user_id, COUNT(event_id) cnt FROM log GROUP BY user_id HAVING cnt >= 2",
"SELECT SUM(id), MIN(id), AVG(id), STDDEV_POP(id) FROM log",
"SELECT id, LOG(id), TAN(id), BIN(id), CONCAT('X = ', 3/4 * PI() * POW(id, 3)) FROM log"
)
for (sqlQuery <- sqlQueryList) {
println(sqlQuery)
sqlContext.sql(sqlQuery).show
}Вывод в консоль будет следующий:
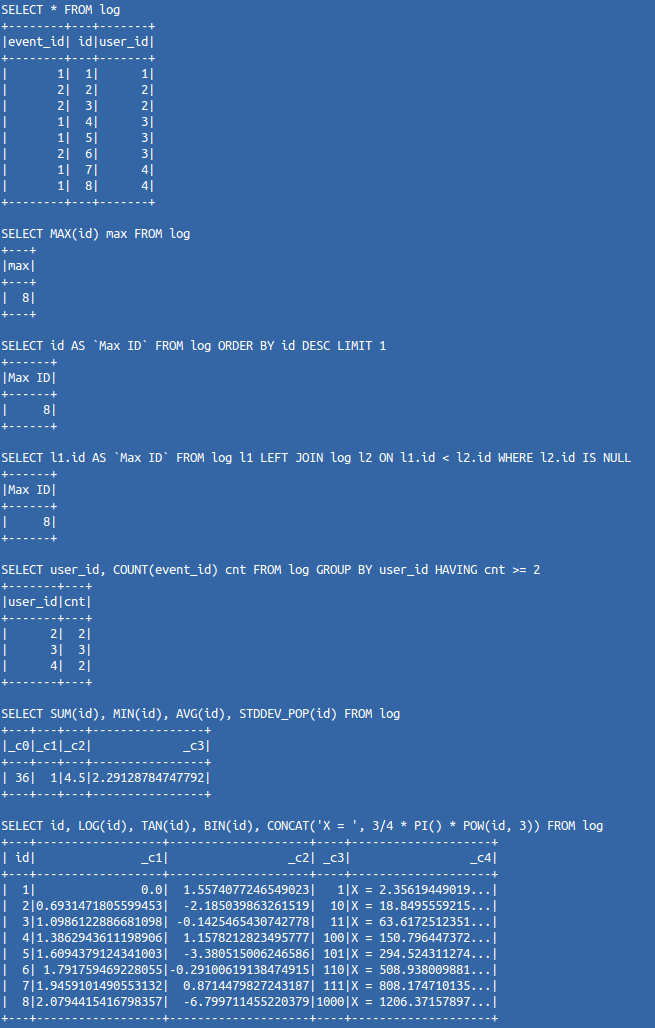
Как видите, упомянутый компонент в ряде случаев способен значительно повысить комфортность анализа слабоструктурированных данных. Более того, для работы с ним вы уже всё знаете, так как запросы пишутся с использованием стандартного синтаксиса SQL.
