
1. Вступление
Данная заметка рассказывает о некоторых аспектах практического применения классификаторов в системах анализа активности посетителей сайтов. Показаны примеры кода для задач машинного обучения, которые активно применяются как для глобального анализа статистики в интернет, так и для локальных задач классификации поведенческих факторов на крупных порталах.
2. Некоторые методы теории вероятностей
Основная проблема состоит в том факте, что при стохастических процессах (активность посетителей сайтов) невозможно заранее выявить значение случайной величины. Однако, мы сможем оценить вероятность каждого из значений. Более того, используя методы машинного обучения мы сможем понять причины, по которым та или иная случайная величина приняла своё значение.
Бывают стохастических процессы с весьма остро выраженной закономерностью, например, наблюдатель зафиксировал несколько тысяч испытаний. Предположим, что за весь длительный период наблюдений было выявлено, что случайная величина принимала только четыре возможных значения с равным распределением. Логично предположить, что количество одного из этих значений будет примерно в четыре раза меньше количества всех. И наоборот: умножив количество значений из одной группы на четыре мы получим примерное количество всех объектов.
По аналогии можно выявлять (по методу Монте-Карло) приблизительную площадь сложных фигур, если известно количество попаданий по ней точки, общее количество случайных точек и площадь пространства, в которое вписана сложная фигура. Интуитивно будет ощущаться, что если разделить количество попаданий в сложную фигуру на всё количество точек, то это и будет примерная часть, занимаемая фигурой в пространстве. Более того, это также будет вероятностью попадания точки в эту сложную фигуру.
Рассмотрим упрощённый пример. Пусть на огромном новостном портале есть четыре основные темы. Некие пользователи заходят на сайт и смотрят строго только одну из тем. Распределение между ними равное, т.е. равная вероятность, что будет просмотрена тема одного из кластеров. Но точная позиция новой точки заранее не известна, а известно только то, что она обязательно появится в одном из этих кластеров (центроиды показаны в виде больших зелёных точек):

Невозможно, чтобы была просмотрена несуществующая тема (как её посмотреть, если её нет?), т.е. её вероятность равна нулю. Любая точка принадлежит только этому пространству. Вероятность попадания в конкретный кластер равна 1/4. Вероятность попадания хотя бы в один из кластеров будет равна 1 (сумма вероятностей всех событий), так как точка обязательно попадает в один из них. Вероятность того, что точки несколько раз подряд попадут в один кластер равна произведению вероятностей этих событий. Это можно увидеть экспериментально и формально записать как:

А вот для нормального распределения используется несколько отличная тактика прогноза. Необходимо выявить среднее значение. Именно оно и будет самым вероятным. Далее привожу два визуальных отображения равновероятного распределения и нормального распределения.
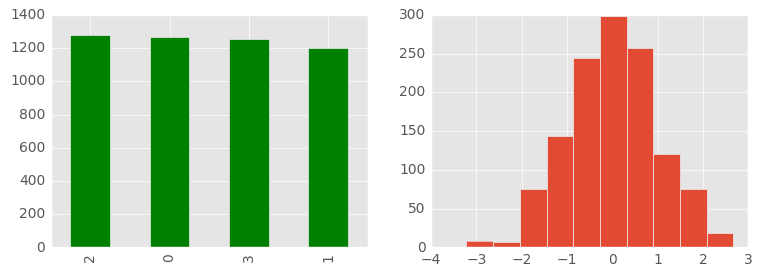
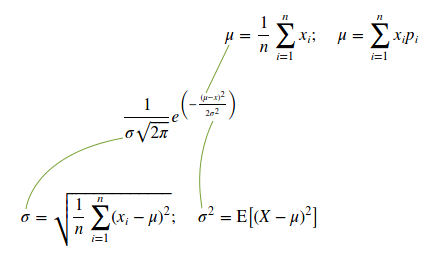
Чтобы понять силу разброса необходимо выявить дисперсию (или квадратный корень из неё, который называют среднеквадратическим отклонением и обозначают греческой буквой сигма). Для прогнозирования значения дискретной случайной величины это весьма важный показатель, так как большинство значений (если это нормальное распределение) находятся в пределах сигмы.
Другими словами: если при нормальном распределении мы будем ожидать среднее арифметическое (оно равно математическому ожиданию), а допустимая ошибка (неточность или погрешность) составит хотя бы около одной сигмы, то в большинстве случаев (около 68%) мы будем успешно угадывать. Визуально отобразим случайную величину с разным уровнем дисперсии: вначале дисперсия небольшая, а потом явно увеличивается. Для удобства визуального восприятия также увеличено и математическое ожидание.
