

1. Вступление
Это небольшое практическое руководство по применению алгоритмов машинного обучения. Разумеется, существует немалое число алгоритмов машинного обучения и способов математического (статистического) анализа информации, однако, эта заметка посвящена именно Random Forest. В заметке показаны примеры использования этого алгоритма для задач классификации и регрессии, а также даны некоторые теоретические пояснения.
2. Несколько слов о деревьях
Прежде всего, рассмотрим некоторые базовые теоретические принципы работы этого алгоритма, а начнём с такого понятия, как деревья решений. Наша основная задача — принять решение на основе имеющейся информации. В самом простом случае у нас есть всего один признак (метрика, предиктор, регрессор) с хорошо различимыми границами между классов (максимальное значение для одного класса явно меньше минимального значения для другого). Например, зная массу тела нужно отличить кита от пчелы, если известно, что среди всех наблюдений нет ни одного кита, который бы имел массу тела как у пчелы. Следовательно, достаточно всего одного показателя (предиктора), чтобы дать точный ответ, предсказав тем самым верный класс.
Допустим, что точки одного класса (пусть они будут показаны красным цветом) во всех наблюдениях находятся выше точек синего цвета. Человек может провести между ними прямую линию и сказать, что это и будет граница классов. Следовательно, всё расположенное выше этой границы будет относиться к одному классу, а всё ниже линии — к другому.
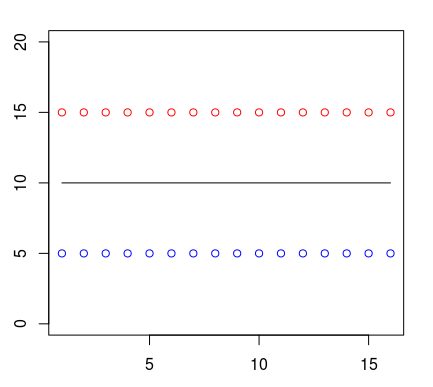
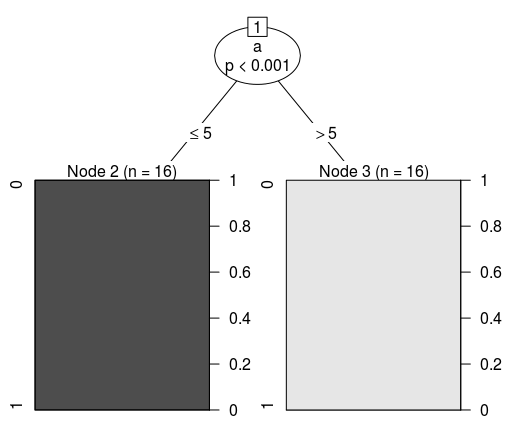
Отобразим это в виде древовидной структуры. Если мы воспользуемся одним из алгоритмов (CART) для создания дерева решений по указанным ранее данным, то получим следующее условие классификации:
Conditional inference tree with 2 terminal nodes
Response: class
Input: a
Number of observations: 32
1) a <= 5; criterion = 1, statistic = 31
2)* weights = 16
1) a > 5
3)* weights = 16 Следовательно, его визуальное представление будет таким:
Разумеется, каждый признак обладает разной степенью важности. Из следующего набора данных (формат LibSVM) видно, что первый признак (его индекс 1, так как нумерация начинается не с нуля) абсолютно идентичен у представителей всех классов. Фактически, этот показатель не имеет никакой ценности для классификации, следовательно, его можно назвать избыточной информацией, которая не несёт никакой практической пользы. Аналогичная ситуация и со вторым признаком (предиктором). Однако, третий из них отличается.
1 1:10 2:20 3:4
0 1:10 2:20 3:5
1 1:10 2:20 3:4
0 1:10 2:20 3:5
1 1:10 2:20 3:4
0 1:10 2:20 3:5
1 1:10 2:20 3:4
0 1:10 2:20 3:5
1 1:10 2:20 3:4
0 1:10 2:20 3:5Именно третий признак (feature 2) и будет служить тем самым заветным различием, с помощью которого можно предсказывать класс по вектору. Логично предположить, что задача может быть решена одним единственным условием (If-Else). Действительно, каждое дерево в алгоритме машинного обучения правильно смогло понять различия. Далее показана отладочная информация (использован классификатор Random Forest из фреймворка Apache Spark 2.1.0) для нескольких деревьев ансамбля случайного леса.
Tree 0:
If (feature 2 <= 4.0)
Predict: 1.0
Else (feature 2 > 4.0)
Predict: 0.0
Tree 1:
If (feature 2 <= 4.0)
Predict: 1.0
Else (feature 2 > 4.0)
Predict: 0.0
Tree 2:
If (feature 2 <= 4.0)
Predict: 1.0
Else (feature 2 > 4.0)
Predict: 0.0Для более сложных задач необходимы более сложные деревья. В следующем примере закономерность перестала быть такой очевидной для человека. Нужно более внимательно посмотреть набор данных, чтобы заметить различия. Условие будет немного более сложным, так как нужна дополнительная проверка.
