
1. Вступление
В широком спектре приложений можно встретить весьма различный функционал обработки статистики, которая необходима как для отчётов, так и для автоматизации работы самого приложения (рейтинги, рекомендации, результаты поиска). Заметка содержит краткое описание некоторых основных методов анализа информации, а также примеры исходного кода, предназначенного для обработки статистики, сбора и подготовки данных.
Статистический компонент — это часть приложения или отдельный сервис, который выполняет обработку информации, включая удобное для пользователя отображение отчёта. В некоторых архитектурах его создают в качестве отдельного сервиса, взаимодействующего посредством API или очередей (RabbitMQ, Redis). Генерация графиков и диаграмм может происходить непосредственно в браузере (Chart.js, D3.js и подобные решения) на основании полученных в JSON данных, а может выполняться заранее (в формате PNG), т.е. в момент обработки данных. Таким образом, с технической точки зрения сервис (модуль, компонент) может быть внешним проектом, реализованным на другом языке программирования.
2. Обработка статистики
Наблюдение — это процесс сбора (регистрации) таких метрик изучаемого объекта, которые позволяют его объективно характеризовать. Наличие подобных метрик (данных, предикторов) позволяет делать выводы о явлениях, прогнозировать сценарий развития событий, классифицировать и сравнивать различные показатели. Однако, накопленный массив измерений сам по себе не является результатом анализа, следовательно, данные необходимо обработать.
Хорошо известный «Anscombe's quartet» (квартет Энскомба, который составил английский математик Френсис Энскомб, а опубликовал журнал «The American Statistician» в феврале 1973 года) показывает пример того, как целый ряд показателей (среднее значение, дисперсия, линейная корреляция между нужными парами предикторов и даже прямая линейной регрессии) может дезинформировать и создать ложное представление о наборах данных.
Чтобы снизить вероятность подобных ошибок первичное описание наблюдений стараются делать достаточно подробным. Оно должно содержать не просто количество измерений, максимум, минимум и среднее значение. Для защиты от выбросов указывают медиану, нижний и верхний квартили, а для понимания степени отклонения случайной величины от математического ожидания указывают и среднеквадратическое отклонение. Если есть несколько предикторов, то вполне логично отображать матрицу корреляции.
В результате пользователь должен увидеть несколько таблиц, которые способны кратко характеризовать полученные измерения. Решить такую задачу можно посредством различных программных продуктов и библиотек (модулей, пакетов) для языков программирования. Например, в языке программирования Python (с применением Pandas) код решения задачи в интерактивном режиме может иметь следующий вид:
import pandas as pd
dataset = pd.read_csv(url)
dataset.info()
dataset.head(4)
dataset.sample(4)
dataset.describe()
dataset.corr()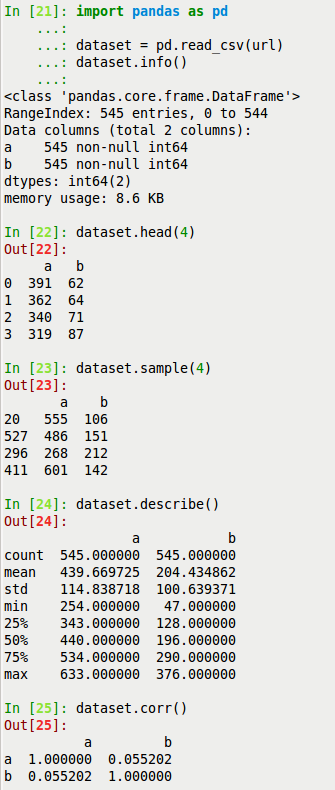
Как уже было упомянуто ранее, крайне сложно переоценить важность визуального отображения информации. Главными способами показать распределение данных являются гистограмма и облако точек. Именно эти два способа визуализации данных можно назвать одними из первых, которые применяются с целью ознакомления с новыми наборами данных. Кроме этого, такое изображение интуитивно понятно широкому кругу лиц, довольно удобно в интерпретации, но при этом весьма информативно.