Так как речь идёт о дискретных случайных величинах, то допустимо использовать формулу среднего арифметического значения вместо формулы математического ожидания. По упомянутой причине можно использовать показанную внизу слева формулу, чтобы не вычислять сумму квадрата значения, умноженного их на вероятность, а потом вычитать из суммы этих произведений математическое ожидание, возведённое в квадрат. Привожу функцию нормального распределения и необходимые для неё переменные (формулы для их вычисления):
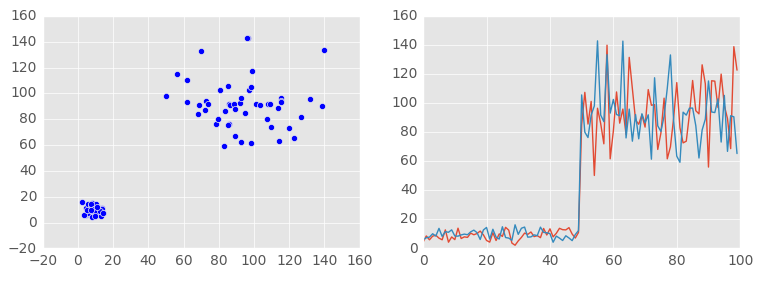
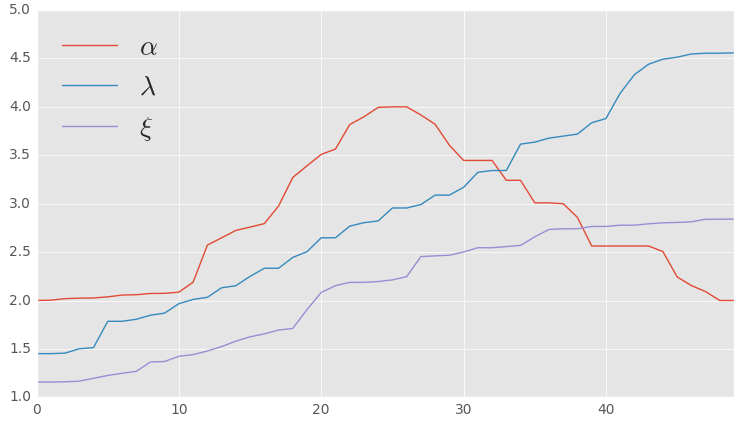
Но не всегда всё так предсказуемо. Естественно, вероятность случайной величины может меняться. Далеко не во всех процессах будет наблюдаться распределение по закону Гаусса или равновероятное распределение. Весьма часто можно зафиксировать изменения вероятности со временем, т.е. некоторые метрики могут непредсказуемым образом менять свои значения, что явным образом будет сказываться на вероятности. Пример изменения значений, в котором две метрики неравномерно растут, а одна после роста возвращается к исходному значению:
Следовательно, в ряде процессов результаты (появление точки) могут быть распределены не равномерно. Очевидно, что в следующем примере облако нельзя назвать равномерно распределённым в пространстве. Для наглядности также привожу его контуры:

В анализе большого числа данных с разными распределениями нам поможет машинное обучение. У каждого наблюдения будет большой вектор признаков. Например, при диагностике ОРВИ часто используют такой показатель, как температура тела. Его очень легко объективно измерить с помощью соответствующего прибора. Очевидно, что если посмотреть описательную статистику температуры тела двух групп людей (здоров и с ОРВИ), то будет достаточно легко понять различия по этому показателю. Разумеется, одной метрики будет недостаточно, так как симптом повышенной температуры может возникать (или отсутствовать) и при множестве других болезней. Следовательно, нам необходимо объективно замерить огромный список показателей (вектор предикторов). Каждый вектор должен иметь метку: здоров или болен. Это общий принцип подготовки данных для тех методов машинного обучения, о которых сейчас пойдёт речь.
3. Предварительное исследование
Предварительный этап анализа далеко не всегда требует задействования серверов в дата-центре, следовательно, его выполняют на локальных компьютерах. Одними из самых популярных инструментов анализа данных являются языки программирования R и Python (в сочетании с Jupyter, Pandas, NumPy и SciPy). Они обладают богатыми наборами уже реализованных математических функций и средств для визуализации информации.
На этапе предварительного исследования необходимо собрать нужную для классификации информацию. Это всегда вектор признаков, т.е. чисел (обычно тип данных Double). На этом этапе выбираются методы сбора и действия в случае невозможности получить значение (иногда допустимо заменять пропущенные значения средним арифметическим или медианой).
Метрика (предиктор) должна быть таким числом, которое объективно отражает суть этой части явление. Такая метрика измерима, а сами измерения воспроизводимы (любой человек с исправным устройством измерений может повторить эксперимент и получить примерно такие же показатели). Интуитивно ожидается, что чем сильнее будет разница между значениями метрики в разных группах, тем проще будет классифицировать. В самом идеальном случае они не пересекаются (максимум одного явно меньше минимума другого).