1 1:10 2:25
0 1:10 2:20
1 1:15 2:20
0 1:10 2:20
1 1:10 2:25
0 1:10 2:20
1 1:15 2:20
0 1:10 2:20
1 1:10 2:25
0 1:10 2:20
1 1:15 2:20
0 1:10 2:20Вот такие дополнительные проверки требуют новых ветвлений (узлов) дерева. После каждого ветвления необходимо будет делать ещё проверки, т.е. новые ветвления. Это видно на отладочной информации. В целях экономии места я привожу только несколько деревьев:
Tree 0:
If (feature 0 <= 10.0)
If (feature 1 <= 20.0)
Predict: 0.0
Else (feature 1 > 20.0)
Predict: 1.0
Else (feature 0 > 10.0)
Predict: 1.0
Tree 1:
If (feature 1 <= 20.0)
If (feature 0 <= 10.0)
Predict: 0.0
Else (feature 0 > 10.0)
Predict: 1.0
Else (feature 1 > 20.0)
Predict: 1.0
Tree 2:
If (feature 1 <= 20.0)
If (feature 0 <= 10.0)
Predict: 0.0
Else (feature 0 > 10.0)
Predict: 1.0
Else (feature 1 > 20.0)
Predict: 1.0А теперь представим себе набор данных из миллиона строк и из нескольких сотен (даже тысяч) столбцов. Согласитесь, что простыми условиями такие задачи будет сложно решить. Более того, при очень сложных условиях (глубокое дерево) оно может быть слишком специфично для конкретного набора данных (переобучено). Одно дерево стойко к масштабированию данных, но не стойко к шумам. Если объединить большое количество деревьев в одну композицию, то можно получить значительно более хорошие результаты. В итоге получается весьма эффективная и достаточно универсальная модель.
3. Random Forest
По сути, Random Forest является композицией (ансамблем) множества решающих деревьев, что позволяет снизить проблему переобучения и повысить точность в сравнении с одним деревом. Прогноз получается в результате агрегирования ответов множества деревьев. Тренировка деревьев происходит независимо друг от друга (на разных подмножествах), что не просто решает проблему построения одинаковых деревьев на одном и том же наборе данных, но и делает этот алгоритм весьма удобным для применения в системах распределённых вычислений. Вообще, идея бэггинга, предложенная Лео Брейманом, хорошо подходит для распределения вычислений.
Для бэггинга (независимого обучения алгоритмов классификации, где результат определяется голосованием) есть смысл использовать большое количество деревьев решений с достаточно большой глубиной. Во время классификации финальным результатом будет тот класс, за который проголосовало большинство деревьев, при условии, что одно дерево обладает одним голосом.
Так, например, если в задаче бинарной классификации была сформирована модель с 500 деревьями, среди которых 100 указывают на нулевой класс, а остальные 400 на первый класс, то в результате модель будет предсказывать именно первый класс. Если использовать Random Forest для задач регрессии, то подход выбора того решения, за которое проголосовало большинство деревьев будет неподходящим. Вместо этого происходит выбор среднего решения по всем деревьям.
Random Forest (по причине независимого построения глубоких деревьев) требует весьма много ресурсов, а ограничение на глубину повредит точности (для решения сложных задач нужно построить много глубоких деревьев). Можно заметить, что время обучения деревьев возрастает приблизительно линейно их количеству.
Естественно, увеличение высоты (глубины) деревьев не самым лучшим образом сказывается на производительности, но повышает эффективность этого алгоритма (хотя и вместе с этим повышается склонность к переобучению). Слишком сильно бояться переобучения не следует, так как это будет скомпенсировано числом деревьев. Но и увлекаться тоже не следует. Везде важны оптимально подобранные параметры (гиперпараметры).
Рассмотрим пример классификации на языке программирования R. Так как нам сейчас нужна классификационная модель, а не регрессионная, то в качестве первого параметра следует явно задать, что класс является именно фактором. Кроме количества деревьев уделим внимание числу признаков (mtry), которое будет использовать элементарная модель (дерево) для ветвлений. Фактически, это два основных параметра, которые есть смысл настраивать в первую очередь.
library(randomForest)
dataset <- read.csv(file="/home/kalinin84/data/real.csv", head=TRUE, sep=",")
model <- randomForest(factor(Class) ~ ., data=dataset, ntree=250, mtry=9)Убедимся, что это именно модель для классификации:
model$typeОзнакомимся с результатами confusion matrix:
model$confusionИнтересно увидеть предсказанные значения (на основе out-of-bag):
model$predictedА функции varImpPlot и importance предназначены для отображения важности предикторов (ценности для точности работы классификатора).
varImpPlot(model)
importance(model)Разумеется, для получения вероятного класса существует специальная функция. Она называется predict. В качестве первого аргумента требует модель, а в качестве второго — набор данных. Результатом будет вектор предсказанных классов. Для надёжной проверки необходимо выполнять тренировку на одном наборе данных, а проверку на другом наборе данных.