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('ggplot')
dataset.hist(figsize = (8, 3))
pd.scatter_matrix(dataset, figsize = (5, 5))
Однако, этого далеко не всегда достаточно. Например, показанное множество пар значений описывает координаты точек в двухмерном пространстве. Точки распределены не случайным образом, а образуют четыре явных кластера. Пусть необходимо отобразить точки разными цветами в зависимости от принадлежности к кластеру. Учтём, что четыре кластера имеют разное количество точек и форму.
Если мы применим KMeans, то он постарается разделить все точки на примерно равные группы, а вот DBSCAN с нужными параметрами будет более подходящим для этой задачи. Вначале применим алгоритм KMeans, чтобы увидеть результаты его работы на данном наборе точек. Далее будет приведён пример работы DBSCAN для этого же набора данных. Для максимальной наглядности я специально сформировал искусственный массив координат (использовал HTML5 Canvas с логированием координат кликов, на которых рисуются точки), таким образом, чтобы он был относительно сложной, но понятной формы.
import numpy as np
from sklearn.cluster import KMeans
from sklearn.cluster import DBSCAN
colors = np.array(['red', 'blue', 'green', 'yellow'])
plt.rcParams['figure.figsize'] = (5, 4)
models = [
KMeans(n_clusters = 4).fit(dataset[['a', 'b']]),
DBSCAN(eps = 30.5, min_samples = 20).fit(dataset[['a', 'b']])
]
for model in models:
plt.scatter(dataset.a, dataset.b, c = colors[model.labels_])
plt.show()
Конечно, бывают случаи, когда необходима разметка по специальным формулам предметной области. Общеизвестные алгоритмы кластерного анализа не всегда эффективны, так как действуют законы предметной области. Допустим, необходимо разметить все точки единого облака в заданном радиусе от заранее известного участка. Возможно, что размечаются не все точки, а только с нужной вероятностью, либо им присваивают разные классы в зависимости от расстояний. Выявлять расстояние можно как и в физическом мире, т.е. геометрическое расстояние (евклидово расстояние) между двумя объектами. В качестве примера будет явно расписана логика разметки точек в зависимости от их удаления от некоторых заранее известных координат:
from scipy.spatial import distance
labels = []
values = np.random.normal(250, 40, 4000).reshape(2000, 2)
for v in values:
label = 0
d = distance.euclidean((v[0], v[1]), (220, 240))
if (d > 0 and d < 20):
label = 1
if (d >= 20 and d < 40):
label = 2
if (d >= 40 and d < 50):
label = 3
labels.append(label)
plt.rcParams['figure.figsize'] = (5, 5)
plt.scatter(values[:, 0], values[:, 1], c = colors[labels])
Теперь в этом наборе данных появился ещё один признак. Он является категориальной переменной, с помощью которой можно узнать класс объекта (его принадлежность к тому или иному кластеру). Это позволяет выполнять такие операции как подсчёт количества точек в каждом кластере или посмотреть описательную статистику сгруппированных по классу объектов. Разумеется, всё это можно красиво отобразить для пользователя (цвет столбцов в диаграмме количества точек будет совпадать с цветом точек).
plt.rcParams['figure.figsize'] = (7, 3)
result = pd.DataFrame({'x': values[:, 0], 'y': values[:, 1], 'c': labels})
result.c.value_counts(normalize = False).plot(kind = 'bar', color = colors)
result.groupby('c').agg(['median']).plot(kind = 'bar')
plt.legend(bbox_to_anchor = (1.00, 1), loc = 2)
Но даже такого анализа данных не всегда достаточно. Существенно сложнее, когда у каждого объекта очень много признаков (предикторов), а описательная статистика и визуальное изучение (первичный общий анализ данных) не может дать конкретных ответов. Как правило, подобное изучение данных не выполняют в полностью автоматическом режиме (средствами статистического компонента), а направляют наблюдения специалистам предметной области и специалистам по машинному обучению.
Однако, в некоторых случаях возможно произвести попытку сразу обучить модель классифицировать (или решить задачу регрессии) на валидных наборах данных с известной структурой. Так, например, упомянутый приём не редко используют в задачах анализа поведенческих факторов, социальных и психологических исследованиях. И так. Разделим всю выборку на две части, выполним тренировку на одной и проверку на второй. Дополнительно отобразим примерный вид кластеров (используя только проверочную выборку) и основные метрики качества классификации.