На этом этапе также могут потребоваться дополнительные проверки. Они реализуются с помощью весьма большого количества сторонних библиотек и программных продуктов. Иногда бывает забавно наблюдать за количеством импортируемых модулей, особенно разного на первый взгляд назначения (вроде Mystem и Selenium). Вполне логично, что можно производить различные эксперименты, которые подтверждают или опровергают гипотезу. Разделять на группы и под тщательным контролем воспроизводить условия и ожидать изменения метрик соответствующим образом.
Если говорить о специфике систем анализа поведенческих факторов, то логика их работы подразумевает, что собранные данные уже прошли чистку и валидацию. В идеале само приложение должно отвечать за качество сбора данных. Остаётся только разметить (для каждого вектора пометить класс, к которому он относится). Не исключено, что приложение уже разметило данные (допустим, в базе данных уже есть запись, которая и станет меткой: купил или не купил товар). Разумеется, это необходимо для того, чтобы в дальнейшем прогнозировать вероятность этого события или выявить наиболее важные предикторы.
Достаточно часто данные хранят в обычных текстовых файлах формата CSV или libsvm. Это позволяет удобно обрабатывать их с помощью R и Python (Pandas, NumPy). В некоторых случаях необходимо поместить их в базу данных. А в отдельных случаях могут потребоваться распределённые вычисления. На огромных порталах и в глобальных статистических системах получается весьма большая матрица. Тут возникает вопрос выбора системы для хранения огромного числа наблюдений в весьма широкой таблице (очень много кортежей с большим числом атрибутов).
Скорее всего, есть смысл обратить внимание на специализированные аналитические решения, которые обладают огромной скоростью обработки. Применение таких технологий как ClickHouse (аналитическая система управления базами данных) позволяет предварительно проанализировать некоторые важные показатели и подготовить сами данные. И речь сейчас не просто о высокой производительности, но и о ряде полезных функций для работы со статистикой, а также дополнительных возможностях, например, возможности выбора формата экспорта данных (включая JSON и XML) или ответ прямо в браузере после get-запроса (http://localhost:8123/?query=Q), где вместо Q следующее выражение на SQL:
SELECT page, COUNT() AS views, uniqCombined(uuid) AS users
FROM example.page_views
GROUP BY page
FORMAT CSVWithNames;Подготовка и проверка данных — это очень серьёзный процесс, ему уделяют огромное внимание. После нескольких исследовательских запросов начинается выбор алгоритмов машинного обучения и более детальный анализ выборки упомянутыми ранее инструментами. Даже на этапе подбора наиболее подходящих алгоритмов классификации продолжается проверка исходных данных и попытка найти новые предикторы. Во всяком случае, очень многие «чудеса классификации» легко объясняются парочкой упущенных или зашумлённых предикторов. В ряде случаев можно даже создать массив классификаторов и проанализировать правильность работы каждого из них с соответствующими параметрами:
import pylab
import pandas as pd
import numpy as np
import xgboost as xgb
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from mpl_toolkits.mplot3d import Axes3D
from sklearn.linear_model import SGDClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from IPython.core.display import display, HTML
#
# Список классификаторов
#
classifiers = [
LogisticRegression(max_iter=200, penalty="l2"),
SGDClassifier(loss="hinge", penalty="l2"),
MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(3, 4)),
RandomForestClassifier(n_estimators=60, max_depth=5),
GradientBoostingClassifier(n_estimators=180, learning_rate=1.0, max_depth=4),
DecisionTreeClassifier(),
SVC(),
]
#
# Тренировка и оценка точности
#
result = []
for classifier in classifiers:
classifier.fit(features, classes)
report = accuracy_score(testClasses, classifier.predict(testFeatures))
result.append({'class' : classifier.__class__.__name__, 'accuracy' : report})
display(HTML('<h2>Result</h2>'))
display(pd.DataFrame(result))
#
# Исследуем уровень важности предикторов
#
model = xgb.XGBClassifier()
model.fit(features, classes)
pylab.rcParams['figure.figsize'] = 3, 3
plt.style.use('ggplot')
pd.Series(model.feature_importances_).plot(kind='bar')
plt.title('Feature Importances')
plt.show()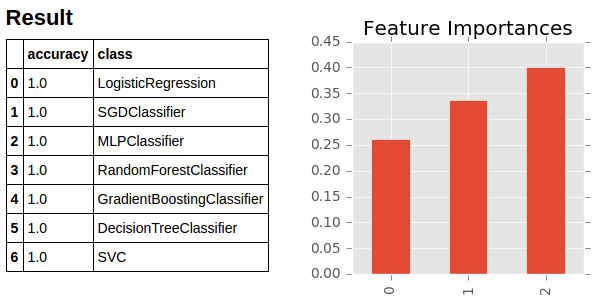