Ещё один пример. На этот раз используем Apache Spark 2.1.0 и язык программирования Scala. Информацию мы прочитаем из файла формата LibSVM. После этого необходимо будет явно разделить набор данных на две части. Одна из них будет учебная, а вторая — проверочная. Выполнять стандартизацию или нормализацию нет особого смысла. Наша модель устойчива к этому, равно как и достаточно устойчива к данным различной природы (вес, возраст, доход).
Повторюсь, что обучение необходимо производить только на учебной выборке. Количество классов в этом примере будет равно двум. Количество деревьев пусть будет 50. Оставим индекс Джинни в качестве критерия расщепления, так как теоретически применение энтропии не будет значительно более эффективным критерием. Глубину дерева ограничим девятью.
import org.apache.spark.mllib.tree.RandomForest
import org.apache.spark.mllib.tree.model.RandomForestModel
import org.apache.spark.mllib.util.MLUtils
val data = MLUtils.loadLibSVMFile(sc, "/home/kalinin84/data/real.data")
val splits = data.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
val model = RandomForest.trainClassifier(trainingData, 2, Map[Int, Int](), 50, "auto", "gini", 9, 32)Теперь используем тестовый набор данных, чтобы проверить работу классификатора с указанными параметрами. Следует заметить, что порог точности (пригодность модели) определяется индивидуально в каждом конкретном случае.
import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics
val result = testData.map(p => (p.label, model.predict(p.features)))
val metrics = new BinaryClassificationMetrics(result)
// Результат: 1.0 — т.е. всё пространство под ROC
metrics.areaUnderROC
// Результат: Array((0.0,0.0), (0.0,1.0), (1.0,1.0), (1.0,1.0))
metrics.roc.collectПолучив на вход вектор предикторов, система должна угадать (с допустимой вероятностью) класс объекта. Если в результате нескольких проверок на большом наборе данных это удалось сделать, то можно утверждать о точности модели. Однако, никакой человек и никакая система не смогут угадать с очень высокой точностью по росту человека его уровень образования. Следовательно, без правильно собранных и подготовленных данных сложно (или вообще невозможно) будет решить задачу.
4. Несколько мыслей о практическом применении
Бывают такие ситуации, когда простым условием или методами описательной статистики задачу сходу решить не получается. Как раз в задачах повышения эффективности интернет-проектов (анализ клиентов, выявление вероятности покупки, оптимальные стратегии рекламы, выбор товаров для показа в популярных блоках, рекомендации и персональные ранжирования, классификация записей в каталогах и справочниках) и встречаются подобные сложные наборы данных.
Помню, несколько лет назад впервые столкнулся с необходимостью применения ML-технологий. Была ситуация, когда мы с коллегами (группа разработчиков) пытались придумать метод классификации материалов подробного справочника на очень большом портале. Раньше классификация выполнялась вручную другими специалистами, что требовало огромного количества времени. А вот автоматизировать никак не получалось (правила и статистические методы не дали нужной точности). У нас уже был набор векторов, который ранее разметили специалисты.
Тогда меня удивило, что несколько строк кода (применение одной из популярных библиотек машинного обучения) смогли решить проблему буквально сразу. Естественно, что изучалась возможность применения различных моделей (включая нейронные сети) и продумывались рациональные гиперпараметры. Но так как эта заметка про случайный лес, то пример на языке программирования Python будет посвящён именно ему. Естественно, код примера написан с учётом новых версий готовых классификаторов, а не используемых тогда:
import pandas as pd
from sklearn.metrics import classification_report, accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
#
# Получение данных
#
dataset = pd.read_csv('/home/kalinin84/data/real.csv')
#
# Разделяем (тестовый и тренировочный наборы)
#
train, test = train_test_split(dataset, test_size = 0.4)
classes = train.pop('Class').values
features = train
testClasses = test.pop('Class').values
testFeatures = test
#
# Тренировка модели
#
model = RandomForestClassifier(n_estimators=500, max_depth=30).fit(features, classes)
#
# Отчёты о точности работы
#
print(classification_report(testClasses, model.predict(testFeatures)))
print(accuracy_score(testClasses, model.predict(testFeatures)))Таких примеров очень много. Расскажу ещё одну историю. Была задача повысить эффективность огромной системы управления рекламой. Её работа напрямую зависела от точности предсказания рейтинга товаров и услуг. У каждого из них был вектор из 64-ти признаков. Стратегически важно было заранее дать относительно точный прогноз значения рейтинга для каждого нового вектора признаков. До этого система управлялась нехитрыми правилами и описательной статистикой. Но, как известно, эффективности и точности в таких вопросах много не бывает. Для решения задачи повышения эффективности была использована регрессионная модель, похожая на указанную в примере:
from sklearn.datasets import load_svmlight_files
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
#
# Получение данных (тестовый и тренировочный наборы)
#
X, y, Xt, yt = load_svmlight_files(("/data/001.data", "/data/001_test.data"))
#
# Тренировка модели и отчёт о точности работы
#
model = RandomForestRegressor(n_estimators=500, max_features=5).fit(X,y)
print(mean_squared_error(yt, model.predict(Xt)))
#
# Сравним с алгоритмом на основе идеи бустинга
# Он должен быть явно быстрее случайного леса
#
import xgboost as xgb
modelXGB = xgb.XGBRegressor().fit(X, y)
print(mean_squared_error(yt, modelXGB.predict(Xt)))В итоге мы получаем достаточно мощный инструментарий анализа информации, который способен прийти на помощь в тех задачах, где другие методы дают не самые лучшие результаты.