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
plt.rcParams['figure.figsize'] = (3, 3)
X, X_test, y, y_test = train_test_split(values, labels)
models = [
RandomForestClassifier(n_estimators = 1000).fit(X, y),
xgb.XGBClassifier(max_depth = 3, n_estimators = 1000).fit(X, y)
]
for model in models:
print(classification_report(y_test, model.predict(X_test)))
print('Accuracy =', accuracy_score(y_test, model.predict(X_test)))
plt.scatter(X_test[:, 0], X_test[:, 1], c = colors[model.predict(X_test)])
plt.show()
Здесь следует отметить, что в реальных системах большая часть функционала связана с первичной обработкой и сбором данных. Не редко бывает, что до 90% ресурсов расходуется на сбор и подготовку информации, а все оставшиеся ресурсы расходуются на довольно простые задачи (применение нескольких формул предметной области и показ общей описательной статистики в сочетании с визуализацией данных). Следовательно, рассмотрим основные способы сбора и подготовки наборов данных.
3. Сбор данных из внешних ресурсов
В ряде случаев отдельный компонент выполняет парсинг других ресурсов с помощью различных библиотек и программных продуктов (BeautifulSoup, Jsoup, Scrapy, Guzzle, Symfony DomCrawler, PhantomJS, Selenium WebDriver, wget, curl). Для автоматизации браузера подходят такие решения как PhantomJS и Selenium, а для быстрой сборки статического контента BeautifulSoup, Jsoup, Scrapy, Guzzle и подобные решения. Упомянутые технологии могут применяться как интерактивно, так и в качестве специальных сервисов, которые выполняют сбор и сохранение данных с целью последующей (отложенной) обработки иными системами.
В момент парсинга данные проходят предварительную обработку и валидацию. Если всё же этого недостаточно и возникает необходимость дополнительной обработки, то можно применить произвольную функцию обработки данных (в Pandas это делается с помощью метода, который называется apply) к выбранному атрибуту каждой записи. Естественно, можно использовать и свои формулы, допустим, нормализацию и стандартизацию. А вот для замены одной записи на другую (допустим, названия на идентификатор) есть метод map.
Отдельно следует упомянуть возможность разделения вариационного ряда наблюдений на группы (маркировка, разметка). Такая разметка очень часто применяется в задачах с известной предметной областью (банальный пример: весовые категории бойцов MMA). Делается это посредством метода cut. Возможные варианты разбиения: автоматическое разбиение на нужное количество групп и по заданным интервалам. В обоих случаях можно выполнять операцию с указанием собственных меток. К подготовке данных также относят метод one hot encoding, для которого также есть уже реализованный алгоритм. Вот небольшая демонстрация решения упомянутых задач:
obs = pd.DataFrame({
'F': ['второй', 'первый', 'пятый', 'первый', 'пятый', 'первый'],
'A': [10, 20, 30, 40, 50, 60]
})
obs['cut'] = pd.cut(obs.A, 2)
obs['cut_bins'] = pd.cut(obs.A, [8, 30, 70])
obs['cut_labels'] = pd.cut(obs.A, 2, labels = ['OK', 'ERROR'])
obs['apply'] = obs.F.apply(len)
obs['map'] = obs.F.map({'второй': 0, 'первый': 1, 'пятый': 2})
obs['scaler_st'] = ((obs.A - obs.A.mean()) / obs.A.std())
obs['scaler_mm'] = ((obs.A - obs.A.min()) / (obs.A.max() - obs.A.min()))
obs['sigmoid'] = 1.0 / (1.0 + np.exp(-(obs['scaler_st'])))
obs.join(pd.get_dummies(obs['cut_labels']))
Что касается сбора данных парсером, то логика работы и архитектура сильно зависят от масштабов задачи. Вот два примера, которые предназначены для небольших интерактивных задач, следовательно, не содержат менеджер нагрузки, работу с потоками, планировщик обходов. В целях сокращения размеров примеров кода я не добавлял обработку ошибок. Первый фрагмент кода реализован с применением Selenium WebDriver:
from selenium import webdriver
driver = webdriver.Firefox()
result = []
for url in urls:
driver.get(url)
title_len = len(driver.title)
title_words_count = len(driver.title.split())