В некоторых случаях он значительно помог при анализе поведенческих факторов на очень большом портале. С помощью Spark SQL был сформирован индекс классификации для весьма большого энциклопедического справочника. Это лучше описать следующим примером исходного кода на Yii2 (PHP). И так. В системе был виджет, отображающий материал. Его представление:
/**
* @var frontend\widgets\EncyclopediaWidget $this->context
*/
use yii\helpers\Html;
?>
<h1><?= Html::encode($this->context->title) ?></h1>
<div class="well">
<?= $this->context->content ?>
</div>Предположим, что это представление принадлежит вот такому виджету:
namespace frontend\widgets;
use yii\base\Widget;
/**
* Виджет для Encyclopedia
*
* @author Kalinin Alexandr
*/
class EncyclopediaWidget extends Widget
{
/**
* @var string заголовок заметки
*/
public $title;
/**
* @var string содержимое заметки
*/
public $content;
/**
* {@inheritDoc}
* @see \yii\base\Object::init()
*/
public function init()
{
parent::init();
if (empty($this->title)) {
$this->title = 'Нет заголовка.';
}
if (empty($this->content)) {
$this->content = 'Нет содержимого.';
}
}
/**
* {@inheritDoc}
* @see \yii\base\Widget::run()
*/
public function run()
{
return $this->render('encyclopedia');
}
}А он используется в неком представлении контроллера:
/**
* @var frontend\controllers\EncyclopediaController $this->context
* @var common\models\Encyclopedia $encyclopedia
*/
use frontend\widgets\EncyclopediaWidget;
?>
<?= EncyclopediaWidget::widget([
'title' => $encyclopedia->title,
'content' => $encyclopedia->content
]) ?>Контроллер просит нас указать в запросе алиас (система должна найти документ по этому алиасу, а не по ID, который является первичным ключом кластерного индекса):
namespace frontend\controllers;
use yii\web\NotFoundHttpException;
use common\models\Encyclopedia;
use yii\web\Controller;
/**
* Encyclopedia
*
* @author Kalinin Alexandr
*/
class EncyclopediaController extends Controller
{
/**
* @var integer время кэширования
*/
const CACHE_TIME = 20;
/**
* @param string $alias
* @return string
*/
public function actionDoc($alias)
{
$encyclopedia = Encyclopedia::getDb()->cache(function ($db) use ($alias) {
return Encyclopedia::getByAlias($alias);
}, self::CACHE_TIME);
if ($encyclopedia === null) {
throw new NotFoundHttpException('Нет такого документа в нашей энциклопедии.');
}
return $this->render('doc', ['encyclopedia' => $encyclopedia]);
}
}Модель создал с помощью Gii, затем добавил один метод, способный находить документ по упомянутому атрибуту:
namespace common\models;
use Yii;
/**
* This is the model class for table "{{%encyclopedia}}".
*
* @property integer $id
* @property string $alias
* @property string $title
* @property string $content
* @property integer $created_at
* @property integer $updated_at
*/
class Encyclopedia extends \yii\db\ActiveRecord
{
/**
* @inheritdoc
*/
public static function tableName()
{
return '{{%encyclopedia}}';
}
/**
* @inheritdoc
*/
public function rules()
{
return [
[['alias', 'title', 'content', 'created_at', 'updated_at'], 'required'],
[['content'], 'string'],
[['created_at', 'updated_at'], 'integer'],
[['alias', 'title'], 'string', 'max' => 255],
[['alias'], 'unique']
];
}
/**
* @inheritdoc
*/
public function attributeLabels()
{
return [
'id' => 'ID',
'alias' => 'Alias',
'title' => 'Title',
'content' => 'Content',
'created_at' => 'Created At',
'updated_at' => 'Updated At',
];
}
/**
* @param string $alias
* @return Encyclopedia|null
*/
public static function getByAlias($alias)
{
return static::find()->where(['alias' => $alias])->one();
}
}Вот класс миграции:
use yii\db\Migration;
/**
* Миграция для encyclopedia
*
* @author Kalinin Alexandr
*/
class m160706_130958_id100_encyclopedia extends Migration
{
/**
* @var string имя таблицы
*/
const TABLE_NAME = '{{%encyclopedia}}';
/**
* @var string параметры таблицы
*/
const TABLE_PARAMS = 'CHARACTER SET utf8 COLLATE utf8_unicode_ci ENGINE=InnoDB';
/**
* {@inheritDoc}
* @see \yii\db\Migration::up()
*/
public function up()
{
$this->createTable(self::TABLE_NAME, [
'id' => $this->primaryKey(),
'alias' => $this->string()->notNull()->unique(),
'title' => $this->string()->notNull(),
'content' => $this->text()->notNull(),
'created_at' => $this->integer()->notNull(),
'updated_at' => $this->integer()->notNull(),
], self::TABLE_PARAMS);
}
/**
* {@inheritDoc}
* @see \yii\db\Migration::down()
*/
public function down()
{
$this->dropTable(self::TABLE_NAME);
}
}Данные для этой энциклопедии импортировались из другой системы. Правила импорта необходимо было улучшить. С применением Spark SQL были проанализированы очень большие логи, что позволило явно повысить нужные метрики конверсии. Кроме этого, удобство базового синтаксиса SQL повысило субъективную оценку комфортности анализа логов.