Как можно заметить, основные алгоритмы классификации уже реализованы в популярных библиотеках, что позволяет очень просто и быстро их задействовать буквально несколькими строками кода. Кроме этого, очень полезно у некоторых моделей посмотреть диаграмму уровня значимости предикторов с помощью подходящих для этого классификаторов (таких как: RandomForestClassifier, GradientBoostingClassifier, XGBClassifier). Весьма удобно выполнять и другие типы анализа и визуализации данных, например, кластерный анализ:
import pylab
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from mpl_toolkits.mplot3d import Axes3D
centroids = KMeans(n_clusters=4, random_state=0).fit(features).cluster_centers_
ax = Axes3D(pylab.figure())
ax.scatter(features[:, 0], features[:, 1], features[:, 2], c='blue', marker='p', s=8)
ax.scatter(centroids[:, 0], centroids[:, 1], centroids[:, 2], c='g', marker='o', s=80)
plt.show()4. Создание готовой модели
После того, как на локальной системе был выбран подходящий алгоритм с нужными параметрами, начинается подготовка распределённых вычислений, задача которых заранее предсказать класс события. Это может быть не просто бинарная классификация (случится событие или нет), но и многоклассовая классификация. Для таких задач распределённых вычислений часто используют Apache Spark (примеры показаны на Scala для версии 2.0.2). Разумеется, первые пробные запуски также требуют очень тщательную проверку выбранного решения на новых данных:
import org.apache.spark.ml.classification.MultilayerPerceptronClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
val train = spark.read.format("libsvm").load(file)
val test = spark.read.format("libsvm").load(fileTest)
val trainer = new MultilayerPerceptronClassifier().setLayers(Array[Int](3, 5, 4, 4)).setBlockSize(128).setSeed(1234L).setMaxIter(100)
val result = trainer.fit(train).transform(test)
val predictionAndLabels = result.select("prediction", "label")
val evaluator = new MulticlassClassificationEvaluator()
evaluator.setMetricName("accuracy").evaluate(predictionAndLabels)По окончанию процесса проверки и настройки, финальная версия алгоритма машинного обучения приступает к своей работе. Она размечает огромные массивы данных, а результаты отображаются в удобном для пользователя интерфейсе. За визуализацию отвечает отдельное приложение (часто это веб-риложение или часть портала). Как правило, приложение ничего не знает о системе анализа, а связана с ней только импортом в базу данных или через API. По моему личному опыту для отдельного отображающего приложения обычно используется известный стек технологий (PHP7, Yii 2, Laravel, MySQL, Redis, Memcached, RabbitMQ) для backend и набор библиотек для визуального представления (например, Chart.js и множество иных).
Таким образом, мы взглянули на основные шаги создания системы анализа поведенческих факторов. По аналогичному принципу работают и системы для классификации других наборов данных. Самыми основными шагами можно назвать сбор правильных метрик в пригодном формате (как говорят, «развернуть в вектор») и выбор подходящего алгоритма с нужными параметрами. Разумеется, критически важно проверить правильность работы классификатора.
Пользуясь случаем (учитывая сегодняшнюю дату) заранее поздравляю уважаемых читателей с наступающим новым годом и абсолютно искренни желаю счастья и успехов во всех сферах жизни.
Комментарии (5)

Ingref
29.12.2016 13:24+1Александр, можете привести пример, какие конкретно поведенческие факторы можно измерить таким образом? Пока и правда статья выглядит как измерение сферического коня в вакууме.

kalinin84
29.12.2016 14:27Спасибо за комментарий. Я побоялся приводить конкретные примеры алгоритмов сбора признаков, так как они не универсальны и очень сильно зависят от задачи. А вот сам принцип анализа (упомянутый в заметке) у них схожий. В любом случае, спасибо, я сделаю выводы.
novoxudonoser
Спасибо очень интересно, но вот только для человека не в теме очень сложно воспринимается нить рассказа. Было бы неплохо добавить немного описания для совсем бумбум в этой теме.
А есть ли алгоритмы машинного обучения которые работают с вероятностными входными данными? Как я понимаю везде используются огромные массивы точных данных, а как быть если данные не точны и имеют некоторую вероятность на правдивость, например с выхода другой системы обучения?
azsx
Это называется доверительный интервал. Рассчитать его несложно для статических ошибок при выборке и часто невозможно для систематических ошибок, которые зависят от внешних неизмеренных факторов.