links_count = len(driver.find_elements_by_xpath("//a[@href]"))
imgs_count = len(driver.find_elements_by_xpath("//img[@src]"))
result.append([url, title_len, title_words_count, links_count, imgs_count])
driver.close()
report = pd.DataFrame(result)А второй с помощью BeautifulSoup:
import urllib.request
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import CountVectorizer
titles = []
for url in urls:
with urllib.request.urlopen(url) as response:
soup = BeautifulSoup(response.read(), 'html.parser')
titles.append(soup.title.string)
vectorizer = CountVectorizer(ngram_range = (1, 1))
report = pd.DataFrame(vectorizer.fit_transform(titles).toarray())
report.columns = vectorizer.vocabulary_В ином случае, если необходимо получить информацию из базы данных основного проекта, то есть смысл создать отдельную копию базы данных или предоставить доступ только на чтение к тестовой базе данных (допустим, через view). А вот при необходимости получать данные по API из самого проекта или публично делиться ими (тогда важно вспомнить про кэширование) добавляют функционал в основное приложение. Пусть оно будет написано на PHP7 (фреймворк Yii2). Передача данных будет осуществляться по запросу клиента. Использование приложения позволит выполнять некоторую дополнительную обработку данных. Для их передачи можно использовать встроенный ActiveController с нужными правами (в примере не указаны):
namespace backend\controllers;
use yii\rest\ActiveController;
class ApiController extends ActiveController
{
public $modelClass = 'common\models\Content';
}Если это решение не подходит, то можно создать свой контроллер:
namespace backend\controllers;
use \yii\web\Response;
use common\models\Content;
class ContentController extends \yii\web\Controller
{
public function actionIndex()
{
\Yii::$app->response->format = Response::FORMAT_JSON;
return Content::find()->newItems()->all();
}
}Пусть в собственной реализации контроллера нам нужна специальная логика получения записей (сортировка, лимит). Такой функционал я вынесу в соответствующий метод класса ContentQuery:
namespace common\models;
/**
* This is the ActiveQuery class for [[Content]].
*
* @see Content
*/
class ContentQuery extends \yii\db\ActiveQuery
{
/**
* New data
* @return Content[]|array
*/
public function newItems()
{
return $this->orderBy('id DESC')->limit(100);
}
/**
* @inheritdoc
* @return Content[]|array
*/
public function all($db = null)
{
return parent::all($db);
}
/**
* @inheritdoc
* @return Content|array|null
*/
public function one($db = null)
{
return parent::one($db);
}
}А логику отображения атрибутов в класс Content:
namespace common\models;
use Yii;
/**
* This is the model class for table "content".
*
* @property integer $id
* @property string $content
* @property integer $created_at
* @property integer $updated_at
*/
class Content extends \yii\db\ActiveRecord
{
/**
* @inheritdoc
*/
public static function tableName()
{
return 'content';
}
/**
* @inheritdoc
*/
public function rules()
{
return [
[['content', 'created_at', 'updated_at'], 'required'],
[['content'], 'string'],
[['created_at', 'updated_at'], 'integer'],
];
}
/**
* @inheritdoc
*/
public function attributeLabels()
{
return [
'id' => 'ID',
'content' => 'Content',
'created_at' => 'Created At',
'updated_at' => 'Updated At',
];
}
/**
* @inheritdoc
* @return ContentQuery the active query used by this AR class.
*/
public static function find()
{
return new ContentQuery(get_called_class());
}
/**
* @inheritdoc
*/
public function fields()
{
return [
'id',
'data' => 'content',
'parsed' => function ($model) {
return $model->parse();
},
];
}
/**
* @return array
*/
public function parse()
{
if (preg_match('~=(\d{1,5})=(\d{1,5})=~', $this->content, $matches)) {
return [$matches[1], $matches[2]];
} else {
return [];
}
}
}Очевидно, что создание нужной таблицы выполняется посредством миграции:
use yii\db\Migration;
/**
* Handles the creation of table `content`.