Комментарии (8)

IliaSafonov
29.01.2017 22:21+4На эту же тему стоит почитать пост в блоге одного из лучших специалистов по ML профессора Александра Дьяконова: Случайный лес (Random Forest)

ternaus
29.01.2017 23:11+1Постов про RandomForest много. Лучше бы, конечно, пост про LightGBM, там красиво деревья строят. И по точности сопоставимо, хоть и чуть хуже, с xgboost, но на большинстве данных всяко лучше, чем RandomForest.

yorko
30.01.2017 00:37+2Рассказывать о деревьях и ни разу не нарисовать дерево? Это как так? Сравните с тем, как деревья описываются тут в статье "Энтропия и деревья принятия решений". Или как Xgboost описывается в официальной документации.
Код у вас то на R, то на Python.
Вывода нет. Зачем нам видеть "print(mean_squared_error(yt, modelXGB.predict(Xt)))", если ничего не печатается, а воспроизвести результаты мы не можем (лучше к статье прикладывать код на GitHub).
"… для решения сложных задач нужно построить много глубоких деревьев". Тут бы рассказать про bias-variance decomposition, почему лес вообще лучше одного дерева.
В-общем, как-то тут ни теории, ни практики… что-то услышал, рассказал.
yorko
30.01.2017 00:50Ну и да… куда полезней была бы статья про Vowpal Wabbit, Xgboost (так ничего внятного на хабре и не появилось), LightGBM, факторизационные машины, Generative adversarial networks, Neural Turing Machine, обучение с подкреплением и т.д.

ServPonomarev
30.01.2017 11:50-1Желательно писать о задачах, в которых описываемый классификатор даёт результаты лучше, чем другие.
Например, попробуем предсказать результаты армрестлингового матча имея вес каждого из соперников, обхват бицепса, количество отжиманий и т.д.
Может дерево решений такую задачу решить? нет. Потому, что не в состоянии сравнивать значения факторов между собой. Деревья решений могут сравнивать факторы только с константами. Доработав набор факторов, включив туда разности между оригинальными факторами, можно и деревья приспособить под такую задачу, но опять таки — разности брать абсолютные (x — y) или относительные ( (x — y)/(x+y)). Что лучше? Вот такие советы и стоит давать.
Dark_Daiver
30.01.2017 19:28Вы безусловно правы, но вот только
Может дерево решений такую задачу решить? нет.
Все же это не совсем так.
Если у нас есть достаточно большая и хорошая (хорошо покрывающая случаи которые будут возникать на практике) обучающая выборка, то в принципе можно достигнуть не идеальных, но приемлемых результатов.
Доработав набор факторов, включив туда разности между оригинальными факторами, можно и деревья приспособить под такую задачу, но опять таки — разности брать абсолютные (x — y) или относительные ( (x — y)/(x+y)). Что лучше?
Кстати говоря, какие-нить из алгоритмов ML умеют вытаскивать подобные зависимости по дефолту?
ternaus
31.01.2017 02:46В 95% случаев на данных смешанного типа, с размером train set в диапазоне 10^4-10^7 ансамбли деревьев обойдут все остальные алгоритмы и часто с сильным отрывом. И ваша задача про армреслеров при наличии достаточного числа данных в эту категорию и попадает.
Какие признаки использовать? Добавляйте все сколько фантазии / опыта хватит и выкидывайте все те, что не работают или "шумят".
PapaBubaDiop
Все здорово, но где файл /home/kalinin84/data/real.csv?
Хотя бы в щелку посмотреть.