*/
class m170405_131114_create_content_table extends Migration
{
/**
* @inheritdoc
*/
public function up()
{
$this->createTable('content', [
'id' => $this->primaryKey(),
'content' => $this->text()->notNull(),
'created_at' => $this->integer()->notNull(),
'updated_at' => $this->integer()->notNull(),
]);
}
/**
* @inheritdoc
*/
public function down()
{
$this->dropTable('content');
}
}В некоторых реализациях сбор данных происходит по CRON на стороне веб-приложения. При этом подходе нужные данные сохраняются в базу данных. На практике лучше создавать отдельный модуль, который не затрагивает код основного приложения. Особо подчеркну, что такая реализация явно не пригодна для масштабных задач. В целях компактности примера следующий схематический код на PHP (с применением Slim, Illuminate, Guzzle и Symfony DomCrawler) будет показан без архитектуры (в одном файле в стиле «Hello World»):
use Symfony\Component\DomCrawler\Crawler;
use Illuminate\Database\Capsule\Manager as Capsule;
/**
* Для работы примера нужна миграция
* Одна должна быть в отдельном специальном файле
* Здесь она просто для удобства воспроизведения
*/
$app->get('/install', function ($request, $response, $args) {
Capsule::schema()->dropIfExists('dataset');
Capsule::schema()->create('dataset', function($table) {
$table->increments('id');
$table->string('title');
$table->timestamps();
});
});
/**
* Проверим, что получилось в итоге
* Так как это пример для локальной системы, то тут нет кэширования
*/
$app->get('/json', function ($request, $response, $args) {
$results = Capsule::table('dataset')->select('title')->limit(100)->get();
return $response->withJson($results);
});
/**
* Версия с некоторой обработкой и ответом в формате CSV
*/
$app->get('/csv', function ($request, $response, $args) {
$results = Capsule::table('dataset')->select('title')->limit(1000)->get();
$csv = array_map(function($item) {
return implode(",", Raw::toVector($item->title));
}, $results);
return $response->getBody()->write(implode("\n", $csv));
});
/**
* Непосредственно сбор данных
*/
$app->get('/example', function ($request, $response, $args) use ($urls) {
$errorUrls = [];
$dataset = [];
$client = new \GuzzleHttp\Client(['timeout' => 5.0]);
foreach($urls as $url) {
try {
$respGuzzle = $client->request('GET', $url);
if($respGuzzle->getStatusCode() == 200) {
$crawler = new Crawler($respGuzzle->getBody()->getContents());
$dataset[] = ['title' => $crawler->filterXPath('//title')->text()];
}
} catch (Throwable $e) {
$errorUrls[] = $url;
}
}
Capsule::table('dataset')->insert($dataset);
return $response->withJson(['errorUrls' => $errorUrls, 'data' => $dataset]);
});В тех задачах, где необходимо собрать и проанализировать очень большой набор данных используют распределение задач по серверам. Каждый из них выполняет парсинг по своему плану, что делает его работу независимой, но заранее согласованной операцией. В качестве конкретного примера я приведу Solr (платформа полнотекстового поиска, основанная на библиотеке Lucene). Сбор данных происходит с помощью Jsoup, а запись с помощью Solrj.
Одним из преимуществ такого подхода (применение локальных поисковых систем) можно назвать возможность сразу (в интерактивном режиме) получать некоторую статистическую информацию по записям. Отобразим параметры запроса (полнотекстовый поиск с использованием фасетов и сортировкой по специальному атрибуту). Система должна будет выбрать из всех документов только те, которые содержат нужную ключевую фразу.

Как видно, список (фасет по тексту) содержит заранее обработанные слова. Строка была разделена на отдельные слова. Для этого в Solr используется класс StandardTokenizer. Далее все слова переводятся в нижний регистр (LowerCaseFilter). После этого происходит удаление списка стоп-слов (применяется класс фильтра StopFilter), и, наконец, класс SnowballFilter выполняет их стемминг. В интерфейсе пользователя это будет выглядеть следующим образом:

4. Сбор данных из логов
Это очень важный источник, о котором следует рассказать отдельно. Очень многие системы, распределяющие свою работу на большом количестве независимых устройств записывают свои наблюдение именно в логи. У таких файлов заранее известный формат и структура, но их размеры могут быть невероятно большими.
Такой подход (лог) к записи данных применяют системы протоколирования поведенческих факторов, выгрузки из специальных баз данных (ClickHouse) или административных частей сайтов, протоколы изучения социальных и психологических явлений и множество иных систем. Даже парсеры сайтов стараются разрабатывать с возможностью динамической обработки данных, т.е. извлечения нужных признаков в момент парсинга (по возможности). Общеизвестный формат CSV стал фактически стандартом, в который записывают векторы признаков и различные наблюдения.
Если необходимо проанализировать действительно очень большой набор данных в логах, то часто используют специальный фреймворк для реализации распределённой обработки слабоструктурированных данных (в примере будет показан код на Scala с использованием Apache Spark версии 2.1.0). Если мы уверены в том, что все строки имеют известную и предугадываемую структуру, то будет достаточно просто преобразовать тип данных каждого элемента строки. Сделать это можно несколькими способами, например, таким:
val rawData = sc.parallelize(Array(
"0,3,0.5",
"0,3,1.7",
"1,3,2.5",
"1,2,4.3",
"2,4,1.01",
"2,4,0.012",
"2,4,0.254"
))
// val rawData = sc.textFile("/data/*.log")
val dataset = rawData.map(s => s.split(',').map(_.toDouble))Показанный образец зарегистрированных наблюдений был преобразован в удобный для дальнейших манипуляций массив с нужным типом данных. Можно выполнить и другую трансформацию наборов данных, скажем, в расстояние до заранее известной точки в многомерном пространстве:
val distance = dataset.map(s => {
val dx = math.pow(s(0) - 2, 2)
val dy = math.pow(s(1) - 4, 2)
val dz = math.pow(s(2) - 0.012, 2)
math.sqrt(dx + dy + dz)
})
distance.collect().mkString("\n")Возможно, нам нужны не все показатели, а только соответствующие заранее заданным требованиям. Подобную задачу решают с помощью фильтров, допустим, следующим образом:
distance.filter(_ > 7).collect().mkString("\n")Логика обработки данных может выполняться в методах классов. Сами данные могут быть преобразованы не только в массивы, списки или кортежи, но и в специальные классы:
case class Point3D(x: Double, y: Double, z: Double)
object PointsHelper {
def toPoints(s: String): Point3D = {
val list = s.split(',').map(_.toDouble)
Point3D(list(0), list(1), list(2))
}
}
val points = rawData.map(PointsHelper.toPoints)Пусть один из атрибутов будет идентификатором группы, к которой относится наблюдение. Посмотрим на количество объектов каждой группы:
val groupCount = points.map(p => (p.x, 1)).reduceByKey((a, b) => a + b)
groupCount.collect().mkString("\n")Как известно, в Apache Spark есть собственные классы для типов данных, которые весьма часто необходимы в задачах машинного обучения. Допустим, что по некоторым причинам невозможно загрузить данные посредством MLUtils.loadLibSVMFile или заранее конвертировать в LibSVM, следовательно, необходимо преобразовать их из другого объекта:
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.mllib.tree.RandomForest
import org.apache.spark.mllib.tree.model.RandomForestModel
val labeled = points.map(p => LabeledPoint(p.x, Vectors.dense(p.y, p.z)))
val model = RandomForest.trainClassifier(labeled, 3, Map[Int, Int](), 5, "auto", "gini", 4, 32)
println(model.toDebugString)5. Выводы
Разумеется, охватить в одной заметке всю сложность этой темы не представляется возможным. Однако, заметка содержит краткое описание самых часто используемых способов сбора и анализа информации, применение которых можно встретить в самых различных статистических компонентах для широкого спектра систем и порталов.